





行存储索引改换成列存储索引
Data compression is required to reduce database storage size as well as improving performance for the existing data. SQL Server 2008 introduced Data compression as an enterprise version feature. Further to this, SQL Server 2016 SP1 and above supports data compression using the standard edition as well.
需要数据压缩以减小数据库存储大小以及提高现有数据的性能。 SQL Server 2008引入了数据压缩作为企业版功能。 除此之外,SQL Server 2016 SP1和更高版本还支持使用标准版的数据压缩。
As per Microsoft docs, SQL Server 2017 and Azure SQL Database support row and page compression for rowstore tables and indexes, and supports columnstore and columnstore archival compression for columnstore tables and indexes.
根据Microsoft 文档 ,SQL Server 2017和Azure SQL数据库支持行存储表和索引的行和页面压缩,并支持列存储表和索引的列存储和列存储档案压缩。
We used to analyze the objects using the stored procedure sp_estimate_data_compression_savings. This procedure gives the estimated object size of the object after the specified compression. Until SQL Server 2017, we can estimate indexes, indexed views, heaps using this procedure.
我们曾经使用存储过程sp_estimate_data_compression_savings分析对象。 此过程给出指定压缩后对象的估计对象大小。 在SQL Server 2017之前,我们可以使用此过程估算索引,索引视图,堆。
In my previous article, Columnstore Index Enhancements in SQL Server 2019 – Part 1, we learned Columnstore index stats update in clone databases. SQL Server 2019 also provides enhancement to sp_estimate_data_compression_savings. In this article, we will explore the benefit out of it.
在我之前的文章SQL Server 2019中的Columnstore索引增强-第1部分中 ,我们了解了克隆数据库中的Columnstore索引统计信息更新。 SQL Server 2019还提供了对sp_estimate_data_compression_savings的增强。 在本文中,我们将探讨从中受益。
Syntax for sp_estimate_data_compression_savings is as below:
sp_estimate_data_compression_savings的语法如下:
sp_estimate_data_compression_savings
[ @schema_name = ] 'schema_name'
, [ @object_name = ] 'object_name'
, [@index_id = ] index_id
, [@partition_number = ] partition_number
, [@data_compression = ] 'data_compression'
[;]
- @schema_name: Schema of the object(table,index) @schema_name:对象的架构(表,索引)
- @object_name: Name of the table or indexed views @object_name:表或索引视图的名称
- @index_id: we need to specify the ID of the index. If there is no index on the table, we can specify 0 or NULL @index_id:我们需要指定索引的ID。 如果表上没有索引,我们可以指定0或NULL
- @partition_number: it is the partition number of the object. If there is no index, we need to specify NULL in this value as well @partition_number:它是对象的分区号。 如果没有索引,我们也需要在该值中指定NULL
- COLUMNSTORE, or COLUMNSTORE或COLUMNSTORE_ARCHIVE in SQL Server 2019 COLUMNSTORE_ARCHIVE
When we create the columnstore index, we specify the data compression method to apply. There are two kinds of data compression applied to the columnstore index.
创建列存储索引时,我们指定要应用的数据压缩方法。 列存储索引有两种数据压缩。
- COLUMNSTORE: It is the default compression option is the default and specifies to compress data with the columnstore compression
- COLUMNSTORE :这是默认的压缩选项,是默认选项,它指定使用列存储压缩来压缩数据
- COLUMNSTORE_ARCHIVE: we can compress data further by using this option. This is useful to compress data that is used very less frequent. This type of compression takes extra system resources in terms of CPU and Memory
- COLUMNSTORE_ARCHIVE :我们可以使用此选项进一步压缩数据。 这对于压缩很少使用的数据很有用。 这种类型的压缩会占用CPU和内存方面的额外系统资源
Until SQL Server 2017, sp_estimate_data_compression_savings works for row or page store data compression. This actually takes a sampling of the source object pages and creates them in the tempdb using the specified compression. Now we have two objects- source and the sampling object in tempdb. Both the objects are compared to calculate the estimated size of the object after compression.
