





描述 (Description)
Fixing bad queries and resolving performance problems can involve hours (or days) of research and testing. Sometimes we can quickly cut that time by identifying common design patterns that are indicative of poorly performing TSQL.
解决错误的查询和解决性能问题可能需要数小时(或数天)的研究和测试。 有时,我们可以通过识别表明TSQL性能不佳的常见设计模式来快速缩短时间。
Developing pattern recognition for these easy-to-spot eyesores can allow us to immediately focus on what is most likely to the problem. Whereas performance tuning can often be composed of hours of collecting extended events, traces, execution plans, and statistics, being able to identify potential pitfalls quickly can short-circuit all of that work.
为这些易于眼部的眼Kong开发模式识别可以使我们立即专注于最容易出现问题的地方。 尽管性能调整通常由收集扩展事件,跟踪,执行计划和统计信息的时间组成,但能够快速识别潜在的缺陷可能会使所有工作短路。
While we should perform our due diligence and prove that any changes we make are optimal, knowing where to start can be a huge time saver!
尽管我们应该进行尽职调查并证明我们所做的任何更改都是最佳的,但知道从哪里开始可以节省大量时间!
For more information about Query optimization, see the SQL Query Optimization — How to Determine When and If It’s Needed article
有关查询优化的更多信息,请参见“ SQL查询优化-如何确定何时以及是否需要”一文。
技巧和窍门 (Tips and tricks)
OR in the Join Predicate/WHERE Clause Across Multiple Columns 跨多个列的联接谓词/ WHERE子句中的ORSQL Server can efficiently filter a data set using indexes via the WHERE clause or any combination of filters that are separated by an AND operator. By being exclusive, these operations take data and slice it into progressively smaller pieces, until only our result set remains.
SQL Server可以通过WHERE子句或使用AND运算符分隔的过滤器的任意组合,使用索引有效地过滤数据集。 通过互斥,这些操作会获取数据并将其切成越来越小的片段,直到只有我们的结果集为止。
OR is a different story. Because it is inclusive, SQL Server cannot process it in a single operation. Instead, each component of the OR must be evaluated independently. When this expensive operation is completed, the results can then be concatenated and returned normally.
或是另外一个故事。 由于包含性,SQL Server无法在单个操作中对其进行处理。 取而代之的是,必须单独评估OR的每个组成部分。 完成此昂贵的操作后,可以将结果连接起来并正常返回。
The scenario in which OR performs worst is when multiple columns or tables are involved. We not only need to evaluate each component of the OR clause, but need to follow that path through the other filters and tables within the query. Even if only a few tables or columns are involved, the performance can become mind-bogglingly bad.
OR表现最差的情况是涉及多个列或表。 我们不仅需要评估OR子句的每个组成部分,而且还需要沿着该路径遍历查询中的其他过滤器和表。 即使只涉及几个表或列,性能也可能令人难以置信。
Here is a very simple example of how an OR can cause performance to become far worse than you’d ever imagine it could be:
这是一个非常简单的示例,说明“或”如何导致性能变得比您想象的要差得多:
SELECT DISTINCT
PRODUCT.ProductID,
PRODUCT.Name
FROM Production.Product PRODUCT
INNER JOIN Sales.SalesOrderDetail DETAIL
ON PRODUCT.ProductID = DETAIL.ProductID
OR PRODUCT.rowguid = DETAIL.rowguid;
The query is simple enough: 2 tables and a join that checks both ProductID and rowguid. Even if none of these columns were indexed, our expectation would be a table scan on Product and a table scan on SalesOrderDetail. Expensive, but at least something we can comprehend. Here is the resulting performance of this query:
该查询非常简单:2个表和一个连接,同时检查ProductID和rowguid 。 即使没有对这些列进行索引,我们的期望还是对Product进行表扫描,对SalesOrderDetail进行表扫描。 昂贵,但至少我们可以理解。 这是此查询的结果性能:
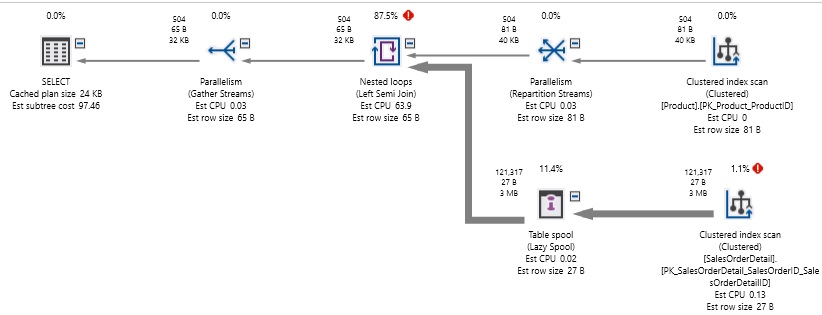

We did scan both tables, but processing the OR took an absurd amount of computing power. 1.2 million reads were made in this effort! Considering that Product contains only 504 rows and SalesOrderDetail contains 121317 rows, we read far more data than the full contents of each of these tables. In addition, the query took about 2 seconds to execute on a relatively speedy SSD-powered desktop.
