





SQL Server 2016 is the most advanced version of Microsoft’s Data Platform released yet. This is obviously my favorite one as it has tremendous capabilities and enormous features. These new additions not only enhance the productivity of its users (Database Developer, DBA or Application Developer), but also enable the enterprise to use its data more effectively and efficiently.
SQL Server 2016是迄今为止发布的Microsoft数据平台的最高级版本。 显然,这是我最喜欢的功能,因为它具有强大的功能和强大的功能。 这些新增加的功能不仅可以提高其用户(数据库开发人员,DBA或应用程序开发人员)的工作效率,还可以使企业更有效地使用其数据。
Microsoft SQL Server 2016 offer a lot of features and enhancements which cannot be covered in a single article. Though, in this article I will try to outline a couple of most useful T-SQL and SQL Server Engine Enhancements which are not commonly used, but they can make life of the user easier and boost up the enterprise productivity.
Microsoft SQL Server 2016提供了许多功能和增强功能,这些功能和增强功能无法在一篇文章中介绍。 但是,在本文中,我将尝试概述一些最不常用的最有用的T-SQL和SQL Server Engine增强功能,但是它们可以使用户的生活更轻松并提高企业生产率。
T-SQL is most used feature in the life of a DBA/Developer. Microsoft has focused on this part in almost every release of its SQL Server version.
T-SQL是DBA /开发人员一生中最常用的功能。 Microsoft几乎在其SQL Server版本的每个发行版中都专注于这一部分。
Mentioned below are couple of T-SQL enhancements which are most useful for all DBAs/Developers but are rarely talked about.
下面提到的是几个T-SQL增强功能,这些增强功能对所有DBA /开发人员都非常有用,但鲜有提及。
1.更灵活的TRUNCATE TABLE: (1. The more flexible TRUNCATE TABLE:)
TRUNCATE TABLE is not the favorite command of DBAs, especially while using the partitions. But that was history. Now, we can easily use the TRUNCATE TABLE in partitions to remove the data of specific partitions in a blink of an eye. Let me give you a small demo for this.
TRUNCATE TABLE不是DBA的常用命令,尤其是在使用分区时。 但这就是历史。 现在,我们可以轻松地在分区中使用TRUNCATE TABLE来瞬间删除特定分区的数据。 让我给你一个小演示。
To test the scenario, we need to create a table with partition and put some data. Then we will try to remove data from a single partition using TRUNCATE TABLE.
为了测试该场景,我们需要创建一个带有分区的表并放置一些数据。 然后,我们将尝试使用TRUNCATE TABLE从单个分区中删除数据。
Note: To benefit from this feature, you need to have all the indexes aligned to the partition.
注意:要利用此功能,您需要使所有索引与分区对齐。
Create a Table with some columns:
用一些列创建一个表:

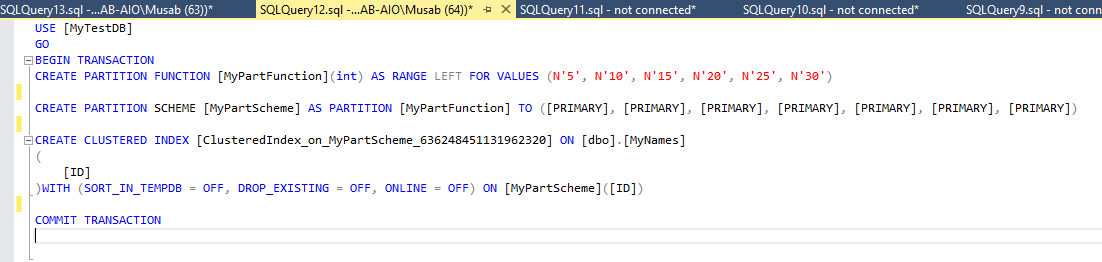
After creating the required schema, we can create Partition Function, Partition Scheme and create a Clustered Index on the table using the newly created Function and Scheme.
创建所需的架构后,我们可以创建分区功能,分区方案,并使用新创建的功能和方案在表上创建聚簇索引。
We have partitions (just for the demo we have small partitions but in your production you can test on large tables with huge partitions) with 5 rows each.
我们有分区(对于演示来说,我们有小分区,但是在您的生产中,您可以在具有大分区的大表上进行测试),每个分区有5行。
Now, we will insert some data with names of my friends, 5 times each.
现在,我们将插入一些带有我朋友名字的数据,每次5次。

