





A SQL Server backup and restore strategy is an essential process to safeguard and protect critical data. The vital role of any DBA is to minimize the risk of data loss and preserve data modifications at regular intervals of time. A well-planned and well-tested backup-and-restore strategy always help to protect the organization with no data loss, or at least a minimum, from the many varieties of system and database failure. As such, it is recommended to understand the importance and implication of the backup-and-restore strategy.
SQL Server备份和还原策略是保护和保护关键数据的重要过程。 任何DBA的至关重要的作用是最大程度地减少数据丢失的风险,并定期维护数据修改。 精心计划和测试的备份和还原策略始终可以帮助保护组织,而不会因多种系统和数据库故障而导致数据丢失,至少没有损失。 因此,建议您了解备份和还原策略的重要性和含义。
In this article the following topics are covered:
本文涵盖以下主题:
- High-level components and concepts of Memory-optimized objects 内存优化对象的高级组件和概念
- Introduction to Backup and Restore Strategies 备份和还原策略简介
- Background of In-Memory OLTP engine 内存中OLTP引擎的背景
- Explain database recovery phases 说明数据库恢复阶段
- Transaction logging 交易记录
- Backup and restore of the memory-optimized database 备份和还原内存优化的数据库
- Piecemeal restore of the memory-optimized database 内存优化数据库的零碎恢复
- And more… 和更多…
介绍 (Introduction)
One should understand the basic business requirements, of an organization, and system internals so that the good backup-and-restore strategy can be defined. OLTP workloads define the state of the data. Data-manipulation and data-transformation operations define the memory and disk requirements for the operation to complete. A good knowledge about the systems and local applications is always a key factor for successful backups. Improper management of backups may lead to a greater risk to database availability.
人们应该了解组织的基本业务需求以及系统内部,以便可以定义良好的备份和还原策略。 OLTP工作负载定义数据的状态。 数据操作和数据转换操作定义了要完成操作的内存和磁盘要求。 熟悉系统和本地应用程序始终是成功备份的关键因素。 备份管理不当可能导致数据库可用性面临更大风险。
In-Memory OLTP engine and storage engines both use the same transaction log and Write-Ahead Logging (WAL) logging mechanism; however, the log record format and algorithms used for In-Memory OLTP logging mechanism is entirely different. It generates log records only at the time of a commit transaction. There is no concept of tracking uncommitted changes and there’s no need to write any undo records to the transaction log. In-Memory OLTP generates logs based on the transaction write-set. All the modifications are combined to form one or very few log records.
内存中的OLTP引擎和存储引擎都使用相同的事务日志和预写日志记录(WAL)日志记录机制; 但是,用于内存中OLTP日志记录机制的日志记录格式和算法完全不同。 它仅在提交事务时生成日志记录。 没有跟踪未提交的更改的概念,也不需要将任何撤消记录写入事务日志。 内存中OLTP根据事务写集生成日志。 所有修改组合在一起形成一个或很少的日志记录。
The SQL Server engine handles the backup-and-recovery of durable memory-optimized databases in a different way than the traditional database backups. As we know, any data held in RAM is volatile and it’s lost when the server reboots or server crashes. However, the In-Memory architecture is engineered to create a backup of the data on the localized disk. As it’s a memory-centric, this adds a new step in the database recovery phase. Memory management is a very important step. If it’s not managed, we’ll end up with out-of-memory issues.
SQL Server引擎以与传统数据库备份不同的方式处理持久性内存优化数据库的备份和恢复。 众所周知,RAM中保存的所有数据都是易失性的,并且在服务器重新启动或服务器崩溃时会丢失。 但是,内存中体系结构经过了工程设计,可以在本地化磁盘上创建数据备份。 由于它是以内存为中心的,因此在数据库恢复阶段增加了新的步骤。 内存管理是非常重要的一步。 如果不加以管理,最终将导致内存不足的问题。
数据库恢复阶段 (Database Recovery Phases)
When SQL Server instances restart, each database goes through different recovery stages.