我们确实扫描了两个表,但是处理“或”运算需要大量的计算能力。 这项工作进行了120万次读取! 考虑到产品仅包含504行,而SalesOrderDetail包含121317行,我们读取的数据远远超过每个表的全部内容。 此外,查询需要大约2秒钟才能在相对快速的SSD驱动的桌面上执行。
The take-away from this scary demo is that SQL Server cannot easily process an OR condition across multiple columns. The best way to deal with an OR is to eliminate it (if possible) or break it into smaller queries. Breaking a short and simple query into a longer, more drawn-out query may not seem elegant, but when dealing with OR problems, it is often the best choice:
这个可怕的演示的结果是,SQL Server无法轻松处理多个列之间的OR条件。 处理OR的最佳方法是消除OR(如果可能)或将其分解为较小的查询。 将简短而简单的查询分解为更长,更引人注意的查询似乎并不明智,但是在处理OR问题时,通常是最佳选择:
SELECT
PRODUCT.ProductID,
PRODUCT.Name
FROM Production.Product PRODUCT
INNER JOIN Sales.SalesOrderDetail DETAIL
ON PRODUCT.ProductID = DETAIL.ProductID
UNION
SELECT
PRODUCT.ProductID,
PRODUCT.Name
FROM Production.Product PRODUCT
INNER JOIN Sales.SalesOrderDetail DETAIL
ON PRODUCT.rowguid = DETAIL.rowguid
In this rewrite, we took each component of the OR and turned it into its own SELECT statement. UNION concatenates the result set and removes duplicates. Here is the resulting performance:
在此重写中,我们采用了OR的每个组件,并将其转换为自己的SELECT语句。 UNION连接结果集并删除重复项。 这是产生的性能:
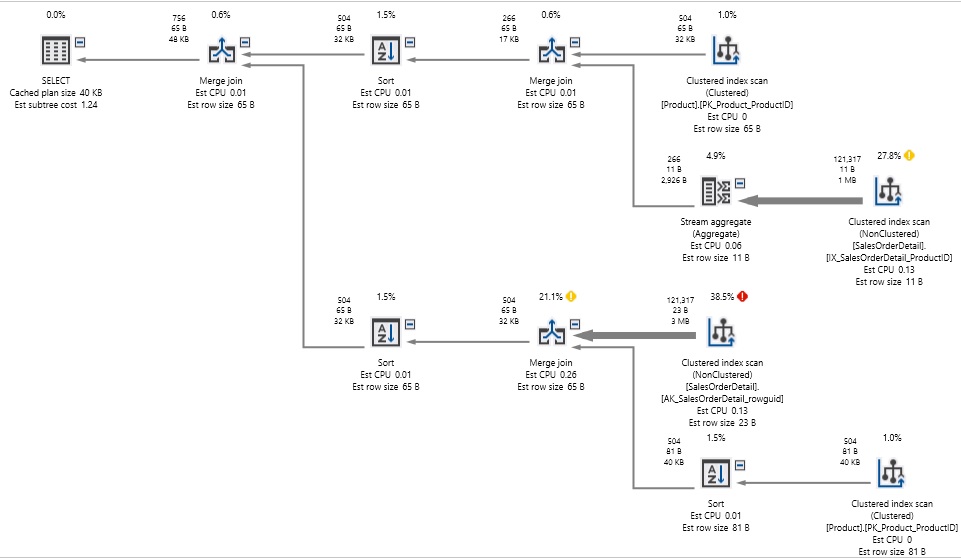
The execution plan got significantly more complex, as we are querying each table twice now, instead of once, but we no longer needed to play pin-the-tail-on-the-donkey with the result sets as we did before. The reads have been cut down from 1.2 million to 750, and the query executed in well under a second, rather than in 2 seconds.
执行计划变得更加复杂,因为我们现在查询每个表两次,而不是查询一次,但是我们不再需要像以前那样在结果集上打“钉上尾巴”。 读取次数已从120万减少到750,查询执行时间不到一秒钟,而不是2秒。
Note that there are still a boatload of index scans in the execution plan, but despite the need to scan tables four times to satisfy our query, performance is much better than before.
请注意,执行计划中仍然有大量索引扫描,但是尽管需要四次扫描表来满足我们的查询,但是性能比以前要好得多。
Use caution when writing queries with an OR clause. Test and verify that performance is adequate and that you are not accidentally introducing a performance bomb similar to what we observed above. If you are reviewing a poorly performing application and run across an OR across different columns or tables, then focus on that as a possible cause. This is an easy to identify query pattern that will often lead to poor performance.
使用OR子句编写查询时请小心。 测试并验证性能是否足够,并且您没有意外引入类似于上面观察到的性能炸弹。 如果您正在查看性能不佳的应用程序并在不同列或表的OR上运行,则应将其作为可能的原因。 这是一种易于识别的查询模式,通常会导致性能下降。
通配符字符串搜索 (Wildcard String Searches)
String searching efficiently can be challenging, and there are far more ways to grind through strings inefficiently than efficiently. For frequently searched string columns, we need to ensure that:
有效地搜索字符串可能会具有挑战性,而且效率低下的字符串搜索比有效的方法要多得多。 对于经常搜索的字符串列,我们需要确保:
- Indexes are present on searched columns. 索引出现在搜索列中。
- Those indexes can be used. 这些索引可以使用。
- If not, can we use full-text indexes? 如果没有,我们可以使用全文索引吗?
- If not, can we use hashes, n-grams, or some other solution? 如果没有,我们可以使用哈希,n-gram或其他解决方案吗?
Without use of additional features or design considerations, SQL Server is not good at fuzzy string searching. That is, if I want to detect the presence of a string in any position within a column, getting that data will be inefficient:
如果不使用其他功能或设计方面的考虑,SQL Server就不会进行模糊字符串搜索。 也就是说,如果我想检测一列中任何位置的字符串,则获取该数据将效率很低:
SELECT
Person.BusinessEntityID,
Person.FirstName,
Person.LastName,
Person.MiddleName
FROM Person.Person
WHERE Person.LastName LIKE '%For%';
In this string search, we are checking LastName for any occurrence of “For” in any position within the string. When a “%” is placed at the beginning of a string, we are making use of any ascending index impossible. Similarly, when a “%” is at the end of a string, using a descending index is also impossible. The above query will result in the following performance:
在此字符串搜索中,我们正在检查姓氏是否在字符串中的任何位置出现“ For”。 当在字符串的开头放置“%”时,我们将无法使用任何升序索引。 同样,当“%”位于字符串的末尾时,也无法使用降序索引。 上面的查询将导致以下性能:
As expected, the query results in a scan on Person.Person. The only way to know if a substring exists within a text column is to churn through every character in every row, searching for occurrences of that string. On a small table, this may be acceptable, but against any large data set, this will be slow and painful to wait for.
如预期的那样,该查询导致对Person.Person进行扫描。 知道子字符串是否存在于文本列中的唯一方法是翻动每一行中的每个字符,以查找该字符串的出现情况。 在一个小表上,这可能是可以接受的,但是对于任何大数据集,这将是缓慢而痛苦的等待。
There are a variety of ways to attack this situation, including:
有多种方法可以解决这种情况,包括:
- Re-evaluate the application. Do we really need to do a wildcard search in this manner? Do users really want to search all parts of this column for a given string? If not, get rid of this capability and the problem vanishes! 重新评估应用程序。 我们真的需要以这种方式进行通配符搜索吗? 用户是否真的要在此列的所有部分中搜索给定的字符串? 如果没有,请摆脱这种能力,问题就消失了!
- Can we apply any other filters to the query to reduce the data size prior to crunching the string comparison? If we can filter by date, time, status, or some other commonly used type of criteria, we can perhaps reduce the data we need to scan down to a small enough amount so that our query perform acceptably. 我们可以在查询字符串比较之前将其他任何过滤器应用于查询以减小数据大小吗? 如果我们可以按日期,时间,状态或其他一些常用的条件类型进行过滤,则可以将需要扫描的数据减少到足够小的数量,以便我们的查询可以令人满意地执行。
- Can we do a leading string search, instead of a wildcard search? Can “%For%” be changed to “For%”? 我们可以进行前导字符串搜索而不是通配符搜索吗? 可以将“%For%”更改为“ For%”吗?
- Is full-text indexing an available option? Can we implement and use it? 全文索引可用吗? 我们可以实现和使用它吗?
- Can we implement a query hash or n-gram solution? 我们可以实现查询哈希或n-gram解决方案吗?