在SQL Server 2017之前,sp_estimate_data_compression_savings可用于行或页面存储数据压缩。 实际上,这将对源对象页面进行采样,并使用指定的压缩在tempdb中创建它们。 现在,在tempdb中有两个对象-源和采样对象。 比较两个对象以计算压缩后对象的估计大小。
In SQL Server 2019, this procedure works differently for the columnstore a columnstore_archive data compression options. It actually creates a new columnstore index with the specified data compression state columnstore or columnstore_archive. Therefore, in SQL Server 2019, we compare with an equivalent columnstore object. The type of the source object defines the destination columnstore index. The below table shows the mapping between source and reference object if data compression state is columnstore or columnstore_archive.
在SQL Server 2019中,此过程对于columnstore和columnstore_archive数据压缩选项的工作方式不同。 实际上,它使用指定的数据压缩状态columnstore或columnstore_archive创建一个新的columnstore索引。 因此,在SQL Server 2019中,我们将其与等效的列存储对象进行比较。 源对象的类型定义目标列存储索引。 下表显示了如果数据压缩状态为columnstore或columnstore_archive,则源对象与参考对象之间的映射。
| Source | Reference |
| Heap or Clustered index or clustered columnstore index | Clustered columnstore index |
| Non-clustered index or non clustered columnstore index | Non-clustered columnstore index |
| 资源 | 参考 |
| 堆或聚集索引或聚集列存储索引 | 集群列存储索引 |
| 非聚集索引或非聚集列存储索引 | 非集群列存储索引 |
Likewise, if the source object is a columnstore index, we can use below reference table
同样,如果源对象是列存储索引,则可以在下面的引用表中使用
| Source | Reference |
| clustered columnstore index | Heap |
| non clustered columnstore index | Non-clustered index |
| 资源 | 参考 |
| 集群列存储索引 | 堆 |
| 非集群列存储索引 | 非聚集索引 |
Before we move further, let me give an overview of the important columns in the output of the stored procedure
在继续之前,让我概述一下存储过程输出中的重要列。
- object_name: Object (table, index name) object_name:对象(表,索引名称)
- size_with_current_compression_setting: This column represents current size of the table, index size_with_current_compression_setting:此列表示表的当前大小,索引
- size_with_requested_compression_setting: This column shows the estimated size of the table, index, with the data compression specified size_with_requested_compression_setting:此列显示表,索引的估计大小,并指定了数据压缩
- sample_size_with_current_compression_setting: this column shows the size of the current sample compression sample_size_with_current_compression_setting:此列显示当前样本压缩的大小
- sample_size_with_requested_compression_setting (KB): this represents the size of the sample created using the specified compression option sample_size_with_requested_compression_setting(KB):这表示使用指定的压缩选项创建的样本的大小
Now let us perform the demonstration. For this purpose, we will be using the StockItemTransactions table in the WideWorldImporters database in SQL Server 2019.
现在让我们进行演示。 为此,我们将使用SQL Server 2019中WideWorldImporters数据库中的StockItemTransactions表。
Firstly, verify the Compatibility level of the database with the below steps:
首先,通过以下步骤验证数据库的兼容性级别:
Right click on database name -> Properties -> Options
右键单击数据库名称->属性->选项
We can see here that compatibility level is set to SQL Server 2019 (150). if the compatibility level is other than 150 change it using the drop-down value or from below query.
我们在这里可以看到兼容性级别设置为SQL Server 2019(150)。 如果兼容性级别不是150,则使用下拉值或从下面的查询中进行更改。
USE [master]
GO
ALTER DATABASE [WideWorldImporters] SET COMPATIBILITY_LEVEL = 150
GO
Below indexes exist on the StockItemTransactions table of WideworldImporters database. We can see the list of indexes using below query.
WideworldImporters数据库的StockItemTransactions表上存在以下索引。 我们可以使用下面的查询来查看索引列表。
select object_name(object_id) as object_name,type_desc,*
from sys.indexes
Where object_id=638625318 --object id of StockItemTransactions table
Let us examine all options using the sp_estimate_data_compression_saving procedure.