SQL Server实例重新启动时,每个数据库将经历不同的恢复阶段。
The different phases are:
不同的阶段是:
- Analysis 分析
- Redo 重做
- Undo 撤消
Analysis: In this phase, the transaction log is analyzed to track the information about the last checkpoint and create the Dirty Page Table (DPT); this captures all the dirty-page details. In In-Memory OLTP engine, the analysis phase identifies the checkpoint inventory and prepares the system table with all the log entries and also its processes the associated file allocation log records
分析:在此阶段,将分析事务日志以跟踪有关最后一个检查点的信息并创建脏页表(DPT); 这将捕获所有脏页详细信息。 在内存OLTP引擎中,分析阶段将识别检查点清单,并准备带有所有日志条目的系统表,并处理相关的文件分配日志记录
Redo: This is the roll-forward phase. When this phase completes, the database comes online.
重做:这是前滚阶段。 此阶段完成后,数据库将联机。
Here are the points to ponder:
以下是需要考虑的要点:
- For disk-based tables, the database is moved to the current point-in-time and acquires locks taken by uncommitted transactions. 对于基于磁盘的表,数据库将移至当前时间点并获取未提交的事务获取的锁。
- For memory-optimized tables, data from the data and delta file pairs are loaded into the memory and then update the data with the active transaction-log based on the last durable checkpoint. During this phase, disk and memory-optimized based object recovery run concurrently.
- 对于内存优化表,将数据和增量文件对中的数据加载到内存中,然后基于最后的持久检查点使用活动事务日志更新数据。 在此阶段,基于磁盘和内存优化的对象恢复同时运行。
- In SQL Server 2017, the redo phase of the memory-optimized tables (the associated data and delta files) is done in parallel. This results in faster times for database recovery process. 在SQL Server 2017中,内存优化表(相关数据和增量文件)的重做阶段是并行完成的。 这样可以缩短数据库恢复过程的时间。
- When the above operations are completed for both disk-based and memory-optimized tables, the database becomes online and available for access. 对于基于磁盘的表和针对内存优化的表,完成上述操作后,数据库将变为联机状态并可供访问。
Undo: This is the rollback phase. It holds the list of the active transaction from the analysis phase basically undoing the transactions. This phase is not needed for memory-optimized tables since In-Memory OLTP doesn’t record any uncommitted transactions for memory-optimized tables.
撤消:这是回滚阶段。 它保留了从分析阶段开始基本上撤消交易的活动交易的清单。 对于内存优化表,不需要此阶段,因为内存中OLTP不会记录针对内存优化表的任何未提交的事务。
检查站 (Checkpoint)
A checkpoint is a background process continuously scans the transaction log records and then writes the data and delta files on disk. Writing to the data and delta files is done in an append-only manner by appending newly created rows to the end of the current data file and appending the deleted rows to the corresponding delta file.
检查点是后台进程,它连续扫描事务日志记录,然后将数据和增量文件写入磁盘。 通过将新创建的行附加到当前数据文件的末尾并将删除的行附加到相应的增量文件,以仅附加的方式完成对数据文件和增量文件的写入。
数据和增量文件 (Data and Delta Files)
For persistence, the data for memory-optimized tables are stored in one or more checkpoint file pairs (CFP). The data file(s) store inserted rows and delta file(s) stores the references of deleted rows. The update operation is an insert followed by delete rows. Over time, based on the merge policy, the background checkpoint process merges the CFP’s into a new CFP and older CFP’s go through removal process with a process of garbage collection.
