






 本文介绍了如何在Azure Databricks中使用Scala API挂载和访问Azure Blob存储,包括创建Scala笔记本,读取和转换数据,以及将处理后的数据写回Blob存储。首先,创建Scala笔记本并挂载Blob存储容器,然后读取CSV文件并进行数据转换,最后将结果写回Blob存储。
本文介绍了如何在Azure Databricks中使用Scala API挂载和访问Azure Blob存储,包括创建Scala笔记本,读取和转换数据,以及将处理后的数据写回Blob存储。首先,创建Scala笔记本并挂载Blob存储容器,然后读取CSV文件并进行数据转换,最后将结果写回Blob存储。
azure blob
We introduced Azure Databricks, how it is created and some of its important components in my previous article here. We will look at how we can work with Azure Blob Storage in Azure Databricks in this article.
我们推出了Azure的Databricks,它是如何创建和我以前的文章一些重要的组成部分在这里 。 在本文中,我们将研究如何在Azure Databricks中使用Azure Blob存储。
Azure Blob Storage is a storage service in Azure that enables users to store large amounts of unstructured data like videos, audios, images, text, backup data, etc. This cloud service is a cost-effective and scalable approach when compared to on-premises storage options. There are four types of storage in Azure, including Blob (Binary large object) storage; you can learn about them here: Different Azure Storage types (File, Blob, Queue and Table).
Azure Blob存储是Azure中的一项存储服务,使用户能够存储大量非结构化数据,例如视频,音频,图像,文本,备份数据等。与本地部署相比,此云服务是一种经济高效且可扩展的方法存储选项。 Azure中有四种存储类型,包括Blob(二进制大对象)存储; 您可以在此处了解它们: 不同的Azure存储类型(文件,Blob,队列和表) 。
Azure Databricks is an implementation of Apache Spark on Microsoft Azure. It is a powerful chamber that handles big data workloads effortlessly and helps in both data wrangling and exploration. It lets you run large-scale Spark jobs from any Python, R, SQL, and Scala applications. Spark is written in Scala (a high-level language) and there are definitely some performance benefits if commands are run in Scala in Azure Databricks.
Azure Databricks是Microsoft Azure上Apache Spark的实现。 它是一个强大的工具箱,可轻松处理大数据工作负载,并有助于数据整理和探索。 它使您可以从任何Python,R,SQL和Scala应用程序运行大规模Spark作业。 Spark用Scala(一种高级语言)编写,如果在Azure Databricks中的Scala中运行命令,则肯定会带来一些性能上的好处。
先决条件 (Pre-requisites)
To follow along with this article, you need to have the following requisites:
要继续阅读本文,您需要满足以下条件:
- here 在这里为自己创建一个
- this site, to know how to create a Databricks service on Azure 此站点,以了解如何在Azure上创建Databricks服务
- here if you are new to the Azure Storage service. Afterward, we will require a .csv file on this Blob Storage that we will access from Azure Databricks 此处 。 之后,我们将在此Blob存储上需要一个.csv文件,我们将从Azure Databricks访问该文件
Once the storage account is created using the Azure portal, we will quickly upload a block blob (.csv) in it. Note: Azure Blob Storage supports three types of blobs: block, page and append. We can only mount block blob to DBFS (Databricks File System), so for this reason, we will work on a block blob.