让我们使用sp_estimate_data_compression_saving过程检查所有选项。
- Using ‘None‘ parameter in data_compression: this shows data if we no data compression is enabled
- 在data_compression中使用' None '参数:如果未启用数据压缩,则显示数据
USE WideWorldImporters;
GO
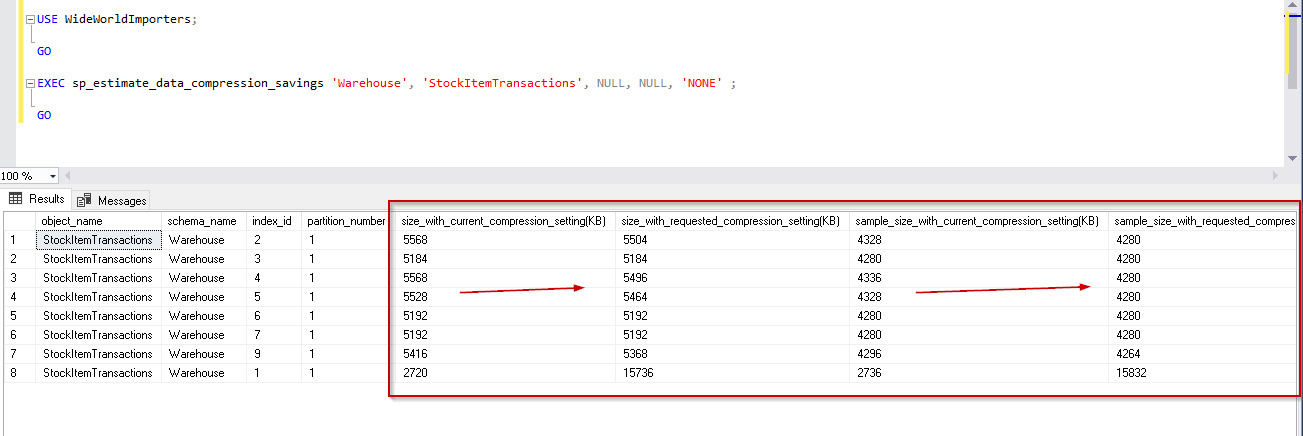
EXEC sp_estimate_data_compression_savings 'Warehouse', 'StockItemTransactions', NULL, NULL, 'NONE' ;
GO
- Using ‘Row‘ parameter in data_compression: this shows data if we no data compression is enabled
- 在data_compression中使用“ 行 ”参数:如果未启用数据压缩,则显示数据
USE WideWorldImporters;
GO
EXEC sp_estimate_data_compression_savings 'Warehouse', 'StockItemTransactions', NULL, NULL, 'Row' ;
GO
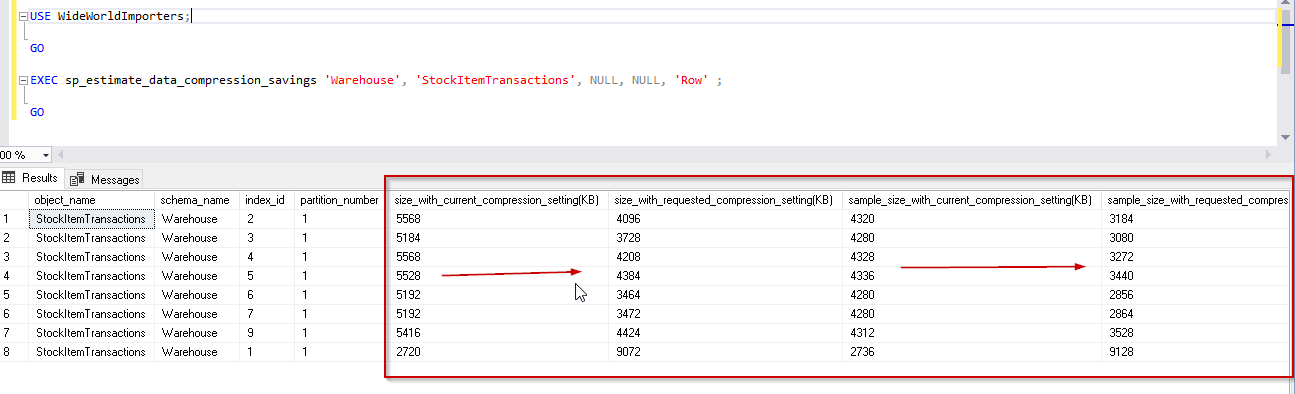
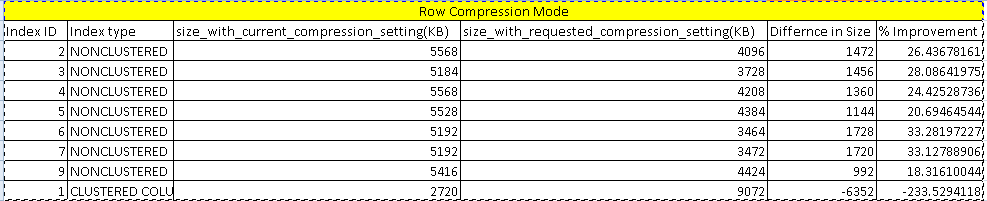
We can see in the image that with Row compression mode, data compression is around 26%. Here it shows a negative value for the clustered columnstore index because we cannot compress it with the row compression. For other indexes, you can notice the difference is index size with current compression setting and requested compression setting in KB.
