





 SQL Server 2008引入的稀疏列特性减少了含有大量NULL值的列的存储消耗。使用稀疏列时,NULL值不占用空间,但非NULL值会额外消耗4字节。当NULL值比例高于一定阈值时,使用稀疏列才划算。此外,稀疏列无法用作主键、IDENTITY或ROWGUIDCOL。文章通过示例展示了如何定义和使用稀疏列,以及如何利用过滤索引来进一步优化查询性能。
SQL Server 2008引入的稀疏列特性减少了含有大量NULL值的列的存储消耗。使用稀疏列时,NULL值不占用空间,但非NULL值会额外消耗4字节。当NULL值比例高于一定阈值时,使用稀疏列才划算。此外,稀疏列无法用作主键、IDENTITY或ROWGUIDCOL。文章通过示例展示了如何定义和使用稀疏列,以及如何利用过滤索引来进一步优化查询性能。
SQL Server 2008 introduces a new column attribute that is used to reduce the storage consumed by NULL values in the database tables. This feature is known as Sparse Columns. Sparse Columns work effectively in the case of the columns with high proportion of NULL values, as SQL Server will not consume any space storing the NULL values at all, which helps in optimizing the SQL storage usage.
SQL Server 2008引入了一个新的列属性,该属性用于减少数据库表中NULL值消耗的存储。 此功能称为“ 稀疏列” 。 稀疏列在NULL值比例较高的情况下有效工作,因为SQL Server完全不会占用存储NULL值的任何空间,这有助于优化SQL存储的使用。
A trade-off when using the Sparse Columns is the additional 4 bytes space required to store the non-NULL values in the Sparse Columns. So, it is recommended not to use the Sparse Columns unless the column has a high percentage of NULL values in it, in order to gain the storage saving benefits of the Sparse Column feature.
使用稀疏列时的权衡是在稀疏列中存储非NULL值所需的额外4个字节空间。 因此,建议不要使用稀疏列,除非该列中包含较高百分比的NULL值,以便获得稀疏列功能的存储节省优势。
When you store a NULL value in a fixed-length column such as a column with INT data type, the NULL value will consume the whole column length. But if you store that NULL value in a variable-length column such as a column with VARCHAR data type, it will consume only two bytes from the column’s length. Using Sparse Columns, NULL value will not consume any space regardless of using fixed-length or variable-length columns. But as mentioned previously, the trade-off here is the additional 4 bytes when storing non-NULL values in the Sparse Column. For example, a column with BIGINT datatype consumes 8 bytes when storing actual or NULL values in it. Defining that BIGINT column as Sparse Column, it will consume 0 bytes storing NULL values, but 12 bytes storing non-NULL values in it.
当您在固定长度的列(例如具有INT数据类型的列)中存储NULL值时,NULL值将占用整个列的长度。 但是,如果将NULL值存储在可变长度的列中(例如VARCHAR数据类型的列),则它将仅消耗列长度的两个字节。 使用稀疏列,无论使用固定长度列还是可变长度列,NULL值都不会占用任何空间。 但是如前所述,这里需要权衡的是在稀疏列中存储非NULL值时需要额外的4个字节。 例如,具有BIGINT数据类型的列在其中存储实际值或NULL值时会消耗8个字节。 将BIGINT列定义为“稀疏列”,它将消耗0字节存储NULL值,但是12字节存储非NULL值。
The reason why NULL values in the Sparse Columns consume 0 bytes and the non-NULL values consumes extra 4 bytes is that the Sparse Column values will not be stored with the normal columns, instead it is stored in a special structure at the end of each row, with 2 bytes to store the non-NULL values IDs and 2 bytes to store the non-NULL values offsets. This complex structure results in extra overhead too to retrieve the non-NULL values from the Sparse Columns.
