





 本文介绍了如何收集SQL Server索引的结构信息、碎片信息和使用信息。通过数据库管理视图、系统存储过程和动态管理视图等方法,监控索引的性能,包括扫描、查找、更新和碎片率,以优化数据库性能。
本文介绍了如何收集SQL Server索引的结构信息、碎片信息和使用信息。通过数据库管理视图、系统存储过程和动态管理视图等方法,监控索引的性能,包括扫描、查找、更新和碎片率,以优化数据库性能。
In the previous articles of this series (see the full article TOC at bottom), we discussed the internal structure of both the SQL Server tables and indexes, the best practices that you can follow in order to design a proper index, list of operations that you can perform on the SQL Server indexes, how to design effective Clustered and Non-clustered indexes, the different types of SQL Server indexes, above and beyond Clustered and Non-clustered indexes classification and finally how to tune the performance of the bad queries using the different types of SQL Server Indexes. In this article, we will discuss how to gather statistical information about the index structure and the index usage information.
在本系列的前几篇文章中(请参阅底部的完整文章TOC),我们讨论了SQL Server表和索引的内部结构,可以用来设计适当索引的最佳实践,可操作的操作列表。您可以对SQL Server索引执行以下操作:如何设计有效的聚集索引和非聚集索引,不同类型SQL Server索引,超出聚集索引和非聚集索引分类的范围以及最终如何使用以下方法调整错误查询的性能不同类型SQL Server索引。 在本文中,我们将讨论如何收集有关索引结构和索引使用信息的统计信息。
For this point in this series, we are familiar on the SQL Server Index structure and how to design and create the most suitable index, that the SQL Server Query Optimizer will definitely take benefits from, in speeding up the performance of our queries. After creating the indexes, we should proactively know which indexes are badly used, or totally unused in order to perform the correct decision to maintain these indexes or replace it with more efficient ones. Recall that removing the unused indexes or badly indexes will improve the performance of the data modification queries, that needs to replicate the same table change to the indexes, and reduce the index maintaining and storing overhead.
对于本系列中的这一点,我们熟悉SQL Server索引结构以及如何设计和创建最合适的索引,SQL Server Query Optimizer肯定会从中受益,从而加快了查询性能。 创建索引之后,我们应该主动知道哪些索引使用不当或完全未使用,以便执行正确的决定来维护这些索引或将其替换为更有效的索引。 回想一下,删除未使用的索引或不良索引将提高数据修改查询的性能,该数据修改查询需要将相同的表更改复制到索引,并减少索引的维护和存储开销。
索引结构信息 (Index structure information)
The first category of information that we need to gather about the indexes is the list of available indexes in our database, the list of columns participating in each index and the properties of these indexes. The classical way of gathering such information about the indexes is expanding the Indexes node under the database tables, then right-clicking on each index, and choose the Properties option as shown below:
我们需要收集的有关索引的第一类信息是数据库中可用索引的列表,参与每个索引的列的列表以及这些索引的属性。 收集有关索引的此类信息的经典方法是展开数据库表下的Indexes节点,然后右键单击每个索引,然后选择Properties选项,如下所示:
Where you can browse the list of columns participating in the index key and different properties of the selected index. The problem with gathering the indexes information using the UI method is that you need to browse it one index at a time per each table. You can imagine the effort required to check all indexes in a specific database. The list of properties of a selected index can be shown below:
您可以在其中浏览参与索引键的列的列表以及所选索引的不同属性。 使用UI方法收集索引信息的问题在于,您需要在每个表中一次浏览一次索引。 您可以想象检查特定数据库中所有索引所需的工作。 所选索引的属性列表如下所示:
The second way of gathering metadata about the index structure is the sp_helpindex system stored procedure, by providing the name of the table that you need to list its indexes. In order to gather information about all indexes in a specific database, you need to execute the sp_helpindex number of time equal to the number of tables in your database. For the previously created database that has three tables, we need to execute the sp_helpindex three times as shown below:
收集有关索引结构的元数据的第二种方法是sp_helpindex系统存储过程,方法是提供需要列出其索引的表的名称。 为了收集有关特定数据库中所有索引的信息,您需要执行等于数据库中表数量的sp_helpindex时间。 对于以前创建的具有三个表的数据库,我们需要执行三次sp_helpindex,如下所示:
sp_helpindex '[dbo].[STD_Evaluation]'
GO
sp_helpindex '[dbo].[Courses]'
GO
sp_helpindex '[dbo].[STD_Info]'
The name of the index, the columns that participate in the index key and description of that index, such as index type, will be returned from the sp_helpindex system stored procedure, as shown in the result below:
索引名称,参与索引键的列以及该索引的描述(例如索引类型)将从sp_helpindex系统存储过程中返回,如以下结果所示:
The main disadvantage of using the sp_helpindex system stored procedure to retrieve the indexes information of a specific database is that you need to execute it per each table, as mentioned previously. In addition, the sp_helpindex system stored procedure returns only the key columns that are participating in the index key. You can see that the columns that are added using the INCLUDE clause as non-key columns will not be listed using that stored procedure.
