





查看表结构索引
介绍 (Introduction)
Among many different things that can affect SQL Server performance, some are more significant than others. In addition, some changes can be relatively easy to implement, but others are quite painfully:
在可能影响SQL Server性能的许多不同因素中,某些因素比其他因素更为重要。 此外,某些更改可能相对容易实现,但其他更改则非常痛苦:
- Schema design has the single biggest impact on performance, but it’s also almost impossible to change afterwards 模式设计对性能有最大的影响,但之后几乎也无法更改
- Proper indexes also can switch a database to “turbo mode”, and they can be relatively easy added to production systems 适当的索引还可以将数据库切换为“ turbo模式”,并且可以相对容易地将其添加到生产系统中
- Query optimization should be the third task in performance tuning — the impact can be significant, but more often than not it requires changes on the client side 查询优化应该是性能调整中的第三项任务-影响可能很大,但通常它需要在客户端进行更改
- Concurrency control, like switching from locking to versioning, can help in some specific cases 并发控制,例如从锁定切换到版本控制,可以在某些特定情况下提供帮助
- Hardware tuning should be the last option. 硬件调整应该是最后的选择。
Through this series we are going to evaluate end to end indexing strategy that helps you improve SQL Server overall performance without affecting others aspects of production systems, like data consistency, client applications behavior or maintenance routines.
通过本系列文章,我们将评估端到端索引策略,该策略可帮助您提高SQL Server的整体性能而又不影响生产系统的其他方面,例如数据一致性,客户端应用程序行为或维护例程。
四种不同的表格结构 (Four different table structures)
Before SQL Server 2014 we had only two options:a table could be a heap or a b-tree. Now data can also be stored inside in-memory tables or in form of columnstore indexes. Due to the fact that these structures are completely different, the very first step of index strategy is to choose the correct table structure. To help you take informed decision, I’m going to compare available options.
在SQL Server 2014之前,我们只有两个选择:表可以是堆或b树。 现在,数据也可以存储在内存表中或以列存储索引的形式存储。 由于这些结构完全不同, 因此索引策略的第一步就是选择正确的表结构 。 为了帮助您做出明智的决定,我将比较可用的选项。
Test environment 测试环境Let’s start with a sample database:
让我们从一个示例数据库开始:
USE [master];
GO
IF DATABASEPROPERTYEX (N'Indices', N'Version') > 0
BEGIN
ALTER DATABASE Indices SET SINGLE_USER
WITH ROLLBACK IMMEDIATE;
DROP DATABASE Indices;
END
GO
CREATE DATABASE Indices
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'Indices',
FILENAME = N'e:\SQL\Indices.mdf' ,
SIZE = 500MB , FILEGROWTH = 50MB )
LOG ON
( NAME = N'Indices_log', FILENAME = N'e:\SQL\Indices_log.ldf' ,
SIZE = 250MB , FILEGROWTH = 25MB )
GO
ALTER DATABASE Indices SET RECOVERY SIMPLE;
GO
USE Indices
GO
In addition to this, we will need a tool that allows us to simulate and measure user activity(all we need is the ability to execute queries simultaneously and monitor execution times as well as number of read/write pages). You will find a lot of tools such as those in the Internet – I chose SQLQueryStress, a free tool made by Adam Mechanic.
除此之外,我们将需要一个工具来模拟和衡量用户活动(我们需要的是能够同时执行查询并监视执行时间以及读/写页数的功能)。 您会发现很多工具,例如Internet上的工具-我选择了Adam Mechanic免费提供SQLQueryStress工具。
堆 (Heaps)
A table without clustered index is a heap — just a set of unordered pages. This is the simplest data structure available, but as you will see definitely not the best one:
没有聚集索引的表就是一个堆-只是一组无序的页面。 这是可用的最简单的数据结构,但是您肯定不会看到最好的数据结构:
CREATE TABLE dbo.Heap(
id INT IDENTITY(1,1),
fixedColumns CHAR(200) CONSTRAINT Col2Default DEFAULT 'This column mimics
all fixed-legth columns',
varColumns VARCHAR(200) CONSTRAINT Col3Default DEFAULT 'This column mimics
all length-legth columns',
);
GO
Let’s check how long it takes to load 100000 rows into this table using 50 concurrent sessions — for this purpose I’m going to execute simple INSERT INTO dbo.Heap DEFAULT VALUES; statement with number of iteration set to 2000 and number of threads to 50.
