





描述 (Description)
SQL Server 2016 includes a variety of query optimizer enhancements. Some of these have existed since the first previews while others were added later. This is an opportunity to discuss, test out, and validate the behavior and benefits of these changes!
SQL Server 2016包括各种查询优化器增强功能。 其中一些自第一次预览以来就存在,而其他则后来添加。 这是讨论,测试和验证这些更改的行为和收益的机会!
细节 (The Details)
What follows is a feature-by-feature walkthrough, with some demos, explanations, and the implications of each change based on my testing and analysis. Some of these changes are very straightforward and do not require any real testing, but discussion is still worth the time and effort 🙂
接下来是一个逐个功能的演练,其中包含一些演示,说明以及根据我的测试和分析得出的每个更改的含义。 其中一些更改非常简单明了,不需要任何实际测试,但是讨论仍然值得时间和精力time
兼容性等级保证 (Compatibility Level Guarantee)
Any database may have its compatibility mode set to a previous (supported) version of SQL Server. This allows some level of backward compatibility between a newer version of SQL Server and an older one. By doing so, we can facilitate a smoother upgrade between versions, knowing that we are not immediately cutting the cord on all discontinued or altered features. Despite being in a compatibility mode, you can still take advantage of new SQL Server features, so long as they do not directly conflict with a feature of the older compatibility level you are using.
任何数据库都可以将其兼容模式设置为SQL Server的先前(受支持)版本。 这样可以在较新版本SQL Server和较旧版本SQL Server之间实现某种程度的向后兼容性。 这样一来,我们就知道不会立即切断所有已终止或已更改功能的电源,从而可以促进版本之间的平滑升级。 尽管处于兼容模式,但只要不与所使用的旧兼容性级别的功能直接冲突,您仍然可以利用SQL Server的新功能。
We can validate the current compatibility mode for any (or all) databases on a server via the sys.databases system view:
我们可以通过sys.databases系统视图验证服务器上任何(或所有)数据库的当前兼容模式:
SELECT
databases.name,
databases.compatibility_level
FROM sys.databases;
The results are a list of databases and their associated compatibility mode. This is a nice quick way to verify if any databases have an old compatibility level, or are not at a desired version:
结果是数据库及其关联的兼容模式的列表。 这是一种验证任何数据库是否具有旧兼容性级别或未达到所需版本的好方法:
SELECT
databases.name,
databases.compatibility_level
FROM sys.databases
WHERE databases.compatibility_level <= 100
Running this on my local machine returns a single database that is running under SQL Server 2008R2 compatibility mode:
在本地计算机上运行此命令将返回在SQL Server 2008R2兼容模式下运行的单个数据库:
Compatibility mode may be updated using an ALTER DATABASE command, such as this:
可以使用ALTER DATABASE命令来更新兼容模式,例如:
ALTER DATABASE AdventureWorks2014
SET COMPATIBILITY_LEVEL = 130;
This TSQL will adjust AdventureWorks2014 to use SQL Server 2016 compatibility.
此TSQL将调整AdventureWorks2014以使用SQL Server 2016兼容性。
Prior to SQL Server 2016, running a database in a previous version’s compatibility mode had no guarantees with regards to the behavior of the query optimizer and the executions plans it generated. Starting in SQL Server 2016, Microsoft guarantees that new query optimizer improvements will only be available in compatibility level 130. If you are running a database on a SQL Server 2016 server, but it is in an earlier compatibility mode, then no new optimizer features will be applied when queries are executed in your database.
在SQL Server 2016之前,以以前版本的兼容模式运行数据库无法保证查询优化器的行为及其生成的执行计划。 从SQL Server 2016开始,Microsoft保证仅在兼容级别130中提供对新查询优化器的改进。如果您在SQL Server 2016服务器上运行数据库,但是它处于较早的兼容模式,则不会有新的优化器功能在数据库中执行查询时应用。
This means that if you upgrade a server from SQL Server 2014 to 2016 and leave a database in compatibility level 120, then query plans will remain the same as they were on the old version. New optimizer features will only become available when the database is altered to utilize compatibility level 130.