稀疏列中的NULL值占用0字节而非NULL值消耗额外的4个字节的原因是稀疏列值将不与普通列一起存储,而是存储在每个末尾的特殊结构中行,其中2个字节用于存储非NULL值ID,而2个字节用于存储非NULL值偏移量。 这种复杂的结构也会导致额外的开销,以便从稀疏列中检索非NULL值。
Enjoying the storage optimization benefits of the Sparse Columns depends on the datatype of that Sparse Column. For example, the NULL values percentage of a column with BIGINT or DATETIME datatypes should not be less than 52% of the overall column values to take benefits of the Sparse Columns space saving, and should not be less than 64% for the INT datatype. On the other hand, 98% NULL values from a column with BIT datatype will allow you to take benefits of the Sparse Column storage optimization.
享受稀疏列的存储优化优势取决于稀疏列的数据类型。 例如,具有BIGINT或DATETIME数据类型的列的NULL值百分比应不小于总列值的52%,以利用稀疏列空间节省的优点,而对于INT数据类型,应不小于64%。 另一方面,具有BIT数据类型的列中98%的NULL值将使您能够利用稀疏列存储优化。
Sparse Columns can be defined easily by adding the SPARSE keyword beside the column’s definition. The NULL keyword in the Sparse Column definition is optional, as the Sparse Column must allow NULL values. As a result, Sparse Columns can’t be configured as Primary Key, IDENTITY or ROWGUIDCOL columns. You should take into consideration when you define a Sparse Column that you can’t assign the default value for the Sparse Column. Also, Computed columns can’t be defined as Sparse Columns. The text, ntext, image, vbinary(max) , geometry, geography, timestamp and user-defined datatypes can’t be used for the Sparse Columns. Sparse columns don’t support also data compression.
通过在列定义旁边添加SPARSE关键字,可以轻松定义稀疏列。 稀疏列定义中的NULL关键字是可选的,因为稀疏列必须允许NULL值。 结果,稀疏列不能配置为主键,IDENTITY或ROWGUIDCOL列。 定义稀疏列时应考虑到不能为稀疏列指定默认值的情况。 另外,不能将“计算列”定义为“稀疏列”。 稀疏列不能使用text,ntext,image,vbinary(max),geometry,geography,timestamp和用户定义的数据类型。 稀疏列也不支持数据压缩。
Let’s have a small demo to understand the Sparse Columns feature practically. We will start with creating two new tables in our SQLShackDemo test database with the same schema, except that the Emp_Last_Name , Emp_Address, and Emp_Email columns on the SPARSEDemo_WithSparse table are defined with the SPARSE attribute as follows:
让我们做一个小演示,以实际了解稀疏列功能。 我们将首先在SQLShackDemo测试数据库中使用相同的架构创建两个新表,不同的是,SPARSEDemo_WithSparse表上的Emp_Last_Name,Emp_Address和Emp_Email列使用SPARSE属性定义如下:
USE SQLShackDemo
GO
CREATE TABLE SPARSEDemo_WithSparse
(
ID int IDENTITY (1,1),
Emp_First_Name VARCHAR(50) NULL,
Emp_Last_Name VARCHAR(50) SPARSE,
TS DateTime NULL,
Emp_Address VARCHAR(100) SPARSE,
Emp_Email VARCHAR(100) SPARSE,
)ON [PRIMARY]
GO
CREATE TABLE SPARSEDemo_WithoutSparse
(
ID int IDENTITY (1,1),
Emp_First_Name VARCHAR(50) NULL,
Emp_Last_Name VARCHAR(50) NULL,
TS DateTime NULL ,
Emp_Address VARCHAR(100) NULL,
Emp_Email VARCHAR(100) NULL,
)ON [PRIMARY]
GO
You can also define a column with SPARSE property using the SQL Server Management Studio tool. Right-click on the target table and select the Design option, then select the column you need to define as Sparse Column and change the Is Sparse property from the Column Properties page to Yes as in the below figure:
您还可以使用SQL Server Management Studio工具定义具有SPARSE属性的列。 右键单击目标表,然后选择“ 设计”选项,然后选择需要定义为“稀疏列”的列,并将“稀疏属性”从“ 列属性”页面更改为“ 是 ”,如下图所示:
The Is_Sparse property can be checked by querying the sys.objects and sys.columns system tables with the columns with is_sparse property value equal 1 as in the below query:
可以通过查询sys.objects和sys.columns系统表来检查Is_Sparse属性,这些表的is_sparse属性值等于1,如以下查询所示:
USE SQLShackDemo
GO
SELECT OBJ.name Table_Name,
COL.name Column_Name
FROM sys.columns COL
