



 本文介绍了SQL Server查询优化的重要性,特别是如何利用动态管理视图来发现和处理缺失索引问题。通过定期收集缺失索引数据并分析,可以主动解决性能瓶颈,避免等待用户投诉。作者警告过量索引也可能导致性能下降,并提供了一些判断何时添加或忽略索引的准则。最后,文章预告将通过合并索引使用统计和缺失索引统计,创建一个定期更新的推荐索引集。
本文介绍了SQL Server查询优化的重要性,特别是如何利用动态管理视图来发现和处理缺失索引问题。通过定期收集缺失索引数据并分析,可以主动解决性能瓶颈,避免等待用户投诉。作者警告过量索引也可能导致性能下降,并提供了一些判断何时添加或忽略索引的准则。最后,文章预告将通过合并索引使用统计和缺失索引统计,创建一个定期更新的推荐索引集。
sql错误索引中丢失
描述 (Description)
Indexing is key to efficient query execution. Determining what indexes are needed to satisfy production needs is often a game of cat and mouse in which we are forced to react to performance problems after they are brought to our attention. Being able to proactively monitor index needs and respond effectively before complaints are received can save us immense time while preventing costly performance messes.
索引是有效执行查询的关键。 确定满足生产需求所需的指标通常是一场猫捉老鼠的游戏,在这种情况下,我们不得不在引起性能问题后对性能问题做出React。 能够主动监控索引需求并在收到投诉之前做出有效响应,可以为我们节省大量时间,同时又避免了代价高昂的性能混乱。
This is the second part in a series that will culminate in an automated index analysis solution, allowing you to understand index usage proactively, rather than waiting for things to break in order to resolve them.
这是该系列文章的第二部分,该文章将以自动化的索引分析解决方案为高潮,使您可以主动了解索引的使用,而不必等待事情破裂来解决它们。
介绍 (Introduction)
Typically, our notice of missing indexes arrives via an end user or developer who has discovered some aspect of the application running unusually slowly. We then can trace the latency to a specific query that would benefit greatly from an index and work through the process to create, test, and implement the new index.
通常,我们会通过最终用户或开发人员发现丢失索引的通知,他们发现应用程序某些方面的运行异常缓慢。 然后,我们可以将延迟跟踪到特定查询,该查询将从索引中受益匪浅,并逐步完成创建,测试和实施新索引的过程。
This process is inherently reactive and requires us to wait until someone experiences unacceptable latency in order for us to respond. As a result, we are often put into rushed situations in which we are fighting performance problems rather than creating these indexes in a proactive manner.
这个过程本质上是被动的,需要我们等到有人遇到不可接受的延迟后才能做出响应。 结果,我们经常陷入匆忙的境地,在这种情况下,我们正在解决性能问题,而不是主动创建这些索引。
There are many reasons why we do not create these indexes up-front and are forced to discover their absence at a later time:
我们没有预先创建这些索引并在以后的时间中发现它们不存在的原因有很多:
- The size of data within a table has increased greatly over time, slowing down query performance. 表中的数据大小随着时间的推移已大大增加,从而降低了查询性能。
- The application has new queries or variants on existing queries that are not satisfied by existing indexes. 该应用程序具有新查询或现有索引无法满足的现有查询的变体。
- QA efforts did not take into account production-like data, so the need for an index never came to our attention. 质量检查工作并未考虑类似生产的数据,因此对索引的需求从未引起我们的注意。
- Performance and scalability were not taken into account in the development process. 在开发过程中未考虑性能和可伸缩性。
- The index previously existed, but we removed it previously for some reason. 该索引以前存在,但由于某种原因我们之前已将其删除。
For these reasons and more, we end up with performance holes and a desire to fill them as seamlessly as possible. Given the choice, we’d rather tune performance before anyone notices a problem, rather than wait for an angry user to ask why their app is slow. Therein lies the solution that will be presented in this article!
由于这些原因以及更多原因,我们最终会遇到性能漏洞,并希望尽可能无缝地填补这些漏洞。 如果有选择,我们宁愿在任何人注意到问题之前调整性能,而不是等待生气的用户问为什么他们的应用程序运行缓慢。 其中包含将在本文中介绍的解决方案!
什么是缺失索引 (What Is a Missing Index)
Whenever TSQL is executed, the query optimizer needs to generate an execution plan in order to SQL Server to know how to go about completing the request. If during this process there is an operation that would benefit greatly from an index that does not currently exist, you’ll be presented with an additional line of feedback when executed:
每当执行TSQL时,查询优化器都需要生成一个执行计划,以使SQL Server知道如何完成请求。 如果在此过程中有一项操作将从当前不存在的索引中受益匪浅,那么在执行该操作时,系统会为您提供附加的反馈:
SELECT
BusinessEntityID,
FirstName,
Title
FROM Person.Person
WHERE FirstName LIKE 'Ed%';
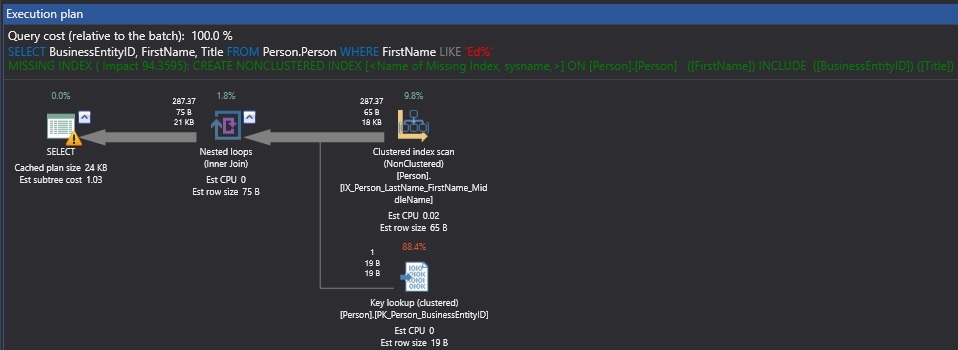
When our query executed against AdventureWorks, the execution plan, in addition to telling us how the query was executed, also provides a missing index warning, shown in green text in between the query text and the execution plan. The full text of this suggestion is as follows:
当针对AdventureWorks执行查询时,执行计划除了告诉我们查询的执行方式外,还会提供缺失的索引警告,该警告在查询文本和执行计划之间以绿色文本显示。 该建议的全文如下:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>]
ON [Person].[Person] ([FirstName])
INCLUDE ([BusinessEntityID],[Title]);
Based on our query and the resulting performance, SQL Server has suggested an index on FirstName with include columns on BusinessEntityID and Title.
