





sql server合并行
In this article we will discuss about SQL Server Merge Replication Parameterized row filter issues while replicating incremental data changes post initial snapshot.
在本文中,我们将讨论有关SQL Server合并复制参数化行过滤器问题,同时在初始快照后复制增量数据更改。
We had merge replication configured on one of our database and used parameterized row filters to replicate rows that match the filter condition of the subscriber. While validating data on the subscribers we found that there were a few records that did not match the filter condition. First, we looked at bulk copy files in snapshot. The data looked normal in snapshot files and matched with the filter condition.
我们已经在数据库之一上配置了合并复制,并使用了参数化的行过滤器来复制与订阅者的过滤条件匹配的行。 在验证订户上的数据时,我们发现有一些记录与过滤条件不匹配。 首先,我们查看了快照中的批量复制文件。 快照文件中的数据看起来正常,并且与过滤条件匹配。
So, we determined that the filters did not work properly only on incremental changes after snapshot and this filter condition did not work for the rows that were modified at publisher database. Let us see how filters work in merge replication and why they got replicated to the subscriber even though the filter condition did not match.
因此,我们确定筛选器不能仅在快照后的增量更改上正常运行,并且此筛选条件不适用于在发布者数据库上修改的行。 让我们看看过滤器如何在合并复制中工作,以及为什么即使过滤条件不匹配也将它们复制到订阅服务器。
Below are my publisher and subscriber databases.
以下是我的发布者和订阅者数据库。
Test1: Publisher database
测试1:发布者数据库
Test2: Subscriber database with partition ORG1
Test2:具有分区ORG1的订户数据库
On the publisher database, let us create sample tables and add these tables to merge replication in SQL Server.
在发布者数据库上,让我们创建示例表并添加这些表以合并SQL Server中的复制。
- Note: This is to just illustrate the scenario. actual tables are different in structure with lot of columns and a trigger to update Org value if the row is inserted with NULL UserOrg or wrong UserOrg.
- 注意:这只是为了说明这种情况。 实际的表在结构上有所不同,有很多列,并且如果在行中插入NULL UserOrg或错误的UserOrg,则会触发更新Org值的触发器。
CREATE TABLE Users (UserID INT,UserOrg varchar(50))
CREATE TABLE UserDetails
(UserID INT,Add1 varchar(50), Add2 varchar(50),UserOrg VARCHAR(50))
CREATE TRIGGER TR_INS_UserDetails ON UserDetails
FOR INSERT
NOT FOR REPLICATION
AS
BEGIN
DECLARE @ParentOrg VARCHAR(50)
,@Userid INT
DECLARE UpdateOrg CURSOR
FOR
SELECT UserID
FROM inserted
OPEN UpdateOrg
FETCH NEXT
FROM UpdateOrg
INTO @Userid
WHILE @@FETCH_STATUS = 0
BEGIN
SELECT @ParentOrg = UserOrg
FROM Users
WHERE userid = @Userid
UPDATE UserDetails
SET UserOrg = @ParentOrg
WHERE userid = @Userid
FETCH NEXT
FROM UpdateOrg
INTO @Userid
END
CLOSE UpdateOrg
DEALLOCATE UpdateOrg
END
INSERT INTO Users VALUES (1,'ORG1')
INSERT INTO Users VALUES (2,'ORG1')
INSERT INTO Users VALUES (3,'ORG1')
INSERT INTO Users VALUES (4,'ORG2')
INSERT INTO Users VALUES (5,'ORG2')
INSERT INTO UserDetails VALUES (1,'Lane1','Lane2','ORG1')
INSERT INTO UserDetails VALUES (2,'Lane1','Lane2','ORG1')
INSERT INTO UserDetails VALUES (3,'Lane1','Lane2','ORG1')
INSERT INTO UserDetails VALUES (4,'Lane1','Lane2','ORG2')
INSERT INTO UserDetails VALUES (5,'Lane1','Lane2','ORG2')
Now add these tables to merge replication with parametrized row filters. Follow the steps in the referenced article to configure merge publication and adding tables to the publication: SQL Server Replication (Merge) – What gets replicated and what doesn’t
现在添加这些表以将复制与参数化的行过滤器合并。 请按照引用的文章中的步骤配置合并发布并将表添加到发布中: SQL Server复制(合并)–复制哪些内容而不复制哪些内容
At Add filter step add below filter.
