





Database maintenance is very important, a critical part of our database administrators’ daily tasks. However, this aspect is frequently underestimated which could lead to performance problems and respectively angry, unhappy customers. In this article, we will take a look at the different maintenance operations we have in SQL Server and how we can optimize them and take the maximum out of each.
数据库维护非常重要,这是我们数据库管理员日常任务的关键部分。 但是,这方面经常被低估,这可能会导致性能问题以及分别使生气,不满意的客户。 在本文中,我们将研究SQL Server中进行的各种维护操作,以及如何优化它们并从中获得最大收益。
索引重组操作 ( Index Reorganize operation )
We are taking off with the indexes in our databases. I am not going to convince you how important is to keep our indexes in a good shape, so we are directly jumping into how we can maintain them.
我们正在使用数据库中的索引。 我不会说服您保持索引良好状态的重要性,因此我们将直接跳入如何维护索引的过程。
One of the possibilities that we have in SQL Server to keep our indexes defragmented, is the index reorganize operation. This operation is always online, uses minimal system resources, honors the fill factor that has been used during the creation of the index (common misconception is that reorganize operation does not take into account fill factor at all) and if you kill it due to any reason, the work that has been done would still persist. So far so good! However there are several major drawbacks:
在SQL Server中使索引进行碎片整理的一种可能性是索引重组操作。 此操作始终在线,使用最少的系统资源,尊重在创建索引期间使用的填充因子(常见的误解是,重组操作根本不考虑填充因子),并且如果您由于任何原因而将其杀死因此,已经完成的工作仍将继续。 到目前为止,一切都很好! 但是,有几个主要缺点:
- Index statistics are not being updated 索引统计信息未更新
- Not efficient when you have a large fragmentation as it is only reorganizing the leaf-level pages 当您的碎片很大时,效率不高,因为它只是重新组织叶级页面
- Cannot change the initial fill factor used during index creation 无法更改索引创建期间使用的初始填充因子
Let’s test this with one simple scenario:
让我们用一个简单的场景进行测试:
Create a test database to play with one simple table and insert some data with deliberately skipping some values to produce page splits and larger fragmentation:
创建一个测试数据库来处理一个简单的表,并故意跳过一些值以插入一些数据以产生页面拆分和更大的碎片:
USE master GO IF EXISTS (SELECT name FROM sys.databases WHERE name = N'IndexMaintenance') DROP DATABASE [IndexMaintenance] GO CREATE DATABASE IndexMaintenance; GO USE IndexMaintenance; GO CREATE TABLE IndexTable (c1 INT, c2 CHAR (4000)); CREATE CLUSTERED INDEX IndexTable_CL ON IndexTable (c1); GO DECLARE @a INT SET @a = 1 WHILE (@a<80) BEGIN IF (@a=5 or @a=15 or @a=22 or @a=29 or @a=34 or @a=38 or @a=45) PRINT 'Nothing to insert' ELSE INSERT INTO IndexTable VALUES (@a, 'a') SET @a=@a + 1 END INSERT INTO IndexTable VALUES (5, 'a'); GO INSERT INTO IndexTable VALUES (15, 'a'); GO INSERT INTO IndexTable VALUES (22, 'a'); GO INSERT INTO IndexTable VALUES (29, 'a'); GO INSERT INTO IndexTable VALUES (34, 'a'); GO INSERT INTO IndexTable VALUES (38, 'a'); GO INSERT INTO IndexTable VALUES (45, 'a'); GOCheck the index details – we are interested mainly in the fragmentation, page fullness and last statistics update for this index:
检查索引详细信息–我们主要对该索引的碎片,页面填充和最新统计信息感兴趣:
USE IndexMaintenance SELECT a.index_id, name, avg_fragmentation_in_percent, a.page_count,a.record_count,a.index_type_desc,a.avg_page_space_used_in_percent,STATS_DATE(b.object_id,b.index_id) as stats_updated FROM sys.dm_db_index_physical_stats (DB_ID(N'IndexMaintenance'), OBJECT_ID(N'dbo.IndexTable'), 1, NULL, 'DETAILED') AS a JOIN sys.indexes AS b ON a.object_id = b.object_id AND a.index_id = b.index_id
Our index has above 30 % fragmentation, so we need to do something. Try with Index Reorganize first:
我们的索引有30%以上的碎片,因此我们需要做一些事情。 请先尝试使用“索引重组”:
USE IndexMaintenance ALTER INDEX IndexTable_CL ON dbo.IndexTable REORGANIZEUse the query from point 2 to see what happened with the index:
使用第2点的查询来查看索引发生了什么:
Fragmentation is lower than the initial 34 %, but there is still some left so our operation did not finish the job completely. If you take a look at the page fullness, SQL Server tried to honor the fill factor, which is 100 % (or 0) in our case:
碎片率低于最初的34%,但仍有一些碎片,因此我们的操作未能完全完成工作。 如果您看一下页面的填充度,SQL Server会尝试使用填充因子,在我们的例子中,填充因子为100%(或0):
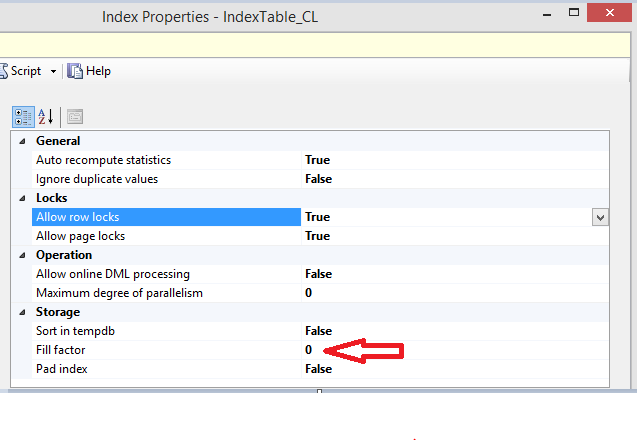
Last but not least, statistics associated with this index, have not been touched.
最后但并非最不重要的一点是,尚未触及与此索引相关的统计信息。
Repeat steps 1 and 2 to recreate our setup and check index details. This time, use Index Rebuild operation:
重复步骤1和2以重新创建我们的设置并检查索引详细信息。 这次,使用索引重建操作:
USE IndexMaintenance ALTER INDEX IndexTable_CL ON dbo.IndexTable REBUILDCheck the index details again after the rebuild with the script from point 2:
使用第2点的脚本重建后,再次检查索引详细信息:
Fragmentation is completely gone, fill factor was honored again and this time, index statistics have been updated!
