





 本文探讨了在构建新数据库时应考虑的设计和体系结构,以优化性能。强调了了解应用程序的业务需求、可扩展性、数据类型和空值的重要性,以及避免过度使用触发器。建议将OLTP和OLAP系统分开,以提高性能和避免潜在问题。通过智能设计和架构决策,可以减少后期的性能优化工作。
本文探讨了在构建新数据库时应考虑的设计和体系结构,以优化性能。强调了了解应用程序的业务需求、可扩展性、数据类型和空值的重要性,以及避免过度使用触发器。建议将OLTP和OLAP系统分开,以提高性能和避免潜在问题。通过智能设计和架构决策,可以减少后期的性能优化工作。
描述 (Description)
One of the best ways to optimize performance in a database is to design it right the first time! Making design and architecture decisions based on facts and best practices will reduce technical debt and the number of fixes that you need to implement in the future.
优化数据库性能的最佳方法之一是在第一时间进行正确设计! 根据事实和最佳实践做出设计和体系结构决策将减少技术负担,并减少将来需要实施的修复程序数量。
While there are often ways to tweak queries, indexes, and server settings to make things faster, there are limits to what we can accomplish in a cost-efficient and timely manner. Those limits are dictated by database architecture and application design. It may often seem that prioritizing good design up-front will cost more than the ability to roll features out quickly, but in the long-run, the price paid for hasty or poorly-thought-out decisions will be higher.
尽管通常可以通过多种方法来调整查询,索引和服务器设置,以加快处理速度,但以经济高效且及时的方式来完成工作却受到了限制。 这些限制由数据库体系结构和应用程序设计决定。 通常看来,优先考虑良好的设计要比快速部署功能花费更多,但是从长远来看,为草率或考虑周全的决策付出的代价会更高。
This article is a fast-paced dive into the various design considerations that we can make when building new databases, tables, or procedural TSQL. Consider these as ways to improve performance in the long-term by making careful, well thought-out decisions now. Predicting the future of an application may not be easy when we are still nursing it through infancy, but we can consider a variety of tips that will give us a better shot at doing it right the first time!
本文是对构建新数据库,表或过程TSQL时可以进行的各种设计考虑的快速了解。 现在考虑通过谨慎,周到的决策将这些方法视为长期改善性能的方法。 在婴儿期仍在护理中的情况下,预测应用程序的未来可能并不容易,但是我们可以考虑各种技巧,这些技巧可以让我们在第一时间正确地进行操作!
“Measure twice, cut once” applies to application development in that regard. We need to accept that doing it right the first time will be significantly cheaper and less time-consuming than needing to rearchitect in the future.
在这方面,“两次测量,一次剪切”适用于应用程序开发。 我们需要接受的是,与将来重新配置相比,第一次正确执行将大大便宜且耗时更少。
了解应用 (Understand the application)
Learn the business need behind the application and its database. In addition to a basic understanding of what an app will do, consider the following questions:
了解应用程序及其数据库背后的业务需求。 除了对应用程序的功能有基本了解之外,请考虑以下问题:
- What is it used for? What is the app and its purpose? What kind of data will be involved? 它是干什么用的? 该应用程序及其用途是什么? 将涉及哪种数据?
- Who will access it? Will it be end-users on the web or internal employees? Will it be 5 people, 5,000 people or 5 million people? 谁将访问它? 是网络上的最终用户还是内部员工? 是5个人,5,000个人还是500万人?
- How will they access it? Will it be a web page? Mobile app? Local software on a computer or private cloud? A reporting interface? 他们将如何访问它? 会是网页吗? 移动应用? 计算机或私有云上的本地软件? 报告界面?
- Are there specific times of day when usage is heavier? Do we need to accommodate busy times with extra resources? Will quiet times allow for planned maintenance or downtime? What sort of uptime is expected? 有一天的特定时段使用量更大吗? 我们需要额外的资源来适应繁忙的时间吗? 安静的时间是否可以按计划进行维护或停机? 预计什么样的正常运行时间?
Getting a basic idea of the purpose of a database will allow you to better forecast its future and avoid making any major mistakes in the beginning. If we know about application quirks, such as busy or quiet times, the use of ORMs, or the use of an API, we can better understand how it will interact with the database and make decisions to accommodate that usage.
了解数据库用途的基本概念将使您能够更好地预测数据库的未来,并避免在开始时犯任何重大错误。 如果我们了解应用程序的怪癖,例如繁忙或安静的时间,ORM的使用或API的使用,我们将更好地了解它如何与数据库交互并做出适应该用法的决策。
Often, a good understanding of the app allows us to make simplifying assumptions and cut through a lot of the decisions we need to make. This conversation may involve both technical folks (architects, developers, engineers, and other DBAs) or it may involve business reps that have a strong understanding of the purpose of the app, even if they may not know much about the technical implementation of it.
通常,对应用程序有一个很好的了解,可以使我们做出简化的假设并简化许多需要做出的决定。 这种对话可能涉及技术人员(架构师,开发人员,工程师和其他DBA),也可能涉及对应用程序用途有深刻理解的业务代表,即使他们可能不太了解应用程序的技术实现。
Here are some more details on the questions and considerations we should make when designing new database objects:
以下是有关在设计新数据库对象时应考虑的问题和注意事项的更多详细信息:
可扩展性 (Scalability)
How will the application and its data grow over time? The ways we build, maintain, and query data change when we know the volume will be huge. Very often we build and test code in very controlled dev/QA environments in which the data flow does not mirror a real production environment. Even without this, we should be able to estimate how much an app will be used and what the most common needs will be.
随着时间的流逝,应用程序及其数据将如何增长? 当我们知道数据量将会很大时,我们构建,维护和查询数据的方式就会改变。 通常,我们在受严格控制的dev / QA环境中构建和测试代码,在该环境中数据流不会反映真实的生产环境。 即使没有这个,我们也应该能够估计将使用多少应用程序以及最常见的需求是什么。
We can then infer metrics such as database size, memory needs, CPU, and throughput. We want the hardware that we put our databases on to be able to perform adequately and this requires us to allocate enough computing resources to make this happen. A 10TB database will likely not perform well (or at all) on a server with 2GB of RAM available to it. Similarly, a high-traffic application may require faster throughput on the network and storage infrastructure, in addition to speedy SSDs. A database will only perform as quickly as its slowest component, and it is up to us to make sure that the slowest component is fast enough for our app.
然后,我们可以推断指标,例如数据库大小,内存需求,CPU和吞吐量。 我们希望我们放置数据库的硬件能够充分发挥作用,这需要我们分配足够的计算资源来实现这一目标。 10TB数据库在具有2GB RAM的服务器上可能无法很好(或根本无法)运行。 同样,高流量的应用程序除了需要快速的SSD之外,还可能需要在网络和存储基础结构上具有更快的吞吐量。 数据库的运行速度仅与最慢的组件一样快,我们需要确保最慢的组件对我们的应用程序足够快。
How will data size grow over time? Can we easily expand storage and memory easily when needed? If downtime is not an option, then we will need to consider hardware configurations that will either provide a ton of extra overhead to start or allow for seamless expansions later on. If we are not certain of data growth, do we expect the user or customer count to grow? If so, we may be able to infer data or usage growth based on this.