在添加过滤器步骤中,在过滤器下方添加。
SELECT <published_columns> FROM [dbo].[UserDetails] WHERE [UserOrg] = HOST_NAME()
Similarly add the filter for user tables as well.
同样,也为用户表添加过滤器。
SELECT <published_columns> FROM [dbo].[Users] WHERE [UserOrg] =HOST_NAME()
Once the publication setup is completed, generate the snapshot for merge replication. After generating the snapshot navigate to publication, right click and click on Properties -> Data Partitions
发布设置完成后,生成快照以进行合并复制。 生成快照后,导航至发布,右键单击并单击“ 属性” ->“ 数据分区”
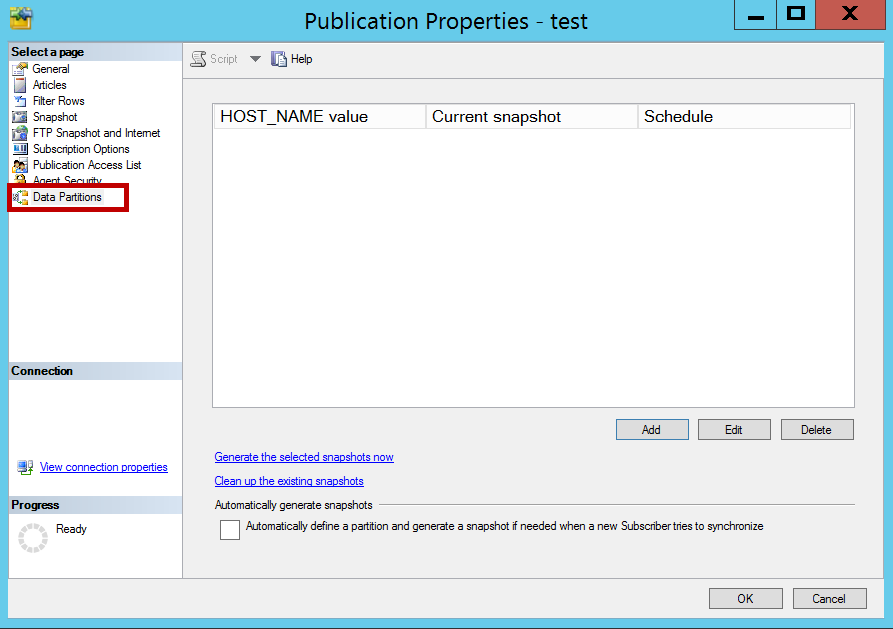
Click on Add and enter the partition value i.e. ORG1 and click ok. As of now I am adding only one partition ORG1. We can add more based on subscribers. For example, if I have a subscriber with partition ORG2 then we can add partition for ORG2 here and generate a partitioned snapshot which will be applied on specific subscriber.
