





数据库逻辑删除的sql语句
Database design and Logical Asseveration play a vital role in database performance and SQL Query optimization. Both have different parameters to make your database and the query accurate.
数据库设计和逻辑断言在数据库性能和SQL查询优化中起着至关重要的作用。 两者都有不同的参数以使您的数据库和查询准确。
数据库设计 (Database Design)
Database design plays an essential role in the database performance side. If the table structure is not in proper terms of data distribution and normalized way, then it could raise the significant challenge to change the structure as and when a problem comes in the picture. We will discuss a few parameters below to keep in mind when we design the database.
数据库设计在数据库性能方面起着至关重要的作用。 如果表结构没有按照正确的数据分布和规范化方式进行,那么当问题出现时,更改表结构可能会带来重大挑战。 在设计数据库时,我们将在下面讨论一些要记住的参数。
正常化 (Normalization)
Normalization is a technique to structure relational data in the form of schema and table to reduce the data redundancy and avoid the data anomaly. Data relation can be designed in 1NF, 2NF, 3NF as required with the nature of the information. Performance side, Normalization reduces IO operations with avoiding Insert/Update/Delete anomaly. Normalization of the database structure causes less amount of storage compared to unstructured data in the SQL Server database. You can understand it more over here, What is Database Normalization in SQL Server?
规范化是一种以架构和表的形式构造关系数据以减少数据冗余并避免数据异常的技术。 可以根据信息的性质在1NF,2NF,3NF中设计数据关系。 在性能方面,规范化避免了Insert / Update / Delete异常,从而减少了IO操作。 与SQL Server数据库中的非结构化数据相比,数据库结构的规范化导致较少的存储量。 您可以在这里进一步了解它, 什么是SQL Server中的数据库规范化?
For example:
例如:
We have a table with Merchant_stock with details of Item, Merchant, Available Quantity, Price. We normalized it to end the level with the lookup table references in the last normalized form.
我们有一个带有Merchant_stock的表格,其中包含商品,商家,可用数量,价格的详细信息。 我们对其进行归一化,以最后一次归一化形式的查找表引用结束该级别。
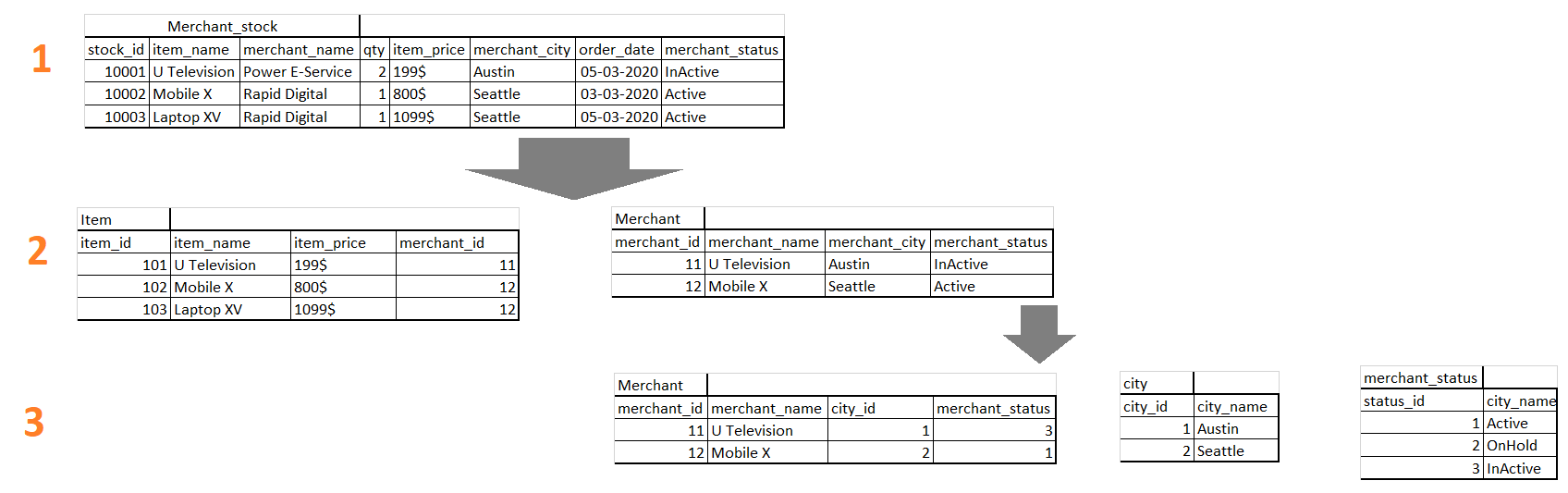
When a user wants details of Merchant, Merchant City, and Merchant status with the stock item, then the user can join multiple tables with the clause of Primary Key of the lookup tables.