JOIN sys.objects OBJ
ON OBJ.OBJECT_ID = COL.OBJECT_ID
WHERE is_sparse = 1
GO
The output in our case will be like:
在本例中,输出将如下所示:
The two tables are created now. We will use the ApexSQL Generate tool to fill the SPARSEDemo_WithoutSparse table with 100,000 records after connecting to the local SQL Server instance as follows:
现在创建了两个表。 在连接到本地SQL Server实例后,我们将使用ApexSQL生成工具将100,000条记录填充到SPARSEDemo_WithoutSparse表中,如下所示:
In order to have fair comparison between the table with Sparse Columns and the one without, we will fill the same data from the SPARSEDemo_WithoutSparse table to the SPARSEDemo_WithSparse one:
为了公平地比较带有稀疏列的表和没有稀疏列的表,我们将从SPARSEDemo_WithoutSparse表到SPARSEDemo_WithSparse表中填充相同的数据:
USE [SQLShackDemo]
GO
INSERT INTO [dbo].[SPARSEDemo_WithSparse]
([Emp_First_Name]
,[Emp_Last_Name]
,[TS]
,[Emp_Address]
,[Emp_Email])
SELECT [Emp_First_Name]
,[Emp_Last_Name]
,[TS]
,[Emp_Address]
,[Emp_Email] from SPARSEDemo_WithoutSparse
GO
Using the sp_spaceused system object to check the storage properties for the two tables:
使用sp_spaceused系统对象检查两个表的存储属性:
sp_spaceused 'SPARSEDemo_WithoutSparse'
GO
sp_spaceused 'SPARSEDemo_WithSparse'
GO
The result will be like:
结果将如下所示:
The previous shocking numbers meet what we mentioned previously, that the non-NULL values on the Sparse Columns will consume extra 4 bytes for each value, resulting more space consumption.
先前的令人震惊的数字符合我们前面提到的内容,即稀疏列上的非NULL值将为每个值占用额外的4个字节,从而导致更多的空间消耗。
Let’s update the Emp_Last_Name , Emp_Address and Emp_Email columns to have a high percentage of NULL values on both tables with and without Sparse properties:
让我们更新Emp_Last_Name,Emp_Address和Emp_Email列,以在具有和不具有稀疏属性的两个表上都具有很高的NULL值:
USE SQLShackDemo
GO
Update SPARSEDemo_WithSparse set Emp_Last_Name = NULL WHERE ID >20000 and ID <80000
GO
Update SPARSEDemo_WithSparse set Emp_Address = NULL WHERE ID >60000 and ID <80000
GO
Update SPARSEDemo_WithSparse set Emp_Email = NULL WHERE ID >20000 and ID <100000
GO
Update SPARSEDemo_WithoutSparse set Emp_Last_Name = NULL WHERE ID >20000 and ID <80000
GO
Update SPARSEDemo_WithoutSparse set Emp_Address = NULL WHERE ID >60000 and ID <80000
GO
Update SPARSEDemo_WithoutSparse set Emp_Email = NULL WHERE ID >20000 and ID <100000
GO
After changing the values, we will check the NULL values percentage in each column. Remembering that the NULL values percentage in the Sparse Columns decide if we will take benefits of the space saving advantage of the Sparse Column or not, taking into consideration that this percentage for the VARCHAR data type is 60%:
更改值后,我们将检查每列中的NULL值百分比。 请记住,稀疏列中的NULL值百分比决定了我们是否要利用稀疏列的空间节省优势,并考虑到VARCHAR数据类型的此百分比为60%:
SELECT COUNT (ID) NumOfNullLastName, cast(COUNT (ID) as float)/100000 NullPercentage
FROM [SQLShackDemo].[dbo].[SPARSEDemo_WithSparse]
WHERE Emp_Last_Name is NULL
GO
SELECT COUNT (ID) NumOfNullAddress,cast(COUNT (ID) as float)/100000 NullPercentage
FROM [SQLShackDemo].[dbo].[SPARSEDemo_WithSparse]
WHERE Emp_Address is NULL
GO
SELECT COUNT (ID) NumOfNullEmail,cast(COUNT (ID) as float)/100000 NullPercentage
FROM [SQLShackDemo].[dbo].[SPARSEDemo_WithSparse]
WHERE Emp_Email is NULL
The percentage will be similar to:
该百分比将类似于:
As you can see from the previous result, we will take benefits of defining the Emp_Last_Name and Emp_Email columns as Sparse Columns, as the Null Values percentage is over or equal to 60%. Defining the Emp_Address column as Sparse Column is not the correct decision here.
