





Because databases aren’t always designed efficiently, data is sometimes stored in ways that make sorting and searching extremely difficult. Requests for meaningful, informative reports from such data, however, still must be fulfilled.
由于并非总是高效地设计数据库,因此有时会以使排序和搜索变得极为困难的方式存储数据。 但是,仍然必须满足从此类数据中获取有意义的,内容丰富的报告的要求。
Note: This applies to SQL Server 2012 and higher.
注意:这适用于SQL Server 2012及更高版本。
场景 ( SCENARIO )
I have a preexisting table of 96 rows of company store locations and their respective phone contact numbers. There is one record for each store, each having a single ‘PhoneNumbers’ field that contains three separate phone numbers: the main store number with or without an extension, a secondary store number, and a mobile phone number. The phone data is very messy (all three numbers are crammed together into one field) and cannot easily be searched or sorted.
我有一个预先存在的表格,该表格包含96行公司存储位置及其各自的电话联系号码。 每个商店都有一个记录,每个记录都有一个“ PhoneNumbers”字段,其中包含三个单独的电话号码:带或不带扩展名的主要商店编号,辅助商店编号和移动电话号码。 电话数据非常混乱(所有三个数字都挤在一个字段中),无法轻松搜索或排序。
USE COMPANY;
SELECT TOP 10 * FROM Locations;
As you can see, the store numbers are delimited by either a slash (/) or an ampersand (&). The ‘main’ phone numbers are followed by one (or none) of the following text: ‘x’, ‘ext’, ‘extension’; an extension number; and then the text ‘ofc’, ‘main’, or ‘office’. The ‘secondary’ phone numbers are trailed by either the text ‘2nd’ or ‘secondary’; while the final ‘mobile’ numbers are followed by the text ‘cell’ or ‘cellphone’.
如您所见,商店编号由斜杠( / )或与号( & )分隔。 “主”电话号码后跟以下文本之一(或无):“ x ”,“ ext ”,“ 分机 ”; 分机号码; 然后是文字' ofc ',' main '或' office '。 “次要”的电话号码是由可以是文本“第2”或“ 次级 ”落后; 而最终的“移动”号码,然后输入文本“ 细胞 ”或“ 手机 ”。
Our objective is to parse the three separate kinds of phone numbers, implement consistency, and return the parsed data so that each phone number is on a separate row (unpivoting).
我们的目标是解析三种不同的电话号码,实现一致性,并返回解析的数据,以便每个电话号码都位于单独的行中(不可透视)。
PARSENAME ( PARSENAME )
Our first step will be to parse the phone numbers on the delimiters. One method that neatly accomplishes this is the using the PARSENAME function. The PARSENAME function is logically designed to parse four-part object names – distinguishing between server name, database name, schema name, and object name:
我们的第一步将是解析定界符上的电话号码。 巧妙地做到这一点的一种方法是使用PARSENAME函数。 PARSENAME函数在逻辑上被设计为解析由四部分组成的对象名称-区分服务器名称,数据库名称,架构名称和对象名称:
SELECT PARSENAME('COMPANY.dbo.Locations',3) AS 'ObjectName';
SELECT PARSENAME('COMPANY.dbo.Locations',2) AS 'SchemaName';
SELECT PARSENAME('COMPANY.dbo.Locations',1) AS 'DatabseName';
The syntax to use for PARSENAME is:
用于PARSENAME的语法是:
PARSENAME ( 'object_name' , object_piece )
The first parameter is the object to parse, and the second is the integer value of the object piece to return. The nice thing about PARSENAME is that it’s not limited to parsing just SQL Server four-part object names – it will parse any function or string data that is delimited by dots:
第一个参数是要解析的对象,第二个参数是要返回的对象片段的整数值。 PARSENAME的好处是它不仅限于解析SQL Server的四部分对象名称-它将解析由点分隔的任何函数或字符串数据:
USE COMPANY;
SELECT PARSENAME('Whatever.you.want.parsed',3) AS 'ReturnValue';
DECLARE @FourPartName NVARCHAR(100) = SCHEMA_NAME()+'.'+DB_NAME();
SELECT PARSENAME(@FourPartName,1) AS 'ReturnValue';
SELECT PARSENAME(@FourPartName,2) AS 'ReturnValue';
Let’s use PARSENAME to separate the three types of phone numbers. To simplify things, let’s use a bit of code with the REPLACE function to replace the delimiters with the expected ‘object part’ separator (dot):
让我们使用PARSENAME分隔三种电话号码。 为简化起见,让我们在REPLACE函数中使用一些代码,用所需的“对象部分”分隔符(点)替换定界符:
--replace all delimiters with the object part separator (.)
