





ssis导出数据性能
In the previously published article, we talked briefly about Hadoop, and we gave an overview of the SSIS Hadoop components added in the SQL Server 2016 release, and we focused on the Hadoop connection manager and the Hadoop file system task.
在先前发布的文章中,我们简要介绍了Hadoop,并概述了SQL Server 2016版本中添加的SSIS Hadoop组件,并且我们重点介绍了Hadoop连接管理器和Hadoop文件系统任务。
As illustrated, there are two SSIS Hadoop components at the package data flow level:
如图所示,在包数据流级别有两个SSIS Hadoop组件:
- HDFS Files Source HDFS文件源
- HDFS File Destination HDFS文件目标
In this article, we will briefly explain the Avro and ORC Big Data file formats. Then, we will be talking about Hadoop data flow task components and how to use them to import and export data into the Hadoop cluster. Then we will compare those Hadoop components with the Hadoop File System Task. Finally, we will conclude our work.
在本文中,我们将简要说明Avro和ORC大数据文件格式。 然后,我们将讨论Hadoop数据流任务组件以及如何使用它们将数据导入和导出到Hadoop集群中。 然后,我们将这些Hadoop组件与Hadoop File System Task进行比较。 最后,我们将结束我们的工作。
Note: To run an experiment, we will use the AdventureWorks2017 database, which can be downloaded from the following link.
注意 :要运行实验,我们将使用AdventureWorks2017数据库,可从以下 链接 下载该数据库 。
大数据文件格式 (Big data files formats)
There are many file formats developed for Big Data, but we will talk only about Avro and ORC since they are supported by HDFS source and destination components.
有许多针对大数据开发的文件格式,但由于HDFS源和目标组件支持Avro和ORC,因此我们仅讨论它们。
阿夫罗 (Avro)
Apache Avro is a row-oriented data serialization system developed within the Hadoop framework. It relies mainly on JSON to define data types, structure, and to serialize data. Also, it can be used to communicate between Hadoop nodes. You can read more about this technology from the official documentation.
Apache Avro是在Hadoop框架内开发的面向行的数据序列化系统。 它主要依靠JSON来定义数据类型 ,结构和序列化数据。 此外,它还可用于在Hadoop节点之间进行通信。 您可以从官方文档中了解有关此技术的更多信息。
优化行列(ORC) (Optimized Row columnar (ORC))
Apache ORC is a column-oriented data storage format developed for the Hadoop framework. It was announced in 2013 by HortonWorks in collaboration with Facebook. This format is mainly used with Apache Hive, and it has a better performance than row-oriented formats. You can read more about this technology from the official documentation.
Apache ORC是为Hadoop框架开发的面向列的数据存储格式。 它是由HortonWorks在2013年与Facebook合作宣布的。 该格式主要用于Apache Hive,并且比面向行的格式具有更好的性能。 您可以从官方文档中了解有关此技术的更多信息。
HDFS文件目标 (HDFS File Destination)
HDFS file destination is a component used to store tabular data within the Hadoop cluster. It supports text, Avro, and ORC files.
HDFS文件目标是用于在Hadoop集群中存储表格数据的组件。 它支持文本,Avro和ORC文件。
If we open the HDFS file destination editor, we can see that it contains two tab pages:
如果打开HDFS文件目标编辑器,则可以看到它包含两个选项卡页面:
- Connection Manager: Where we should specify the Hadoop connection and the destination file format: 连接管理器 :我们应该在其中指定Hadoop连接和目标文件格式:
- Hadoop Connection Manager: We should select the relevant Hadoop connection manager (Creating and configuring an SSIS Hadoop connection manager is illustrated in our previously published article in this series, SSIS Hadoop Connection Manager and related tasks)
- Hadoop连接管理器:我们应该选择相关的Hadoop连接管理器(本系列先前发布的文章SSIS Hadoop连接管理器和相关任务中说明了创建和配置SSIS Hadoop连接管理器 )
- Location (File Path): The file path within the Hadoop cluster (it must start with a slash “/”. As an example: “/Test/Persons.avro”).; you don’t need to create directories manually since they are automatically generated before data is inserted. 位置(文件路径): Hadoop集群中的文件路径(必须以斜杠“ /”开头。例如:“ / Test / Persons.avro”)。 您不需要手动创建目录,因为它们是在插入数据之前自动生成的。
- File Format: Text, Avro, or ORC 文件格式:文本,Avro或ORC
- Column delimiter character (Only available for the Text file format) 列定界符 (仅适用于文本文件格式)
- Columns names in the first data row (Only available for the Text file format) 第一个数据行中的列名 (仅适用于文本文件格式)
- Mappings: Where we should set the columns mappings 映射:应该在哪里设置列映射
其他特性 (Additional properties)
Besides these properties, there are some additional properties that are not shown in this component editor. You can find them in the properties tab (Select the HDFS File destination component and click F4).
