





sql azure 语法
In this article, we will review how to configure the sync group to replicate data between Azure SQL databases using Azure SQL Data Sync.
在本文中,我们将回顾如何配置同步组以使用Azure SQL数据同步在Azure SQL数据库之间复制数据。
Azure SQL Data Sync is a service that is used to replicate the tables in Azure SQL database to another Azure SQL database or on-premises databases. Data can be replicated one way or bidirectional.
Azure SQL数据同步是一项服务,用于将Azure SQL数据库中的表复制到另一个Azure SQL数据库或本地数据库。 数据可以单向或双向复制。
We will be discussing the following topics in this article:
我们将在本文中讨论以下主题:
- Creating a sync group 创建一个同步组
- Adding the member databases 添加成员数据库
- Adding the tables to the sync group 将表添加到同步组
- Replicating schema changes 复制架构更改
- Limitations of Azure SQL Data Sync service Azure SQL数据同步服务的局限性
- Consideration while using triggers on both hub and member databases 在中心数据库和成员数据库上使用触发器时的注意事项
创建一个同步组 (Creating a sync group)
To create a sync group, Navigate to All resources page or SQL databases page and click on the database which will act as a hub database.
要创建同步组,请导航到“所有资源”页面或“ SQL数据库”页面,然后单击将用作中心数据库的数据库。
In the database details page, click on Sync to other databases and click on New Sync Group as shown in the below image.
在数据库详细信息页面中,单击“ 同步到其他数据库” ,然后单击“ 新建同步组” ,如下图所示。
Enter the name of the sync group and choose the Sync Metadata Database. If you choose New database, then a new database is created on the server you choose with tables that store the sync information. If you choose to use an existing database, all the available databases on the server are shown in the drop-down and you must select one. The tables are created in the database you selected to store sync information. Set Automatic sync On and set the frequency to sync the data changes automatically at a specified interval.
输入同步组的名称,然后选择“ 同步元数据数据库”。 如果选择“新建数据库”,则会在您选择的服务器上使用存储同步信息的表创建一个新数据库。 如果选择使用现有数据库,则服务器上所有可用的数据库都会显示在下拉列表中,并且您必须选择一个。 这些表是在您选择用来存储同步信息的数据库中创建的。 将自动同步设置为开,并设置频率以指定的时间间隔自动同步数据更改。
Conflict resolution: Conflict occurs when the data is modified on the Azure SQL hub and member database within the same sync cycle. Conflict resolution helps which change needs to be persisted. We have only two options available as of now unlike in SQL Server replication. We cannot have a custom conflict resolver to resolve conflict when it occurs. If you choose Hub to win as Conflict resolution, then the change from Hub database is persisted. If you choose Member to win as conflict resolution, then the change from the member database is persisted when a conflict arises.
冲突解决:在同一同步周期内在Azure SQL集线器和成员数据库上修改数据时发生冲突。 解决冲突可以帮助保留哪些更改。 到目前为止,与SQL Server复制不同,我们只有两个选项可用。 我们无法使用自定义冲突解决程序来解决冲突。 如果您选择集线器作为冲突解决方案获胜,那么来自集线器数据库的更改将保留。 如果选择“赢得成员”作为冲突解决方案,则发生冲突时,将保留来自成员数据库的更改。
After selecting the conflict resolution Click Ok.