The first 3 options above are as much design/architecture considerations as they are optimization solutions. They ask: What else can we assume, change, or understand about this query to tweak it to perform well? These all require some level of application knowledge or the ability to change the data returned by a query. These may not be options available to us, but it is important to get all parties involved on the same page with regard to string searching. If a table has a billion rows and users want to frequently search an NVARCHAR(MAX) column for occurrences of strings in any position, then a serious discussion needs to occur as to why anyone would want to do this, and what alternatives are available. If that functionality is truly important, then the business will need to commit additional resources to support expensive string searching, or accept a whole lot of latency and resource consumption in the process.
上面的前3个选项作为优化解决方案,既是设计/体系结构方面的考虑因素。 他们问:我们还可以假设,更改或了解该查询以使其性能良好吗? 这些都需要一定程度的应用知识,或者具有更改查询返回的数据的能力。 这些可能不是我们可以使用的选项,但对于字符串搜索,让所有参与方都在同一页面上很重要。 如果一个表有十亿行,并且用户希望经常在NVARCHAR(MAX)列中搜索在任何位置出现的字符串,那么就需要认真讨论为什么有人要这样做以及有哪些可用的替代方法。 如果该功能确实很重要,那么企业将需要投入额外的资源来支持昂贵的字符串搜索,或者在此过程中接受大量的延迟和资源消耗。
Full-Text Indexing is a feature in SQL Server that can generate indexes that allow for flexible string searching on text columns. This includes wildcard searches, but also linguistic searching that uses the rules of a given language to make smart decisions about whether a word or phrase are similar enough to a column’s contents to be considered a match. While flexible, Full-Text is an additional feature that needs to be installed, configured, and maintained. For some applications that are very string-centric, it can be the perfect solution! A link has been provided at the end of this article with more details on this feature, what it can do, and how to install and configure it.
全文索引是SQL Server中的一项功能,可以生成索引,以允许在文本列上进行灵活的字符串搜索。 这不仅包括通配符搜索,还包括使用给定语言的规则进行语言搜索的明智搜索,该决策会根据单词或短语是否与列内容足够相似来视为匹配项做出明智的决策。 全文本虽然灵活,但是是需要安装,配置和维护的附加功能。 对于某些非常以字符串为中心的应用程序,这可能是完美的解决方案! 本文结尾处提供了一个链接,其中包含有关此功能,它可以做什么以及如何安装和配置它的更多详细信息。
One final option available to us can be a great solution for shorter string columns. N-Grams are string segments that can be stored separately from the data we are searching and can provide the ability to search for substrings without the need to scan a large table. Before discussing this topic, it is important to fully understand the search rules that are used by an application. For example:
对于较短的字符串列,我们可以使用的最后一个选择是一个很好的解决方案。 N-Grams是字符串段,可以与我们正在搜索的数据分开存储,并且可以提供搜索子字符串的功能,而无需扫描大型表。 在讨论此主题之前,重要的是要充分了解应用程序使用的搜索规则。 例如:
- Are there a minimum or maximum number of characters allowed in a search? 搜索中是否有最小或最大字符数?
- Are empty searches (a table scan) allowed? 是否允许空搜索(表扫描)?
- Are multiple words/phrases allowed? 是否允许多个单词/短语?
- Do we need to store substrings at the start of a string? These can be collected with an index seek if needed. 我们是否需要在字符串的开头存储子字符串? 如果需要,可以使用索引搜索来收集这些信息。
Once these considerations are assessed, we can take a string column and break it into string segments. For example, consider a search system where there is a minimum search length of 3 characters, and the stored word “Dinosaur”. Here are the substrings of Dinosaur that are 3 characters in length or longer (ignoring the start of the string, which can be gathered separately & quickly with an index seek against this column):
ino, inos, inosa, inosau, inosaur, nos, nosa, nosau, nosaur, osa, osau, osaur, sau, saur, aur.
评估完这些考虑因素后,我们可以将一个字符串列分成多个字符串段。 例如,考虑一个搜索系统,其中最小搜索长度为3个字符,并且存储了单词“ Dinosaur”。 以下是Dinosaur的子字符串,其长度为3个字符或更长(忽略字符串的开头,可以通过针对此列的索引查找来单独且快速地收集该字符串的开头):
ino,inos,inosa,inosau,inosaur,nos,nosa,nosau,nosaur,osa,osau,osaur,sau,saur,aur。
If we were to create a separate table that stored each of these substrings (also known as n-grams), we can link those n-grams to the row in our big table that has the word dinosaur. Instead of scanning a big table for results, we can instead do an equality search against the n-gram table. For example, if I did a wildcard search for “dino”, my search can be redirected to a search that would look like this:
如果我们要创建一个单独的表来存储每个子字符串(也称为n-gram),则可以将这些n-gram链接到我们的大表中包含恐龙一词的行。 代替扫描大表寻找结果,我们可以对n-gram表进行相等搜索。 例如,如果我对“ dino”进行了通配符搜索,则可以将我的搜索重定向到如下所示的搜索:
SELECT
n_gram_table.my_big_table_id_column
FROM dbo.n_gram_table
WHERE n_gram_table.n_gram_data = 'Dino';
Assuming n_gram_data is indexed, then we will quickly return all IDs for our large table that have the word Dino anywhere in it. The n-gram table only requires 2 columns, and we can bound the size of the n-gram string using our application rules defined above. Even if this table gets large, it would likely still provide very fast search capabilities.
假设已为n_gram_data编制了索引,那么我们将快速返回大表中所有带有单词Dino的ID。 n-gram表仅需要2列,我们可以使用上面定义的应用程序规则来绑定n-gram字符串的大小。 即使该表很大,它仍可能会提供非常快速的搜索功能。
The cost of this approach is maintenance. We need to update the n-gram table every time a row is inserted, deleted, or the string data in it is updated. Also, the number of n-grams per row will increase rapidly as the size of the column increases. As a result, this is an excellent approach for shorter strings, such as names, zip codes, or phone numbers. It is a very expensive solution for longer strings, such as email text, descriptions, and other free-form or MAX length columns.
这种方法的成本是维护费用。 每次插入,删除一行或更新其中的字符串数据时,我们都需要更新n-gram表。 同样,每行n克数将随着列大小的增加而Swift增加。 因此,这对于处理较短的字符串(例如名称,邮政编码或电话号码)是一种极好的方法。 对于较长的字符串(例如电子邮件文本,描述以及其他自由格式或MAX长度列),这是一个非常昂贵的解决方案。
To quickly recap: Wildcard string searching is inherently expensive. Our best weapons against it are based on design and architecture rules that allow us to either eliminate the leading “%”, or limit how we search in ways that allow for other filters or solutions to be implemented. A link has been provided at the end of this article with more information on, and some demos of generating and using n-gram data. While a more involved implementation, it is another weapon in our arsenal when other options have failed us.