从上一个结果中可以看到,由于Null值百分比大于或等于60%,我们将受益于将Emp_Last_Name和Emp_Email列定义为稀疏列。 在此处将Emp_Address列定义为“稀疏列”不是正确的决定。
If you run the previous sp_spaceused statements again to check the space usage after the update, you will see no space consumption change on the table with no Sparse Columns, but you will notice a big difference in the case of the table with Sparse Columns due to high percentage of NULL values:
如果再次运行以前的sp_spaceused语句以检查更新后的空间使用情况,则在没有稀疏列的表上将看不到空间消耗的变化,但是对于具有稀疏列的表,由于以下原因,您会发现差异很大高百分比的NULL值:
If we change the Sparse Column property of the Emp_Address column in the previous example, and check the space consumption after the change, the numbers will show us that having this column as Sparse Column is worse than having it a normal one as below:
如果我们在上一个示例中更改Emp_Address列的Sparse Column属性,并检查更改后的空间消耗,则数字将向我们显示,将该列作为Sparse Column比将其作为普通列更糟糕,如下所示:
Again, if we try to change all the Emp_Last_Name , Emp_Address and Emp_Em columns values to NULL:
同样,如果我们尝试将所有Emp_Last_Name,Emp_Address和Emp_Em列的值更改为NULL:
update SPARSEDemo_WithSparse set Emp_Last_Name = NULL , Emp_Address=NULL , Emp_Email=NULL
GO
update SPARSEDemo_WithoutSparse set Emp_Last_Name = NULL , Emp_Address=NULL , Emp_Email=NULL
GO
And check the space consumption using the sp_spaceused system object, we will see that the space consumption of the first table without the Sparse Columns will not be affected, and the space consumption of the second one with Sparse Columns changed clearly as follows:
并使用sp_spaceused系统对象检查空间消耗,我们将看到没有稀疏列的第一个表的空间消耗不会受到影响,而具有稀疏列的第二个表的空间消耗则发生了明显变化,如下所示:
When trying to Select Top 1000 Rows from the database table with Sparse Columns, SQL Server will retrieve only the non-Sparse columns:
尝试从数据库表中选择“具有稀疏列”的前1000行时 ,SQL Server将仅检索非稀疏列:
The result will exclude the Emp_Last_Name , Emp_Address and Emp_Email columns as below:
结果将不包括Emp_Last_Name,Emp_Address和Emp_Email列,如下所示:
As retrieving the non-Null values from the Sparse columns will slow down the query. If we try to run the previous SELECT statement retrieved from the SSMS that excludes the Sparse Columns and the SELECT * statement after turning the STATISTICS TIME ON:
从稀疏列中检索非null值将减慢查询速度。 如果在打开STATISTICS TIME后尝试运行从SSMS检索的前一个SELECT语句,该语句不包括稀疏列和SELECT *语句:
SET STATISTICS TIME ON
SELECT [ID]
,[Emp_First_Name]
,[TS]
FROM [SQLShackDemo].[dbo].[SPARSEDemo_WithSparse]
GO
SELECT * FROM [SQLShackDemo].[dbo].[SPARSEDemo_WithSparse]
SET STATISTICS TIME OFF
You will notice clearly the performance overhead that is resulted from reading the Sparse Columns with non-NULL values as below:
您会清楚地注意到由于读取具有非NULL值的稀疏列而导致的性能开销,如下所示:
SQL Server Filtered Non-Clustered Indexes can be used with the Sparse Columns in order to enhance the queries performance in addition to the space saving gain from the Sparse Columns. With the Sparse Column, the filtered index will be smaller and faster than the normal non-clustered index, as it will store only the data that meets the criteria specified in the WHERE clause of the index definition. You can easily exclude the NULL values in the filtered index to make the index smaller and more efficient.