After the insert used above, we can see that the table is filled with sample data of 30 rows.
在上面使用了插入之后,我们可以看到该表填充了30行的样本数据。

Now let’s see how the magic of TRUNCATE TABLE with PARITION Clause works!
现在,让我们看看带有PARITION子句的TRUNCATE TABLE的魔力是如何工作的!
For instance, we might have the requirement of removing the data of first partition containing “Noman” from the table completely. (Nothing is wrong with the name Noman, it’s just that Noman might not be with us anymore so we have to remove his name ).
例如,我们可能需要从表中完全删除包含“ Noman”的第一个分区的数据。 (Noman这个名字没什么错,只是Noman可能不再与我们在一起,所以我们必须删除他的名字)。
As we know that the first five rows are in the partition number 1 and we want to delete all those rows. To do this, we will use TRUNCATE TABLE with PARTITIONS clause.
我们知道前五行在分区号1中,我们想删除所有这些行。 为此,我们将TRUNCATE TABLE与PARTITIONS子句一起使用。
The mentioned below command of TRUNCATE TABLE with PARTITIONS clause will remove only first partition’s data i.e. truncate the partition number one.
下面提到的带有PARTITIONS子句的TRUNCATE TABLE命令将仅删除第一个分区的数据,即截断分区号1。
Note: We can use multiple Partition numbers in the PARTITIONS clause to delete data simultaneously for multiple partitions.
注意:我们可以在PARTITIONS子句中使用多个分区号来同时删除多个分区的数据。

After the above statement executed successfully, we can see that all the rows in first partition are no longer in the table. And this is really a handy way to remove one partition’s data or even more partition numbers can be specified in this clause as per your requirements.
成功执行以上语句后,我们可以看到表中不再有第一个分区中的所有行。 这实际上是删除一个分区的数据的便捷方法,甚至可以根据您的要求在此子句中指定更多的分区号。

2.新的String函数用于拆分 (2. New String function for splitting)
Every Database Administrator I know has his own string splitting function which he has written him in T-SQL or using some CLR functions. And generally I see a lot of functions in every environment. This is not very complex to implement but still in every new environment we might need to enable the CLR and deploy the DLL or even we might end up in re-writing what we already did.
我认识的每个数据库管理员都有自己的字符串拆分功能,该功能是他用T-SQL或使用一些CLR函数编写的。 通常,我在每个环境中都会看到很多功能。 这实现起来不是很复杂,但是仍然在每个新环境中,我们可能都需要启用CLR和部署DLL,或者甚至可能最终要重写已经完成的工作。
With SQL Server 2016 the pain is over. You can simply use STRING_SPLIT table valued function to get a string split based on a separator.
使用SQL Server 2016时,痛苦已经过去。 您可以简单地使用STRING_SPLIT表值函数来基于分隔符来拆分字符串。
The simplest example would be like this:
最简单的示例如下所示:

Though, there are endless ways you can use this T-SQL function but I will show you another useful feature of STRING_SPLIT which can be beneficial to Database or Application Developers.
虽然,您可以通过多种方式使用此T-SQL函数,但是我将向您展示STRING_SPLIT的另一个有用功能,该功能可能对数据库或应用程序开发人员有所帮助。
Here I have used a string with random County names separated by Comma. I used the Table Valued Function STRING_SPLIT to join it with a table named “Countries”. The aim is to get all the countries in the Countries table which match the variable values.
在这里,我使用了一个字符串,其中随机县名用逗号分隔。 我使用表值函数STRING_SPLIT将其与名为“ Countries”的表连接起来。 目的是获得“国家”表中所有与变量值匹配的国家。
This is one of the most common ways developer use to search items. Though, it’s not the best way but this is to show you that how flexible is the function and it can be used in multiple ways.
这是开发人员用于搜索项目的最常用方法之一。 虽然,这不是最好的方法,但这是向您展示该功能的灵活性,并且可以多种方式使用它。