除了这些属性,还有一些其他属性未在此组件编辑器中显示。 您可以在属性选项卡中找到它们(选择“ HDFS文件”目标组件,然后单击F4)。
These properties are:
这些属性是:
- IsBatchMode: Specify whether data is imported in batch mode IsBatchMode :指定是否以批处理模式导入数据
- BatchSize: Specify the batch size BatchSize :指定批次大小
- ValidateExternalMetadata: Select whether metadata is validated before data is inserted (This property is common between all SSIS source and destination) components ValidateExternalMetadata :选择是否在插入数据之前验证元数据(此属性在所有SSIS源和目标之间都是公共的)
表达方式 (Expressions)
There are some properties of the HDFS file destination that can be evaluated as an expression. These properties are:
HDFS文件目标的某些属性可以评估为表达式。 这些属性是:
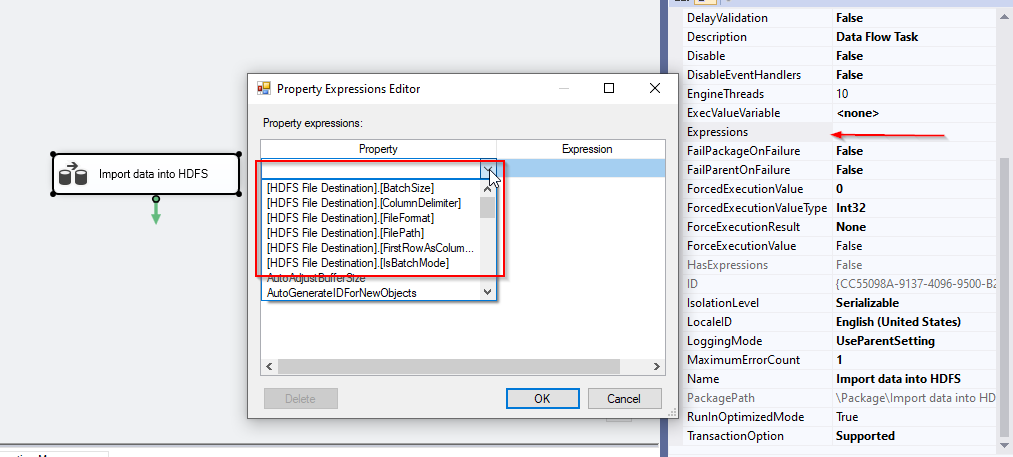
- BatchSize 批量大小
- ColumnDelimiter 列分隔符
- FileFormat 文件格式
- FilePath 文件路径
- FirstRowAsColumnHeader FirstRowAsColumnHeader
- IsBatchMode IsBatchMode
To set these properties, select the data flow task, in the properties tab, click on expression. Then, you will find a list of these properties within the Property Expressions editor form, as shown below:
要设置这些属性,请选择数据流任务,在“属性”选项卡中,单击“表达式”。 然后,您将在“属性表达式”编辑器表单中找到这些属性的列表,如下所示:
HDFS文件源 (HDFS File Source)
HDFS file source is a component used to read tabular data stored within the Hadoop cluster. It supports text and Avro files.
