





This is the fourth article in a series of learning the CREATE VIEW SQL statement. So far, we have done a great deal of creating and altering views using T-SQL. In this last part, I want to take a big look at how to work with indexed views.
这是学习CREATE VIEW SQL语句系列的第四篇文章。 到目前为止,我们已经完成了使用T-SQL创建和更改视图的大量工作。 在最后一部分中,我想看一下如何使用索引视图。
As always, to follow along with the series, it’s highly recommended to read the previous parts first and then this one. This is primarily because we created our own sample database and objects in it from scratch that we’ll be using in this part too, but also because it will be much easier to see the big picture.
与往常一样,强烈建议您先阅读前面的部分,然后再阅读本部分。 这主要是因为我们从头开始创建了自己的示例数据库和其中的对象,这也是我们将在本部分中使用的,而且还因为更容易看到全局。
Here are the previous three pieces of the CREATE VIEW SQL series:
这是CREATE VIEW SQL系列的前三部分:
- Creating views in SQL Server 在SQL Server中创建视图
- Modifying views in SQL Server 在SQL Server中修改视图
- Inserting data through views in SQL Server 通过SQL Server中的视图插入数据
So, head over and read those before continuing with this one.
因此,在继续之前,请先阅读并阅读这些内容。
介绍 (Introduction)
The first thing that we’ll do is create an indexed view. We will, of course, use the CREATE VIEW SQL statement for this as we did many times through the series. But the general idea, as the title says, is to see how to work with indexed views, see what the requirements are for adding an index to a view, and how to do it programmatically. Furthermore, to explain the pros of indexed views, we’ll be looking at executions plans in SQL Server. They are a great tool for DBAs and developers when it comes to finding and fixing a bottleneck in the slow running query.
我们要做的第一件事是创建索引视图。 当然,我们将在整个系列中多次使用CREATE VIEW SQL语句。 但是,正如标题所述,一般的想法是查看如何使用索引视图,查看将索引添加到视图的要求以及如何以编程方式进行操作。 此外,为了解释索引视图的优点,我们将研究SQL Server中的执行计划。 对于查找和修复运行缓慢的查询中的瓶颈而言,它们是DBA和开发人员的绝佳工具。
CREATE VIEW SQL语句 (CREATE VIEW SQL statement)
Without further ado, let’s create a view using the CREATE VIEW SQL statement from below and see what it does:
事不宜迟,让我们使用下面的CREATE VIEW SQL语句创建一个视图,然后查看其作用:
USE SQLShackDB;
GO
CREATE VIEW dbo.vEmployeeSalesOrders
WITH SCHEMABINDING
AS
SELECT Employees.EmployeeID,
Products.ProductID,
SUM(price * quantity) AS SaleTotal,
SaleDate
FROM dbo.Employees
JOIN dbo.Sales ON Employees.EmployeeID = Sales.EmployeeID
JOIN dbo.Products ON Sales.ProductID = Products.ProductID
GROUP BY Employees.EmployeeID,
Products.ProductID,
Sales.SaleDate;
GO
Notice that this view has a WITH SCHEMABINDING option on it. The reason why it has this option turned on is because when creating indexes on views, they actually physically get stored in the database. In other words, anything that this view relies on, as far as the tables are concerned, the structure cannot change from what we’re referencing.
注意,该视图上有一个WITH SCHEMABINDING选项。 之所以启用此选项,是因为在视图上创建索引时,它们实际上实际上存储在数据库中。 换句话说,就表而言,此视图所依赖的任何内容,其结构都无法从我们所引用的内容中更改。
Therefore, it must be bound to the underlying tables so that we can’t modify them in a way that would affect the view definition. If we try to change them in any way, SQL Server will throw an error saying that this view depends on something. So, look at it as a hard requirement for creating an index on a view.