数据大小将如何随着时间增长? 是否可以在需要时轻松轻松地扩展存储和内存? 如果不能选择停机,那么我们将需要考虑硬件配置,这些配置将提供大量额外的启动费用,或者允许以后进行无缝扩展。 如果我们不确定数据的增长,那么我们期望用户或客户数量会增长吗? 如果是这样,我们也许可以据此推断数据或使用量的增长。
Licensing matters, too as licensing database software isn’t cheap. We should consider what edition of SQL Server will function on and what the least expensive edition is that we are allowed to use. A completely internal server with no customer-facing customer access may be able to benefit from using Developer edition. Alternatively, the choice between Enterprise and Standard may be decided by features (such as AlwaysOn) or capacity (memory limitations, for example). A link is provided at the end of this article with extensive comparisons between editions of SQL Server.
许可也很重要,因为许可数据库软件并不便宜。 我们应考虑将在哪个版本SQL Server上运行以及允许使用的最便宜版本。 没有面向客户的客户访问权限的完全内部服务器可能会从使用Developer Edition中受益。 或者,企业和标准之间的选择可以由功能(例如AlwaysOn)或容量(例如内存限制)决定。 本文结尾处提供了一个链接,其中包含SQL Server版本之间的广泛比较。
High availability and disaster recovery are very important considerations early-on that often are not visited until it is too late. What is the expected up-time of the app? How quickly are we expected to recover from an outage (recovery time objective/RTO)? In addition, how much data loss is tolerated in the event of an outage or disaster (recovery point objective,/RPO)? These are tough questions as businesses will often ask for a guarantee of zero downtime and no data loss, but will back off when they realize the cost to do so is astronomically high. This discussion is very important to have prior to an application being released as it ensures that contracts, terms of service, and other documentation accurately reflect the technical capabilities of the systems it resides on. It also allows you to plan ahead with disaster recovery plans and avoid the panic often associated with unexpected outages.
高可用性和灾难恢复是非常重要的考虑因素,通常要等到太晚才进行访问。 该应用程序的预期正常运行时间是多少? 我们期望从中断中恢复的速度有多快(恢复时间目标/ RTO)? 此外,如果发生中断或灾难(恢复点目标,/ RPO),可以容忍多少数据丢失? 这些难题是棘手的,因为企业通常要求保证零停机时间且没有数据丢失,但是当他们意识到这样做的成本天文数字很高时,就会退缩。 在发布应用程序之前进行此讨论非常重要,因为它可以确保合同,服务条款和其他文档准确反映其所驻留的系统的技术能力。 它还使您可以提前计划灾难恢复计划,并避免经常因意外中断而引起的恐慌。
资料类型 (Data types)
One of the most basic decisions that we can make when designing a database is to choose the right data types. Good choices can improve performance and maintainability. Poor choices will make work for us in the future 🙂
设计数据库时,我们可以做出的最基本的决定之一就是选择正确的数据类型。 好的选择可以提高性能和可维护性。 糟糕的选择将在未来为我们服务
Choose natural data types that fit the data being stored. A date should be a date, not a string. A bit should be a bit and not an integer or string. Many of these decisions are holdovers from years ago when data types were more limited and developers had to be creative in order to generate the data they wanted.
选择适合要存储的数据的自然数据类型。 日期应该是日期,而不是字符串。 位应该是位,而不是整数或字符串。 这些决定中有许多是几年前的决定,当时数据类型更加有限,开发人员必须具有创造力才能生成所需的数据。
Choose length, precision, and size that fits the use case. Extra precision may seem like a useful add-on, but can be confusing to developers who need to understand why a DECIMAL(18,4) contains data with only two digits of decimal detail. Similarly, using a DATETIME to store a DATE or TIME can also be confusing and lead to bad data.
选择适合用例的长度,精度和大小。 额外的精度似乎是有用的附加功能,但是对于需要理解为什么DECIMAL(18,4)包含仅两位数字的十进制详细信息的开发人员来说,这可能会造成混淆。 同样,使用DATETIME存储DATE或TIME也可能造成混乱,并导致数据损坏。
When in doubt, consider using a standard, such as ISO5218 for gender, ISO3166 for country, or ISO4217 for currency. These allow you to quickly refer anyone to universal documentation on what data should look like, what is valid, and how it should be interpreted.
如有疑问,请考虑使用诸如性别的ISO5218,国家的ISO3166或货币的ISO4217等标准。 这些使您可以快速地向任何人推荐通用文档,以了解什么样的数据,什么是有效的以及应该如何解释它们。
Avoid storing HTML, XML, JSON, or other markup languages in the database. Storing, retrieving, and displaying this data is expensive. Let the app manage data presentation, not the database. A database exists to store and retrieve data, not to generate pretty documents or web pages.
避免在数据库中存储HTML,XML,JSON或其他标记语言。 存储,检索和显示此数据非常昂贵。 让应用程序管理数据表示,而不是数据库。 存在一个数据库来存储和检索数据,而不是生成漂亮的文档或网页。
Dates and times should be consistent across all tables. If time zones or locations will matter, consider using UTC time or DATETIMEOFFSET to model them. Upgrading a database in the future to add time zone support is much harder than using these conventions in the beginning. Dates, times, and durations are different. Label them so that it is easy to understand what they mean. Duration should be stored in a one-dimensional scalar unit, such as seconds or minutes. Storing duration in the format “HH:MM:SS.mmm” is confusing and difficult to manipulate when mathematical operations are needed.
所有表中的日期和时间应该一致。 如果时区或位置很重要,请考虑使用UTC时间或DATETIMEOFFSET对其建模。 与开始时使用这些约定相比,将来升级数据库以增加时区支持要困难得多。 日期,时间和持续时间是不同的。 给它们加上标签,以便于理解它们的含义。 持续时间应以一维标量单位存储,例如秒或分钟。 当需要数学运算时,以“ HH:MM:SS.mmm”格式存储持续时间会造成混乱并且难以操作。
空值 (NULLs)
Use NULL when non-existence of data needs to be modelled in a meaningful fashion. Do not use made-up data to fill in NOT NULL columns, such as “1/1/1900” for dates, “-1” for integers, “00:00:00” for times, or “N/A” for strings. NOT NULL should mean that a column is required by an application and should always be populated with meaningful data.
当需要以有意义的方式对不存在的数据进行建模时,请使用NULL。 请勿使用虚构数据来填充NOT NULL列,例如,“ 1/1/1900”代表日期,“-1”代表整数,“ 00:00:00”代表时间,或“ N / A”代表字符串。 NOT NULL表示应用程序需要一列,并且应始终填充有意义的数据。
NULL should have meaning and that meaning should be defined when the database is being designed. For example, “request_complete_date = NULL” could mean that a request is not yet complete. “Parent_id = NULL“ could indicate an entity with no parent.
NULL应该具有含义,并且在设计数据库时应该定义含义。 例如,“ request_complete_date = NULL”可能意味着请求尚未完成。 “ Parent_id = NULL”可能表示没有父代的实体。
NULL can be eliminated by additional normalization. For example, a parent-child table could be created that models all hierarchical relationships for an entity. This may be beneficial if these relationships form a critical component of how an app operates. Reserve the removal of NULLable columns via normalization for those that are important to an app or that may require additional supporting schema to function well. As always, normalization for the sake of normalization is probably not a good thing!