为了持久化,用于内存优化表的数据存储在一个或多个检查点文件对(CFP)中。 数据文件存储插入的行,而增量文件存储删除的行的引用。 更新操作是插入,然后是删除行。 随着时间的流逝,基于合并策略,后台检查点过程会将CFP合并到新的CFP中,而较旧的CFP会通过垃圾回收过程进行删除过程。
入门 (Getting started)
To create a sample Memory optimized database run through the following steps
要创建示例内存优化数据库,请执行以下步骤
- SQLShackInMemDB SQLShackInMemDB
- Map file-stream container to In-Memory file-group 将文件流容器映射到内存中文件组
- SQLShackInMemAuthor SQLShackInMemAuthor
CREATE DATABASE SQLShackInMemDB
GO
ALTER DATABASE SQLShackInMemDB ADD FILEGROUP SQLShackInMemDB_FG CONTAINS MEMORY_OPTIMIZED_DATA
ALTER DATABASE SQLShackInMemDB ADD FILE (name=SQLShackInMemDB_FG, filename='F:\SQLShackInMemDB_FG_Container') TO FILEGROUP SQLShackInMemDB_FG
GO
USE SQLShackInMemDB
GO
CREATE TABLE dbo.SQLShackInMemAuthor (
ID bigint NOT NULL,
Name char (30) NOT NULL,
Address char (8000) NOT NULL,
CONSTRAINT [pk_SQLShackInMemTBL_ID] PRIMARY KEY NONCLUSTERED HASH (ID)
WITH (BUCKET_COUNT = 500000)
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
Though data is stored in memory for memory-optimized objects, SQL Server still needs to data persistence for disaster recovery hence the transactions are scattered across containers
尽管数据存储在内存中以进行内存优化的对象,但是SQL Server仍需要数据持久性以进行灾难恢复,因此事务分散在各个容器中
SELECT state_desc
, file_type_desc
, COUNT(*) AS Cnt
, SUM(file_size_in_bytes) / 1024 / 1024 AS DiskSizeMB
FROM sys.dm_db_xtp_checkpoint_files
GROUP BY state, state_desc, file_type, file_type_desc
ORDER BY state, file_type
The size of the container on disk
磁盘上容器的大小
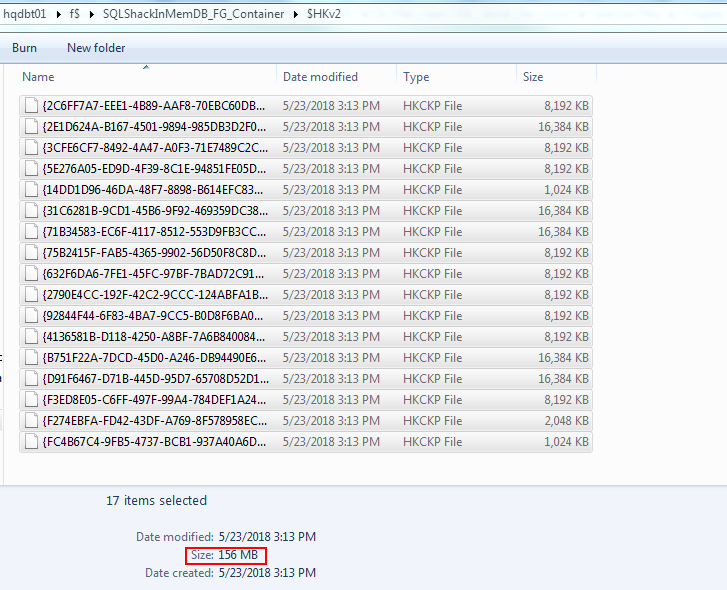
数据库备份操作 (Database backup operations)
Now, let’s backup the SQLShackInMemDB database using the following T-SQL
现在,让我们使用以下T-SQL备份SQLShackInMemDB数据库
BACKUP DATABASE SQLShackInMemDB TO DISK = N'F:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Backup\SQLShackInMemDB-FULL-empty-data.bak'
WITH CHECKSUM,NOFORMAT, INIT, NAME = N'SQLShackInMemDB-Full Database Backup', SKIP, STATS = 15
The full database backup size is 5.3 MB. The space consumed on the disk is 156 MB. On comparison; backup size is relatively much smaller in size. On other side, though the database is empty, still there is a lot of space consumed on the disk due to the fixed storage constraints.
完整的数据库备份大小为5.3 MB。 磁盘上消耗的空间为156 MB。 比较而言; 备份大小相对较小。 另一方面,尽管数据库为空,但由于固定的存储约束,磁盘上仍然消耗大量空间。
Insert dummy values to the table to understand the storage internals and allocation units
在表中插入虚拟值以了解存储内部和分配单位
DECLARE @id bigint = 0
WHILE (@id < 8000)
BEGIN
INSERT SQLShackInMemTBL VALUES (@id, 'SQLShack', replicate ('USA, WI,Appleton', 8000))
SET @id =@id+ 1;
END
The following query is used to check the different states of the and status of checkpoint files
以下查询用于检查和检查点文件的不同状态
SELECT state_desc
, file_type_desc
, COUNT(*) AS Cnt
, SUM(file_size_in_bytes) / 1024 / 1024 AS DiskSizeMB
FROM sys.dm_db_xtp_checkpoint_files
GROUP BY state, state_desc, file_type, file_type_desc
ORDER BY state, file_type
Now, initiate a full database backup. As we can see that the database backup command is no different from the standard backup command T-SQL.