HDFS文件源是用于读取Hadoop集群中存储的表格数据的组件。 它支持文本和Avro文件。
If we open the HDFS file source editor, we can see that it contains three tab pages:
如果打开HDFS文件源编辑器,我们可以看到它包含三个选项卡页面:
- Connection Manager: Where we should specify the Hadoop connection and the destination file format: 连接管理器 :我们应该在其中指定Hadoop连接和目标文件格式:
- Hadoop Connection Manager: We should select the relevant Hadoop connection manager Hadoop连接管理器:我们应该选择相关的Hadoop连接管理器
- Location (File Path): The file path within the Hadoop cluster (it must start with a slash “/”) 位置(文件路径): Hadoop集群中的文件路径(必须以斜杠“ /”开头)
- File Format: Text or Avro 档案格式:文字或Avro
- Column delimiter character (Only available for the Text file format) 列定界符 (仅适用于文本文件格式)
- Columns names in the first data row (Only available for the Text file format) 第一个数据行中的列名 (仅适用于文本文件格式)
- Columns: Where we should select the input columns and add aliases 列 :我们应该在其中选择输入列并添加别名
- Error output: Where we can configure the error output (Like other source components) 错误输出:我们可以在其中配置错误输出的地方(就像其他源组件一样)
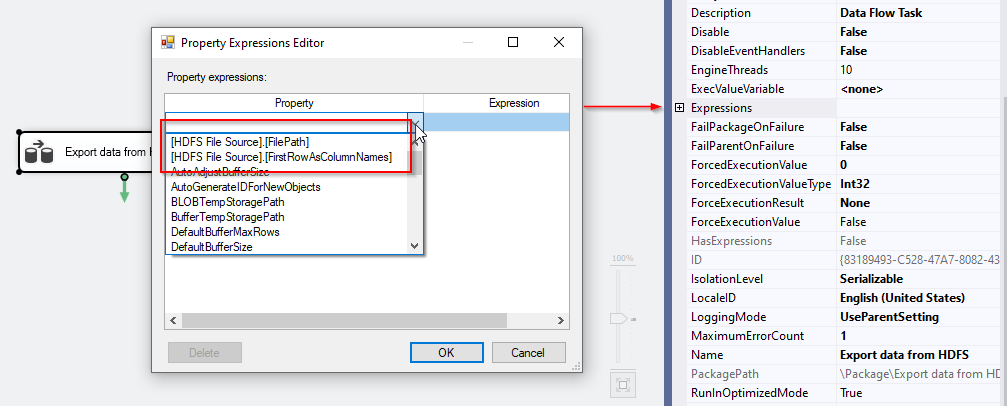
HDFS file source differs from the HDFS file destination component since it doesn’t have any custom properties that are not shown within the editor. Besides, only two properties can be evaluated as an expression, as shown in the screenshot below:
HDFS文件源与HDFS文件目标组件不同,因为它没有编辑器中未显示的任何自定义属性。 此外,只能将两个属性作为表达式求值,如下面的屏幕快照所示:
- FilePath 文件路径
- FirstRowAsColumnName FirstRowAsColumnName
例 (Example)
To test these components, we will create an SSIS package and add three connection managers:
为了测试这些组件,我们将创建一个SSIS包并添加三个连接管理器:
- Hadoop Connection Manager: to connect with the Hadoop cluster (check the previous article) Hadoop连接管理器:与Hadoop集群连接(请查看上一篇文章)
- OLE DB Connection Manager: to connect to SQL Server instance where AdventureWorks2017 database is stored OLE DB连接管理器:连接到存储AdventureWorks2017数据库SQL Server实例
- Flat File Connection Manager: We will use it to export data from HDFS Source: 平面文件连接管理器:我们将使用它从HDFS导出数据源:
We will add two data flow tasks:
我们将添加两个数据流任务:
- Import data into HDFS: it will read data from the [Person].[Person] table into the following file path: “/TestSSIS/Persons.txt”: 将数据导入HDFS:它将从[Person]。[Person]表中读取数据到以下文件路径:“ / TestSSIS / Persons.txt”:
- Export data from HDFS” it will read data from a file in HDFS within the following path: “/Test/Persons/txt” into a flat-file: 从HDFS导出数据”,它将在以下路径中从HDFS中的文件读取数据:“ / Test / Persons / txt”成平面文件:
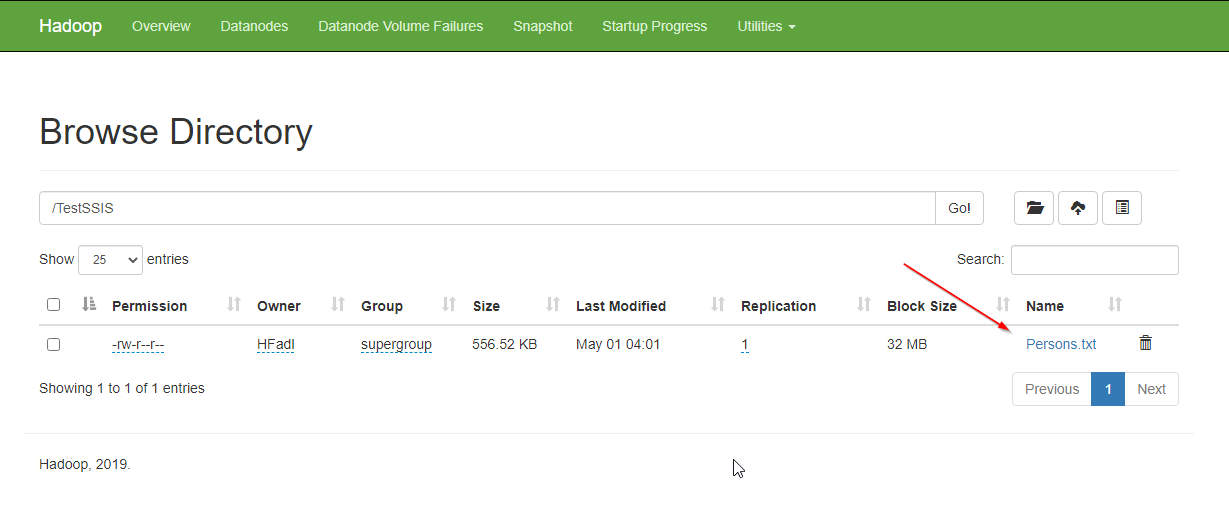
We run the SSIS package, and after execution is finished successfully, we can verify that the data is exported successfully from the Hadoop web interface.