可以通过其他归一化来消除NULL。 例如,可以创建一个父子表来对实体的所有层次关系进行建模。 如果这些关系构成了应用程序运行的关键组成部分,那么这可能是有益的。 通过规范化保留对应用程序很重要或可能需要其他支持架构才能正常运行的那些可空列的删除。 与往常一样,为了标准化而进行标准化可能不是一件好事!
Beware NULL behavior. ORDER BY, GROUP BY, equalities, inequalities, and aggregate functions will all treat NULL differently. Always SET ANSI_NULLS ON. When performing operations on NULLable columns, be sure to check for NULL whenever needed. Here is a simple example from Adventureworks:
当心NULL行为。 ORDER BY,GROUP BY,等式,不等式和聚合函数都将以不同的方式对待NULL。 始终将ANSI_NULLS设置为ON。 对NULLable列执行操作时,请确保在需要时检查NULL。 这是Adventureworks的一个简单示例:
SELECT
*
FROM Person.Person
WHERE Title = NULL
SELECT
*
FROM Person.Person
WHERE Title IS NULL
These queries look similar but will return different results. The first query will return 0 rows, whereas the second will return 18,963 rows:
这些查询看起来相似,但将返回不同的结果。 第一个查询将返回0行,而第二个查询将返回18,963行:
The reason is that NULL is not a value and cannot be treated like a number or string. When checking for NULL or working with NULLable columns, always check and validate if you wish to include or exclude NULL values, and always use IS NOT NULL or IS NULL, instead of =, <, >, etc…
原因是NULL不是值,不能将其视为数字或字符串。 在检查NULL或使用NULLable列时,请始终检查并验证是否要包含或排除NULL值,并始终使用IS NOT NULL或IS NULL代替=,<,>等。
SET ANSI NULLS ON is a default in SQL Server and should be left as a default. Adjusting this will change how the above behavior works and will go against ANSI standards. Building code to handle NULL effectively is a far more scalable approach than adjusting this setting.
SET ANSI NULLS ON是SQL Server中的默认值,应保留为默认值。 调整此设置将更改上述行为的工作方式,并违反ANSI标准。 构建代码以有效处理NULL是比调整此设置更具伸缩性的方法。
对象名称 (Object names)
Naming things is hard! Choosing descriptive, useful names for objects will greatly improve readability and the ability for developers to easily use those objects for their work and not make unintended mistakes.
命名很难! 为对象选择描述性,有用的名称将极大地提高可读性,并使开发人员能够轻松地将这些对象用于工作而不犯意外错误。
Name an object for what it is. Include units in the name if they are not absurdly obvious. “duration_in_seconds” is much more useful than “duration”. “Length_inches” is easier to understand than “length”. Bit columns should be named in the positive and match the business use case: “is_active”, “is_flagged_for_deletion”, “has_seventeen_pizzas”. Negative columns are usually confusing: “is_not_taxable”, “has_no_pizzas”, “is_not_active” will lead to mistakes and confusion as they are not intuitive. Database schema should not require puzzle-solving skills to understand ?
为对象命名。 如果名称不是很明显,则在名称中包括单位。 “ duration_in_seconds”比“ duration”有用得多。 “ Length_inches”比“ length”更容易理解。 位列的名称应为正,并与业务用例匹配:“ is_active”,“ is_flagged_for_deletion”,“ has_seventeen_pizzas”。 负数列通常令人困惑:“ is_not_taxable”,“ has_no_pizzas”,“ is_not_active”会导致错误和混乱,因为它们不直观。 数据库架构不应该需要解谜技巧才能理解?
Other things to avoid:
其他需要避免的事情:
- Abbreviations & shorthand. This is rarely not confusing. If typing speed is a concern for slower typists, consider the many tools available that provide Intellisense or similar auto-completion features. 缩写和速记。 这很少会引起混淆。 如果打字速度较慢的打字员担心,请考虑提供Intellisense或类似自动完成功能的许多可用工具。
- Spaces & special characters. They will break maintenance processes, confuse developers, and be a nuisance to type correctly when needed. Stick to numbers, letters, and underscores. 空格和特殊字符。 它们会破坏维护流程,使开发人员感到困惑,并且在需要时妨碍您正确键入内容。 坚持数字,字母和下划线。
- Reserved words. If it’s blue, white, or pink in SSMS, don’t use it! This only causes confusion and increases the chances of logical coding errors. 保留字。 如果它在SSMS中是蓝色,白色或粉红色,请不要使用它! 这只会引起混乱并增加逻辑编码错误的机会。
Consistency is valuable and creating effective naming schemes early will pay dividends later when there is no need to “fix” standards to not be awful. As for the debate between capitalization and whether you should use no capitals, camel case, pascal case, etc…, this is completely arbitrary and up to a development team. In databases with lots of objects, prefixes can be used to allow objects of specific types, origins, or purposes to be easily searchable. Alternatively, different schemas can be used to divide up objects of different types.
一致性是有价值的,并且当不需要为“糟糕”的标准而“固定”标准时,尽早创建有效的命名方案将为您带来回报。 至于大写与是否应该不使用大写,骆驼案,帕斯卡案等之间的争论,这完全是武断的,取决于开发团队。 在具有许多对象的数据库中,前缀可用于允许轻松搜索特定类型,起源或目的的对象。 或者,可以使用不同的模式来划分不同类型的对象。
Good object naming reduces mistakes and errors while speeding up app development. While nothing is truly self-documenting, quality object names reduce the need to find additional resources (docs or people) to determine what something is for or what it means.
良好的对象命名可以减少错误和错误,同时加快应用程序开发速度。 虽然没有什么是真正的自记录文档,但是高质量的对象名称减少了寻找其他资源(文档或人员)来确定其用途或含义的需求。
旧数据 (Old Data)
Whenever data is created, ask the question, “How long should it exist for?”. Forever is a long time and most data does not need to live forever. Find out or create a data retention policy for all data and write code to enforce it. Many businesses have compliance or privacy rules to follow that may dictate how long data needs to be retained for.
每当创建数据时,都问一个问题:“数据应存在多长时间?”。 永远是很长的时间,大多数数据并不需要永远存在。 查找或为所有数据创建数据保留策略,并编写代码以实施该策略。 许多企业都有遵从法规或隐私规则,可能会规定需要保留多长时间。
Limiting data size is a great way to improve performance and reduce data footprint! This is true for any table that stores historical data. A smaller table means smaller indexes, less storage use, less memory use, and less network bandwidth usage. All scans and seeks will be faster as the indexes are more compact and quicker to search.
限制数据大小是提高性能和减少数据占用的好方法! 对于任何存储历史数据的表都是如此。 较小的表意味着较小的索引,较少的存储使用,较少的内存使用和较少的网络带宽使用。 由于索引更紧凑且搜索更快,因此所有扫描和查找都会更快。
There are many ways to deal with old data. Here are a few examples:
有许多方法可以处理旧数据。 这里有一些例子:
- Delete it. Forever. If allowed, this is an easy and quick solution. 删除它。 永远。 如果允许,这是一个简单快捷的解决方案。
- Archive it. Copy it to a secondary location (different database, server, partition, etc…) and then delete it. 存档。 将其复制到辅助位置(不同的数据库,服务器,分区等),然后将其删除。
- Soft-delete it. Have a flag that indicates that it is no longer relevant and can be ignored in normal processes. This is a good solution when you can leverage different storage partitions, filtered indexes, or ways to segregate data as soon as it is flagged as old. 软删除它。 有一个标志,表明它不再相关,在正常过程中可以忽略。 当您可以利用不同的存储分区,过滤索引或将数据标记为旧数据时将数据隔离的方法时,这是一个很好的解决方案。
- Nothing. Some data truly is needed forever. If so, consider how to make the underlying structures scalable so that they perform well in the future. Consider how large the tables can grow. 没有。 确实确实需要一些数据。 如果是这样,请考虑如何使基础结构具有可伸缩性,以使其在将来表现良好。 考虑表可以增长到多大。
Data retention doesn’t only involve production OLTP tables, but may also include backup files, reporting data, or data copies. Be sure to apply your retention policies to everything!