快速回顾:通配符字符串搜索本质上是昂贵的。 我们针对它的最佳武器是基于设计和体系结构规则,这些规则使我们可以消除领先的“%”,或者限制我们以允许其他过滤器或解决方案得以实施的方式进行搜索。 本文末尾提供了一个链接,其中提供了有关生成和使用n-gram数据的更多信息以及一些演示。 虽然实施起来更加复杂,但是当其他选择使我们失败时,这是我们武器库中的另一把武器。
大写操作 (Large Write Operations)
After a discussion of why iteration can cause poor performance, we are now going to explore a scenario in which iteration IMPROVES performance. A component of optimization not yet discussed here is contention. When we perform any operation against data, locks are taken against some amount of data to ensure that the results are consistent and do not interfere with other queries that are being executed against the same data by others besides us.
在讨论了为什么迭代会导致较差的性能后,我们现在将探讨一种迭代会提高性能的场景。 此处尚未讨论的优化组件是竞争。 当我们对数据执行任何操作时,将对一定数量的数据进行锁定,以确保结果一致,并且不会干扰除我们之外其他人针对相同数据执行的其他查询。
Locking and blocking are good things in that they safeguard data from corruption and protect us from bad result sets. When contention continues for a long time, though, important queries may be forced to wait, resulting in unhappy users and the resulting latency complaints.
锁定和阻止是一件好事,因为它们可以保护数据免遭损坏,并保护我们免受不良结果的影响。 但是,当争用持续很长时间时,可能会迫使重要的查询等待,从而导致用户不满意并导致延迟投诉。
Large write operations are the poster-child for contention as they will often lock an entire table during the time it takes to update the data, check constraints, update indexes, and process triggers (if any exist). How large is large? There is no strict rule here. On a table with no triggers or foreign keys, large could be 50,000, 100,000, or 1,000,000 rows. On a table with many constraints and triggers, large might be 2,000. The only way to confirm that this is a problem is to test it, observe it, and respond accordingly.
大型写操作是争用者的后代,因为它们通常会在更新数据,检查约束,更新索引和处理触发器(如果有)的过程中锁定整个表。 多大? 这里没有严格的规定。 在没有触发器或外键的表上,大行可能是50,000、100,000或1,000,000行。 在具有许多约束和触发器的表上,大可能为2,000。 确认这是问题的唯一方法是对其进行测试,观察并做出相应响应。
In addition to contention, large write operations will generate lots of log file growth. Whenever writing unusually big volumes of data, keep an eye on the transaction log and verify that you do not risk filling it up, or worse, filling up its physical storage location.
除了争用之外,大型写操作还将导致大量日志文件增长。 每当写入异常大量的数据时,请密切注意事务日志并确认您不会冒充它的风险,或更糟的是充满它的物理存储位置。
Note that many large write operations will result from our own work: Software releases, data warehouse load processes, ETL processes, and other similar operations may need to write a very large amount of data, even if it is done infrequently. It is up to us to identify the level of contention allowed in our tables prior to running these processes. If we are loading a large table during a maintenance window when no one else is using it, then we are free to deploy using whatever strategy we wish. If we are instead writing large amounts of data to a busy production site, then reducing the rows modified per operation would be a good safeguard against contention.
请注意,许多大量的写操作将由我们自己的工作产生:软件发行版,数据仓库加载过程,ETL过程和其他类似操作可能需要写非常大量的数据,即使它不经常执行也是如此。 在运行这些过程之前,我们需要确定表中允许的争用级别。 如果在维护窗口期间没有人使用它时正在加载一个大表,那么我们可以随意使用所需的任何策略进行部署。 如果我们改为将大量数据写入繁忙的生产站点,则减少每次操作所修改的行将是防止争用的良好保障。
Common operations that can result in large writes are:
可能导致大量写入的常见操作是:
- Adding a new column to a table and backfilling it across the entire table. 在表中添加新列,然后在整个表中回填它。
- Updating a column across an entire table. 更新整个表中的列。
- Changing the data type of a column. See link at the end of the article for more info on this. 更改列的数据类型。 有关更多信息,请参见文章末尾的链接。
- Importing a large volume of new data. 导入大量新数据。
- Archiving or deleting a large volume of old data. 归档或删除大量旧数据。
This may not often be a performance concern, but understanding the effects of very large write operations can avoid important maintenance events or releases from going off-the-rails unexpectedly.
这可能通常不涉及性能,但是了解非常大的写操作的效果可以避免重要的维护事件或发布意外脱离预期。
缺少索引 (Missing Indexes)
SQL Server, via the Management Studio GUI, execution plan XML, or missing index DMVs, will let us know when there are missing indexes that could potentially help a query perform better:
通过Management Studio GUI,执行计划XML或缺少索引DMV,SQL Server将在缺少索引可能会帮助查询更好地执行操作时通知我们:

This warning is useful in that it lets us know that there is a potentially easy fix to improve query performance. It is also misleading in that an additional index may not be the best way to resolve a latency issue. The green text provides us with all of the details of a new index, but we need to do a bit of work before considering taking SQL Server’s advice:
此警告很有用,因为它使我们知道存在一个可能很容易解决的问题,可以提高查询性能。 这也具有误导性,因为附加索引可能不是解决延迟问题的最佳方法。 绿色文本为我们提供了新索引的所有详细信息,但是在考虑采用SQL Server的建议之前,我们需要做一些工作:
- Are there any existing indexes that are similar to this one that could be modified to cover this use case? 是否有任何与该索引相似的现有索引可以修改以涵盖此用例?
- Do we need all of the include columns? Would an index on only the sorting columns be good enough? 我们是否需要所有包含列? 仅排序列上的索引是否足够好?
- How high is the impact of the index? Will it improve a query by 98%, or only 5%. 指数的影响有多高? 它将查询提高98%或仅5%。
- Does this index already exist, but for some reason the query optimizer is not choosing it? 该索引是否已经存在,但是由于某种原因查询优化器没有选择它?
Often, the suggested indexes are excessive. For example, here is the index creation statement for the partial plan shown above:
通常,建议的索引过多。 例如,这是上面显示的部分计划的索引创建语句:
CREATE NONCLUSTERED INDEX <Name of Missing Index, sysname,>
ON Sales.SalesOrderHeader (Status,SalesPersonID)
INCLUDE (SalesOrderID,SubTotal)
In this case, there is already an index on SalesPersonID. Status happens to be a column in which the table mostly contains one value, which means that as a sorting column it would not provide very much value. The impact of 19% isn’t terribly impressive. We would ultimately be left to ask whether the query is important enough to warrant this improvement. If it is executed a million times a day, then perhaps all of this work for a 20% improvement is worth it.