SQL Server 筛选的非聚簇索引可与稀疏列一起使用,以提高查询性能,此外还可从稀疏列中节省空间。 使用“稀疏列”,过滤后的索引将比正常的非聚集索引更小和更快,因为它仅存储满足索引定义的WHERE子句中指定的条件的数据。 您可以轻松地在过滤后的索引中排除NULL值,以使索引更小,更有效。
We will first define the ID column in our sparse demo table as Primary Key:
我们首先将稀疏演示表中的ID列定义为主键:
ALTER TABLE [dbo].[SPARSEDemo_WithSparse] ADD CONSTRAINT [PK_SPARSEDemo_WithSparse] PRIMARY KEY CLUSTERED
(
[ID] ASC
)
If we try to run the below simple SELECT statement from the SPARSEDemo_WithSparse table and check the query execution plan and time and IO statistics:
如果我们尝试从SPARSEDemo_WithSparse表运行以下简单的SELECT语句,并检查查询执行计划以及时间和IO统计信息:
USE SQLShackDemo
GO
SELECT ID, Emp_First_Name FROM SPARSEDemo_WithSparse where [Emp_Last_Name] = 'Jenkins'
The result will show us that SQL Server scans all records in the clustered index to retrieve the data, performs 759 logical reads, consumes 16 ms from the CPU time and takes 52 ms to finish:
结果将向我们展示SQL Server扫描聚集索引中的所有记录以检索数据,执行759次逻辑读取,从CPU时间消耗16毫秒并花费52毫秒来完成:
Let’s create a non-clustered filtered index on the Emp_Last_Name column INCLUDE the Emp_First_name column, excluding the Emp_Last_Name NULL values from the index in order to be small one:
让我们在Emp_Last_Name列上创建一个非聚集过滤索引,包括Emp_First_name列,从索引中排除Emp_Last_Name NULL值以使其较小:
USE [SQLShackDemo]
GO
CREATE NONCLUSTERED INDEX [IX_SPARSEDemo_WithSparse_Emp_Last_Name] ON [dbo].[SPARSEDemo_WithSparse]
(
[Emp_Last_Name] ASC
)
INCLUDE ( [Emp_First_Name])
WHERE ([Emp_Last_Name] IS NOT NULL)
GO
If we try to run the previous SELECT statement after creating the index, an index seek will be used on the table to retrieve the data, performing only 5 logical reads, consuming 0 ms from the CPU time and taking 41 ms to finish. With clear variation from the statistics without using that filtered index:
如果我们尝试在创建索引后运行上一个SELECT语句,则将在表上使用索引查找来检索数据,仅执行5次逻辑读取,从CPU时间消耗0毫秒,并花费41毫秒来完成。 在不使用该过滤索引的情况下,与统计信息存在明显差异:
SQL Server provides you with a way to combine all the Sparse Columns in your table and return it in an untyped XML representation, this new feature is called the Column Set. The Column Set concept is similar to the computed column concept, where SQL Server will gather all Sparse Columns in your table into a new column that is not physically stored in the table, with the ability to retrieve and update it directly from that new column. And you still able to access these Sparse Columns individually by providing the column name. This feature is useful when you have a large number of Sparse Columns in your table, which allows you to operate on these set of columns in one shot, as working on it individually is very difficult.
