





As database professionals, we are often in very close proximity to important processes, data, and applications. While we adopt the mantra of “Do no harm”, many maintenance or reporting tasks that we create carry unseen risks associated with them.
作为数据库专业人员,我们通常非常靠近重要的流程,数据和应用程序。 尽管我们奉行“请勿伤害”的口号,但我们创建的许多维护或报告任务都存在与之相关的未知风险。
What happens when a drive fills up during daily differential backups? What if an index rebuild job runs abnormally long and interferes with morning processing? How about if a data load process causes extensive resource contention, bringing normal operations to their knees? All of these are planned events, yet can cause considerable disruption to the very processes we are trying to safeguard.
如果在每日差异备份期间驱动器已满,会发生什么情况? 如果索引重建作业的运行时间异常长并且干扰了早上的处理该怎么办? 数据加载过程是否会引起大量资源争用,从而使正常操作瘫痪怎么办? 所有这些都是有计划的事件,但是会严重破坏我们试图维护的流程。
There are many simple ways to protect our important maintenance jobs against situations that could easily bring down production systems. This is a chance to greatly improve our standard practices and avoid unnecessary wake-up-calls at 2am on a Sunday!
有很多简单的方法可以保护我们重要的维护工作,以防可能导致生产系统崩溃的情况。 这是一次极大地改善我们的标准惯例并避免在周日凌晨2点进行不必要的叫醒电话的机会!
有什么问题吗? (What can go wrong?)
In the tasks that we regularly perform, a wide variety of bad (yet preventable) things can happen. Here is a short list of examples that can keep us up late at night:
在我们定期执行的任务中,可能会发生各种各样的不良(但可以预防)的事情。 以下是一些可以使我们熬夜的例子:
- A data collector job performs an unusually large amount of work, filling up the data drive for a reporting database and leaving it in a state where reports cannot run. 数据收集器作业执行了异常大量的工作,为报告数据库填充了数据驱动器,并使数据驱动器处于无法运行报告的状态。
- A large software release results in far more changed data than expected. The transaction log backups become very large during the release, filling up the backup destination drive and causing subsequent backups to fail. 大型软件版本导致更改的数据远远超出预期。 发行期间,事务日志备份变得非常大,填满了备份目标驱动器,并导致后续备份失败。
- Following that large release, an index rebuild job finds far more indexes than usual that require rebuilding. This process causes significant log growth, filling up the log file drive and preventing further transactional processing. 发行了如此大的索引之后,索引重建作业发现的索引要比通常需要重建的索引要多得多。 此过程会导致日志显着增长,填满日志文件驱动器并阻止进一步的事务处理。
- An archiving process takes longer than usual, running into normal production hours and interfering with important daily operations. 归档过程比平时花费更长的时间,导致正常的生产时间并干扰重要的日常操作。
- Multiple maintenance jobs run long, running into each other and causing excessive CPU consumption and disk I/O. In addition, each job is slowed down by the resource contention caused by the presence of the other. 多个维护作业的运行时间很长,彼此之间并存,从而导致过多的CPU消耗和磁盘I / O。 另外,每个作业都会因另一个作业的存在而导致资源争用而减慢速度。
Depending on your database environments, some of these may be more relevant than others, and there may be more that aren’t listed here. Note the significance of how jobs can impact each other and cause bigger problems when combined. The large software release mentioned above causes data and log growth, which we can anticipate and mitigate. The index fragmentation caused by the release, though, leads to the index maintenance job having to work far more than is typically expected. Not only must we guard jobs against expected problems, but we need to build in protection against unusual or infrequent situations, especially those caused by the interaction of multiple jobs.
根据您的数据库环境,其中一些可能比其他环境更相关,这里可能没有列出更多的内容。 请注意工作组合在一起时如何相互影响并引起更大问题的重要性。 上面提到的大型软件版本导致数据和日志增长,这是我们可以预期和缓解的。 但是,由发行引起的索引碎片会导致索引维护工作的工作量远远超出通常的预期。 我们不仅必须保护工作免受预期的问题,而且还需要建立保护措施,以防止出现异常或偶发情况,尤其是由多个工作的交互作用引起的情况。
解 (Solution)
We can build simple checks into our maintenance jobs that verify available resources as well as what an operation will require prior to execution. This allows us to ensure that our environment can handle what we are about to do, and abort with a meaningful error if resources are inadequate.
我们可以在维护作业中进行简单的检查,以验证可用资源以及执行之前需要执行的操作。 这使我们可以确保我们的环境可以处理我们将要做的事情,并在资源不足时中止并产生有意义的错误。
To illustrate some of these options, we’ll demo a simple index maintenance stored procedure. Your index maintenance may be significantly more complex, but the techniques shown here will be useful regardless of the intricacy of your maintenance procedures.
为了说明其中一些选项,我们将演示一个简单的索引维护存储过程。 您的索引维护可能要复杂得多,但是无论维护过程的复杂程度如何,此处显示的技术都将很有用。
CREATE PROCEDURE dbo.index_maintenance_daily
@reorganization_percentage TINYINT = 10,
@rebuild_percentage TINYINT = 35
AS
BEGIN
DECLARE @sql_command NVARCHAR(MAX) = '';
DECLARE @parameter_list NVARCHAR(MAX) = '@reorganization_percentage TINYINT, @rebuild_percentage TINYINT'
DECLARE @database_list TABLE
(database_name NVARCHAR(MAX) NOT NULL);
INSERT INTO @database_list
(database_name)
SELECT
name
FROM sys.databases
WHERE databases.name NOT IN ('msdb', 'master', 'TempDB', 'model');
CREATE TABLE #index_maintenance
( database_name NVARCHAR(MAX),
schema_name NVARCHAR(MAX),
object_name NVARCHAR(MAX),
index_name NVARCHAR(MAX),
index_type_desc NVARCHAR(MAX),
avg_fragmentation_in_percent FLOAT,
index_operation NVARCHAR(MAX));
SELECT @sql_command = @sql_command + '
USE [' + database_name + ']
INSERT INTO #index_maintenance
(database_name, schema_name, object_name, index_name, index_type_desc, avg_fragmentation_in_percent, index_operation)
SELECT
CAST(SD.name AS NVARCHAR(MAX)) AS database_name,
CAST(SS.name AS NVARCHAR(MAX)) AS schema_name,
CAST(SO.name AS NVARCHAR(MAX)) AS object_name,
CAST(SI.name AS NVARCHAR(MAX)) AS index_name,
IPS.index_type_desc,
IPS.avg_fragmentation_in_percent, -- Be sure to filter as much as possible...this can return a lot of data if you dont filter by database and table.