让我们检查一下使用50个并发会话将100000行加载到该表中需要多长时间-为此,我将执行简单的INSERT INTO dbo。 迭代次数设置为2000,线程数设置为50的语句。
On my test machine (SQL Server 2014, Intel Pentium i7 with SSD drive), it took 18 seconds, in average. As a result we got these 3300 pages of table:
在我的测试机器(SQL Server 2014,带SSD驱动器的Intel Pentium i7)上,平均花费了18秒。 结果,我们得到了3300页的表格:
SELECT index_type_desc,avg_page_space_used_in_percent
,avg_fragment_size_in_pages,page_count,record_count,forwarded_record_count,
avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(db_id(), OBJECT_ID('dbo.Heap'), NULL, NULL, 'detailed');
GO;
-------------------------------------------------------------------------------------
HEAP 97,2869038794168 300,090909090909 3301 100000 0 258
Of course, because there is no ordering whatsoever, the only way to get a row from this table is through a scan:
当然,由于根本没有排序,因此从该表中获取行的唯一方法是通过扫描:
SET STATISTICS IO ON;
SELECT *
FROM dbo.Heap
WHERE id=2345;
GO
----------------------------------------------------------------------------------------------------------
(1 row(s) affected)
Table 'Heap'. Scan count 1, logical reads 3301, physical reads 0, read-ahead reads 0, lob logical reads 0,
lob physical reads 0, lob read-ahead reads 0.
Not only SELECT performance is bad, UPDATEs against heaps are also really slow. In order to see it we need two queries: the first one will return some numbers and will be used for parameter substation, the second one will be executed in 5 concurrent sessions:
不仅SELECT性能很差,而且针对堆的UPDATE确实也很慢。 为了查看它,我们需要两个查询:第一个查询将返回一些数字并将用于参数变电站,第二个查询将在5个并发会话中执行:
SELECT 9 AS nr
UNION
SELECT 13
UNION
SELECT 17
UNION
SELECT 25
UNION
SELECT 29;
UPDATE dbo.Heap
SET varColumns = REPLICATE('a',200)
WHERE id % @var = 0;
The results are shown in the picture below (4 noticed exceptions were due to deadlocks):
结果如下图所示(4个异常是由于死锁引起的):
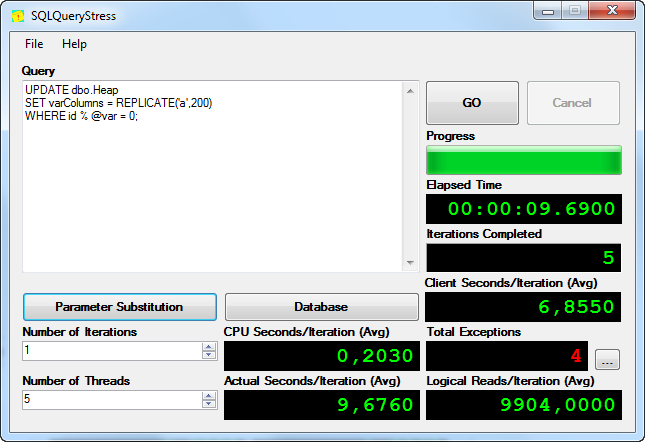
Altogether 7 700 rows were modified, it means that we achieved about 800 modifications per second.