使用sp_helpindex系统存储过程来检索特定数据库的索引信息的主要缺点是,如前所述,您需要针对每个表执行该信息。 此外,sp_helpindex系统存储过程仅返回参与索引键的键列。 您可以看到,使用INCLUDE子句作为非关键列添加的列不会使用该存储过程列出。
The third way, and the best for me, to gather metadata information about the index structure is querying the sys.indexes system dynamic management view. The sys.indexes contains one row per each index in the table or view. It is recommended to join sys.indexes DMV with other systems DMVs , such as the sys.index_columns, sys.columns and sys.tables in order to return meaningful information about these indexes. A good example of using the sys.indexes DMV, that needs to be executed once per each database, is shown below:
收集关于索引结构的元数据信息的第三种方法(也是我的最佳选择)是查询sys.indexes系统动态管理视图。 sys.indexes表或视图中的每个索引包含一行。 建议将sys.indexes DMV与其他系统DMV(例如sys.index_columns,sys.columns和sys.tables)结合在一起,以返回有关这些索引的有意义的信息。 下面显示了一个使用sys.indexes DMV的好例子,该例子需要每个数据库执行一次:
SELECT Tab.name Table_Name
,IX.name Index_Name
,IX.type_desc Index_Type
,Col.name Index_Column_Name
,IXC.is_included_column Is_Included_Column
FROM sys.indexes IX
INNER JOIN sys.index_columns IXC ON IX.object_id = IXC.object_id AND IX.index_id = IXC.index_id
INNER JOIN sys.columns Col ON IX.object_id = Col.object_id AND IXC.column_id = Col.column_id
INNER JOIN sys.tables Tab ON IX.object_id = Tab.object_id
The result of the previous query, that includes the table name, the index name, the type of the index and finally the name and the type of key and non-key columns participating in these indexes, will be as shown below:
上一个查询的结果,包括表名,索引名,索引的类型,最后是参与这些索引的键和非键列的名称和类型,如下所示:
The previous query can be rewritten, to list more properties of the indexes, as below:
可以重写先前的查询,以列出索引的更多属性,如下所示:
SELECT Tab.name Table_Name
,IX.name Index_Name
,IX.type_desc Index_Type
,Col.name Index_Column_Name
,IXC.is_included_column Is_Included_Column
,IX.fill_factor
,IX.is_disabled
,IX.is_primary_key
,IX.is_unique
FROM sys.indexes IX
INNER JOIN sys.index_columns IXC ON IX.object_id = IXC.object_id AND IX.index_id = IXC.index_id
INNER JOIN sys.columns Col ON IX.object_id = Col.object_id AND IXC.column_id = Col.column_id
INNER JOIN sys.tables Tab ON IX.object_id = Tab.object_id
And the result that contains the extra index properties is shown below:
包含额外索引属性的结果如下所示:
索引碎片信息 (Index fragmentation information)
The main target of creating an SQL Server index is speeding up the data retrieval performance and enhance the overall performance of the queries. But when the underlying table data is changed or deleted, this change should be replicated to the related table indexes. Over time, and as a result of many inserting, updating, deleting operations, the index will become fragmented, with a large number of unordered pages with free space in these pages, degrading the performance of the queries, due to increasing the number of pages to be scanned in order to retrieve the requested data. As a result, the index could be ignored in most cases by the SQL Server Query Optimizer. Another cause of the fragmentation problem is the page splitting, in which the page will be split into two pages when the inserted or newly updated values do not fit the available space in the page, due to wrong setting of the Fill Factor and pad_index index creation options, mentioned in detail in the previous articles of this series.