数据保留不仅涉及生产OLTP表,还可能包括备份文件,报告数据或数据副本。 确保将保留政策应用于所有内容!
笛卡尔积(交叉联接/无联接谓词) (Cartesian Products (Cross Joins/No Join Predicate))
All joins occur between some data set and a new data set. In bringing them together, we are connecting them via some set of keys. When we join data sets without any matching criteria, we are performing a CROSS JOIN (or cartesian product). While this can be a useful way to generate data needed by an application, it can also be a performance and data quality issue when done unintentionally.
所有联接都发生在某些数据集和新数据集之间。 在将它们组合在一起时,我们通过一组键将它们连接起来。 当我们在没有任何匹配条件的情况下联接数据集时,我们将执行“交叉联接”(或笛卡尔积)。 尽管这可能是生成应用程序所需数据的有用方法,但如果无意间完成操作,也可能成为性能和数据质量问题。
There are a variety of ways to generate CROSS JOIN conditions:
有多种方法可以生成CROSS JOIN条件:
- Use the CROSS JOIN operator 使用CROSS JOIN运算符
- Enter incorrect join criteria 输入不正确的加入条件
- Unintentionally omit a join predicate 无意中省略了连接谓词
- Forget a WHERE clause 忘记WHERE子句
The following query is an example of the second possibility:
以下查询是第二种可能性的示例:
SELECT
Product.Name,
Product.ProductNumber,
ProductModel.Name AS Product_Model_Name
FROM Production.Product
INNER JOIN Production.ProductModel
ON ProductModel.ProductModelID = ProductModel.ProductModelID
WHERE Product.ProductID = 777;
What we expect is a single row returned with some product data. What we get instead are 128 rows, one for each product model:
我们期望的是一行返回一些产品数据。 相反,我们得到的是128行,每个产品型号对应一个:
We have two hints that something has gone wrong: An overly large result set, and an unexpected index scan in the execution plan:
我们有两个提示,表明出了点问题:结果集太大,执行计划中的索引扫描意外:
Upon closer inspection of our query, it becomes obvious that I fat-fingered the INNER JOIN and did not enter the correct table names:
在仔细检查我们的查询后,很明显,我用手指指着INNER JOIN并没有输入正确的表名:
INNER JOIN Production.ProductModel
ON ProductModel.ProductModelID = ProductModel.ProductModelID
By entering ProductModel on both sides of the join, I inadvertently told SQL Server to not join Product to ProductModel, but instead join Product to the entirety of ProductModel. This occurs because ProductModel.ProductModel will always equal itself. I could have entered “ON 1 = 1” for the join criteria and seen the same results.
通过在连接的两边都输入ProductModel ,我无意间告诉了SQL Server不要将Product连接到ProductModel ,而是将Product连接到整个ProductModel 。 发生这种情况是因为ProductModel.ProductModel将始终等于自身。 我可以为连接条件输入“ ON 1 = 1”,并看到相同的结果。
The correction here is simple, adjust the join criteria to connect Product to ProductModel, as was intended:
此处的校正很简单,按预期调整连接条件以将Product连接到ProductModel :
INNER JOIN Production.ProductModel
ON Product.ProductModelID = ProductModel.ProductModelID
Once fixed, the query returns a single row and utilizes an index seek on ProductModel.
修复后,查询将返回单行并利用ProductModel上的索引查找。
Situations in which a join predicate is missing or wrong can be difficult to detect. SQL Server does not always warn you of this situation, and you may not see an error message or show-stopping bad performance that gets your immediate attention. Here are some tips on catching bad joins before they cause production headaches:
连接谓词丢失或错误的情况可能很难检测到。 SQL Server并不总是会警告您这种情况,并且您可能不会看到引起您立即注意的错误消息或停止性能下降。 以下是在导致生产麻烦之前赶上不良联接的一些技巧:
- Make sure that each join correlates an existing data set with the new table. CROSS JOINs should only be used when needed (and intentionally) to inflate the size/depth a data set. 确保每个联接将现有数据集与新表相关联。 仅在需要时(有意地)使用CROSS JOIN来扩大数据集的大小/深度。
- An execution plan may indicate a “No Join Predicate” warning on a specific join in the execution plan. If so, then you’ll know exactly where to begin your research. 执行计划可能会在执行计划中的特定联接上指示“无联接谓词”警告。 如果是这样,那么您将确切地知道从哪里开始研究。
- Check the size of the result set. Is it too large? Are any tables being cross joined across an entire data set, resulting in extra rows of legit data with extraneous data tacked onto the end of it? 检查结果集的大小。 太大了吗 是否有任何表交叉连接到整个数据集,从而导致合法数据的额外行加上多余的数据?
- Do you see any unusual index scans in the execution plan? Are they for tables where you expect to only seek a few rows, such as in a lookup table? 您在执行计划中是否看到任何异常的索引扫描? 它们是否用于您希望仅查找几行的表(例如在查找表中)?
For reference, here is an example of what a “No Join Predicate” warning looks like:
作为参考,以下是“无连接谓词”警告的示例:
We’ll follow the standard rule that yellow and red exclamation marks will always warrant further investigation. In doing so, we can see that this specific join is flagged as having no join predicate. In a short query, this is easy to spot, but in a larger query against many tables, it is easy for these problems to get buried in a larger execution plan.
我们将遵循标准规则,即黄色和红色感叹号将始终值得进一步调查。 这样,我们可以看到此特定联接被标记为没有联接谓词。 在短查询中,这很容易发现,但是在针对许多表的较大查询中,这些问题很容易被埋入较大的执行计划中。
迭代 (Iteration)
SQL Server is optimized for set-based operations and performs best when you read and write data in batches, rather than row-by-row. Applications are not constrained in this fashion and often use iteration as a method to parse data sets.