当用户想要库存商品的商人,商人城市和商人状态的详细信息时,则用户可以将多个表与查找表的主键子句连接起来。
SELECT * --(Required Columns)
FROM Item AS I
INNER JOIN Merchant AS M ON I.merchant_id = M.merchant_id
INNER JOIN city AS C ON C.city_id = M.city_id
INNER JOIN merchant_status AS MS ON M.merchant_status = MS.status_id
End level normalization reduces the redundancy of the table. For example: a user wants to change the city or status for the merchant, (n) numbers of rows will be affected in the update statement with the first case of the above example table(merchant_stock). And in the second case, just one row will be affected in the Merchant table. Again status name change will update (n) rows in the second case. Therefore, in the third case, Integer reference is used for the merchant staus to avoid the update (n) rows in the table.
最终级别规范化减少了表的冗余。 例如:用户想要更改商家的城市或状态,在上述示例表的第一种情况下( 商人 _股票),(n)行数将在更新语句中受到影响。 在第二种情况下, Merchant表中将只影响一行。 在第二种情况下,状态名称更改将再次更新(n)行。 因此,在第三种情况下,Integer引用用于商户状态以避免表中的更新(n)行。
Static kinds of fields should be store in the lookup table always, and use the integer reference in the detail table is the best practice for the database design with the normalization.
静态类型的字段应始终存储在查找表中,并且在明细表中使用整数引用是通过规范化进行数据库设计的最佳实践。
指标 (Indexes)
Indexes are a reference to a quick search on the information. An index is a powerful tool to directly locate the target data rather than scanning the entire table and find the required row/s from the table. The use of a Clustered or Non-Clustered index is to make quick data matching patterns. The index improves the overall query performance with the wise use of it. SQL Server allows us to create an index with the number of options as below, and each one has a significant role in the Query performance.
索引是对信息进行快速搜索的参考。 索引是一种功能强大的工具,可直接定位目标数据,而不是扫描整个表并从表中查找所需的行。 使用聚簇索引或非聚簇索引是为了建立快速的数据匹配模式。 索引的明智使用提高了整体查询性能。 SQL Server允许我们创建一个具有以下选项数量的索引,每个选项在查询性能中都起着重要作用。
Index Options:
索引选项:
- ALLOW_PAGE_LOCKS ALLOW_PAGE_LOCKS
- ALLOW_ROW_LOCKS ALLOW_ROW_LOCKS
- DATA_COMPRESSION DATA_COMPRESSION
- DROP_EXISTING DROP_EXISTING
- FILLFACTOR 填充因子
- IGNORE_DUP_KEY IGNORE_DUP_KEY
- MAX_DURATION MAX_DURATION
- MAXDOP (max_degree_of_parallelism) MAXDOP(最大平行度)
- ONLINE 线上
- OPTIMIZE_FOR_SEQUENTIAL_KEY OPTIMIZE_FOR_SEQUENTIAL_KEY
- PAD_INDEX PAD_INDEX
- RESUMABLE 可恢复
- SORT_IN_TEMPDB SORT_IN_TEMPDB
- STATISTICS_INCREMENTAL STATISTICS_INCREMENTAL
- STATISTICS_NORECOMPUTE STATISTICS_NORECOMPUTE
表分区 (Table Partition)
SQL Server Table Partition is a way of distributing the data across the file system with the set of user-defined rules. When we are working on a large-sized table, the row filter option is also available; however, it is comparatively slower compared to Table Partition option. When we have used the Table Partition on the table, the Query filter will target the required portion of the table and return the result-set relatively quickly. A query filter will decide to focus on a particular piece or partition of the table by the partition schema. Proper use of the Table Partition and table design make excellent query performance on the large table.
