






 本文深入探讨了SQL Server中并行嵌套循环连接的实现,包括并行处理和外部行优化。文章指出,表假脱机在某些情况下可能增加额外开销,而残留谓词在JOIN和WHERE列相同的情况下是不必要的。同时,讨论了内侧行数的估算误差及其对执行计划的影响。
本文深入探讨了SQL Server中并行嵌套循环连接的实现,包括并行处理和外部行优化。文章指出,表假脱机在某些情况下可能增加额外开销,而残留谓词在JOIN和WHERE列相同的情况下是不必要的。同时,讨论了内侧行数的估算误差及其对执行计划的影响。
并行循环和嵌套循环
This article is the second part of the Nested Loop Join Series. In the first part, Introduction of Nested Loop Join, we gave a brief introduction to Native, Indexed and Temporary Index Nested Loop Joins along with CPU cost details.
本文是嵌套循环连接系列的第二部分。 在第一部分“嵌套循环连接简介”中 ,我们简要介绍了本机,索引和临时索引嵌套循环连接以及CPU成本详细信息。
The second part shows how parallelism is implemented in the Nested Loop Join, a brief introduction about a few Outer Row Optimizations and interesting concepts about the inner side of the Nested Loop Join.
第二部分展示了如何在嵌套循环连接中实现并行性,简要介绍了一些外部行优化,以及有关嵌套循环连接内侧的有趣概念。
并行嵌套循环连接 (Parallel Nested Loop Join)
In this section we will concentrate on parallel processing in the Nested Loop Join. Before we start this article, I would like to explain a bit about the Parallel Page Supplier, because it helps in understanding the Nested Loop Join as a whole.
在本节中,我们将集中讨论嵌套循环连接中的并行处理 。 在开始本文之前,我想先解释一下并行页面供应商 ,因为它有助于整体理解嵌套循环联接。
Whenever parallel scan/seek is initiated on the table, a storage engine feature called the Parallel Page Supplier performs its task of distributing a set of pages to the available threads on the basis of the demand based schema.
每当在表上启动并行扫描/搜索时,称为“并行页面供应商”的存储引擎功能便会根据基于需求的架构执行将页面集分配给可用线程的任务。
When a thread finishes with its assigned set of pages, it requests the next set of pages from the parallel page supplier. The demand based schema balances the load efficiently, if one thread runs slower than the other threads for any reason. For example, if a thread is busy doing some other processing, then that thread simply requests fewer pages while the other threads pick up the extra work.
当线程完成其分配的页面集时,它将向并行页面供应商请求下一组页面。 如果一个线程由于某种原因运行速度慢于其他线程,则基于需求的架构可以有效地平衡负载。 例如,如果某个线程正忙于执行其他一些处理,则该线程仅请求较少的页面,而其他线程则承担了额外的工作。
For a better understanding about Parallel Nested Loop Join, we will insert more rows to the DBO.T1 table and create a new NL_Parallel table. The script for this can be found below.
为了更好地了解并行嵌套循环联接,我们将在DBO.T1表中插入更多行,并创建一个新的NL_Parallel表。 可以在下面找到该脚本。
Insert into [DBO].[T1]
Select Primarykey +100000 ,Primarykey +100000 , Primarykey +100000 , SomeData from [DBO].[T1]
Create Table NL_Parallel
(PrimaryKey INT NOT NULL CONSTRAINT PK_PrimaryKey PRIMARY KEY , KeyCol varchar(50) , SearchCol int , SomeData char(8000) )
Insert INTO NL_Parallel
SELECT
* FROM T1
WHERE Primarykey < 50001
GO
In the below query, we are controlling the query to choose the specific execution plan by using Option clause, so that we can get the identical execution plan. But if in case you are unable to get it then please run the script of statistics copy of the above tables on your system from below the article.