USE COMPANY;
SELECT ID, Store, REPLACE(REPLACE(PhoneNumbers,'&','.'),'/','.') AS PhoneNumbers
FROM Locations;
We should now have the PhoneNumbers field values returned in this format: [main number].[secondary number].[mobile number]. Now we can use PARSENAME against the table’s delimiter-replaced data. PARSENAME will see the PhoneNumbers string as follows: [main number] = ‘object name’, [secondary number] = ‘schema name’, and [mobile number] = ‘database name’ – because of the order of the delimited data positions. We’ll use a Common Table Expression (CTE) called ‘replaceChars’ to run PARSENAME against the delimiter-replaced values. A CTE is useful for returning a temporary view or result set. We’ll return the original PhoneNumbers field as well, for comparison purposes:
现在,我们应该以以下格式返回PhoneNumbers字段值: [main number ]。[ secondary number]。[mobile number] 。 现在,我们可以对表的定界符替换数据使用PARSENAME。 PARSENAME将看到PhoneNumbers字符串,如下所示:[主号码] ='对象名称',[第二电话号码] ='模式名称',[移动电话号码] ='数据库名称'–因为分隔数据位置的顺序。 我们将使用称为“ replaceChars”的公用表表达式 (CTE)对分隔符替换的值运行PARSENAME。 CTE对于返回临时视图或结果集很有用。 为了进行比较,我们还将返回原始的PhoneNumbers字段:
USE COMPANY;
WITH replaceChars (ID, Store, PhoneNumbers)
AS
(
--replace all separators with the object part separator (.)
SELECT ID, Store, REPLACE(REPLACE(PhoneNumbers,'&','.'),'/','.') AS PhoneNumbers
FROM Locations
)
SELECT *
FROM
(
SELECT ID,
Store,
PhoneNumbers,
PARSENAME(PhoneNumbers, 3) AS [Main], --returns 'object name'
PARSENAME(PhoneNumbers, 2) AS [Secondary], --returns 'schema name'
PARSENAME(PhoneNumbers, 1) AS [Mobile] --returns 'database name'
FROM replaceChars
)x;
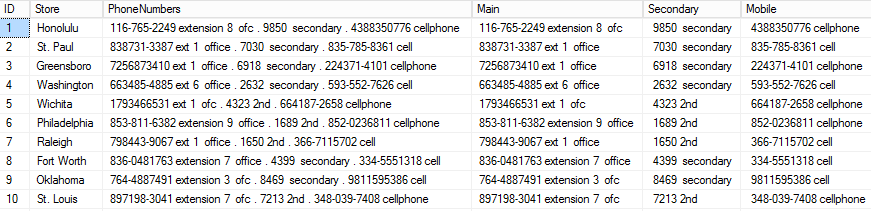
Based on the replaced delimiter values, PARSENAME returns each section of the PhoneNumbers field by its position in the data string. Each of the three types of numbers now has its own field.
根据替换的定界符值,PARSENAME将按其在数据字符串中的位置返回PhoneNumbers字段的每个部分。 现在,三种类型的数字都有各自的字段。
志愿人员 ( UNPIVOT )
Our next task is to make sure each number for a given store is displayed on a separate record. Essentially, we want to convert some columns into rows. The UNPIVOT function was designed exactly for scenarios like this. Since we have three distinct types of values (Main, Secondary, and Mobile), we can designate them to be rotated and consolidated into a new field (‘Number’) and labeled by another new field (‘Precedence’) – all by using UNPIVOT:
我们的下一个任务是确保给定商店的每个编号都显示在单独的记录中。 本质上,我们希望将某些列转换为行。 UNPIVOT功能正是针对这种情况而设计的。 由于我们具有三种不同类型的值(主要,次要和移动),因此我们可以将它们指定为要轮换并合并到一个新字段 (“数字”)中,并用另一个新字段(“优先级”)标记-通过使用志愿人员:
USE COMPANY;
WITH replaceChars (ID, Store, PhoneNumbers)
AS
(
--replace all separators with the object part separator (.)
SELECT ID, Store, REPLACE(REPLACE(PhoneNumbers,'&','.'),'/','.') AS PhoneNumbers
FROM Locations
)
SELECT *
FROM
(
SELECT ID,
Store,
PhoneNumbers,
PARSENAME(PhoneNumbers, 3) AS [Main], --returns 'object name'
PARSENAME(PhoneNumbers, 2) AS [Secondary], --returns 'schema name'
PARSENAME(PhoneNumbers, 1) AS [Mobile] --returns 'database name'
FROM replaceChars
)x
UNPIVOT
(
[Number] for Precedence in ([Main], [Secondary], [Mobile]) --rotate the three phone fields into one
)y
ORDER BY ID;
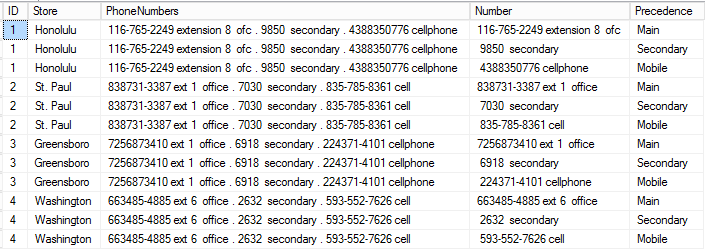
Note that each store now has three records to accommodate the three types of phone number. The UNPIVOT function has allowed us to effectively rotate the three new phone number columns into rows – facilitating a more normalized table structure.