SQL Server表分区是一种使用一组用户定义的规则在文件系统中分发数据的方法。 当我们处理大型表时,行过滤器选项也可用; 但是,与“表分区”选项相比,它相对较慢。 当我们在表上使用了表分区后,查询过滤器将以表的所需部分为目标并相对快速地返回结果集。 查询过滤器将决定通过分区模式将重点放在表的特定部分或分区上。 正确使用表分区和表设计可以使大型表具有出色的查询性能。
Users can add the File Group and Files with the database to use partition with the table. For example:
用户可以将文件组和文件与数据库一起添加,以对表使用分区。 例如:
--Adding File Group for a Database
ALTER DATABASE [Database Name]
ADD FILEGROUP [File Group name]
GO
--Adding File to File Group
ALTER DATABASE [Database Name]
ADD FILE
(
NAME = [PartJan],
FILENAME = '\C:\\...\DATA\File.ndf',
SIZE = 2048 KB,
MAXSIZE = UNLIMITED,
FILEGROWTH = 1024 KB
) TO FILEGROUP [File Group name]
GO
行平衡 (Row balancing)
Keeping rows in a single table for all clients is not the only solution in a product-based database solution. For the different geographic client base, data needs to be stored in the database according to the client geography to meet the latency issues and better SQL Query optimization. An application can be deployed on multiple locations to perform different activities; however, the database insert location will be single. Therefore, we can have a database set up with the same tables on multiple sites, and according to the client, geography requests can be served to the target database.
在所有基于客户端的表中保留行并不是在基于产品的数据库解决方案中的唯一解决方案。 对于不同的地理客户基础,需要根据客户地理位置将数据存储在数据库中,以满足延迟问题和更好SQL查询优化。 可以将应用程序部署在多个位置以执行不同的活动。 但是,数据库插入位置将是单个。 因此,我们可以在多个站点上建立一个具有相同表的数据库,并且根据客户端,可以将地理请求提供给目标数据库。
约束条件 (Constraints)
SQL Server Query Optimizer always checks for the foreign key and check constraints to prepare an efficient query execution plan, and each execution runs on the execution plan. SQL Server optimizer is too reliable and smart; if any constraint exists on the column, then the execution plan will skip the unnecessary part of data manipulation checks.
SQL Server Query Optimizer始终检查外键并检查约束以准备有效的查询执行计划,并且每次执行都在执行计划上运行。 SQL Server优化器过于可靠和聪明; 如果列上存在任何约束,则执行计划将跳过数据操作检查的不必要部分。
逻辑断言 (Logical Asseveration)
Logical Asseveration is a part of the query process and related performance parameters. Different query strategies with the most efficient way are the right solutions for SQL Query Optimization. Here we will discuss a few parameters below to keep in mind when we write a query, Procedure, Function, or Trigger.
逻辑断言是查询过程和相关性能参数的一部分。 以最有效的方式使用不同的查询策略是SQL查询优化的正确解决方案。 在这里,我们将讨论以下一些参数,以便在编写查询,过程,函数或触发器时牢记。
联接结构 (JOIN Structure)
JOIN structure with improper order of the table affects the query performance when several tables are present in joins with multiple conditions in the ‘Where’ clause. Query optimizer always refers to the table order in joins and changes it accordingly to prepare the execution plan. However, the optimizer will not follow all the possible orders with the query statement. Therefore, the developers have to try to order the table in the prepared query with one to one mapping. Improper order of tables in the join query consumes more resources in the server, and it affects other queries as well in the SQL Server.