碎片完全消失了,填充因子再次得到了认可,这一次,索引统计信息已更新!
Index Reorganize is a useful operation when your fragmentation is below 20-30 %, you do not need to change the original fill factor of your index and you are planning on doing index statistics update at a later point in time.
当您的碎片率低于20%至30%,您不需要更改索引的原始填充因子,并且计划在以后的某个时间进行索引统计信息更新时,索引重组是一项有用的操作。
索引重建操作 ( Index Rebuild operation )
We already covered that index rebuild is the approach you should use when the fragmentation is high. When you use this method, there are two options:
我们已经介绍了索引重建是在碎片过多时应该使用的方法。 使用此方法时,有两个选项:


- Offline 离线
- Online 线上
Offline index rebuild means really offline! While an index is being created, dropped or rebuilt offline, the table cannot be accessed and this is valid for non-clustered indexes as well:
离线索引重建意味着真正的离线! 在创建索引,离线删除或重建索引时,无法访问该表,这对于非聚集索引也有效:
- codeplex and restore the database to your SQL ServerCodeplex中获取“ AdventureWorks2014”数据库并将数据库还原到您SQL Server
Then run this script created by Jonathan Kehayias to enlarge several tables:
然后运行Jonathan Kehayias创建的此脚本来放大几个表:
USE [AdventureWorks2014] GO IF OBJECT_ID('Sales.SalesOrderHeaderEnlarged') IS NOT NULL DROP TABLE Sales.SalesOrderHeaderEnlarged; GO CREATE TABLE Sales.SalesOrderHeaderEnlarged ( SalesOrderID int NOT NULL IDENTITY (1, 1) NOT FOR REPLICATION, RevisionNumber tinyint NOT NULL, OrderDate datetime NOT NULL, DueDate datetime NOT NULL, ShipDate datetime NULL, Status tinyint NOT NULL, OnlineOrderFlag dbo.Flag NOT NULL, SalesOrderNumber AS (isnull(N'SO'+CONVERT([nvarchar](23),[SalesOrderID],0),N'*** ERROR ***')), PurchaseOrderNumber dbo.OrderNumber NULL, AccountNumber dbo.AccountNumber NULL, CustomerID int NOT NULL, SalesPersonID int NULL, TerritoryID int NULL, BillToAddressID int NOT NULL, ShipToAddressID int NOT NULL, ShipMethodID int NOT NULL, CreditCardID int NULL, CreditCardApprovalCode varchar(15) NULL, CurrencyRateID int NULL, SubTotal money NOT NULL, TaxAmt money NOT NULL, Freight money NOT NULL, TotalDue AS (isnull(([SubTotal]+[TaxAmt])+[Freight],(0))), Comment nvarchar(128) NULL, rowguid uniqueidentifier NOT NULL ROWGUIDCOL, ModifiedDate datetime NOT NULL ) ON [PRIMARY] GO SET IDENTITY_INSERT Sales.SalesOrderHeaderEnlarged ON GO INSERT INTO Sales.SalesOrderHeaderEnlarged (SalesOrderID, RevisionNumber, OrderDate, DueDate, ShipDate, Status, OnlineOrderFlag, PurchaseOrderNumber, AccountNumber, CustomerID, SalesPersonID, TerritoryID, BillToAddressID, ShipToAddressID, ShipMethodID, CreditCardID, CreditCardApprovalCode, CurrencyRateID, SubTotal, TaxAmt, Freight, Comment, rowguid, ModifiedDate) SELECT SalesOrderID, RevisionNumber, OrderDate, DueDate, ShipDate, Status, OnlineOrderFlag, PurchaseOrderNumber, AccountNumber, CustomerID, SalesPersonID, TerritoryID, BillToAddressID, ShipToAddressID, ShipMethodID, CreditCardID, CreditCardApprovalCode, CurrencyRateID, SubTotal, TaxAmt, Freight, Comment, rowguid, ModifiedDate FROM Sales.SalesOrderHeader WITH (HOLDLOCK TABLOCKX) GO SET IDENTITY_INSERT Sales.SalesOrderHeaderEnlarged OFF GO ALTER TABLE Sales.SalesOrderHeaderEnlarged ADD CONSTRAINT PK_SalesOrderHeaderEnlarged_SalesOrderID PRIMARY KEY CLUSTERED ( SalesOrderID ) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO CREATE UNIQUE NONCLUSTERED INDEX AK_SalesOrderHeaderEnlarged_rowguid ON Sales.SalesOrderHeaderEnlarged ( rowguid ) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO CREATE UNIQUE NONCLUSTERED INDEX AK_SalesOrderHeaderEnlarged_SalesOrderNumber ON Sales.SalesOrderHeaderEnlarged ( SalesOrderNumber ) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO CREATE NONCLUSTERED INDEX IX_SalesOrderHeaderEnlarged_CustomerID ON Sales.SalesOrderHeaderEnlarged ( CustomerID ) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO CREATE NONCLUSTERED INDEX IX_SalesOrderHeaderEnlarged_SalesPersonID ON Sales.SalesOrderHeaderEnlarged ( SalesPersonID ) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO IF OBJECT_ID('Sales.SalesOrderDetailEnlarged') IS NOT NULL DROP TABLE Sales.SalesOrderDetailEnlarged; GO CREATE TABLE Sales.SalesOrderDetailEnlarged ( SalesOrderID int NOT NULL, SalesOrderDetailID int NOT NULL IDENTITY (1, 1), CarrierTrackingNumber nvarchar(25) NULL, OrderQty smallint NOT NULL, ProductID int NOT NULL, SpecialOfferID int NOT NULL, UnitPrice money NOT NULL, UnitPriceDiscount money NOT NULL, LineTotal AS (isnull(([UnitPrice]*((1.0)-[UnitPriceDiscount]))*[OrderQty],(0.0))), rowguid uniqueidentifier NOT NULL ROWGUIDCOL, ModifiedDate datetime NOT NULL ) ON [PRIMARY] GO SET IDENTITY_INSERT Sales.SalesOrderDetailEnlarged ON GO INSERT INTO Sales.SalesOrderDetailEnlarged (SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber, OrderQty, ProductID, SpecialOfferID, UnitPrice, UnitPriceDiscount, rowguid, ModifiedDate) SELECT SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber, OrderQty, ProductID, SpecialOfferID, UnitPrice, UnitPriceDiscount, rowguid, ModifiedDate FROM Sales.SalesOrderDetail WITH (HOLDLOCK TABLOCKX) GO SET IDENTITY_INSERT Sales.SalesOrderDetailEnlarged OFF GO ALTER TABLE Sales.SalesOrderDetailEnlarged ADD CONSTRAINT PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID PRIMARY KEY CLUSTERED ( SalesOrderID, SalesOrderDetailID ) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO CREATE UNIQUE NONCLUSTERED INDEX AK_SalesOrderDetailEnlarged_rowguid ON Sales.SalesOrderDetailEnlarged ( rowguid ) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO CREATE NONCLUSTERED INDEX IX_SalesOrderDetailEnlarged_ProductID ON Sales.SalesOrderDetailEnlarged ( ProductID ) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO BEGIN TRANSACTION DECLARE @TableVar TABLE (OrigSalesOrderID int, NewSalesOrderID int) INSERT INTO Sales.SalesOrderHeaderEnlarged (RevisionNumber, OrderDate, DueDate, ShipDate, Status, OnlineOrderFlag, PurchaseOrderNumber, AccountNumber, CustomerID, SalesPersonID, TerritoryID, BillToAddressID, ShipToAddressID, ShipMethodID, CreditCardID, CreditCardApprovalCode, CurrencyRateID, SubTotal, TaxAmt, Freight, Comment, rowguid, ModifiedDate) OUTPUT inserted.Comment, inserted.SalesOrderID INTO @TableVar SELECT RevisionNumber, DATEADD(dd, number, OrderDate) AS OrderDate, DATEADD(dd, number, DueDate), DATEADD(dd, number, ShipDate), Status, OnlineOrderFlag, PurchaseOrderNumber, AccountNumber, CustomerID, SalesPersonID, TerritoryID, BillToAddressID, ShipToAddressID, ShipMethodID, CreditCardID, CreditCardApprovalCode, CurrencyRateID, SubTotal, TaxAmt, Freight, SalesOrderID, NEWID(), DATEADD(dd, number, ModifiedDate) FROM Sales.SalesOrderHeader AS soh WITH (HOLDLOCK TABLOCKX) CROSS JOIN ( SELECT number FROM ( SELECT TOP 10 number FROM master.dbo.spt_values WHERE type = N'P' AND number < 1000 ORDER BY NEWID() DESC UNION SELECT TOP 10 number FROM master.dbo.spt_values WHERE type = N'P' AND number < 1000 ORDER BY NEWID() DESC UNION SELECT TOP 10 number FROM master.dbo.spt_values WHERE type = N'P' AND number < 1000 ORDER BY NEWID() DESC UNION SELECT TOP 10 number FROM master.dbo.spt_values WHERE type = N'P' AND number < 1000 ORDER BY NEWID() DESC ) AS tab ) AS Randomizer ORDER BY OrderDate, number INSERT INTO Sales.SalesOrderDetailEnlarged (SalesOrderID, CarrierTrackingNumber, OrderQty, ProductID, SpecialOfferID, UnitPrice, UnitPriceDiscount, rowguid, ModifiedDate) SELECT tv.NewSalesOrderID, CarrierTrackingNumber, OrderQty, ProductID, SpecialOfferID, UnitPrice, UnitPriceDiscount, NEWID(), ModifiedDate FROM Sales.SalesOrderDetail AS sod JOIN @TableVar AS tv ON sod.SalesOrderID = tv.OrigSalesOrderID ORDER BY sod.SalesOrderDetailID COMMITNote this might take several minutes to complete.
请注意,这可能需要几分钟才能完成。
- After the script finishes, use the table “Sales.SalesOrderDetailEnlarged” which is already with a suitable size. 脚本完成后,使用已经具有适当大小的表“ Sales.SalesOrderDetailEnlarged”。
-
Script for reading data (select * not a good command but it will work for test)
读取数据的脚本(选择*不是一个好的命令,但可以用于测试)
SELECT * FROM [AdventureWorks2014].[Sales].[SalesOrderDetailEnlarged]Rebuild offline one of the non-clustered indexes in this table:
离线重建此表中的非聚集索引之一:
USE [AdventureWorks2014] GO ALTER INDEX [AK_SalesOrderDetailEnlarged_rowguid] ON [Sales].[SalesOrderDetailEnlarged] REBUILD PARTITION = ALL WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) GOExamine the locks in your SQL Server (note to change the session_ids in your environment):
检查您SQL Server中的锁(注意在您的环境中更改session_ids):
SELECT session_id, blocking_session_id, wait_resource, wait_time, wait_type FROM sys.dm_exec_requests WHERE session_id = 64 or session_id = 63 SELECT request_session_id ,request_mode ,request_type ,request_status ,resource_type FROM sys.dm_tran_locks WHERE request_session_id = 63 or request_session_id=64 ORDER BY request_session_id
If we run the query from a., it will work and return the result for around 1 minute without any blockings. Let’s start the index rebuild from b., then switch to a. query and run it and observe the locks with the query c. This time, we are not seeing any rows immediately coming from a. query (session 63) because the offline index rebuild on the non-clustered index is blocking our session (session 64):
如果我们从a。运行查询,它将正常工作并返回结果约1分钟,而不会出现任何阻塞。 让我们从b。开始索引重建,然后切换到a。 查询并运行它,并观察查询的锁c。 这次,我们没有看到来自a的任何行。 查询(会话63),因为在非聚集索引上重建脱机索引会阻止我们的会话(会话64):
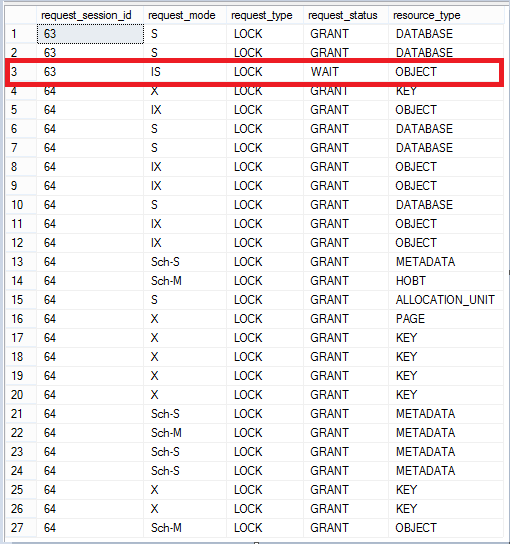
Even this was a non-clustered index, we were not able to read our data while the rebuild operation was taking place.
