





ssis中数据类型
In this article, we will be discussing how SQL Server Integration Services (SSIS) can be used to predict data mining models built from SSAS. In this article, we will be looking at the Data Mining Query in SSIS. During the data mining article series, we have discussed all the Data mining techniques that are available in SQL Server. The discussed techniques were Naïve Bayes, Decision Trees, Time Series, Association Rules, Clustering, Linear Regression, Neural Network, Sequence Clustering. Further, we discussed how the accuracy of the data mining models can be verified.
在本文中,我们将讨论如何使用SQL Server Integration Services(SSIS)来预测根据SSAS构建的数据挖掘模型。 在本文中,我们将研究SSIS中的数据挖掘查询。 在数据挖掘文章系列中,我们讨论了SQL Server中可用的所有数据挖掘技术。 讨论的技术是朴素贝叶斯 , 决策树 , 时间序列 , 关联规则 , 聚类 , 线性回归 , 神经网络 , 序列聚类 。 此外,我们讨论了如何验证数据挖掘模型的准确性 。
When Data Mining models are built and deployed to SQL Server Analysis Services (SSAS), a few maintenance and usage tasks can be used from SSIS. Since SSIS is a tool that can be used to integrate data from heterogeneous sources, SSIS can be used to execute some tasks in Data Mining.
在构建数据挖掘模型并将其部署到SQL Server Analysis Services(SSAS)时,可以从SSIS中使用一些维护和使用任务。 由于SSIS是可用于集成来自异构源的数据的工具,因此SSIS可用于执行数据挖掘中的某些任务。
数据挖掘查询 (Data Mining Query)
Though we create data mining models from SSAS, modelled data can be used for different activities. One of the obvious tasks with data mining modeling is prediction. There is a Data flow task in SSIS that can be used to query the data mining models.
尽管我们从SSAS创建数据挖掘模型,但是建模数据可用于不同的活动。 数据挖掘建模的一项显而易见的任务是预测。 SSIS中有一个数据流任务,可用于查询数据挖掘模型。
Let us look at a scenario to use the Data Mining Query. Let us see how we can predict who the possible bike buyers are using a built model.
让我们看一下使用数据挖掘查询的场景。 让我们看看我们如何预测谁可能使用自行车模型。
For the last article, we developed a mining structure that has four data mining models, Decision Trees, Logistic Regression, Naïve Bayes, and Neural Network. We will be using that data mining model. Let us assume that we have a dataset, that can be used to predict whether the bike buyer or not.
在上一篇文章中,我们开发了一种挖掘结构,其中包含四个数据挖掘模型:决策树,逻辑回归,朴素贝叶斯和神经网络。 我们将使用该数据挖掘模型。 让我们假设我们有一个数据集,可用于预测是否是自行车购买者。
In the AdventureWorksDW database, there is a table named [ProspectiveBuyer] that contains prospect buyers. Now our task is to predict the possible bike buyers using any data mining models.
在AdventureWorksDW数据库中,有一个名为[ProspectiveBuyer]的表,其中包含潜在买家。 现在,我们的任务是使用任何数据挖掘模型来预测可能的自行车购买者。
SSIS项目创建 (SSIS Project Creation)
First, let us create an SSIS project using SQL Server Data Tools. Then for the default package let us drag and drop a Data Flow Task. Your SSIS package should look like the following screenshot.
首先,让我们使用SQL Server数据工具创建一个SSIS项目。 然后,对于默认包,让我们拖放数据流任务 。 您的SSIS软件包应类似于以下屏幕截图。
Now, let us create the data flow task by double-clicking the Data Flow Task in the SSIS package.
现在,让我们通过双击SSIS包中的“数据流任务”来创建数据流任务。
First, you need to include the data source which is the ProspectBuyer table. The following query can be used.
