





Database administrators can leverage the scalability, automation, and flexibility of Kubernetes to create a highly available SQL database cluster. In this article, you will learn what Kubernetes is, what are the benefits of running an SQL database on Kubernetes, and how to deploy MySQL on Kubernetes.
数据库管理员可以利用Kubernetes的可伸缩性,自动化和灵活性来创建高度可用SQL数据库集群。 在本文中,您将学习什么是Kubernetes,在Kubernetes上运行SQL数据库有什么好处,以及如何在Kubernetes上部署MySQL。
什么是Kubernetes? (What Is Kubernetes?)
Kubernetes (k8s) is an open-source orchestration and management system for containers. It was developed by Google to help teams reliably deploy and manage containers at scale with automation. Although k8s started as an internal project, it was released to the public back in 2015.
Kubernetes(k8s)是用于容器的开源编排和管理系统。 它由Google开发,旨在帮助团队通过自动化可靠地大规模部署和管理容器。 尽管k8s最初是内部项目,但早在2015年就向公众发布。
Kubernetes如何工作 (How Kubernetes works)
Kubernetes is based on a client-server model. It implements a layered architecture with a master server controlling several nodes (clusters of machines) on which containers are hosted. On each node are a variable number of pods (containers) which run your services and workloads.
Kubernetes基于客户端-服务器模型。 它通过一个主服务器来实现分层架构,该主服务器控制托管容器的多个节点(机器集群)。 在每个节点上有数量可变的Pod(容器),它们可以运行您的服务和工作负载。
During operation, Kubernetes monitors these nodes, distributing traffic across services, and replacing failed resources as needed. It does this with the help of a number of daemons, APIs, and templates.
在运行期间,Kubernetes监视这些节点,跨服务分布流量,并根据需要替换发生故障的资源。 它借助许多守护程序,API和模板来完成此任务。
在Kubernetes上运行SQL数据库 (Running SQL databases on Kubernetes)
When running SQL in containers is discussed, it often means running SQL Server. SQL Server container images have been available since 2017. Within each image are the files needed for the SQL Server engine, the server agent, built-in features like replication, and command-line tools.
当讨论在容器中运行SQL时,通常意味着运行SQL Server。 SQL Server容器映像自2017年以来已可用。每个映像中都包含SQL Server引擎,服务器代理,复制等内置功能和命令行工具所需的文件。
These images originally only supported Ubuntu 16.04, but with the 2019 update, now support Red Hat, Ubuntu, and Windows. With the 2019 update, a focus has been added to containerization to support big data clusters.
这些映像最初仅支持Ubuntu 16.04,但随着2019更新,现在支持Red Hat,Ubuntu和Windows。 在2019年更新中,重点已放在容器化上以支持大数据集群。
However, you can run other SQL-based databases as well, such as MySQL or Oracle. These work roughly the same way as SQL Server, and there are many images available for you to use.
但是,您也可以运行其他基于SQL的数据库,例如MySQL或Oracle 。 它们的工作方式与SQL Server大致相同,并且有许多图像可供您使用。
Here are some key benefits:
以下是一些主要好处:
- No installation after container start-up 容器启动后未安装
- Portability across environments 跨环境的可移植性
- Easy to start, stop, and update 易于启动,停止和更新
- Services are isolated for better security 隔离服务以提高安全性
Kubernetes上SQL数据库的要求 (Requirements for SQL databases on Kubernetes)
When you want to run a stateful component, such as SQL Server, in Kubernetes, there are several components that you need to be aware of. These components enable you to run your databases without fear of losing data should a container fail.
当您想在Kubernetes中运行有状态组件(例如SQL Server)时,需要注意几个组件。 这些组件使您可以运行数据库,而不必担心容器发生故障时会丢失数据。
有状态集 (Stateful sets)
Stateful sets are API objects that ensure that pods are unique and ordered. When pods are deployed in a StatefulSet, each has a persistent identifier that it retains regardless of rescheduling. This persistent ID enables you to reconnect pods to the correct storage after a pod has failed.
状态集是API对象,可确保pod的唯一性和有序性。 当Pod部署在StatefulSet中时 ,每个Pod都有一个永久标识符,无论重新调度如何,Pod都会保留。 此永久性ID使您可以在Pod发生故障后将Pod重新连接到正确的存储。
持久卷 (Persistent volumes )
Persistent volumes are storage resources in Kubernetes that operate independently of attached pods. These resources can be provisioned statically at configuration or dynamically through Storage Classes. When you use persistent volumes, you create a PersistentVolumeClaim that operates like a pod. You can attach pods to this claim to allow them to use the persistent storage you created.