即使这是一个非聚集索引,在进行重建操作时我们也无法读取数据。
The only exception to this rule is that we are allowed to read data from the table while a non-clustered index is being created offline.
该规则的唯一例外是,允许我们离线创建非聚集索引时从表中读取数据。
We now know for sure that offline operations are really offline. I guess this is very intuitive so we did not reinvent the wheel. The interesting point is when it comes to online operations. Are they really online?
现在,我们确定离线操作实际上是离线的。 我想这是非常直观的,所以我们没有重新发明轮子。 有趣的一点是在线操作。 他们真的在线吗?
Let’s see!
让我们来看看!
Before we go into more details, keep in mind that this is an Enterprise edition feature only.
在我们进行详细讨论之前,请记住,这仅是企业版功能。
Online operations are divided into three phases (if you are keen on learning more details, please check this whitepaper):
在线操作分为三个阶段(如果您想了解更多详细信息,请查看此白皮书 ):
- Preparation phase – you need to take at this point a Share lock for the row versioning and the lock is not compatible with an exclusive lock 准备阶段–此时,您需要为行版本控制使用共享锁,并且该锁与排他锁不兼容
- Build phase – the phase of populating data into the new index. Typically you should not see any locks here 构建阶段–将数据填充到新索引中的阶段。 通常,您在这里应该看不到任何锁
- Final phase – declare to SQL that the new index is ready. In order this to happen, we need a Schema Modification lock is not compatible with any locks. 最后阶段–向SQL声明新索引已准备就绪。 为了做到这一点,我们需要一个“模式修改”锁与任何锁都不兼容。
Example:
例:
- here and attach it.此处下载数据库“ AdventureWorksDW2012”并附加它。
Get an exclusive lock on the table:
在桌子上获得排他锁:
USE [AdventureWorksDW2012] GO BEGIN TRANSACTION UPDATE [dbo].[FactProductInventory] SET UnitsIn=5Start index rebuild operation in another tab:
在另一个选项卡中开始索引重建操作:
USE [AdventureWorksDW2012] GO ALTER INDEX [PK_FactProductInventory] ON [dbo].[FactProductInventory] REBUILD WITH (ONLINE= ON);Examine the locks with the same script used above (again do not forget to put your session_ids):
使用上面使用的相同脚本检查锁(同样不要忘记放置session_ids):
SELECT session_id, blocking_session_id, wait_resource, wait_time, wait_type FROM sys.dm_exec_requests WHERE session_id = 58 or session_id = 57 SELECT request_session_id ,request_mode ,request_type ,request_status ,resource_type FROM sys.dm_tran_locks WHERE request_session_id = 58 or request_session_id=57 ORDER BY request_session_idSession 57 (online index rebuild) is waiting for all of the exclusive locks to be released. This makes the operation unpredictable as we cannot say for sure when the maintenance operation will be able to take this lock and start its work. This might take several seconds or minutes, but in some situations even hours!
会话57(联机索引重建)正在等待释放所有排他锁。 这使操作变得不可预测,因为我们无法确定维护操作何时能够获取此锁定并开始其工作。 这可能需要几秒钟或几分钟,但在某些情况下甚至需要数小时!
Rollback the transaction holding the lock (session 58 in my case) and immediately start it again (you have several seconds to do this before the index rebuild operation finishes). Check the locks now:
回滚持有该锁的事务(在本例中为会话58),然后立即再次启动它(在索引重建操作完成之前,您有几秒钟的时间来执行此操作)。 现在检查锁:
Oh no! We are waiting one more time, but for a Schema Modification lock to be granted so the SQL can complete the rebuild operation. This is another unpredictable time interval at the end of our procedure.
不好了! 我们又等了一段时间,但是等待授予Schema Modification锁,以便SQL可以完成重建操作。 这是程序结束时另一个不可预测的时间间隔。
Online maintenance is holding locks at the beginning and at the end of our operations, which might be problematic especially on critical and busy production servers. Today online index rebuild might take 1 hour, but tomorrow might need 10 hours or even more!
在线维护在我们运营的开始和结束时都处于锁定状态,这可能会出现问题,尤其是在关键和繁忙的生产服务器上。 今天的在线索引重建可能需要1个小时,但明天可能需要10个小时甚至更长的时间!