根据我们的查询和所得到的性能,SQL Server建议在FirstName上创建索引,并在BusinessEntityID和Title上包含include列。
Missing index suggestions do not require us to execute queries manually within SQL Server Management Studio. This process occurs in the background regularly, even if we are not monitoring it. SQL Server provides a handful of dynamic management views that can provide insight into suggested missing indexes:
缺少索引建议不需要我们在SQL Server Management Studio中手动执行查询。 即使我们不监视它,该过程也会在后台定期发生。 SQL Server提供了一些动态管理视图,这些视图可以洞悉建议的缺失索引:
- Sys.dm_db_missing_index_details: Provides information on the table affected, and suggested index columns. Sys.dm_db_missing_index_details :提供有关受影响的表的信息以及建议的索引列。
- Sys.dm_db_missing_index_group_stats: Returns info on the query cost, number of seeks the index would have resulted in, and some other metrics to gauge effectiveness. Sys.dm_db_missing_index_group_stats :返回有关查询成本的信息,将导致索引的搜索次数以及其他一些衡量有效性的指标。
- Sys.dm_db_missing_index_groups: Provides an Sys.dm_db_missing_index_groups :提供一个index_handle, which can be used for joining to other views. index_handle ,可用于加入其他视图。
These views are reset upon SQL Server restart and can be checked anytime in order to gauge what potential indexes SQL Server has been collecting data on. To view this data, we can run a query that joins these views together with sys.databases, which returns the database name that the index would be applicable to:
这些视图在SQL Server重新启动时被重置,并且可以随时检查以查看SQL Server收集数据的潜在索引。 要查看此数据,我们可以运行将这些视图与sys.databases结合在一起的查询,该查询返回该索引将适用于的数据库名称:
SELECT
databases.name AS [Database_Name],
dm_db_missing_index_details.statement AS Table_Name,
dm_db_missing_index_details.Equality_Columns,
dm_db_missing_index_details.Inequality_Columns,
dm_db_missing_index_details.Included_Columns AS Include_Columns,
dm_db_missing_index_group_stats.Last_User_Seek,
dm_db_missing_index_group_stats.Avg_Total_User_Cost,
dm_db_missing_index_group_stats.Avg_User_Impact,
dm_db_missing_index_group_stats.User_Seeks
FROM sys.dm_db_missing_index_groups
INNER JOIN sys.dm_db_missing_index_group_stats
ON dm_db_missing_index_group_stats.group_handle = dm_db_missing_index_groups.index_group_handle
INNER JOIN sys.dm_db_missing_index_details
ON dm_db_missing_index_groups.index_handle = dm_db_missing_index_details.index_handle
INNER JOIN sys.databases
ON databases.database_id = dm_db_missing_index_details.database_id;
The output of this query shows the four indexes that have been suggested on my laptop since it was last restarted:
该查询的输出显示自上次重新启动以来在笔记本电脑上建议的四个索引:

Included in this list is the query on Person.Person that we ran earlier, as well as a few other index suggestions on the same table, and an index relating to my baseball statistics database. A busy production server will likely have far more index suggestions, as well as a more significant volume of user seeks that could be applied to them.
此列表中包括我们先前运行的Person.Person查询,以及同一表上的其他一些索引建议,以及与我的棒球统计数据库有关的索引。 繁忙的生产服务器可能会具有更多的索引建议,以及可应用于它们的大量用户搜索。
From these results, we can see exactly what SQL Server was suggesting. Equality columns represent the columns in the index that would have been used for an equality operation, such as “=” or “IN”. Inequality columns are those that would have been used to support a query using operations such as “<>”, “>”, or “NOT IN”. Include columns are those that would help a query execute with minimal (or no) key lookups by maintaining additional columns for quick retrieval when needed.
从这些结果中,我们可以确切地看到SQL Server的建议。 相等列表示索引中将用于相等操作的列,例如“ =”或“ IN”。 不等式列是使用诸如“ <>”,“>”或“ NOT IN”之类的操作来支持查询的列。 包含列是那些通过维护其他列以便在需要时快速检索来帮助查询以最少(或没有)键查找执行的列。
Our next steps would be to evaluate each index and determine if the underlying queries are important enough to warrant implementing the new index.
我们的下一步将是评估每个索引并确定基础查询是否足够重要以保证实现新索引。
缺少索引指标集合 (Missing Index Metrics Collection)
Missing index data is most useful when it is collected regularly, aggregated, and reported on. We can only make intelligent decisions in a production environment when we have a consistent set of data that spans a reasonable amount of time. We also want this data to be resilient against server restarts (planned or otherwise). If a server is shut down for maintenance, I don’t want all of my index metrics to be gone forever!
定期收集,汇总和报告丢失的索引数据最有用。 只有在合理的时间内获得一致的数据集,我们才能在生产环境中做出明智的决策。 我们还希望该数据可抵抗服务器重启(计划的或其他方式)。 如果为了维护而关闭服务器,我不希望所有索引指标永远消失!