在这种情况下, SalesPersonID上已经有一个索引。 Status恰好是一列,其中表中大部分包含一个值,这意味着作为排序列它不会提供太多值。 19%的影响并不令人印象深刻。 我们最终将被问到查询是否足够重要以保证这一改进。 如果每天执行一百万次,那么将所有这些工作提高20%的成本是值得的。
Consider another alternative index recommendation:
考虑另一种替代索引建议:
Here, the missing index suggested is:
在这里,建议缺少的索引是:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>]
ON [Person].[Person] ([FirstName])
INCLUDE ([BusinessEntityID],[Title])
This time, the suggested index would provide a 93% improvement and handle an unindexed column (FirstName). If this is at all a frequently run query, then adding this index would likely be a smart move. Do we add BusinessEntityID and Title as INCLUDE columns? This is far more of a subjective question and we need to decide if the query is important enough to want to ensure there is never a key lookup to pull those additional columns back from the clustered index. This question is an echo of, “How do we know when a query’s performance is optimal?”. If the non-covering index is good enough, then stopping there would be the correct decision as it would save the computing resources required to store the extra columns. If performance is still not good enough, then adding the INCLUDE columns would be the logical next step.
这次,建议的索引将提供93%的改进,并处理未索引的列( FirstName )。 如果这是一个经常运行的查询,那么添加此索引可能是明智之举。 我们是否将BusinessEntityID和Title添加为INCLUDE列? 这远不是一个主观的问题,我们需要确定查询是否足够重要,以确保永远不会进行键查找来将这些其他列从聚簇索引中拉回。 这个问题是对“我们如何知道查询的性能何时最佳”的回应。 如果非覆盖索引足够好,那么停止将有一个正确的决定,因为这将节省存储额外列所需的计算资源。 如果性能仍然不够好,那么逻辑上下一步就是添加INCLUDE列。
As long as we remember that indexes require maintenance and slow down write operations, we can approach indexing from a pragmatic perspective and ensure that we do not make any of these mistakes:
只要我们记得索引需要维护并减慢写操作的速度,我们就可以从务实的角度处理索引并确保我们不会犯以下任何错误:
Over-Indexing a Table 过度索引表When a table has too many indexes, write operations become slower as every UPDATE, DELETE, and INSERT that touches an indexed column must update the indexes on it. In addition, those indexes take up space on storage as well as in database backups. “Too Many” is vague, but emphasizes that ultimately application performance is the key to determining whether things are optimal or not.
当表中的索引过多时,写操作会变慢,因为每一个接触索引列的UPDATE,DELETE和INSERT都必须更新其上的索引。 此外,这些索引会占用存储空间以及数据库备份空间。 “太多”是模糊的,但强调最终的应用程序性能是确定事物是否最佳的关键。
Under-Indexing a Table 索引不足的表An under-indexed table does not serve read queries effectively. Ideally, the most common queries executed against a table should benefit from indexes. Less frequent queries are evaluated on a case-by-case need and indexed when beneficial. When troubleshooting a performance problem against tables that have few or no non-clustered indexes, then the issue is likely an under-indexing one. In these cases, feel empowered to add indexes to improve performance as needed!
索引不足的表不能有效地服务于读取查询。 理想情况下,对表执行的最常见查询应受益于索引。 不太频繁的查询将根据具体情况进行评估,并在有益时进行索引。 当针对具有很少或没有非聚集索引的表对性能问题进行故障排除时,该问题很可能是索引不足的问题。 在这些情况下,请根据需要添加索引以提高性能!
No Clustered Index/Primary Key 没有聚集索引/主键All tables should have a clustered index and a primary key. Clustered indexes will almost always perform better than heaps and will provide the necessary infrastructure to add non-clustered indexes efficiently when needed. A primary key provides valuable information to the query optimizer that helps it make smart decisions when creating execution plans. If you run into a table with no clustered index or no primary key, consider these top priorities to research and resolve before continuing with further research.
所有表都应具有聚簇索引和主键。 聚集索引几乎总是比堆性能更好,并且将提供必要的基础结构,以便在需要时有效地添加非聚集索引。 主键为查询优化器提供了有价值的信息,可帮助其在创建执行计划时做出明智的决策。 如果您遇到没有聚集索引或主键的表,请在继续进行进一步研究之前,考虑这些最优先的问题进行研究和解决。
See the link at the end of this article for details on capturing, trending, and reporting on missing index data using SQL Server’s built-in dynamic management views. This allows you to learn about missing index suggestions when you may not be staring at your computer. It also allows you to see when multiple suggestions are made on a single query. The GUI will only display the top suggestion, but the raw XML for the execution plan will include as many as are suggested.
有关使用SQL Server内置的动态管理视图捕获,趋势化和报告丢失的索引数据的详细信息,请参见本文结尾处的链接。 这样,当您不盯着计算机时,您就可以了解缺少的索引建议。 它还允许您查看何时在单个查询上提出多个建议。 GUI将仅显示最上面的建议,但是执行计划的原始XML将包括所建议的内容。
高表数 (High Table Count)
The query optimizer in SQL Server faces the same challenge as any relational query optimizer: It needs to find a good execution plan in the face of many options in a very short span of time. It is essentially playing a game of chess and evaluating move after move. With each evaluation, it either throws away a chunk of plans similar to the suboptimal plan, or setting one aside as a candidate plan. More tables in a query would equate to a larger chess board. With significantly more options available, SQL Server has more work to do, but cannot take much longer to determine the plan to use.
SQL Server中的查询优化器面临着与任何关系查询优化器相同的挑战:面对非常多的选择,它需要在很短的时间内找到一个好的执行计划。 它本质上是在下象棋游戏,并一步步地评估移动。 每次评估时,它要么丢弃与次优计划相似的计划,要么将其作为候选计划。 查询中的更多表将等于更大的棋盘。 有了更多可用的选项,SQL Server有更多的工作要做,但是无需花费更长的时间来确定要使用的计划。
Each table added to a query increases its complexity by a factorial amount. While the optimizer will generally make good decisions, even in the face of many tables, we increase the risk of inefficient plans with each table added to a query. This is not to say that queries with many tables are bad, but that we need to use caution when increasing the size of a query. For each set of tables, it needs to determine join order, join type, and how/when to apply filters and aggregation.
添加到查询中的每个表都将其复杂性增加了一定数量。 尽管优化器通常会做出明智的决定,即使面对许多表,我们也会在将每个表添加到查询中的情况下增加无效计划的风险。 这并不是说包含多个表的查询是不好的,而是在增加查询的大小时需要谨慎。 对于每组表,它需要确定连接顺序,连接类型以及应用过滤器和聚合的方式/时间。
Based on how tables are joined, a query will fall into one of two basic forms:
根据表的连接方式,查询将分为两种基本形式之一:
- Left-Deep Tree: A join B, B join C, C join D, D join E, etc…This is a query in which most tables are sequentially joined one after another. 左深树 :A联接B,B联接C,C联接D,D联接E等等,这是一个查询,其中大多数表依次一个接一个地联接。
- Bushy Tree: A join B, A join C, B join D, C join E, etc…This is a query in which tables branch out into multiple logical units within each branch of the tree.