从图中可以看到,在行压缩模式下,数据压缩约为26%。 在这里,它显示了集群列存储索引的负值,因为我们无法使用行压缩对其进行压缩。 对于其他索引,您会注意到不同之处在于索引大小与当前压缩设置和请求的压缩设置(以KB为单位)。
- Using ‘Page‘ parameter in data_compression: This shows data if we compress data with page data compression
- 在data_compression中使用“ Page ”参数:如果我们使用页面数据压缩来压缩数据,则显示数据
USE WideWorldImporters;
GO
EXEC sp_estimate_data_compression_savings 'Warehouse', 'StockItemTransactions', NULL, NULL, 'Page' ;
GO
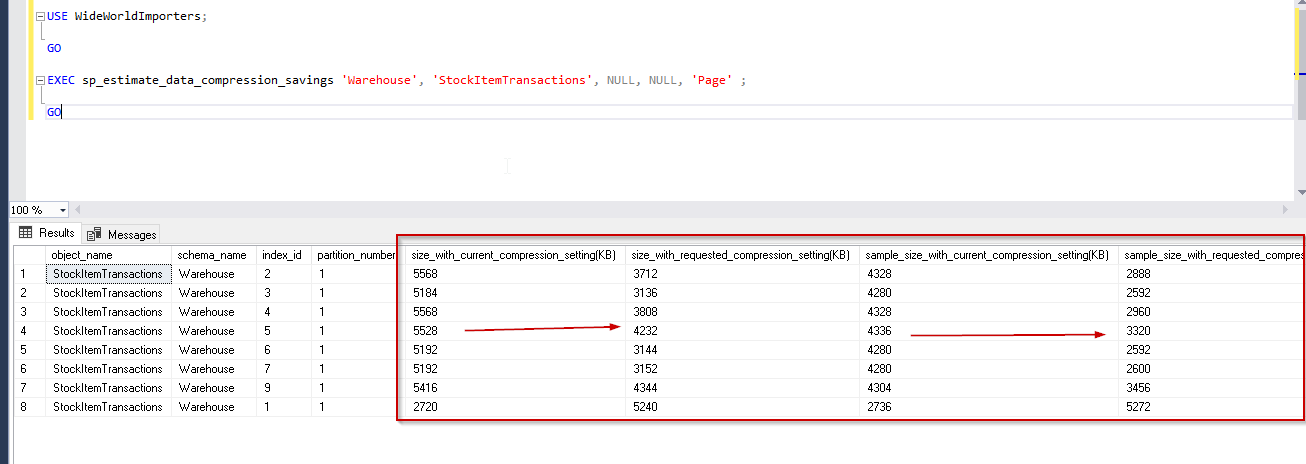
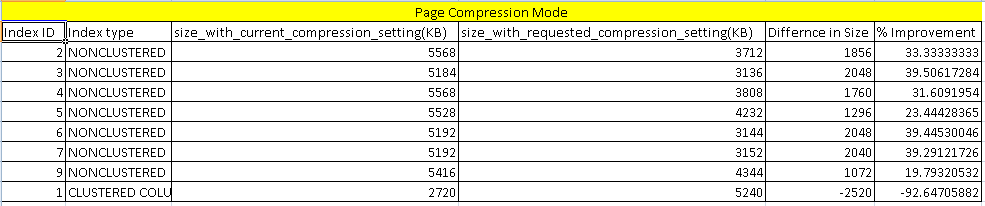
Previously we checked the benefit from the row compression mode. In the above comparison report, you can find an improvement or saving around 30% on average for the indexes. For the columnstore index as well, it shows -92%, which is better than the row compression.