CAST(CASE
WHEN IPS.avg_fragmentation_in_percent >= @rebuild_percentage THEN ''REBUILD''
WHEN IPS.avg_fragmentation_in_percent >= @reorganization_percentage THEN ''REORGANIZE''
END AS NVARCHAR(MAX)) AS index_operation
FROM sys.dm_db_index_physical_stats(NULL, NULL, NULL, NULL , NULL) IPS
INNER JOIN sys.databases SD
ON SD.database_id = IPS.database_id
INNER JOIN sys.indexes SI
ON SI.index_id = IPS.index_id
INNER JOIN sys.objects SO
ON SO.object_id = SI.object_id
AND IPS.object_id = SO.object_id
INNER JOIN sys.schemas SS
ON SS.schema_id = SO.schema_id
WHERE alloc_unit_type_desc = ''IN_ROW_DATA''
AND index_level = 0
AND SD.name = ''' + database_name + '''
AND IPS.avg_fragmentation_in_percent >= @reorganization_percentage
AND SI.name IS NOT NULL -- Only review index, not heap data.
AND SO.is_ms_shipped = 0 -- Do not perform maintenance on system objects
ORDER BY SD.name ASC;'
FROM @database_list
WHERE database_name IN (SELECT name FROM sys.databases);
EXEC sp_executesql @sql_command, @parameter_list, @reorganization_percentage, @rebuild_percentage;
SELECT @sql_command = '';
SELECT @sql_command = @sql_command +
' USE [' + database_name + ']
ALTER INDEX [' + index_name + '] ON [' + schema_name + '].[' + object_name + ']
' + index_operation + ';
'
FROM #index_maintenance;
SELECT * FROM #index_maintenance
ORDER BY avg_fragmentation_in_percent;
EXEC sp_executesql @sql_command;
DROP TABLE #index_maintenance;
END
This stored procedure takes two parameters that indicate at what level of fragmentation an index should be reorganized and rebuilt. Using that information, every index in every non-system database will be checked and operated on, if fragmentation is high enough. This would presumably be run on a daily or weekly schedule at an off-hours time when system usage is low.
该存储过程采用两个参数,这些参数指示应该在哪个碎片级别上重组和重建索引。 如果碎片足够高,则使用该信息将检查并操作每个非系统数据库中的每个索引。 当系统使用率较低时,大概可以每天或每周在非工作时间运行。
No limits are set in this stored proc. As a result, it could chew up any amount of log space, run for 18 hours, or cause unwanted contention. Since it runs at an off-hours time, we would most likely be asleep and not be able to respond quickly to a problem when it arises. With the fear of these situations instilled, let’s consider some ways to prevent them before they can manifest themselves.
在此存储的过程中没有设置限制。 结果,它可能占用任何数量的日志空间,运行18小时或引起不必要的争用。 由于它是在下班时间运行的,因此我们很可能会睡着,并且在出现问题时无法快速做出响应。 在担心这些情况的情况下,让我们考虑一些防止它们出现的方法。
日志空间消耗过多 (Excessive log space consumption)
The first situation to address is log usage. Index operations are logged and can generate significant log file growth that could potentially fill up a log drive if left unchecked. Since we iterate through indexes one-by-one, we have the luxury of taking a moment before each one to check on disk space and verify that we are good to go. By checking available disk space as well as the size of the index to be operated on, we can ensure that we leave exactly as much space as we want behind.
要解决的第一种情况是日志使用情况。 索引操作已记录下来,并且会产生显着的日志文件增长,如果不检查,可能会填满日志驱动器。 由于我们一次又一次地遍历索引,因此可以在每个索引之前花一点时间检查磁盘空间并验证我们是否行得通。 通过检查可用的磁盘空间以及要操作的索引的大小,我们可以确保我们留出了我们想要的空间。
Introduced in SQL Server 2008R2 SP 1 was the dynamic management view sys.dm_os_volue_stats, which takes parameters for a database ID and file ID, returning the total and available disk space on the respective drive for that file. We can use that here in order to check how much space is remaining prior to an index operation by evaluating the following TSQL:
SQL Server 2008R2 SP 1中引入了动态管理视图sys.dm_os_volue_stats ,该视图采用数据库ID和文件ID的参数,并返回该文件在相应驱动器上的总磁盘空间和可用磁盘空间。 我们可以在此处使用它,以便通过评估以下TSQL来检查索引操作之前剩余的空间:
SELECT
CAST(CAST(available_bytes AS DECIMAL) / (1024 * 1024 * 1024) AS BIGINT) AS gb_free
FROM sys.master_files AS f
CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id)
WHERE f.database_id = DB_ID()
AND f.type_desc = 'LOG';
This returns the free space on the log drive, in gigabytes. Our next step is to add index size to the stored procedure above and compare the two in order to determine if enough space exists to support an operation. For this example, we’ll assume that we must maintain 100GB free on the log drive at all times, therefore any index operation that would bring free space below that amount should not occur. The resulting stored procedure, shown below, shows how we can guard against filling up the log drive while rebuilding indexes:
这将以GB为单位返回日志驱动器上的可用空间。 我们的下一步是将索引大小添加到上面的存储过程中,并对两者进行比较,以确定是否存在足够的空间来支持某个操作。 对于此示例,我们假设必须始终在日志驱动器上保持100GB的可用空间,因此不会发生将可用空间降至该数量以下的任何索引操作。 生成的存储过程(如下所示)显示了我们如何在重建索引时防止填满日志驱动器:
IF EXISTS (SELECT * FROM sys.procedures WHERE procedures.name = 'index_maintenance_daily')
BEGIN
DROP PROCEDURE dbo.index_maintenance_daily;
END
GO
CREATE PROCEDURE dbo.index_maintenance_daily
@reorganization_percentage TINYINT = 10,
@rebuild_percentage TINYINT = 35,
@log_space_free_required_gb INT = 100
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql_command NVARCHAR(MAX) = '';
DECLARE @parameter_list NVARCHAR(MAX) = '@reorganization_percentage TINYINT, @rebuild_percentage TINYINT'
DECLARE @database_list TABLE
(database_name NVARCHAR(MAX) NOT NULL);
INSERT INTO @database_list
(database_name)
SELECT
name
FROM sys.databases
WHERE databases.name NOT IN ('msdb', 'master', 'TempDB', 'model');
CREATE TABLE #index_maintenance
( database_name NVARCHAR(MAX),
schema_name NVARCHAR(MAX),
object_name NVARCHAR(MAX),
index_name NVARCHAR(MAX),
index_type_desc NVARCHAR(MAX),
avg_fragmentation_in_percent FLOAT,
index_operation NVARCHAR(MAX),
size_in_GB BIGINT);
SELECT @sql_command = @sql_command + '
USE [' + database_name + ']
INSERT INTO #index_maintenance
(database_name, schema_name, object_name, index_name, index_type_desc, avg_fragmentation_in_percent, index_operation,size_in_GB)
SELECT
CAST(SD.name AS NVARCHAR(MAX)) AS database_name,
CAST(SS.name AS NVARCHAR(MAX)) AS schema_name,
CAST(SO.name AS NVARCHAR(MAX)) AS object_name,
CAST(SI.name AS NVARCHAR(MAX)) AS index_name,
IPS.index_type_desc,
IPS.avg_fragmentation_in_percent, -- Be sure to filter as much as possible...this can return a lot of data if you dont filter by database and table.