当“ Where”子句中具有多个条件的联接中存在多个表时,表顺序不正确的JOIN 结构会影响查询性能。 查询优化器始终在联接中引用表顺序,并相应地对其进行更改以准备执行计划。 但是,优化器不会使用查询语句来遵循所有可能的顺序。 因此,开发人员必须尝试使用一对一映射在准备好的查询中对表进行排序。 联接查询中表的顺序不正确会消耗服务器中的更多资源,并且还会影响SQL Server中的其他查询。
关系表达 (Relation Expression)
Relational Expression in the WHERE clause is significant for SQL Query optimization. IF EXISTS, IF NOT EXISTS, NOT IN, IN, CASE WHEN, and many more conditions can be used in the WHERE clause. Sightless use of conditions makes a surprising execution time and execution plan too. Even NOT IN can be replaced by the LEFT JOIN with IS NULL condition as well, which is not known to many developers. What kind of Expression can be used, and when that depends on the nature and types of data? To make your query fast and optimized, it depends on the logic which is being written by the developer.
WHERE子句中的关系表达式对于SQL查询优化很重要。 如果存在,如果不存在,则不输入,输入,发生时以及在WHERE子句中可以使用更多条件。 盲目使用条件也使执行时间和执行计划变得令人惊讶。 甚至NOT IN也可以用具有IS NULL条件的LEFT JOIN替换,这对于许多开发人员而言并不为人所知。 可以使用哪种表达式,什么时候取决于数据的性质和类型? 为了使查询快速和优化,取决于开发人员正在编写的逻辑。
For example:
例如:
SELECT *
FROM TableA
WHERE COL1 NOT IN (SELECT COL1 FROM TableB)
Or
要么
SELECT A.*
FROM TableA AS A
LEFT JOIN TableB AS B ON A.COL1 = B.COL1
WHERE B.COL1 IS NULL
3.数据排序 (3. Data Sorting)
Data Sorting is an expensive part of the query execution in SQL Server. Users can avoid using unnecessary sorting in the SQL Server program because it stores the query result set into the buffer to sort it in particular order reference. Even a SQL Server index option provides an option to store data with the sorting, yet again it is the job of the query optimizer to make perfect query execution plan.
数据排序是SQL Server中查询执行的昂贵部分。 用户可以避免在SQL Server程序中使用不必要的排序,因为它将查询结果集存储到缓冲区中以按特定的顺序引用对其进行排序。 甚至SQL Server索引选项都提供了一种存储数据以进行排序的选项,再次,查询优化器的工作就是制定完美的查询执行计划。
For example: an Index is defined with the sorting column option, and rows returns from the table will be in order as well; however, SQL statement can have multiple fields in the ORDER BY clause. So, it could cause various issues to process the data to sort into the order of columns in the ORDER BY term. User needs to use required fields only to having data sorting in a particular result set only to avoid unnecessary data sorting in the procedure.
例如:使用排序列选项定义了索引,并且从表返回的行也将按顺序排列; 但是,SQL语句在ORDER BY子句中可以有多个字段。 因此,这可能会导致各种问题来处理数据以将它们排序为ORDER BY术语中的列顺序。 用户只需要在特定结果集中进行数据排序就可以使用必填字段,以避免在过程中进行不必要的数据排序。
SET选项 (SET Options)
When we are working on large-sized database or having good experience in SQL Query Optimization then definitely we could face issues like: Multiple execution plan for the single procedure in the SQL Server, Query or procedure will turn the execution faster in SSMS but not with the application, errors can be returned by the application for the procedure (Nested Procedure), but it works fine using SSMS, and many more issues can be resolved with the help of SET Options declaration in the SQL Server.
当我们在大型数据库上工作或在SQL查询优化方面有丰富的经验时,我们肯定会遇到以下问题:SQL Server中单个过程的多执行计划,查询或过程将使SSMS中的执行速度更快,而在在应用程序中,该应用程序可以为该过程(嵌套过程)返回错误,但是使用SSMS可以正常运行,并且可以借助SQL Server中的SET Options声明解决更多问题。
When we execute a query using SSMS, it uses SSMS default configured SET Options. Whether application uses SET Options, which are defined in the procedure or defined in the SQL Connection, therefore, there could be different ways of execution for the same procedure by the SQL Server query optimizer and to make multiple execution plans with a set of SET Options.