以前,我们检查了行压缩模式的好处。 在上面的比较报告中,您可以发现索引平均可以改善或节省大约30%。 对于列存储索引,它也显示-92%,这比行压缩要好。
- Using ‘ColumnStore‘ parameter in data_compression: This is newly added in SQL Server 2019 preview version
- 在data_compression中使用' ColumnStore '参数:这是SQL Server 2019预览版中新添加的
USE WideWorldImporters;
GO
EXEC sp_estimate_data_compression_savings 'Warehouse', 'StockItemTransactions', NULL, NULL, 'COLUMNSTORE' ;
GO
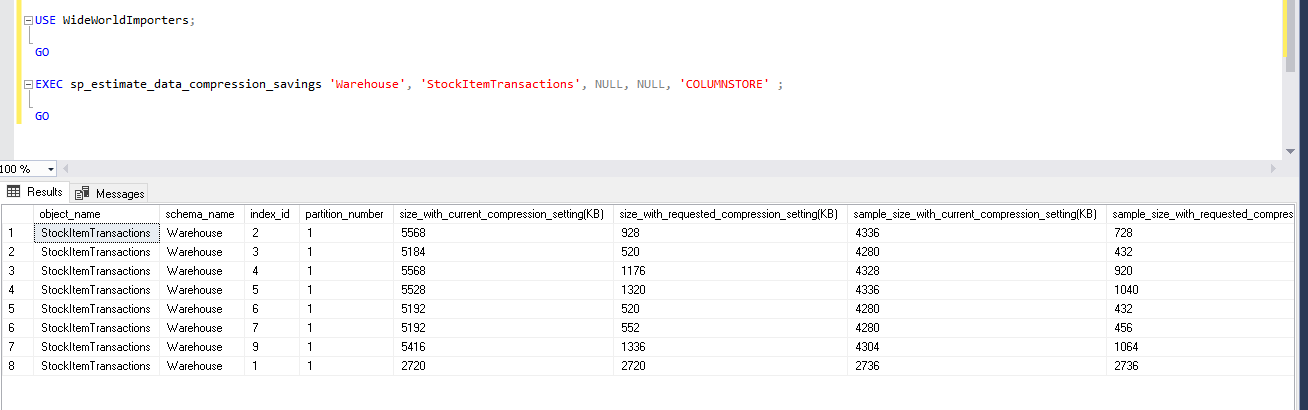
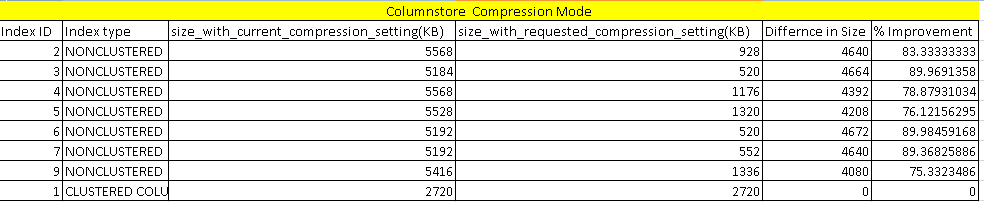
Now, let us view the data compression saving for the columnstore index. This is newly added in SQL Server 2019. We can see huge data compression around 70-80% for the indexes. It is helpful for the large databases of TB’s and PB’s. This is huge storage and cost-saving, especially for data warehouse databases. For a clustered columnstore index, it does not show any improvement because clustered columnstore index default compression mode is columnstore. Therefore, the index is already compressed using this mode.