永久卷是Kubernetes中的存储资源,它们独立于附加的Pod运行。 这些资源可以在配置时静态配置,也可以通过存储类动态配置。 使用永久卷时,将创建一个像Pod一样运行的PersistentVolumeClaim 。 您可以将吊舱附加到此声明,以允许它们使用您创建的永久性存储。
There are several different storage types you can use as persistent volumes, including Google Cloud Engine persistent disks, AWS EBS volumes, Azure Disks, and Azure Files. You can learn more in this article about building an ASP.NET app with Azure SQL Database.
您可以将几种不同的存储类型用作永久性卷,包括Google Cloud Engine永久性磁盘,AWS EBS卷,Azure磁盘和Azure文件。 您可以在本文中了解有关使用Azure SQL数据库构建ASP.NET应用程序的更多信息。
Below you can see a diagram that outlines how these components are deployed for a SQL database on Kubernetes in a single cluster:
在下面可以看到一个示意图,概述了如何在单个集群中的Kubernetes上为SQL数据库部署这些组件:
在Kubernetes中部署SQL数据库的关键注意事项和提示 (Key Considerations and Tips for Deploying SQL Databases in Kubernetes )
When you’re thinking about deploying a SQL database on Kubernetes, there are a few considerations you should keep in mind. Kubernetes is challenging to operate even with relatively simple workloads, so you should make sure that it can provide the implementation that you need first. Additionally, once you’ve determined that k8s is the right option for you, you can apply the tips below.
当您考虑在Kubernetes上部署SQL数据库时,应牢记一些注意事项。 即使在工作负载相对简单的情况下,Kubernetes仍具有挑战性,因此您应确保它可以首先提供所需的实现。 此外,一旦确定k8s是适合您的选项,就可以应用以下提示。
注意事项 (Considerations)
The most important consideration to keep in mind is that Kubernetes was designed primarily for stateless workloads. While it can support stateful workloads, this requires extra work and diligence.
要记住的最重要的考虑因素是Kubernetes主要是为无状态工作负载设计的。 虽然它可以支持有状态的工作负载,但这需要额外的工作和勤奋。
For example, when it comes time to upgrade Kubernetes, you likely need to take extra steps to backup your persistent volumes in case something goes wrong. This is because, unlike with stateless applications, you can’t just redeploy a clean container image.
例如,当需要升级Kubernetes时 ,您可能需要采取额外的步骤来备份持久卷,以防出现问题。 这是因为,与无状态应用程序不同,您不能只是重新部署干净的容器映像。
Another consideration is that any database deployed on k8s has a high chance of database application restarts and failovers. This is because pods are transient and are designed to be killed and restarted whenever issues arise.
另一个考虑因素是,部署在k8s上的任何数据库都有很大的机会重新启动数据库应用程序并进行故障转移。 这是因为Pod是瞬态的,旨在在出现问题时被杀死并重新启动。
In general, this type of deployment is primarily useful for local application development and testing. In these situations, persistent storage is generally not a concern, as opposed to production environments.
通常,这种类型的部署主要用于本地应用程序开发和测试。 在这些情况下,与生产环境相反,持久性存储通常不是问题。
提示 (Tips)
When setting up your database deployment, it’s a good idea to start with a test database and pilot it extensively. You need to see how it operates with development and QA workloads and ensure that your storage configurations are correct. This means checking load balancing, ID persistence, and maintenance of persistent volumes.
在设置数据库部署时,最好从测试数据库开始并进行广泛试验。 您需要查看它如何在开发和QA工作负载下运行,并确保您的存储配置正确。 这意味着检查负载平衡 ,ID持久性和持久卷的维护。
Additionally, take time to make sure that you understand what replication modes are enabled between your components. While synchronous modes require more resources, asynchronous modes can lead to data loss if a pod dies before data is replicated.
此外,请花一些时间来确保您了解组件之间启用了哪些复制模式。 尽管同步模式需要更多资源,但如果在复制数据之前将容器吊销,则异步模式可能会导致数据丢失。
You can also use operators to wrap your SQL database on Kubernetes with more accessible features. Operators are methods of packaging Kubernetes that enable you to more easily manage and monitor stateful applications. There are many operators already available, such as the SQL Server Operator released with the preview of SQL Server 2019. You can also create your operators with the help of the coreOS’ Operator Framework.