CAST(CASE
WHEN IPS.avg_fragmentation_in_percent >= @rebuild_percentage THEN ''REBUILD''
WHEN IPS.avg_fragmentation_in_percent >= @reorganization_percentage THEN ''REORGANIZE''
END AS NVARCHAR(MAX)) AS index_operation,
(page_count * 8 / 1024 / 1024) AS size_in_GB
FROM sys.dm_db_index_physical_stats(NULL, NULL, NULL, NULL , NULL) IPS
INNER JOIN sys.databases SD
ON SD.database_id = IPS.database_id
INNER JOIN sys.indexes SI
ON SI.index_id = IPS.index_id
INNER JOIN sys.objects SO
ON SO.object_id = SI.object_id
AND IPS.object_id = SO.object_id
INNER JOIN sys.schemas SS
ON SS.schema_id = SO.schema_id
WHERE alloc_unit_type_desc = ''IN_ROW_DATA''
AND index_level = 0
AND SD.name = ''' + database_name + '''
AND IPS.avg_fragmentation_in_percent >= @reorganization_percentage
AND SI.name IS NOT NULL -- Only review index, not heap data.
AND SO.is_ms_shipped = 0 -- Do not perform maintenance on system objects
ORDER BY SD.name ASC;'
FROM @database_list
WHERE database_name IN (SELECT name FROM sys.databases);
EXEC sp_executesql @sql_command, @parameter_list, @reorganization_percentage, @rebuild_percentage;
SELECT @sql_command = 'DECLARE @log_drive_space_free_gb INT;
DECLARE @error_message VARCHAR(MAX);';
SELECT @sql_command = @sql_command +
'
USE [' + database_name + '];
SELECT
@log_drive_space_free_gb = CAST(CAST(available_bytes AS DECIMAL) / (1024 * 1024 * 1024) AS BIGINT)
FROM sys.master_files AS f
CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id)
WHERE f.database_id = DB_ID()
AND f.type_desc = ''LOG'';
SELECT @error_message = ''Not enough space available to process maintenance on ' + index_name + ' while executing the nightly index maintenance job. '' + CAST(@log_drive_space_free_gb AS VARCHAR(MAX)) + ''GB are currently free.''
IF @log_drive_space_free_gb - ' + CAST(size_in_GB AS VARCHAR(MAX)) + ' < @log_space_free_required_gb
BEGIN
RAISERROR(@error_message, 16, 1);
RETURN;
END
ALTER INDEX [' + index_name + '] ON [' + schema_name + '].[' + object_name + ']
' + index_operation + ';'
FROM #index_maintenance;
SELECT @parameter_list = '@log_space_free_required_gb INT'
SELECT * FROM #index_maintenance
ORDER BY avg_fragmentation_in_percent;
EXEC sp_executesql @sql_command, @parameter_list, @log_space_free_required_gb;
DROP TABLE #index_maintenance;
END
The updated version of this stored procedure checks the size of the index to be rebuilt, the amount of free space on the log drive, and our required free space. With that information, it determines if we should proceed or immediately exit the stored procedure without taking actions on any further indexes. If this happens, we receive an error message like this:
此存储过程的更新版本检查要重建的索引的大小,日志驱动器上的可用空间量以及所需的可用空间。 有了这些信息,它将确定我们应该继续还是立即退出存储过程,而不对任何其他索引采取任何措施。 如果发生这种情况,我们会收到如下错误消息:
Msg 50000, Level 16, State 1, Line 126
Not enough space available to process maintenance on PK_ProductCostHistory_ProductID_StartDate while executing the nightly index maintenance job. 97GB are currently free.
讯息50000,第16级,状态1,第126行
执行夜间索引维护作业时,没有足够的空间来处理PK_ProductCostHistory_ProductID_StartDate上的维护。 97GB当前是免费的。
More information could be added to the error message to assist in troubleshooting, or to address specific needs in your environment. The key result was that the stored procedure immediately threw an error and exited, halting any further log growth from it and preventing an unpleasant late night wake-up-call.
可以将更多信息添加到错误消息中,以帮助进行故障排除或解决您环境中的特定需求。 关键结果是该存储过程立即引发错误并退出,从而阻止了该日志中任何进一步的日志增长,并防止了令人不快的深夜唤醒呼叫。
工作时间长 (Long job run times)
The timing of maintenance jobs is important. We want them to run during off-hours times when usage from production workloads and other maintenance procedures are minimal. We also want those jobs to end before our busier times begin. For this example, let’s assume that we want a particular job to start at 1am and be finished by no later than 7am. There are two ways to approach this challenge:
维护工作的时间安排很重要。 我们希望它们在下班时间运行,此时生产工作负载和其他维护程序的使用量最少。 我们还希望这些工作在我们的繁忙时期开始之前就结束。 对于此示例,假设我们希望特定的工作在凌晨1点开始并且不迟于上午7点完成。 有两种方法可以应对这一挑战:
- Proactively: Add TSQL to the maintenance proc, similar to above, that will end it if a certain time is exceeded.主动 :将TSQL添加到维护过程中,类似于以上内容,如果超过一定时间,它将结束该过程。
- Reactively: Add a parallel job that actively monitors maintenance jobs, ending them if they run too long (or if any other unacceptable conditions arise).React性 :添加并行作业以主动监视维护作业,如果维护作业运行时间过长(或出现任何其他不可接受的情况),则将其终止。
We can easily make a case for both options. The proactive solution gracefully ends the job when we get past 7am, but it is not infallible. If a specific index took an unusually long time, then the job would continue until that index has completed. Only then would the job end, preventing the remaining indexes from being rebuilt.
我们可以轻松地为这两种选择辩护。 当我们凌晨7点过后,主动解决方案会优雅地结束工作,但这并不是万无一失的。 如果特定索引花费了异常长的时间,则作业将继续进行直到该索引完成。 只有这样,作业才能结束,从而阻止了其余索引的重建。
The active monitoring solution can stop a job at any time, regardless of its progress. This job would be something to maintain over time and ensure it works correctly—if it were to accidentally end an important job at the wrong time, the cost of that mistake could be high. Also, jobs stopped by this process would need to be tolerant of ending at any point. An archiving or ETL process that is interrupted in the middle could inadvertently leave inconsistent data behind, unless it were designed to be robust and prevent that situation from arising.
主动监视解决方案可以随时停止作业,而不管其进度如何。 这项工作将随着时间的推移而得以维护,并确保其正常工作—如果要在错误的时间意外结束一项重要的工作,则该错误的代价可能会很高。 同样,在此过程中停止的作业将需要容忍在任何时候结束。 在中间中断的归档或ETL流程可能会无意间将不一致的数据留下,除非将其设计为健壮的并防止这种情况发生。
The proactive solution is similar to our log growth TSQL in the last example. Prior to each index operation, we want to check either the job runtime or the current time and take action based on it. For this example, we’ll do both, checking that the time is not between 7am and 1am, and that the stored procedure itself has not run for more than 6 hours.