SQL Server针对基于集合的操作进行了优化,当您批量(而不是逐行)读取和写入数据时,SQL Server的性能最佳。 应用程序不受这种方式的限制,并且经常使用迭代作为解析数据集的方法。
While it may anecdotally seem that collecting 100 rows from a table one-at-a-time or all at once would take the same effort overall, the reality is that the effort to connect to storage and read pages into memory takes a distinct amount of overhead. As a result, one hundred index seeks of one row each will take far more time and resources than one seek of a hundred rows:
也许一次或一次从一个表中收集100行可能总会花费相同的精力,但现实情况是,连接到存储并将页面读入内存的工作要花费大量的精力。高架。 结果,每行一百个索引查找要比一百行索引查找花费更多的时间和资源:
DECLARE @id INT = (SELECT MIN(BusinessEntityID) FROM HumanResources.Employee)
WHILE @id <= 100
BEGIN
UPDATE HumanResources.Employee
SET VacationHours = VacationHours + 4
WHERE BusinessEntityID = @id
AND VacationHours < 200;
SET @id = @id + 1;
END
This example is simple: iterate through a loop, update an employee record, increment a counter and repeat 99 times. The performance is slow and the execution plan/IO cost abysmal:
这个例子很简单:循环遍历,更新员工记录,增加计数器并重复99次。 性能缓慢,执行计划/ IO成本极低:
At first glance, things seem good: Lots of index seeks and each read operation is inexpensive. When we look more closely, we realize that while 2 reads may seem cheap, we need to multiply that by 100. The same is true for the 100 execution plans that were generated for all of the update operations.
乍一看,情况似乎不错:进行大量索引搜索,并且每个读取操作都很便宜。 当我们仔细观察时,我们意识到虽然2次读取可能看起来很便宜,但我们需要将其乘以100。对于为所有更新操作生成的100个执行计划,情况也是如此。
Let’s say we rewrite this to update all 100 rows in a single operation:
假设我们重写此代码以在一次操作中更新所有100行:
UPDATE HumanResources.Employee
SET VacationHours = VacationHours + 4
WHERE VacationHours < 200
AND BusinessEntityID <= 100;

Instead of 200 reads, we only need 5, and instead of 100 execution plans, we only need 1.
不需要200个读取,我们只需要5个,而不是100个执行计划,我们只需要1个。
Data in SQL Server is stored in 8kb pages. When we read rows of data from disk or memory, we are reading 8kb pages, regardless of the data size. In our iterative example above, each read operation did not simply read a few numeric values from disk and update one, but had to read all of the necessary 8kb pages needed to service the entire query.
SQL Server中的数据存储在8kb页面中。 当我们从磁盘或内存中读取数据行时,无论数据大小如何,我们都在读取8kb页面。 在上面的迭代示例中,每个读取操作都不能简单地从磁盘读取几个数值并更新一个,而是必须读取服务整个查询所需的所有8kb页面。
Iteration is often hidden from view because each operation is fast an inexpensive, making it difficult to locate it when reviewing extended events or trace data. Watching out for CURSOR use, WHILE loops, and GOTO can help us catch it, even when there is no single poor-performing operation.
迭代通常从视图中隐藏,因为每个操作快速且便宜,因此在查看扩展事件或跟踪数据时很难找到它。 警惕使用CURSOR,WHILE循环和GOTO可以帮助我们抓住它,即使没有单个性能不佳的操作也是如此。
There are other tools available that can help us avoid iteration. For example, a common need when inserting new rows into a table is to immediately return the IDENTITY value for that new row. This can be accomplished by using @@IDENTITY or SCOPE_IDENTITY(), but these are not set-based functions. To use them, we must iterate through insert operations one-at-a-time and retrieve/process the new identity values after each loop. For row counts greater than 2 or 3, we will begin to see the same inefficiencies introduced above.
还有其他可用的工具可以帮助我们避免迭代。 例如,将新行插入表中时,通常需要立即返回该新行的IDENTITY值。 这可以通过使用@@ IDENTITY或SCOPE_IDENTITY()来实现,但是这些不是基于集合的函数。 要使用它们,我们必须一次遍历插入操作,并在每次循环后检索/处理新的标识值。 对于大于2或3的行数,我们将开始看到上面介绍的相同的低效率。
The following code is a short example of how to use OUTPUT INSERTED to retrieve IDENTITY values in bulk, without the need for iteration:
以下代码是一个简短示例,说明如何使用OUTPUT INSERTED来批量检索IDENTITY值,而无需进行迭代:
CREATE TABLE #color
(color_id SMALLINT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED, color_name VARCHAR(50) NOT NULL, datetime_added_utc DATETIME);
CREATE TABLE #id_values
(color_id SMALLINT NOT NULL PRIMARY KEY CLUSTERED, color_name VARCHAR(50) NOT NULL);
INSERT INTO #color
(color_name, datetime_added_utc)
OUTPUT INSERTED.color_id, INSERTED.color_name
INTO #id_values
VALUES
('Red', GETUTCDATE()),
('Blue', GETUTCDATE()),
('Yellow', GETUTCDATE()),
('Brown', GETUTCDATE()),
('Pink', GETUTCDATE());
SELECT * FROM #id_values;
DROP TABLE #color;
DROP TABLE #id_values;
In this script, we insert new rows into #color in a set-based fashion, and pull the newly inserted IDs, as well as color_name, into a temp table. Once in the temp table, we can use those new values for whatever additional operations are required, without the need to iterate through each INSERT operation one-at-a-time.
在此脚本中,我们在基于集合的方式插入新行# 颜色 ,新插入的ID,以及COLOR_NAME,拉成一个临时表。 进入临时表后,我们可以将这些新值用于所需的任何其他操作,而无需一次遍历每个INSERT操作。
Window functions are also very useful for minimizing the need to iterate. Using them, we can pull row counts, sums, min/max values, and more without executing additional queries or iterating through data windows manually:
窗口函数对于最小化迭代需求也非常有用。 使用它们,我们可以获取行数,总和,最小值/最大值等,而无需执行其他查询或手动遍历数据窗口:
SELECT
SalesOrderHeader.SalesOrderID,
SalesOrderDetail.SalesOrderDetailID,
SalesOrderHeader.SalesPersonID,
ROW_NUMBER() OVER (PARTITION BY SalesOrderHeader.SalesPersonID ORDER BY SalesOrderDetail.SalesOrderDetailID ASC) AS SalesPersonRowNum,
SUM(SalesOrderHeader.SubTotal) OVER (PARTITION BY SalesOrderHeader.SalesPersonID ORDER BY SalesOrderDetail.SalesOrderDetailID ASC) AS SalesPersonSales
FROM Sales.SalesOrderHeader
INNER JOIN Sales.SalesOrderDetail
ON SalesOrderDetail.SalesOrderID = SalesOrderHeader.SalesOrderID
WHERE SalesOrderHeader.SalesPersonID IS NOT NULL
AND SalesOrderHeader.Status = 5;
The results of this query show us not only a row per detail line, but include a running count of orders per sales person and a running total of sales:
该查询的结果不仅向我们显示了每个明细行,而且还包括每个销售人员的连续订单计数和销售总额:
Window functions are not inherently efficient: The above query required some hefty sort operations to generate the results. Despite the cost, this is far more efficient that iterating through all sales people, orders, or some other iterative operation over a large data set:
窗口函数本身并不是有效的方法:上面的查询需要进行大量的排序操作才能生成结果。 尽管付出了代价,但与在大型数据集上遍历所有销售人员,订单或其他迭代操作相比,这要高效得多:

In addition to avoiding iteration, we also avoid the need for aggregation within our query, allowing us to freely select whatever columns we’d like without the typical constraints of GROUP BY/HAVING queries.
除了避免迭代外,我们还避免了在查询中进行聚合的需要,从而使我们可以自由选择所需的任何列,而无需GROUP BY / HAVING查询的典型约束。
Iteration is not always a bad thing. Sometimes we need to query all databases on a server or all servers in a list. Other times we need to call a stored procedure, send emails, or perform other operations that are either inefficient or impossible to do in a set-based fashion. In these scenarios, make sure that performance is adequate and that the number of times that a loop needs to be repeated is limited to prevent unexpected long-running jobs.