创建SQL Server索引的主要目标是加快数据检索性能并增强查询的整体性能。 但是,当更改或删除基础表数据时,应将此更改复制到相关的表索引中。 随着时间的流逝,由于许多插入,更新,删除操作的结果,索引将变得碎片化,其中大量无序页面具有这些页面中的可用空间,由于增加了页面数,因此降低了查询性能进行扫描以检索请求的数据。 结果,在大多数情况下,SQL Server查询优化器可以忽略该索引。 导致碎片问题的另一个原因是页面拆分,其中由于填充因子设置错误和pad_index索引创建错误,当插入的值或新更新的值不适合页面中的可用空间时,会将页面拆分为两页选项,在本系列以前的文章中有详细介绍。
The straight-forward way of getting the fragmentation percentage of an index is from the Fragmentation tab of the index Properties window. For the newly created index, the fragmentation level will be 0%, as shown in the Index Properties window below:
获取索引碎片百分比的直接方法是从“索引属性”窗口的“ 碎片”选项卡中。 对于新创建的索引,碎片级别将为0%,如下面的“索引属性”窗口所示:
If we try to fill the previously created tables with extra 1K records, using APEXSQL Generate tool, as shown in the snapshot below:
如果我们尝试使用APEXSQL Generate工具用额外的1K记录填充先前创建的表,如下面的快照所示:
And check the fragmentation percentage of the same index again, you will see that the index became highly fragmented, due to the inserting operation, with fragmentation percentage equal to 99%, as shown in the Index Properties window below:
再次检查同一索引的碎片百分比,您将发现由于插入操作,索引变得高度碎片化,碎片百分比等于99%,如下面的“索引属性”窗口所示:
Checking the fragmentation percentage of all indexes in a specific database, using the UI method requires a big effort, as you need to check one index at a time. Another way to gather the fragmentation percentage information about all database indexes at one shot is by querying the sys.dm_db_index_physical_stats dynamic management function, that is Introduced the first time in SQL Server 2005. The sys.dm_db_index_physical_stats DMF can be joined with the sys.indexes DMV to return the fragmentation percentage of all indexes under the specified database, as in the query shown below:
使用UI方法检查特定数据库中所有索引的碎片百分比需要花费很大的精力,因为您需要一次检查一个索引。 一次收集有关所有数据库索引的碎片百分比信息的另一种方法是查询sys.dm_db_index_physical_stats动态管理功能,这是SQL Server 2005中首次引入。sys.dm_db_index_physical_stats DMF可以与sys.indexes联接。 DMV返回指定数据库下所有索引的碎片百分比,如下所示:
SELECT OBJECT_NAME(IDX.OBJECT_ID) AS Table_Name,
IDX.name AS Index_Name,
IDXPS.index_type_desc AS Index_Type,
IDXPS.avg_fragmentation_in_percent Fragmentation_Percentage
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) IDXPS
INNER JOIN sys.indexes IDX ON IDX.object_id = IDXPS.object_id
AND IDX.index_id = IDXPS.index_id
ORDER BY Fragmentation_Percentage DESC
The result in our case will be as shown below:
在本例中,结果将如下所示:
To overcome this issue, we should perform the proper index maintenance operation, with the optimal FillFactor and Pad_index value. In this article, we will stop at the point of gathering the index fragmentation information. In the next article of this series, we will see how to fix the index fragmentation issue.
为了克服这个问题,我们应该使用最佳的FillFactor和Pad_index值执行正确的索引维护操作。 在本文中,我们将停止收集索引碎片信息。 在本系列的下一篇文章中,我们将看到如何解决索引碎片问题。
索引使用信息 (Index usage information)
SQL Server allows us to create up to 999 Non-clustered indexes and one Clustered indexes per each table. This huge number of allowed, but not recommended, indexes help us in covering and enhancing the performance of a large number of queries that try to retrieve data from the database table. The drawbacks of having too many indexes in the table include slowing down the data modification operations, due to the fact that all changes performed on the table should be replicated to the related indexes. In addition, this large number of indexes require extra storage and should be all maintained, although some of these indexes are not used, hurting the overall performance, instead of the expected enhancement from it.