主动解决方案与上一个示例中的日志增长TSQL相似。 在执行每个索引操作之前,我们要检查作业运行时或当前时间,并据此采取措施。 在此示例中,我们将同时检查时间是否在上午7点至凌晨1点之间,并且存储过程本身的运行时间不超过6小时。
The following TSQL statement checks the current time and will return from the current proc if it is no longer within the allotted maintenance period:
下面的TSQL语句检查当前时间,如果不在指定的维护期内,它将从当前proc返回:
DECLARE @current_time TIME = CAST(CURRENT_TIMESTAMP AS TIME);
IF @current_time > '07:00:00' OR @current_time < '01:00:00'
BEGIN
PRINT 'This job is running outside of the allotted maintenance period (1:00am-7:00am). Current time: ' + CAST(@current_time AS VARCHAR(MAX))
RETURN
END
Variables can be added to take the place of the times so that they can be passed in as parameters from a job. Currently it is almost 7pm local time, so running this TSQL will provide the expected output:
可以添加变量来代替时间,以便可以将它们作为作业中的参数传递。 当前本地时间将近晚上7点,因此运行此TSQL将提供预期的输出:
This job is running outside of the allotted maintenance period (1:00am-7:00am). Current time: 18:59:08.3230000
该作业在指定的维护时段(1:00 am-7:00am)之外运行。 当前时间:18:59:08.3230000
Alternatively, had it been 3am, running the TSQL above would have resulted in no output as we would be within the bounds set by our maintenance/business rules.
另外,如果是凌晨3点,则运行上面的TSQL将导致没有输出,因为我们将在我们的维护/业务规则所设定的范围内。
Checking the job’s runtime is also relatively simple, and can be done with an artificial timestamp. We’ll check and verify that the current time is not more than six hours greater than the job’s start time as follows:
检查作业的运行时间也相对简单,可以使用人工时间戳进行检查。 我们将检查并确认当前时间不比作业的开始时间多六小时,如下所示:
DECLARE @job_start_time DATETIME = CURRENT_TIMESTAMP;
--...Insert maintenance TSQL here
DECLARE @current_time DATETIME = CURRENT_TIMESTAMP;
IF DATEDIFF(HOUR, @job_start_time, @current_time) >= 6
BEGIN
PRINT 'This job has exceeded the maximum runtime allowed (6 hours). Start time: ' + CAST(@job_start_time AS VARCHAR(MAX)) + ' Current Time: ' + CAST(@current_time AS VARCHAR(MAX));
RETURN
END
The start time is logged as soon as the proc begins. Whenever we want to check the current runtime, we can do so with the TSQL above. In the event that over six hours has passed, the DATEDIFF check will return true and a message will be printed and the proc will end.
proc开始后,将记录开始时间。 每当我们想要检查当前运行时时,都可以使用上面的TSQL进行检查。 如果超过六个小时,则DATEDIFF检查将返回true,并且将打印一条消息,并且过程将结束。
RAISERROR can be used if you’d like your job to throw an error message to the error logs (and fail noticeably). Alternatively, if you have a custom error log for detailed job information, the messages and details above can be sent there as well. RAISERROR alternatives for the hour check scenario above would look like this:
如果您希望您的工作向错误日志中抛出错误消息(并且明显失败),则可以使用RAISERROR。 另外,如果您有一个自定义错误日志以获取详细的作业信息,则上面的消息和详细信息也可以发送到该日志。 以上小时检查方案的RAISERROR替代方案如下所示:
DECLARE @current_time TIME = CAST(CURRENT_TIMESTAMP AS TIME);
DECLARE @message VARCHAR(MAX);
IF @current_time > '07:00:00' OR @current_time < '01:00:00'
BEGIN
SELECT @message = 'This job is running outside of the allotted maintenance period (1:00am-7:00am). Current time: ' + CAST(@current_time AS VARCHAR(MAX));
RAISERROR(@message, 16, 1);
RETURN;
END
Similarly, the duration check can be written to raise an error as well:
同样,持续时间检查也可以编写为引发错误:
DECLARE @job_start_time DATETIME = CURRENT_TIMESTAMP;
DECLARE @message VARCHAR(MAX);
--...Insert maintenance TSQL here
DECLARE @current_time DATETIME = CURRENT_TIMESTAMP;
IF DATEDIFF(HOUR, @job_start_time, @current_time) >= 6
BEGIN
SELECT @message = 'This job has exceeded the maximum runtime allowed (6 hours). Start time: ' + CAST(@job_start_time AS VARCHAR(MAX)) + ' Current Time: ' + CAST(@current_time AS VARCHAR(MAX));
RAISERROR(@message, 16, 1);
RETURN
END
The resulting error would appear like this:
产生的错误如下所示:
Msg 50000, Level 16, State 1, Line 250
This job has exceeded the maximum runtime allowed (6 hours). Start time: Jan 13 2016 7:14PM Current Time: Jan 13 2016 7:14PM
讯息50000,第16级,状态1,第250行
该作业已超过允许的最大运行时间(6小时)。 开始时间:2016年1月13日7:14 PM当前时间:2016年1月13日7:14 PM
An alternate (albeit more complex) way to acquire similar information would be to query msdb for job data, assuming your TSQL is running within a job. This information is stored in a pair of system tables that can be joined together:
假设您的TSQL在作业中运行,则获取类似信息的另一种方法(尽管更为复杂)是查询msdb以获取作业数据。 此信息存储在一对可以结合在一起的系统表中:
SELECT
sysjobs.name,
sysjobactivity.*
FROM msdb.dbo.sysjobactivity
INNER JOIN msdb.dbo.sysjobs
ON sysjobactivity.job_id = sysjobs.job_id
This returns run history on all jobs, a sample of which looks like this:
这将返回所有作业的运行历史记录,其示例如下所示:

From this data, we can check for the current job by name, the most current instance of which has a start_execution_date populated, but no stop_execution_date. Manipulating this data is a bit more complex than checking time or duration as we demonstrated previously, but could be desirable when runtimes are sporadic, or business rules vary with each separate run.