因此,它必须绑定到基础表,以便我们不能以会影响视图定义的方式修改它们。 如果我们尝试以任何方式更改它们,则SQL Server将引发错误,指出此视图取决于某些内容。 因此,将其视为在视图上创建索引的硬性要求。
Once the command is executed successfully, you should see the vEmployeeSalesOrders view under Views folder in Object Explorer as shown below:
成功执行命令后,您应该在Object Explorer的 Views文件夹下看到vEmployeeSalesOrders视图,如下所示:
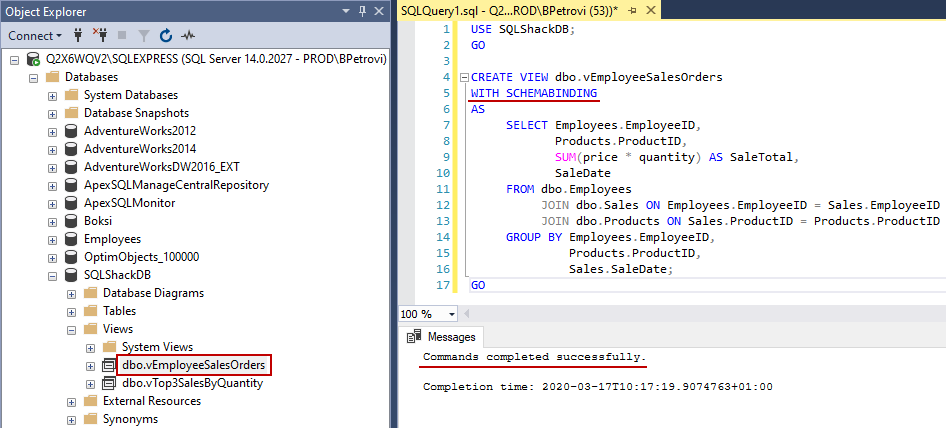
The definition of the view is a bit more complex query. We got an aggregate in the SELECT statement followed by the GROUP BY clause. Remember, when we have an aggregate in the query, it adds the numbers together, so we need to have the GROUP BY clause.
视图的定义有点复杂。 我们在SELECT语句中得到一个汇总,然后是GROUP BY子句。 请记住,当查询中有聚合时,它会将数字加在一起,因此我们需要有GROUP BY子句。
Basically, when there’s a GROUP BY in a query, we need to group by everything that is in the select list except the aggregate.
基本上,当查询中有GROUP BY时,我们需要对选择列表中除聚合之外的所有内容进行分组。
Now, I’ve already created the view, but remember that it’s always a good idea to test out the definition of the view by running only the SELECT part of the CREATE VIEW SQL statement to see what it returns:
现在,我已经创建了视图,但是请记住,通过仅运行CREATE VIEW SQL语句的SELECT部分以查看其返回值来测试视图的定义始终是一个好主意:
Moving on, here’s how you can check whether the Schema bound option is enabled or disabled. Head over to Object Explorer, expand Views, right-click on the view, and select Properties:
继续,这里是您如何检查“ 模式绑定”选项是启用还是禁用的方法。 转至“ 对象资源管理器” ,展开“ 视图” ,右键单击该视图,然后选择“ 属性” :
Among all other information in the View Properties window, you’ll see if the Schema bound option is set to True or False under the General page.
在“ 视图属性”窗口中的所有其他信息中,您将看到“ 常规”页面下的“ 模式绑定”选项是否设置为True或False 。
创建索引视图 (Creating indexed views)
Let’s move on and create an index on our view. Consider the script from below for creating a clustered index on the vEmployeeSalesOrders view:
让我们继续在视图上创建索引。 考虑下面的脚本,用于在vEmployeeSalesOrders视图上创建聚簇索引:
USE SQLShackDB;
GO
CREATE UNIQUE CLUSTERED INDEX CAK_vEmployeesSalesOrders
ON dbo.vEmployeeSalesOrders(EmployeeID, ProductID, SaleDate);
GO
If we hit the Execute button in SSMS, SQL Server will throw an error saying that index cannot be created:
如果我们在SSMS中单击“ 执行”按钮,则SQL Server将引发错误,指出无法创建索引:
Here’s the full error message that cannot be seen in the shot above:
这是上面的快照中看不到的完整错误消息:
Cannot create index on view ‘SQLShackDB.dbo.vEmployeeSalesOrders’ because its select list does not include a proper use of COUNT_BIG. Consider adding COUNT_BIG(*) to select list.
无法在视图“ SQLShackDB.dbo.vEmployeeSalesOrders”上创建索引,因为其选择列表未正确使用COUNT_BIG。 考虑添加COUNT_BIG(*)以选择列表。
We need COUNT_BIG in this case given the fact that we’re using GROUP BY in our view.