这意味着,如果将服务器从SQL Server 2014升级到2016,并使数据库的兼容性级别为120,则查询计划将与旧版本相同。 仅当更改数据库以利用兼容性级别130时,新的优化器功能才可用。
兼容性级别130的变化 (Changes in Compatibility Level 130)
What changes when you move to compatibility level 130? Here’s a brief list with a bit of detail:
当您升级到兼容级别130时,会有什么变化? 这是一个简短列表,其中包含一些细节:
MD2, MD4, MD5, SHA, and SHA1 hash algorithms are no longer supported. Use SHA2_256 or SHA2_512 instead.
不再支持MD2,MD4,MD5,SHA和SHA1哈希算法。 请改用SHA2_256或SHA2_512。
A given table can now have 10,000 foreign keys or referential constraints. The limit used to be 253. That is a LOT of foreign keys!
给定的表现在可以具有10,000个外键或引用约束。 以前的限制是253。这是很多外键!
Statistics sampling is now multi-threaded. All previous versions were single-threaded.
现在,统计信息采样是多线程的。 所有以前的版本都是单线程的。
Trace flag 2371 is on by default, whereas in all previous versions it was off. This trace flag changes how automatically updating statistics determine when to update and how to update. Without it enabled, statistics would update when 20% of a table changed. For smaller tables, this is generally acceptable. For larger tables, it become untenable. The trace flag makes it so that statistics are auto-updated for a smaller % of change, starting at about 25k rows, which is ideal for very large tables. In SQL Server 2016, in addition to the trace flag being on, improvements have been made to which rows are sampled (leaning towards newer data). Lastly, auto-updating statistics will no longer block queries while running.
跟踪标记2371默认情况下处于打开状态,而在所有以前的版本中,它处于关闭状态。 此跟踪标志更改自动更新统计信息确定何时更新以及如何更新的方式。 如果不启用它,则当表的20%更改时,统计信息将更新。 对于较小的表,这通常是可以接受的。 对于较大的表,它变得站不住脚。 跟踪标志使它可以自动更新统计信息,以实现较小的变化(从大约25,000行开始),这对于非常大的表是理想的选择。 在SQL Server 2016中,除了启用了跟踪标记之外,还对采样行进行了改进(倾向于更新数据)。 最后,运行时自动更新统计信息将不再阻止查询。
Batch mode is used by the optimizer for more operations in SQL Server 2016 than it was previously. This mode allows batches of rows to be operated on by a CPU, rather than one at a time. This greatly improves performance on large data sets, and can be very helpful in warehousing or other environments with massive amounts of data. Prior to SQL Server 2016, batch mode could be used with columnstore indexes, but its use was limited. In the new version, batch mode can be used for:
优化程序使用批处理模式在SQL Server 2016中执行比以前更多的操作。 此模式允许CPU批量处理一行,而不是一次处理一行。 这极大地提高了大数据集的性能,并且在仓储或其他具有大量数据的环境中非常有帮助。 在SQL Server 2016之前,批处理模式可以与列存储索引一起使用,但是其使用受到限制。 在新版本中,批处理模式可用于:
Sorts using columnstore indexes
使用列存储索引排序
Window function aggregation
窗口函数聚合
Multiple distinct operators on columnstore indexes
列存储索引上的多个不同运算符
Queries with serial plans, or those under maximum degree of parallelism = 1.
具有串行计划或最大并行度= 1的查询。
Cardinality estimation is improved, beyond those enhancements found in SQL Server 2014.
除了SQL Server 2014中的增强功能外,基数估计也得到了改进。
Queries on In-Memory OLTP tables can utilize parallel execution plans.
内存中OLTP表的查询可以利用并行执行计划。
INSERT INTO…SELECT queries can be multi-threaded or benefit from a parallel execution plans.
