





介绍 (Introduction)
In a previous article, Functions vs stored procedures in SQL Server, we compared Functions vs stored procedures across various attributes. In this article, we will continue the discussion. We will talk also about Table-valued functions and compare performance with stored procedures with table valued functions and scalar functions.
在上一篇文章SQL Server中的功能与存储过程中 ,我们比较了各种属性中的功能与存储过程。 在本文中,我们将继续讨论。 我们还将讨论表值函数,并比较具有表值函数和标量函数的存储过程的性能。
We will include the following topics:
我们将包括以下主题:
- Manipulating stored procedure results and Table valued functions 处理存储过程结果和表值函数
- Comparing performance of stored procedures and Table valued functions with a where clause 使用where子句比较存储过程和表值函数的性能
- Are the scalar functions the devil’s sons? 标量功能是魔鬼的儿子吗?
入门 (Getting started)
1.处理存储过程结果和表值函数 (1. Manipulating stored procedure results and Table valued functions)
To store data retrieved from a stored procedure in a table when we invoke it, it is necessary to create the table first and then insert the data from the stored procedure to the table.
若要在调用表时将从存储过程中检索到的数据存储在表中,有必要先创建表,然后将数据从存储过程插入表中。
Let’s take a look to an example. First, we will create a stored procedure that returns a select statement:
让我们来看一个例子。 首先,我们将创建一个存储过程,该存储过程返回一个select语句:
create procedure tablexample
as
select
[AddressID],
[AddressLine1],
[AddressLine2],
City
from
[Person].[Address]
This is a procedure named tableexample and it returns select information of the table Person.Address included in the Adventureworks databases mentioned in the requirements.
这是一个名为tableexample的过程,它返回需求中提到的Adventureworks数据库中包含的表Person.Address的选择信息。
After creating the stored procedure, you need to create a table where you will store the data:
创建存储过程之后,您需要创建一个表,您将在其中存储数据:
CREATE TABLE [Person].[Address2](
[AddressID] [int] NOT NULL,
[AddressLine1] [nvarchar](60) NOT NULL,
[AddressLine2] [nvarchar](60) NULL,
[City] [nvarchar](30) NOT NULL
CONSTRAINT [PK_Address_AddressID2] PRIMARY KEY CLUSTERED
(
[AddressID] ASC
)
) ON [PRIMARY]
GO
Finally, you can do an insert into table and invoke the stored procedure:
最后,您可以在表中插入并调用存储过程:
insert into Person.Address2
exec tablexample
As you can see, it is possible to invoke a stored procedure and retrieve the data using insert into.
如您所见,可以调用存储过程并使用insert into检索数据。
If we try to do an insert into from a stored procedure to create automatically the table we will have the following result:
如果我们尝试从存储过程中进行插入以自动创建表,则会得到以下结果:
exec tablexample into
Person.Address3
When we try to insert into a table the result of the stored procedure invocation, we have the following message:
当我们尝试将存储过程调用的结果插入表中时,我们收到以下消息:
Msg 156, Level 15, State 1, Line 170
Incorrect syntax near the keyword ‘into’.
讯息156,第15级,州1,行170
关键字“ into”附近的语法不正确。
Let’s create a table valued function and compare it with the stored procedure:
让我们创建一个表值函数并将其与存储过程进行比较:
CREATE FUNCTION dbo.functiontable( )
RETURNS TABLE
AS
RETURN
(
select
[AddressID],
[AddressLine1],
[AddressLine2],
City
from
[Person].[Address]
)
This function named functiontable returns the information from a Person.Address table. To invoke a table valued function, we can do a select like this:
此名为functiontable的函数从Person.Address表返回信息。 要调用表值函数,我们可以执行如下选择:
select *
from dbo.functiontable()
The table valued function can be used like a view. You can filters the columns that you want to see:
表值函数可以像视图一样使用。 您可以过滤要查看的列:
select AddressID
from dbo.functiontable()
You can also add filters:
您还可以添加过滤器:
select AddressID from dbo.functiontable()
where AddressID=502
If you want to store the functions results, you do not need to create a table. You can use the select into clause to store the results in a new table:
如果要存储函数结果,则无需创建表。 您可以使用select into子句将结果存储在新表中:
select *
into mytable
from dbo.functiontable()
As you can see, you do not need to create a table as we did with the stored procedures. If you go to the Object Explorer in SSMS, you will be able to see that the table mytable was created successfully:
如您所见,您不需要像存储过程那样创建表。 如果转到SSMS中的“对象资源管理器”,将可以看到表mytable已成功创建:
2.使用where子句比较存储过程和表值函数的性能 (2. Comparing performance of stored procedures and Table valued functions with a where clause)
Some developers claim that stored procedures are faster than Table valued functions. Is that true?
一些开发人员声称存储过程比表值函数快。 真的吗?