请注意,每个商店现在都有三个记录来容纳三种类型的电话号码。 UNPIVOT功能使我们能够有效地将三个新的电话号码列旋转到行中,从而简化了表格结构。
清洁数据 ( CLEANING THE DATA )
Now that we’ve done the heavy lifting needed to parse and rotate the phone numbers, let’s spend some time cleaning up the inconsistencies in the data.
现在,我们已经完成了解析和旋转电话号码所需的繁重工作,让我们花一些时间来清理数据中的不一致之处。
One improvement that can be made is to pull out the extension numbers that are associated with the Main numbers. We know that all extensions are referenced by either ‘x’, ‘ext’, or ‘extension’, so we can use the SUBSTRING and CHARINDEX functions to extract the single-digit extension numbers. We’ll generate a new field (‘Extension’) for these values in the return statement:
可以进行的一项改进是拔出与主号码关联的分机号码。 我们知道,所有的扩展是由是“X”,“ 转 ”,或“ 延伸 ”引用的,所以我们可以使用SUBSTRING和CHARINDEX函数提取的个位数的分机号码。 我们将在return语句中为这些值生成一个新字段(“扩展名”):
USE COMPANY;
WITH replaceChars (ID, Store, PhoneNumbers)
AS
(
--replace all separators with the object part separator (.)
SELECT ID, Store, REPLACE(REPLACE(PhoneNumbers,'&','.'),'/','.') AS PhoneNumbers
FROM Locations
)
SELECT ID, Store, PhoneNumbers, [Number], Precedence,
CASE WHEN CHARINDEX('extension',[Number]) > 0
THEN SUBSTRING([Number],CHARINDEX('extension',[Number])+10,1) --extract the extension number
WHEN CHARINDEX('ext',[Number]) > 0
THEN SUBSTRING([Number],CHARINDEX('ext',[Number])+4,1) --extract the extension number
WHEN CHARINDEX('x',[Number]) > 0
THEN SUBSTRING([Number],CHARINDEX('x',[Number])+2,1) --extract the extension number
END AS [Extension]
FROM
(
SELECT ID,
Store,
PhoneNumbers,
PARSENAME(PhoneNumbers, 3) AS [Main], --returns 'object name'
PARSENAME(PhoneNumbers, 2) AS [Secondary], --returns 'schema name'
PARSENAME(PhoneNumbers, 1) AS [Mobile] --returns 'database name'
FROM replaceChars
)x
UNPIVOT
(
[Number] for Precedence in ([Main], [Secondary], [Mobile]) --rotate the three phone fields into one
)y
ORDER BY ID;
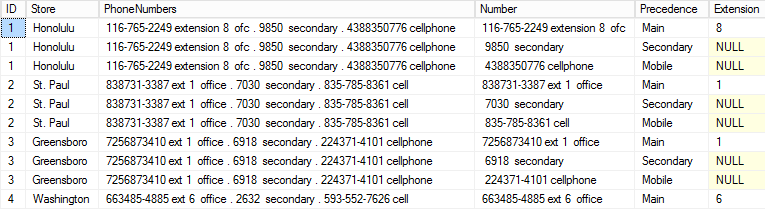
We’ve successfully extracted the extension numbers from the Main numbers into a new field. Remember, only Main numbers have an associated extension, so the others will be NULL.
我们已经成功地将分机号码从主要号码中提取到一个新字段中。 请记住,只有Main数字具有关联的扩展名,因此其他数字将为NULL。
Our next challenge is to do the following:
我们的下一个挑战是执行以下操作:
- Remove the intermittent dashes (-) from all numbers for standardization. 从所有数字中删除断续的破折号(-)以进行标准化。
- Remove leading whitespaces. 删除前导空格。
- Separate the numbers from all trailing text. 将数字与所有尾随的文本分开。
- Prepend the four-digit Secondary numbers with the first six numbers from its respective store’s Main number – it can be assumed that each Secondary phone has the same area code and exchange as its associated Main number does. 在四位数的辅助电话号码前面加上其各自商店的主电话号码中的前六个号码–可以假设每个辅助电话都具有与其关联的主电话号码相同的区号和交换方式。
For steps one and two, we’ll employ the REPLACE and LTRIM functions:
对于步骤一和步骤二,我们将使用REPLACE和LTRIM函数:
LTRIM(REPLACE([Number],'-',''))
This combination removes leading whitespaces and eliminates dashes.