总共修改了7700行,这意味着我们每秒实现了约800次修改 。
Not only UPDATEs are slow, but they can have a side effect that will affect the performance of queries and will last till the heap is rebuilt. Now I’m talking about forwarded records (if there is not enough space on a page to store new version of a record, the part of it will be saved on a different page, and only forwarding pointer to this page will be stored with the remaining part of this record). In this case more than 3000 forwarded records were created:
不仅UPDATE的速度很慢,而且它们还会产生副作用,这会影响查询的性能并持续到重建堆为止。 现在,我谈论的是转发记录(如果页面上没有足够的空间来存储记录的新版本,则记录的一部分将保存在其他页面上,并且仅指向该页面的转发指针将与该记录的其余部分)。 在这种情况下,创建了3000多个转发记录:
SELECT index_type_desc,avg_page_space_used_in_percent
,avg_fragment_size_in_pages,page_count,record_count,forwarded_record_count,
avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(db_id(), OBJECT_ID('dbo.Heap'), NULL, NULL, 'detailed');
----------------------------------------------------------------------------------------
HEAP 96,9105263157895 316,090909090909 3477 103160 3160 262,446
The remaining operations, DELETEs, also have unwanted side effects — space taken by deleted records will not be reclaim automatically:
其余操作DELETE也会产生有害的副作用-删除的记录所占用的空间将不会自动回收:
DELETE dbo.Heap
WHERE id % 31 = 0;
SELECT index_type_desc,avg_page_space_used_in_percent
,avg_fragment_size_in_pages,page_count,record_count,forwarded_record_count,
avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(db_id(), OBJECT_ID('dbo.Heap'), NULL, NULL, 'detailed');
GO
----------------------------------------------------------------------------------------
HEAP 93,8075858660736 316,090909090909 3477 99827 3052 262,461
At this point the only way of reclaiming this space and getting rid of forwarded records is to rebuild a table:
此时,回收此空间并摆脱转发记录的唯一方法是重建表:
ALTER TABLE dbo.Heap
REBUILD;
SELECT index_type_desc,avg_page_space_used_in_percent
,avg_fragment_size_in_pages,page_count,record_count,forwarded_record_count,
avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(db_id(), OBJECT_ID('dbo.Heap'), NULL, NULL, 'detailed');
----------------------------------------------------------------------------------------
HEAP 97,7820607857672 195,647058823529 3326 96775 0 270,076
推荐建议 (Recommendations)
Because of suboptimal SELECT performance, and side effects of UPDATE and DELETE statements, heaps are sometimes used for logging and stage tables — in first case, rows are almost always only inserted into a table, in the second one we try maximize data load by inserting rows into a heap and after moving them to a destination, indexed table. But even for those scenarios heaps are not necessary the best (more on this topic in upcoming articles). So, the first step our indexing strategy is to find heaps. Quite often these tables will be unused, so they will have no or minimal impact on performance. This is why you should concentrate on active heaps — one of the standard ways of finding them in current database is to execute this query:
由于SELECT性能欠佳,以及UPDATE和DELETE语句的副作用,因此有时会将堆用于日志记录和阶段表-在第一种情况下,行几乎总是只插入到表中,在第二种情况下,我们尝试通过插入来最大化数据负载行到堆中,然后将它们移到目标索引表中。 但是即使对于那些场景,也不一定是最好的堆(有关更多信息,请参见后续文章)。 因此,我们的索引策略的第一步是查找堆。 这些表经常不被使用,因此它们对性能没有影响或影响很小。 这就是为什么您应该专注于活动堆的原因-在当前数据库中查找活动堆的标准方法之一是执行以下查询:
SELECT t.name, ius.user_seeks, ius.user_scans, ius.user_lookups, ius.user_updates,
ius.last_user_scan
FROM sys.indexes i
INNER JOIN sys.objects o
ON i.object_id = o.object_id
INNER JOIN sys.tables t
ON o.object_id = t.object_id
INNER JOIN sys.partitions p
ON i.object_id = p.object_id AND i.index_id = p.index_id
LEFT OUTER JOIN sys.dm_db_index_usage_stats ius
ON i.object_id = ius.object_id AND i.index_id = ius.index_id
WHERE i.type_desc = 'HEAP'
AND COALESCE(ius.user_seeks, ius.user_scans, ius.user_lookups, ius.user_updates) IS NOT
NULL
AND o.is_ms_shipped = 0
AND o.type <> 'S';
----------------------------------------------------------------
Heap 0 1 0 0 2014-09-24 15:42:38.923
With this list in hand you should start asking serious question why these tables are heaps. And if no excuses were given, covert them into different structures.
有了这个列表,您应该开始问一个严肃的问题,为什么这些表是堆。 如果没有借口,则将其隐藏为不同的结构。
接下来会发生什么? (What is coming next?)
In the next article two new table structures (in-memory tables and columnstore indexes) will be described and compared with heaps.
在下一篇文章中,将描述两个新的表结构(内存表和列存储索引)并将其与堆进行比较。
翻译自: https://www.sqlshack.com/index-strategies-part-1-choosing-right-table-structure/
查看表结构索引















 787
787











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