- 浓密树 :A 联接 B,A联接C,B联接D,C联接E等等,这是一个查询,其中表分支成树的每个分支内的多个逻辑单元。
Here is a graphical representation of a bushy tree, in which the joins branch upwards into the result set:
这是一棵浓密树的图形表示,其中联接向上分支到结果集中:
Similarly, here is a representation of what a left-deep tree would look like.
同样,这是一棵左深树的样子的表示。
Since the left-deep tree is more naturally ordered based on how the tables are joined, the number of candidate execution plans for the query are less than for a bushy tree. Included above is the math behind the combinatorics: that is, how many plans will be generated on average for a given query type.
由于根据表的连接方式更自然地对左深树进行排序,因此查询的候选执行计划的数量少于丛生树的数量。 上面包含的是组合方法背后的数学公式:即,对于给定的查询类型,平均将生成多少个计划。
To emphasize the enormity of the math behind table counts, consider a query that accesses 12 tables:
为了强调表计数背后的数学运算的庞大性,请考虑访问12个表的查询:
SELECT TOP 25
Product.ProductID,
Product.Name AS ProductName,
Product.ProductNumber,
CostMeasure.UnitMeasureCode,
CostMeasure.Name AS CostMeasureName,
ProductVendor.AverageLeadTime,
ProductVendor.StandardPrice,
ProductReview.ReviewerName,
ProductReview.Rating,
ProductCategory.Name AS CategoryName,
ProductSubCategory.Name AS SubCategoryName
FROM Production.Product
INNER JOIN Production.ProductSubCategory
ON ProductSubCategory.ProductSubcategoryID = Product.ProductSubcategoryID
INNER JOIN Production.ProductCategory
ON ProductCategory.ProductCategoryID = ProductSubCategory.ProductCategoryID
INNER JOIN Production.UnitMeasure SizeUnitMeasureCode
ON Product.SizeUnitMeasureCode = SizeUnitMeasureCode.UnitMeasureCode
INNER JOIN Production.UnitMeasure WeightUnitMeasureCode
ON Product.WeightUnitMeasureCode = WeightUnitMeasureCode.UnitMeasureCode
INNER JOIN Production.ProductModel
ON ProductModel.ProductModelID = Product.ProductModelID
LEFT JOIN Production.ProductModelIllustration
ON ProductModel.ProductModelID = ProductModelIllustration.ProductModelID
LEFT JOIN Production.ProductModelProductDescriptionCulture
ON ProductModelProductDescriptionCulture.ProductModelID = ProductModel.ProductModelID
LEFT JOIN Production.ProductDescription
ON ProductDescription.ProductDescriptionID = ProductModelProductDescriptionCulture.ProductDescriptionID
LEFT JOIN Production.ProductReview
ON ProductReview.ProductID = Product.ProductID
LEFT JOIN Purchasing.ProductVendor
ON ProductVendor.ProductID = Product.ProductID
LEFT JOIN Production.UnitMeasure CostMeasure
ON ProductVendor.UnitMeasureCode = CostMeasure.UnitMeasureCode
ORDER BY Product.ProductID DESC;
With 12 tables in a relatively busy-style query, the math would work out to:
在一个相对繁忙的查询中有12个表,该数学公式可以得出:
(2n-2)! / (n-1)! = (2*12-1)! / (12-1)! = 28,158,588,057,600 possible execution plans.
(2n-2)! /(n-1)! =(2 * 12-1)! /(12-1)! = 28,158,588,057,600个可能的执行计划。
If the query had happened to be more linear in nature, then we would have:
如果查询的性质恰好是线性的,那么我们将有:
n! = 12! = 479,001,600 possible execution plans.
n! = 12! = 479,001,600个可能的执行计划。
This is only for 12 tables! Imagine a query on 20, 30, or 50 tables! The optimizer can often slice those numbers down very quickly by eliminating entire swaths of sub-optimal options, but the odds of it being able to do so and generate a good plan decrease as table count increases.
这仅适用于12张桌子! 想象一下对20、30或50个表的查询! 通过消除整个次优选项,优化器通常可以非常Swift地减少这些数字,但是随着表格数量的增加,优化器能够这样做并生成良好计划的几率会降低。
What are some useful ways to optimize a query that is suffering due to too many tables?
有什么有用的方法可以优化由于表太多而受苦的查询?
- Move metadata or lookup tables into a separate query that places this data into a temporary table. 将元数据或查找表移到一个单独的查询中,该查询将该数据放入一个临时表中。
- Joins that are used to return a single constant can be moved to a parameter or variable. 可以将用于返回单个常量的联接移至参数或变量。
- Break a large query into smaller queries whose data sets can later be joined together when ready. 将大型查询分解为较小的查询,这些较小的查询的数据集可以在准备好以后连接在一起。
- For very heavily used queries, consider an indexed view to streamline constant access to important data. 对于使用率很高的查询,请考虑使用索引视图来简化对重要数据的持续访问。
- Remove unneeded tables, subqueries, and joins. 删除不需要的表,子查询和联接。
Breaking up a large query into smaller queries requires that there will be no data change in between those queries that would somehow invalidate the result set. If a query needs to be an atomic set, then you may need to use a mix of isolation levels, transactions, and locking to ensure data integrity.
将大型查询分解为较小的查询要求这些查询之间没有数据更改,这会使结果集无效。 如果查询需要是原子集,则可能需要混合使用隔离级别,事务和锁定来确保数据完整性。
More often than not when we are joining a large number of tables together, we can break the query up into smaller logical units that can be executed separately. For the example query earlier on 12 tables, we could very easily remove a few unused tables and split out the data retrieval into two separate queries:
当我们将大量表连接在一起时,通常可以将查询分解为较小的逻辑单元,这些逻辑单元可以单独执行。 对于前面对12个表的示例查询,我们可以很容易地删除一些未使用的表,并将数据检索分为两个单独的查询:
SELECT TOP 25
Product.ProductID,
Product.Name AS ProductName,
Product.ProductNumber,
ProductCategory.Name AS ProductCategory,
ProductSubCategory.Name AS ProductSubCategory,
Product.ProductModelID
INTO #Product
FROM Production.Product
INNER JOIN Production.ProductSubCategory
ON ProductSubCategory.ProductSubcategoryID = Product.ProductSubcategoryID
INNER JOIN Production.ProductCategory
ON ProductCategory.ProductCategoryID = ProductSubCategory.ProductCategoryID
ORDER BY Product.ModifiedDate DESC;
SELECT
Product.ProductID,
Product.ProductName,
Product.ProductNumber,
CostMeasure.UnitMeasureCode,
CostMeasure.Name AS CostMeasureName,
ProductVendor.AverageLeadTime,
ProductVendor.StandardPrice,
ProductReview.ReviewerName,
ProductReview.Rating,
Product.ProductCategory,
Product.ProductSubCategory
FROM #Product Product
INNER JOIN Production.ProductModel
ON ProductModel.ProductModelID = Product.ProductModelID
LEFT JOIN Production.ProductReview
ON ProductReview.ProductID = Product.ProductID
LEFT JOIN Purchasing.ProductVendor
ON ProductVendor.ProductID = Product.ProductID
LEFT JOIN Production.UnitMeasure CostMeasure
ON ProductVendor.UnitMeasureCode = CostMeasure.UnitMeasureCode;
DROP TABLE #Product;
This is only one of many possible solutions, but is a way to reduce a larger, more complex query into two simpler ones. As a bonus, we can review the tables involved and remove any unneeded tables, columns, variables, or anything else that may not be needed to return the data we are looking for.