现在,启动完整的数据库备份。 如我们所见,数据库备份命令与标准备份命令T-SQL没什么不同。
BACKUP DATABASE SQLShackInMemDB TO DISK = N'F:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Backup\SQLShackInMemDB-FULL-data.bak'
WITH CHECKSUM,NOFORMAT, INIT, NAME = N'SQLShackInMemDB-Full Database Backup', SKIP, STATS = 15
Let’s initiate differential backup. The backup size is relatively smaller than the full backup.
让我们启动差异备份。 备份大小相对小于完整备份。
BACKUP DATABASE SQLShackInMemDB TO DISK = N'F:\PowerSQL\SQLShackInMemDB-DIFF-data.bak'
WITH DIFF, CHECKSUM,NOFORMAT, INIT, NAME = N'SQLShackInMemDB-DIFF Database Backup', SKIP,STATS = 15
Execute the backup log command. This proves that it’s no different from normal backup operation command.
执行backup log命令。 这证明它与正常的备份操作命令没有什么不同。
BACKUP LOG SQLShackInMemDB TO DISK =N'F:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Backup\SQLShackInMemDB-LOG-data_1.trn'
WITH CHECKSUM,NOFORMAT, INIT, NAME = N'SQLShackInMemDB-Tran Database Backup', SKIP, STATS = 15
Using sys.dm_db_xtp_checkpoint_files, it’s really that easy to see the state_desc. The “WAITING FOR LOG TRUNCATION” state of the checkpoint files reminds to backup the transaction logs. Checkpoint files go through various stages before they can be deleted and removed.
使用sys.dm_db_xtp_checkpoint_files,查看state_desc确实很容易。 检查点文件的“ WAITING FOR LOG TRUNCATION”状态提醒您备份事务日志。 检查点文件在删除和删除之前要经历各个阶段。
SELECT state_desc
, file_type_desc
, COUNT(*) AS Cnt
, SUM(file_size_in_bytes) / 1024 / 1024 AS DiskSizeMB
FROM sys.dm_db_xtp_checkpoint_files
GROUP BY state, state_desc, file_type, file_type_desc
ORDER BY state, file_type
数据库还原操作 (Database restore operation)
In this section, we will discuss the steps to restore the In-Memory optimized database.
在本节中,我们将讨论还原内存中优化的数据库的步骤。
As we can see that the database restore commands for an In-Memory optimized database are no different than traditional database restore commands. But, there are few key points to consider. In this case, the size of the memory optimized objects is relatively small (~400 MB). Loading such a small chunk is relatively pretty straightforward. When dealing with larger objects, here are some of the general recommendations for how much memory is needed for the restoration activity.
我们可以看到,针对内存中优化的数据库的数据库还原命令与传统的数据库还原命令没有什么不同。 但是,要考虑的关键点很少。 在这种情况下,内存优化对象的大小相对较小(〜400 MB)。 加载这么小的块是相当简单的。 当处理较大的对象时,以下是一些有关恢复活动需要多少内存的常规建议。
- Identify the size of data/delta storage 确定数据/增量存储的大小
- Measure the size of the durable memory optimized tables 测量持久内存优化表的大小
- Understand the workload on the durable tables 了解耐用表上的工作量
- Compare the size of the t-log backups 比较t-log备份的大小
Note: The outcome of the database restore always depends on the available resources.
