





This article gives you an insight into SQL Server Index properties in SSMS.
本文使您可以深入了解SSMS中SQL Server索引属性。
介绍 (Introduction)
We can create indexes in SQL Server using both GUI and t-SQL method. Once we create an index using t-SQL, we specify the index name, key columns, included columns, filter to create it. We do not consider other index options. While on the other hand, if you use the SSMS GUI method, it gives many options to you. You might get overwhelmed with all SSMS index options. In this article, we will take a look at all SSMS index properties.
我们可以使用GUI和t-SQL方法在SQL Server中创建索引。 使用t-SQL创建索引后,我们将指定索引名称,键列,包含的列并进行过滤以创建索引。 我们不考虑其他索引选项。 另一方面,如果使用SSMS GUI方法,它将为您提供许多选择。 您可能对所有SSMS索引选项不知所措。 在本文中,我们将研究所有SSMS索引属性。
Let’s first create a table for demo and use the CREATE INDEX command for the clustered index on it. In the index script, we specified the clustered index key, and it creates the index with all default options:
首先,我们为演示创建一个表,并对表上的聚集索引使用CREATE INDEX命令。 在索引脚本中,我们指定了聚集索引键,它使用所有默认选项创建索引:
CREATE TABLE Test
(id INT,
name VARCHAR(50)
);
CREATE CLUSTERED INDEX ix_1 ON Test(id);
To verify the index, navigate to source database -> Tables -> dbo.Test-> Indexes. Right-click on the index -> Script Index as -> Create To -> New Query Editor Window:
要验证索引,请导航到源数据库->表-> dbo.Test->索引。 右键单击索引->脚本索引为->创建至->新建查询编辑器窗口:
It gives you the following script with all default configurations:
它为您提供了以下脚本以及所有默认配置:
We can see these index properties while creating the index using SSMS Index GUI. For this purpose, right-click on the earlier index and drop it.
使用SSMS索引GUI创建索引时,我们可以看到这些索引属性。 为此,请右键单击较早的索引并将其删除。
Now, we will create the same clustered index using SSMS. First right-click on the Indexes and choose the required index type such as clustered index, Non-Clustered index, XML index, Clustered Columnstore index, Non-Clustered columnstore index:
现在,我们将使用SSMS创建相同的聚簇索引。 首先右键单击索引,然后选择所需的索引类型,例如聚集索引,非聚集索引,XML索引,聚集列存储索引,非聚集列存储索引:
- Note: If you are not sure about Index type, you can refer 注意:如果不确定索引类型,可以参考SQLShack的“ Performance tuning – Indexes section at SQLShack to learn all about SQL Server Indexes性能调优–索引”部分,以了解有关SQL Server索引的所有信息。
常规选项卡 (General tab)
It gives you the following create new index window.
它为您提供了以下创建新索引窗口。
表名 (Table Name)
It gives you the table name for which we want to create an index.
它为您提供了我们要为其创建索引的表名。
SQL Server索引名称 (SQL Server Index Name)
By default, it generates a unique name for the index in the format of [Index type]_YYYYMMDD-hhmmss. You should use a proper format to easily identify the index, its type, table, key from the index name. for example, you can use format such as [IX_Index name_tablename_keycolumn].