这只是许多可能的解决方案中的一种,但是是一种将较大,更复杂的查询简化为两个简单查询的方法。 另外,我们可以查看所涉及的表,并删除不需要的表,列,变量或其他可能不需要的任何东西来返回我们要查找的数据。
Table count is a hefty contributor towards poor execution plans as it forces the query optimizer to sift through a larger result set and discard more potentially valid results in the search for a great plan in well under a second. If you are evaluating a poorly performing query that has a very large table count, try splitting it into smaller queries. This tactic may not always provide a significant improvement, but is often effective when other avenues have been explored and there are many tables that are being heavily read together in a single query.
表计数是执行计划不佳的重要因素,因为它迫使查询优化器筛选较大的结果集,并在不到一秒钟的时间内寻找更好的计划而放弃了更多可能有效的结果。 如果您正在评估一个性能很差的查询,该查询的表数量很大,请尝试将其拆分为较小的查询。 该策略可能并不总是可以提供重大的改进,但是当已经探索了其他途径并且有很多表在单个查询中被大量读取时,该策略通常是有效的。
查询提示 (Query Hints)
A query hint is an explicit direction by us to the query optimizer. We are bypassing some of the rules used by the optimizer to force it to behave in ways that it normally wouldn’t. In this regard, it’s more of a directive than a hint.
查询提示是我们对查询优化器的明确指示。 我们绕过了优化器使用的一些规则,以强制其以通常不会的方式运行。 在这方面,它更多是指令而不是提示。
Query hints are often used when we have a performance problem and adding a hint quickly and magically fixes it. There are quite a few hints available in SQL Server that affect isolation levels, join types, table locking, and more. While hints can have legitimate uses, they present a danger to performance for many reasons:
当我们遇到性能问题时,通常会使用查询提示,并快速添加提示并神奇地修复它。 SQL Server中有很多提示会影响隔离级别,联接类型,表锁定等等。 尽管提示可以合法使用,但由于多种原因,它们会对性能造成威胁:
- Future changes to the data or schema may result in a hint no longer being applicable and becoming a hindrance until removed. 数据或架构的未来更改可能会导致提示不再适用,并成为障碍,直到将其删除。
- Hints can obscure larger problems, such as missing indexes, excessively large data requests, or broken business logic. Solving the root of a problem is preferable than solving a symptom. 提示可能会掩盖较大的问题,例如缺少索引,数据请求过大或业务逻辑中断。 解决问题的根源比解决症状更可取。
- Hints can result in unexpected behavior, such as bad data from dirty reads via the use of NOLOCK. 提示可能会导致意外行为,例如通过使用NOLOCK进行脏读而导致的不良数据。
- Applying a hint to address an edge case may cause performance degradation for all other scenarios. 应用提示解决极端情况可能会导致其他所有情况的性能下降。
The general rule of thumb is to apply query hints as infrequently as possible, only after sufficient research has been conducted, and only when we are certain there will be no ill effects of the change. They should be used as a scalpel when all other options fail. A few notes on commonly used hints:
一般的经验法则是,只有在进行了充分的研究之后,并且只有在我们确定更改不会造成不良影响的情况下,才尽可能少地应用查询提示。 当所有其他选项均失败时,应将其用作手术刀。 关于常用提示的一些注意事项:
- NOLOCK: In the event that data is locked, this tells SQL Server to read data from the last known value available, also known as a dirty read. Since it is possible to use some old values and some new values, data sets can contain inconsistencies. Do not use this in any place in which data quality is important. NOLOCK :如果数据被锁定,则告诉SQL Server从最后一个已知的可用值(也称为脏读取)读取数据。 由于可以使用一些旧值和一些新值,因此数据集可能包含不一致之处。 不要在数据质量很重要的任何地方使用此功能。
- RECOMPILE: Adding this to the end of a query will result in a new execution plan being generated each time this query executed. This should not be used on a query that is executed often, as the cost to optimize a query is not trivial. For infrequent reports or processes, though, this can be an effective way to avoid undesired plan reuse. This is often used as a bandage when statistics are out of date or parameter sniffing is occurring. RECOMPILE :将其添加到查询的末尾将导致每次执行该查询时都生成一个新的执行计划。 不应在经常执行的查询上使用此方法,因为优化查询的成本并非微不足道。 但是,对于不经常使用的报告或流程,这可能是避免不必要的计划重用的有效方法。 当统计数据过时或发生参数嗅探时,通常将其用作绷带。
- MERGE/HASH/LOOP: This tells the query optimizer to use a specific type of join as part of a join operation. This is super-risky as the optimal join will change as data, schema, and parameters evolve over time. While this may fix a problem right now, it will introduce an element of technical debt that will remain for as long as the hint does. MERGE / HASH / LOOP :这告诉查询优化器将特定类型的联接用作联接操作的一部分。 这是超级风险,因为最佳连接将随着数据,模式和参数随时间的变化而变化。 尽管这可能会立即解决问题,但它会引入技术债务的一种元素,这种隐患会一直存在,直到提示出现为止。
- OPTIMIZE FOR: Can specify a parameter value to optimize the query for. This is often used when we want performance to be controlled for a very common use case so that outliers do not pollute the plan cache. Similar to join hints, this is fragile and when business logic changes, this hint usage may become obsolete. OPTIMIZE FOR :可以指定参数值以优化查询。 当我们希望在非常常见的用例中控制性能以使异常值不会污染计划缓存时,通常使用此方法。 与联接提示类似,它很脆弱,并且当业务逻辑更改时,此提示用法可能已过时。