The answer to this problem is to build a process that collects missing index data and stores it in permanent tables. From here, we can report on it at our leisure and know that our data set is as complete as possible. To do this, we will build a handful of dedicated database objects to store and view this data, and a collection process that regularly populates and maintains this data. Our goal is for the process to be lightweight and resilient so that it requires as little intervention by us as possible.
该问题的答案是建立一个收集丢失的索引数据并将其存储在永久表中的过程。 从这里,我们可以在闲暇时报告它,并且知道我们的数据集尽可能完整。 为此,我们将构建一些专用的数据库对象来存储和查看此数据,并建立一个定期填充和维护此数据的收集过程。 我们的目标是使该过程轻巧,有弹性,以便我们需要尽可能少的干预。
To assist in collecting meaningful data, we will maintain tables of both detail and aggregate data. The detail data provides an exact copy of what is stored in the SQL Server dynamic management views. This data will be persisted for long enough that we can refer to it as needed in order to understand current missing index behavior.
为了帮助收集有意义的数据,我们将维护详细数据表和汇总数据表。 详细数据提供了SQL Server动态管理视图中存储的内容的精确副本。 该数据将保留足够长的时间,以便我们可以根据需要引用它,以了解当前缺少的索引行为。
The aggregate summary data will contain a running total of missing index data with a single row per index. The data in the table will be the all-time sum of all statistics. This allows us to understand how queries perform, even if a server or service is restarted. This data can lose usefulness after a major software release or other hardware/software change, and therefore it may be worthwhile to completely purge the summary data from time to time. Further aggregation or crunching of this data by week, month, quarter, or other metric is also possible, if that data would be useful.
汇总摘要数据将包含缺少的索引数据的运行总计,每个索引只有一行。 表中的数据将是所有统计数据的总和。 这使我们能够了解查询的执行方式,即使重新启动服务器或服务也是如此。 在主要软件版本或其他硬件/软件更改之后,此数据可能会失去用处,因此可能不时需要完全清除摘要数据。 如果该数据有用,则还可以按周,月,季度或其他指标对这些数据进行进一步汇总或处理。
To begin, here is our detail data table:
首先,这是我们的详细数据表:
CREATE TABLE dbo.Missing_Index_Details
( Missing_Index_Details_Id INT NOT NULL IDENTITY(1,1) CONSTRAINT PK_Missing_Index_Details PRIMARY KEY CLUSTERED,
Missing_Index_Details_Create_Datetime DATETIME NOT NULL,
[Database_Name] SYSNAME NOT NULL,
Table_Name VARCHAR(256) NOT NULL,
Equality_Columns VARCHAR(MAX) NULL,
Inequality_Columns VARCHAR(MAX) NULL,
Include_Columns VARCHAR(MAX) NULL,
Last_User_Seek DATETIME NOT NULL,
Avg_Total_User_Cost FLOAT NOT NULL,
Avg_User_Impact FLOAT NOT NULL,
User_Seeks BIGINT NOT NULL,
Index_Group_Handle INT NOT NULL,
Index_Handle INT NOT NULL
);
CREATE NONCLUSTERED INDEX IX_Missing_Index_Details_lastUserSeek ON dbo.Missing_Index_Details(Last_User_Seek);
This table contains a single row per missing index per run of our process. Missing_Index_Details_Create_Datetime lets us know from what point in time this data comes from. If the data collection process runs hourly, then we will end up with 24 rows per index per day. If run daily, then we would get one row per day. The index group handle and index handle are provided solely for research purposes as they allow us to return to the underlying DMVs and view any data we’d like easily. Cleaning up this table from time to time is important, and we won’t forget to include that in our data collection process.
该表在我们的流程每次运行中每个缺少的索引包含一行。 Missing_Index_Details_Create_Datetime让我们知道该数据来自什么时间点。 如果数据收集过程每小时运行一次,那么最终每个索引每天将有24行。 如果每天运行,那么我们每天将获得一行。 索引组句柄和索引句柄仅出于研究目的而提供,因为它们使我们能够返回到基础DMV并轻松查看我们想要的任何数据。 经常清理该表很重要,我们也不会忘记在我们的数据收集过程中包括该表。
With a comfy place to store our detail data, we can now create a table for our aggregate data:
现在有了一个方便的地方来存储我们的详细数据,我们现在可以为汇总数据创建一个表:
CREATE TABLE dbo.Missing_Index_Summary
( Missing_Index_Summary_Id INT NOT NULL IDENTITY(1,1) CONSTRAINT PK_Missing_Index_Summary PRIMARY KEY CLUSTERED,
[Database_Name] SYSNAME NOT NULL,
Table_Name VARCHAR(256) NOT NULL,
Equality_Columns VARCHAR(MAX) NOT NULL,
Inequality_Columns VARCHAR(MAX) NOT NULL,
Include_Columns VARCHAR(MAX) NOT NULL,
First_Index_Suggestion_Time DATETIME NOT NULL,
Last_User_Seek DATETIME NOT NULL,
Avg_Total_User_Cost FLOAT NOT NULL,
Avg_User_Impact FLOAT NOT NULL,
User_Seeks BIGINT NOT NULL,
User_Seeks_Last_Update BIGINT NOT NULL
);
CREATE NONCLUSTERED INDEX IX_Missing_Index_Summary_lastUserSeek ON dbo.Missing_Index_Summary(Last_User_Seek);
CREATE NONCLUSTERED INDEX IX_Missing_Index_Summary_databaseName_tableName ON dbo.Missing_Index_Summary([Database_Name], Table_Name);
This table contains a row per index. The last user seek, user cost, and user impact are whatever the most recent values were. User seeks is cumulative over time. The column User_Seeks_Last_Update will be set equal to whatever the last value that was collected. If the server is restarted, then counts will reset and knowing the last value allows us to quickly determine if that has happened or not. We could also track server restart time via server metrics or SQL Server system views, but the value check is reliable and would work under any conditions or versions of SQL Server.