SQL Server允许我们每个表最多创建999个非聚集索引和一个聚集索引。 大量允许但不建议使用的索引可帮助我们覆盖和增强大量尝试从数据库表中检索数据的查询的性能。 由于在表上执行的所有更改都应复制到相关索引,因此表中索引过多的缺点包括减慢了数据修改操作的速度。 此外,尽管没有使用这些索引中的某些索引,但大量索引需要额外的存储并且应该全部维护,这会损害整体性能,而不是预期的增强性能。
So that, it becomes the main task for the database administrator to regularly monitor the usage of these indexes, to identify the indexes that are badly used, or not used, and drop it or replace it with more optimal ones if required. The indexes that are badly used include the ones that have a large number of write with few numbers of reads and a large number of scans with few numbers of seeks.
因此,这成为数据库管理员的主要任务,即定期监视这些索引的使用情况,识别使用不当或未使用的索引,并在需要时将其删除或替换为最佳索引。 索引使用不当的索引包括写入次数多,读取次数少,扫描次数多,寻道次数少的索引。
SQL Server keeps the information about the index usage statistics automatically in the system tables and flushes that data when the SQL Server service is restarted. To access these system tables, SQL Server provides us with the sys.dm_db_index_usage_stats dynamic management view, that helps in tracking the usage of the database indexes since the last SQL Server service restart.
SQL Server自动在系统表中保留有关索引使用情况统计信息,并在重新启动SQL Server服务时刷新该数据。 为了访问这些系统表,SQL Server为我们提供了sys.dm_db_index_usage_stats动态管理视图,该视图有助于跟踪自上一次SQL Server服务重新启动以来数据库索引的使用情况。
The T-SQL script below uses the sys.dm_db_index_usage_stats DMV, along with other system catalog views, to return a meaningful and useful cumulative information about each index and its usage since the last restart. This information includes the name of the table, on which the index is created, the name and type of that index, the size of the index, the number of seeks, scans, lookups and updates performs on the index and finally the last seeks, scans, lookups and updates date, as shown below:
下面的T-SQL脚本使用sys.dm_db_index_usage_stats DMV以及其他系统目录视图,以返回有关自上次重新启动以来每个索引及其用法的有意义且有用的累积信息。 这些信息包括在其上创建索引的表的名称,该索引的名称和类型,索引的大小,对该索引执行的查找,扫描,查找和更新的次数,最后是最后一个查找,扫描,查找和更新日期,如下所示:
SELECT OBJECT_NAME(IX.OBJECT_ID) Table_Name
,IX.name AS Index_Name
,IX.type_desc Index_Type
,SUM(PS.[used_page_count]) * 8 IndexSizeKB
,IXUS.user_seeks AS NumOfSeeks
,IXUS.user_scans AS NumOfScans
,IXUS.user_lookups AS NumOfLookups
,IXUS.user_updates AS NumOfUpdates
,IXUS.last_user_seek AS LastSeek
,IXUS.last_user_scan AS LastScan
,IXUS.last_user_lookup AS LastLookup
,IXUS.last_user_update AS LastUpdate
FROM sys.indexes IX
INNER JOIN sys.dm_db_index_usage_stats IXUS ON IXUS.index_id = IX.index_id AND IXUS.OBJECT_ID = IX.OBJECT_ID
INNER JOIN sys.dm_db_partition_stats PS on PS.object_id=IX.object_id
WHERE OBJECTPROPERTY(IX.OBJECT_ID,'IsUserTable') = 1
GROUP BY OBJECT_NAME(IX.OBJECT_ID) ,IX.name ,IX.type_desc ,IXUS.user_seeks ,IXUS.user_scans ,IXUS.user_lookups,IXUS.user_updates ,IXUS.last_user_seek ,IXUS.last_user_scan ,IXUS.last_user_lookup ,IXUS.last_user_update
The number of Seeks indicates the number of times the index is used to find a specific row, the number of Scans shows the number of times the leaf pages of the index are scanned, the number of Lookups indicates the number of times a Clustered index is used by the Non-clustered index to fetch the full row and the number of Updates shows the number of times the index data is modified. The result in our case will be like the below:
“ 搜索次数”指示使用索引查找特定行的次数,“ 扫描次数”显示索引索引的叶页被扫描的次数,“ 查找次数”指示“聚簇索引”为的次数。非聚集索引使用它来获取整行, 更新次数显示了索引数据被修改的次数。 在我们的案例中,结果将如下所示:

The previous result can be analyzed as follows:
先前的结果可以分析如下:
- zero values mean that the table is 零值表示not used, or the SQL Server service 未使用该表,或者SQL Server服务最近restarted recently. 重新启动 。
- zero or 零 , small number of seeks, scans or lookups and 少量搜索,扫描或查找以及large number of updates is a useless index and should be 大量更新的索引是无用的索引,应在与系统所有者确认后将其removed, after verifying with the system owner, as the main purpose of adding the index is speeding up the read operations. 删除 ,因为添加索引的主要目的是加快读取操作。
- heavily with 零或zero or 很少的寻道数进行small number of seeks means that the index is 大量扫描的索引意味着该索引使用badly used and should be replaced with more optimal one. 不佳 ,应替换为更优的索引。
- large number of Lookups means that we need to 大量查找的索引意味着我们需要通过使用INCLUDE子句将经常查找的列添加到现有索引非键列中来optimize the index by adding the frequently looked up columns to the existing index non-key columns using the INCLUDE clause. 优化索引。
- large number of Scans indicates that SELECT * queries are heavily used, retrieving more columns than what is required, or the index statistics should be updated. 大量 “扫描”的表表明SELECT *查询被大量使用,检索的列多于所需的列,或者应更新索引统计信息。
- large number of Scans means that a new Non-clustered index should be created to cover a non-covered query. 大量扫描的聚簇索引意味着应该创建一个新的非聚簇索引来覆盖一个非覆盖查询。
- Dates with NULL values mean that this action has not occurred yet. 具有NULL值的日期表示此操作尚未发生。
- Large scans are OK in small tables. 在小表中进行大扫描是可以的。
- Your index is not here, then no action is performed on that index yet. 您的索引不在此处,因此尚未对该索引执行任何操作。
The previous readings give you good indications about the database indexes usage, but you need to dig deeper before deciding to remove or replace an index. You can use the previous results in conjunction with the result of the sys.dm_db_index_physical_stats dynamic management function to have a full view of the index usage. The sys.dm_db_index_physical_stats DMF returns information about the lower-level I/O activities, such as INSERT, UPDATE and DELETE operations, occurred on that index, per each table partition.
以前的阅读材料为您提供了有关数据库索引使用情况的良好指示,但是在决定删除或替换索引之前,您需要深入研究。 您可以将先前的结果与sys.dm_db_index_physical_stats动态管理功能的结果结合使用,以全面了解索引的使用情况。 对于每个表分区,sys.dm_db_index_physical_stats DMF返回有关该索引上发生的较低级I / O活动的信息,例如INSERT,UPDATE和DELETE操作。
The sys.dm_db_index_physical_stats DMF takes the database_id, the object_id, the index_id and the partition_number as parameters. Providing NULL or DEFAULT values to the sys.dm_db_index_physical_stats DMF will return a row for each partition in the database. Similar to all other DMOs, the sys.dm_db_index_physical_stats DMF returns cumulative data that will be refreshed when the SQL Server service is restarted. Rebuilding, reorganizing or disabling the index will not affect its statistics. An index will have an entry in the sys.dm_db_index_physical_stats DMF only if the metadata cache object that represents this index is available.