根据这些数据,我们可以按名称检查当前作业,该作业的最新实例具有填充的start_execution_date ,但没有stop_execution_date 。 像我们之前演示的那样,处理这些数据要比检查时间或持续时间复杂一点,但是当运行时是零散的或者业务规则随每次单独运行而变化时,则可能需要这样做。
These options can both easily be inserted into the index maintenance stored procedure shown earlier. The result will have built-in protection against log growth and unacceptable runtimes:
这些选项都可以轻松插入前面显示的索引维护存储过程。 结果将具有针对日志增长和不可接受的运行时的内置保护:
IF EXISTS (SELECT * FROM sys.procedures WHERE procedures.name = 'index_maintenance_daily')
BEGIN
DROP PROCEDURE dbo.index_maintenance_daily;
END
GO
CREATE PROCEDURE dbo.index_maintenance_daily
@reorganization_percentage TINYINT = 10,
@rebuild_percentage TINYINT = 35,
@log_space_free_required_gb INT = 100
AS
BEGIN
SET NOCOUNT ON;
DECLARE @job_start_time DATETIME = CURRENT_TIMESTAMP;
DECLARE @sql_command NVARCHAR(MAX) = '';
DECLARE @parameter_list NVARCHAR(MAX) = '@reorganization_percentage TINYINT, @rebuild_percentage TINYINT'
DECLARE @database_list TABLE
(database_name NVARCHAR(MAX) NOT NULL);
INSERT INTO @database_list
(database_name)
SELECT
name
FROM sys.databases
WHERE databases.name NOT IN ('msdb', 'master', 'TempDB', 'model');
CREATE TABLE #index_maintenance
( database_name NVARCHAR(MAX),
schema_name NVARCHAR(MAX),
object_name NVARCHAR(MAX),
index_name NVARCHAR(MAX),
index_type_desc NVARCHAR(MAX),
avg_fragmentation_in_percent FLOAT,
index_operation NVARCHAR(MAX),
size_in_GB BIGINT);
SELECT @sql_command = @sql_command + '
USE [' + database_name + ']
INSERT INTO #index_maintenance
(database_name, schema_name, object_name, index_name, index_type_desc, avg_fragmentation_in_percent, index_operation,size_in_GB)
SELECT
CAST(SD.name AS NVARCHAR(MAX)) AS database_name,
CAST(SS.name AS NVARCHAR(MAX)) AS schema_name,
CAST(SO.name AS NVARCHAR(MAX)) AS object_name,
CAST(SI.name AS NVARCHAR(MAX)) AS index_name,
IPS.index_type_desc,
IPS.avg_fragmentation_in_percent, -- Be sure to filter as much as possible...this can return a lot of data if you dont filter by database and table.
CAST(CASE
WHEN IPS.avg_fragmentation_in_percent >= @rebuild_percentage THEN ''REBUILD''
WHEN IPS.avg_fragmentation_in_percent >= @reorganization_percentage THEN ''REORGANIZE''
END AS NVARCHAR(MAX)) AS index_operation,
(page_count * 8 / 1024 / 1024) AS size_in_GB
FROM sys.dm_db_index_physical_stats(NULL, NULL, NULL, NULL , NULL) IPS
INNER JOIN sys.databases SD
ON SD.database_id = IPS.database_id
INNER JOIN sys.indexes SI
ON SI.index_id = IPS.index_id
INNER JOIN sys.objects SO
ON SO.object_id = SI.object_id
AND IPS.object_id = SO.object_id
INNER JOIN sys.schemas SS
ON SS.schema_id = SO.schema_id
WHERE alloc_unit_type_desc = ''IN_ROW_DATA''
AND index_level = 0
AND SD.name = ''' + database_name + '''
AND IPS.avg_fragmentation_in_percent >= @reorganization_percentage
AND SI.name IS NOT NULL -- Only review index, not heap data.
AND SO.is_ms_shipped = 0 -- Do not perform maintenance on system objects
ORDER BY SD.name ASC;'
FROM @database_list
WHERE database_name IN (SELECT name FROM sys.databases);
EXEC sp_executesql @sql_command, @parameter_list, @reorganization_percentage, @rebuild_percentage;
SELECT @sql_command = 'DECLARE @log_drive_space_free_gb INT;
DECLARE @error_message VARCHAR(MAX);
DECLARE @current_time TIME;';
SELECT @sql_command = @sql_command +
'
USE [' + database_name + '];
SELECT
@log_drive_space_free_gb = CAST(CAST(available_bytes AS DECIMAL) / (1024 * 1024 * 1024) AS BIGINT)
FROM sys.master_files AS f
CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id)
WHERE f.database_id = DB_ID()
AND f.type_desc = ''LOG'';
SELECT @error_message = ''Not enough space available to process maintenance on ' + index_name + ' while executing the nightly index maintenance job. '' + CAST(@log_drive_space_free_gb AS VARCHAR(MAX)) + ''GB are currently free.''
IF @log_drive_space_free_gb - ' + CAST(size_in_GB AS VARCHAR(MAX)) + ' < @log_space_free_required_gb
BEGIN
RAISERROR(@error_message, 16, 1);
RETURN;
END
IF DATEDIFF(HOUR, ''' + CAST(@job_start_time AS VARCHAR(MAX)) + ''', @current_time) >= 6
BEGIN
SELECT @error_message = ''This job has exceeded the maximum runtime allowed (6 hours). Start time: ''''' + CAST(@job_start_time AS VARCHAR(MAX)) + ''''' Current Time: '' + CAST(@current_time AS VARCHAR(MAX));
RAISERROR(@error_message, 16, 1);
RETURN
END
SELECT @current_time = CAST(CURRENT_TIMESTAMP AS TIME);
IF @current_time > ''07:00:00'' OR @current_time < ''01:00:00''
BEGIN
SELECT @error_message = ''This job is running outside of the allotted maintenance period (1:00am-7:00am). Current time: '' + CAST(@current_time AS VARCHAR(MAX));
RAISERROR(@error_message, 16, 1);
RETURN
END
ALTER INDEX [' + index_name + '] ON [' + schema_name + '].[' + object_name + ']
' + index_operation + ';'
FROM #index_maintenance;
SELECT @parameter_list = '@log_space_free_required_gb INT'
SELECT * FROM #index_maintenance
ORDER BY avg_fragmentation_in_percent;
EXEC sp_executesql @sql_command, @parameter_list, @log_space_free_required_gb;
DROP TABLE #index_maintenance;
END
Prior to each index rebuild/reorganize operation, after free log space is verified, the duration of the stored procedure is checked, and then the time of day that it is running. These verification processes take a trivial amount of time to run, and provide a great deal of insurance against resource-intensive operations running into critical production operation hours.
在每个索引重建/重组操作之前,在验证了可用日志空间之后,将检查存储过程的持续时间,然后检查存储过程的运行时间。 这些验证过程需要花费很短的时间才能运行,并且为运行在关键生产操作时间内的资源密集型操作提供了很多保障。
An alternative to the built-in approach is the parallel job, which runs periodically and checks that our maintenance jobs are operating within parameters. If any unacceptable situation is detected, then the responsible job can be forcibly ended. This is very useful if the offending job is stuck in a large operation and unable to reach one of the verification checkpoints that we created in our previous examples. To illustrate this, I have created a job that runs the index maintenance proc above:
内置方法的一种替代方法是并行作业,该作业定期运行并检查我们的维护作业是否在参数范围内运行。 如果检测到任何不可接受的情况,则可以强制终止负责的工作。 如果有问题的作业被卡在大型操作中而无法到达我们在前面的示例中创建的验证检查点之一,这将非常有用。 为了说明这一点,我创建了一个运行上述索引维护过程的作业:
From here, we will build the TSQL for a verification job that will run every 30 seconds and kill the index maintenance job if it is running and any unacceptable conditions (such as low log space or a long runtime) exist. The following stored procedure will encapsulate all of the logic presented above:
从这里开始,我们将为验证作业构建TSQL,该验证作业每30秒运行一次,如果索引维护作业正在运行并且存在任何不可接受的条件(例如,日志空间不足或运行时间较长),则将其终止。 以下存储过程将封装上面介绍的所有逻辑:
IF EXISTS (SELECT * FROM sys.procedures WHERE procedures.name = 'job_verification')
BEGIN
DROP PROCEDURE dbo.job_verification;
END
GO
CREATE PROCEDURE dbo.job_verification
@log_space_free_required_gb INT = 100,
@job_to_check VARCHAR(MAX) = 'Index Maintenance!'