低优先级等待 ( Wait at low priority )
With SQL Server 2014, Microsoft has shipped a new functionality which could be very useful in relieving our online index operations. The feature is called: wait at low priority. It is now possible to have an influence on what is happening with our maintenance after a predefined period of time elapsed and we are still not able to acquire the required locks:
Microsoft使用SQL Server 2014提供了一项新功能,该功能对于减轻我们的在线索引操作可能非常有用。 该功能称为:低优先级等待。 经过预定的时间后,现在有可能影响我们的维护工作,而我们仍然无法获得所需的锁:
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 1 MINUTES, ABORT_AFTER_WAIT = BLOCKERS|SELF|NONE))
- MAX_DURATION – how many minutes we will wait to take a lock on the table before SQL takes any actions MAX_DURATION –在执行任何操作之前,我们将等待多少分钟来锁定表
-
- BLOCKERS – sessions, that are preventing our locks, will be killed BLOCKERS –阻止我们锁定的会话将被杀死
- SELF – our maintenance session will be killed 自检–我们的维护工作将被取消
- NONE – we will keep waiting and nothing will happen (the same behavior we would see if we are not using this feature) 无-我们将继续等待,并且不会发生任何事情(如果不使用此功能,我们将看到相同的行为)
In this scenario we will use again “AdventureWorksDW2012” database – if you do not keep it from the previous demos, grab it from here and attach it:
在这种情况下,我们将再次使用“ AdventureWorksDW2012”数据库–如果您不保留以前的演示中的数据库,请从此处获取并附加它:
Run this to take an exclusive lock:
运行此命令以排它锁:
USE [AdventureWorksDW2012] GO BEGIN TRANSACTION UPDATE [dbo].[FactProductInventory] SET UnitsIn=5Start index rebuild operation, using wait at low priority with BLOCKERS option:
使用具有BLOCKERS选项的低优先级等待来启动索引重建操作:
ALTER INDEX [PK_FactProductInventory] ON [dbo].[FactProductInventory] REBUILD WITH ( ONLINE = ON ( WAIT_AT_LOW_PRIORITY ( MAX_DURATION = 1 MINUTES, ABORT_AFTER_WAIT = BLOCKERS ) ) )Check the locks (note to put your session_ids):
检查锁(注意放入session_ids):
SELECT session_id, blocking_session_id, wait_resource, wait_time, wait_type FROM sys.dm_exec_requests WHERE session_id = 52 or session_id = 57 SELECT request_session_id ,request_mode ,request_type ,request_status ,resource_type FROM sys.dm_tran_locks WHERE request_session_id = 52 or request_session_id=57 ORDER BY request_session_id
Session 57, online index operation, is waiting again for a Shared lock, but, this time, waiting at low priority. After 1 minute in our case, SQL Server will kill the queries preventing us from taking this Shared lock on the table, if they have not succeeded yet and the rebuild operation will start. The good news is that we have these stuff logged in the error log:
会话57,联机索引操作,再次等待共享锁,但是这次,它以低优先级等待。 在本例中,经过1分钟后,SQL Server将终止查询,阻止我们在表上使用此共享锁(如果尚未成功),并且重新生成操作将开始。 好消息是我们在错误日志中记录了以下内容:
Message
An ‘ALTER INDEX REBUILD’ statement was executed on object ‘dbo.FactProductInventory’ by hostname ‘XXXXX’, host process ID 6124 using the WAIT_AT_LOW_PRIORITY options with MAX_DURATION = 1 and ABORT_AFTER_WAIT = BLOCKERS. Blocking user sessions will be killed after the max duration of waiting time.
信息
使用WAIT_AT_LOW_PRIORITY选项(MAX_DURATION = 1且ABORT_AFTER_WAIT = BLOCKERS),主机名“ XXXXX”,主机进程ID 6124在对象“ dbo.FactProductInventory”上执行了“ ALTER INDEX REBUILD”语句。 在最长等待时间后,阻塞的用户会话将被终止。
Message
An ABORT_AFTER_WAIT = BLOCKERS lock request was issued on database_id = 8, object_id = 642101328. All blocking user sessions will be killed.
信息
在database_id = 8,object_id = 642101328上发出了ABORT_AFTER_WAIT = BLOCKERS锁定请求。所有阻塞的用户会话都将被杀死。
Message
Process ID 52 was killed by an ABORT_AFTER_WAIT = BLOCKERS DDL statement on database_id = 8, object_id = 642101328.
信息
进程ID 52被database_id = 8,object_id = 642101328的ABORT_AFTER_WAIT = BLOCKERS DDL语句杀死。
The transaction holding the lock has been killed and we were able to complete our very important rebuild operation on time 🙂
拥有锁的事务已被终止,我们能够按时完成非常重要的重建操作🙂
This is a nice feature, but we have to be very careful with it! Depending on what kind of transactions are using the different tables and indexes respectively, we have to make an educated and informed choice how and if we are going to utilize this new SQL option.
这是一个不错的功能,但是我们必须非常小心! 根据分别使用不同表和索引的事务类型,我们必须做出明智且明智的选择,我们将如何以及是否将利用此新SQL选项。
填充系数 ( Fill factor )
When we are creating indexes in SQL Server, there is one very important property – fill factor: it is instructing what percentage of each leaf-level page we would like to be filled up. Recommendations are to play with the fill factor for indexes that are becoming fragmented very often. We will not go into details about page splits and how pages in indexes are becoming out of order. The focus will be what the influence is if we change the default instance-level fill factor.
在SQL Server中创建索引时,有一个非常重要的属性–填充因子:它指示我们希望填充每个叶级页面的百分比。 对于经常变得零散的索引,建议使用填充因子。 我们将不讨论有关页面拆分以及索引中的页面如何变得混乱的详细信息。 如果我们更改默认实例级填充因子,重点将是影响。
SQL Server is being shipped with a fill factor of 0:
SQL Server出厂时的填充因子为0:
This means that if we do not specify a new fill factor during index creation, we will try to fill the leaf-level pages as much as possible (fullness will be a number close to 100 %). If there are a lot of fragmented indexes in our instance and all of the databases residing there are being utilized in a similar manner (in terms of a number of read/write operations) we can benefit of changing this setting.
这意味着,如果在索引创建过程中未指定新的填充因子,则将尝试尽可能多地填充叶级页面(填充度将接近100%)。 如果我们的实例中有很多零散的索引,并且驻留在其中的所有数据库都以类似的方式使用(就许多读/写操作而言),我们可以从更改此设置中受益。
Keep in mind several important stuff:
请记住一些重要的东西:
-
Changed the setting without restarting SQL Server:
更改了设置而不重新启动SQL Server:
Use again “AdventureWorksDW2012” database, table dbo.DimProduct without specifying the fill factor:
再次使用“ AdventureWorksDW2012”数据库,表dbo.DimProduct,而不指定填充因子:
USE [AdventureWorksDW2012] GO CREATE NONCLUSTERED INDEX [NCI_TestFillFactor] ON [dbo].[DimProduct] ( [WeightUnitMeasureCode] ASC, [SizeUnitMeasureCode] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) GOCheck the fill factor from SSMS:
从SSMS检查填充因子:
It is still using the default fill factor.
它仍在使用默认填充因子。
Restart SQL Server, drop the newly created index and recreate it again with the above script
重新启动SQL Server,删除新创建的索引,然后使用上述脚本再次创建它
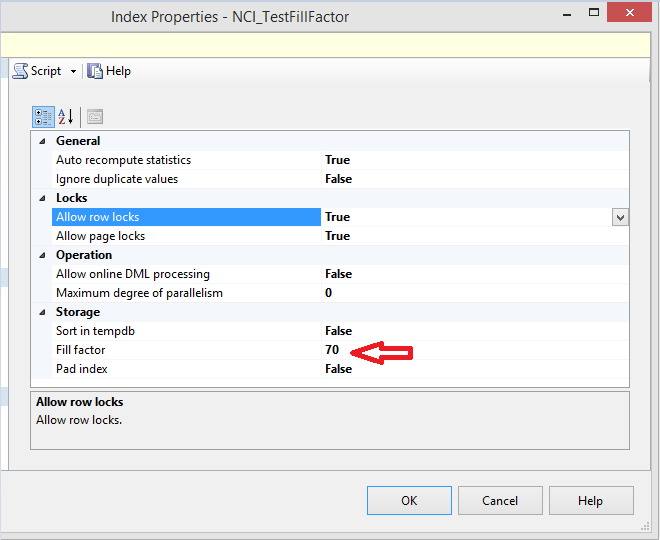
It is now using the instance-level current setting.