The Countries table is joined with STRING_SPLIT table valued function on the column “CountryName” from Countries table and column Value (the default column from the STRING_SPLIT function) from the STRING_SPLIT function. Based on this join, only values matching the string are returned.
国家表与国家表的“ CountryName”列上的STRING_SPLIT表值函数以及STRING_SPLIT函数的“值”列(STRING_SPLIT函数的默认列)结合在一起。 基于此连接,仅返回与字符串匹配的值。
Mentioned below are couple of enhancements which are done in the engine of Microsoft SQL Server 2016. These are also very useful but uncommon. These make the life of a DBA a lot easier and administration work more productive.
下面提到的是在Microsoft SQL Server 2016引擎中完成的几项增强。它们也非常有用,但并不常见。 这些使DBA的工作更加轻松,并且管理工作效率更高。
3.数据库级别的“自动增长单个或所有文件”功能: (3. “Auto grow Single or All files” features at Database Level:)
We all know that in large environments we have to use multiple data files. Ideally speaking, all the data files should grow in equal sizes. This is not directly supported by default in SQL Server 2014 and earlier editions.
我们都知道,在大型环境中,我们必须使用多个数据文件。 理想情况下,所有数据文件都应以相等的大小增长。 默认情况下,SQL Server 2014和早期版本中不直接支持此功能。
Before SQL Server 2016, to make the files grow equally we used the Trace flag 1117. Now this is no more required and not even effective. The ALTER DATABASE command with AUTOGROW_SINGLE_FILE or AUTOGROW_ALL_FILES has the flexibility of using the Auto Growth for all or single file at File Group level.
在SQL Server 2016之前,为了使文件平均增长,我们使用了跟踪标志1117。现在,这不再是必需的,甚至没有效果。 带有AUTOGROW_SINGLE_FILE或AUTOGROW_ALL_FILES的ALTER DATABASE命令具有在文件组级别对所有文件或单个文件使用自动增长的灵活性。
Let’s have a small demo to see how it works.
让我们做一个小演示,看看它是如何工作的。
I created a small database with 4 data files of 3 MB of equal size.
我创建了一个小型数据库,其中包含4个大小相等的3 MB数据文件。

The current size of all the files are as follow
当前所有文件的大小如下

Now, let us update the database with AUTOGROW_SINGLE_FILE using the mentioned below command.
现在,让我们使用下面提到的命令使用AUTOGROW_SINGLE_FILE更新数据库。
Note: Please note that all the mentioned below commands “altering the database” must be issued with no users connected to it. These command require exclusive lock on database.
注意:请注意,下面提到的所有“更改数据库”命令必须在没有用户连接的情况下发出。 这些命令需要对数据库的排他锁。

Now, I have started to insert the data in the table using a loop. As soon as the files started to grow, the database files also expanded in Round Robin algorithm.
现在,我开始使用循环将数据插入表中。 文件开始增长后,数据库文件也以Round Robin算法扩展。
The file sizes looked like this after a while:
一段时间后,文件大小如下所示:

Here we can see that the files are growing one by one. The first & second files are of 4 MB while the 3rd & 4th are of 5MB. The files are incremented by 1 MB.
在这里我们可以看到文件正在逐一增长。 第一个和第二个文件的大小为4 MB,而第三个和第 4 个文件的大小为5MB。 文件增加1 MB。
So, this was the behavior with single file size growth.
因此,这就是单个文件大小增长的行为。
Note: This small size increment to data or log file is NOT recommended in production. This is just to show the demo for file growth. In Production environment always use a large file growth rate of at least 1 GB or more whichever is suitable.
注意:在生产中不建议这种小的数据或日志文件增量。 这只是为了演示文件增长的演示。 在生产环境中,请始终使用至少1 GB或更大的较大文件增长速率(以适当者为准)。
Now we will see how the AUTOGRO_ALL_FILES will work. I will issue the mentioned below command on the same database.
现在,我们将看到AUTOGRO_ALL_FILES将如何工作。 我将在同一数据库上发出以下提到的命令。