单击添加,然后输入分区值,即ORG1,然后单击确定。 截至目前,我仅添加一个分区ORG1。 我们可以根据订阅者添加更多内容。 例如,如果我的订户具有分区ORG2,则可以在此处为ORG2添加分区,并生成一个分区快照,该快照将应用于特定订户。
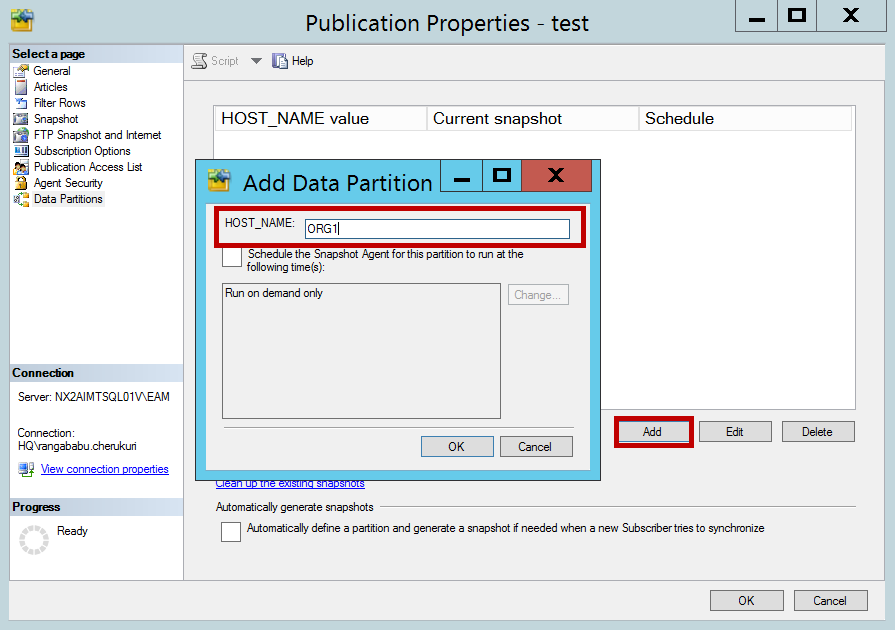
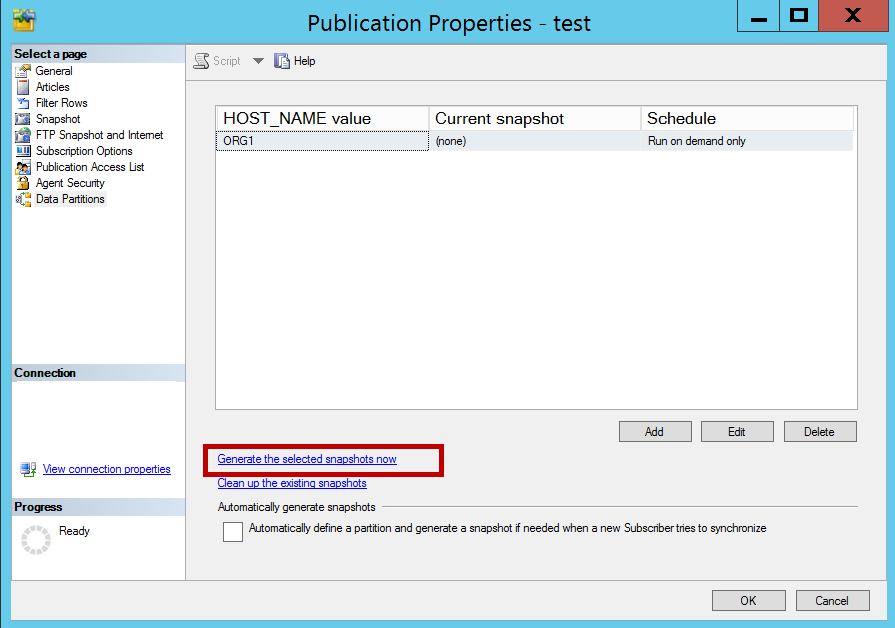
Now click on generate the selected snapshot now and click OK.
现在单击立即生成所选快照 ,然后单击确定 。
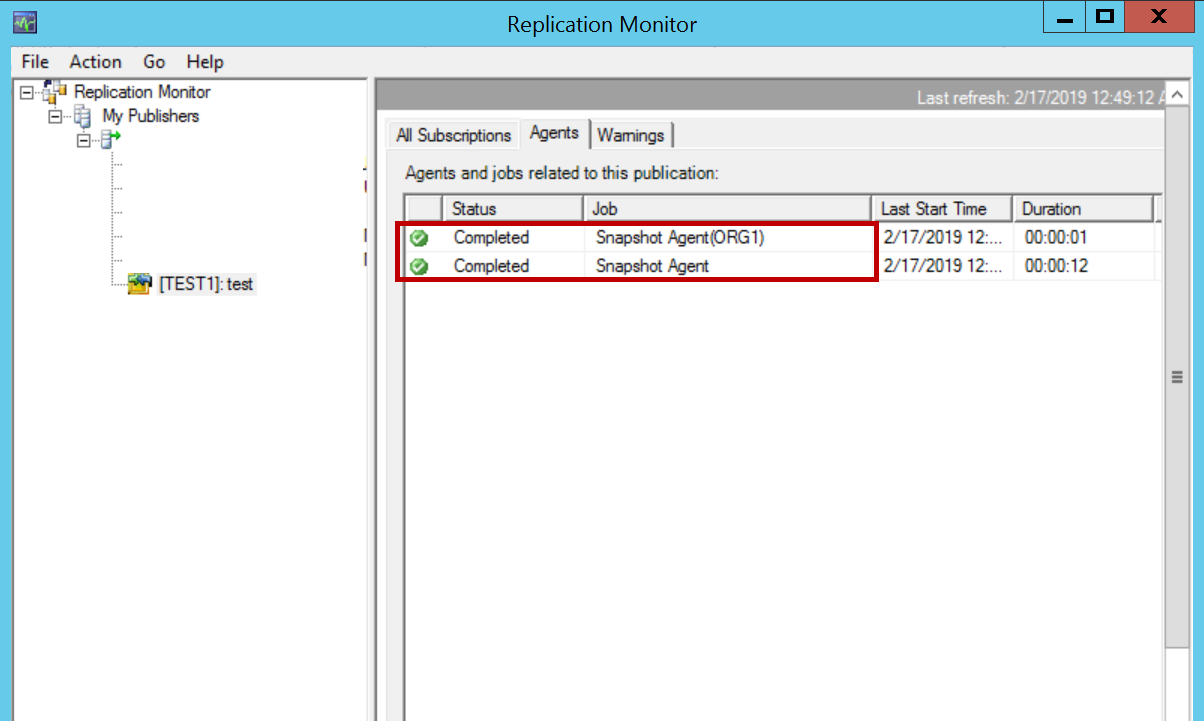
Right click on publication in merge replication, launch SQL Server replication monitor and make sure the partitioned snapshot is also completed.
右键单击合并复制中的发布,启动SQL Server复制监视器,并确保分区快照也已完成。
Now add subscription. Please follow steps in the following article to add subscriber: Merge Replication – What gets replicated and what doesn’t
现在添加订阅。 请按照以下文章中的步骤添加订户: 合并复制–复制哪些内容,哪些不复制
While adding the subscriber specify the HOST_NAME() value of the subscriber, so that the rows with UserOrg value ORG1 only will be replicated to the subscriber.
在添加订阅服务器时,请指定订阅服务器的HOST_NAME()值,以便将仅具有UserOrg值ORG1的行复制到订阅服务器。
