





德鲁伊 oltp oltp
When creating a hash index in a memory optimized table we need to define a value for the bucket count. Think twice before set a random value, you may pay the price later… On this article we will explain the effects of a bad defined bucket count and how to monitor it.
在内存优化表中创建哈希索引时,我们需要为存储桶计数定义一个值。 设置随机值之前请三思而后行,您稍后可能会付出代价……在本文中,我们将解释定义的存储桶计数错误的后果以及如何对其进行监控。
After two articles we’ve reached the last key point to monitor on In-memory OLTP environments. We are talking about the BUCKET! And no…this is not related to the ice bucket challenge 🙂
在撰写了两篇文章之后,我们到达了监视内存中OLTP环境的最后一个关键点。 我们正在谈论桶! 不,这与冰桶挑战无关related
The purpose of monitor the bucket usage state is a performance matter and we will check it in detail later in this article. To bring some background, let’s review some points…
监视存储桶使用状态的目的是性能问题,我们将在本文后面详细检查。 为了带来一些背景,让我们回顾一些要点...
内存优化表上的索引 ( Indexes on memory optimized tables )
Every memory-optimize table must have, at least, one index and a maximum of 8 indexes (this is a limit of SQL Server 2014). As the data in memory is not stored in some specific order, the indexes are “connecting” the data through pointers, building a linked list of rows.
每个内存优化表必须至少具有一个索引,最多具有8个索引(这是SQL Server 2014的限制)。 由于内存中的数据未按特定顺序存储,因此索引通过指针“连接”数据,从而建立了行的链接列表。
With the introduction of the in-memory technology, two new types of index came on board:
随着内存技术的引入,出现了两种新的索引类型:
- RANGE indexes (Bw-tree indexes).RANGE索引 (Bw树索引)。
- HASH indexes.HASH索引 。
During this article, we will be focusing on Hash Indexes, where actually the bucket count should be provided and where the possible problem is present.
在本文中,我们将重点关注哈希索引,该索引实际上应提供存储区计数,并且可能存在问题。
哈希指数 ( Hash Index )
To describe a HASH Index in a simple sentence, we could say the following: “A hash index is a collection of buckets organized in an array “. And that’s pretty much this!
为了用一个简单的句子描述一个HASH索引,我们可以这样说:“哈希索引是存储在数组中的存储桶的集合”。 差不多就是这个!
This kind of index is optimized for point-lookup operations, unlike the range indexes.
与范围索引不同,此类索引针对点查找操作进行了优化。
When creating a hash index, we need to provide an index key. This index key will be used by a hash function which is going to generate a hash value and be mapped to a corresponding bucket in the hash index. The hash function is deterministic, therefore, for a single input value it will return (output) the same hash value. In other words, the same index key is always mapped to the same bucket in the hash index.
创建哈希索引时,我们需要提供索引键。 该索引键将由哈希函数使用,该哈希函数将生成哈希值并映射到哈希索引中的相应存储桶。 哈希函数是确定性的,因此,对于单个输入值,它将返回(输出)相同的哈希值。 换句话说,相同的索引键始终映射到哈希索引中的相同存储桶。
The following picture shows the relation between all the mentioned components: a certain index key is used as input by a hash function f(x) which is going to generate a hash value and assign this to a bucket in the hash index.
下图显示了所有提到的组件之间的关系:某个索引键用作哈希函数f(x)的输入,该函数将生成哈希值并将其分配给哈希索引中的存储桶。
We already introduced the word “bucket” in the previous explanation, and this is the point where we want to reach here. When creating a hash index, we need to provide a value for the BUCKET_COUNT as the following example – Note: remember that we need to create all the indexes when creating a table, so far this is the only option that we have…
在前面的说明中,我们已经引入了“ bucket”这个词,这就是我们想要达到的目的。 创建哈希索引时,我们需要为BUCKET_COUNT提供一个值,如下例所示–注意:请记住,创建表时我们需要创建所有索引,到目前为止,这是我们唯一的选择……
The value provided as bucket count is critical and needs to be well planned, as neither a HIGH or a LOW value are acceptable. To determine a correct value for the bucket count is not an easy task… Microsoft says that on most of the cases the best is set a value “between 1 and 2 times the number of distinct values in the index key”, but it depends…Each case is a case!
作为存储桶计数提供的值很关键,并且需要精心计划,因为HIGH或LOW值都不可接受。 要确定存储桶计数的正确值并非易事……Microsoft表示,在大多数情况下,最好将值设置为“索引键中不同值的数量的1到2倍之间”,但这取决于…每个案例都是案例!
For who is managing the SQL Server instance, monitor the current BUCKET UTILIZATION is essential, as we care about the server performance… As said before, the final user is our QoS indicator, if everything is performing well, our service is seen as good 🙂
对于谁来管理SQL Server实例,监视当前的BUCKET UTILIZATION是必不可少的,因为我们关心服务器的性能……如前所述,最终用户是我们的QoS指标,如果一切运行良好,我们的服务将被视为良好🙂
为什么存储桶计数如此重要? ( Why the bucket count is so important? )
To answer this question I usually make an analogy with a fisherman… Let’s pretend that a guy wake up and thinks “From now I’m going to leave the IT world and I want to be a fisherman! I’ll be rich selling fish!”.