默认情况下,它以[索引类型] _YYYYMMDD-hhmmss的格式为索引生成一个唯一的名称。 您应该使用适当的格式来轻松地从索引名称中识别索引,其类型,表,键。 例如,您可以使用[IX_Index name_tablename_keycolumn]之类的格式。
索引类型 (Index type)
As we have chosen to create a clustered index, it shows that in the index type. You can put a check on the UNIQUE to create a Unique Clustered Index:
当我们选择创建聚簇索引时,它将在索引类型中显示出来。 您可以检查UNIQUE以创建唯一的聚集索引:
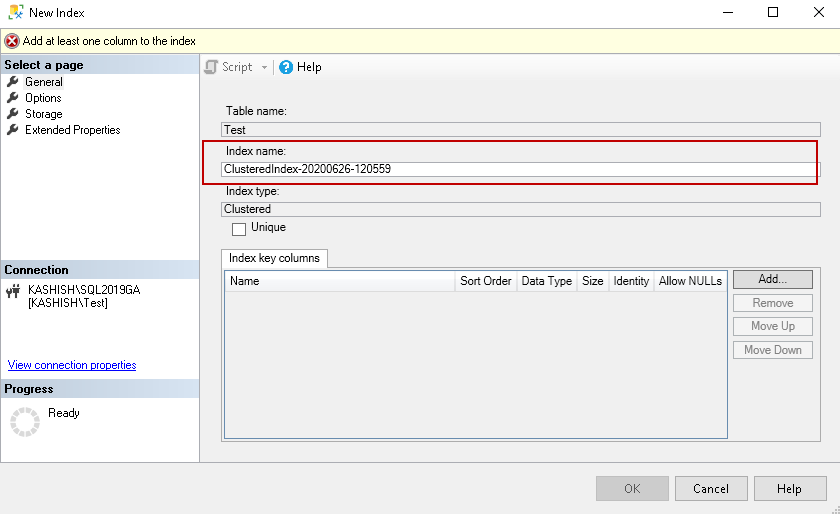
索引键列 (Index Key Columns)
It is the key column in a table for which we want to create the index. Click on Add, and you can see all columns of the selected table:
这是我们要为其创建索引的表中的关键列。 点击添加 ,您可以看到所选表格的所有列:
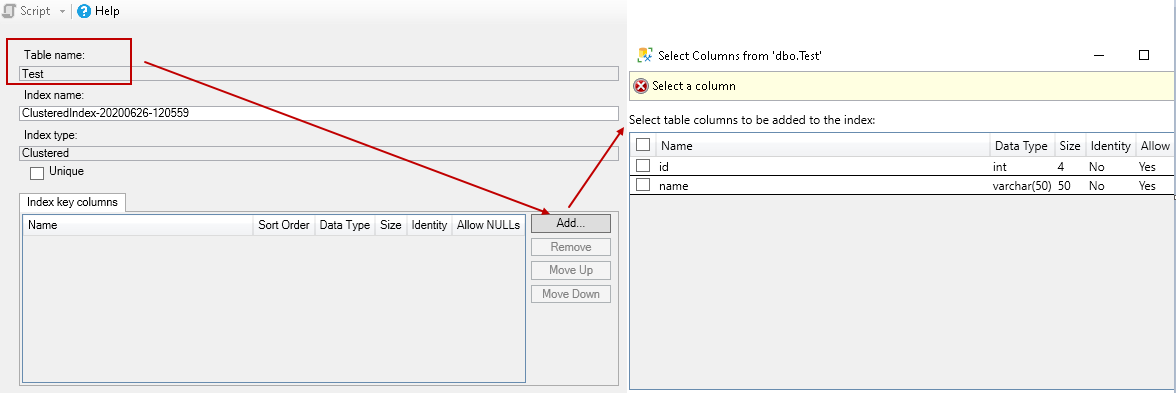
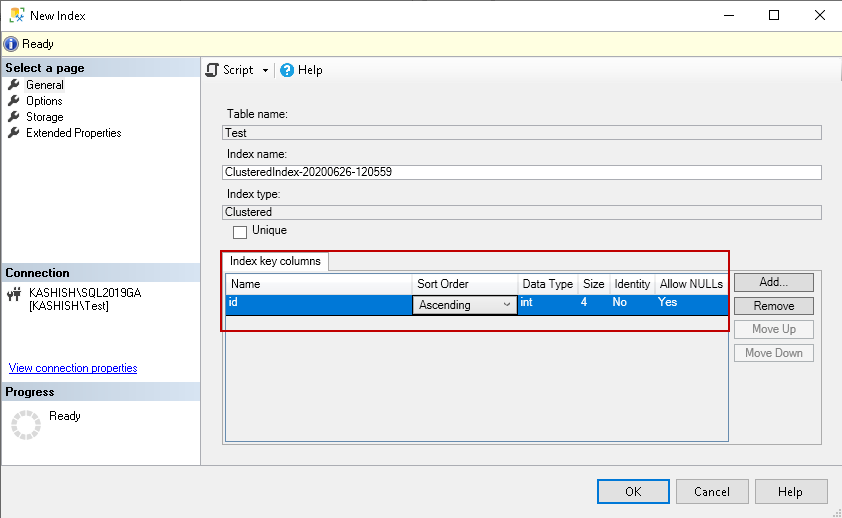
Once you select the key column, it shows you on the general page. By default, it shows an ascending order for the key column. You can change the value as descending if required.