sys.dm_db_index_physical_stats DMF将database_id,object_id,index_id和partition_number作为参数。 向sys.dm_db_index_physical_stats DMF提供NULL或DEFAULT值将为数据库中的每个分区返回一行。 与所有其他DMO相似,sys.dm_db_index_physical_stats DMF返回的累积数据将在重新启动SQL Server服务后刷新。 重建,重组或禁用索引不会影响其统计信息。 仅当表示该索引的元数据缓存对象可用时,索引才会在sys.dm_db_index_physical_stats DMF中具有一个条目。
The below T-SQL script can be used to query the sys.dm_db_index_physical_stats DMF, joined with other DMOs to get more meaningful information, can be used to retrieve the I/O operations statistics for each index on the current database. This information includes the name of the table on which the index is created, the name and size of the index and finally the number of INSERT, UPDATE and DELETE operations occurred on these indexes. The script will be as shown below:
下面的T-SQL脚本可用于查询sys.dm_db_index_physical_stats DMF,并与其他DMO结合使用以获得更有意义的信息,可用于检索当前数据库上每个索引的I / O操作统计信息。 该信息包括在其上创建索引的表的名称,索引的名称和大小以及最后在这些索引上发生的INSERT,UPDATE和DELETE操作的数量。 该脚本将如下所示:
SELECT OBJECT_NAME(IXOS.OBJECT_ID) Table_Name
,IX.name Index_Name
,IX.type_desc Index_Type
,SUM(PS.[used_page_count]) * 8 IndexSizeKB
,IXOS.LEAF_INSERT_COUNT NumOfInserts
,IXOS.LEAF_UPDATE_COUNT NumOfupdates
,IXOS.LEAF_DELETE_COUNT NumOfDeletes
FROM SYS.DM_DB_INDEX_OPERATIONAL_STATS (NULL,NULL,NULL,NULL ) IXOS
INNER JOIN SYS.INDEXES AS IX ON IX.OBJECT_ID = IXOS.OBJECT_ID AND IX.INDEX_ID = IXOS.INDEX_ID
INNER JOIN sys.dm_db_partition_stats PS on PS.object_id=IX.object_id
WHERE OBJECTPROPERTY(IX.[OBJECT_ID],'IsUserTable') = 1
GROUP BY OBJECT_NAME(IXOS.OBJECT_ID), IX.name, IX.type_desc,IXOS.LEAF_INSERT_COUNT, IXOS.LEAF_UPDATE_COUNT,IXOS.LEAF_DELETE_COUNT
The result in our case will be like:
在我们的案例中,结果将是:
The previous result provides us with more detailed information about the number of data inserting and modification operations occurred on each index. This result, in conjunction with the sys.dm_db_index_usage_stats DMV result helps to decide if we need to remove that index or replace it with more optimal one.
先前的结果为我们提供了有关每个索引上发生的数据插入和修改操作数量的更详细信息。 该结果与sys.dm_db_index_usage_stats DMV结果一起有助于确定我们是否需要删除该索引或将其替换为最佳索引。
SQL标准报告 (SQL standard reports)
SQL Server provides us with two built-in reports that help us in monitoring the database indexes fragmentation and usage statistics, the Index Usage Statistics and the Index Physical Statistics. These standard reports use the previously described DMOs, and the reports data will be refreshed when the SQL Server service is restarted. Both reports can be viewed by right-clicking on the database, which you need to monitor its indexes, choose Reports -> Standard Reports and select the Index Usage Statistics or Index Physical Statistics report, as shown below:
SQL Server为我们提供了两个内置报告,它们帮助我们监视数据库索引碎片和使用情况统计信息,即“ 索引使用情况统计信息”和“ 索引物理统计信息” 。 这些标准报表使用前面描述的DMO,并且在重新启动SQL Server服务时将刷新报表数据。 可以通过右键单击数据库来查看这两个报告,您需要监视该数据库的索引,选择“报告” ->“ 标准报告”,然后选择“索引使用情况统计信息”或“索引物理统计信息”报告,如下所示:
The first report is the Index Usage Statistics report, that consists of two parts; the Index Usage Statistics report that shows statistics about the number of Scans, Seeks, Updates and Lookups with the latest date for each operation, that is retrieved by querying the sys.dm_db_index_usage_stats DMV, as shown below:
第一个报告是“ 索引使用情况统计”报告,由两部分组成; 索引使用情况统计报告,其中显示有关每个操作具有最新日期的扫描,查找,更新和查找次数的统计信息,可以通过查询sys.dm_db_index_usage_stats DMV来检索,如下所示:
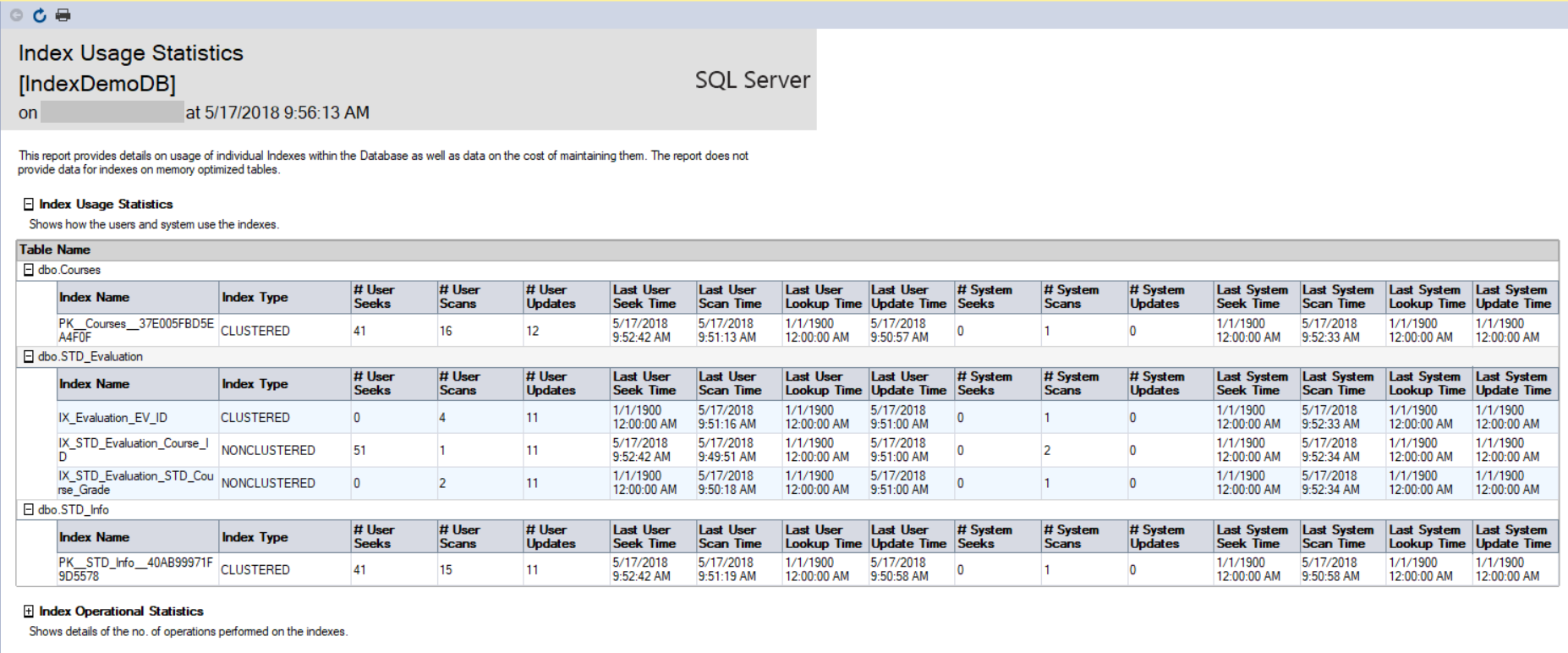
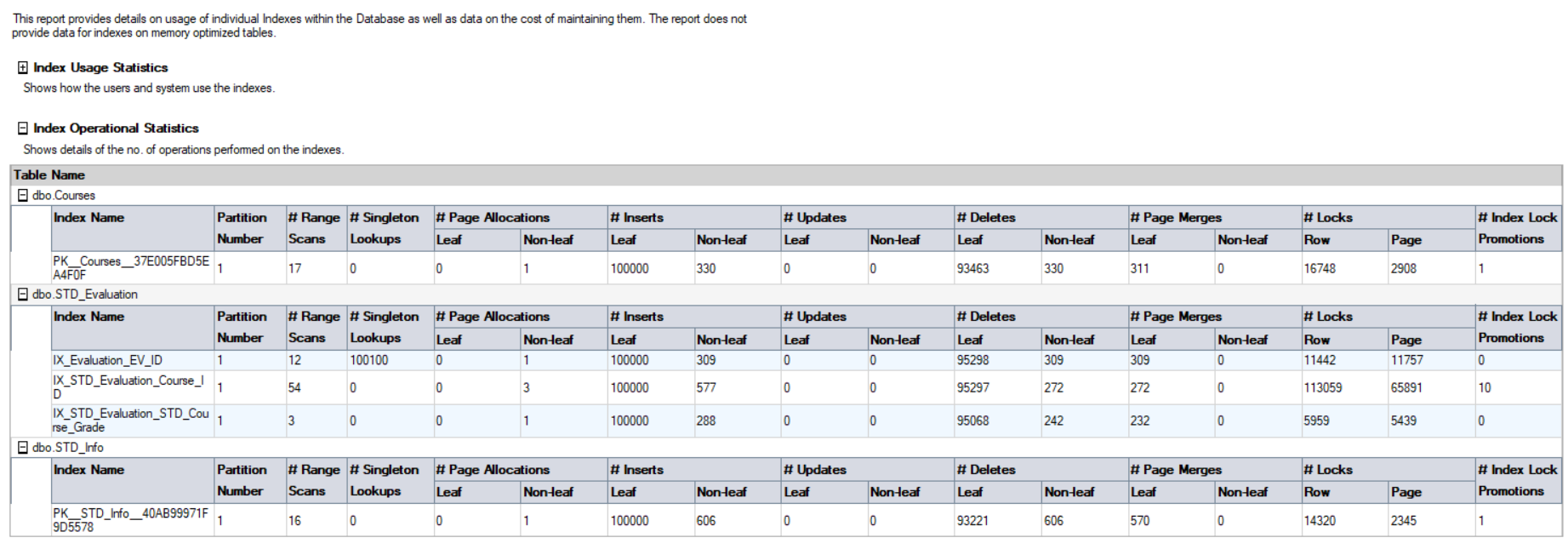