选择解决冲突后,单击“ 确定”。
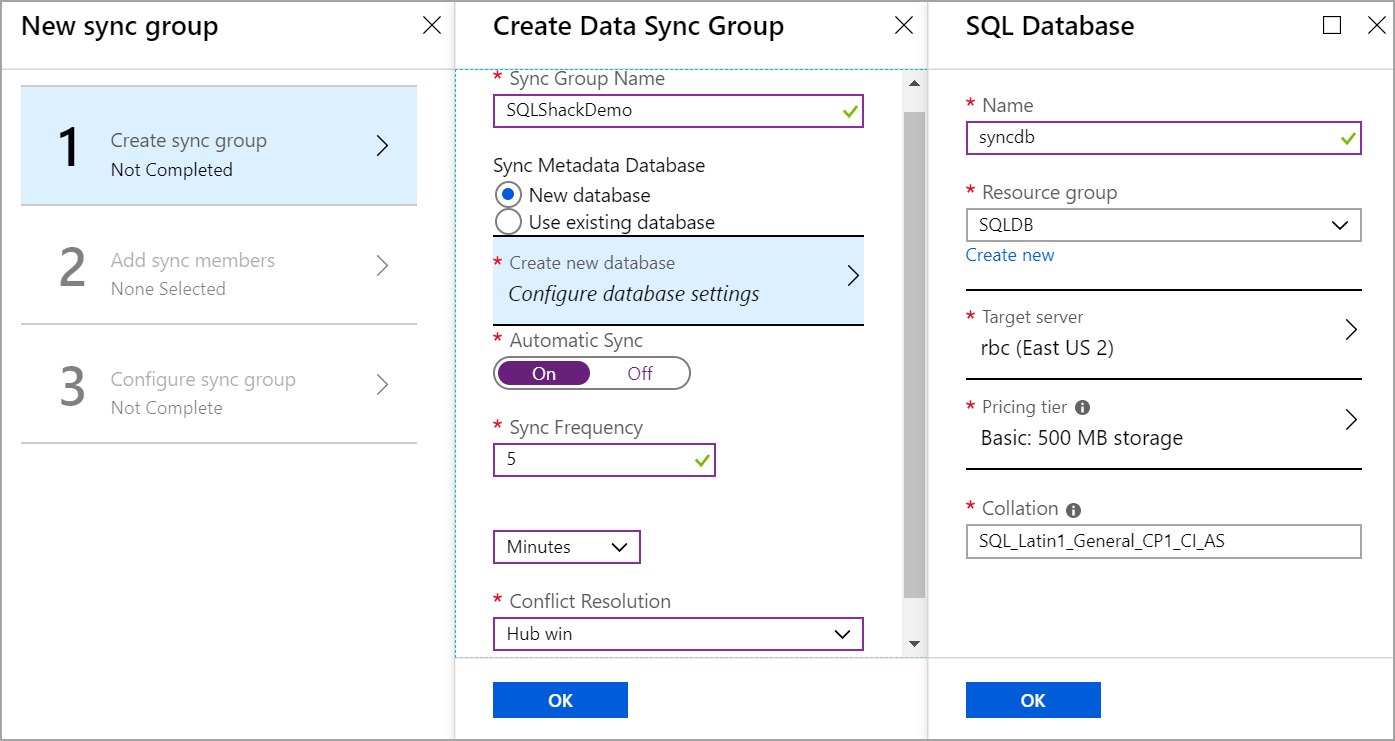
Once the sync group is created, we should add the Azure SQL database as a member of the sync group.
创建同步组后,我们应将Azure SQL数据库添加为同步组的成员。
添加成员数据库 (Adding the member database)
To add a member database, Click on Add sync members. Enter the username and password of the hub database. Click on Add an Azure Database to add the Azure SQL database as a member database.
要添加成员数据库,请单击添加同步成员。 输入中心数据库的用户名和密码。 单击“ 添加Azure数据库”以将Azure SQL数据库添加为成员数据库。
Enter the name of the sync member and select the database. there are three sync directions available.
输入同步成员的名称,然后选择数据库。 共有三个同步方向。
- Bi-directional: the data changes are replicated from hub to member and member database to the hub database 双向 :将数据更改从集线器复制到成员,并将成员数据库复制到集线器数据库
- To Hub: the data changes are replicated from the member database to the Hub database which is one-way replication 到集线器 :将数据更改从成员数据库复制到集线器数据库,这是单向复制
- From Hub: The data changes are replicated from the Hub database to member database only which is one-way replication 从集线器 :数据更改仅从集线器数据库复制到成员数据库,这是单向复制
Select the sync direction and enter the username, password of a member database as shown in the below image.