该表每个索引包含一行。 最近的用户搜寻,用户成本和用户影响是最新值。 用户搜寻是随着时间累积的。 User_Seeks_Last_Update列将设置为等于上一次收集的值。 如果服务器重新启动,那么计数将重置,并且知道最后一个值使我们能够快速确定是否已发生。 我们还可以通过服务器指标或SQL Server系统视图跟踪服务器重新启动时间,但是值检查是可靠的,并且可以在任何条件或SQL Server版本下使用。
The view sys.dm_db_missing_index_columns can be used in order to generate a normalized list of columns that are referenced in the index data above. This dynamic management function takes the index_handle as a parameter and returns a row per column, with some additional details. I’ve left this out of our work as we have column lists, which can easily be broken apart or read with little effort on our part.
可以使用sys.dm_db_missing_index_columns视图生成上面索引数据中引用的列的规范化列表。 此动态管理功能将index_handle作为参数,并每列返回一行,并带有一些其他详细信息。 由于我们有列列表,因此我将其排除在工作之外,可以轻松地将其分解或花费很少的精力阅读。
With holding tables created, we can now create a stored procedure that collects and stores this data for us. The basic structure of the proc will be:
创建保持表后,我们现在可以创建一个存储过程,为我们收集和存储此数据。 proc的基本结构为:
- Delete any detail data older than an arbitrary date (your choice). 删除任何早于任意日期的详细数据(您的选择)。
- Missing_Index_Details. This helps us avoid collecting redundant data for indexes that do not see frequent change. Missing_Index_Details中的最后搜索时间。 这有助于我们避免为不经常更改的索引收集冗余数据。
- Collect all missing index details newer than the time identified above and dump them to a temporary table. This allows us to populate both target tables using a single, small data set, without the need to return to the DMVs. 收集所有丢失的索引详细信息,它们比上面确定的时间新,并将它们转储到临时表中。 这使我们可以使用单个较小的数据集来填充两个目标表,而无需返回DMV。
- Missing_Index_Details. Missing_Index_Details中 。
- Missing_Index_Summary by comparing the database, table, and column lists together in order to determine which indexes can and should be updated, or if a new index suggestion should be added. Missing_Index_Summary中,以确定可以和应该更新哪些索引,或者是否应该添加新的索引建议。
CREATE PROCEDURE dbo.Populate_Missing_Index_Data
@Retention_Period_for_Detail_Data_Days SMALLINT = 30,
@Delete_All_Summary_Data BIT = 0
AS
BEGIN
SET NOCOUNT ON;
DELETE Missing_Index_Details
FROM dbo.Missing_Index_Details
WHERE Missing_Index_Details.Last_User_Seek < DATEADD(DAY, -1 * @Retention_Period_for_Detail_Data_Days, CURRENT_TIMESTAMP);
IF @Delete_All_Summary_Data = 1
BEGIN
TRUNCATE TABLE dbo.Missing_Index_Summary;
END
DECLARE @Last_Seek_Time DATETIME;
SELECT
@Last_Seek_Time = MAX(Missing_Index_Details.Last_User_Seek)
FROM dbo.Missing_Index_Details;
IF @Last_Seek_Time IS NULL
BEGIN
SELECT @Last_Seek_Time = DATEADD(WEEK, -1, CURRENT_TIMESTAMP);
END
SELECT
databases.name AS [Database_Name],
dm_db_missing_index_details.statement AS Table_Name,
dm_db_missing_index_details.Equality_Columns,
dm_db_missing_index_details.Inequality_Columns,
dm_db_missing_index_details.Included_Columns AS Include_Columns,
dm_db_missing_index_group_stats.Last_User_Seek,
dm_db_missing_index_group_stats.Avg_Total_User_Cost,
dm_db_missing_index_group_stats.Avg_User_Impact,
dm_db_missing_index_group_stats.User_Seeks,
dm_db_missing_index_groups.Index_Group_Handle,
dm_db_missing_index_groups.Index_Handle
INTO #Missing_Index_Details
FROM sys.dm_db_missing_index_groups
INNER JOIN sys.dm_db_missing_index_group_stats
ON dm_db_missing_index_group_stats.group_handle = dm_db_missing_index_groups.index_group_handle
INNER JOIN sys.dm_db_missing_index_details
ON dm_db_missing_index_groups.index_handle = dm_db_missing_index_details.index_handle
INNER JOIN sys.databases
ON databases.database_id = dm_db_missing_index_details.database_id
WHERE dm_db_missing_index_group_stats.Last_User_Seek > @Last_Seek_Time;
INSERT INTO dbo.Missing_Index_Details
(Missing_Index_Details_Create_Datetime, [Database_Name], Table_Name, Equality_Columns, Inequality_Columns, Include_Columns, Last_User_Seek,
Avg_Total_User_Cost, Avg_User_Impact, User_Seeks, Index_Group_Handle, Index_Handle)
SELECT
CURRENT_TIMESTAMP AS Missing_Index_Details_Create_Datetime,
[Database_Name],
Table_Name,
Equality_Columns,
Inequality_Columns,
Include_Columns,
Last_User_Seek,
Avg_Total_User_Cost,
Avg_User_Impact,
User_Seeks,
Index_Group_Handle,
Index_Handle
FROM #Missing_Index_Details;
MERGE INTO dbo.Missing_Index_Summary AS Index_Summary_Target
USING (SELECT [Database_Name], Table_Name, ISNULL(Equality_Columns, '') AS Equality_Columns, ISNULL(Inequality_Columns, '') AS Inequality_Columns, ISNULL(Include_Columns, '') AS Include_Columns, MAX(Last_User_Seek) AS Last_User_Seek,
AVG(Avg_Total_User_Cost) AS Avg_Total_User_Cost, AVG(Avg_User_Impact) AS Avg_User_Impact, SUM(User_Seeks) AS User_Seeks
FROM #Missing_Index_Details GROUP BY [Database_Name], Table_Name, Equality_Columns, Inequality_Columns, Include_Columns) AS Index_Summary_Source
ON (Index_Summary_Source.Database_Name = Index_Summary_Target.Database_Name