现在它正在使用实例级别的当前设置。
-
If we take a look at the PK on the same table dbo.DimProduct, it still has fill factor 0 (the one used during the creation of the index):
如果我们看一下同一表dbo.DimProduct上的PK,它的填充因子仍然为0(在创建索引期间使用的填充因子):
Even if you do rebuild the indexes after the new fill factor is already in effect and working for new indexes, the old one would still be using the fill factor specified at the time of their creation unless you specify a new one in the rebuild command.
即使在新的填充因子已经生效并为新索引工作之后确实重建了索引,旧索引仍将使用创建索引时指定的填充因子,除非您在rebuild命令中指定了新的填充因子。
Rebuild the index with this query:
使用以下查询重建索引:
USE [AdventureWorksDW2012] ALTER INDEX [PK_DimProduct_ProductKey] ON [dbo].[DimProduct] REBUILDCheck the fill factor now:
现在检查填充因子:
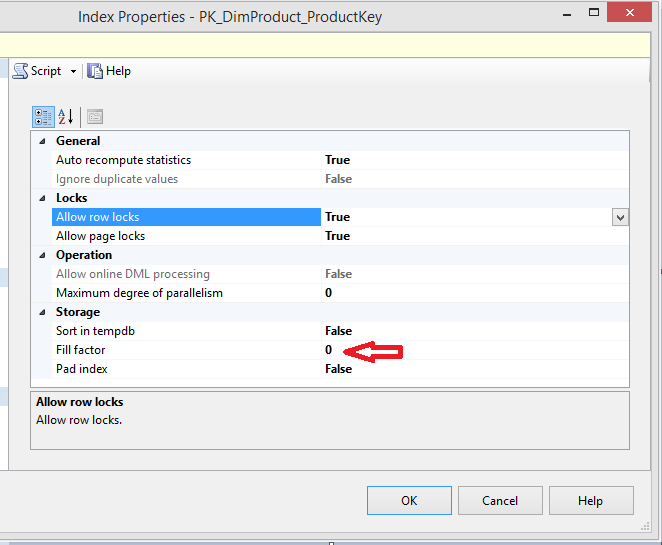
It has not been changed even after the rebuild operation.
即使在重建操作之后也没有更改。
I have heard a lot of questions regarding what is happening with the indexes when I change the instance-level fill factor, so I hope you now have a better understanding 🙂
我在更改实例级填充因子时听到了很多有关索引发生问题的问题,所以希望您现在对它有更好的了解🙂
Note that on the majority of the occasions it is not recommended to change the instance-level fill factor. The better approach is to leave this at 0 and change it only for specific indexes where you have noticed a lot of fragmentation and expecting heavy page split operations.
请注意,在大多数情况下,不建议更改实例级别的填充因子。 更好的方法是将其保留为0并仅针对发现大量碎片并期望进行大量页面拆分操作的特定索引进行更改。
统计 ( Statistics )
Statistics are very important objects in our databases as they are being used to produce optimal query execution plans. There are two types of statistics: index and column statistics. Index statistics are always generated when a new index is created. There is no way to circumvent this behavior! Column statistics are being built by SQL Server in order to have a better understanding of the data distribution and decide what the best option to execute a certain query is. Unlike index statistics, we can have our word for column ones:
统计数据在我们的数据库中是非常重要的对象,因为它们被用于生成最佳的查询执行计划。 统计信息有两种:索引统计和列统计。 创建新索引时始终会生成索引统计信息。 没有办法避免这种行为! SQL Server正在建立列统计信息,以便更好地了解数据分布并确定执行特定查询的最佳选择是什么。 与索引统计不同,我们可以用“列”来表示:
On database level, we can disable Auto Create Statistics and this will be valid only for the column ones.
在数据库级别,我们可以禁用“自动创建统计信息”,这仅对列中的有效。
Let’s see a simple example:
让我们看一个简单的例子:
- here and attach it此处获取 “ AdventureWorksDW2008R2”数据库并将其附加
Run this script to turn off Auto Create Statistics for this database:
运行以下脚本以关闭此数据库的“自动创建统计信息”:
USE [master] GO ALTER DATABASE [AdventureWorksDW2008R2] SET AUTO_CREATE_STATISTICS OFF WITH NO_WAIT GOInclude the actual execution plan and start this query:
包括实际的执行计划并启动此查询:
USE [AdventureWorksDW2008R2] GO SELECT RevisionNumber FROM dbo.FactInternetSales WHERE TaxAmt = 5.08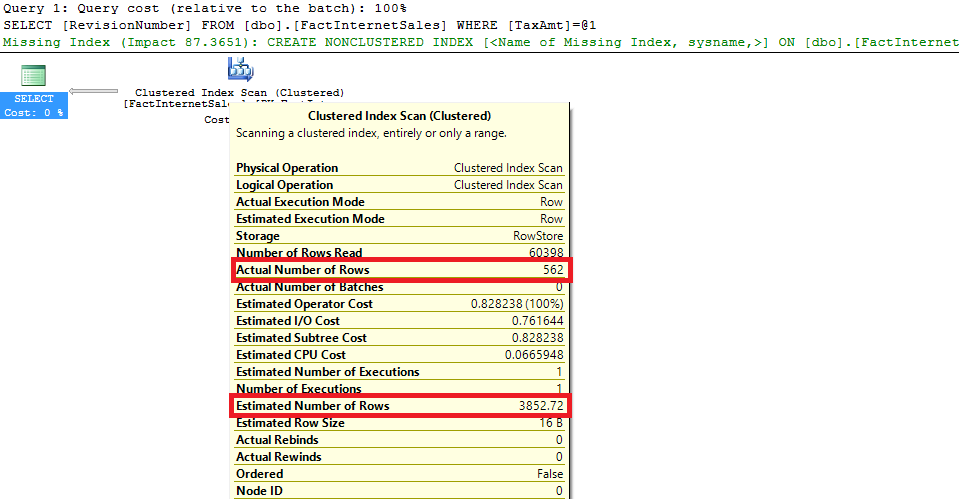
There is a great difference in the actual and estimated number of rows for this query which is an issue in most of the situations.