注意:数据库还原的结果始终取决于可用资源。
USE [master]
GO
RESTORE DATABASE [SQLShackInMemDB] FROM DISK = N'F:\PowerSQL\SQLShackInMemDB-FULL-data.bak' WITH FILE = 1,
MOVE N'SQLShackInMemDB_FG' TO N'f:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\SQLShackInMemDB_FG_Container', NORECOVERY, NOUNLOAD, STATS = 5
Restore t-logs
恢复日志
RESTORE LOG [SQLShackInMemDB] FROM DISK = N'F:\PowerSQL\SQLShackInMemDB-LOG-data_1.trn' WITH FILE = 1, NORECOVERY, NOUNLOAD, STATS = 5
RESTORE LOG [SQLShackInMemDB] FROM DISK = N'F:\PowerSQL\SQLShackInMemDB-LOG-data_2.trn' WITH FILE = 1, NOUNLOAD, STATS = 5
GO
内存优化数据库的逐步恢复 (Piecemeal restore of a memory-optimized database)
A key consideration for piecemeal restore of the memory-optimized database is that the file-group must be backed up and restored together with the primary file-group.
内存优化数据库的逐段还原的关键考虑因素是必须备份文件组并将其与主文件组一起还原。
演示版 (Demo )
Let’s add another file-group and file named SQLShack_IndexFG and ShackShack_IndexFile
让我们添加另一个文件组和名为SQLShack_IndexFG和ShackShack_IndexFile的文件
ALTER DATABASE SQLShackInMemDB ADD FILEGROUP SQLShack_IndexFG
ALTER DATABASE SQLShackInMemDB ADD FILE (name=SQLShack_IndexFile, filename='F:\PowerSQL\SQLShack_IndexFG.ndf') TO FILEGROUP SQLShack_IndexFG
If you’re intended to back up or restore the primary file-group, it is must to specify the memory-optimized file-group. In the backup T-SQL, we can see that primary and SQLShackInMemDB_FG are added. It is must to include the primary file-group, if you intend to backup memory-optimized file-group.
如果要备份或还原主文件组,则必须指定内存优化的文件组。 在备份T-SQL中,我们可以看到已添加primary和SQLShackInMemDB_FG 。 如果要备份内存优化的文件组,则必须包括主文件组。
BACKUP DATABASE SQLShackInMemDB filegroup='primary', filegroup='SQLShackInMemDB_FG' TO DISK = N'F:\PowerSQL\SQLShackInMemDB-Primary-and-InMem-data.bak'
WITH CHECKSUM,FORMAT, INIT, NAME = N'SQLShackInMemDB-Primary and In-Mem Database Backup', SKIP, NOREWIND, NOUNLOAD,STATS = 10

Now, backup the secondary filegroups. Here, SQLShack_IndexFG is the index file-group.
现在,备份辅助文件组。 在这里,SQLShack_IndexFG是索引文件组。
BACKUP DATABASE SQLShackInMemDB filegroup='SQLShack_IndexFG' TO DISK = N'F:\PowerSQL\SQLShackInMemDB-indexFG.bak'
WITH CHECKSUM,FORMAT, INIT, NAME = N'SQLShackInMemDB-IndexFG Database Backup', SKIP, NOREWIND, NOUNLOAD,STATS = 10
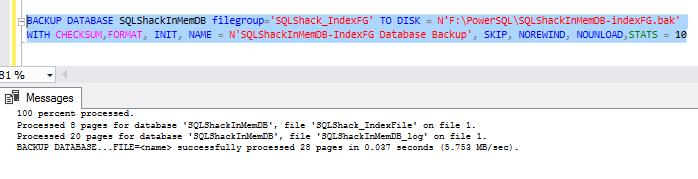
Next, lets perform the t-log backup
接下来,让我们执行t-log备份
BACKUP LOG SQLShackInMemDB TO DISK =N'F:\PowerSQL\SQLShackInMemDB-LOG-data_1.trn'
WITH CHECKSUM,FORMAT, INIT, NAME = N'SQLShackInMemDB-Transaction log Database Backup', SKIP, NOREWIND, NOUNLOAD,STATS = 10
Thus far, we have seen the database backup operation. Now, we will see how to perform the database restore.
到目前为止,我们已经看到了数据库备份操作。 现在,我们将看到如何执行数据库还原。
To restore the database, first restore the primary and memory-optimized file-group together and then restore the transaction log.