选择键列后,它将在常规页面上显示。 默认情况下,它显示键列的升序。 如果需要,可以将值更改为递减。
Note: You should analyze whether ascending or descending order is useful for your workloads:
注意 :您应该分析升序或降序对您的工作负载是否有用:
SQL Server索引选项页面 (SQL Server Index Options page)
Click on the options page to set various index properties of a specified index. You can see that each property has its default value.
单击选项页面以设置指定索引的各种索引属性。 您可以看到每个属性都有其默认值。
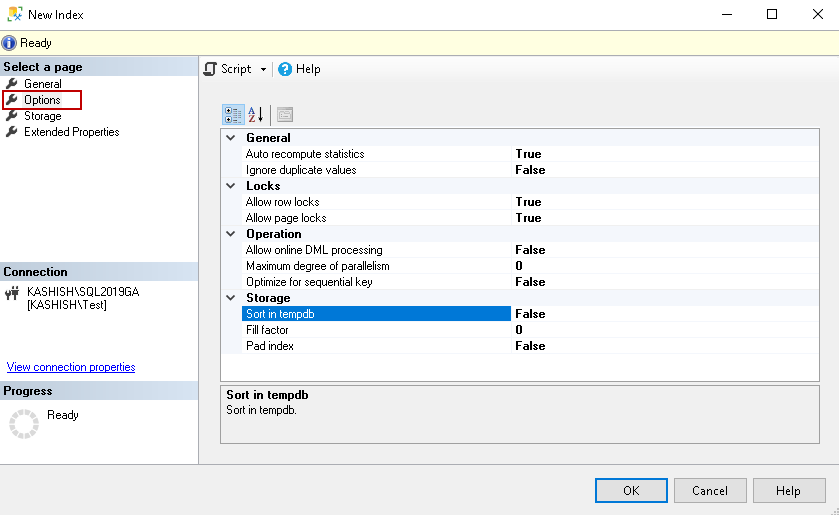
It is an important aspect to know these properties before creating the index. You should be careful in changing the default value for an index as it might change your index behavior. Let’s understand these options.
在创建索引之前了解这些属性是重要的方面。 您应谨慎更改索引的默认值,因为它可能会更改索引行为。 让我们了解这些选项。
自动重新计算统计 (Auto recompute statistics)
You should have updated statistics in SQL Server so that query optimizer can create the optimized execution plan. This property defines whether you require SQL Server to update index statistics automatically or not. By default, it is enabled. You should leave this option to default unless you update them regularly.
您应该在SQL Server中具有更新的统计信息,以便查询优化器可以创建优化的执行计划。 此属性定义是否需要SQL Server自动更新索引统计信息。 默认情况下,它是启用的。 除非定期更新它们,否则应将此选项保留为默认值。
By default, SQL Server uses the following mechanism for automatically update statistics.
默认情况下,SQL Server使用以下机制来自动更新统计信息。
SQL Server 2014 or below: It uses a threshold for the percentage number of rows modified.
SQL Server 2014或更低版本:它将阈值用于修改的行数百分比。
- Table cardinality<500 : Update statistics for every 500 modifications 表基数<500:每500次修改的更新统计信息
- Table cardinality>500: Update statistics for every 500 + 20 % of the total number of rows in the table at the time of statistics computation 表基数> 500:在统计信息计算时,对表中的每500 + 20总行数更新统计信息
SQL Server 2016 and above: It uses a decreasing, dynamic statistics update threshold, but the database should be compatibility level 130 or more. It uses the following formula for calculating the threshold:
SQL Server 2016及更高版本:它使用递减的动态统计信息更新阈值,但数据库的兼容性级别应为130或更高。 它使用以下公式计算阈值:
As per the above formula, for a table with 1 million rows, it updates the statistics for every 31622 modifications:
根据上面的公式,对于具有一百万行的表,它将对每31622次修改更新统计信息:
You can go through Microsoft docs for detailed knowledge of SQL Server statistics.
您可以浏览Microsoft文档以获取有关SQL Server统计信息的详细知识。
忽略重复的值 (Ignore Duplicate Values)
It defines whether we can have a duplicate key in the index column or not. By default, it is set to False which means if someone tries to insert a duplicate key value, SQL Server generates an error message and rollbacks the transaction.