考虑到我们在视图中使用的是GROUP BY ,在这种情况下,我们需要COUNT_BIG 。
In general, if we are using aggregates like COUNT, SUM, AVG, etc. in the index’s select list, we also have to include COUNT_BIG in order to create an index on it.
通常,如果在索引的选择列表中使用COUNT , SUM , AVG等聚合,则还必须包括COUNT_BIG才能在其上创建索引。
That’s exactly what we’re going to do. Modify the existing view with the ALTER VIEW command by changing its definition created previously using the CREATE VIEW SQL statement and add COUNT_BIG to the select list using the script from below:
这正是我们要做的。 通过更改先前使用CREATE VIEW SQL语句创建的定义,使用ALTER VIEW命令修改现有视图,并使用以下脚本从选择列表中添加COUNT_BIG :
USE SQLShackDB;
GO
ALTER VIEW dbo.vEmployeeSalesOrders
WITH SCHEMABINDING
AS
SELECT Employees.EmployeeID,
Products.ProductID,
SUM(price * quantity) AS SaleTotal,
SaleDate,
COUNT_BIG(*) AS RecordCount
FROM dbo.Employees
JOIN dbo.Sales ON Employees.EmployeeID = Sales.EmployeeID
JOIN dbo.Products ON Sales.ProductID = Products.ProductID
GROUP BY Employees.EmployeeID,
Products.ProductID,
Sales.SaleDate;
GO
If you’re wondering why this is happening in this case, the answer is because SQL Server needs a way of tracking the number of the record that we’re turning for the index and this is also one of a whole bunch of limitations with creating indexed views.
如果您想知道为什么在这种情况下会发生这种情况,答案是因为SQL Server需要一种跟踪我们正在为索引求助的记录数的方法,而这也是创建过程中的一大堆限制之一索引视图 。
So far, everything looks good. We successfully changed the definition of our view:
到目前为止,一切看起来都不错。 我们成功地更改了视图的定义:
Now, we can get back to creating an index on the view by executing the previously used script one more time. This time, the operation will complete smoothly. If we go to Object Explorer and expand the Indexes folder of our view, we’ll see the newly created index:
现在,我们可以再执行一次以前使用的脚本,回到在视图上创建索引的方式。 这次,操作将顺利完成。 如果转到对象资源管理器并展开视图的Indexes文件夹,我们将看到新创建的索引:
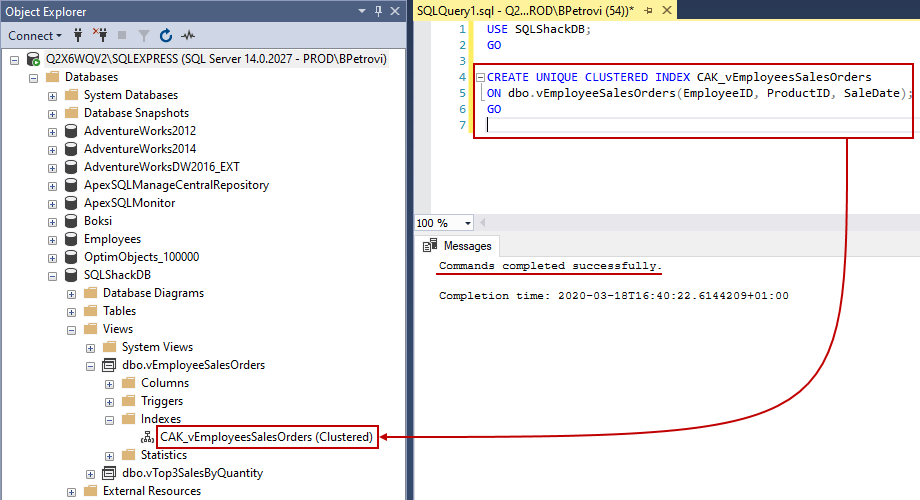
From here, if we right-click on the index and select Properties, under the General page, you can see view name, index name, type, key columns, etc.:
在这里,如果我们右键单击索引并选择“ 常规”页面下的“ 属性” ,则可以看到视图名称,索引名称,类型,键列等:
If we switch over to Storage, you’ll see that it has a Filegroup because it is physically stored in a database:
如果我们切换到Storage ,您将看到它具有文件组,因为它实际上存储在数据库中:
Furthermore, if we switch over to Fragmentation, it should say that Total fragmentation is zero percent because we only have a few records in our tables:
此外,如果切换到Fragmentation ,应该说Total fragmentation为零,因为我们的表中只有几条记录:
Looking for a detailed but fun and easy to read primer on maintaining and monitoring SQL indexes? Check out SQL index maintenance.