选择同步方向,然后输入成员数据库的用户名和密码,如下图所示。
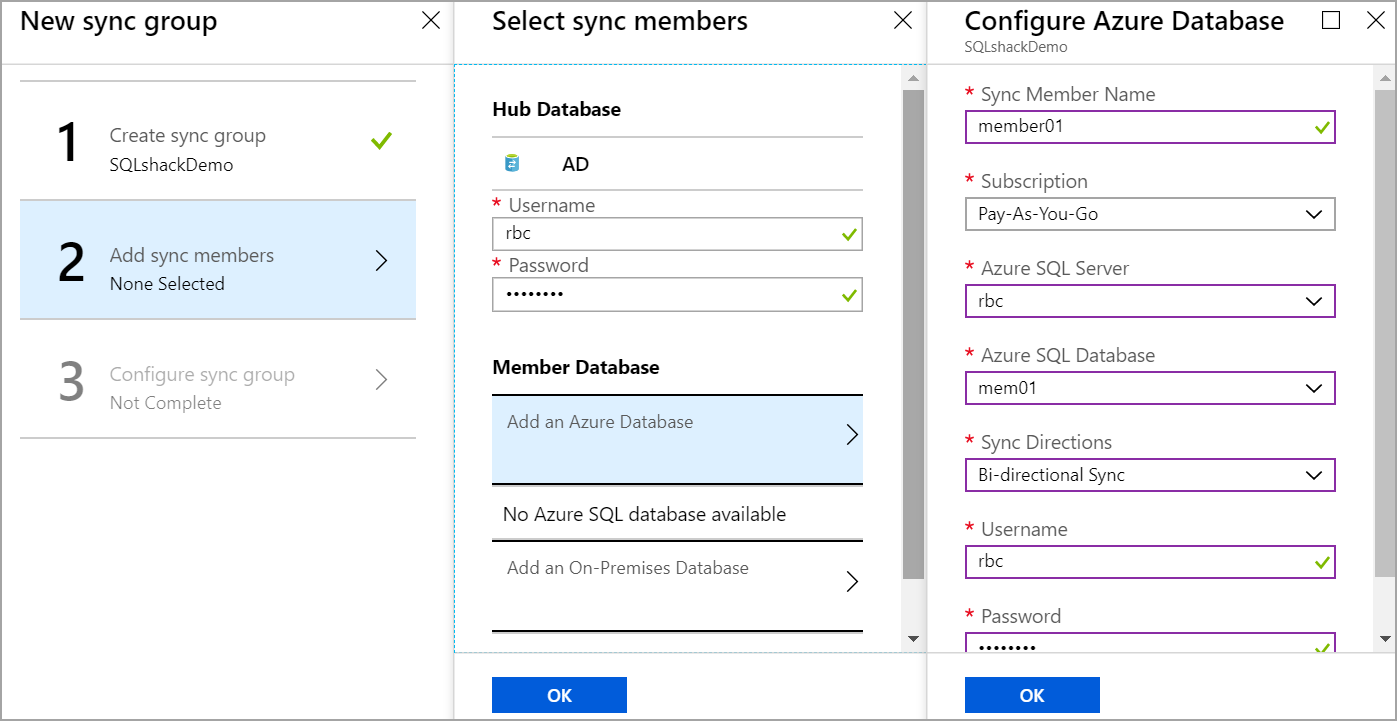
Here you can add multiple Azure SQL databases.
在这里您可以添加多个Azure SQL数据库。
将表添加到同步组 (Adding tables to the sync group)
To add the tables to a sync group, click on the configure sync group as shown in the below image and select the Hub database. Click on Refresh Schema to list the tables in the hub database. select the table you want to replicate and click on Save.
