





 SQL Server使用比例填充算法管理数据库文件中的数据存储,根据每个数据文件的可用空间分配数据。存储引擎会根据文件的空闲空间量决定写入频率,这种方法称为比例填充算法。当文件满时,会按预设的自动增长值扩展数据库文件。跳过目标值用于确定文件在写入过程中的跳过次数,可通过启用Trace Flag 1165和3605进行监视。文章通过实例展示了如何跟踪跳过目标值和比例填充算法的工作原理。
SQL Server使用比例填充算法管理数据库文件中的数据存储,根据每个数据文件的可用空间分配数据。存储引擎会根据文件的空闲空间量决定写入频率,这种方法称为比例填充算法。当文件满时,会按预设的自动增长值扩展数据库文件。跳过目标值用于确定文件在写入过程中的跳过次数,可通过启用Trace Flag 1165和3605进行监视。文章通过实例展示了如何跟踪跳过目标值和比例填充算法的工作原理。
When creating a database, SQL Server maps this database with minimum two operating system files; the database data file MDF and the database log file LDF. Logically, the database data files are created under a collection set of files that simplifies the database administration, this logical file container is called the Filegroup. Database data files can come in two types, the Primary data files that contains metadata information for the database and pointers to the other database files in addition to the data, where each database should have only one Primary data file and the optional Secondary files to store data only. The basic storage unit in SQL Server is the Page, with each page size equal to 8KB. And each 8 pages with 64KB size called Extent.
创建数据库时,SQL Server会使用至少两个操作系统文件来映射该数据库。 数据库数据文件MDF和数据库日志文件LDF 。 从逻辑上讲,数据库数据文件是在一个文件集合下创建的,该集合简化了数据库管理,该逻辑文件容器称为Filegroup 。 数据库数据文件有两种类型,一种是主数据文件,它包含数据库的元数据信息,另一种是除数据外还指向其他数据库文件的指针,其中每个数据库应该只有一个主数据文件和可选的辅助文件来存储仅数据。 SQL Server中的基本存储单元是Page ,每个页面大小等于8KB。 每8页64KB的大小称为Extent 。
The SQL Server component that is responsible for managing the data storage within the database files, called the SQL Server Storage Engine. It uses a fill mechanism that writes data to the database files depending on the amount of free space in each data file rather than writing in each file untill it is full then moving to the second one sequentially. This data filling algorithm is called Proportional Fill Algorithm. In other words, the SQL Server Storage Engine will write more frequently to the files with more free space. For example, if the first data file has 10 MB free space and the second one has 20 MB, the storage engine will fill one extent to the first file and two extents to the second one. If auto-growth is enabled to the database files and the database files become full, the SQL Server Database Engine will expand the database files one at a time and write to that file, once the expanded file becomes full, SQL Server Database Engine will expand the second database file and so on.
负责管理数据库文件中数据存储SQL Server组件,称为SQL Server 存储引擎 。 它使用填充机制,该机制根据每个数据文件中的可用空间量将数据写入数据库文件,而不是写入每个文件直到其填满,然后按顺序移至第二个文件。 这种数据填充算法称为“ 比例填充算法” 。 换句话说,SQL Server存储引擎将更频繁地将文件写入具有更多可用空间的文件。 例如,如果第一个数据文件具有10 MB的可用空间,而第二个数据文件具有20 MB,则存储引擎将为第一个文件填充一个扩展区,为第二个文件填充两个扩展区。 如果对数据库文件启用了自动增长功能,并且数据库文件已满,则SQL Server数据库引擎将一次扩展一个数据库文件并写入该文件,一旦扩展文件变满,SQL Server数据库引擎将扩展第二个数据库文件,依此类推。
In the Proportional Fill Algorithm, each database data file will be assigned with a ranking integer number to specify how many times this file will be skipped from the writing process to the next file depending on the free space of that file, this number is called the Skip Target where the minimum value equal to 1 means that a write process will be performed on that file. The Skip Target can be measured by dividing the number of free extents in the file with the largest free space amount by the number of free extents in the current file, as integer value. The larger the free space in the database data file, the smaller Skip Target value. To have one file to write on each loop, there should be minimum one data file with Skip Target value equal to 1. Each time a new database data file is added or removed, or 8192 extents is filled in the database filegroup, the Skip Target value will be calculated again. In this way, all database data files will become full approximately at the same time. The Skip Target calculation can be monitored by enabling the Trace Flag 1165.