首先,您需要包括ProspectBuyer表的数据源。 可以使用以下查询。
SELECT CONCAT ( [Salutation],' ',[FirstName],' ',[MiddleName] ,' ',[LastName] ) FullName
,CONCAT ([AddressLine1],' ‘,[AddressLine2],' ',[City] ,' '
,[StateProvinceCode],' ',[PostalCode] )
Address
,[Phone]
,[EmailAddress]
,[MaritalStatus]
,[Gender]
,[YearlyIncome]
,[TotalChildren]
,[NumberChildrenAtHome]
,[Education]
,[Occupation]
,[HouseOwnerFlag]
,[NumberCarsOwned]
FROM [AdventureWorksDW2017].[dbo].[ProspectiveBuyer]
We used CONCAT command for columns Full Name and Address as they are divided into multiple attributes. The following is the sample dataset for the above query.
我们将CONCAT命令用于全名和地址列,因为它们被分为多个属性。 以下是上述查询的样本数据集。
In the above data set, Full Name, Address, Phone and Email Address will be used as contact attributes so that the marketing team can contact them once they identify someone as a possible bike buyer. Rest of the attributes, [MaritalStatus], [Gender], [YearlyIncome], [TotalChildren], [NumberChildrenAtHome], [Education], [Occupation], [HouseOwnerFlag], [NumberCarsOwned] are used to determine whether the prospect customer is a bike buyer or not.
在上述数据集中,全名,地址,电话和电子邮件地址将用作联系人属性,以便营销团队在确定某人可能是自行车购买者后就可以与其联系。 其余属性[MaritalStatus],[Gender],[YearlyIncome],[TotalChildren],[NumberChildrenAtHome],[Education],[Occupation],[HouseOwnerFlag],[NumberCarsOwned]用于确定潜在客户是否为自行车购买者与否。
Let us Drag and Drop an OLEDB Source from the Data Flow list to the data flow task, configure the source with the above query. The OLEDB Source configuration will look like the following screenshot.
让我们将OLEDB源从“数据流”列表拖放到数据流任务中,使用上面的查询配置源。 OLEDB Source配置如下图所示。
After data source, the next is to configure the Data Mining Query. Let us drag and drop the Data Mining Query data flow task from the SSIS toolbox and the package will be shown as the below screenshot.
在数据源之后,接下来是配置数据挖掘查询。 让我们从SSIS工具箱中拖放数据挖掘查询数据流任务,该包将显示为以下屏幕截图。
在SSIS中配置数据挖掘查询 (Configure the Data Mining Query in SSIS)
In this, we need to configure the connection to the SSAS server in which the Data Mining Model is deployed.
在此,我们需要配置与部署了数据挖掘模型的SSAS服务器的连接。
In the above configuration, the SSAS server and the catalog is configured. SQLShack is the SSAS catalog that was used to deploy the Data Mining structures.
在以上配置中,配置了SSAS服务器和目录。 SQLShack是用于部署数据挖掘结构的SSAS目录。
After the SSAS connection is completed, next is to select the relevant Data Mining Structure and data mining model as shown in the following screenshot.
SSAS连接完成后,下一步是选择相关的数据挖掘结构和数据挖掘模型,如以下屏幕快照所示。
In the last article, we understood that the Decision Trees data mining algorithm has the highest accuracy for the bike buyer date set. Let us select the Decision Trees from the Mining Models. However, you have the option of using any data mining model.
在上一篇文章中,我们了解到决策树数据挖掘算法对于自行车购买者日期集具有最高的准确性。 让我们从挖掘模型中选择决策树。 但是,您可以选择使用任何数据挖掘模型。
After the data mining model is selected, the next is to write the prediction query for Data Mining Query in SSIS. By clicking the Build New Query will take you to the Data Mining Query design screen as shown in the following screenshot.