要回答这个问题,我通常会比喻一个渔夫……让我们假装一个人醒来后想:“从现在开始,我要离开IT世界,我想成为一个渔夫! 我将有钱卖鱼!”。
As every newbie, he cast into the unknown and bought a thousand buckets in order to separate every species of fish in a single place. What an organized guy!!
作为每个新手,他都投掷了未知的东西,并购买了1000桶水桶,以便将各种鱼类分开放置在一个地方。 多么有组织的家伙!
On his first day, he was just learning and fished only a few different kinds of fish. Guess what happened? A lot of buckets were empty! But that’s ok… Was just the first day 🙂
在他的第一天,他只是学习并且只钓鱼了几种不同种类的鱼。 猜猜发生了什么事? 很多水桶都空了! 没关系...只是第一天day
However this overestimation cannot be ignored… He was having side-effects caused by the number of unused buckets. The logistic was not easy, as the place was packed of buckets… to reach a particular bucket, he needed to pass over a few of empty ones. This was making his business be slow.
但是,这种高估不容忽视……他由于未使用的存储桶数量而产生了副作用。 物流并不容易,因为这个地方挤满了水桶……要到达特定的水桶,他需要越过一些空的水桶。 这使他的生意变慢了。
The same happens with the hash index: a high number of buckets may slow down the operations, and we are also using memory space for nothing, as each bucket needs 8 bytes.
哈希索引也会发生同样的情况: 大量的存储桶可能会减慢操作速度,并且我们也没有使用内存空间 ,因为每个存储桶需要8个字节。
After some days, he realized that he was being very ambitious. He is just a greener… Why that much buckets? Maybe there aren’t even a thousand of distinguished species of fish on that place…
几天后,他意识到自己非常有野心。 他只是一个绿色的人...为什么要那么多水桶? 也许那个地方甚至没有上千种鱼类。
In the next day, he came with only 3 buckets, as usually he fishes only 3 different species of fish: Codfish, Salmon and Sardine (yes, this is a special place to fish :p ). How unlucky is this person…poor guy! Just that day he fished Codfish, Salmon, Sardine, Flounder and Herrings. Five different species! This day he even fished a tire…
第二天,他只带了3个桶,因为通常他只钓鱼3种不同的鱼:鳕鱼,鲑鱼和沙丁鱼(是的,这是钓鱼的特别地方:p)。 这个人真不幸……可怜的家伙! 就在那天,他钓鱼了鳕鱼,鲑鱼,沙丁鱼,比目鱼和鲱鱼。 五种不同的物种! 这一天他甚至钓鱼了一个轮胎……
What was the problem? He had only three buckets and 5 distinguished species of fish, so he had to mix two different species in the same bucket. When someone approached him to buy a certain fish, he needed to go to the bucket and start seeking for the correct fish. Not an efficient way to serve a customer, right?
怎么了 他只有三个水桶和5种不同的鱼类,因此他必须在同一桶中混合两种不同的鱼。 当有人找他买某种鱼时,他需要去找水桶,开始寻找正确的鱼。 不是一种有效的服务客户的方式,对吗?
Jumping again to the hash index, we have the same problem here. If we have less buckets than distinct values, we will have HASH COLISIONS. This means that for two, or more, key values we will have the same result. The same bucket will be reused for distinct keys and tis will generate performance problems.
再次跳转到哈希索引,这里我们有同样的问题。 如果存储桶的数量少于不同值的存储桶,则将有哈希散列。 这意味着对于两个或多个键值,我们将得到相同的结果。 相同的存储桶将被重复用于不同的键,并且tis将产生性能问题。
So, the moral of the story is that we need to set a value big enough to cover all the possibilities but extremely excessive, in order to avoid performance problems.
因此,这个故事的寓意是,我们需要设置一个足够大的值以涵盖所有可能性,但要考虑到过多的可能性,以避免出现性能问题。
如何监控? ( How to Monitor? )
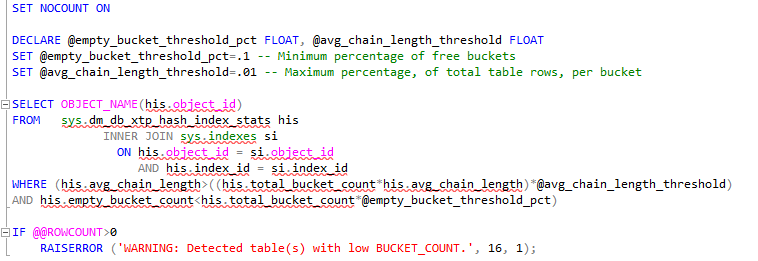
We can use t-sql to verify the state of the buckets, the DMV sys.dm_db_xtp_hash_index_stats is great to be used by this purpose:
我们可以使用t-sql来验证存储桶的状态,DMV sys.dm_db_xtp_hash_index_stats非常适合用于此目的:
翻译自: https://www.sqlshack.com/memory-oltp-three-key-points-entertain-watchdog-bucket-count/
德鲁伊 oltp oltp
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