此查询的实际行数和估计行数之间存在很大差异,这在大多数情况下都是一个问题。
We can create an index on column “TaxAmt” and solve our problems but in this case, I would like to enable Auto Create Statistics and start the query again:
我们可以在“ TaxAmt”列上创建索引并解决我们的问题,但是在这种情况下,我想启用“自动创建统计信息”并再次启动查询:
USE [master] GO ALTER DATABASE [AdventureWorksDW2008R2] SET AUTO_CREATE_STATISTICS ON WITH NO_WAIT GO USE [AdventureWorksDW2008R2] GO SELECT RevisionNumber FROM dbo.FactInternetSales WHERE TaxAmt = 5.08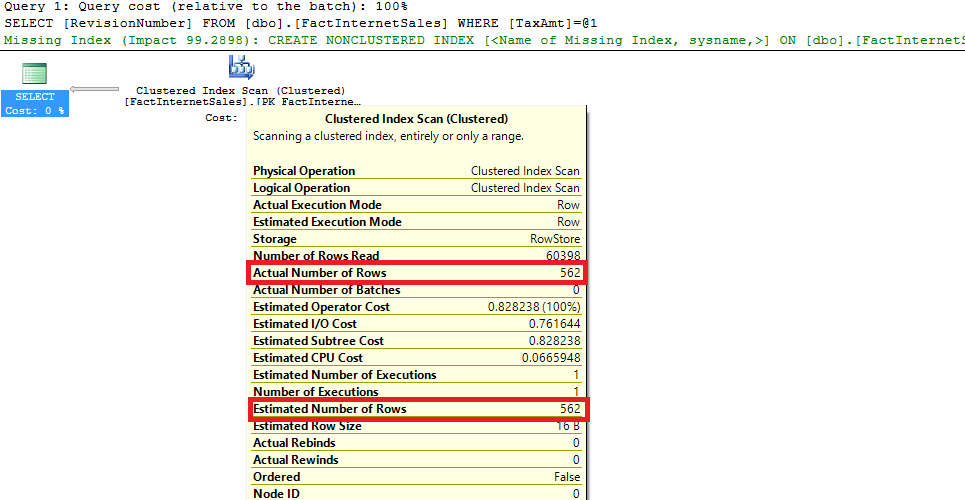
SQL Server created a column statistic that helped to receive a better cardinality.
SQL Server创建了一个列统计信息,该统计信息有助于获得更好的基数。
As we now understand the importance of the statistics, we have to take care of them and include a task in our maintenance that is going to keep these objects in a good shape. Here we need to take into account several critical aspects:
现在我们了解了统计数据的重要性,我们必须照顾好它们,并在维护中包括一项任务,以使这些对象保持良好状态。 在这里,我们需要考虑几个关键方面:
- Index Rebuild operation is updating index statistics. This is always and it is happening with 100 % sample. General mistake is to include update statistics task for all statistics after index rebuild. Not only we will do index statistics update twice, but we will also loose the “free” 100 % sampled stats update due to the index rebuild operation as SQL Server, by default, is doing this using a dynamically determined sample lower than 100 %. 索引重建操作正在更新索引统计信息。 这始终是事实,并且100%的样品都在发生这种情况。 一般错误是在索引重建后将所有统计信息包括在更新统计信息任务中。 我们不仅会进行两次索引统计信息更新,而且还会由于索引重建操作而放弃“免费”的100%采样统计信息更新,因为SQL Server默认情况下使用低于100%的动态确定样本来进行此操作。
- If we are doing some kind of a “clever” maintenance based on the fragmentation of our indexes, we have to take care of the statistics attached to the indexes being maintained with Reorganize operation. Index Reorganize does not update index statistics and they might become stale in the future. 如果我们基于索引的碎片进行某种“灵巧”的维护,则必须注意通过Reorganize操作维护的索引所附带的统计信息。 索引重新组织不会更新索引统计信息,将来它们可能会过时。
Regardless of the index operations being done on our SQL Server, we must make sure that column statistics are being updated as well.
无论在我们SQL Server上执行什么索引操作,我们都必须确保同时更新列统计信息。
Starting with SQL Server 2008 R2 SP 2, we have “modification_counter” column part of “sys.dm_db_stats_properties” which we can utilize to determine if there have been any rows modification since the most recent statistics update. This might be very useful in the following scenario:
从SQL Server 2008 R2 SP 2开始,我们在“ sys.dm_db_stats_properties”中具有“ modification_counter”列部分,我们可以利用该部分来确定自最近的统计信息更新以来是否进行了任何行修改。 在以下情况下,这可能非常有用:
- Create a “clever” maintenance to rebuild or reorganize indexes based on their fragmentation 创建“智能”维护,以根据索引的碎片重建或重新组织索引
-
- If we reorganize an index, the second task will update its statistics (if there have been changes in the data, of course) 如果我们重新组织索引,第二个任务将更新其统计信息(当然,如果数据发生了变化)
- If we rebuild an index, the second task will skip index statistics update for this particular index (unless there have been changes between the rebuild and statistics update operations) 如果我们重建索引,则第二项任务将跳过该特定索引的索引统计信息更新(除非重建和统计信息更新操作之间有更改)
- We make sure that columns statistics are being taken care of 我们确保列统计信息得到处理
完整性检查 ( Integrity checks )
Last but not least, we will take a look the database integrity and consistency checks. This is another task that must be part of your regular maintenance. Nowadays we are all aware how critical the integrity of databases is, but we tend to schedule it by default without any additional tweaks. Of course, this is the better situation compared to the one where we do not have this at all. However, we need to customize this in order to take the maximum out of it.