AS
BEGIN
SET NOCOUNT ON;
DECLARE @log_drive_space_free_gb INT;
DECLARE @job_start_time DATETIME;
DECLARE @error_message VARCHAR(MAX);
DECLARE @current_time TIME;
DECLARE @sql_command VARCHAR(MAX);
DECLARE @stop_job BIT = 0; -- This will be switched to 1 if any job-ending criteria is met
SELECT -- Get free log space
@log_drive_space_free_gb = CAST(CAST(available_bytes AS DECIMAL) / (1024 * 1024 * 1024) AS BIGINT)
FROM sys.master_files AS f
CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id)
WHERE f.database_id = DB_ID()
AND f.type_desc = 'LOG';
-- If current free log space is below our allowed threshold, proceed to check if maintenance job is running
IF @log_drive_space_free_gb < @log_space_free_required_gb
BEGIN
SELECT @error_message = 'Not enough space available to process maintenance while executing the nightly index maintenance job. ' + CAST(@log_drive_space_free_gb AS VARCHAR(MAX)) + 'GB are currently free.';
SELECT @stop_job = 1;
END
-- Get the start time for the index maintenance job, if it is running.
SELECT
@job_start_time = sysjobactivity.start_execution_date
FROM msdb.dbo.sysjobs_view
INNER JOIN msdb.dbo.sysjobactivity
ON sysjobs_view.job_id = sysjobactivity.job_id
WHERE sysjobs_view.name = @job_to_check
AND sysjobactivity.run_Requested_date IS NOT NULL
AND sysjobactivity.stop_execution_date IS NULL
AND sysjobactivity.session_id = (SELECT MAX(session_id) FROM msdb.dbo.sysjobs_view INNER JOIN msdb.dbo.sysjobactivity ON sysjobs_view.job_id = sysjobactivity.job_id WHERE sysjobs_view.name = @job_to_check)
-- If the job has been running for more than six hours, then set the error message and flag it to be ended.
IF (DATEDIFF(HOUR, @job_start_time, @current_time) >= 6) AND @job_start_time IS NOT NULL
BEGIN
SELECT @error_message = 'This job has exceeded the maximum runtime allowed (6 hours). Start time: ' + CAST(@job_start_time AS VARCHAR(MAX)) + ' Current Time: ' + CAST(CURRENT_TIMESTAMP AS VARCHAR(MAX));
SELECT @stop_job = 1;
END
SELECT @current_time = CAST(CURRENT_TIMESTAMP AS TIME);
IF @current_time > '07:00:00' OR @current_time < '01:00:00'
BEGIN
SELECT @error_message = 'This job is running outside of the allotted maintenance period (1:00am-7:00am). Current time: ' + CAST(@current_time AS VARCHAR(MAX));
SELECT @stop_job = 1;
END
-- Verify that the maintenance job is running first, before attempting to stop it (If a condition above was met first).
IF @stop_job = 1 AND EXISTS (
SELECT
*
FROM msdb.dbo.sysjobs_view
INNER JOIN msdb.dbo.sysjobactivity
ON sysjobs_view.job_id = sysjobactivity.job_id
WHERE sysjobs_view.name = @job_to_check
AND sysjobactivity.run_Requested_date IS NOT NULL
AND sysjobactivity.stop_execution_date IS NULL
AND sysjobactivity.session_id = (SELECT MAX(session_id) FROM msdb.dbo.sysjobs_view INNER JOIN msdb.dbo.sysjobactivity ON sysjobs_view.job_id = sysjobactivity.job_id WHERE sysjobs_view.name = @job_to_check))