AND Index_Summary_Source.Table_Name = Index_Summary_Target.Table_Name
AND Index_Summary_Source.Equality_Columns = Index_Summary_Target.Equality_Columns
AND Index_Summary_Source.Inequality_Columns = Index_Summary_Target.Inequality_Columns
AND Index_Summary_Source.Include_Columns = Index_Summary_Target.Include_Columns)
WHEN MATCHED
THEN UPDATE
SET Last_User_Seek = Index_Summary_Source.Last_User_Seek,
User_Seeks = CASE
WHEN Index_Summary_Source.User_Seeks = Index_Summary_Target.User_Seeks_Last_Update
THEN Index_Summary_Target.User_Seeks
WHEN Index_Summary_Source.User_Seeks >= Index_Summary_Target.User_Seeks
THEN Index_Summary_Source.User_Seeks + Index_Summary_Target.User_Seeks - Index_Summary_Target.User_Seeks_Last_Update
WHEN Index_Summary_Source.User_Seeks < Index_Summary_Target.User_Seeks
AND Index_Summary_Source.User_Seeks < Index_Summary_Target.User_Seeks_Last_Update
THEN Index_Summary_Target.User_Seeks + Index_Summary_Source.User_Seeks
WHEN Index_Summary_Source.User_Seeks < Index_Summary_Target.User_Seeks
AND Index_Summary_Source.User_Seeks > Index_Summary_Target.User_Seeks_Last_Update
THEN Index_Summary_Source.User_Seeks + Index_Summary_Target.User_Seeks - Index_Summary_Target.User_Seeks_Last_Update
END,
User_Seeks_Last_Update = Index_Summary_Source.User_Seeks,
Avg_Total_User_Cost = Index_Summary_Source.Avg_Total_User_Cost,
Avg_User_Impact = Index_Summary_Source.Avg_User_Impact
WHEN NOT MATCHED BY TARGET
THEN INSERT
VALUES (Index_Summary_Source.[Database_Name], Index_Summary_Source.Table_Name, Index_Summary_Source.Equality_Columns, Index_Summary_Source.Inequality_Columns,
Index_Summary_Source.Include_Columns, CURRENT_TIMESTAMP, Index_Summary_Source.Last_User_Seek, Index_Summary_Source.Avg_Total_User_Cost,
Index_Summary_Source.Avg_User_Impact, Index_Summary_Source.User_Seeks, Index_Summary_Source.User_Seeks);
DROP TABLE #Missing_Index_Details;
END
Two optional parameters are provided that allow for the maintenance of existing data:
提供了两个可选参数,用于维护现有数据:
- @Retention_Period_for_Detail_Data_Days indicates how many days of detail data to retain. The default is 30 days, but you can enter whatever is appropriate for your needs. The correct value is how far back you expect to need to look at point-in-time measurements. @Retention_Period_for_Detail_Data_Days指示要保留多少天的明细数据。 默认值为30天,但是您可以输入适合您需要的任何内容。 正确的值是您期望在时间点测量上需要回溯多长时间。
- @Delete_All_Summary_Data: When set to 1, the @Delete_All_Summary_Data :设置为1时, Missing_Index_Summary table is truncated. This may be useful if you’d like to begin collecting summary data anew due to there being very old data that is now irrelevant. Alternatively, we could trim the table of unneeded data ourselves, but I’d prefer an automated process to have as little manual intervention as possible Missing_Index_Summary表被截断。 如果由于现在已经不相关的非常旧的数据而想要重新开始收集摘要数据,这可能会很有用。 另外,我们可以自己修剪不需要的数据表,但我更喜欢自动化过程,尽量减少人工干预
With our collection stored procedure in place, let’s execute it and review the results:
使用我们的集合存储过程,让我们执行它并查看结果:
EXEC dbo.Populate_Missing_Index_Data @Retention_Period_for_Detail_Data_Days = 180, @Delete_All_Summary_Data = 0;
This completes relatively quickly, allowing us to query the 2 missing index tables directly:
这相对较快地完成,使我们可以直接查询2个缺失的索引表:
SELECT
*
FROM dbo.Missing_Index_Details;
SELECT
*
FROM dbo.Missing_Index_Summary;
Our data looks like this:
我们的数据如下所示:

Our data shows a total of 4 current index suggestions, three on AdventureWorks, and one on my BaseballStats database. As of right now, the summary and detail data are the same, as we have only run this process once, and I’ve not executed any additional queries since creating the process.
我们的数据总共显示了4条当前的索引建议,其中3条关于AdventureWorks ,1条关于我的BaseballStats数据库。 到目前为止,摘要数据和详细数据是相同的,因为我们只运行了一次此过程,而且自创建过程以来,我没有执行任何其他查询。
To provide a more interesting view, I’ll execute a variety of queries on AdventureWorks in order to cause some more missing index suggestions to be generated, including our test query from earlier. Once complete, we can execute the missing index collection proc and review the results. Here is the detail data that exists now:
为了提供一个更有趣的视图,我将在AdventureWorks上执行各种查询,以使生成更多缺少的索引建议,包括前面的测试查询。 完成后,我们可以执行缺少的索引收集过程并查看结果。 这是现在存在的明细数据:

We can see that five rows were added to the table. Any older queries that have not had any executions since the last run of our process are NOT included in the new data. This helps avoid redundant data, as well as save some space wherever this is being stored. This also allows us to easily query our data set for all missing indexes with a last seek time after a given point in time, and not get an excessively large data set returned to us.