您还可以使用运算符将SQL数据库包装在具有更多可访问功能的Kubernetes上。 运算符是打包Kubernetes的方法,使您可以更轻松地管理和监视有状态的应用程序。 已经有许多运算符可用,例如随SQL Server 2019预览版一起发布SQL Server运算符。您还可以在coreOS的运算符框架的帮助下创建运算符。
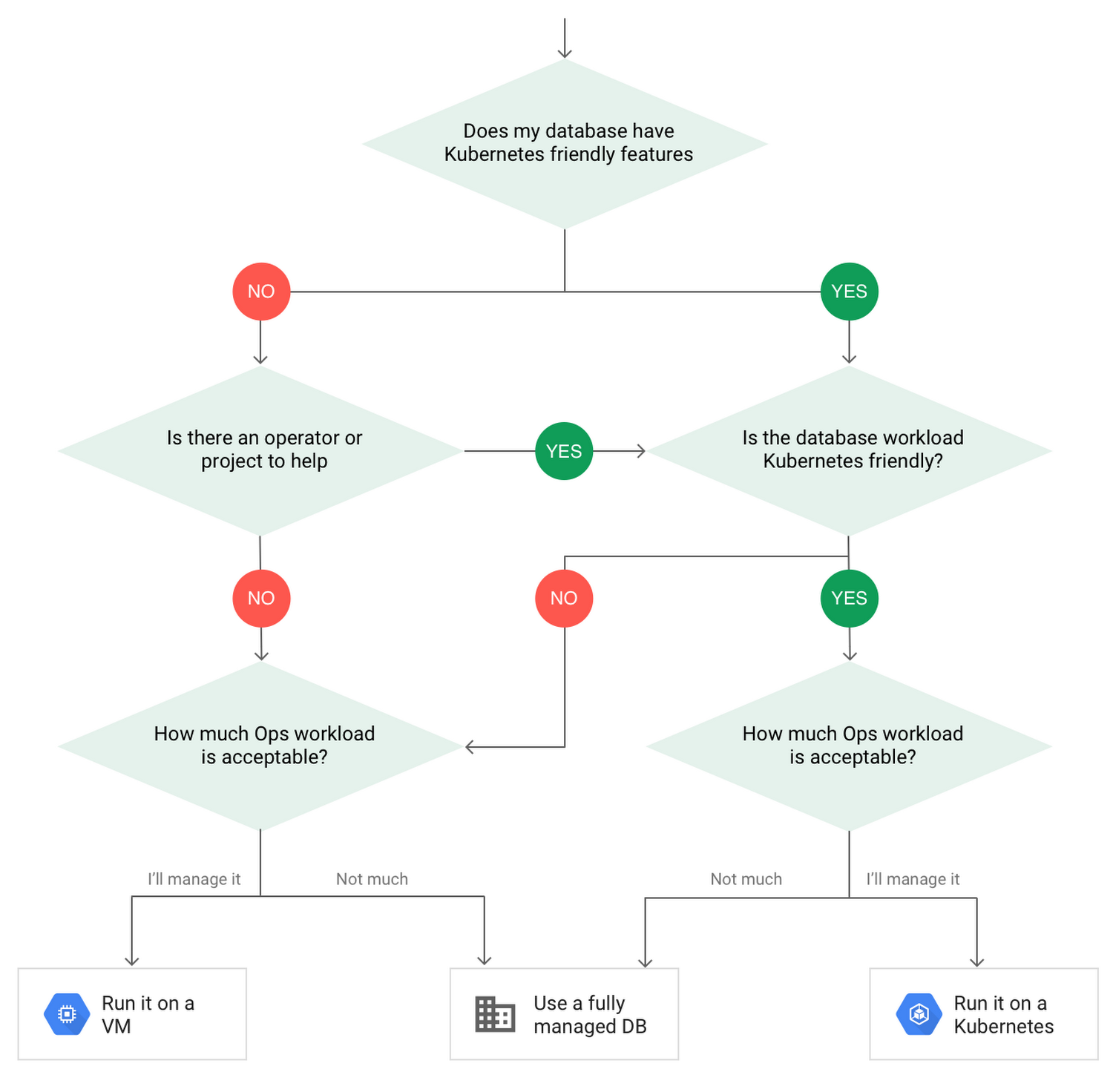
If you still aren’t sure whether deploying to Kubernetes is right for you, consider the following decision tree:
如果仍然不确定是否适合部署到Kubernetes,请考虑以下决策树:
教程:如何在Kubernetes上部署MySQL (Tutorial: How to Deploy MySQL on Kubernetes)
Below is a brief walkthrough that explains how to set up a MySQL database on Kubernetes. This tutorial is abbreviated from the Kubernetes documentation found here.