After adding the subscriber in merge replication, apply the initial snapshot on subscriber. We can see the row with org value ORG1 got replicated to subscriber with partition ORG1.
在合并复制中添加订阅服务器后,将初始快照应用于订阅服务器。 我们可以看到组织值为ORG1的行已复制到分区ORG1的订阅服务器。
Now let us discuss internal tables used for data partitions filters in Merge Replication.
现在让我们讨论合并复制中用于数据分区过滤器的内部表。
When precompute partitions is set to true on subscription options in publication properties, all the inserts, updates and deletes will be evaluated for filter condition at the time of changes and meta data is saved in internal tables listed below.
在发布属性中的订阅选项上将预计算分区设置为true时,将在更改时评估所有插入,更新和删除的筛选条件,并将元数据保存在下面列出的内部表中。
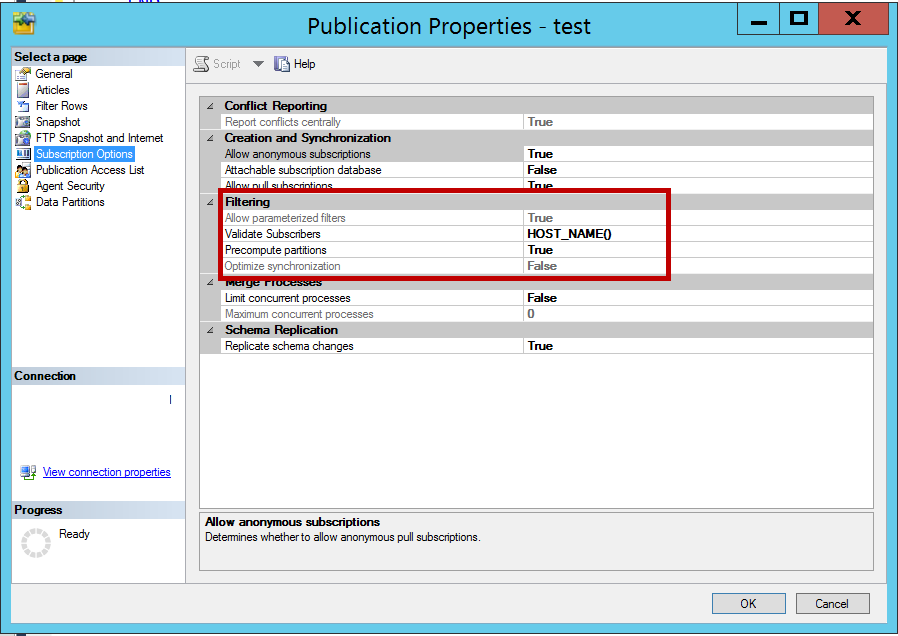
- sysmergepartitioninfo sysmergepartitioninfo
- MSmerge_partition_groups MSmerge_partition_groups
- MSmerge_current_partition_mappings MSmerge_current_partition_mappings
- MSmerge_past_partition_mappings MSmerge_past_partition_mappings
Sysmergepartitioninfo: This table stores the information of partition rules for each table which has parametrized row filter in merge replication.