After I started to insert data in the tables which were in the Primary file group, all files started to grow in parallel.
在我开始将数据插入到主文件组中的表中之后,所有文件开始并行增长。

So, here we can see that all the files are growing equally and this is the result of AUTOGROW_ALL_FILES.
因此,在这里我们可以看到所有文件都在平均增长,这是AUTOGROW_ALL_FILES的结果。
The AUTOGROW_SINGLE_FILE is enabled by DEFAULT on user databases and AUTOGROW_ALL_FILES is enabled by default on TEMPDB. This is really helpful as we always have to do this after a while on production database servers with high volume of data.
默认情况下,在用户数据库上启用了AUTOGROW_SINGLE_FILE,默认情况下在TEMPDB上启用了AUTOGROW_ALL_FILES。 这确实很有帮助,因为我们总是需要一段时间才能在具有大量数据的生产数据库服务器上执行此操作。
Microsoft is using the industry led best practices to be defaults, making the database servers run faster from day 1 and for a long time period. Though there are a lot of other configurations which depends upon the environment and needs expert judgment and detailed knowledge of the load on the server.
Microsoft将业界领先的最佳做法用作默认值,从而使数据库服务器从第一天开始就运行了很长时间。 尽管还有许多其他配置,这些配置取决于环境,并且需要专家判断和服务器负载的详细知识。
4.控制DBCC CHECKDB,CHECKTABLE和CHECKFILEGROUP的CPU使用率。 (4. Controlling CPU Usage for DBCC CHECKDB, CHECKTABLE & CHECKFILEGROUP.)
CHECKDB, CHECKTABLE & CHECKFILEGROUP are some of the most important features for Database Administrators which they use for checking the integrity of databases. But normally we do not get enough downtime or resources to run it on production servers. This is because the commands are Resource Intensive and we cannot control the resource allocation for them. This is the story for Microsoft SQL Server 2014 and earlier versions.
CHECKDB,CHECKTABLE和CHECKFILEGROUP是数据库管理员最重要的功能,可用于检查数据库的完整性。 但是通常我们没有足够的停机时间或资源来在生产服务器上运行它。 这是因为命令是资源密集型的,我们无法控制它们的资源分配。 这是Microsoft SQL Server 2014和更早版本的故事。
Now, we have the ability to change how many processors are being used by these commands. By default, these commands use all the processors available in the session based on Resource Governor or the Server Level MAXDOP Settings. But now SQL Server 2016 (and SQL Server 2014 SP2) enables users to use MAXDOP settings for individual commands.
现在,我们可以更改这些命令使用的处理器数量。 默认情况下,这些命令使用基于资源调控器或服务器级别MAXDOP设置的会话中可用的所有处理器。 但是现在,SQL Server 2016(和SQL Server 2014 SP2)使用户可以对单个命令使用MAXDOP设置。
The examples mentioned below are for executing DBCC CHECKDB for the sample database WideWorldImporters. These commands are executed one by one. You can see the difference between the CPU and elapsed time.
下面提到的示例用于为示例数据库WideWorldImporters执行DBCC CHECKDB。 这些命令一一执行。 您可以看到CPU和经过时间之间的时差。

Even on my low-end machine with a 3 GB database, it made a 5 seconds difference. Just see the flexibility we can have with these commands.
即使在我的具有3 GB数据库的低端计算机上,它也相差5秒。 只需看一下这些命令所具有的灵活性即可。
The CHECKDB with MAXDOP 1 took less CPU and more time but the same command with MAXDOP 0 (which means the command will use all available processors) took more CPU but less time.
使用MAXDOP 1的CHECKDB占用更少的CPU和更多的时间,但是使用MAXDOP 0的相同命令(这意味着该命令将使用所有可用的处理器)花费了更多的CPU,但是花费的时间更少。
So, now we can control the execution behavior of CHECKDB. CHECKTABLE & CHECKFILEGROUP commands and optimize according to our enterprise requirement.
因此,现在我们可以控制CHECKDB的执行行为。 CHECKTABLE&CHECKFILEGROUP命令并根据我们的企业要求进行优化。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