BEGIN -- If job is running, then end it immediately and raise an error with details.
EXEC msdb.dbo.sp_stop_job @job_name = @job_to_check;
RAISERROR(@error_message, 16, 1);
RETURN;
END
END
Next, we’ll create a job that runs every 30 seconds and calls the stored procedure above:
接下来,我们将创建一个每30秒运行一次的作业,并调用上面的存储过程:
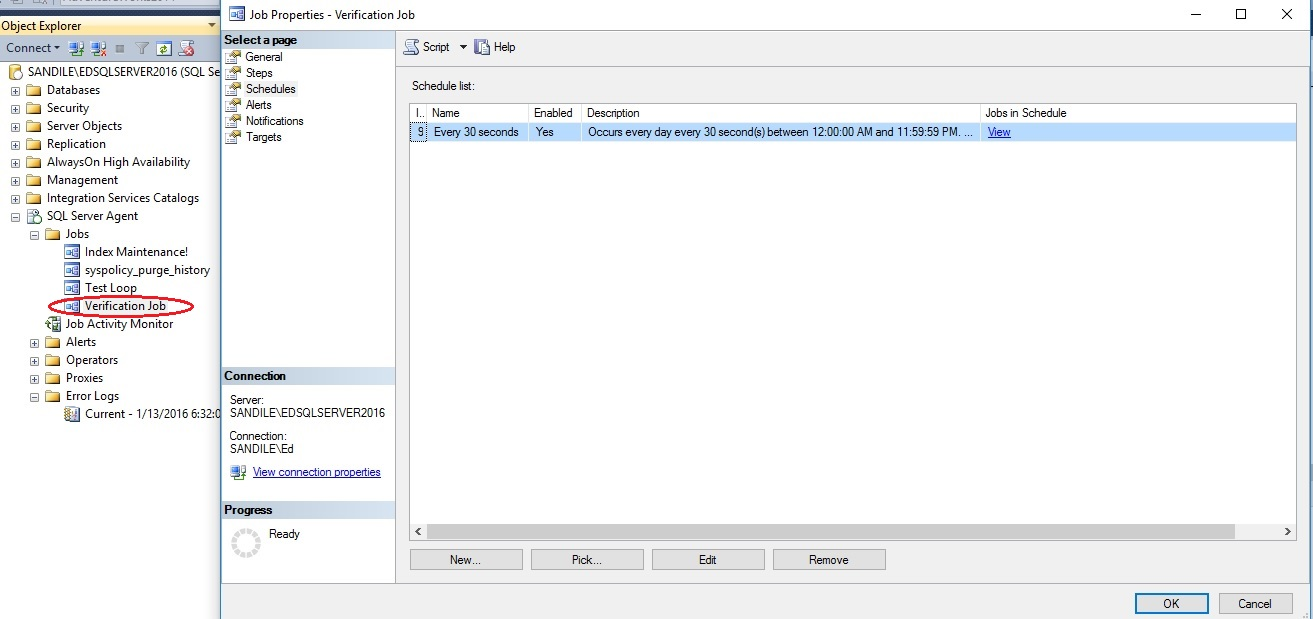
A look at the job history will show the first handful of successful job runs:
查看工作历史记录将显示成功完成的第一批工作:
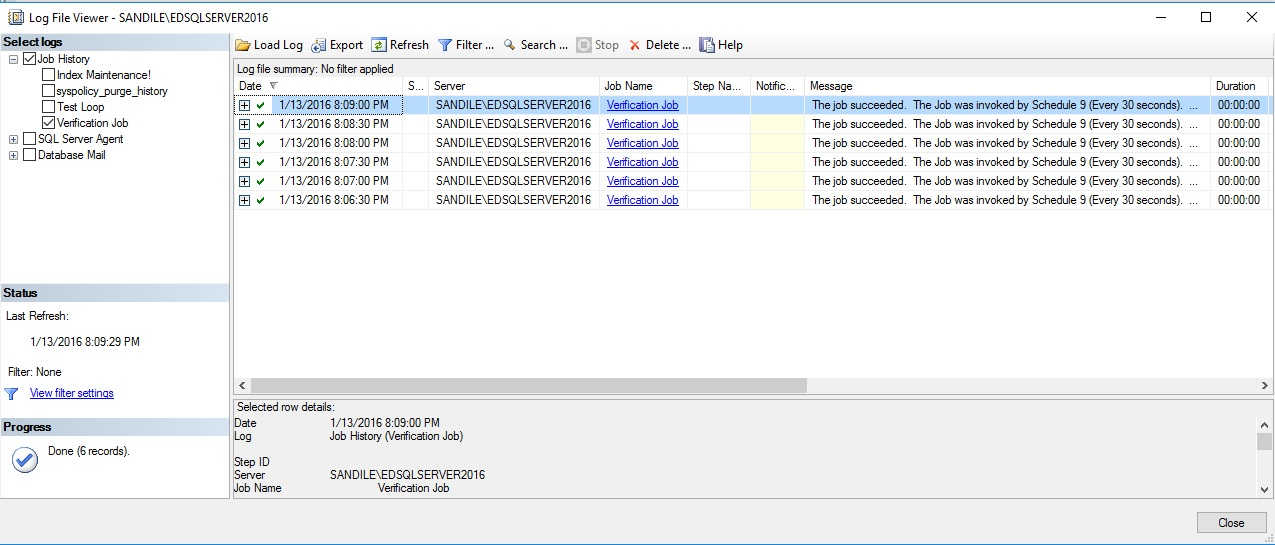
As expected, this verification process doesn’t even require a second to complete. As it is only verifying disk and job metadata and is able to do so extremely quickly and efficiently. Let’s say I were to start my index maintenance job and check back in 30 seconds:
不出所料,此验证过程甚至不需要一秒钟即可完成。 由于它仅验证磁盘和作业元数据,因此能够极其快速和高效地进行验证。 假设我要开始索引维护工作,并在30秒内返回:
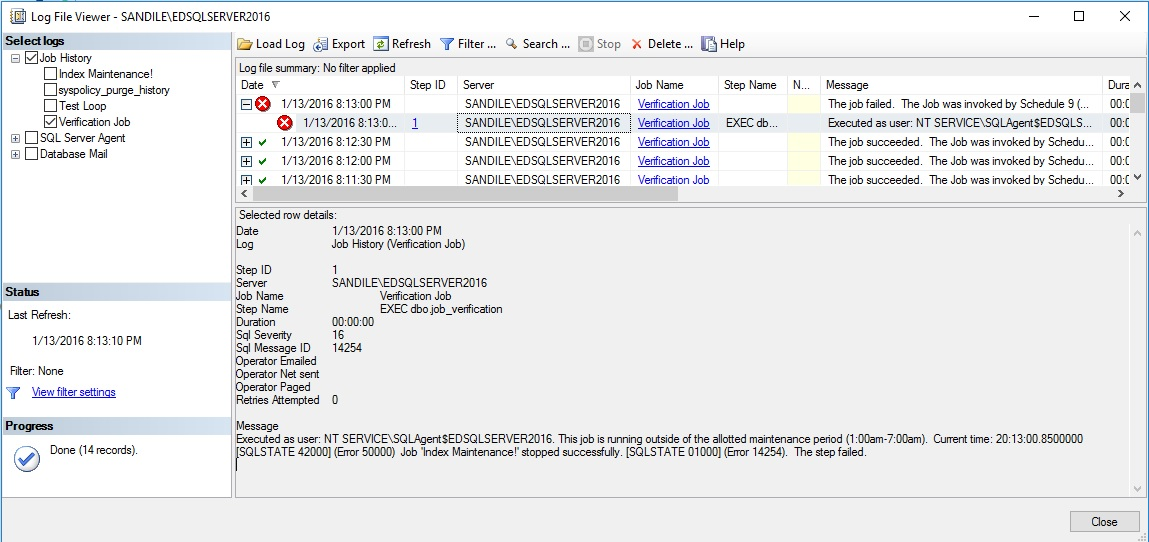
The verification job sees that the index maintenance job should not be running and uses msdb.dbo.sp_stop_job to immediately end it. In addition, the error message thrown within the verification job is visible from within the job history, reminding us that the job is running outside of the allotted maintenance period.
验证作业发现索引维护作业不应运行,并使用msdb.dbo.sp_stop_job立即结束它。 此外,从作业历史记录中可以看到在验证作业中引发的错误消息,提醒我们该作业在指定的维护期限之外运行。
This technique can be expanded as far as your imagination takes you. A surrogate job such as this can be used to monitor any condition in SQL Server and take the appropriate action immediately. In addition to simply ending jobs or writing errors to the SQL Server error log, we could also take other actions such as:
这种技术可以扩展到您的想象力。 诸如此类的替代作业可用于监视SQL Server中的任何条件并立即采取适当的措施。 除了简单地结束作业或将错误写入SQL Server错误日志之外,我们还可以采取其他措施,例如:
-
- The email target could vary depending on the error. For example, a disk space error could also email the SAN administrator, while a TSQL error would only email the responsible DBA. 电子邮件目标可能会因错误而有所不同。 例如,磁盘空间错误也可以通过电子邮件发送给SAN管理员,而TSQL错误仅通过电子邮件发送给负责的DBA。
- Disable a frequently running job, alerting a DBA that it will require attention as soon as possible. 禁用经常运行的作业,警告DBA,它将尽快引起注意。
- Perform a log backup and/or file shrink, if conditions exist where these operations may be necessary. 如果存在可能需要执行这些操作的条件,请执行日志备份和/或文件收缩。
- Write additional data to the Windows Application Event Log. 将其他数据写入Windows应用程序事件日志。
- Execute another stored procedure or job that assists in remediating the situation encountered. 执行另一个有助于补救所遇到情况的存储过程或作业。
The flexibility introduced here is immense and can prevent critical production problems from ever manifesting themselves. If you decide to try it out, be sure to get creative and get the verification process to manage as many of the manual tasks that you’re typically stuck with when these situations arise. Use this not only to prevent disasters, but also to simplify your job and mitigate error-prone manual processes.