Sysmergepartitioninfo :该表存储每个表的分区规则信息,这些表在合并复制中具有参数化的行筛选器。
MSmerge_partition_groups: This table stores one row for each pre-computed partition i.e. In our case we will have one row for ORG1 partition. If any new data partitions were added then entries related to partition are also inserted in this table.
MSmerge_partition_groups:该表为每个预先计算的分区存储一行,也就是说,在我们的情况下,我们为ORG1分区存储一行。 如果添加了任何新的数据分区,则与此分区相关的条目也将插入此表中。
As we know when a table is added to merge replication three system triggers will be created. One for insert, one for update and one for delete. All the inserts, deletes and updates on the replicated database will be tracked by these triggers and store the information in merge SQL Server replication internal tables.
众所周知,添加表以合并复制时,将创建三个系统触发器。 一种用于插入,一种用于更新,另一种用于删除。 这些触发器将跟踪复制数据库上的所有插入,删除和更新,并将信息存储在合并SQL Server复制内部表中。
在合并复制中启用预计算 (Pre-compute Enabled in merge replication)
Now when data is inserted into the table, the Msmerge insert trigger is fired which evaluates the filter condition and store the information in MSmerge_current_partition_mappings table. i.e. this table maintains the information of which row belongs to which partitions. So that when the subscriber syncs with publisher it will get the information from this table which is already pre- computed and starts downloading changes directly instead of evaluating the filter condition while syncing.
现在,当将数据插入表中时,将触发Msmerge插入触发器,该触发器将评估过滤条件并将信息存储在MSmerge_current_partition_mappings表中。 即,该表维护哪个行属于哪个分区的信息。 这样,当订阅者与发布者同步时,它将从此表中获取已经预先计算的信息,并直接开始下载更改,而不是在同步时评估过滤条件。
在合并复制中禁用预计算 (Pre-compute Disabled in merge replication)
If pre-compute partitions option is disabled the subscriber evaluates the filter condition while syncing and this process must be repeated for every subscriber that synchronizes with the publisher.
如果禁用了“预先计算分区”选项,则订阅者将在同步时评估筛选条件,并且必须对与发布者进行同步的每个订阅者重复此过程。
Pre-computed partitions are enabled by default. Let us insert a few rows into these tables and check the rowguid mappings in MSmerge_current_partition_mappings table.
默认情况下会启用预计算分区。 让我们在这些表中插入几行,并检查MSmerge_current_partition_mappings表中的rowguid映射。
INSERT INTO Users (UserID,UserOrg) VALUES (6,'ORG1')
INSERT INTO UserDetails (UserID,Add1,Add2,UserOrg) VALUES (6,'Lane1','Lane2','ORG1')
Now we can see two entries in MSmerge_current_partition_mappings with rowguid’s of inserted rows mapped with ORG1.