We will create a table with a million rows for this test:
我们将为此测试创建一个包含一百万行的表:
with randowvalues
as(
select 1 id, CAST(RAND(CHECKSUM(NEWID()))*100 as int) randomnumber
union all
select id + 1, CAST(RAND(CHECKSUM(NEWID()))*100 as int) randomnumber
from randowvalues
where
id < 1000000
)
select *
into mylargetable
from randowvalues
OPTION(MAXRECURSION 0)
The code creates a table named mylargetable with a million rows with values from 1 to 100.
该代码创建一个名为mylargetable的表,该表包含一百万行,其值从1到100。
We will create a function that returns the values according to a filter specified by a parameter:
我们将创建一个函数,该函数根据参数指定的过滤器返回值:
CREATE FUNCTION dbo.functionlargetable(@rand int)
RETURNS TABLE
AS
RETURN
(
select randomnumber
from mylargetable
where randomnumber=@rand
)
This function named functionlargetable will show randomnumbers equal to the parameter specified.
名为functionlargetable的函数将显示等于指定参数的随机数。
Before running the query, enable the Actual Execution option in SSMS:
在运行查询之前,请在SSMS中启用“实际执行”选项:
The following query will show random numbers equal to 59:
以下查询将显示等于59的随机数:
select randomnumber from dbo.functionlargetable(59)
The Actual Execution plan will show how the query was executed (which indexes were used, cost of the sentences, etc.):
实际执行计划将显示查询的执行方式(使用了哪些索引,句子的成本等):
We will compare the execution plan of the function to a stored procedure:
我们将把函数的执行计划与存储过程进行比较:
CREATE PROCEDURE storedwithlargetable
@rand int
as
select randomnumber
from mylargetable
where randomnumber=@rand
The procedure is showing the random numbers equal to a parameter.
该过程将显示等于参数的随机数。
We will invoke the stored procedure:
我们将调用存储过程:
exec storedwithlargetable 61
If we check the actual plan, we will have the following:
如果我们检查实际计划,我们将获得以下内容:
As you can see, the execution plan is the same. However, it is always a good practice to check the execution time.
如您所见,执行计划是相同的。 但是,检查执行时间始终是一个好习惯。
To check more detailed information about execution time run these sentences:
要查看有关执行时间的更多详细信息,请运行以下语句:
SET STATISTICS io ON
SET STATISTICS time ON
GO
We run the functions and stored procedure cleaning the buffer using these sentences:
我们使用以下语句运行函数和存储过程以清理缓冲区:
DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS;
SET NOCOUNT ON
Here you have the table of results of the function invocation time:
这里有函数调用时间的结果表:
| CPU Parse time (ms) | Elapsed Parse time (ms) | Execution CPU time (ms) | Execution (ms) | Total (ms) |
| 16 | 90 | 313 | 1325 | 1744 |
| 16 | 43 | 390 | 1053 | 1502 |
| 0 | 47 | 328 | 1884 | 2259 |
| 0 | 133 | 344 | 1814 | 2291 |
| 0 | 273 | 391 | 1500 | 2164 |
| Average: 1992 |
| CPU解析时间(毫秒) | 解析时间(毫秒) | 执行CPU时间(毫秒) | 执行时间(毫秒) | 总计(毫秒) |
| 16 | 90 | 313 | 1325 | 1744 |
| 16 | 43 | 390 | 1053 | 1502 |
| 0 | 47 | 328 | 1884年 | 2259 |
| 0 | 133 | 344 | 1814年 | 2291 |
| 0 | 273 | 391 | 1500 | 2164 |
| 平均:1992 |
In addition, here you have the execution time of the stored procedure:
另外,这里您具有存储过程的执行时间:
| CPU Parse time (ms) | Elapsed Parse time (ms) | Execution CPU time (ms) | Execution (ms) | Total (ms) |
| 0 | 143 | 1300 | 1818 | 3261 |
| 1 | 0 | 250 | 1481 | 1731 |
| 0 | 0 | 328 | 1231 | 1559 |
| 0 | 0 | 328 | 1542 | 1870 |
| 16 | 276 | 313 | 1525 | 2130 |
| Average: 2110 |
| CPU解析时间(毫秒) | 解析时间(毫秒) | 执行CPU时间(毫秒) | 执行时间(毫秒) | 总计(毫秒) |
| 0 | 143 | 1300 | 1818年 | 3261 |
| 1个 | 0 | 250 | 1481 | 1731 |
| 0 | 0 | 328 | 1231 | 1559 |
| 0 | 0 | 328 | 1542 | 1870年 |
| 16 | 276 | 313 | 1525 | 2130 |
| 平均:2110 |
As you can see, the average time is 1992 ms for the function and 2110 ms for the stored procedures. The performance is almost the same. So, it is safe to use Table-valued UDFs in this case.
如您所见,该函数的平均时间为1992毫秒,存储过程的平均时间为2110毫秒。 性能几乎相同。 因此,在这种情况下使用表值UDF是安全的。
3.标量函数是否有害? (3. Are the scalar functions evil?)