SQL Server为您提供了一种组合表中所有稀疏列并以无类型XML表示形式返回的方法,此新功能称为列集 。 列集概念与计算列概念相似,SQL Server将把表中的所有稀疏列收集到一个新列中,该新列实际上并不存储在表中,并具有直接从该新列中检索和更新它的能力。 而且,您仍然可以通过提供列名称来单独访问这些稀疏列。 当表中有大量稀疏列时,此功能很有用,因为您很难单独处理这些列,因此您可以一次性对这些列进行操作。
Column Set can be defined by adding the COLUMN_SET FOR ALL_SPARSE_COLUMNS keywords when creating or altering your table. The Column Set can be specified in the definition of the table that contains Sparse Columns which will appear directly, or to a table without any Sparse Column, where it will appear once you add these Sparse Columns. Take into consideration that you can define only one Column Set per each table, and once this Column Set is created, it can’t be changed unless you drop the Sparse Columns and Column Set or the table and create it again. The Column Set can’t be used in Replication, Distributed Queries, and CDC features. Also, you can’t index the Column Set.
在创建或更改表时,可以通过添加COLUMN_SET FOR ALL_SPARSE_COLUMNS关键字来定义列集。 可以在包含将直接显示的稀疏列的表的定义中指定列集,也可以在没有任何稀疏列的表中指定列集,添加这些稀疏列后将在其中出现。 请注意,每个表只能定义一个列集,并且一旦创建了该列集,就不能更改它,除非您删除“稀疏列和列集”或表并再次创建它。 列集不能用于复制,分布式查询和CDC功能。 同样,您不能索引列集。
The Column Set can’t be added to a table that contains Sparse Columns. If we try to add a new Column Set to our Sparse demo table using the below ALTER TABLE statement:
列集不能添加到包含稀疏列的表中。 如果我们尝试使用以下ALTER TABLE语句向稀疏演示表中添加新的列集:
ALTER TABLE SPARSEDemo_WithSparse
ADD EmployeeSet XML COLUMN_SET FOR ALL_SPARSE_COLUMNS
SQL Server will not allow us to create that Column Set on that table that already contains Sparse Columns:
SQL Server不允许我们在已经包含稀疏列的表上创建该列集:

To create the Column Set successfully, we will drop the table and create it again after taking the backup from the existing data to a temp table:
为了成功创建列集,在将现有数据备份到临时表后,我们将删除该表并再次创建它:
USE [SQLShackDemo]
GO
DROP TABLE SPARSEDemo_WithSparse
GO
CREATE TABLE [dbo].[SPARSEDemo_WithSparse](
[ID] [int] IDENTITY(1,1) NOT NULL,
[Emp_First_Name] [varchar](50) NULL,
[Emp_Last_Name] [varchar](50) SPARSE NULL,
[TS] [datetime] NULL,
[Emp_Address] [varchar](100) SPARSE NULL,
[Emp_Email] [varchar](100) SPARSE NULL,
[EmployeeSet] XML COLUMN_SET FOR ALL_SPARSE_COLUMNS
) ON [PRIMARY]
GO
Assume that we filled the table again from the temp backup, if we try to SELECT data from that table, the result will contain additional column in XML format that contains all Sparse Columns values as follows:
假设我们从临时备份中再次填充了表,如果尝试从该表中选择数据,则结果将包含XML格式的附加列,该列包含所有稀疏列值,如下所示:
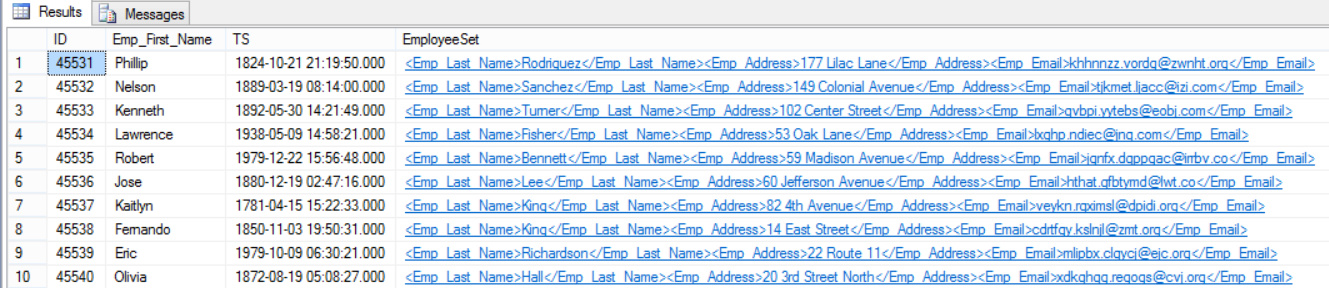
You can also check the Column Set value in more readable format by clicking on the XML blue value which will be displayed in separate window as the below:
您还可以通过单击XML蓝色值(以如下所示在单独的窗口中显示)来以更易读的格式检查Column Set值:
To see how we can take benefits from the Column Set, we will change the Emp_Last_Name and the Emp_Email of an employee with ID 45531 from the ColumnSet XML column in one shot and check if this change will be replicated to the source Sparse Columns. Let’s first check the values before the update:
若要查看如何从列集中受益,我们将一次从ColumnSet XML列中更改ID为45531的员工的Emp_Last_Name和Emp_Email,并检查是否将此更改复制到源稀疏列中。 首先让我们检查一下更新之前的值:
SELECT * FROM [SQLShackDemo].[dbo].[SPARSEDemo_WithSparse] where ID = 45531
The result will be similar to:
结果将类似于:

Now we will perform the update by adding the “phill” to the last name and the last part of the email using the below update statement:
现在,我们将使用以下更新语句在电子邮件的姓氏和末尾添加“ phill”来执行更新:
UPDATE [SQLShackDemo].[dbo].[SPARSEDemo_WithSparse]
SET EmployeeSet ='<Emp_Last_Name>RodriguezPhill</Emp_Last_Name><Emp_Address>177 Lilac Lane</Emp_Address><Emp_Email>khhnnzz.Phill@zwnht.org</Emp_Email>'
WHERE ID =45531
If we retrieve that employee’s information after the update, in addition to the Emp_Last_Name and Emp_Email columns individually:
如果我们在更新后检索到该员工的信息,则除了Emp_Last_Name和Emp_Email列之外:
SELECT [ID],[Emp_First_Name],[Emp_Last_Name],[Emp_Email]
,[EmployeeSet] FROM [SQLShackDemo].[dbo].[SPARSEDemo_WithSparse] where ID = 45531
The result will show you that, the single update statement we performed to that employee Column Set column is reflected on the Sparse Columns as follows:
结果将向您显示,我们对员工Column Set列执行的单个更新语句反映在Sparse Columns上,如下所示:

The Column Set overrides the maximum number of Sparse Columns per each table, which is 1024 columns for each table. The Column Set can contain up to 30,000 Sparse Columns in your table. However, no more than 1024 columns can be returned in the result set at the same time and in the XML Column Set result.
列集将覆盖每个表的最大稀疏列数,即每个表的1024列。 表格中的列集最多可以包含30,000个稀疏列。 但是,结果集和XML列集结果中不能同时返回不超过1024列。
结论: ( Conclusion: )
Sparse Column is a very efficient feature that can be used to store NULL values in a database table with a high NULL values percentage. Combining it with the filtered indexes will result in a performance enhancement to your queries and smaller non-clustered indexes. Together with the Column Set, Sparse Columns can be retrieved and modified in one shot, displayed in XML format and extends the number of columns per table limitation. Be careful when you use these features; as it is a double-edged sword; if you test it well and make sure that it will suit your case, you will get the best performance, otherwise it may cause performance degradation and consume your storage.
稀疏列是一种非常有效的功能,可用于将NULL值存储在具有较高NULL值百分比的数据库表中。 将其与过滤后的索引结合使用,将可以提高查询性能和较小的非聚集索引。 稀疏列与列集一起可以检索和修改,以XML格式显示,并扩展了每个表限制的列数。 使用这些功能时请多加注意。 因为它是一把双刃剑; 如果您对其进行了良好的测试,并确保它适合您的情况,则您将获得最佳性能,否则可能会导致性能下降并占用存储空间。
有用的链接: ( Useful Links: )
翻译自: https://www.sqlshack.com/optimize-null-values-storage-consumption-using-sql-server-sparse-columns/
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









