






In the previous articles of this series (see below for the full index of articles), we went through the internal structure of SQL Server tables and indexes, listed a number of guidelines that help in designing a proper index, discussed the operations that can be performed on SQL Server indexes and finally showed how to design and create a SQL Server Clustered index to speed up data retrieval operations. In this article, we will see how to design an effective Non-clustered index that will improve the performance of frequently used queries that are not covered with a Clustered index and, in doing so, enhance the overall system performance.
在本系列的前几篇文章中(有关文章的完整索引,请参见下文),我们介绍了SQL Server表和索引的内部结构,列出了许多有助于设计适当索引的准则,并讨论了可以进行的操作。在SQL Server索引上执行,最后展示了如何设计和创建SQL Server群集索引以加快数据检索操作。 在本文中,我们将看到如何设计有效的非聚集索引,该索引将提高聚集索引未涵盖的常用查询的性能,并以此提高整体系统性能。
非聚集索引结构概述 (Non-clustered index structure overview)
A Non-clustered index is built using the same 8K-page B-tree structure that is used to build a Clustered index, except that the data and the Non-clustered index are stored separately. A Non-clustered index is different from a Clustered index in that, the underlying table rows will not be stored and sorted based on the Non-clustered key, and the leaf level nodes of the Non-clustered index are made of index pages instead of data pages. The index pages of the Non-clustered index contain Non-clustered index key values with pointers to the storage location of these rows in the underlying heap table or the Clustered index.
非聚集索引使用与用于建立聚集索引相同的8K页B树结构构建,除了数据和非聚集索引是分开存储的。 非聚集索引与聚集索引的不同之处在于,将不会基于非聚集键存储基础表行并对其进行排序,并且非聚集索引的叶级节点由索引页而不是索引页组成数据页。 非聚集索引的索引页包含非聚集索引键值,这些键值具有指向基础堆表或聚集索引中这些行的存储位置的指针。
If a Non-Clustered index is built over a heap table or view (read more about SQL Server indexed views, that have no Clustered index) the leaf level nodes of that index hold the index key values and Row ID (RID) pointers to the location of the rows in the heap table. The RID consists of the file identifier, the data page number, and the number of rows on that data page. On the other hand, if a Non-clustered index is created over a Clustered table, the leaf level nodes of that index contain Non-clustered index key values and clustering keys for the base table, that are the locations of the rows in the Clustered index data pages. If a Non-clustered index is built over a non-unique Clustered index, the leaf level nodes of the Non-clustered index will hold additional uniqueifier values of the data rows, that is added by the SQL Server Engine to ensure uniqueness of the Clustered index.
如果在堆表或视图(非SQL索引视图的更多信息,没有聚簇索引)上构建了非聚集索引,则该索引的叶级节点将保留索引键值和指向该索引的行ID(RID)指针。行在堆表中的位置。 RID由文件标识符,数据页号和该数据页上的行数组成。 另一方面,如果在聚簇表上创建了非聚簇索引,则该索引的叶级节点包含基表的非聚簇索引键值和聚簇键,它们是聚簇中行的位置索引数据页。 如果在非唯一聚集索引上构建了非聚集索引,则非聚集索引的叶级节点将保存数据行的其他唯一标识符值,该值由SQL Server引擎添加以确保簇的唯一性指数。
When submitting a query that searches for specific rows based on Non-clustered index key values, the SQL Server Query Optimizer will search for that key value in the Non-clustered index pages and use the row locator value to locate the requested row in the underlying table, then retrieve the requested records directly from the data storage location, speeding up the data retrieval process, as the Non-clustered index holds a full description for the data exact location in underlying table, based on the index key values.
提交基于非聚集索引键值搜索特定行的查询时,SQL Server查询优化器将在非聚集索引页中搜索该键值,并使用行定位符值在基础中找到请求的行表,然后直接从数据存储位置检索请求的记录,从而加快了数据检索过程,因为非聚集索引根据索引键值对基础表中的数据确切位置拥有完整的描述。
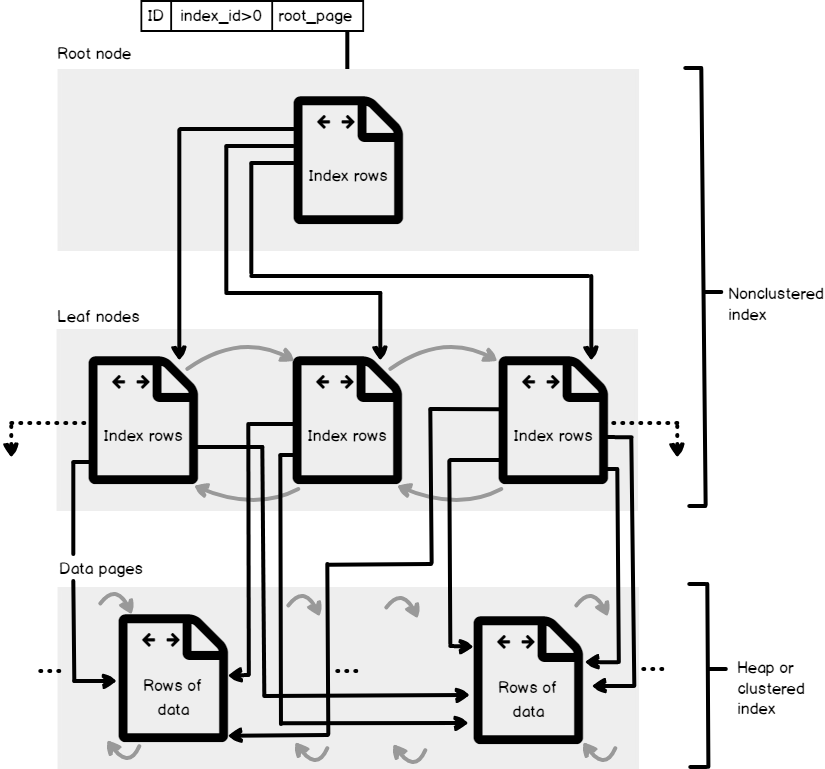
The below figure, from Microsoft Books Online, shows the structure of a Non-clustered index that is built over a Clustered or heap table as described previously. SQL Server allows us to create multiple Non-clustered indexes, up to 999 Non-clustered indexes, on each table, with index IDs values assigned to each index starting from 2 for each partition used by the index, as you can find in the sys.partitions table. Depending on the data type of the columns participating in Non-clustered index key, a SQL Server Non-clustered index will have one or more allocation units that are used to store and manage the index data. Minimally, each Non-clustered index will have the IN_ROW_DATA allocation unit to store the index data. Other special types of allocation units can be also used to store the Non-clustered index data, such as the LOB_DATA allocation unit that is used to store the large object data (LOB) and ROW_OVERFLOW_DATA allocation unit that is used to store the columns with variable length exceeds the 8,060-byte size limit of the row.