现在,我们可以在MSmerge_current_partition_mappings中看到两个条目,其中已插入行的rowguid与ORG1映射。
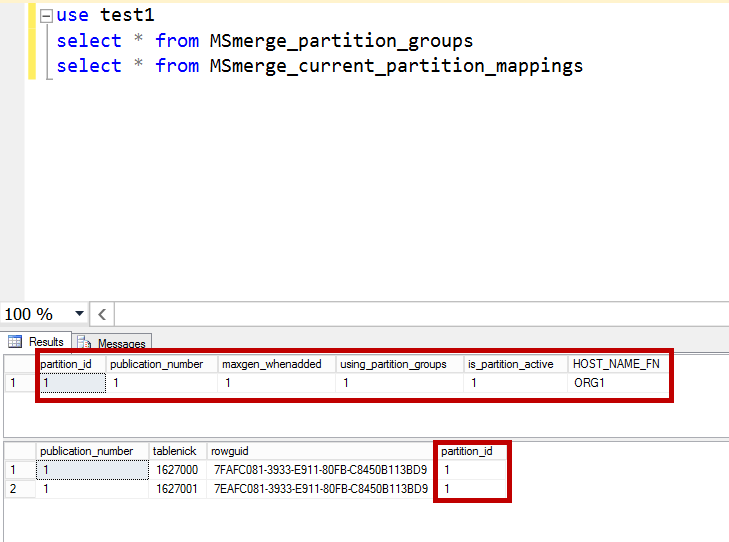
Insert few rows which are related to ORG2 and check for the rowguid mappings in MSmerge_current_partition_mappings table in merge replication.
插入与ORG2相关的几行,并在合并复制中检查MSmerge_current_partition_mappings表中的rowguid映射。
INSERT INTO Users (UserID,UserOrg) VALUES (7,'ORG2')
INSERT INTO UserDetails (UserID,Add1,Add2,UserOrg) VALUES (7,'Lane1','Lane2','ORG2')
We can see there were no entries in table for the above rows as we have not specified the data partition for ORG2 in publication properties.
我们可以看到上面的行在表中没有条目,因为我们没有在发布属性中为ORG2指定数据分区。
Now let us update the UserOrg of UserID 6 and check the data in the MSmerge_current_partition_mappings and MSmerge_past_partition_mappings
现在,让我们更新UserID 6的UserOrg并检查MSmerge_current_partition_mappings和MSmerge_past_partition_mappings中的数据
If we update data of an existing row, the filter conditions are evaluated in merge replication internal MSmerge update trigger and delete the entries for existing partition in MSmerge_current_partition_mappings and insert updated mapping data in MSmerge_current_partition_mappings.
如果我们更新现有行的数据,则在合并复制内部MSmerge更新触发器中评估过滤条件,并删除MSmerge_current_partition_mappings中现有分区的条目,并在MSmerge_current_partition_mappings中插入更新的映射数据。
For example, if we update the UserOrg of Userid 6 to ORG2 then the existing partition information from MSmerge_current_partition_mappings is deleted and move the old partition data to MSmerge_past_partition_mappings table.
例如,如果我们将用户ID 6的UserOrg更新为ORG2,则将删除MSmerge_current_partition_mappings中的现有分区信息,并将旧分区数据移动到MSmerge_past_partition_mappings表中。
UPDATE Users set UserOrg = 'ORG2' WHERE UserID =6
UPDATE Users set UserDetails = 'ORG2' WHERE UserID =6
Now we will check the filters by inserting wrong org values or NULL into the UserDetails table.
现在,我们将通过在UserDetails表中插入错误的组织值或NULL来检查过滤器。
INSERT INTO Users (UserID,UserOrg) VALUES (12,'ORG2')
INSERT INTO UserDetails (UserID,Add1,Add2,UserOrg) VALUES (12,'Lane1','Lane2','ORG1')
The trigger TR_INS_UserDetails on UserDetails table is fired and updates the UserOrg value correctly.
触发UserDetails表上的触发器TR_INS_UserDetails并正确更新UserOrg值。
So, the UserOrg for UserID 12 will be ORG2 as the trigger updated correct org value while inserting data and the row is not replicated to subscriber as per filter condition in Merge Replication.