迭代并不总是一件坏事。 有时我们需要查询服务器上的所有数据库或列表中的所有服务器。 其他时候,我们需要调用存储过程,发送电子邮件或执行其他效率低下或无法以基于集合的方式完成的操作。 在这些情况下,请确保性能足够,并且限制需要重复循环的次数以防止意外的长时间运行的作业。
封装形式 (Encapsulation)
When writing application code, encapsulation is used as a way to reuse code and simplify complex interfaces. By packaging code into functions, stored procedures, and views, we can very easily offload important business logic or reusable code to a common place, where it can be called by any other code.
在编写应用程序代码时,封装被用作重用代码和简化复杂接口的一种方式。 通过将代码打包到函数,存储过程和视图中,我们可以很容易地将重要的业务逻辑或可重用代码卸载到一个通用位置,在该通用位置可以由任何其他代码调用。
While this sounds like a very good thing, when overused it can very quickly introduce performance bottlenecks as chains of objects linked together by other encapsulated objects increases. For example: a stored procedure that calls a stored procedure that uses a function that calls a view that calls a view that calls a view. This may sound absurd but is a very common outcome when views and nested stored procedures are relied on heavily.
虽然这听起来很不错,但是当它被过度使用时,随着其他封装对象链接在一起的对象链的增加,它会很快引入性能瓶颈。 例如:一个存储过程,该存储过程调用一个存储过程,该存储过程使用一个函数来调用一个视图,该函数调用一个视图,该视图又调用一个视图。 这听起来很荒谬,但是当严重依赖视图和嵌套存储过程时,这是非常普遍的结果。
How does this cause performance problems? Here are a few common ways:
这如何导致性能问题? 以下是一些常见的方法:
- Unnecessary joins, filters, and subqueries are applied, but not needed. 应用了不必要的联接,过滤器和子查询,但不是必需的。
- Columns are returned that are not needed for a given application. 返回给定应用程序不需要的列。
- INNER JOINs, CROSS JOINs, or filters force reads against tables that are not needed for a given operation. 内部联接,交叉联接或过滤器强制对给定操作不需要的表进行读取。
- Query size (# of tables referenced in query) results in a poor execution plan. 查询大小(查询中引用的表数)会导致执行计划不佳。
- Logical mistakes are made due to obfuscated query logic not being fully understood. 由于无法完全理解混淆的查询逻辑,因此会导致逻辑错误。
Here is an example of an AdventureWorks query in which simple intentions have complex results:
这是一个AdventureWorks查询的示例,其中简单的意图具有复杂的结果:
SELECT
BusinessEntityID,
Title,
FirstName,
LastName
FROM HumanResources.vEmployee
WHERE FirstName LIKE 'E%'
At first glance, this query is pulling only 4 columns from the employee view. The results are what we expect, but it runs a bit longer than we’d want (over 1 second). Checking the execution plan and IO stats reveals:
乍一看,此查询仅从员工视图中拉出4列。 结果是我们所期望的,但运行时间比我们想要的要长一点(超过1秒)。 检查执行计划和IO统计信息会发现:
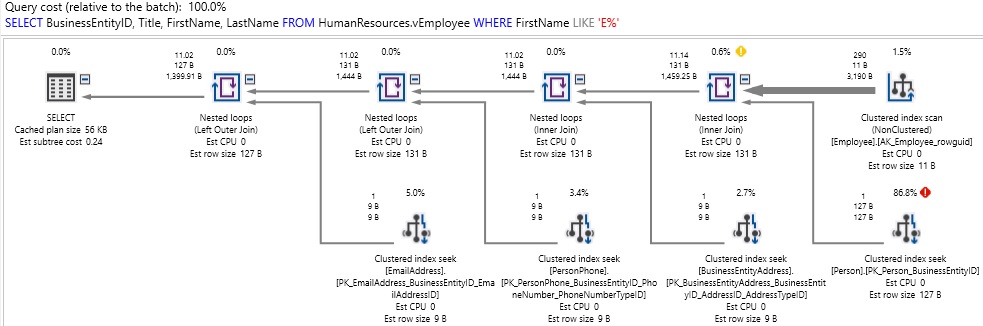
What we discover is that there was quite a bit going on behind-the-scenes that we were not aware of. Tables were accessed that we didn’t need, and excess reads performed as a result. This leads us to ask: What is in vEmployee anyway!? Here is the definition of this view:
我们发现,有很多幕后事件我们还没有意识到。 访问了我们不需要的表,结果执行了多余的读取。 这导致我们问: vEmployee到底有什么!? 这是此视图的定义:
CREATE VIEW [HumanResources].[vEmployee]
AS
SELECT
e.[BusinessEntityID]
,p.[Title]
,p.[FirstName]
,p.[MiddleName]
,p.[LastName]
,p.[Suffix]
,e.[JobTitle]
,pp.[PhoneNumber]
,pnt.[Name] AS [PhoneNumberType]
,ea.[EmailAddress]
,p.[EmailPromotion]
,a.[AddressLine1]
,a.[AddressLine2]
,a.[City]
,sp.[Name] AS [StateProvinceName]
,a.[PostalCode]
,cr.[Name] AS [CountryRegionName]
,p.[AdditionalContactInfo]
FROM [HumanResources].[Employee] e
INNER JOIN [Person].[Person] p
ON p.[BusinessEntityID] = e.[BusinessEntityID]
INNER JOIN [Person].[BusinessEntityAddress] bea
ON bea.[BusinessEntityID] = e.[BusinessEntityID]
INNER JOIN [Person].[Address] a
ON a.[AddressID] = bea.[AddressID]
INNER JOIN [Person].[StateProvince] sp
ON sp.[StateProvinceID] = a.[StateProvinceID]
INNER JOIN [Person].[CountryRegion] cr
ON cr.[CountryRegionCode] = sp.[CountryRegionCode]
LEFT OUTER JOIN [Person].[PersonPhone] pp
ON pp.BusinessEntityID = p.[BusinessEntityID]
LEFT OUTER JOIN [Person].[PhoneNumberType] pnt
ON pp.[PhoneNumberTypeID] = pnt.[PhoneNumberTypeID]
LEFT OUTER JOIN [Person].[EmailAddress] ea
ON p.[BusinessEntityID] = ea.[BusinessEntityID];
This view does not only contain basic Employee data, but also many other tables as well that we have no need for in our query. While the performance we experienced might be acceptable under some circumstances, it’s important to understand the contents of any objects we use to the extent that we can use them effectively. If performance were a key issue here, we could rewrite our query as follows:
该视图不仅包含基本的Employee数据,而且还包含许多我们不需要的其他表。 尽管在某些情况下我们接受的性能可能是可以接受的,但重要的是要了解我们所使用的任何对象的内容,以使我们可以有效地使用它们。 如果性能是此处的关键问题,我们可以按以下方式重写查询:
SELECT
e.BusinessEntityID,
p.Title,
p.FirstName,
p.LastName
FROM HumanResources.Employee e
INNER JOIN Person.Person p
ON p.BusinessEntityID = e.BusinessEntityID
WHERE FirstName LIKE 'E%'
This version only accesses the tables we need, thereby generating half the reads and a much simpler execution plan:
该版本仅访问我们所需的表,从而生成一半的读取次数和一个更简单的执行计划:
It is important to note that encapsulation is in no way a bad thing, but in the world of data, there are dangers to over-encapsulating business logic within the database. Here are some basic guidelines to help in avoiding performance problems resulting from the nesting of database objects:
重要的是要注意,封装绝不是一件坏事,但是在数据世界中,存在将业务逻辑过度封装在数据库中的危险。 以下是一些基本准则,可帮助避免由于数据库对象嵌套而导致的性能问题:
- When possible, avoid nesting views within views. This improves visibility into code and reduces the chances of misunderstanding the contents of a given view. 尽可能避免在视图中嵌套视图。 这样可以提高对代码的可见性,并减少误解给定视图内容的机会。
- Avoid nesting functions if possible. This can be confusing and lead to challenging performance problems. 尽可能避免嵌套函数。 这可能会造成混淆,并导致挑战性的性能问题。
- Avoid triggers that call stored procedures or that perform too much business logic. Nested triggers are equally dangerous. Use caution when operations within triggers can fire more triggers. 避免触发调用存储过程或执行过多业务逻辑的触发器。 嵌套触发器同样危险。 当触发器内的操作可以触发更多触发器时,请谨慎使用。
- Understand the functionality of any defined objects (functions, triggers, views, stored procedures) prior to use. This will avoid misunderstandings of their purpose. 使用前了解任何已定义对象的功能(功能,触发器,视图,存储过程)。 这样可以避免对它们目的的误解。
Storing important and frequently used TSQL in stored procedures, views, or functions can be a great way to increase maintainability via code reuse. Exercise caution and ensure that the complexity of encapsulated objects does not become too high. Performance can be inadvertently impacted when objects are nested many layers deep. When troubleshooting a problem query, always research the objects involved so that you have full exposure to any views, functions, stored procedures, or triggers that may also be involved in its execution.