要将表添加到同步组,请单击下图所示的配置同步组,然后选择集线器数据库。 单击“刷新架构”以列出中心数据库中的表。 选择要复制的表,然后单击保存。
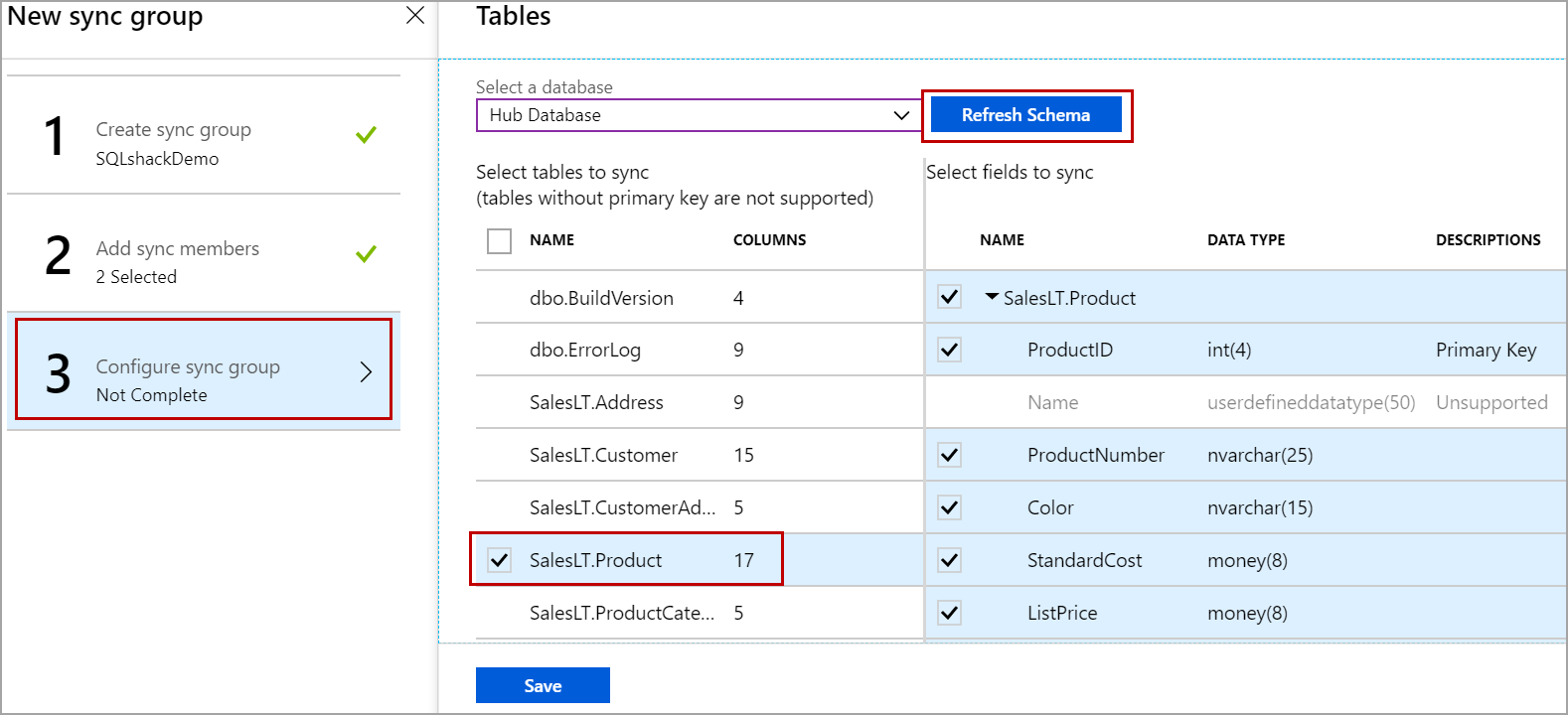
Once you click on Save, the selected tables are added to the sync group and three triggers one for insert, one for delete and one for the update are created on each table to track the data changes and insert information related to the data changes in the tracking tables. The naming convention of these tracking tables is as below.