要还原数据库,请首先同时还原主文件和内存优化的文件组,然后还原事务日志。
RESTORE DATABASE SQLShackInMemDB filegroup = 'primary', filegroup = 'SQLShackInMemDB_FG'
from disk= N'F:\PowerSQL\SQLShackInMemDB-Primary-and-InMem-data.bak' with partial, norecovery
RESTORE LOG SQLShackInMemDB FROM DISK =N'F:\PowerSQL\SQLShackInMemDB-LOG-data_1.trn' WITH FILE = 1, NOUNLOAD, STATS = 10
GO
Next, restore the index file group
接下来,还原索引文件组
use master
go
RESTORE DATABASE SQLShackInMemDB file = N'SQLShack_IndexFile'
from disk= N'F:\PowerSQL\SQLShackInMemDB-indexFG.bak' with RECOVERY, FILE = 1, NOUNLOAD, STATS = 10

The database is up and running! That’s all for now…
数据库已启动并正在运行! 目前为止就这样了…
结语 (Wrapping Up)
Memory-optimized tables are backed up with regular database backup options. The CHECKSUM clause is used in addition to validate the integrity of the data and delta file pairs storage allocations.
使用常规数据库备份选项备份内存优化的表。 CHECKSUM子句还用于验证数据和增量文件对存储分配的完整性。
The process of transaction logging is optimized for scalability and high performance through the use of reduced logging mechanism.
通过使用减少的日志记录机制,事务日志记录的过程针对可伸缩性和高性能进行了优化。
Some extreme cases, like where the system is running out of disk space, may lead into the delete-only-mode.
在某些极端情况下(例如系统磁盘空间不足),可能会导致进入仅删除模式。
Using transaction log and data and delta files, In-Memory tables are automatically rebuilt. As Data and Delta files are loaded and processed in parallel, the outage is further shortened by enforcing faster database recovery technique. Finally, transaction logs are applied to bring back the database online.
使用事务日志以及数据和增量文件,可以自动重建内存表。 由于并行加载和处理Data和Delta文件,因此通过实施更快的数据库恢复技术可以进一步缩短中断时间。 最后,应用事务日志使数据库重新联机。
We ran through the backup and restore procedures with no additional backup procedures. The SQL Server engine manages the In-Memory database recovery process and it’s relatively straightforward with some additional steps. For durable memory-optimized data, the process has to stream the data from CFP (Checkpoint-File-Pairs) back into the memory.
我们执行了备份和还原过程,没有其他备份过程。 SQL Server引擎管理内存数据库恢复过程,并且相对简单一些额外的步骤。 对于持久的内存优化数据,该过程必须将数据从CFP(检查点-文件对)流回内存。
The restore activity may fail due to out-of-memory errors. It is recommended to configure a dedicated resource pool for In-Memory optimized database. In general, there would be a need of 3 * the size of the durable memory-optimized memory for the successful database restores operation. I would recommend testing the backup and restore procedures in your environment.
还原活动可能由于内存不足错误而失败。 建议为内存中优化的数据库配置专用的资源池。 通常,成功的数据库还原操作需要3 *持久内存优化的内存大小。 我建议您在环境中测试备份和还原过程。
目录 (Table of contents)
参考资料 (References)
- Choosing the right server memory for restore and recovery of memory-optimized databases 选择正确的服务器内存以还原和恢复内存优化的数据库
- Restore and recovery of memory-optimized tables 还原和恢复内存优化表
- In-Memory OLTP Series – Data migration guideline process on SQL Server 2014 内存中的OLTP系列– SQL Server 2014上的数据迁移指南过程
- Survey of Initial Areas in In-Memory OLTP 内存中OLTP初始区域的调查
- SQL Server 2016 SP1: Know your limits SQL Server 2016 SP1:了解您的限制
- Restore and recovery of memory-optimized tables 还原和恢复内存优化表
- Resolve Out Of Memory issues 解决内存不足问题
- Piecemeal Restore of Databases With Memory-Optimized Tables 使用内存优化表对数据库进行零碎还原
- Expert SQL Server in-Memory OLTP 专家SQL Server内存中OLTP
翻译自: https://www.sqlshack.com/in-memory-optimized-database-backup-and-restore-in-sql-server/















 757
757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