寻找有关维护和监视SQL索引的详细但有趣且易于阅读的入门知识吗? 查看SQL索引维护 。
删除索引 (Deleting indexes)
Before we go any further, let’s see how we can delete an index. The easiest way is to right-click on the index in Object Explorer and use the Delete option. But in case you need to drop multiple indexes at once, the DROP INDEX statement comes in handy. That’s what we’re going to do, because, after all, this is a T-SQL series about learning the CREATE VIEW SQL statement.
在继续之前,让我们看看如何删除索引。 最简单的方法是在“ 对象资源管理器”中右键单击索引,然后使用“ 删除”选项。 但是,如果您需要一次删除多个索引,则DROP INDEX语句会派上用场。 那就是我们要做的,因为毕竟这是一个有关学习CREATE VIEW SQL语句的T-SQL系列。
Use the script from below to drop the CAK_vEmployeesSalesOrders index:
使用下面的脚本删除CAK_vEmployeesSalesOrders索引:
USE SQLShackDB;
GO
DROP INDEX CAK_vEmployeesSalesOrders ON dbo.vEmployeeSalesOrders;
GO
When you need to drop multiple indexes, just specify all names separated by a comma.
当需要删除多个索引时,只需指定所有名称,并用逗号分隔即可。
生成随机数据 (Generating random data)
Now, that we got rid of the index, let’s generate some random data in our table so that we can look at the execution plan and see how SQL Server fetches data under the hood. Analyzing the execution plan will show the difference in how the performance is affected by running the query with and without an index on the view.
现在,我们摆脱了索引,让我们在表中生成一些随机数据,以便我们可以查看执行计划,并了解SQL Server如何在后台获取数据。 分析执行计划将显示在视图上有无索引的情况下运行查询对性能的影响。
Use the script from below to insert 50000 random records into the Sales table:
使用下面的脚本将50000条随机记录插入Sales表:
USE SQLShackDB;
GO
--Create 50000 random sales records
DECLARE @counter INT;
SET @counter = 1;
WHILE @counter <= 50000
BEGIN
INSERT INTO Sales
SELECT NEWID(),
(ABS(CHECKSUM(NEWID())) % 4) + 1,
(ABS(CHECKSUM(NEWID())) % 2) + 1,
(ABS(CHECKSUM(NEWID())) % 9) + 1,
DATEADD(day, ABS(CHECKSUM(NEWID()) % 3650), '2020-04-01');
SET @counter+=1;
END;
I’m not going to walk you through the script in details, but it’s basically a loop that will execute 5000 times and insert random data into the Sales table. Once the loop is terminated, SQL Server will return 5000 messages saying “1 row affected”:
我不会详细介绍该脚本,但基本上是一个循环,它将执行5000次并将随机数据插入Sales表。 一旦循环终止,SQL Server将返回5000条消息,指出“受影响的1行”:
Just to check if the records were inserted successfully, execute the following SELECT statement that will count all records from the Sales table:
仅为了检查记录是否已成功插入,执行以下SELECT语句,该语句将对Sales表中的所有记录进行计数:
USE SQLShackDB;
GO
SELECT COUNT(*) FROM Sales
The number returned shows that there’re 50006 rows in the Sales table. This is the number of records that we just generated + 6 that we initially had:
返回的数字表明Sales表中有50006行。 这是我们刚生成的记录数+最初有6条记录:
分析执行计划 (Analyzing execution plans)
Now that we have some data in our table, we can really demonstrate the use of an index on the view. Let’s query the vEmployeeSalesOrders view and see how SQL Server retrieves the data. Before executing the SELECT statement from below, make sure to include the Actual Execution Plan as shown below:
现在我们的表中有一些数据,我们可以真正演示在视图上使用索引了。 让我们查询vEmployeeSalesOrders视图,并查看SQL Server如何检索数据。 从下面执行SELECT语句之前,请确保包括如下所示的实际执行计划 :
USE SQLShackDB;
GO
SELECT * FROM dbo.vEmployeeSalesOrders;
This script returned 23814 rows, but what’s more important, it generated the execution plan of the query. Remember that we previously dropped the index on our view. So, right now there’s no index on our view. Therefore, SQL Server will do a few table scans as shown below:
该脚本返回了23814行,但更重要的是,它生成了查询的执行计划。 请记住,我们之前已将索引放在视图上。 因此,目前我们的观点尚无索引。 因此,SQL Server将进行一些表扫描,如下所示:
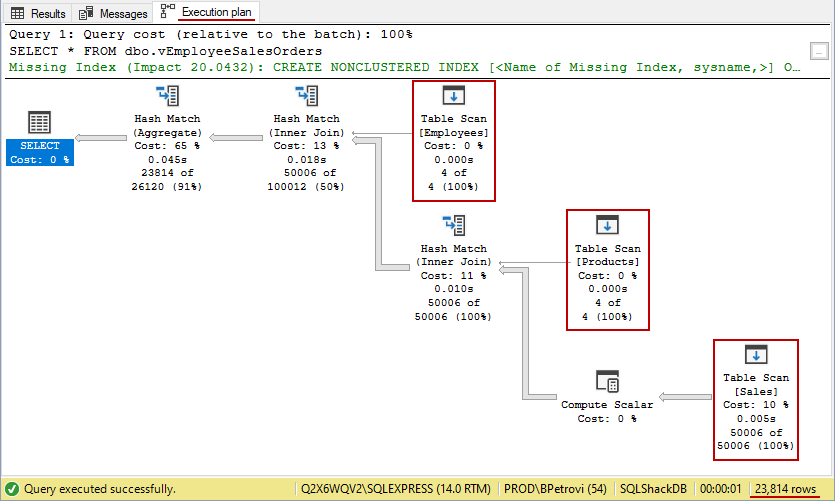
This is pretty much the worst thing in the database world, especially on tables with a large amount of data. It’s okay to have table scans with a small amount of data e.g. the case with our Employees and Products tables, but it’s bad for the Sales table because it has 50K+ records.
这几乎是数据库世界中最糟糕的事情,尤其是在具有大量数据的表上。 可以使用少量数据进行表扫描,例如我们的Employees和Products表的情况,但是对于Sales表却不利,因为它具有超过50K的记录。
The easiest way to get rid of the table scans is to create an index on it because it dramatically speeds things up. So, what we’ll do to fix this problem is re-execute the script for creating the unique clustered index on the vEmployeeSalesOrders view.
摆脱表扫描的最简单方法是在其上创建索引,因为它可以显着加快处理速度。 因此,我们要解决此问题的方法是重新执行脚本,以在vEmployeeSalesOrders视图上创建唯一的聚集索引。
Now, if we just re-run the SELECT statement, there will be no differences even though we just created the index. Why is that? Because I’m using the SQL Server Express edition for the purpose of this series, and only in Enterprise and Developer editions of SQL Server will the Query Optimizer actually take the index into consideration.