单击“ 保存”后 ,将在每个表上创建选定的表并将其添加到同步组,并在每个表上创建三个触发器,一个用于插入,一个用于删除,一个用于更新,以跟踪数据更改并将与数据更改相关的信息插入到同步表中。跟踪表。 这些跟踪表的命名约定如下。
DataSync.tablename_dss_tracking
DataSync.tablename_dss_tracking
复制架构更改 (Replicating schema changes)
Currently, the Azure SQL Data Sync service supports only data sync and schema changes are not replicated to member databases. To replicate schema changes to member databases, we need to do a workaround by following the below steps.
当前,Azure SQL数据同步服务仅支持数据同步,并且架构更改不会复制到成员数据库。 要将架构更改复制到成员数据库,我们需要按照以下步骤进行变通。
- Create a DDL trigger to capture schema changes (DDL command) and insert into a tracking table 创建DDL触发器以捕获架构更改(DDL命令)并将其插入跟踪表
- Add the tracking table to sync group which replicated to all the members in the sync group 将跟踪表添加到同步组,该表已复制到同步组中的所有成员
- On the member database, create a DML trigger on the tracking table and execute the DDL command 在成员数据库上,在跟踪表上创建DML触发器并执行DDL命令
Please refer to the sample table and trigger which should be created on the Azure SQL hub database. I have added only two events for demo purposes.
请参考示例表和触发器,该表应在Azure SQL集线器数据库上创建。 我仅添加了两个用于演示目的的事件。
CREATE TABLE SCHEMACHANGES (ID INT identity(1,1) primary key,EVT_DATA XML,MODIFIED_BY varchar(50))
GO
CREATE TRIGGER TRACK_SCHEMACHANGES
ON DATABASE
FOR
ALTER_TABLE,
CREATE_TRIGGER
AS
BEGIN
SET NOCOUNT ON;
INSERT INTO SCHEMACHANGES
VALUES (
EVENTDATA(),
USER
);
END;
GO
Add the table to the data sync group which will replicate the data changes in the SCHEMACHANGES table to the member database.
将表添加到数据同步组,该组将把SCHEMACHANGES表中的数据更改复制到成员数据库。
On the member database, create a DML trigger which will get the command text from EVENTDATA and execute it on the member database. Please refer to the below sample script. You can add more error handling conditions to the trigger.
在成员数据库上,创建DML触发器,该触发器将从EVENTDATA获取命令文本并在成员数据库上执行。 请参考以下示例脚本。 您可以向触发器添加更多错误处理条件。
CREATE TRIGGER [dbo].[APPLY_SCHEMACHANGES] ON [dbo].[SCHEMACHANGES]
FOR INSERT
AS
BEGIN
declare @cmd nvarchar(max), @id int
DECLARE schemachanges CURSOR
FOR
select
ID,
m.c.value('.', 'nvarchar(max)') as CommandText
from inserted
OUTER APPLY inserted.EVT_DATA.nodes('EVENT_INSTANCE/TSQLCommand/CommandText') as m(c)
OPEN schemachanges
FETCH NEXT FROM schemachanges INTO @id, @cmd
WHILE @@FETCH_STATUS = 0
BEGIN
EXEC (@cmd)
FETCH NEXT FROM schemachanges INTO @id, @cmd
END
CLOSE schemachanges
DEALLOCATE schemachanges
END
GO
ALTER TABLE [dbo].[SCHEMACHANGES] ENABLE TRIGGER [APPLY_SCHEMACHANGES]
GO
局限性 (Limitations)
- Tables with a primary key can only be replicated 具有主键的表只能复制
- User-defined data types are not supported 不支持用户定义的数据类型
- Computed columns are not supported 不支持计算列
- Tables with identity column which is non-primary key are not supported in Azure SQL data sync Azure SQL数据同步中不支持带有标识列为非主键的表
- Tables with the same name but different schema are not supported 不支持名称相同但架构不同的表
- You must manage identity columns manually. No auto identity management like in SQL Server replication. In case if you insert a row with the same identity value on hub and master, the insert will be lost based on your conflict resolution 您必须手动管理标识列。 没有像SQL Server复制中那样的自动身份管理。 如果您在集线器和主服务器上插入具有相同标识值的行,则根据您的冲突解决方案,插入操作将丢失