最后但并非最不重要的一点,我们将看一下数据库的完整性和一致性检查。 这是常规维护中必须包含的另一项任务。 如今,我们都知道数据库完整性的重要性,但默认情况下,我们倾向于对其进行调度,而无需进行任何其他调整。 当然,与我们完全没有这种情况相比,这是更好的情况。 但是,我们需要对其进行自定义,以便最大程度地利用它。
Here are my tips how to reduce the duration of your integrity checks and still rely on them:
这是我的技巧,如何减少完整性检查的持续时间并仍然依赖它们:
- Use always with NO_INFOMSGS – it is less likely that you will miss a critical message and this can reduce the execution time of the integrity check (the effect is greater on small databases). 始终与NO_INFOMSGS一起使用–您不太可能错过关键消息,这可以减少完整性检查的执行时间(对小型数据库影响更大)。
- Use with PHYSICAL_ONLY – DATA_PURITY checks are taking a significant portion of the whole duration of the CHECKDB operation so it is a must to skip it for very large databases. Note that you still have to plan a complete CHECKDB operation once in a while – for example, every one month. 与PHYSICAL_ONLY一起使用– DATA_PURITY检查占用了CHECKDB操作整个过程的很大一部分,因此对于非常大的数据库,必须跳过它。 请注意,您仍然必须偶尔计划一次完整的CHECKDB操作-例如,每个月一次。
- Offload the checks to a secondary server – this is a great option, but unfortunately, the only one that gives you 100% guarantee is to have a backup of your production database restored on another server and run integrity checks there. HA/DR solutions (like AlwaysOn, SAN mirroring, snapshot on mirrored database) are not that trustworthy as you are involving two different storage subsystems. 将检查卸载到辅助服务器上–这是一个不错的选择,但是不幸的是,唯一可以为您提供100%保证的方法是在另一台服务器上还原生产数据库的备份并在其中运行完整性检查。 HA / DR解决方案(例如AlwaysOn,SAN镜像,镜像数据库上的快照)不那么值得信赖,因为您涉及两个不同的存储子系统。
- TF 2549 – instruct SQL to treat each database file as residing on a unique disk. The idea is that there is an internal list of pages that SQL has to read during this process and the list is being built per unique database drives across all files. SQL Server is making the decision based on the drive letter which means in a classic situation where you have, for example, 4 data files, residing on different LUNs, but on the same root drive, you will not take advantage of the fact that your files are actually scattered. TF 2549 –指示SQL将每个数据库文件都视为驻留在唯一磁盘上。 这个想法是,在此过程中有一个内部页面列表,SQL必须读取这些页面,并且该列表是针对所有文件中唯一的数据库驱动器构建的。 SQL Server根据驱动器号做出决定,这意味着在经典情况下,例如,您有4个数据文件,它们位于不同的LUN上,但在同一根驱动器上,因此您将无法利用以下事实:文件实际上是分散的。
- TF 2562 – at the cost of higher TEMPDB utilization (usually up to 10 % of the size of the database), SQL Server is optimizing the integrity check process by treating it as one batch and reducing the latch contention (DBCC_MULTIOBJECT_SCANNER latch). Note that this flag is part of the SQL 2012 code so you do not have to turn it on, if you are running on this SQL or higher. TF 2562 –以更高的TEMPDB利用率(通常高达数据库大小的10%)为代价,SQL Server通过将其视为一批并减少闩锁争用(DBCC_MULTIOBJECT_SCANNER闩锁)来优化完整性检查过程。 请注意,此标志是SQL 2012代码的一部分,因此,如果您正在此SQL或更高版本上运行,则不必打开它。
- TF 2528 – CHECKDB is multi-threaded by default, but only in Enterprise edition. It is not unlikely to detect CPU contentions caused by your integrity checks. By using this TF, you can turn off the parallelism for CHECKDB. TF 2528 –默认情况下,CHECKDB是多线程的,但仅在企业版中。 不太可能检测到由完整性检查引起的CPU争用。 通过使用此TF,可以关闭CHECKDB的并行性。
With using PHYSICAL_ONLY and TF 2549, 2562, we have managed to reduce the time for the integrity check of a 10 TB database to around 5 hours! This was a great achievement as prior to these optimizations, the CHECKDB has been finishing for around 24 hours.
通过使用PHYSICAL_ONLY和TF 2549、2562,我们成功地将10 TB数据库的完整性检查时间减少到大约5小时! 这是一个伟大的成就,因为在进行这些优化之前,CHECKDB已经完成了大约24小时。
自CTP 2.4开始,GUI中新的维护计划选项 ( New maintenance plans options in the GUI since CTP 2.4 )
Before SQL Server 2016 CPT 2.4, our options for creating maintenance plans via the GUI in SSMS have been very limited. Usually, in order to create a good, reliable maintenance, we needed to implement it dynamically with special scripts. This is still the best option that gives you maximum customization, but now some of the restrictions have been lifted and there are new options in the GUI:
在SQL Server 2016 CPT 2.4之前,我们用于通过SSMS中的GUI创建维护计划的选项非常有限。 通常,为了创建良好,可靠的维护,我们需要使用特殊脚本动态地实现它。 这仍然是为您提供最大程度自定义的最佳选择,但是现在一些限制已解除,GUI中有新的选择:
Integrity checks now have PHYSICAL_ONLY and TABLOCK options
完整性检查现在具有PHYSICAL_ONLY和TABLOCK选项
Tons of new stuff in Index rebuild: MAXDOP, WAIT_AT_LOW_PRIORITY, Fragmentation scan type, % Fragmentation, Page count and if the Index has been used:
索引中大量新内容将重建:MAXDOP,WAIT_AT_LOW_PRIORITY,碎片扫描类型,碎片百分比,页数以及是否已使用索引:
As SQL administrators, we cannot deny that we are in love with the SSMS and GUI Since CTP 2.4 of SQL Server 2016, we have the ability to produce good enough maintenance plans with only several clicks and without the need to write complex customized solutions.
作为SQL管理员,我们不能否认我们爱上了SSMS和GUI自SQL Server 2016的CTP 2.4以来,我们只需单击几下即可生成足够好的维护计划,而无需编写复杂的自定义解决方案。
Hope the material covered will be useful for you and, at least, some of the suggestions will be utilized to improve your current maintenance setup Keep in mind that it is important to customize your maintenance it as this might save you a lot of troubles and sleepless nights.
希望本文涵盖的内容对您有用,并且至少会利用一些建议来改进您当前的维护设置。请记住,自定义维护很重要,因为这可以为您节省很多麻烦和失眠晚上。
Thanks for reading!
谢谢阅读!
翻译自: https://www.sqlshack.com/tips-and-tricks-for-sql-server-database-maintenance-optimization/















 1736
1736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