INSERT INTO…SELECT查询可以是多线程的,也可以受益于并行执行计划。
These changes are almost exclusively enhancements—each improving how execution plans or statistics are managed or adding parallelism into plans that previously could not benefit from it. If you’re using old has algorithms that are discontinued in SQL Server 2016, be sure to transition to newer ones that are supported prior to upgrading your compatibility level.
这些更改几乎完全是增强功能-分别改善了执行计划或统计数据的管理方式,或者向以前无法从中受益的计划中增加了并行性。 如果您使用的旧算法在SQL Server 2016中已终止,请确保在升级兼容性级别之前过渡到受支持的新算法。
参照完整性运算符 (Referential Integrity Operator)
Foreign keys provide referential integrity between tables, ensuring that write operations on either do not render the related columns orphaned. Whenever a foreign key column is written, a check must occur of the referenced table to ensure the write operation doesn’t violate the foreign key definition.
外键提供表之间的引用完整性,确保对其中任何一个的写操作都不会使相关列变为孤立状态。 每当写入外键列时,都必须检查被引用的表,以确保写操作不会违反外键定义。
In previous versions of SQL Server, this meant that scans or seeks would be performed against the parent table in order to validate a write operation, prior to it being committed. The specific operations required to validate the foreign key would be explicitly shown in the execution plan, for all referenced tables. In SQL Server 2016, the Foreign Key References Check is introduced to handle all referential integrity checks in a single step. Microsoft’s documentation indicates that this change will greatly simplify execution plans and reduce compilation time for the execution plan.
在早期版本SQL Server中,这意味着将在提交父表之前对父表执行扫描或查找,以验证写操作。 对于所有引用的表,验证外键所需的特定操作将在执行计划中明确显示。 在SQL Server 2016中,引入了外键引用检查以在一个步骤中处理所有引用完整性检查。 Microsoft的文档表明,此更改将大大简化执行计划并减少执行计划的编译时间。
What does this mean for any existing keys and the queries that write to related columns? Let’s take a few minutes to run some tests and find out exactly how this new operator performs and compares to what we experienced in previous versions.