在存储过程,视图或函数中存储重要且经常使用的TSQL是通过代码重用提高可维护性的好方法。 谨慎行事,并确保封装对象的复杂性不会变得太高。 当对象嵌套很多层时,性能可能会受到无意影响。 在对问题查询进行故障排除时,请始终研究涉及的对象,以便您可以充分了解其执行过程中可能涉及的任何视图,函数,存储过程或触发器。
OLTP与OLAP (OLTP vs. OLAP)
Data is typically accessed either for transactional needs or analytical (reporting) needs. A database can be effectively optimized to handle either of these scenarios very well. The ways in which we performance tune for each is very different and needs some consideration when designing database elements.
通常针对事务需求或分析(报告)需求访问数据。 可以有效地优化数据库,以很好地处理这两种情况。 我们对每种性能进行调整的方式非常不同,在设计数据库元素时需要考虑一些因素。
OLTP (OLTP)
Online transaction processing refers to workloads in which data is written to and read for common interactive business usage. OLTP workloads are typically characterized by the following patterns:
在线事务处理是指工作负载,在其中写入和读取数据以用于常见的交互式业务用途。 OLTP工作负载通常具有以下特征:
- More writes, such as adding new data, updating rows, or deleting rows. 更多写操作,例如添加新数据,更新行或删除行。
- More interactive operations in which people are logging into apps or web sites and directly viewing or modifying data. This comprises common business tasks. 人们可以登录到应用程序或网站并直接查看或修改数据的更具交互性的操作。 这包括常见的业务任务。
- Operations on smaller row counts, such as updating an order, adding a new contact, or viewing recent transactions in a store. These operations often operate on current or recent data only. 对较小行数的操作,例如更新订单,添加新联系人或查看商店中的最近交易。 这些操作通常仅对当前或最近的数据进行操作。
- More tables and joins involved in queries. 查询中涉及更多的表和联接。
- Timeliness is important. Since users are waiting for results, latency is not tolerated. 及时性很重要。 由于用户正在等待结果,因此不容许延迟。
- High transaction counts, but typically small transaction size. 事务计数高,但通常事务规模小。
OLTP environments tend to be more relational, with indexes targeted at common updates, searches, or operations that are the core of an application. OLTP processes generally ensure, and rely on data integrity. This may necessitate the use of foreign keys, check constraints, default constraints, or triggers to assist in guaranteeing real-time data integrity.
OLTP环境往往具有更强的关系性,索引针对的是作为应用程序核心的常见更新,搜索或操作。 OLTP流程通常可确保并依赖于数据完整性。 这可能需要使用外键,检查约束,默认约束或触发器来帮助保证实时数据完整性。
OLAP (OLAP)
Online analytical processing generally refers to reporting or search environments. These are used for crunching large volumes of data, such as in reporting, data mining, or analytics. Common features of OLAP workloads are:
在线分析处理通常是指报告或搜索环境。 这些用于处理大量数据,例如在报告,数据挖掘或分析中。 OLAP工作负载的共同特征是:
- Typical workloads are read-only, with writes only occurring during designated load/update times. 典型的工作负载是只读的,仅在指定的加载/更新时间内发生写操作。
- Many operations are automated or scheduled to run and be delivered to users at a later time. These processes are often used to gain insight into a business and to assist in decision making processes. 许多操作是自动化的或已安排运行的,并在以后交付给用户。 这些流程通常用于深入了解业务并协助制定决策流程。
- Operations can run on very large quantities of data. This can be crunching data year-over-year, trending spending over the past quarter, or any other task that may require pulling a longer history to complete. 操作可以在大量数据上运行。 这可能是与去年同期相比数据紧缩,过去一个季度的支出趋势或其他任何可能需要拉长历史才能完成的任务。
- Tables tend to be wider and fewer, allowing for reports to be generated with less joins or lookups. 表格往往更宽,更少,从而允许使用更少的联接或查找来生成报告。
- Users may not be waiting for results, which can be delivered via email, file, or some other asynchronous means. If they are, there may be an expectation of delay due to the size of data. For reports where timeliness is important, the data can be crunched and staged ahead of time to assist in speedy results when requested. 用户可能不等待结果,结果可以通过电子邮件,文件或其他异步方式传递。 如果是这样,可能会由于数据大小而导致延迟。 对于及时性很重要的报告,可以在需要时对数据进行整理和分级,以帮助快速获得结果。
- Low transaction count, but typically large transaction sizes. 交易数量少,但通常交易规模大。
OLAP environments are usually flatter and less relational. Data is created in OLTP applications and then passed onto OLAP environments where analytics can take place. As a result, we can often assume that data integrity has already been established. As a result, constraints, keys, and other similar checks can often be omitted.
OLAP环境通常更平坦,关系更少。 数据在OLTP应用程序中创建,然后传递到可以进行分析的OLAP环境中。 结果,我们经常可以假设已经建立了数据完整性。 结果,通常可以省略约束,键和其他类似的检查。
If data is crunched or transformed, we can validate it afterwards, rather than real-time as with OLTP workloads. Quite a bit of creativity can be exercised in OLAP data, depending on how current data needs to be, how quickly results are requested, and the volume of history required to service requests.