现在,如果我们只是重新运行SELECT语句,即使我们刚刚创建了索引,也不会有任何区别。 这是为什么? 因为本系列的目的是使用SQL Server Express版本,所以只有在SQL Server的Enterprise和Developer版本中, Query Optimizer才会真正考虑索引。
No worries because we can actually force SQL Server to use an index when generating execution plans. This is done by using the NOEXPAND option. NOEXPAND applies only to indexed views:
不用担心,因为我们实际上可以强制SQL Server在生成执行计划时使用索引。 这是通过使用NOEXPAND选项完成的。 NOEXPAND仅适用于索引视图:
SELECT * FROM dbo.vEmployeeSalesOrders WITH (NOEXPAND)
Just like that, we forced SQL Server to use the clustered index which basically means do not use the underlying tables when fetching data. As can be seen below, we’ve made some progress by eliminating a number of operations:
这样,我们强制SQL Server使用聚集索引,这基本上意味着在获取数据时不要使用基础表。 如下所示,我们通过消除许多操作取得了一些进展:
In fact, we can executeboth SELECT statements simultaneously and compare the results by looking at the execution plans:
实际上,我们可以同时执行两个SELECT语句,并通过查看执行计划来比较结果:
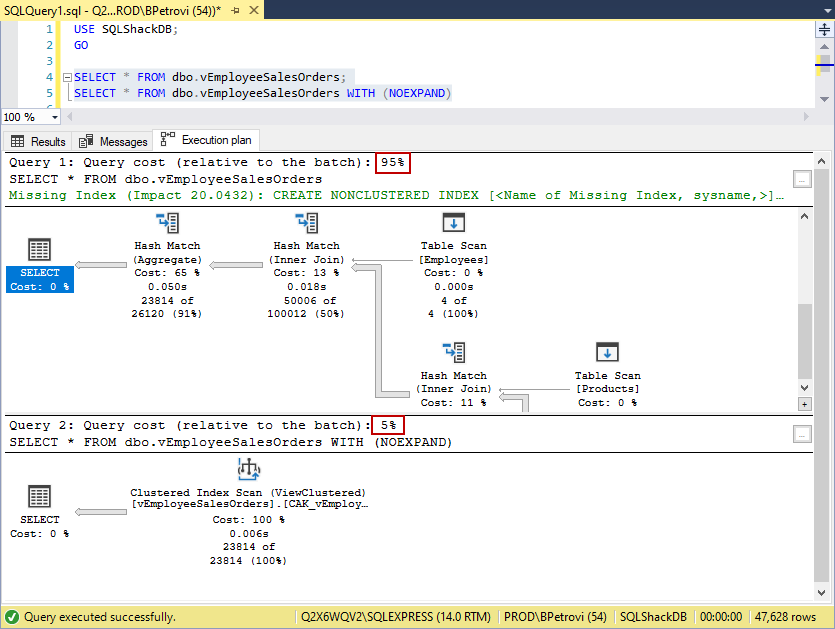
Would you look at that? If we compare the query cost of the first SELECT statement (w/o index 95%) to the second SELECT statement (w/ index 5%), I’d say that’s a huge performance gain using a single index.
你会看看吗? 如果将第一个SELECT语句(不带索引的95%)与第二个SELECT语句(不带索引的5%)的查询成本进行比较,我想说使用单个索引可以大大提高性能。
结论 (Conclusion)
Indexes are great because they speed up the performance and with an index on a view it should really speed up the performance because the index is stored in the database. Indexing both views and tables is one of the most efficient ways to improve the performance of queries and applications using them.
索引之所以出色,是因为它们可以提高性能,并且在视图上使用索引可以真正提高性能,因为索引存储在数据库中。 为视图和表建立索引是提高查询和应用程序性能的最有效方法之一。
I’d like to wrap things up and finish this series of learning the CREATE VIEW SQL statement with this article. We’ve pretty much covered everything about creating and altering views with T-SQL. We started off with the CREATE VIEW SQL statement, created a few views, altered them, deleted, and much more.
我想总结一下所有内容,并通过本文完成本系列的CREATE VIEW SQL语句学习。 我们几乎涵盖了有关使用T-SQL创建和更改视图的所有内容。 我们从CREATE VIEW SQL语句开始,创建了一些视图,对其进行了更改,删除等等。
I hope this series of learning the CREATE VIEW SQL statement has been informative for you and I thank you for reading it.
希望本系列学习CREATE VIEW SQL语句对您有帮助,感谢您阅读它。
目录 (Table of contents)
| CREATE VIEW SQL: Creating views in SQL Server |
| CREATE VIEW SQL: Modifying views in SQL Server |
| CREATE VIEW SQL: Inserting data through views in SQL Server |
| CREATE VIEW SQL: Working with indexed views in SQL Server |
| 创建视图SQL:在SQL Server中创建视图 |
| 创建视图SQL:在SQL Server中修改视图 |
| CREATE VIEW SQL:通过SQL Server中的视图插入数据 |
| CREATE VIEW SQL:在SQL Server中使用索引视图 |
翻译自: https://www.sqlshack.com/create-view-sql-working-with-indexed-views-in-sql-server/















 6051
6051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