我们可以看到在表中添加了五行。 自上次运行过程以来未执行任何旧查询,则不包含在新数据中。 这有助于避免冗余数据,并节省存储空间。 这也使我们能够轻松地在给定时间点之后的最后搜索时间查询所有缺失索引的数据集,而不会将过大的数据集返回给我们。
If maintaining a point-in-time to all detail data, including duplicate data, is important to you, then alter the stored procedure to remove the filter on “Last_User_Seek > @Last_Seek_Time”. This will allow each capture of detail data to include ALL suggested indexes, even if there is no new data to view on them.
如果维护所有细节数据(包括重复数据)的时间点对您来说很重要,请更改存储过程以删除“ Last_User_Seek> @Last_Seek_Time ”上的过滤器。 即使没有新数据可查看,这也将使每次捕获详细数据都包括所有建议的索引。
Now, let’s check the summary data for an aggregate view of our data:
现在,让我们检查摘要数据以获取我们数据的汇总视图:

Here we can see all 8 index suggestions since our process was created and initially executed. Missing indexes that have experienced additional seeks, such as the 3rd query against Person.Person have had their last user seek time updated, as well as total user seeks. New missing indexes have been added to the table and will be updated going forward, as needed. The column First_Index_Suggestion_Time allows us to understand when an index was first suggested, helping us gauge how long a problem may have existed. Last_User_Seek tells us when the last time was that this index was suggested.
在这里,我们可以看到自创建和最初执行流程以来的所有8个索引建议。 缺少索引的索引经历了额外的查找,例如针对Person.Person的 第三次查询已更新了其最后一个用户查找时间以及总的用户查找时间。 新的缺失索引已添加到表中,并将根据需要进行更新。 First_Index_Suggestion_Time列使我们能够了解何时首次建议索引,从而帮助我们确定问题可能存在多长时间。 Last_User_Seek告诉我们上次建议该索引的时间。
There is some data that is missing from our tables that would be handy to have for analysis or implementation:
我们的表中缺少一些便于分析或实施的数据:
- An index creation statement for the suggested index. 建议索引的索引创建语句。
- Counts of equality, inequality, and include columns. 相等,不平等和包括列的计数。
- An improvement measure that helps us better understand how useful an index would be. 一种改进措施,可以帮助我们更好地了解索引的有用性。
These can all be extrapolated from existing data, so they are ideal candidates for inclusion in views that access our data:
这些都可以从现有数据中推断出来,因此它们是包含在访问我们数据的视图中的理想候选者:
CREATE VIEW dbo.v_Missing_Index_Details
AS
SELECT
Missing_Index_Details_Create_Datetime,
[Database_Name],
REVERSE(SUBSTRING(REVERSE(Missing_Index_Details.Table_Name), 2, (CHARINDEX('[', REVERSE(Missing_Index_Details.Table_Name), 2)) - 2)) AS Table_Name,
'CREATE NONCLUSTERED INDEX [missing_index_' + CONVERT (VARCHAR, Missing_Index_Details.Index_Group_Handle) + '_' + CONVERT (VARCHAR, Missing_Index_Details.Index_Handle) + '_' +
LEFT(PARSENAME(REVERSE(SUBSTRING(REVERSE(Missing_Index_Details.Table_Name), 2, (CHARINDEX('[', REVERSE(Missing_Index_Details.Table_Name), 2)) - 2)), 1), 32) + ']' + ' ON ' + REVERSE(SUBSTRING(REVERSE(Missing_Index_Details.Table_Name), 2, (CHARINDEX('[', REVERSE(Missing_Index_Details.Table_Name), 2)) - 2)) +
' (' + ISNULL(Missing_Index_Details.Equality_Columns, '') + CASE WHEN Missing_Index_Details.Equality_Columns IS NOT NULL
AND Missing_Index_Details.Inequality_Columns IS NOT NULL
THEN ','
ELSE ''
END +
ISNULL(Missing_Index_Details.Inequality_Columns, '') + ')' + ISNULL(' INCLUDE (' + Missing_Index_Details.Include_Columns + ')', '') AS Index_Creation_Statement,
Missing_Index_Details.Avg_Total_User_Cost * (Missing_Index_Details.Avg_User_Impact / 100.0) * Missing_Index_Details.User_Seeks AS Improvement_Measure,
Equality_Columns,
Inequality_Columns,
Include_Columns,
ISNULL(LEN(Missing_Index_Details.Equality_Columns) - LEN(REPLACE(Missing_Index_Details.Equality_Columns, '[', '')), 0) AS Equality_Column_Count,
ISNULL(LEN(Missing_Index_Details.Inequality_Columns) - LEN(REPLACE(Missing_Index_Details.Inequality_Columns, '[', '')), 0) AS Inequality_Column_Count,
ISNULL(LEN(Missing_Index_Details.Include_Columns) - LEN(REPLACE(Missing_Index_Details.Include_Columns, '[', '')), 0) AS Included_Column_Count,
Last_User_Seek,
User_Seeks,
Index_Group_Handle,
Index_Handle
FROM dbo.Missing_Index_Details;
GO
CREATE VIEW dbo.v_Missing_Index_Summary
AS
SELECT
[Database_Name],
REVERSE(SUBSTRING(REVERSE(Missing_Index_Summary.Table_Name), 2, (CHARINDEX('[', REVERSE(Missing_Index_Summary.Table_Name), 2)) - 2)) AS Table_Name,
'CREATE NONCLUSTERED INDEX [missing_index_' + CONVERT (VARCHAR, Missing_Index_Summary.Missing_Index_Summary_Id) + '_' +
LEFT(PARSENAME(REVERSE(SUBSTRING(REVERSE(Missing_Index_Summary.Table_Name), 2, (CHARINDEX('[', REVERSE(Missing_Index_Summary.Table_Name), 2)) - 2)), 1), 32) + ']' + ' ON ' + REVERSE(SUBSTRING(REVERSE(Missing_Index_Summary.Table_Name), 2, (CHARINDEX('[', REVERSE(Missing_Index_Summary.Table_Name), 2)) - 2)) +