如果数据受到限制或转换,我们可以事后进行验证,而不是像OLTP工作负载那样进行实时验证。 OLAP数据可以发挥很多创造力,这取决于当前数据的需要方式,请求结果的速度以及处理请求所需的历史记录量。
使它们分开 (Keeping them separated)
Due to their vastly different needs, it behooves us to separate transactional and analytical systems as much as possible. One of the most common reasons that applications become slow and we resort to NOLOCK hints is when we try to run huge search queries or bulky reports against our transactional production application. As transaction counts become higher and data volume increases, the clash between transactional operations and analytical ones will increase. The common results are:
由于它们的需求截然不同,因此我们应该尽可能地将事务和分析系统分开。 应用程序变慢并且诉诸于NOLOCK提示的最常见原因之一是,当我们尝试针对事务型生产应用程序运行大型搜索查询或大型报告时。 随着事务计数的增加和数据量的增加,事务操作与分析操作之间的冲突将增加。 常见的结果是:
- Locking, blocking, and deadlocks when a large search/report runs and users are trying to update data. 当运行较大的搜索/报告并且用户试图更新数据时,将发生锁定,阻塞和死锁。
- Over-indexing of tables in an effort to service all kinds of different queries. 表的过度索引,旨在为各种不同的查询提供服务。
- The removal of foreign keys and constraints to speed up writes. 删除外键和约束以加快写入速度。
- Application latency. 应用程序延迟。
- Use of query hints as workarounds to performance problems. 使用查询提示作为性能问题的解决方法。
- Throwing hardware at the database server in an effort to improve performance. 在数据库服务器上扔硬件以提高性能。
The optimal solution is to recognize the difference between OLAP and OLTP workloads when designing an application, and separate these environments on day 1. This often doesn’t happen due to time, cost, or personnel constraints.
最佳解决方案是在设计应用程序时识别OLAP和OLTP工作负载之间的差异,并在第1天将这些环境分开。由于时间,成本或人员限制,这种情况通常不会发生。
Regardless of the severity of the problem or how long it has persisted, separating operations based on their type is the solution. Creating a new and separate environment to store OLAP data is the first step. This may be developed using AlwaysOn, log shipping, ETL processes, storage-level data copying, or many other solutions to make a copy of the OLTP data.
不管问题的严重性或持续的时间长短,解决方案都是根据其类型将操作分开。 第一步是创建一个新的单独的环境来存储OLAP数据。 可以使用AlwaysOn,日志传送,ETL流程,存储级数据复制或许多其他解决方案来制作OLTP数据,以开发此文件。
Once available, offloading operations can be a process that occurs over time. Easing into it allows for more QA and caution as a business grows familiar with new tools. As more operations are moved to a separate data store, you’ll be able to take remove reporting indexes from the OLTP data source and further optimize it for what it does best (service OLTP workloads). Similarly, the new OLAP data store can be optimized for analytics, allowing you to flatten tables, remove constraints and OLTP indexes, and make it faster for the operations that it services.
一旦可用,卸载操作可能是一个随时间推移发生的过程。 随着企业对新工具的日益熟悉,对其进行简化可以带来更多的质量检查和注意事项。 随着更多的操作转移到单独的数据存储中,您将能够从OLTP数据源中删除报告索引,并针对最佳性能(服务OLTP工作负载)对其进行进一步优化。 同样,可以优化新的OLAP数据存储以进行分析,使您可以展平表,删除约束和OLTP索引,并使其更快地进行服务。
The more separated processes become, the easier it is to optimize each environment for its core uses. This results not only in far better performance, but also ease of development of new features. Tables built solely for reporting are far easier to write queries against than transactional tables. Similarly, being able to update application code with the knowledge that large reports won’t be running against the database removes many of the performance worries that typically are associated with a mixed environment.
流程变得越分离,就越容易针对其核心用途优化每个环境。 这不仅带来了更好的性能,而且还简化了新功能的开发。 仅针对报表而构建的表比对事务表的查询要容易得多。 同样,能够在不针对数据库运行大型报表的情况下更新应用程序代码,从而消除了通常与混合环境相关的许多性能担忧。
扳机 (Triggers)
Triggers themselves are not bad, but overuse of them can certainly be a performance headache. Triggers are placed on tables and can fire instead of, or after inserts, updates, and/or deleted.
触发器本身并不坏,但过度使用触发器肯定会引起性能头痛。 Triggers are placed on tables and can fire instead of, or after inserts, updates, and/or deleted.
The scenarios when they can become performance problems is when there are too many of them. When updating a table results in inserts, updates, or deletes against 10 other tables, tracking performance can become very challenging as determining the specific code responsible can take time and lots of searching.
The scenarios when they can become performance problems is when there are too many of them. When updating a table results in inserts, updates, or deletes against 10 other tables, tracking performance can become very challenging as determining the specific code responsible can take time and lots of searching.
Triggers often are used to implement business/application logic, but this is not what a relational database is built or optimized for. In general, applications should manage as much of this as possible. When not possible, consider using stored procedures as opposed to triggers.
Triggers often are used to implement business/application logic, but this is not what a relational database is built or optimized for. In general, applications should manage as much of this as possible. When not possible, consider using stored procedures as opposed to triggers.
The danger of triggers is that they become a part of the calling transaction. A single write operation can easily become many and result in waits on other processes until all triggers have fired successfully.
The danger of triggers is that they become a part of the calling transaction. A single write operation can easily become many and result in waits on other processes until all triggers have fired successfully.
To summarize some best practices:
To summarize some best practices:
- Use triggers only when needed, and not as a convenience or time-saver. Use triggers only when needed, and not as a convenience or time-saver.
- Avoid triggers that call more triggers. These can lead to crippling amounts of IO or complex query paths that are frustrating to debug. Avoid triggers that call more triggers. These can lead to crippling amounts of IO or complex query paths that are frustrating to debug.
- Server trigger recursion should be turned off. This is the default. Allowing triggers to call themselves, directly or indirectly, can lead to unstable situations or infinite loops. Server trigger recursion should be turned off. 这是默认值。 Allowing triggers to call themselves, directly or indirectly, can lead to unstable situations or infinite loops.
- Keep triggers simple and have them execute a single purpose. Keep triggers simple and have them execute a single purpose.
结论 (Conclusion)
Troubleshooting performance can be challenging, time-consuming, and frustrating. One of the best ways to avoid these troubles is to build a database intelligently up-front and avoid the need to have to fix things later.
Troubleshooting performance can be challenging, time-consuming, and frustrating. One of the best ways to avoid these troubles is to build a database intelligently up-front and avoid the need to have to fix things later.
By gathering information about an application and how it is used, we can make smart architecture decisions that will make our database more scalable and perform better over time. The result will be better performance and less need to waste time on troubleshooting broken things.
By gathering information about an application and how it is used, we can make smart architecture decisions that will make our database more scalable and perform better over time. The result will be better performance and less need to waste time on troubleshooting broken things.
目录 (Table of contents)
| Query optimization techniques in SQL Server: the basics |
| Query optimization techniques in SQL Server: tips and tricks |
| Query optimization techniques in SQL Server: Database Design and Architecture |
| Query Optimization Techniques in SQL Server: Parameter Sniffing |
| SQL Server中的查询优化技术:基础 |
| SQL Server中的查询优化技术:提示和技巧 |
| SQL Server中的查询优化技术:数据库设计和体系结构 |
| SQL Server中的查询优化技术:参数嗅探 |















 1528
1528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