这对于任何现有键和写入相关列的查询意味着什么? 让我们花几分钟时间进行一些测试,并确切地了解该新操作员的性能,并与我们在以前版本中所经历的进行比较。
We’ll start with some simple updates on Production.Product (in AdventureWorks) under compatability mode 120, which indicates that we will use the optimizer rules taken from SQL Server 2014:
我们将从兼容性模式120下的Production.Product (在AdventureWorks中 )进行一些简单的更新开始,这表明我们将使用从SQL Server 2014中获取的优化程序规则:
UPDATE Production.Product
SET WeightUnitMeasureCode = 'LB',
SizeUnitMeasureCode = 'LB'
WHERE Product.ProductID = 919;
UPDATE Production.Product
SET WeightUnitMeasureCode = 'G',
SizeUnitMeasureCode = 'CM '
WHERE Product.ProductID = 919
These updates each are affecting two foreign-keyed columns, both of which link back to Production.UnitMeasure. As a result, when we update them, it is necessary to validate referential integrity for each value added here:
这些更新每个都影响两个外键列,这两个外键列都链接回到Production.UnitMeasure 。 因此,当我们更新它们时,有必要验证此处添加的每个值的参照完整性:
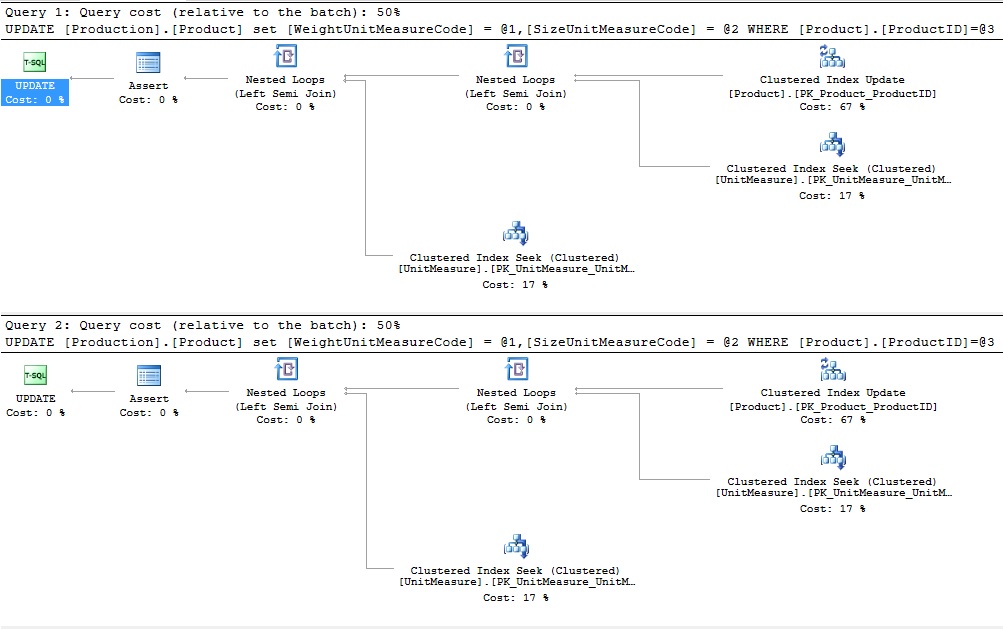
These plans each show that each individual update is check for a valid value in the parent table. Note that in the first update statement, we use the same value twice. Common sense would tell us that it should only be necessary to validate this once, but the optimizer will check Production.UnitMeasure twice anyway. These checks take the firm of the two clustered index seeks seen in each of the above execution plans.
这些计划均表明,每个单独的更新都在父表中检查有效值。 请注意,在第一个update语句中,我们两次使用相同的值。 常识告诉我们,只需要验证一次即可,但是优化程序无论如何都要检查Production.UnitMeasure两次。 这些检查采用了在以上每个执行计划中看到的两个聚集索引查找的确定性。
With SQL Server 2016, we are promised a new operator that will make checks such as these more efficient and better documented. The latter is a useful point, as in large queries, it might not be immediately obvious which operators refer to a referential integrity check and not the active query itself.
通过SQL Server 2016,我们有望获得一个新的操作员,该操作员将使诸如此类的检查更加有效且有据可查。 后者是有用的一点,因为在大型查询中,可能不是立即显而易见的是哪个运算符是引用参照完整性检查,而不是活动查询本身。
