





sql server 转发
This article discusses the Forwarded Records and its performance issues for heap tables in SQL Server.
本文讨论了SQL Server中堆表的转发记录及其性能问题。
堆介绍和性能问题 (Heap introduction and performance issues)
A page of 8KB is the smallest unit of storage in SQL Server. In each page of SQL Server, we have a 96-bytes header to store the system information. SQL Server stores the data in two ways:
8KB的页面是SQL Server中最小的存储单元。 在SQL Server的每一页中,我们都有一个96字节的标头来存储系统信息。 SQL Server以两种方式存储数据:
Clustered index
聚集索引
It stores data in a B+ tree structure according to the defined clustered index key. SQL Server stores the new or an update to an existing row in the correct logical position
它根据定义的聚簇索引关键字将数据存储在B +树结构中。 SQL Server将新行或更新行以正确的逻辑位置存储到现有行
Heap
堆
A table without any clustered index is a heap. A heap table stores data without any logical order. It does not link pages together because we do not have any defined key on heap tables. We can create a non-clustered index on the heap table, but that contains a physical address for the underlying data records. It contains file number, the page number and slot number inside that page for the record
没有任何聚集索引的表是一个堆。 堆表存储的数据没有任何逻辑顺序。 它不会将页面链接在一起,因为我们在堆表上没有任何定义的键。 我们可以在堆表上创建一个非聚集索引,但是它包含基础数据记录的物理地址。 它包含文件号,页号和该页内的插槽号作为记录
Page Free Space ( PFS) page
页面可用空间(PFS)页面
SQL Server scans the Page Free Space (PFS) page before inserting a new record into the heap table. If the data page contains enough free space, it stores the new row into the existing page. Alternatively, if it does not have sufficient free space, SQL Server allocates an extent (eight new data pages – 64 KB). PFS monitors each data page using two bits as specified below:
在将新记录插入堆表之前,SQL Server扫描页面可用空间(PFS)页面。 如果数据页包含足够的可用空间,则它将新行存储到现有页中。 或者,如果没有足够的可用空间,则SQL Server会分配一个扩展区(八个新的数据页– 64 KB)。 PFS使用以下指定的两位监视每个数据页:
0x00
Empty data page
0x01
50 % full data page
0x02
51 to 80% full data page
0x03
81 to 95% full data page
0x04
96 to 100 % full data page
0x00
空数据页
0x01
50%的完整数据页
0x02
51至80%的完整资料页面
0x03
81至95%的完整资料页面
0x04
96至100%的完整资料页面
转发记录问题模拟 (Forwarded Record issue simulation)
Let’s say, we update existing data in a heap table. SQL Server cannot accommodate the new data into the existing page due to its larger data size. In this case, this data is stored in a different storage location, and SQL Server inserts a Forwarded Record in the original data location. SQL Server also maintains a pointer at the new data location pointing to the forwarded pointer so that it can keep track of the forwarding pointer chain in case of any data movement.
假设,我们更新了堆表中的现有数据。 由于较大的数据大小,SQL Server无法将新数据容纳到现有页面中。 在这种情况下,此数据存储在其他存储位置,并且SQL Server在原始数据位置插入转发记录 。 SQL Server还在指向转发指针的新数据位置维护一个指针,以便在发生任何数据移动时它可以跟踪转发指针链。
Let’s create a heap table and reproduce the forwarded record scenario:
让我们创建一个堆表并重现转发的记录方案:
创建数据库和堆表Employees (Create a database and heap table Employees)
CREATE DATABASE SQLShack;
GO
USE SQLShack;
GO
CREATE TABLE Employees
([EmpID] INT IDENTITY(1, 1),
[Name] NVARCHAR(100),
[BirthDate] DATETIME,
[Salary] INT
);
Insert sample records
INSERT INTO Employees
VALUES
('Rajendra',
'1986-03-16',
50000
);
GO 2000
INSERT INTO Employees
VALUES
('Sonu',
'1980-11-29',
50000
);
GO 1000
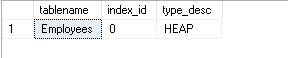
Heap tables have index id zero, and you can identify heap tables using the sys.indexes system view. The following command shows the required output from the system view:
堆表的索引ID为零,您可以使用sys.indexes系统视图标识堆表。 以下命令从系统视图显示所需的输出:
SELECT OBJECT_NAME(object_id) AS tablename,
index_id,
type_desc
FROM sys.indexes
WHERE object_id = OBJECT_ID('Employees');
We use dynamic management function (DMF) sys.dm_db_index_physical_stats for checking index fragmentation percentage, table index type, page counts and forwarded record counts. These details are available in the DETAILED mode of this DMV:
我们使用动态管理功能(DMF) sys.dm_db_index_physical_stats来检查索引碎片百分比,表索引类型,页数和转发记录数。 这些详细信息在此DMV的“详细”模式下可用:
SELECT
OBJECT_NAME(DIPS.object_id) as DBTableName,
DIPS.index_type_desc,
DIPS.avg_fragmentation_in_percent,
DIPS.forwarded_record_count,
DIPS.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS DIPS
WHERE OBJECT_NAME(DIPS.object_id) = 'Employees' AND forwarded_record_count is NOT NULL
In the above screenshot, we can see 17 pages for the heap table Employees and zero forwarded record counts.
在上面的屏幕截图中,我们可以看到17个页面用于堆表Employees和零转发记录计数。
Insert a few more records using the following query. It should increase the pages and index fragmentation:
使用以下查询插入更多记录。 它应该增加页面和索引碎片:
INSERT INTO Employees
VALUES
('Kusum',
'1985-09-25',
60000
);
GO 2000
Re-execute the DMF query specified above and validate the page counts and forward record counts:
重新执行上面指定的DMF查询,并验证页数和转发记录数:
- Page Counts increases from 17 to 27 页数从17增加到27
- Fragmentation increases from 33 to 50% 碎片从33%增加至50%
- Forwarded record counts still at Zero 转发的记录数仍为零