我们运行SSIS包,并在成功完成执行之后,可以验证数据是否已成功从Hadoop Web界面导出。
Also, the text file is exported successfully into the local file system.
此外,文本文件已成功导出到本地文件系统中。
Hadoop文件系统任务与数据流组件 (Hadoop File System Task vs. Data Flow Components)
As we mentioned in the previously published article in this series, there are three SSIS Hadoop components at the package control flow level:
正如我们在本系列先前发布的文章中提到的那样,在程序包控制流级别有三个SSIS Hadoop组件:
- Hadoop File System Task Hadoop文件系统任务
- Hadoop Hive Task Hadoop Hive任务
- Hadoop Pig Task Hadoop Pig任务
Since the data flow Hadoop components are used to import or export data from HDFS, one main question could be asked, When to use these components, especially that importing and exporting data can be done using the Hadoop file system task?
由于数据流Hadoop组件用于从HDFS导入或导出数据,因此可能会提出一个主要问题:何时使用这些组件,尤其是可以使用Hadoop文件系统任务来完成数据的导入和导出?
There are many differences between both Hadoop components concerning the supported data sources and other features, as shown in the following table.
下表显示了Hadoop组件之间在支持的数据源和其他功能方面的许多差异。
Feature | Hadoop File System Task | SSIS Hadoop components |
Package level | Control Flow | Data Flow |
Data warehousing approach | ELT | ETL |
Data Sources | File Connection | All connection |
Supported connection manager | Hadoop connection manager | Hadoop connection manager |
Supported types | Files (any extension) + Directories | Text file, Avro, ORC |
Available transformations | No transformation can be applied | All data flow transformation can be applied to the data (Filter, Adding and removing columns, aggregations) |
Supported operations | Copy From HDFS, Copy to HDFS, Copy within HDFS | Copy From HDFS, Copy to HDFS, Copy within HDFS |
Performance | Higher performance since operations are high-level, and data is not validated | Lower than Hadoop tasks |
特征 | Hadoop文件系统任务 | SSIS Hadoop组件 |
包装等级 | 控制流 | 数据流 |
数据仓储方式 | 电报 | ETL |
数据源 | 档案连线 | 全部连接 |
支持的连接管理器 | Hadoop连接管理器 | Hadoop连接管理器 |
支持的类型 | 文件(任何扩展名)+目录 | 文本文件,Avro,ORC |
可用的转换 | 无法应用转换 | 所有数据流转换都可以应用于数据(过滤,添加和删除列,聚合) |
支持的运营 | 从HDFS复制,复制到HDFS,在HDFS中复制 | 从HDFS复制,复制到HDFS,在HDFS中复制 |
性能 | 更高的性能,因为操作是高级的,并且数据未经验证 | 低于Hadoop任务 |
结论 (Conclusion)
In this article, we illustrated the SSIS Hadoop components in the data flow level and how to use them to import and export data from Hadoop on-premise cluster. Then we made a small comparison between them and the Hadoop File System Task.
在本文中,我们在数据流级别说明了SSIS Hadoop组件以及如何使用它们从Hadoop本地群集中导入和导出数据。 然后,我们在它们和Hadoop File System Task之间进行了比较。
目录 (Table of contents)
| SSIS Hadoop Connection Manager and related tasks |
| Importing and Exporting data using SSIS Hadoop components |
| Connecting to Apache Hive and Apache Pig using SSIS Hadoop components |
| SSIS Hadoop连接管理器和相关任务 |
| 使用SSIS Hadoop组件导入和导出数据 |
| 使用SSIS Hadoop组件连接到Apache Hive和Apache Pig |
翻译自: https://www.sqlshack.com/importing-and-export-data-using-ssis-hadoop-components/
ssis导出数据性能














 5544
5544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