因此,用户ID 12的UserOrg将是ORG2,因为触发器在插入数据时会更新正确的组织值,并且不会按照合并复制中的过滤条件将行复制到订户。
Here the execution order of user trigger and MSmerge insert trigger is very important in case of UserDetails. If the SQL Server replication MSmerge insert trigger is fired first, the sequence of steps that happens next is as follows:
在使用UserDetails的情况下,用户触发器和MSmerge插入触发器的执行顺序非常重要。 如果首先触发SQL Server复制MSmerge插入触发器,则接下来发生的步骤序列如下:
- The MSmerge insert trigger is fired first and maps the rowguid with ORG1 partition in MSmerge_current_partition_mappings 首先触发MSmerge插入触发器,并在MSmerge_current_partition_mappings中将Rowguid与ORG1分区映射
- TR_INS_UserDetails is fired which updates UserOrg to ORG2. Here MSmerge update trigger is fired and deletes the previous partition mapping information in MSmerge_current_partition_mappings and insert mapping with ORG2 if ORG2 partition exist 触发TR_INS_UserDetails,将UserOrg更新为ORG2。 在此触发MSmerge更新触发器,并删除MSmerge_current_partition_mappings中的先前分区映射信息,如果存在ORG2分区,则使用ORG2插入映射
- Now when subscriber with hostname ORG1 syncs with publisher then row with UserID 12 is not replicated 现在,当主机名为ORG1的订阅服务器与发布服务器同步时,不会复制用户ID为12的行
合并复制失败的情况 (Failure case for Merge Replication)
In my case somehow the trigger TR_INS_UserDetails is fired first and MSmerge insert trigger is fired later.
在我的情况下,触发器TR_INS_UserDetails首先被触发,而MSmerge插入触发器随后被触发。
Let us illustrate the same scenario by forcing the user trigger to fire first. On publisher database execute below script to force the user trigger to fire first.
让我们通过强制用户触发先触发来说明相同的情况。 在发布者数据库上,执行以下脚本以强制用户触发器首先触发。
EXEC sys.sp_settriggerorder @triggername = 'TR_INS_UserDetails',
@order = 'FIRST',
@stmttype = 'INSERT',
@namespace = NULL
Below are the steps that happen when user trigger is fired first.
以下是首先触发用户触发器时发生的步骤。
INSERT INTO Users (UserID,UserOrg) VALUES (13,'ORG2')
INSERT INTO UserDetails (UserID,Add1,Add2,UserOrg) VALUES (13,'Lane1','Lane2','ORG1')
- The user trigger is fired first and updates UserOrg with correct value i.e. ORG2. Here the MSmerge update trigger is also fired and check for existing partition and does not find any partition as the MSmerge insert trigger is not fired yet. So, it just maps the rowguid with ORG2 partition if partition for ORG2 exist 首先触发用户触发器,并使用正确的值(即ORG2)更新UserOrg。 在这里,还将触发MSmerge更新触发器,并检查现有分区,并且未找到任何分区,因为尚未触发MSmerge插入触发器。 因此,如果存在ORG2的分区,它只会将rowguid映射到ORG2分区
- The MSmerge insert trigger is fired later which maps the rowguid with old org value i.e. with ORG1 稍后触发MSmerge插入触发器,该触发器将rowguid与旧的org值(即ORG1)映射
-
Please check the following:
请检查以下内容:
- That the execution order of triggers in case if you are updating the column used in filter condition using triggers and make sure the MSmerge_current_partition_mappings table is being filled with correct mappings between rowguid’s and partitions in Merge Replication 如果要使用触发器更新过滤条件中使用的列,并确保MSmerge_current_partition_mappings表被合并复制中rowguid和分区之间的正确映射填充,则触发器的执行顺序
- Database collation is used rather than the table collation when evaluating filter condition 在评估过滤条件时,使用数据库排序规则而不是表排序规则
目录 (Table of contents)
| 具有超过246列的表SQL Server复制 |
| 在SQL Server合并复制中应用快照时出现外键问题 |
| SQL Server复制(合并)–复制什么,什么不复制 |
| SQL Server复制(合并)–复制架构更改中的性能问题 |
| 合并SQL Server复制参数化的行筛选器问题 |
| 镜像数据库上的日志传送 |
翻译自: https://www.sqlshack.com/merge-sql-server-replication-parameterized-row-filter-issues/
sql server合并行















 126
126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