使用Azure门户创建存储帐户后,我们将在其中快速上传一个块Blob(.csv)。 注意:Azure Blob存储支持三种类型的Blob:块,页面和附加。 我们只能将块Blob挂载到DBFS(Databricks文件系统),因此,出于这个原因,我们将在块Blob上工作。
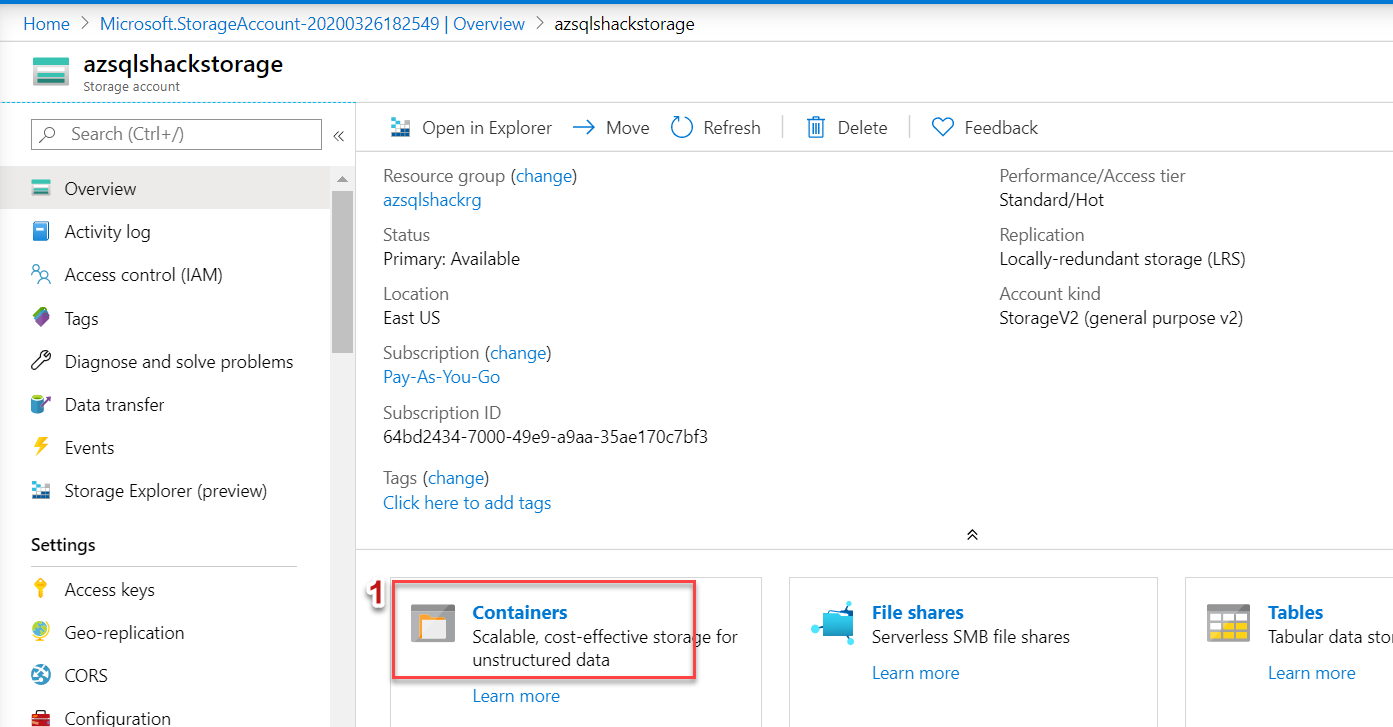
Navigate to your Storage Account in the Azure portal, and click on Containers
在Azure门户中导航到您的存储帐户,然后单击“ 容器”
Click on + Container to create a new container
单击+容器创建一个新容器
Type a name for the container, I am selecting the default access level as Private and finally hit the Create button
输入容器的名称,我选择默认访问级别为“私有”,最后单击“ 创建”按钮
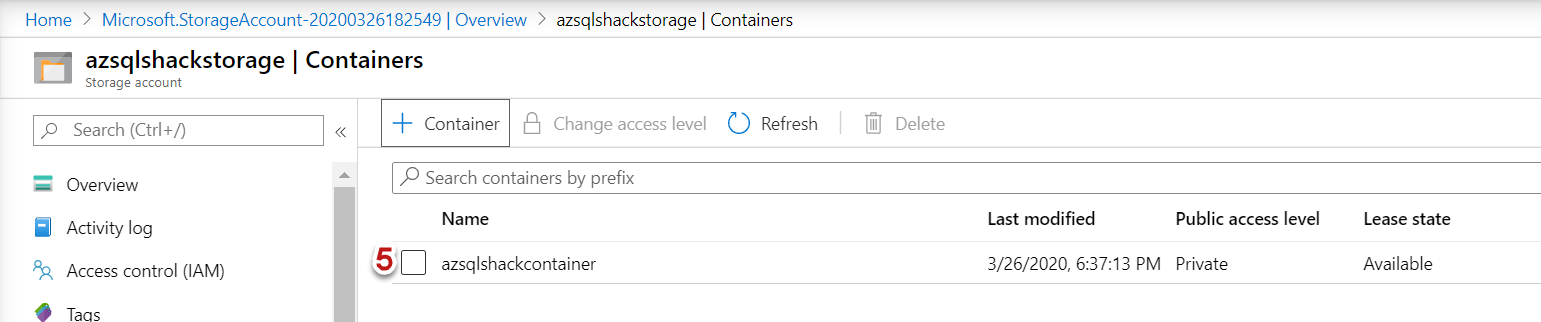
The container ‘azsqlshackcontainer’ is successfully created in the storage account
在存储帐户中成功创建了容器“ azsqlshackcontainer”
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 750
750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}