在“比例填充算法”中,将为每个数据库数据文件分配一个排名整数,以指定根据该文件的可用空间将该文件从写入过程跳过到下一个文件的次数。最小值等于1的“ 跳过目标 ”表示将对该文件执行写过程。 可以通过将具有最大可用空间量的文件中的可用扩展区数除以当前文件中的可用扩展区数(以整数值)来度量“跳过目标”。 数据库数据文件中的可用空间越大,“跳过目标”值越小。 要在每个循环上写入一个文件,至少应有一个数据文件,其“跳过目标”值等于1。每次添加或删除新的数据库数据文件,或在数据库文件组中填充8192盘区时,“跳过目标”值将再次计算。 这样,所有数据库数据文件将大约同时充满。 可以通过启用跟踪标志1165来监视“跳过目标”计算。
Let’s go through the practical part of this article to show how to track the Skip Target and how the Proportional Fill Algorithm works. First we will enable the Trace Flag 1165 to monitor the Skip Target which also required enabling the Trace Flag 3605 to allow showing the debugging info:
让我们遍历本文的实际部分,以显示如何跟踪“跳过目标”以及“比例填充算法”如何工作。 首先,我们将启用跟踪标记1165来监视“跳过目标”,这还需要启用跟踪标记3605以允许显示调试信息:
DBCC TRACEON (1165, 3605);
GO
The error logs will be cycled too to close the current error log file same as restarting the SQL Service:
错误日志也将被循环以关闭当前错误日志文件,就像重新启动SQL Service一样:
EXEC sp_cycle_errorlog;
GO
In the same session, a new database with four database data files will be created with PropFillDemo name and each file with 10 MB size:
在同一会话中,将创建一个具有四个数据库数据文件的新数据库,其名称为PropFillDemo,每个文件的大小为10 MB:
CREATE DATABASE [PropFillDemo]
ON PRIMARY
( NAME = N'PropFillDemo', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\PropFillDemo2.mdf',SIZE = 10MB , MAXSIZE = UNLIMITED, FILEGROWTH = 10MB ),
( NAME = N'PropFillDemo_1', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\PropFillDemo2_1.ndf',SIZE = 10MB , MAXSIZE = UNLIMITED, FILEGROWTH = 10MB ),
( NAME = N'PropFillDemo_2', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\PropFillDemo2_2.ndf' ,SIZE = 10MB , MAXSIZE = UNLIMITED, FILEGROWTH = 10MB ),
( NAME = N'PropFillDemo_3', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\PropFillDemo2_3.ndf' ,SIZE = 10MB , MAXSIZE = UNLIMITED, FILEGROWTH = 10MB )
LOG ON
( NAME = N'PropFillDemo_log', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\PropFillDemo_log.ldf',SIZE = 10MB , MAXSIZE = 2GB , FILEGROWTH = 10%)
As mentioned previously, adding new database files will trigger calculating the Skip Target value. We will read the error log to track the calculation process:
如前所述,添加新的数据库文件将触发计算“跳过目标”值。 我们将阅读错误日志以跟踪计算过程:
EXEC xp_readerrorlog;
GO
The error log shows that the Proportional Fill calculation is started for the newly created database and the Skip Target value is calculated for all database data files with value equal to 1 for all files as they have the same free space percentage. The m_cAllocs value that is mentioned in the error log is the Skip Target recalculation threshold, with random value when the database is created at the first time and 8192 when the database files created:
错误日志显示针对新创建的数据库开始了“比例填充”计算,并且针对所有文件的值都等于1的所有数据库数据文件计算了“跳过目标”值,因为它们具有相同的可用空间百分比。 错误日志中提到的m_cAllocs值是“跳过目标”重新计算阈值,在首次创建数据库时具有随机值,在创建数据库文件时具有8192:
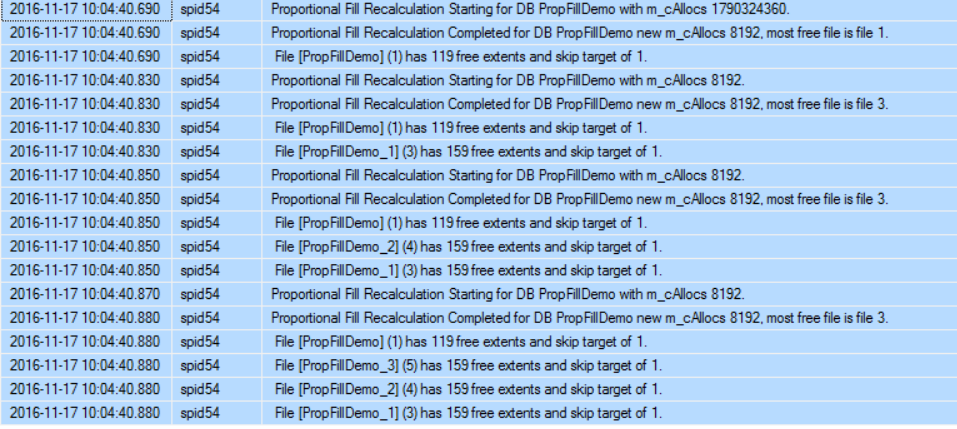
Now, we will list all database files with free space percentage by querying the sys.database_files using the T-SQL script below:
现在,我们将使用以下T-SQL脚本通过查询sys.database_files列出所有具有可用空间百分比的数据库文件:
USE PropFillDemo
GO
Select Name AS DBFileName, file_id AS DBFileID, physical_name PathAndPhysicalName,
(size * 8.0/1024) as FileSizeMB,
((size * 8.0/1024) - (FILEPROPERTY(name, 'SpaceUsed') * 8.0/1024)) As FileFreeSpaceMB,
cast((((size * 8.0/1024) - (FILEPROPERTY(name, 'SpaceUsed') * 8.0/1024))/(size * 8.0/1024))*100 as decimal(6,2)) as FreeSpacePercent
From sys.database_files
The result in our case will be like the below, taking into consideration that the primary database file with ID=1 contains metadata information about the database, so that it has the least free space when the database is created:
考虑到ID = 1的主数据库文件包含有关数据库的元数据信息,因此在我们的情况下,结果如下所示,因此在创建数据库时它具有最少的可用空间:

When the database is created, each database data file assigned 10 MB size, and while each extent has 64KB size, then the number of extents in each database file can be calculated by (10*1024)/64 which is equal to 160 extents per each database file, with 159 free extents as shown in the error log viewed previously. The ShowFileStats DBCC command can be also used to show the database extents information:
创建数据库时,每个数据库数据文件分配10 MB的大小,而每个扩展区具有64KB的大小,则每个数据库文件中的扩展区数可以通过(10 * 1024)/ 64计算,等于每个扩展区160个扩展区每个数据库文件都有159个可用扩展区,如先前查看的错误日志中所示。 ShowFileStats DBCC命令还可以用于显示数据库范围信息:
USE PropFillDemo
GO
DBCC showfilestats
Again the query output shows us that there are 41 extents used from the primary data file storing metadata. The result in our case will be like:
再次,查询输出向我们显示,从主数据文件存储元数据使用了41个扩展区。 在我们的案例中,结果将是:

Till the point, the database created successfully and the initial Skip target value is calculated for all database data files. We can start now monitoring the Proportional Fill Algorithm by creating the PropFillTest simple table:
至此,成功创建了数据库,并为所有数据库数据文件计算了初始“跳过”目标值。 我们现在可以通过创建PropFillTest简单表来开始监视比例填充算法:
CREATE TABLE [PropFillTest] (
[ID] INT IDENTITY (1,1),
[First_Name] NVARCHAR(50),
[Last_Name] NVARCHAR(50) );
And fill it with 1000 records. Note that the number beside the GO statement shows the number of times the query will be executed:
并填充1000条记录。 请注意,GO语句旁边的数字显示将执行查询的次数:
INSERT INTO [PropFillTest] VALUES('Ahmad','Yaseen'),('John','Mikel')
GO 500
Checking the database files free space percentage again using the previous query, you will find that the three secondary data files that have more free space than the primary data file are filled with data as they all have Skip Target value equal to 1. The data file with ID 3 that has the most free space amount from all the three secondary data files and Skip Target value equal to 1 as mentioned in the previous error log figure, is filled with the most amount of data:
使用上一个查询再次检查数据库文件的可用空间百分比,您将发现三个具有比主数据文件更多的可用空间的辅助数据文件都填充有数据,因为它们的“跳过目标”值都等于1。该数据文件ID 3的三个次要数据文件中的可用空间最大,并且上一个错误日志图中提到的Skip Target值等于1时,将填充最多的数据:

Inserting a bigger amount of data, this time 30000 records:
插入大量数据,这次有30000条记录:
INSERT INTO [PropFillTest] VALUES('Ahmad','Yaseen'),('John','Mikel')
GO 15000
And checking the free space percentage in each file, the data will be distributed in the data files depending on the free space of each data file as below:
然后检查每个文件中的可用空间百分比,数据将根据每个数据文件的可用空间分布在数据文件中,如下所示:

Then we will check the number of used extents per each data file:
然后,我们将检查每个数据文件使用的扩展区数:
DBCC showfilestats
The result will show us the real data distribution in the data files and how much extent is used in each data file:
结果将向我们显示数据文件中的实际数据分布以及每个数据文件中使用了多少范围:

The IND DBCC command can be also used to show data pages’ distribution within all database data files by proving the database and table names only:
通过仅证明数据库和表名,IND DBCC命令还可用于显示所有数据库数据文件中数据页的分布:
DBCC IND ('PropFillDemo', 'PropFillTest', -1);
The below three snapshots from the huge result set returned from the DBCC command show that the table’s data is distributed within all data files:
DBCC命令返回的巨大结果集中的以下三个快照显示,表的数据分布在所有数据文件中:
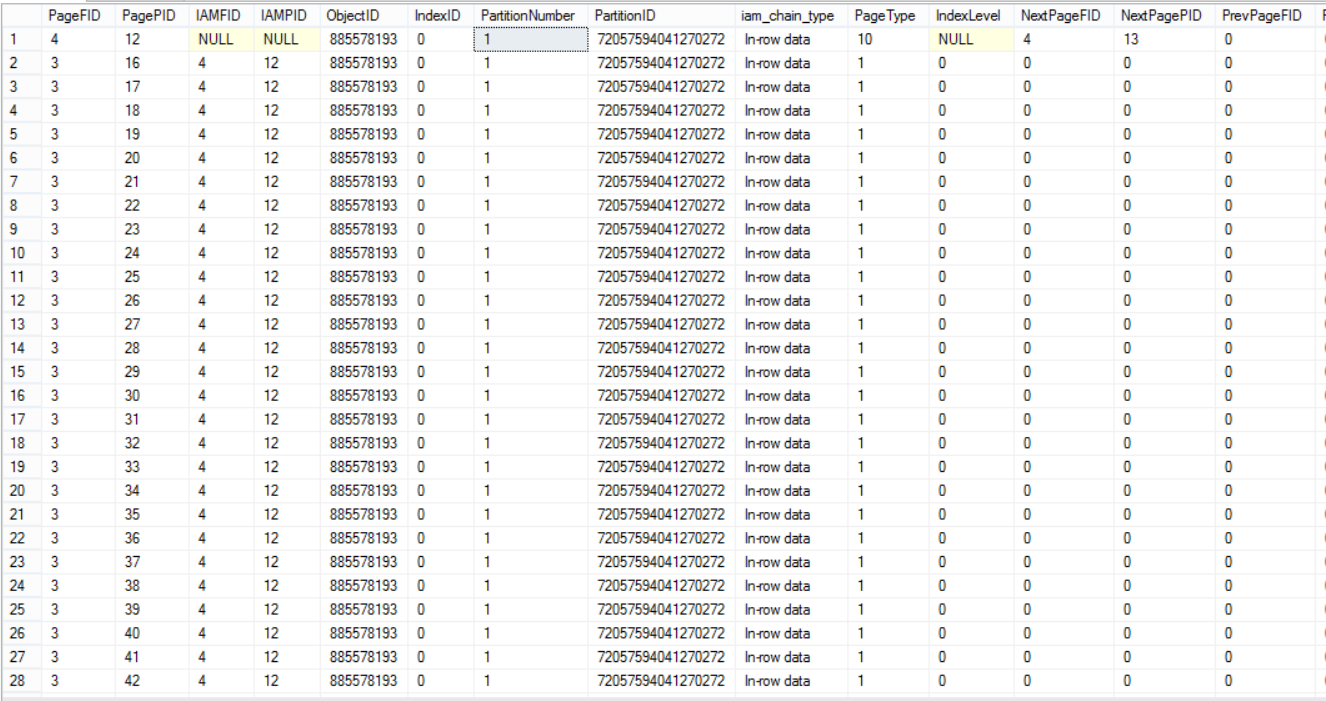
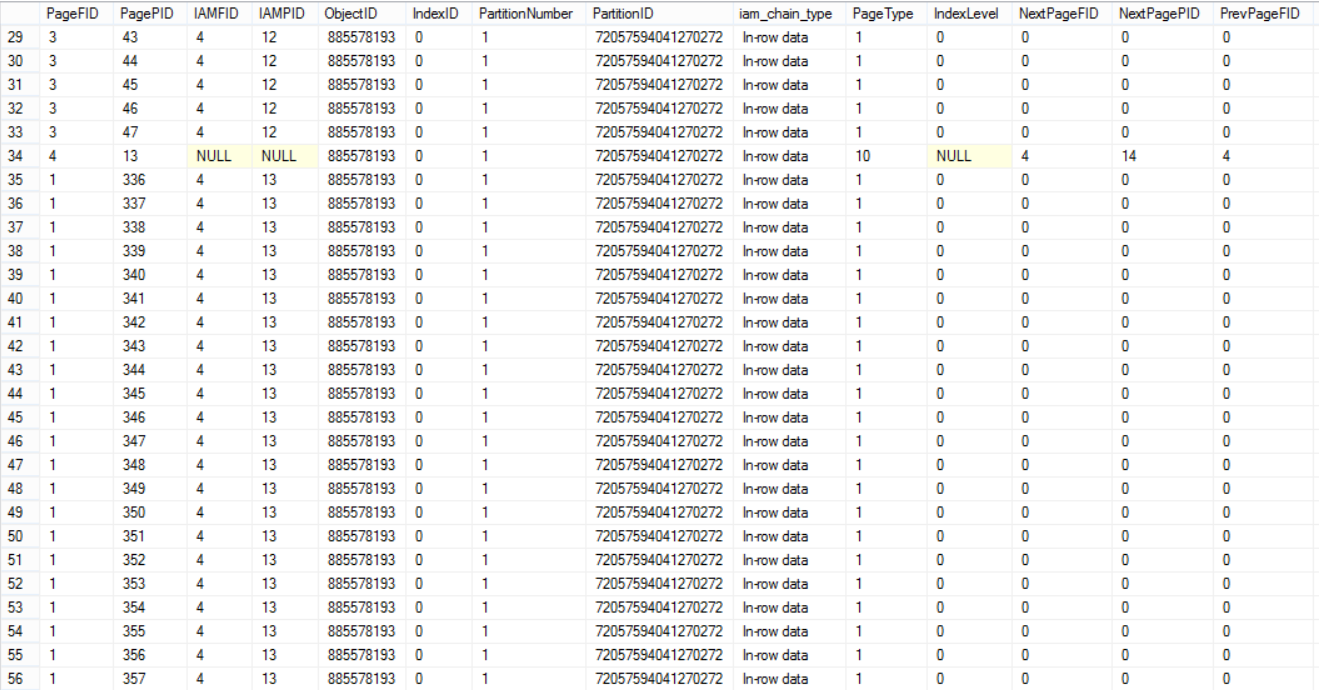
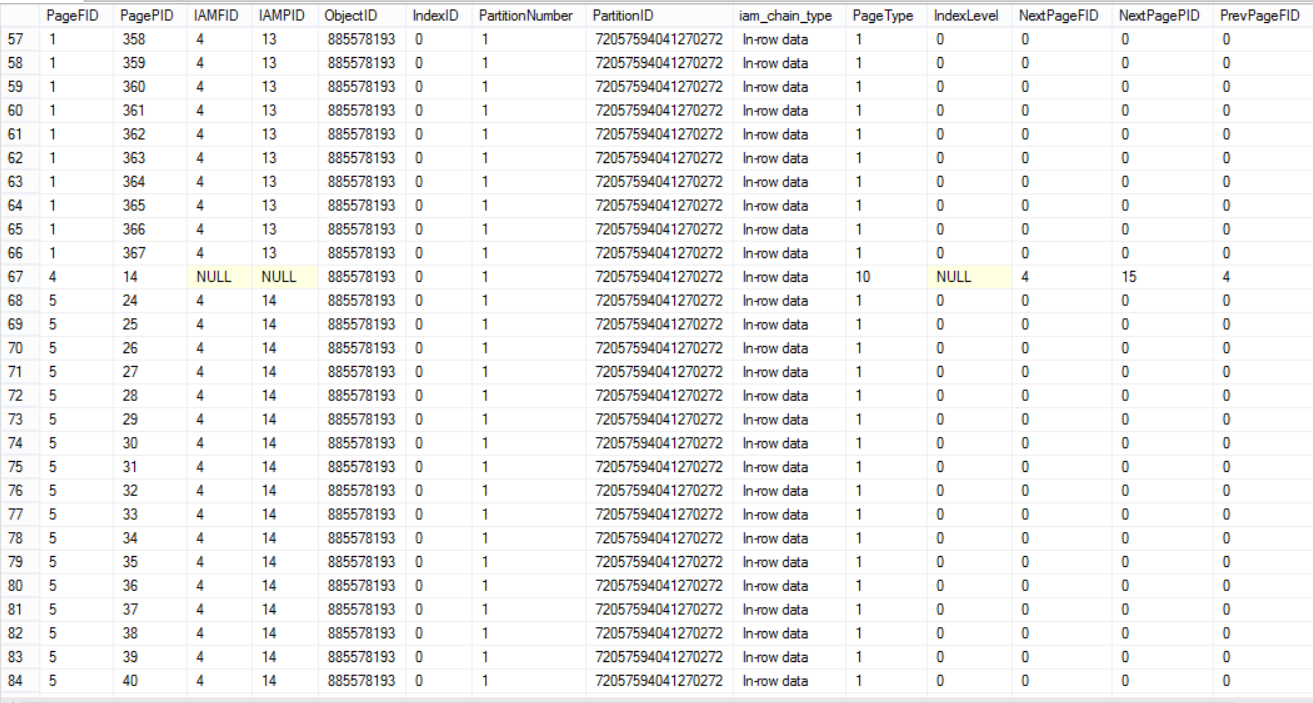
Let’s now try something else. We will insert a huge amount of data to the database data files:
现在让我们尝试其他事情。 我们将向数据库数据文件中插入大量数据:
INSERT INTO [PropFillTest] VALUES('Ahmad','Yaseen'),('John','Mikel')
GO 15000000
And check the data files free space percentage:
并检查数据文件的可用空间百分比:

It is clear from the previous result that once the data file become full, it is expanded again depending on the auto-growth amount value configured previously. Now we will add another database data file with size 15 MB:
从先前的结果可以明显看出,一旦数据文件已满,它将根据先前配置的自动增长量值再次进行扩展。 现在,我们将添加另一个大小为15 MB的数据库数据文件:
USE [master]
GO
ALTER DATABASE [PropFillDemo] ADD FILE ( NAME = N'PropFillDemo_4', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\PropFillDemo_4.ndf' , SIZE = 15360KB , FILEGROWTH = 10240KB ) TO FILEGROUP [PRIMARY]
GO
And check the error log again:
并再次检查错误日志:
EXEC xp_readerrorlog;
GO
Which shows us that the Skip Target will be calculated again for all database data files:
这表明我们将再次为所有数据库数据文件计算“跳过目标”:

Depending on the free space found in the below result, with the new file with the most free space:
根据以下结果中找到的可用空间,使用具有最大可用空间的新文件:

If we try again to insert extra data:
如果我们再次尝试插入其他数据:
INSERT INTO [PropFillTest] VALUES('Ahmad','Yaseen'),('John','Mikel')
GO 15000
The two data files; 5 and 6, with Skip Target 1 will be allocated with the data, where the other database data files; 1,3 and 4, with Skip Target 239 will be skipped 238 times without writing to it:
两个数据文件; 5和6,具有跳过目标1的将被分配的数据,其中其他数据库数据文件; 1,3和4,跳过目标239将被跳过238次而不写:

结论: (Conclusion:)
SQL Server uses the Proportional Fill Algorithm to allocate data in the database data files depending on the free space amount on each data file by calculating a measurable value called the Skip Target. It is clear from the previous demo when the Skip Target is recalculated and how the data is filled in each data file and how SQL Server will skip the files with the least free space due to high Skip Target value and write to the ones with smaller Skip Target Value. I hope that everything is clear and please leave a comment if you find anything not clear.
SQL Server使用比例填充算法通过计算称为“跳过目标”的可测量值,根据每个数据文件上的可用空间量在数据库数据文件中分配数据。 从上一个演示中可以清楚地看到,何时重新计算了“跳过目标”,以及如何在每个数据文件中填充数据,以及由于“跳过目标”值较高,SQL Server如何跳过具有最小可用空间的文件,并写入具有较小“跳过”的文件目标价值。 我希望一切都清楚,如果发现不清楚的地方,请发表评论。
有用的链接: (Useful links:)
- Using Files and Filegroups 使用文件和文件组
- sp_cycle_errorlog (Transact-SQL) sp_cycle_errorlog(Transact-SQL)
- More undocumented fun: DBCC IND, DBCC PAGE, and off-row columns 更多未记录的乐趣:DBCC IND,DBCC PAGE和行外列
翻译自: https://www.sqlshack.com/understanding-sql-server-proportional-fill-algorithm/















 1057
1057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