在下面的查询中,我们通过使用Option子句控制查询以选择特定的执行计划,以便我们获得相同的执行计划。 但是,如果万一无法获得,请从文章下面在您的系统上运行上述表格的统计副本脚本。
SELECT
*
FROM NL_Parallel OT1
JOIN T1 ot2
ON ot1.Keycol = ot2.Keycol
WHERE OT1.SearchCol IN (101,102,103,104,105,106,107,108,109,110, 111,112)
OPTION (LOOP JOIN -- Choose only nested loop join as physical join type
,RECOMPILE -- Compile and create execution plan again
,Querytraceon 8649 -- Undocumented: Force query optimizer to choose a parallel plan
,Force Order -- to match the logical expressed query to physical query plan
,MaxDop 4 -- Run with 4 logical processors
)
Let us first look at the estimated execution plan.
让我们首先看一下估计的执行计划。
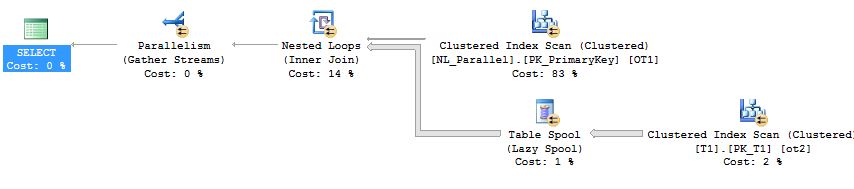
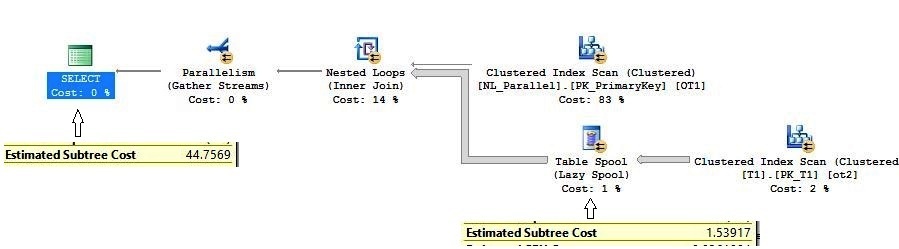
意外的表假脱机(如果您想严格了解嵌套循环联接中的并行执行计划,可以跳过此小节) (The unexpected Table Spool (if you want to learn strictly about the parallel execution plan in the nested loop join you can skip this subsection))
The major features of this execution plan is the Table Spool (Lazy spool, not to be confused with the index spool). A Table Spool (Lazy spool) is a part of the optimization process. The Query Processor creates a hidden temporary table in the Tempdb database, which inserts the rows in the Table Spool only when requested by the parent iterator, and it is a non blocking operator. But is it required here?
该执行计划的主要功能是表假脱机 (惰性假脱机,不要与索引假脱机混淆)。 表假脱机(惰性假脱机)是优化过程的一部分。 查询处理器在Tempdb数据库中创建一个隐藏的临时表,该表仅在父迭代器请求时才在表假脱机中插入行,并且它是非阻塞运算符。 但这是必需的吗?
To give a non-theoretical answer, we will execute two versions of the query one with Table Spool and another without it and we will investigate the results.
为了给出非理论性的答案,我们将执行两个版本的查询,一个使用Table Spool,另一个不使用它,我们将调查结果。
SET STATISTICS TIME,IO ON
SELECT
*
FROM NL_Parallel OT1
JOIN T1 ot2
ON ot1.Keycol = ot2.Keycol
WHERE OT1.SearchCol IN (101,102,103,104,105,106,107,108,109,110, 111,112)
OPTION (LOOP JOIN -- Choose only nested loop join as physical join type
,RECOMPILE -- Compile and create execution plan again
,Querytraceon 8649 -- Force query optimizer to choose a parallel plan
,Force Order -- to match the logical expressed query to physical query plan
,MaxDop 4 -- Run with 4 logical processors
)
Print '2nd Query started'
SELECT
*
FROM NL_Parallel OT1
JOIN T1 ot2
ON ot1.Keycol = ot2.Keycol
WHERE OT1.SearchCol IN (101,102,103,104,105,106,107,108,109,110, 111,112)
OPTION (LOOP JOIN -- Choose only nested loop join as physical join type
,RECOMPILE -- Compile and create execution plan again
,Querytraceon 8649 -- Force query optimizer to choose a parallel plan
,Querytraceon 8690 --disable spooling in query plan
,Force Order -- to match the logical expressed query to physical query plan
,MaxDop 4 -- Run with 4 logical processors
)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1840
1840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}