Consider our name search query from earlier:
考虑一下我们之前的名称搜索查询:
SELECT
e.BusinessEntityID,
p.Title,
p.FirstName,
p.LastName
FROM HumanResources.Employee e
INNER JOIN Person.Person p
ON p.BusinessEntityID = e.BusinessEntityID
WHERE FirstName LIKE 'E%'
We can force a MERGE JOIN in the join predicate:
我们可以在联接谓词中强制执行MERGE JOIN:
SELECT
e.BusinessEntityID,
p.Title,
p.FirstName,
p.LastName
FROM HumanResources.Employee e
INNER MERGE JOIN Person.Person p
ON p.BusinessEntityID = e.BusinessEntityID
WHERE FirstName LIKE 'E%'
When we do so, we might observe better performance under certain circumstances, but may also observe very poor performance in others:
这样做时,我们可能会在某些情况下观察到更好的性能,但在其他情况下也可能会观察到非常差的性能:
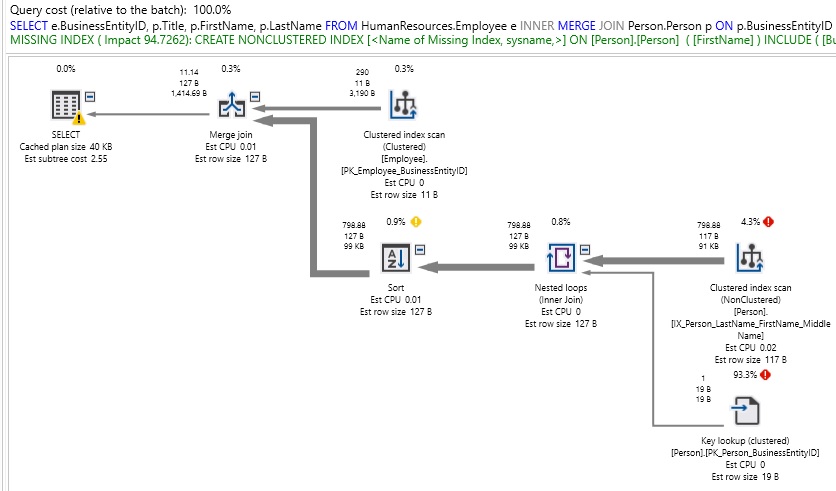
For a relatively simple query, this is quite ugly! Also note than our join type has limited index usage, and as a result we are getting an index recommendation where we likely shouldn’t need/want one. In fact, forcing a MERGE JOIN added additional operators to our execution plan in order to appropriately sort outputs for use in resolving our result set. We can force a HASH JOIN similarly:
对于一个相对简单的查询,这非常难看! 还要注意,我们的联接类型使用的索引有限,因此,我们得到了可能不需要/不需要的索引建议。 实际上,强制执行MERGE JOIN会在我们的执行计划中添加其他运算符,以便对输出进行适当排序以用于解析结果集。 我们可以类似地强制HASH JOIN:
SELECT
e.BusinessEntityID,
p.Title,
p.FirstName,
p.LastName
FROM HumanResources.Employee e
INNER HASH JOIN Person.Person p
ON p.BusinessEntityID = e.BusinessEntityID
WHERE FirstName LIKE 'E%'
Again, the plan is not pretty! Note the warning in the output tab that informs us that the join order has been enforced by our join choice. This is important as it tells is that the join type we chose also limited the possible ways to order the tables during optimization. Essentially, we have removed many useful tools available to the query optimizer and forced it to work with far less than it needs to succeed.
再次,计划不是很漂亮! 请注意输出选项卡中的警告,该警告告知我们我们的联接选择已强制执行联接顺序。 这很重要,因为它表明我们选择的联接类型也限制了优化期间对表进行排序的可能方式。 从本质上讲,我们已经删除了许多可用于查询优化器的有用工具,并迫使其无法成功使用。
If we remove the hints, then the optimizer will choose a NESTED LOOP join and get the following performance:
如果删除提示,那么优化器将选择NESTED LOOP联接并获得以下性能:

Hints are often used as quick fixes to complex or messy problems. While there are legit reasons to use a hint, they are generally held onto as last resorts. Hints are additional query elements that require maintenance and review over time as application code, data, or schema change. If needed, be sure to thoroughly document their use! It is unlikely that a DBA or developer will know why you used a hint in 3 years unless you document its need very well.
提示通常用作解决复杂或混乱问题的快速解决方案。 尽管有合理的理由使用提示,但通常将其作为最后的手段。 提示是其他查询元素,随着应用程序代码,数据或架构的更改,这些查询元素需要不断维护和审查。 如果需要,请务必彻底记录其使用! 除非您非常清楚地记录了需求,否则DBA或开发人员不太可能会在3年内知道您为什么使用该提示。
结论 (Conclusion)
In this article we discussed a variety of common query mistakes that can lead to poor performance. Since they are relatively easy to identify without extensive research, we can use this knowledge to improve our response time to latency or performance emergencies. This is only the tip of the iceberg, but provides a great starting point in finding the weak points in a script.
在本文中,我们讨论了各种可能导致性能下降的常见查询错误。 由于无需大量研究即可相对容易地识别它们,因此我们可以利用这些知识来缩短对延迟或性能紧急情况的响应时间。 这只是冰山一角,但为找到脚本中的薄弱环节提供了一个很好的起点。
Whether by cleaning up joins and WHERE clauses or by breaking a large query into smaller chunks, focusing our evaluation, testing, and QA process will improve the quality of our results, in addition to allowing us to complete these projects faster.
无论是通过清理联接和WHERE子句,还是通过将较大的查询分成较小的块,集中我们的评估,测试和质量检查流程,不仅可以使我们更快地完成这些项目,还可以提高结果的质量。
Everyone has their own toolset of tips & tricks that allow them to work faster AND smarter. Do you have any quick, fun, or interesting query tips? Let me know! I’m always looking at newer ways to speed up TSQL and avoid days of frustrating searching!
每个人都有自己的提示和技巧工具集,使他们可以更快,更聪明地工作。 您有任何快速,有趣或有趣的查询提示吗? 让我知道! 我一直在寻找更新的方法来加快TSQL的速度并避免几天令人沮丧的搜索!
目录 (Table of contents)
| Query optimization techniques in SQL Server: the basics |
| Query optimization techniques in SQL Server: tips and tricks |
| Query optimization techniques in SQL Server: Database Design and Architecture |
| Query Optimization Techniques in SQL Server: Parameter Sniffing |
| SQL Server中的查询优化技术:基础 |
| SQL Server中的查询优化技术:提示和技巧 |
| SQL Server中的查询优化技术:数据库设计和体系结构 |
| SQL Server中的查询优化技术:参数嗅探 |
翻译自: https://www.sqlshack.com/query-optimization-techniques-in-sql-server-tips-and-tricks/

















 321
321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}