Let’s update our compatibility mode to 130, which will allow the use of the new optimizer enhancements:
让我们将兼容模式更新为130,这将允许使用新的优化程序增强功能:
Now that we can make use of the new operator, let’s test it with one of our updates from above:
现在我们可以使用new运算符,让我们使用上面的更新之一对其进行测试:
UPDATE Production.Product
SET WeightUnitMeasureCode = 'LB',
SizeUnitMeasureCode = 'LB'
WHERE Product.ProductID = 919;
The resulting execution plan is the same as earlier:
产生的执行计划与之前的相同:
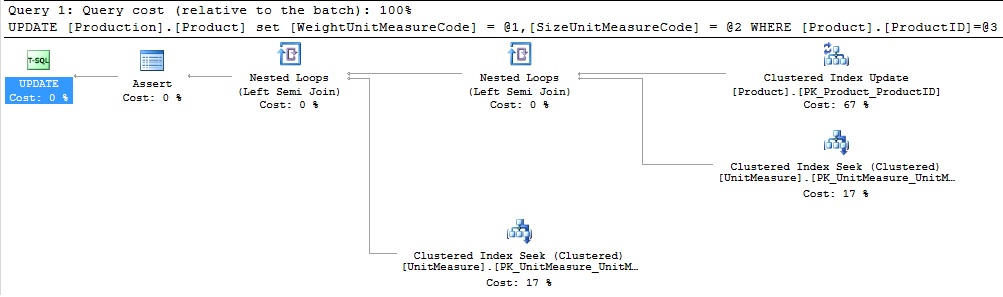
Well, that was uneventful. We hoped for a new, shiny plan operator and instead got exactly the same results as before. Let’s try a few other queries and see what changes we can uncover:
好吧,那很顺利。 我们希望有一个新的,有光泽的计划运营商,而不是得到与以前完全相同的结果。 让我们尝试其他一些查询,看看我们可以发现哪些变化:
INSERT INTO Production.Product
( Name
,ProductNumber
,MakeFlag
,FinishedGoodsFlag
,Color
,SafetyStockLevel
,ReorderPoint
,StandardCost
,ListPrice
,Size
,SizeUnitMeasureCode
,WeightUnitMeasureCode
,Weight
,DaysToManufacture
,ProductLine
,Class
,Style
,ProductSubcategoryID
,ProductModelID
,SellStartDate
,SellEndDate
,DiscontinuedDate
,rowguid
,ModifiedDate )
SELECT
'Wing Nut',
'WN-1234',
1,
0,
'Silver',
1000,
500,
1.00,
1.50,
NULL,
'G',
'CM',
NULL,
0,
NULL,
NULL,
NULL,
NULL,
NULL,
CAST(CURRENT_TIMESTAMP AS DATE),
NULL,
NULL,
NEWID(),
CURRENT_TIMESTAMP;
DELETE FROM Production.Product WHERE Name = 'Wing Nut';
INSERT INTO production.UnitMeasure
(UnitMeasureCode, Name, ModifiedDate)
SELECT
'WOW',
'The wow factor!',
CURRENT_TIMESTAMP;
DELETE FROM Production.UnitMeasure
WHERE UnitMeasureCode = 'WOW';
If updates don’t seem to get what we want, we should also try out some inserts and deletes. Running the above queries will add a row to Production.Product and Production.UnitMeasure, respectively, and then delete those rows. The resulting execution plans for the above queries are as follows:
如果更新似乎没有得到我们想要的,我们还应该尝试一些插入和删除操作。 运行以上查询将分别向Production.Product和Production.UnitMeasure添加一行,然后删除这些行。 以上查询的结果执行计划如下:
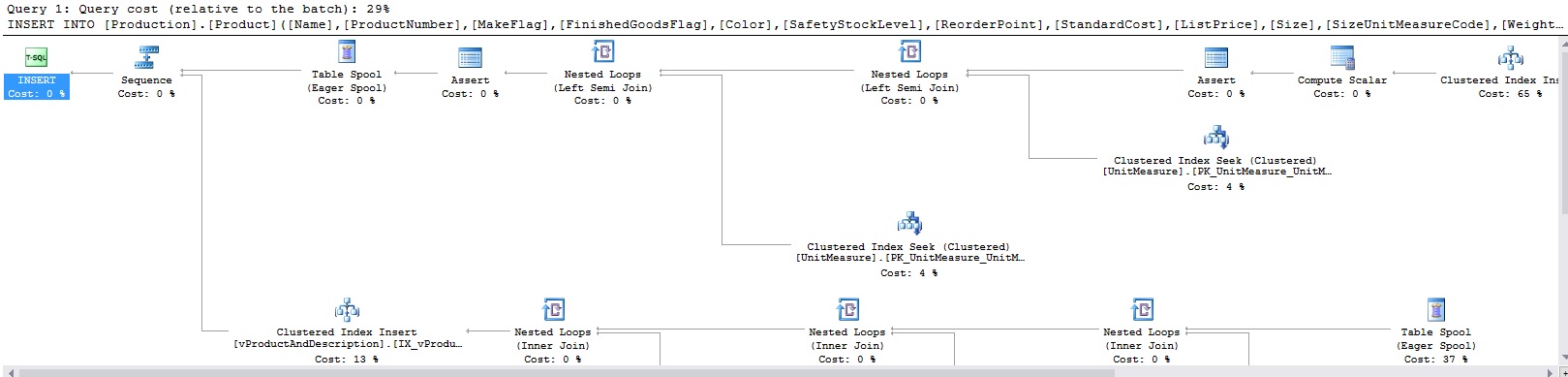
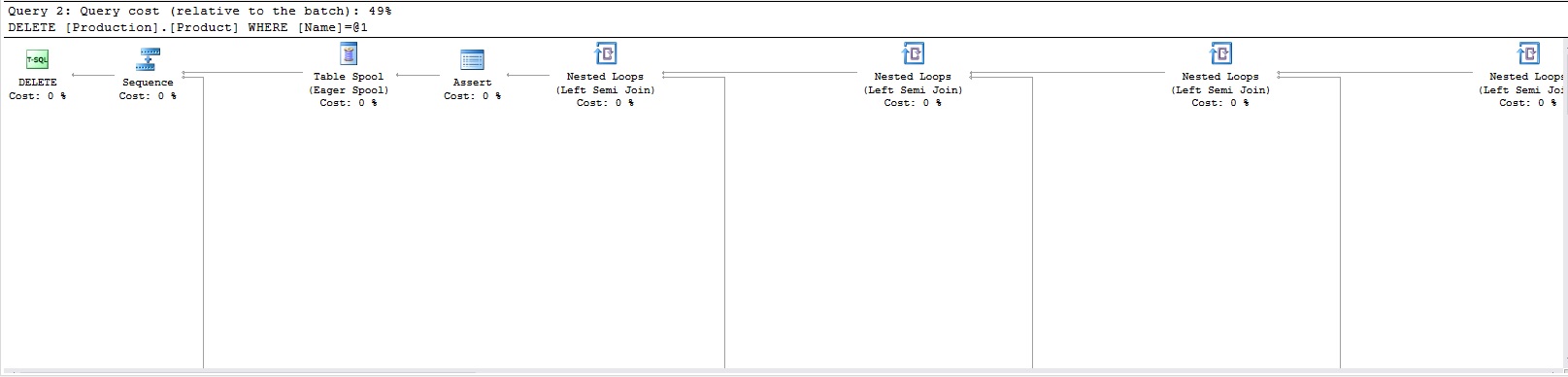
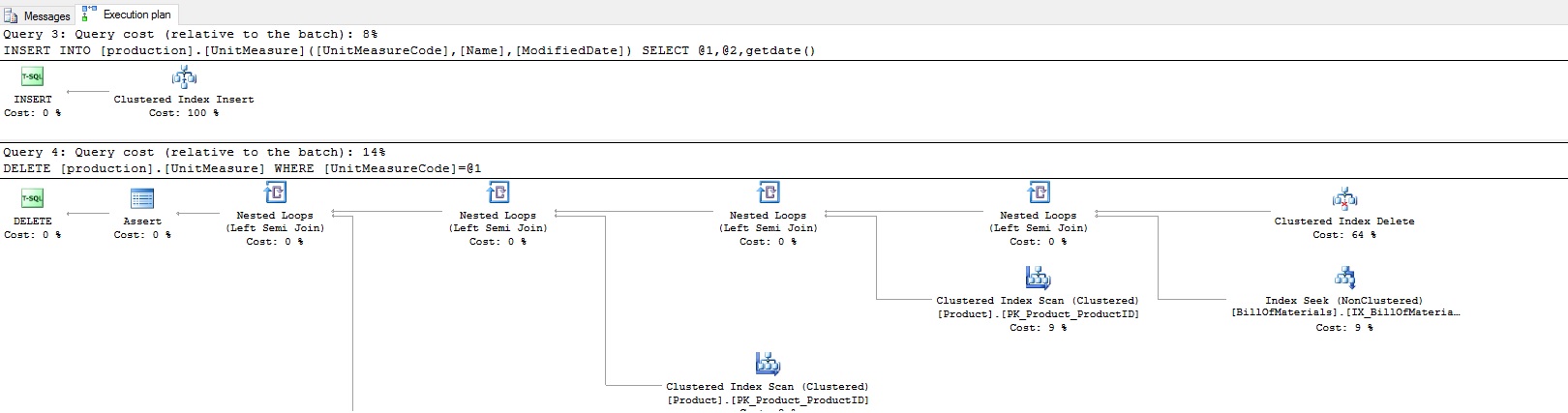
I didn’t bother to fit the entire plans into single images. It’s clear from the number of tables being queries above that we are not getting a clear foreign key operator, and are instead getting the same plans we’ve always gotten previously. What do we expect to see here? The following image is from an MSDN blog post:
我没有费心地将整个计划整合到单个图像中。 从上面查询的表的数量可以明显看出,我们没有一个明确的外键运算符,而是得到了我们以前一直得到的相同计划。 我们希望在这里看到什么? 下图来自MSDN博客文章:
This shows clearly that the long string of referential integrity check scans/seek are replaced with a single simplified operator that presumably outperforms the previous methodology. The following TSQL is what they used to test this new operator:
这清楚地表明,一长串的参照完整性检查扫描/查找已由单个简化的运算符代替,该运算符可能优于以前的方法。 以下TSQL是他们用来测试此新运算符的内容:
CREATE TABLE Customer(Id INT PRIMARY KEY, CustomerName NVARCHAR(128));
CREATE TABLE ReferenceToCustomer1(CustomerId INT FOREIGN KEY REFERENCES Customer(Id));
CREATE TABLE ReferenceToCustomer2(CustomerId INT FOREIGN KEY REFERENCES Customer(Id));
CREATE TABLE ReferenceToCustomer3(CustomerId INT FOREIGN KEY REFERENCES Customer(Id));
DELETE Customer WHERE Id = 1;
The resulting execution plan I receive is the same as the old plan shown above. Since it is unclear why I am unable to get the desired results, I’ve left a note on the article to get more info on why this isn’t working. If there is some feature or setting I am missing, or if this operator is not yet available for the current RTM release, then it’ll be good to have that information to work with.
我收到的最终执行计划与上面显示的旧计划相同。 由于目前尚不清楚为什么我无法获得预期的结果,因此我在文章上留下了注释,以获取有关为什么此方法无效的更多信息。 如果缺少某些功能或设置,或者当前RTM版本尚未提供此运算符,那么最好使用该信息。