它定义了我们是否可以在索引列中有重复的键。 默认情况下,它设置为False ,这意味着如果有人尝试插入重复的键值,则SQL Server会生成错误消息并回滚事务。
If we set it to true, SQL Server will ignore the duplicate key and does not give any error message. We can use ignore duplicate values with unique indexes. You get an error message for non-unique indexes:
如果将其设置为true,则SQL Server将忽略重复键,并且不会给出任何错误消息。 我们可以将忽略重复值与唯一索引一起使用。 您会收到有关非唯一索引的错误消息:
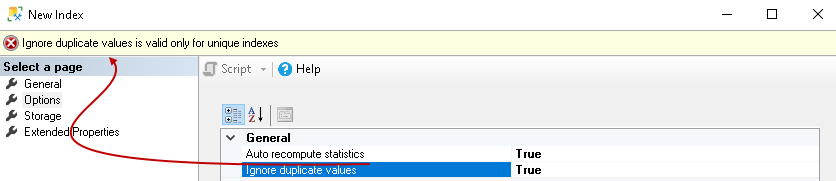
You can understand about unique index in the article, Difference between Unique Indexes and Unique Constraints in SQL Server.
您可以在文章SQL Server中的唯一索引和唯一约束之间的差异中了解唯一索引。
允许行锁和允许页锁 (Allow row locks and Allow page locks)
We can specify to allow or not row-level locking or page lock using these properties. You should not make changes to this property unless you are confident about it. Turning if off might improve index maintenance, but it causes blockings. You should allow SQL Server to choose the locking mechanism efficiently.
我们可以使用这些属性指定是否允许行级锁定或页面锁定。 除非对此有信心,否则不要更改此属性。 如果将其关闭,则可以改善索引维护,但会导致阻塞。 您应该允许SQL Server有效地选择锁定机制。
允许在线DML处理 (Allow Online DML processing)
In a 24*7 OLTP environment, it is challenging to get a window for index maintenance. By default, you face blockings while you perform index maintenance. SQL Server enterprise edition provides options for online index maintenance.
在24 * 7的OLTP环境中,获取索引维护窗口具有挑战性。 默认情况下,在执行索引维护时会遇到阻塞。 SQL Server企业版提供了用于联机索引维护的选项。
You can set this option to true so that Index rebuild is online and it does not block other user’s queries. Users can perform data manipulations queries during an index maintenance operation.
您可以将此选项设置为true,以使索引重建处于联机状态,并且不会阻止其他用户的查询。 用户可以在索引维护操作期间执行数据操作查询。
You can refer to the article Maintaining SQL Server indexes for more details for online index maintenance.
您可以参考文章维护SQL Server索引,以获得有关在线索引维护的更多详细信息。
SQL Server索引的最大并行度 (Maximum degree of parallelism for SQL Server Index)
Usually, we set MAXDOP at the SQL Server instance to limit the number of processors for parallel query execution. By default, its value is 0 which shows it can use all available processors. Sometimes, you face issues due to parallelism, and you want to limit the processors. You can set this property either at the instance level or in the index definition. You can specify the value in this property to create an index that uses specific MAXDOP.
通常,我们在SQL Server实例上设置MAXDOP以限制用于并行查询执行的处理器数量。 默认情况下,其值为0,表示它可以使用所有可用的处理器。 有时,您会由于并行性而遇到问题,并且想要限制处理器。 您可以在实例级别或在索引定义中设置此属性。 您可以在此属性中指定值,以创建使用特定MAXDOP的索引。
优化顺序键 (Optimize For Sequential Key)
This option is available in SQL Server 2019. It solves the performance issues due to concurrent inserts. We can use this option OPTIMIZE_FOR_SEQUENTIAL_KEY to control the rate at which new heads can request latch. It also provides high throughput.
此选项在SQL Server 2019中可用。它解决了由于并发插入而导致的性能问题。 我们可以使用该选项OPTIMIZE_FOR_SEQUENTIAL_KEY来控制新磁头可以请求锁存的速率。 它还提供了高吞吐量。
You can refer article Behind the Scenes on OPTIMIZE_FOR_SEQUENTIAL_KEY to learn about the internals of Optimize For Sequential Key in SQL Server Index.
您可以参考OPTIMIZE_FOR_SEQUENTIAL_KEY上的幕后文章,以了解SQL Server索引中的“优化顺序键”的内部信息。
在Tempdb中排序 (Sort in Tempdb)
We can store the sort results for index creation in the TempDB using this property. By default, SQL Server uses the database in which index lies. Usually, we store TempDB on a faster disk IO throughput so we can set this property to true and it uses TempDB for its sort operation. You should consider the storage requirement as well as the TempDB to use this configuration.