Now, update the records in the Employee table for variable-length column [Name]:
现在,更新Employee表中可变长度列[Name]的记录:
UPDATE Employees
SET
[Name] = 'Rajendra Kumar Gupta'
WHERE [Name] = 'Rajendra';
Now, again use the DMF and view the forward record counts:
现在,再次使用DMF并查看转发记录计数:
- Page Counts increases from 27 to 35 页数从27增加到35
- Forwarded record counts increase from zero to 747 转发的记录数从零增加到747
Let’s perform a few more updates using the following query:
让我们使用以下查询执行更多更新:
UPDATE Employees
SET
[Name] = 'Kusum Kashish Agarwal'
WHERE [Name] = 'Kusum'
In the following screenshot, note the things:
在以下屏幕截图中,请注意以下事项:
- Page Counts increases from 35 to 46 页数从35增加到46
- Forwarded record counts increase from 747 to 1752 转发的记录数从747增加到1752
SQL Server could not accommodate the new updates in the existing pages and created the forward records that increase page counts and forwarded_record_counts.
SQL Server无法在现有页面中容纳新更新,并创建了增加页数和forwarded_record_counts的转发记录。
问题:转发记录是否会导致性能问题? (Question: Do Forwarded Records cause any performance issues?)
Yes, we can see a performance impact on the heap table due to these Forwarded Records. Execute the select statement that performs the search on the [Name] column. We enable the statistics IO to capture the required statistics:
是的,由于这些转发记录,我们可以看到对堆表的性能影响。 在[Name]列上执行执行搜索的select语句。 我们启用统计信息IO来捕获所需的统计信息:
SET STATISTICS IO ON;
SELECT *
FROM dbo.Employees
WHERE name LIKE 'Rajendra%';
In the execution plan, we can see a table scan operator for the heap:
在执行计划中,我们可以看到堆的表扫描运算符:
In the following image, we can see the SQL Server uses IAM pages to find the pages and extents that requires a scan. It analyzes the extent belonging to the heap table and processes them on their allocation order:
在下图中,我们可以看到SQL Server使用IAM页面来查找需要扫描的页面和范围。 它分析属于堆表的扩展区,并按照其分配顺序对其进行处理:
If the page allocation changes, it also changes the order in which pages need to be scanned. Here, it scans a page before page 2 because of its allocation:
如果页面分配发生更改,它也会更改需要扫描页面的顺序。 在这里,由于分配原因,它扫描了第2页之前的页面:
In the message tab of previous query execution, it shows information about logical, physical scans. We can see 1798 logical read operations for retrieving the requested data:
在先前查询执行的消息选项卡中,它显示有关逻辑,物理扫描的信息。 我们可以看到1798逻辑读取操作,用于检索请求的数据:

In the case of a large heap table, we can see the considerable value of these logical reads that can be causing performance issues for the data retrieval, DML’s.
在大型堆表的情况下,我们可以看到这些逻辑读取的巨大价值,这些逻辑读取可能会导致数据检索DML的性能问题。
转发记录问题修复 (Forwarded Records issue fixes)
使用固定长度的数据类型 (Use fixed-length data type)
Sometimes, we use heap tables for the staging tables and do not require clustered index on a heap table. The best way to fix these forwarded record issues and avoid so many logical reads is by using fixed-length data types. We should not use variable-length data types unless required.
有时,我们将堆表用于登台表,而不需要堆表上的聚集索引。 解决这些转发的记录问题并避免进行如此多的逻辑读取的最佳方法是使用固定长度的数据类型。 除非需要,否则我们不应使用可变长度数据类型。
使用聚集索引 (Use a Clustered index)
We should add a clustered index to a table because it sorts and stores data as per the clustered index key. It works for existing as well as new and updated data. Ideally, we should define a primary key on the table as it creates a clustered index key by default.
我们应该向表中添加聚集索引,因为它会根据聚集索引键对数据进行排序和存储。 它适用于现有数据以及新数据和更新数据。 理想情况下,我们应该在表上定义一个主键,因为它默认情况下会创建聚簇索引键。
监视和重建堆表 (Monitor and rebuild heap table)
If due to any specific requirement, we cannot use fixed-length data type or clustered index on a heap table, the best way is to monitor heap tables for Forwarded Records using the scripts provided earlier. We can use Alter Table..REBUILD command to rebuild a heap table. It is available from SQL Server 2008. It also updates the non-clustered index on the heap table.
如果由于任何特定要求,我们不能在堆表上使用固定长度的数据类型或聚簇索引,最好的方法是使用前面提供的脚本来监视堆表中的转发记录。 我们可以使用Alter Table..REBUILD命令来重建堆表。 它可以从SQL Server 2008获得。它还更新堆表上的非聚集索引。
重建表之前进行逻辑读取 (Logical reads before table rebuild)

重建堆表 (Rebuild heap table)
Execute the following command to rebuild Employee heap table:
执行以下命令重建Employee堆表:
ALTER TABLE Employees REBUILD;
重建后验证逻辑读取 (Verify the logical reads after rebuild)

We can notice the following change:
我们可以注意到以下变化:
- Logical Reads before heap rebuild: 1798 堆重建之前的逻辑读取:1798年
- Logical Reads after heap rebuild: 40 堆重建后的逻辑读取:40
Alter table command completely rebuilds the heap and removes all Forwarded Records. We do not any Forwarded Records after rebuild. Let’s verify it:
Alter table命令完全重建堆并删除所有转发记录。 重建后,我们没有任何转发记录。 让我们验证一下:
- Page Counts reset to 40 from 46 页面计数从46重置为40
- Forwarded record counts become zero from 1752 to zero 转发的记录数从1752年的零变为零
- Average fragmentation for heap also reduces to zero from the previous 33 percent 堆的平均碎片也从之前的33%减少到零
结论 (Conclusion)
Database design is an essential criterion for the developers and database administrators for avoiding performance issues due to design. In this article, we explored the Forwarded Records issues with the heap table and logical reads due to these large forwarded record counts. It also wastes the database pages due to Forwarded Records and put IO performance issues due to the large tables. We should try to avoid heap tables and if required, take the necessary steps outlined above.
数据库设计是开发人员和数据库管理员避免设计引起的性能问题的重要标准。 在本文中,由于这些大量的转发记录数,我们探讨了堆表和逻辑读取的转发记录问题。 它还由于转发记录而浪费数据库页面,并且由于表太大而导致IO性能问题。 我们应尽量避免使用堆表,并在需要时采取上述概述的必要步骤。
翻译自: https://www.sqlshack.com/forwarded-records-performance-issue-in-sql-server/
sql server 转发















 83
83

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