Some say scalar functions are the spawn of the devil 😉 We’ll test to see if this bad reputation is warranted
有人说标量函数是魔鬼的产物😉我们将测试以查看这种不良声誉是否值得
We are going to use a stored procedure with a computed column. The computed column will convert USD to Mexican Pesos. The formula will be the following:
我们将使用存储过程和计算列。 计算列会将USD转换为墨西哥比索。 计算公式如下:
select randomnumber * 20.33 [mexican pesos]
1 USD dollar will be 20.33 pesos.
1 USD Dollar将是20.33比索。
The stored procedure will be the following:
存储过程将如下所示:
create procedure largetableproc
as
select randomnumber * 20.33 [mexican pesos]
from mylargetable
We are using the table mylargetable created in the section 2.
我们使用在第2节中创建的表mylargetable。
We can invoke the procedure to test results:
我们可以调用该过程来测试结果:
exec largetableproc
The execution plan will be the following:
执行计划如下:
Let’s compare the results with a function:
让我们将结果与一个函数进行比较:
CREATE FUNCTION priceinpesos(@dollar real)
RETURNS real
AS
BEGIN
RETURN @dollar*20.33
END
The function converts dollar to Mexican Pesos.
该函数将美元转换为墨西哥比索。
Let’s run a query using the scalar function just created:
让我们使用刚刚创建的标量函数运行查询:
select dbo.priceinpesos( randomnumber) as [Mexican Pesos]
from mylargetable
If we check the executing plan using the scalar function, we will notice the following:
如果我们使用标量函数检查执行计划,则会注意到以下几点:
As you can see, in many cases, the execution plan to run queries is the same in functions than in stored procedures. It is not always the case. However, how is the execution time?
如您所见,在许多情况下,运行查询的执行计划在功能上与在存储过程中相同。 并非总是如此。 但是,执行时间如何?
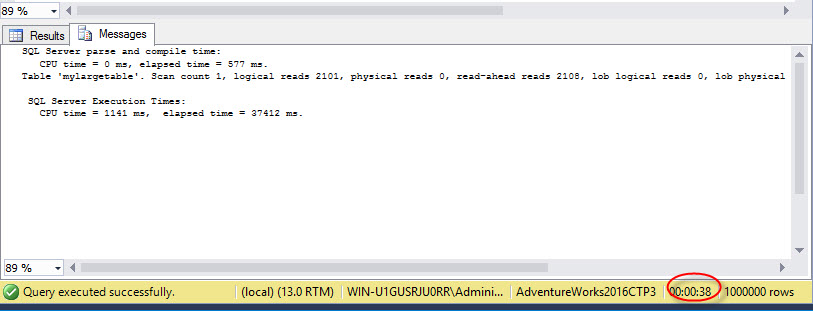
The execution time of a stored procedure is 38 seconds:
存储过程的执行时间为38秒:
Here you have a comparison table of procedures vs scalar functions:
这里有一个过程与标量函数的比较表:
| Stored procedure execution time (s) | Function execution time (s) |
| 43 | 50 |
| 38 | 59 |
| 27 | 61 |
| 36 | 59 |
| 35 | 58 |
| Average: 35.8 | Average: 57.4 |
| 存储过程执行时间(秒) | 功能执行时间(秒) |
| 43 | 50 |
| 38 | 59 |
| 27 | 61 |
| 36 | 59 |
| 35 | 58 |
| 平均:35.8 | 平均:57.4 |
As you can see, the scalar functions are slower than stored procedures. In average, the execution time of the scalar function was 57 seconds and the stored procedure 36 seconds.
如您所见,标量函数比存储过程慢。 平均而言,标量函数的执行时间为57秒,存储过程为36秒。
结论 (Conclusions)
We conclude that the table-valued functions are more flexible to filter results horizontally and vertically, to use a select into. Stored procedures are less flexible to reuse the results.
我们得出结论,表值函数更灵活地在水平和垂直方向上过滤结果,以使用select into。 存储过程不太灵活,无法重复使用结果。
In terms of performance, table-valued functions are a good choice. The performance is basically the same than stored procedures. However, it depends on the situation. Always check the execution time, Execution plan and test your functions and procedures with big amounts of data. Check our article to generate random values for testing.
就性能而言,表值函数是一个不错的选择。 性能基本上与存储过程相同。 但是,这取决于情况。 始终检查执行时间,执行计划,并使用大量数据测试您的功能和过程。 查看我们的文章以生成随机值进行测试。
Scalar functions can be used if you are sure that there are not many rows. When there are millions of rows or more, the execution time of scalar functions can be very slow.
如果您确定行数不多,则可以使用标量函数。 当有数百万行或更多的行时,标量函数的执行时间可能会很慢。
参考资料 (References)
For more information, refer to these links:
有关更多信息,请参考以下链接:
- T-SQL User-Defined Functions: the good, the bad, and the ugly (part 1) T-SQL用户定义的函数:好的,坏的和丑陋的(第1部分)
- Performance Considerations of User-Defined Functions in SQL Server 2012 SQL Server 2012中用户定义函数的性能注意事项
- How to generate random SQL Server test data using T-SQL 如何使用T-SQL生成随机SQL Server测试数据
翻译自: https://www.sqlshack.com/functions-stored-procedures-comparisons-sql-server/















 1951
1951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