下面是一个简短的演练,解释了如何在Kubernetes上设置MySQL数据库。 本教程是从此处找到的Kubernetes文档的缩写。
Prerequisites
先决条件
Before you can get started you need to have:
在开始之前,您需要具备以下条件:
- A configured Kubernetes cluster 配置的Kubernetes集群
- The kubectl command-line tool kubectl命令行工具
- Either a dynamic or statically provisioned PersistentVolumeClaim 动态或静态设置的PersistentVolumeClaim
- A database image 数据库映像
在Kubernetes上部署MySQL数据库 (Deploy your MySQL database on Kubernetes)
To start, you need to create two YAML files, assuming you are statically defining your persistent volume. One should define your deployment, including the image you’re using, your credentials, and your persistent volume names and paths (see an example from the Kubernetes documentation). The other defines your PersistentVolume (PV) and PersistentVolumeClaim (PVC), including storage capacity, access modes, and path (see an example)
首先,假设您正在静态定义持久卷,则需要创建两个YAML文件。 应该定义您的部署,包括您正在使用的映像,您的凭据以及您的持久卷名称和路径( 请参阅 Kubernetes文档中的示例 )。 另一个定义您的PersistentVolume (PV)和PersistentVolumeClaim (PVC),包括存储容量,访问模式和路径( 请参阅示例 )
Once your files are defined, you are ready to deploy them. Deploy your PV and PVC definitions first, followed by your deployment definition. You can do this by using:
定义文件后,就可以部署它们了。 首先部署您的PV和PVC定义,然后再部署您的部署定义。 您可以使用以下方法做到这一点:
kubectl apply -f {file source}
kubectl apply -f {文件源}
After this is done, you need to verify that the deployment went as expected. You can do this by checking the deployment specs:
完成此操作后,您需要验证部署是否按预期进行。 您可以通过检查部署规范来做到这一点:
kubectl describe deployment mysql
kubectl描述部署mysql
Checking the pods that were created:
检查已创建的吊舱:
kubectl get pods -l app=mysql
kubectl get pods -l app = mysql
And inspecting your PersistentVolumeClaim:
并检查您的PersistentVolumeClaim:
kubectl describe pvc mysql-pv-claim
kubectl描述pvc mysql-pv-claim
- Assuming that everything looks correct, your database is deployed and ready for use 假设一切看起来正确,则数据库已部署并可以使用
How can you access your new MySQL instance?
如何访问新MySQL实例?
The YAML files we showed in the previous section creates a service that let Pods in the cluster access the MySQL database. We are using Service option clusterIP: None to ensure the Service DNS name resolve to Pod’s IP address. This is because, in our example, there is only one Pod behind the database service.
我们在上一节中显示的YAML文件创建了一项服务,该服务使群集中的Pod可以访问MySQL数据库。 我们正在使用服务选项clusterIP:无,以确保服务DNS名称解析为Pod的IP地址。 这是因为在我们的示例中,数据库服务后面只有一个Pod。
Here is how to run a MySQL client and connect to your MySQL instance running on Kubernetes:
这是运行MySQL客户端并连接到在Kubernetes上运行MySQL实例的方法:
kubectl run -it –rm –image=mysql:5.6 –restart=Never mysql-client — mysql -h mysql -ppassword
kubectl运行-it –rm –image = mysql:5.6 –restart =从不mysql-client — mysql -h mysql -ppassword
This creates a new Pod running a MySQL client and connects to the server using the Service, with direct DNS resolution.
这将创建一个运行MySQL客户端的新Pod,并使用服务通过DNS直接解析连接到服务器。
If the connection is successful, you should see a MySQL command prompt, like this:
如果连接成功,您应该看到一个MySQL命令提示符,如下所示:
mysql>
mysql>
How can you delete your MySQL instance?
如何删除MySQL实例?
Use the following commands to delete the objects you deployed as per the instructions above:
使用以下命令按照上述说明删除您部署的对象:
kubectl delete deployment,svc mysql
kubectl delete pvc mysql-pv-claim
kubectl delete pv mysql-pv-volume
kubectl删除部署,svc mysql
kubectl删除pvc mysql-pv-claim
kubectl删除pv mysql-pv-volume
Please note that if you manually provisioned a PersistentVolume, it needs to be deleted as well. However, if you dynamically provisioned the volume, it will be deleted together with the PersistentVolumeClaim.
请注意,如果您手动设置了PersistentVolume,则也需要将其删除。 但是,如果您动态配置该卷,它将与PersistentVolumeClaim一起删除。
结论 (Conclusion)
SQL database infrastructure containerization is not necessarily different from building and deploying any other mission-critical database. However, you need to consider the implications of moving mission-critical data to Kubernetes and containers. Databases on Kubernetes do not include concepts like failover elections, replication, and sharding like in MongoDB or Cassandra. You should put the right level of management and monitoring in place if you want to use Kubernetes and containers for production databases.
SQL数据库基础结构容器化与构建和部署任何其他任务关键型数据库不一定相同。 但是,您需要考虑将关键任务数据移至Kubernetes和容器的含义。 Kubernetes上的数据库不像MongoDB或Cassandra那样包含诸如故障转移选举,复制和分片之类的概念。 如果要将Kubernetes和容器用于生产数据库,则应该进行适当级别的管理和监视。
翻译自: https://www.sqlshack.com/sql-database-on-kubernetes-considerations-and-best-practices/















 2080
2080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