' (' + Missing_Index_Summary.Equality_Columns + CASE WHEN Missing_Index_Summary.Equality_Columns <> ''
AND Missing_Index_Summary.Inequality_Columns <> ''
THEN ','
ELSE ''
END +
ISNULL(Missing_Index_Summary.Inequality_Columns, '') + ')' + CASE WHEN Missing_Index_Summary.Include_Columns = ''
THEN ''
ELSE ' INCLUDE (' + Missing_Index_Summary.Include_Columns + ')'
END AS Index_Creation_Statement,
Missing_Index_Summary.Avg_Total_User_Cost * (Missing_Index_Summary.Avg_User_Impact / 100.0) * Missing_Index_Summary.User_Seeks AS Improvement_Measure,
Missing_Index_Summary.Equality_Columns,
Missing_Index_Summary.Inequality_Columns,
Missing_Index_Summary.Include_Columns,
ISNULL(LEN(Missing_Index_Summary.Equality_Columns) - LEN(REPLACE(Missing_Index_Summary.Equality_Columns, '[', '')), 0) AS Equality_Column_Count,
ISNULL(LEN(Missing_Index_Summary.Inequality_Columns) - LEN(REPLACE(Missing_Index_Summary.Inequality_Columns, '[', '')), 0) AS Inequality_Column_Count,
ISNULL(LEN(Missing_Index_Summary.Include_Columns) - LEN(REPLACE(Missing_Index_Summary.Include_Columns, '[', '')), 0) AS Included_Column_Count,
Missing_Index_Summary.First_Index_Suggestion_Time,
Missing_Index_Summary.Last_User_Seek,
Missing_Index_Summary.User_Seeks
FROM dbo.Missing_Index_Summary;
GO
When we select data from either view, 5 additional columns are added that provide the columns mentioned above. Here is what the summary view looks like now:
当我们从任一视图中选择数据时,将添加5个额外的列,以提供上述列。 这是摘要视图现在的样子:

The index creation statement provides a basis for what we could run in order to actually implement the suggested index:
索引创建语句为我们可以执行以实际实现建议的索引提供基础:
CREATE NONCLUSTERED INDEX [missing_index_8_SalesOrderHeader] ON SalesOrderHeader ([Status]) INCLUDE ([SalesOrderID], [RevisionNumber], [SalesOrderNumber], [CustomerID])
创建NONCLUSTERED索引[missing_index_8_SalesOrderHeader] ON SalesOrderHeader([状态])包括([SalesOrderID],[RevisionNumber],[SalesOrderNumber],[CustomerID])
While we should certainly rename the index to something meaningful, the remainder of the statement is accurate, assuming that you’d like to include all of the suggested columns. The column counts can be useful when determining how large or complex an index is. Adding an index on one column is not a difficult decision, whereas adding an index on 25 columns would be comparatively expensive!
尽管我们当然应该将索引重命名为有意义的名称,但是假设您希望包括所有建议的列,那么该语句的其余部分是准确的。 确定索引的大小或复杂度时,列数可能很有用。 在一个列上添加索引并不是一个困难的决定,而在25个列上添加索引将相对昂贵!
Lastly, the improvement measure is the product of the average total user cost of the query, the average user impact, and the total user seeks by the query. This measure allows us to assess a measure of query cost, execution frequency, and the impact of the index itself. This is by no means a perfect measure, but it is one way to filter and sort missing indexes in a helpful fashion.
最后,改进措施是查询的平均总用户成本,平均用户影响和查询所吸引的总用户的乘积。 该度量使我们可以评估查询成本,执行频率以及索引本身的影响的度量。 这绝不是一个完美的方法,但是它是一种以有用的方式筛选和排序缺失索引的方法。
The last step in our process would be to create a SQL Server Agent job, or some other process that calls the missing index stored procedure on a semi-regular basis. If your server doesn’t restart often, then daily is likely acceptable. If software releases occur at specific times, then having the job run immediately afterwards could be a useful way to pinpoint the appearance of new queries that are missing indexes. For more granularity, feel free to schedule hourly, or every N hours, based on your needs. All of the queries in this article are lightweight and will not impact any user data, as they read from system views only.
我们过程的最后一步是创建一个SQL Server代理作业,或其他一些过程以半规则方式调用丢失的索引存储过程。 如果服务器不经常重启,则每天可以接受。 如果在特定时间发布软件,则可以在以后立即运行作业,这是查明缺少索引的新查询的外观的有用方法。 要获得更详细的信息,请根据需要随时安排每小时或每N个小时安排一次。 本文中的所有查询都是轻量级的,并且不会影响任何用户数据,因为它们仅从系统视图中读取。
With a process that regularly collects missing index data, we can periodically check on it, report against it, and use those results to make smart indexing decisions to keep queries executing fast!
通过定期收集缺失索引数据的过程,我们可以定期对其进行检查,报告并使用这些结果做出明智的索引决策,以保持查询快速执行!
警告过多索引 (Caution Against Too Many Indexes)
Indexing is an area in which too much of a good thing is not good. Indexes improve read speeds for the queries they cover, but slow down writes on those columns. Any insert, delete, or update that touches columns in an index will also need to update the index with whatever change was made. A table with 10 indexes will require changes to any or all of them when the table is written to. Wide indexes also require more effort to maintain than narrow indexes. In addition, each index consumes valuable disk space.