If an update on the new operator is received, either via the MSDN post or some other channel, I’ll update this article with the details.
如果通过MSDN帖子或其他渠道收到了有关新运算符的更新,我将用详细信息更新本文。
The MSDN article referenced above can be found here
上面引用的MSDN文章可以在这里找到
I had some high hopes for this change, being that the current execution plans used to enforce referential integrity tend to be rather unintelligent. To be sure, though, I installed a separate SQL Server 2016 instance on another computer, and ran the same queries from above. Results were the same in that I was unable to make use of the new plan operator. It’s possible this feature will become available in a future revision of SQL Server 2016, so I’ll keep an eye out, and if this feature becomes usable, I’ll be sure to document and test the heck out of it 🙂
对于此更改,我寄予了很高的期望,因为用于强制执行参照完整性的当前执行计划往往相当不智能。 不过可以肯定的是,我在另一台计算机上安装了单独SQL Server 2016实例,并从上面运行了相同的查询。 结果相同,因为我无法使用新的计划运算符。 可能在SQL Server 2016的将来版本中将使用此功能,所以我会密切注意,如果此功能可用,我将确保对其进行记录和测试。
查询优化器修补程序/服务包更改 (Query Optimizer Hotfix/Service Pack Changes)
In previous versions of SQL Server, when a hotfix or cumulative update was released, any query optimizer improvements bestowed by that update would not immediately go into effect. Instead, it was necessary to turn on trace flag 4199, which would then enable any new optimizer features originating from any installed updates to SQL Server.
在早期版本SQL Server中,当发布修补程序或累积更新时,该更新赋予的任何查询优化器改进都不会立即生效。 相反,必须打开跟踪标志4199,这将启用任何新的优化程序功能,这些功能源自对SQL Server的所有已安装更新。
This off-by-default methodology worked, but was a bit obfuscated and not clear to administrators that this was the intended behavior that they should work with. Often, patches would be installed, the trace flag not turned on, and thus no optimizer changes were realized until a major upgrade occurred. This is typically acceptable as we shouldn’t change optimizer behavior unless a problem exists that needs resolution, or if we upgrading to a new major version.