选择数据挖掘模型后,下一步是在SSIS中编写数据挖掘查询的预测查询。 通过单击“ 构建新查询”,您将进入“数据挖掘查询”设计屏幕,如以下屏幕快照所示。
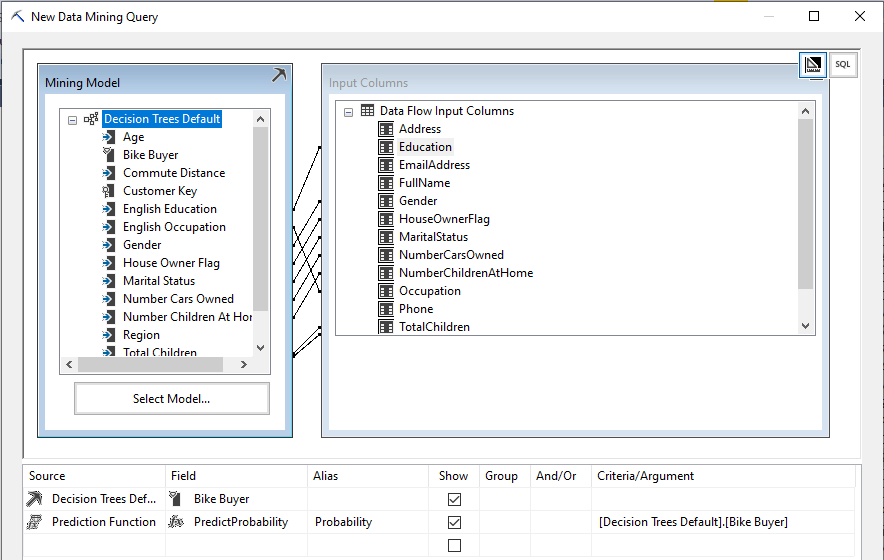
In the above screen, Input attributes are mapped to the model parameters. By default, the same name attributes will be matched automatically. From this model, we are expecting two things. Those two are whether the prospective customer is a bike buyer and what the probability of him buying a bike is. Those two parameters are defined at the bottom of the screenshot.
在以上屏幕中,输入属性映射到模型参数。 默认情况下,相同名称的属性将自动匹配。 从这个模型中,我们期待两件事。 这两个是潜在客户是否是自行车购买者,以及他购买自行车的概率是多少。 这两个参数在屏幕截图的底部定义。
When the above query is defined, the DMX query will be updated in the following screen as shown below.
定义以上查询后,DMX查询将在以下屏幕中更新,如下所示。
Following is the DMX query for the prediction of the above data mining model that will be used in Data Mining Query in SSIS.
以下是用于预测上述数据挖掘模型的DMX查询,该模型将在SSIS中的数据挖掘查询中使用。
SELECT FLATTENED
[Decision Trees Default].[Bike Buyer],
(PredictProbability([Decision Trees Default].[Bike Buyer])) as [Probability]
From
[Decision Trees Default]
PREDICTION JOIN
@InputRowset AS t
ON
[Decision Trees Default].[Marital Status] = t.[MaritalStatus] AND
[Decision Trees Default].[Gender] = t.[Gender] AND
[Decision Trees Default].[Yearly Income] = t.[YearlyIncome] AND
[Decision Trees Default].[Total Children] = t.[TotalChildren] AND
[Decision Trees Default].[Number Children At Home] = t.[NumberChildrenAtHome] AND
[Decision Trees Default].[House Owner Flag] = t.[HouseOwnerFlag] AND
[Decision Trees Default].[Number Cars Owned] = t.[NumberCarsOwned] AND
[Decision Trees Default].[English Occupation] = t.[Occupation] AND
[Decision Trees Default].[English Education] = t.[Education]
After the Data Mining Query is configured, the following data flow task can be seen. In the below data flow task, Row Count is configured to view the results.
配置数据挖掘查询后,可以看到以下数据流任务。 在下面的数据流任务中,将“行数”配置为查看结果。
Let us view the results by enabling the Data Viewer as shown in the above screenshot. The following screenshot shows the data viewer results as shown in the below screenshot.
让我们通过启用数据查看器来查看结果,如上面的屏幕快照所示。 以下屏幕截图显示了数据查看器结果,如以下屏幕截图所示。
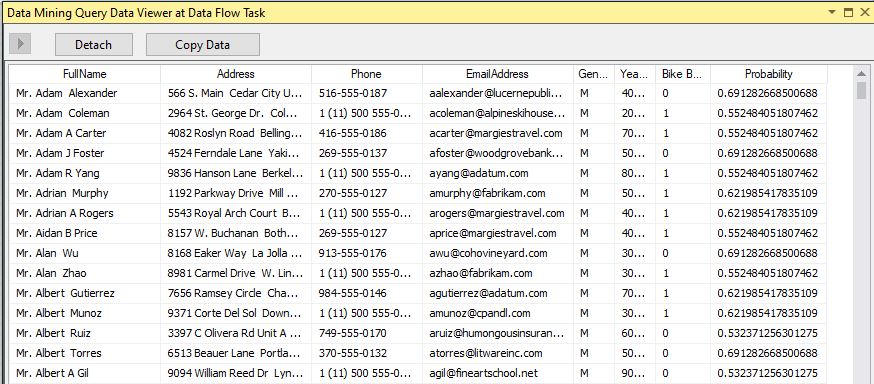
The Bike Buyer column indicates whether the relevant customer is a bike buyer or not with the relevant Probability.