- Supports only data sync not the schema changes. For example, if you insert a row in member database with identity value 1 and there is an insert with same identity value on hub database, if the conflict resolution is set to member win then the row inserted at the Azure SQL hub database is deleted and row inserted at member will be persisted in both member and hub databases 仅支持数据同步,不支持架构更改。 例如,如果在成员数据库中插入一个标识值为1的行,而在中心数据库上插入一个具有相同标识值的插入,如果将冲突解决方案设置为member win,则将删除在Azure SQL集线器数据库中插入的行并在成员处插入的行将保留在成员数据库和中心数据库中
- The initial sync will only create a table on the member database, not the other objects created on top of the table like triggers, foreign keys, etc. 初始同步只会在成员数据库上创建一个表,而不会在表顶部创建的其他对象(如触发器,外键等)创建表。
- Continuous synchronization is not supported. The minimum sync frequency interval is 5 minutes 不支持连续同步。 最小同步频率间隔是5分钟
双方使用触发器时的注意事项 (Considerations while using triggers on both sides)
There is no keyword to identify the changes done by Azure SQL Data Sync like “NOT FOR REPLICATION” in SQL Server Replication. For example, if you have a trigger for insert on the Locations table which inserts data into Locations_History table. You added both the tables to Azure SQL data sync group and created the same trigger on Locations at member database as well to track changes done by the user and insert into Locations_History table. Please refer to the below sequence of actions.
在SQL Server复制中,没有关键字来标识由Azure SQL数据同步完成的更改,例如“ NOT FOR REPLICATION”。 例如,如果您在Locations表上有一个插入触发器,该触发器将数据插入Locations_History表中。 您将两个表都添加到Azure SQL数据同步组,并在成员数据库的位置上创建了相同的触发器,以跟踪用户所做的更改并将其插入到Locations_History表中。 请参考以下动作顺序。
- Locations table which will insert a row in 位置表中的行,这将在Locations_History table as well Locations_History表中插入一行,以及
- Locations and Locations和Locations_History will be replicated to the member database Locations_History中的插入内容将被复制到成员数据库中
- Locations_History Locations_History中插入一行
In this case, you may have two records in Locations_History table even though there is only one insert on Locations table in Azure SQL hub database. In such cases use a specific user for data synchronization and add a piece of code in your trigger to return without executing if the data is modified by user or you can also add a piece of code to capture the application name and return without executing the trigger if the data is modified by Azure SQL Data Sync service.
在这种情况下,即使Azure SQL集线器数据库的Locations表上只有一个插入,您在Locations_History表中也可能有两条记录。 在这种情况下,如果用户修改了数据,请使用特定的用户进行数据同步,并在触发器中添加一段代码以不执行就返回,或者您也可以添加一段代码以捕获应用程序名称并在不执行触发器的情况下返回如果数据是由Azure SQL数据同步服务修改的。
结论 (Conclusion)
In this article, we explored Azure SQL Data Sync service and how to sync schema changes using Azure data sync. In case you have any questions, please feel free to ask in the comment section below.
在本文中,我们探讨了Azure SQL数据同步服务以及如何使用Azure数据同步来同步架构更改。 如果您有任何疑问,请随时在下面的评论部分中提问。
Please refer to the SQL Azure category to learn more about Azure SQL.
请参考SQL Azure 类别以了解有关Azure SQL的更多信息。
sql azure 语法















 1137
1137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