现在,让我们查看columnstore索引的数据压缩保存。 这是SQL Server 2019中新添加的。我们可以看到索引的巨大数据压缩率约为70-80%。 这对于TB和PB的大型数据库很有帮助。 这是巨大的存储并节省了成本,尤其是对于数据仓库数据库而言。 对于群集的列存储索引,它没有显示任何改进,因为群集的列存储索引的默认压缩模式是列存储。 因此,索引已使用此模式进行压缩。
- Using ‘ColumnStore_Archive’ parameter in data_compression: This is also a new enhancement in SQL Server 2019
- 在data_compression中使用'ColumnStore_Archive'参数:这也是SQL Server 2019中的新增功能
USE WideWorldImporters;
GO
EXEC sp_estimate_data_compression_savings 'Warehouse', 'StockItemTransactions', NULL, NULL, 'COLUMNSTORE_ARCHIVE' ;
GO
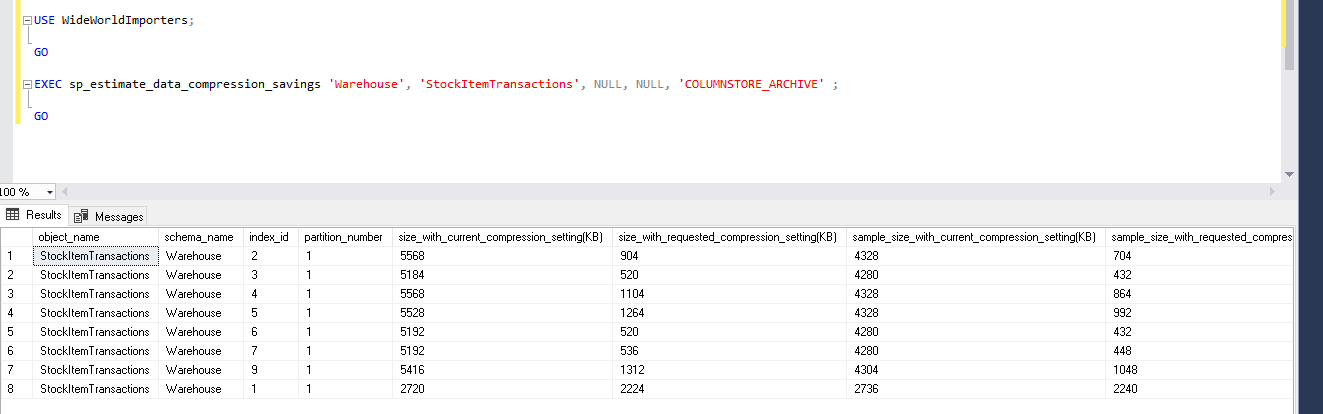
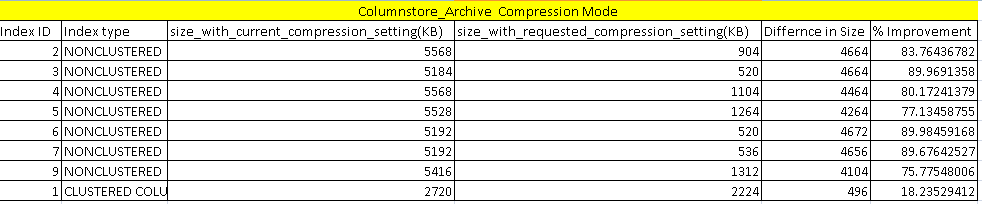
In ColumnStore_Archive compression mode, we can do more data compression that the columnstore compression mode. We can see here that improvement is around 80%. It further compresses the columnstore index by 18%. Columnstore index with archive compression can perform slowly as compared with the columnstore index. This also requires high CPU and Memory to access the data. You should compress data with this method only for old data with very less frequency of usage.
在ColumnStore_Archive压缩模式下,我们可以执行比列存储压缩模式更多的数据压缩。 我们在这里可以看到,改进幅度约为80%。 它将列存储索引进一步压缩18%。 与列存储索引相比,具有存档压缩功能的列存储索引的执行速度较慢。 这也需要较高的CPU和内存来访问数据。 您只应使用此方法压缩使用频率极少的旧数据。
结论 (Conclusion)
In SQL Server 2019, improvements to the procedure sp_estimate_data_compression_saving are helpful to estimate the data saving for columnstore indexes. You can explore this into your environment to get an overview. We will cover more on the columnstore index in SQL Server 2019 in future articles.
在SQL Server 2019中,对过程sp_estimate_data_compression_saving的改进有助于估计列存储索引的数据保存。 您可以将其探索到您的环境中以获得概述。 我们将在以后的文章中详细介绍SQL Server 2019中的列存储索引。
目录 (Table of contents)
| Columnstore Index Enhancements – Index stats update in clone databases |
| Columnstore Index Enhancements – data compression, estimates and savings |
| Columnstore Index Enhancements – online and offline (re)builds |
| 列存储索引增强功能–克隆数据库中的索引统计信息更新 |
| 列存储索引增强功能–数据压缩,估计和节省 |
| 列存储索引增强功能–在线和离线(重新)构建 |
翻译自: https://www.sqlshack.com/columnstore-index-enhancements-data-compression-estimates-and-savings/
行存储索引改换成列存储索引















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