索引是一个好东西太多的地方,不好的地方。 索引提高了它们所覆盖查询的读取速度,但减慢了这些列的写入速度。 任何涉及索引列的插入,删除或更新都将需要使用所做的任何更改来更新索引。 具有10个索引的表在写入表时将需要对其进行任何更改。 与窄索引相比,宽索引还需要更多的维护工作。 另外,每个索引消耗宝贵的磁盘空间。
Our goal when indexing our tables is to cover all of our most frequent/important queries as effectively as possible while not adding indexes unless they are truly needed. Adding every index suggestion that SQL Server provides will eventually result in our tables being large, bloated, and slow to write to. Index maintenance would also take an excessive amount of time. Given these facts, how do we choose which index suggestions to add or ignore? Here are some guidelines that can help when making these decisions:
为表建立索引时,我们的目标是尽可能有效地覆盖所有最频繁/重要的查询,而除非确实需要,否则不添加索引。 添加SQL Server提供的每个索引建议最终将导致我们的表很大,过大且写入速度很慢。 索引维护也将花费大量时间。 鉴于这些事实,我们如何选择要添加或忽略的索引建议? 以下是一些有助于做出这些决定的准则:
- How often is a query executed? If it’s a one-off report that will never run again, then an index is probably a waste of time. If it is an important piece of app code that runs a million times a day, then making sure it runs efficiently is probably worth the effort. 查询多久执行一次? 如果它是一次性报告,将永远不会再次运行,那么索引可能是浪费时间。 如果它是每天运行一百万次的重要应用代码,那么确保其高效运行可能值得付出努力。
- How expensive is a query? Are you scanning a table of a billion rows or are you scanning a table of 5? If the index would reduce logical reads from 10 million to 10, then it’s likely a useful one to consider! 查询有多贵? 您是在扫描十亿行的表还是在扫描5个表? 如果该索引将逻辑读取数从1000万减少到10,则可能是一个有用的考虑因素!
- Do any similar indexes already exist? If so, consider ways to combine them into one. If all that is needed is an additional include column to allow the existing index to cover the new query, then that effort is likely worth it. 是否存在任何类似的索引? 如果是这样,请考虑将它们组合为一个的方法。 如果只需要一个附加的include列,以允许现有索引覆盖新查询,那么付出这种努力就很值得。
- How long does the query take to execute? If a query is getting slow enough so as to be problematic for the end user, then an index to speed it up may be necessary. If an index would reduce runtime from 10ms to 8ms, then it might not be needed. If a query used to be fast and is getting slower over time, then this is your chance to get in front of a performance problem and proactively fix it, before anyone else notices a latency issue! 查询执行需要多长时间? 如果查询变得足够慢以至于对于最终用户来说是个问题,那么可能需要一个索引来加快查询速度。 如果索引将运行时间从10ms减少到8ms,则可能不需要它。 如果查询曾经很快并且随着时间的推移变得越来越慢,那么这是您有机会面对性能问题并主动进行修复的机会,然后其他人才注意到延迟问题!
Note that many of these suggestions involve performing additional research on the query that resulted in the index suggestion. This information can be gathered from the query plan cache, as well as from 3rd party monitoring tools. Additionally, solid knowledge of an application may make it easy to find areas in which queries are performing poorly and resulting in common index suggestions. To make an intelligent decision about whether an index should be added requires understanding the queries that it would cover. Only then can we be sure it’s the correct choice.
请注意,其中许多建议涉及对导致索引建议的查询进行其他研究。 这些信息可以从查询计划缓存被收集,以及来自第三方监控工具。 此外,对应用程序的扎实了解可能使查找查询执行不佳并导致常见索引建议的领域变得容易。 要就是否应添加索引做出明智的决策,需要了解它将涵盖的查询。 只有这样,我们才能确定它是正确的选择。
结论 (Conclusion)
Collecting, aggregating, and storing data on missing indexes from SQL Server’s dynamic management views allows us to keep track of new indexes that we should consider adding. Trending this data over time and keeping an extra close eye on it after any major software releases or events will allow us to be proactive in resolving performance issues before they become serious.
从SQL Server的动态管理视图中收集,聚合和存储丢失的索引上的数据,使我们能够跟踪应该考虑添加的新索引。 随时间推移对这些数据进行趋势分析,并在发布任何主要软件或事件后密切关注这些数据,将使我们能够在性能问题变得严重之前主动解决它们。
In the last article in this series, we will take index usage stats and missing index stats and create a data structure that allows us to combine all index suggestions into a single set of recommendations that are updated regularly. The result of this work will be a data set that can be used for monitoring, alerting, and reporting on index effectiveness with the desire to make indexing a proactive science, rather than a reactive frenzy to user complaints.
在本系列的最后一篇文章中,我们将获取索引使用情况统计信息和缺失的索引统计信息,并创建一个数据结构,该数据结构使我们可以将所有索引建议合并为一组定期更新的建议。 这项工作的结果将是一个数据集,该数据集可用于监视,警告和报告索引有效性,以期使索引成为一种积极主动的科学,而不是对用户抱怨的React狂热。
Other articles in this series:
本系列的其他文章:
- SQL Server Index Performance Tuning Using Built-in Index Utilization Metrics 使用内置索引利用率指标SQL Server索引性能调优
- SQL Server reporting – SQL Server Index Utilization Description SQL Server报告– SQL Server索引使用说明
资料下载 (Downloads)
翻译自: https://www.sqlshack.com/collecting-aggregating-analyzing-missing-sql-server-index-stats/
sql错误索引中丢失


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