这种组合消除了前导空格并消除了破折号。
For step three, we’ll wrap the above solution in the SUBSTRING function:
对于第三步,我们将上述解决方案包装在SUBSTRING函数中:
SUBSTRING(LTRIM(REPLACE([Number],'-','')),1,10)
For Secondary numbers, we’ll use a different ‘length’ argument value, since they have only four digits:
对于辅助数字,我们将使用不同的“长度”参数值,因为它们只有四个数字:
SUBSTRING(LTRIM(REPLACE([Number],'-','')),1,4)
落后 ( LAG )
For our fourth step, we can use the LAG function (new for SQL Server 2012) – it allows referencing of previous records (exactly what we need to do to grab the first six characters from each store’s Main number):
对于第四步,我们可以使用LAG函数(SQL Server 2012的新增功能)–它允许引用以前的记录(正是从每个商店的主号码中抓取前六个字符所需要做的事情):
LAG(SUBSTRING(LTRIM(REPLACE([Number],'-','')),1,6)) OVER (ORDER BY ID)
We’ll append those results with the extracted Secondary number. Putting it all together, we have a complete solution. We can now also eliminate the original PhoneNumbers field:
我们将这些结果附加到提取的次要编号上。 综上所述,我们有一个完整的解决方案。 现在,我们还可以消除原始的PhoneNumbers字段:
USE COMPANY;
WITH replaceChars (ID, Store, PhoneNumbers)
AS
(
--replace all separators with the object part separator (.)
SELECT ID, Store, REPLACE(REPLACE(PhoneNumbers,'&','.'),'/','.') AS PhoneNumbers
FROM Locations
)
SELECT ID, Store, Precedence,
CASE WHEN Precedence = 'Secondary'
THEN LAG(SUBSTRING(LTRIM(REPLACE([Number],'-','')),1,6)) OVER (ORDER BY ID) + SUBSTRING(LTRIM(REPLACE([Number],'-','')),1,4) --prepend Secondary numbers with the first six numbers of the store’s Main number
ELSE SUBSTRING(LTRIM(REPLACE([Number],'-','')),1,10)
END AS [Number],
CASE WHEN CHARINDEX('extension',[Number]) > 0
THEN SUBSTRING([Number],CHARINDEX('extension',[Number])+10,1) --extract the extension number
WHEN CHARINDEX('ext',[Number]) > 0
THEN SUBSTRING([Number],CHARINDEX('ext',[Number])+4,1) --extract the extension number
WHEN CHARINDEX('x',[Number]) > 0
THEN SUBSTRING([Number],CHARINDEX('x',[Number])+2,1) --extract the extension number
END AS [Extension]
FROM
(
SELECT ID,
Store,
PhoneNumbers,
PARSENAME(PhoneNumbers, 3) AS [Main], --returns 'object name'
PARSENAME(PhoneNumbers, 2) AS [Secondary], --returns 'schema name'
PARSENAME(PhoneNumbers, 1) AS [Mobile] --returns 'database name'
FROM replaceChars
)x
UNPIVOT
(
[Number] for Precedence in ([Main], [Secondary], [Mobile])
)y
ORDER BY ID;
分析和最后步骤 ( ANALYSIS & FINAL STEPS )
The Locations table’s data has now been parsed, rotated, cleaned, and standardized to the given requirements. It is now in a highly searchable and sortable format, and can be easily inserted to a new, permanent table that could replace the original.
现在已根据给定的要求对Locations表的数据进行了解析,旋转,清理和标准化。 现在,它具有高度可搜索和可排序的格式,并且可以轻松插入新的永久性表中,以替换原始表。
Some remaining steps that could be tackled would be to
其他可以解决的步骤是
- Normalize the data further – for example, if a ‘Store’ table exists, we could replace the Store field in the Locations data with one containing Store IDs, and establish referential integrity with a foreign key to the primary key of the Stores table. 进一步规范化数据–例如,如果存在一个“ Store”表,我们可以用一个包含Store ID的位置数据替换Locations数据中的Store字段,并使用指向Stores表主键的外键建立引用完整性。
- Add appropriate indexes to the tables based on historical or anticipated queries. 根据历史查询或预期查询向表中添加适当的索引。
看更多 (See more)
Consider these free tools for SQL Server that improve database developer productivity.
考虑使用这些免费SQL Server工具来提高数据库开发人员的生产力。

翻译自: https://www.sqlshack.com/parsing-and-rotating-delimited-data-in-sql-server/

















 1262
1262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