当我们使用SSMS执行查询时,它将使用SSMS默认配置的SET选项。 应用程序是使用过程中定义的SET选项还是SQL连接中定义的SET选项,因此,SQL Server查询优化器可以对同一过程执行不同的执行方式,并使用一组SET选项制定多个执行计划。
For example:
例如:
SET ARITHABORT ON statement is needed with the query statement or procedure 0when arithmetic operation is being used in the query.
查询中使用算术运算时,查询语句或过程0需要使用SET ARITHABORT ON语句。
隔离度 (ISOLATION LEVEL)
SQL Server ISOLATION LEVEL stands for the transaction Concurrency control and ACID (Atomicity, Consistency, Isolation, and Durability). ISOLATION LEVEL for each transaction determines the integration of data with the row-level locking for the users with different level and how long the transaction must hold locks to protect data against these changes. User can define the ISOLATION LEVEL in the database connections, and requests with the command of SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED / READ COMMITTED / REPEATABLE READ / SERIALIZABLE. Even the user can change the ISOLATION LEVEL on the same command in between execution for the different purposes to data visibility and SQL Query optimization.
SQL Server ISOLATION LEVEL代表事务并发控制和ACID(原子性,一致性,隔离性和持久性)。 每个事务的ISOLATION LEVEL决定具有不同级别用户的行级别锁定的数据集成,以及事务必须持有锁多长时间以保护数据免受这些更改。 用户可以在数据库连接中定义ISOLATION LEVEL,然后使用SET TRANSACTION ISOLATION LEVEL的命令请求READ UNCOMMITTED / READ COMMITTED / REPEATABLE READ / SERIALIZABLE 。 甚至用户也可以在执行之间的同一命令上更改ISOLATION LEVEL,以实现数据可见性和SQL查询优化的不同目的。
For example:
例如:
Users can use WITH(NOLOCK) with the table name in the query to fetch read uncommitted data. For the procedure, the SET statement can be written with ISOLATION LEVEL to get applied with all tables of the procedure.
用户可以在查询中将WITH(NOLOCK)与表名一起使用以读取读取的未提交数据。 对于该过程,可以使用ISOLATION LEVEL编写SET语句,以将其应用于该过程的所有表。
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
远程通话 (Remote Call)
Remote call a is cross SQL Server Query or procedure to requests or perform operation on the remote site. Users can perform any of INSERT / UPDATE or DELETE operations using remote queries with the help of Linked Server. Even user can JOIN the remote table on the local server database table as well. A remote query is not considered as a bad thing in the SQL Server; however, if we filter or manipulate the remote data into the local server that affects the query performance, for better query performance, a user can execute the remote procedure in the local server.
远程调用是跨SQL Server查询或过程来请求或在远程站点上执行操作。 用户可以在链接服务器的帮助下使用远程查询执行任何INSERT / UPDATE或DELETE操作。 甚至用户也可以在本地服务器数据库表上加入远程表。 在SQL Server中,远程查询不被认为是一件坏事。 但是,如果我们将远程数据过滤或处理到影响查询性能的本地服务器中,则为了获得更好的查询性能,用户可以在本地服务器中执行远程过程。
The remote procedure is a good option for the SQL Query optimization, write your logic in the procedure at the remote server end and execute that procedure with the Linked Server on the local SQL Server.
远程过程是SQL查询优化的一个不错的选择,可以在远程服务器端的过程中编写逻辑,然后与本地SQL Server上的链接服务器一起执行该过程。
结论 (Conclusion)
SQL Server Query optimization can be a difficult task, especially when dealing with a large database where even the minor change can have a negative impact on the existing query and database performance.
SQL Server查询优化可能是一项艰巨的任务,尤其是在处理大型数据库时,即使是很小的更改也会对现有查询和数据库性能产生负面影响。
The parameters discussed above are relevant to the database design and query writing. The product and database will be reliable and better as the above parameters are accurately defined and used in your database.
上面讨论的参数与数据库设计和查询编写有关。 由于以上参数已在您的数据库中准确定义和使用,因此产品和数据库将可靠且更好。
翻译自: https://www.sqlshack.com/database-design-and-logical-asseveration-for-sql-query-optimization/
数据库逻辑删除的sql语句
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