下图来自Microsoft联机丛书 ,显示了如前所述在群集表或堆表上构建的非群集索引的结构。 SQL Server允许我们在每个表上创建多个非聚集索引,最多可创建999个非聚集索引,并为索引所使用的每个分区的索引分配从2开始的索引ID值,如您在sys中所发现的那样.partitions表。 根据参与非聚集索引键的列的数据类型,SQL Server非聚集索引将具有一个或多个用于存储和管理索引数据的分配单元。 最少,每个非聚集索引都将具有IN_ROW_DATA分配单元来存储索引数据。 其他特殊类型的分配单元也可以用于存储非聚集索引数据,例如用于存储大对象数据(LOB)的LOB_DATA分配单元和用于存储具有可变列的列的ROW_OVERFLOW_DATA分配单元长度超过了该行的8,060字节大小限制。
非聚集索引设计注意事项 (Non-clustered index design considerations)
The main goal of creating a Non-clustered index is to improve query performance by speeding up the data retrieval process. Although SQL Server allows us to create multiple Non-clustered indexes, up to 999 Non-clustered on each table that can cover our queries, any index added to the table will negatively impact data modification performance on that table. This is due to the fact that, when you modify a key column in the underlying table, the Non-clustered indexes should be adjusted appropriately as well.
创建非聚集索引的主要目标是通过加快数据检索过程来提高查询性能。 尽管SQL Server允许我们创建多个非聚集索引,但每个表上最多可以包含999个非聚集索引,这些索引可以覆盖我们的查询,但是添加到表中的任何索引都会对该表的数据修改性能产生负面影响。 这是由于以下事实:在修改基础表中的键列时,也应适当调整非聚集索引。
When designing a Non-clustered index, you should consider the type of the workload performed on your database or table by compromising between the benefits taken from creating a new index and the data modification overhead that will be caused by this index creation. It is recommended to create a minumu of narrow indexes, with a minimum number of columns participating in the index key, on the heavily updated table. A table that has a large number of rows with a low data modification requirement can heavily benefit from more Non-clustered indexes with composite index keys, that contain more than one column in the index key, that cover all columns in the query to improve the data retrieval performance.
在设计非聚集索引时,应通过在创建新索引所带来的好处与该索引创建将导致的数据修改开销之间折中考虑,来考虑在数据库或表上执行的工作负载的类型。 建议在高度更新的表上创建最少的窄索引,并在索引键中包含最少的列。 具有大量行且数据修改要求低的表可以从具有复合索引键的更多非聚簇索引中受益匪浅,这些索引索引的索引键中包含多个列,这些索引覆盖了查询中的所有列,从而改善了数据检索性能。
When the index contains all columns required by the query, the SQL Server Query Optimizer will retrieve all column values from the index itself, without the need to perform lookup operations to retrieve the rest of columns in the underlying table or the Clustered index, reducing the costly disk I/O operations. In addition, if the Non-clustered index is built over a Clustered table, the columns that participate in the Clustered index will be appended automatically to the end of each Non-clustered index on that Clustered table, without the need to include these columns to the Non-clustered index key or non-key columns to cover the queries.
当索引包含查询所需的所有列时,SQL Server查询优化器将从索引本身检索所有列值,而无需执行查找操作来检索基础表或群集索引中的其余列,从而减少了昂贵的磁盘I / O操作。 另外,如果非聚簇索引建立在聚簇表之上,则参与聚簇索引的列将自动附加到该聚簇表上每个非聚簇索引的末尾,而无需将这些列包括在内。非聚集索引键或非键列来覆盖查询。
Rather than creating a Non-clustered index with a wide key, large columns that are used to cover the query can be included to the Non-clustered index as non-key columns, up to 1023 non-key columns, using the INCLUDE clause of the CREATE INDEX T-SQL statement, that is introduced in SQL Server 2005 version, with a minimum of one key column. The INCLUDE feature extends the functionality of the Non-clustered index, by allowing us to cover more queries by adding the columns as non-key columns to be stored and sorted only in the leaf level of the index, without considering that columns values in the root and intermediate levels of the Non-clustered index. In this case, the SQL Server Query Optimizer will locate all required columns from that index, without the need for any extra lookups. Using the included columns can help to avoid exceeding the Non-clustered size limit of 900 bytes and 16 columns in the index key, as the SQL Server Database Engine will not consider the columns in the Non-clustered index non-key when calculating the size and number of columns of the index key. In addition, SQL Server allows us to include the columns with data types that are not allowed in the index key, such as VARCHAR(MAX), NVARCHAR
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 367
367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