“自行车购买者”列指示相关客户是否是具有相关概率的自行车购买者。
Though this is the basic configuration of Data Mining Query in SSIS, there are a few features of SSIS that can be used to get the best out from the data mining models.
尽管这是SSIS中数据挖掘查询的基本配置,但是SSIS的一些功能可用于从数据挖掘模型中获得最大收益。
用于数据挖掘的扩展SSIS功能 (Extended SSIS features for Data Mining)
Data Mining Query in SSIS can be extended to different features of SSIS. If you are a marketing person at the above organization, you would prefer to get a list of Bike buyers who have the highest probability of buying bikes and less probability of buying a bike so that you can target these to customer segments separately. Further, you would prefer to have the prospects in the order of highest probability.
SSIS中的数据挖掘查询可以扩展到SSIS的不同功能。 如果您是上述组织的市场营销人员,则希望获得自行车购买者的列表,这些购买者购买自行车的可能性最高,而购买自行车的可能性较小,因此您可以将这些消费者分别定位到客户群。 此外,您更希望前景具有最高的概率。
Conditional Split in SSIS is used to split the data flow into multiple depending on the conditions. Let us split the entire data set, Bike buyers with more than 75% probability and Bike Buyers with less probability and not bike buyers. This can be configured by Conditional split control in SSIS as shown in the following screen.
SSIS中的条件拆分用于根据条件将数据流拆分为多个。 让我们分割整个数据集,概率大于75%的自行车购买者和概率较小的自行车购买者,而不是自行车购买者。 可以通过SSIS中的条件拆分控制进行配置,如下屏幕所示。
Next, we will sort the data stream with the highest probability using the Sort transformation.
接下来,我们将使用Sort转换对具有最高概率的数据流进行排序。
The following screenshot shows the final SSIS package for Data Mining Query.
以下屏幕快照显示了用于数据挖掘查询的最终SSIS包。
You will see that there are 35 records of customers who are more likely to buy a bike with the probability of 75% and there 995 possible bike buyers with less probability. 1028 customers are unlikely to buy bikes from this organization.
您将看到有35个客户记录,他们更有可能以75%的概率购买自行车,而有995个可能的自行车购买者的概率较小。 1028位客户不太可能从该组织购买自行车。
Following is the list of customers who are more likely to buy bikes.
以下是更可能购买自行车的客户列表。
The above list provides the contact details of the prospect customers.
上面的列表提供了潜在客户的联系方式。
Since Data Mining Query in SSIS can be used to query the data mining models, it can incorporate other options like storing data into a database table, saving to a text file, sending emails and so on.
由于SSIS中的数据挖掘查询可用于查询数据挖掘模型,因此它可以合并其他选项,例如将数据存储到数据库表中,保存到文本文件中,发送电子邮件等。
结论 (Conclusion)
In this article, we looked at the Data Mining Query in SSIS to perform predictions with data mining models in SQL Server. Since SSIS has rich transformation controls, data splitting, data filtering, sorting can be performed. Apart from those operations, writing to the database, sending emails too can be done via SSIS.
在本文中,我们研究了SSIS中的数据挖掘查询,以使用SQL Server中的数据挖掘模型执行预测。 由于SSIS具有丰富的转换控件,因此可以执行数据拆分,数据过滤和排序。 除了这些操作之外,还可以通过SSIS完成写入数据库,发送电子邮件的操作。
目录 (Table of contents)
ssis中数据类型















 424
424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