这种默认情况下的方法有效,但是有点混乱,并且对于管理员来说还不清楚这是他们应该使用的预期行为。 通常,将安装补丁程序,未打开跟踪标志,因此直到发生重大升级之前,才实现优化程序更改。 这通常是可以接受的,因为除非存在需要解决的问题或升级到新的主要版本,否则我们不应该更改优化程序的行为。
Starting with SQL Server 2016, all query optimizer improvements will be linked directly to compatibility level. If a database is upgraded to compatibility level 130, then all previous optimizations will be implemented. A database that is not in compatibility mode 130 will not receive optimizer enhancements from SQL Server 2016. Trace flag 4199 will be reserved for turning on any optimizer changes introduced in subsequent patches while still running the current version of SQL Server. If you were to upgrade to some future version of SQL Server, perhaps SQL Server 2018, then switching to the hypothetical 140 compatibility level would retroactively enable all optimizer enhancements introduced via hotfixes and service packs to SQL Server 2016.
从SQL Server 2016开始,所有查询优化器的改进将直接链接到兼容性级别。 如果将数据库升级到兼容性级别130,则将实现所有以前的优化。 不在兼容模式130中的数据库将不会从SQL Server 2016获得优化器增强功能。将保留跟踪标志4199,以用于在运行当前版本SQL Server的同时打开后续修补程序中引入的任何优化器更改。 如果要升级到某个将来SQL Server版本(例如SQL Server 2018),则切换到假设的140兼容性级别将追溯启用通过修补程序和Service Pack引入SQL Server 2016的所有优化程序增强功能。
Specific trace flags used to be used prior to trace flag 4199 for enabling query optimizer enhancements via an individual hotfix. This functionality was intended for scenarios where a distinct bug is in need of patching, and the enhancement needed as part of the fix. A variety of trace flags from 4101 – 4135 (non-inclusive) handled these specific hotfixes, which were no longer utilized after trace flag 4199 was created.
以前在跟踪标志4199之前使用的特定跟踪标志用于通过单个修补程序启用查询优化器增强功能。 此功能用于需要修补的明显错误以及作为修补程序一部分需要的增强功能的方案。 这些特定的修补程序处理了从4101 – 4135(不包括在内)的各种跟踪标记,这些跟踪修补程序在创建跟踪标记4199之后不再使用。
结论 (Conclusion)
Each version of SQL Server comes with its share of query optimizer changes. Some are paired with new features, while others are intended to improve existing functionality. At least one of the new features, the foreign key referential integrity operator, isn’t available yet, but hopefully will make its appearance in a soon-to-be released revision.
每个版本SQL Server都具有其对查询优化器所做的更改。 一些与新功能配对,而另一些则旨在改善现有功能。 至少尚没有新功能之一,即外键引用完整性运算符,但希望它将在即将发布的修订版中出现。
The compatibility mode guarantee provides significantly more control over how new features affect the optimizer and ensures that upgrade processes can be better designed. The guaranteed knowledge of how features will behave provides a level of confidence that was not as easily available in previous versions of SQL Server.
兼容性模式保证提供了对新功能如何影响优化器的更多控制,并确保可以更好地设计升级过程。 有关功能行为方式的保证知识提供了一定的可信度,这在早期版本SQL Server中是不容易获得的。
Keep an eye out for more! It is not unheard of for Microsoft to release or document additional improvements in later service packs. These can be innocuous bug fixes or possibly cool new DMVs, optimizer enhancements, or feature additions!
留意更多! 对于Microsoft来说,在以后的Service Pack中发布或记录其他改进并不是闻所未闻的。 这些可能是无害的错误修复,也可能是很酷的新DMV,优化程序增强或功能添加!
翻译自: https://www.sqlshack.com/query-optimizer-changes-in-sql-server-2016-explained/















 1080
1080











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