Note that the result in the report differ from the previous DMV result, as the SQL Server service is restarted on my machine and a different workload performed on that database. The second part of that report is the Index Operational Statistics, that returns the number if I/O INSERT, UPDATE and DELETE operations occurred on that database. The statistics in that report are retrieved by querying the sys.dm_db_index_operational_stats(db_id(),null,null,null) DMF, as shown below:
请注意,报告中的结果与以前的DMV结果不同,因为在我的计算机上重新启动了SQL Server服务,并且对该数据库执行了不同的工作负载。 该报告的第二部分是索引操作统计信息,如果该数据库上发生了I / O INSERT,UPDATE和DELETE操作,则返回该数字。 通过查询sys.dm_db_index_operational_stats(db_id(),null,null,null)DMF可以检索该报告中的统计信息,如下所示:
The second report is the Index Physical Statistics report, that returns statistics about the index partitions, fragmentation percentage and the number of pages on each index partition. This report also gives the recommendation to rebuild or reorganize the index depending on the fragmentation percentage of the index. The recommendation provided by that report does not take into consideration the size of the table. If you try to rebuild an index on a small table, you may still receive the same recommendation from that report. The report in our case will be as shown below:
第二个报告是“ 索引物理统计信息”报告,该报告返回有关索引分区,碎片百分比和每个索引分区上的页数的统计信息。 该报告还提出了根据索引的碎片百分比来重建或重组索引的建议。 该报告提供的建议未考虑表格的规模。 如果尝试在小表上重建索引,则可能仍会从该报告中收到相同的建议。 我们的报告如下所示:
In this article, we described the different methods that can be used to gather statistical information about the SQL Server indexes structure and usage. stay tuned for the last article in this series, in which we will describe how to maintain the SQL Server indexes.
在本文中,我们描述了可用于收集有关SQL Server索引结构和使用情况的统计信息的不同方法。 请继续关注本系列的最后一篇文章,其中我们将描述如何维护SQL Server索引。
目录 (Table of contents)
翻译自: https://www.sqlshack.com/gathering-sql-server-indexes-statistics-and-usage-information/















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