我们可以使用此属性将排序结果存储在TempDB中以创建索引。 默认情况下,SQL Server使用索引所在的数据库。 通常,我们将TempDB存储在更快的磁盘IO吞吐量上,因此我们可以将此属性设置为true,并将TempDB用于其排序操作。 您应该考虑存储要求以及使用此配置的TempDB。
SQL Server索引填充因子 (SQL Server Index Fill Factor)
Fill factor in an index that how much the leaf level page of each index can be for SQL Server. For example, if we specify the fill factor value is 90, it means that 10 percent of each leaf node page will be empty for future data inserts. We can specify a value between 1 and 100 in this. By default, it shows value 0 that is equivalent to 100. You should consider changing the value with attention as it could cause page splits that impact database performance.
索引中的填充因子,即对于SQL Server,每个索引的叶级页面可以有多少。 例如,如果我们将填充因子值指定为90,则意味着每个叶节点页面的10%将为将来的数据插入而为空。 我们可以在其中指定1到100之间的一个值。 默认情况下,它显示的值0等于100。您应该考虑更改该值,因为它可能导致页面拆分影响数据库性能。
You can refer article Specify Fill Factor for an Index for more details.
您可以参考文章指定索引的填充因子以获取更多详细信息。
垫子指数 (Pad index)
Pad index is similar to a fill factor except that it applies to the non-leaf levels of an index. This index configuration is available only when we set the fill factor as well. By default, it is turned off.
填充索引类似于填充因子,不同之处在于填充索引适用于索引的非叶级别。 仅当我们也设置填充因子时,此索引配置才可用。 默认情况下,它是关闭的。
存储 (Storage)
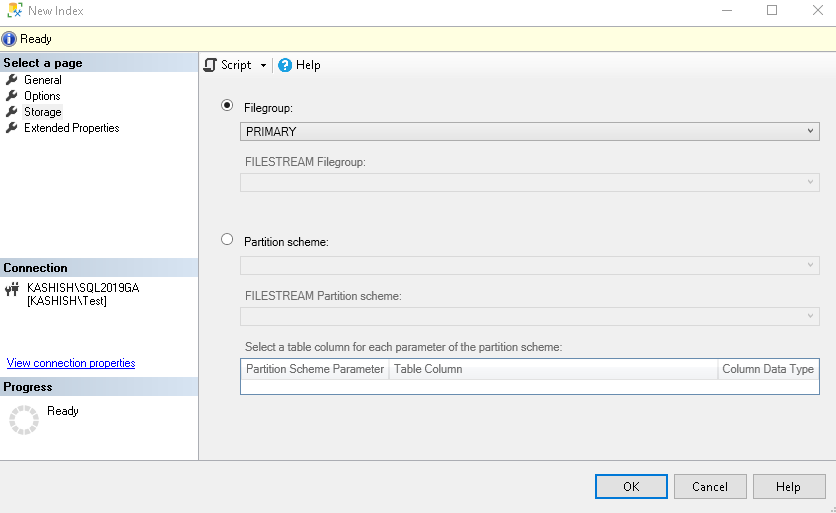
Click on the Storage tab in the new index. Here, you can define the filegroup for the index along with the partition scheme. You can use the partition scheme if you have defined partitions in SQL Server table.
单击新索引中的“ 存储”选项卡。 在这里,您可以定义索引的文件组以及分区方案。 如果在SQL Server表中定义了分区,则可以使用分区方案。
By default, SQL Server stores all data and indexes in a primary filegroup. As the best practices, you should create a new filegroup to store indexes. If you have created the filegroup, you can select the filegroup from the drop-down:
默认情况下,SQL Server将所有数据和索引存储在主文件组中。 作为最佳实践,您应该创建一个新的文件组来存储索引。 如果已创建文件组,则可以从下拉列表中选择文件组:
结论 (Conclusion)
In this article, we explored various configurations in the SSMS for SQL Server Index. We should be aware of all these index properties and configure them as per our workload requirement.
在本文中,我们探讨了SQL Server SSMS中的各种配置。 我们应该了解所有这些索引属性,并根据我们的工作负载要求进行配置。
You should not change the default value directly in a production database. It should be implemented in non-prod instance with proper load testing.
您不应直接在生产数据库中更改默认值。 应该在非产品实例中通过适当的负载测试来实现。
翻译自: https://www.sqlshack.com/explore-sql-server-index-properties-in-ssms/

















 1105
1105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