这里引入的灵活性是巨大的,可以防止严重的生产问题显现出来。 如果您决定尝试一下,请务必发挥创意并获得验证过程,以管理出现这些情况时通常遇到的许多手动任务。 使用此功能不仅可以预防灾难,还可以简化您的工作并减轻容易出错的手动流程。
An email at 9am letting you know of unexpected index maintenance problems overnight is 100% preferable over a 2:00am wake-up call when a disk runs out of space and SQL Server is unable to write to its transaction log files!
如果磁盘空间不足并且SQL Server无法写入其事务日志文件,那么在凌晨9点通过电子邮件通知您过夜的意外索引维护问题比在凌晨2:00进行唤醒时要高出100%。
备份磁盘空间 (Backup disk space)
Backups are by nature going to result in disk space being eaten up whenever they run. Most of the backup routines we build involve full backups (once or maybe twice a week), differential backups (daily on non-full backup days), and/or transaction log backups, which run frequently and backup changes since the last log backup. Regardless of the specifics in your environment, there are a few generalizations that we can make:
备份天生就会导致磁盘空间在运行时被耗尽。 我们构建的大多数备份例程都涉及完整备份(每周一次或可能两次),差异备份(每天在非完整备份日)和/或事务日志备份,这些备份经常运行并自上次日志备份以来进行备份更改。 无论您的环境中有什么具体细节,我们都可以做一些概括:
- Data will get larger over time, and hence backups will increase in size. 数据会随着时间的推移而变大,因此备份的大小也会增加。
- Anything that causes significant data change will also cause transaction log backup sizes to increase. 任何会导致重大数据更改的事物都会导致事务日志备份大小增加。
- If a backup target is shared with other applications, then they could potentially interfere or use up space. 如果备份目标与其他应用程序共享,则它们可能会干扰或耗尽空间。
- The more time that has passed since the last differential/transaction log backup, the larger they will be and the longer they will take. 自上次差异/事务日志备份以来经过的时间越多,它们将越长且花费的时间越长。
- If cleanup of the target backup drive does not occur regularly, it will eventually fill up, causing backup failures. 如果不定期清理目标备份驱动器,则最终该驱动器将填满,从而导致备份失败。
Each of these situations lends themselves to possible solutions, such as not sharing the backup drive with other programs, or testing log growth on release scripts prior to the final production deployment. While we can mitigate risk, the potential always exists for drives to fill up. If they do, then all further backups will fail, leaving holes in the backup record that could prove detrimental in the event of a disaster or backup data request.
这些情况中的每一种都适合可能的解决方案,例如不与其他程序共享备份驱动器,或者在最终生产部署之前测试发布脚本上的日志增长。 虽然我们可以减轻风险,但驱动器总是有潜力被填满。 如果这样做,那么所有进一步的备份都将失败,从而在备份记录中留下漏洞,如果发生灾难或备份数据请求,这可能证明是有害的。
As with log space, we can monitor backup size and usage in order to make intelligent decisions about how a job should proceed. This can be managed from within a backup stored procedure using xp_cmdshell, if usage of that system stored procedure is tolerated. Alternatively, Powershell can be used to monitor drive space as well. An alternative solution that I am particularly fond of is to create a tiny unused or minimally used database on the server you’re backing up and put the data and log files on the backup drive. This allows you to use dm_os_volume_stats to monitor disk usage directly within the backup process without any security compromises.
与日志空间一样,我们可以监视备份的大小和使用情况,以便就如何进行作业做出明智的决定。 如果允许使用该系统存储过程,则可以使用xp_cmdshell在备份存储过程中进行管理。 另外,Powershell还可用于监视驱动器空间。 我特别喜欢的替代解决方案是在要备份的服务器上创建一个很小的未使用或使用最少的数据库,并将数据和日志文件放在备份驱动器上。 这样,您就可以使用dm_os_volume_stats直接在备份过程中监视磁盘使用情况,而不会影响任何安全性。
For an example of this solution, we will use my local C drive as the backup drive and the F drive as the target for all other database data files. Since our data files are on the F drive, we can easily view the space available like this:
对于此解决方案的示例,我们将使用本地C驱动器作为备份驱动器,并使用F驱动器作为所有其他数据库数据文件的目标。 由于我们的数据文件位于F驱动器上,因此我们可以轻松地查看可用空间,如下所示:
SELECT
CAST(CAST(available_bytes AS DECIMAL) / (1024 * 1024 * 1024) AS BIGINT) AS gb_free
FROM sys.master_files AS f
CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id)
WHERE f.database_id = DB_ID()
AND f.type_desc = 'ROWS';
This returns the free space on the drive corresponding to the database I am querying from, in this case AdventureWorks2014. The result is exactly what I am looking for:
这将返回驱动器上与我要查询的数据库相对应的可用空间,在本例中为AdventureWorks2014。 结果正是我要寻找的:
With 14.5TB free, we’re in good shape for quite a while. How about our backup drive? If we are willing to use xp_cmdshell, we can gather that information fairly easily:
凭借14.5TB的免费空间,我们在相当长一段时间内都处于良好状态。 我们的备份驱动器怎么样? 如果我们愿意使用xp_cmdshell ,我们可以很容易地收集该信息:
DECLARE @results TABLE (output_data NVARCHAR(MAX));
INSERT INTO @results
(output_data)
EXEC xp_cmdshell 'DIR C:';
SELECT
*
FROM @results
WHERE output_data LIKE '%bytes free%';
The result of this query is a single row with the number of directories and bytes free:
该查询的结果是一行,其中目录和字节数可用:
Unfortunately, xp_cmdshell is a security hole, allowing direct access to the OS from SQL Server. While some environments can tolerate its use, many cannot. As a result, let’s present an alternative that may feel a bit like cheating at first, but provides better insight into disk space without the need to enable any additional features:
不幸的是, xp_cmdshell是一个安全漏洞,允许从SQL Server直接访问操作系统。 虽然某些环境可以容忍其使用,但许多环境却不能。 因此,让我们提出一个替代方案,乍一看可能有点像作弊,但无需启用任何其他功能就可以更好地了解磁盘空间:
CREATE DATABASE DBTest
ON
( NAME = DBTest_Data,
FILENAME = 'C:\SQLData\DBTest.mdf',
SIZE = 10MB,
MAXSIZE = 10MB,
FILEGROWTH = 10MB)
LOG ON
( NAME = DBTest_Log,
FILENAME = 'C:\SQLData\DBTest.ldf',
SIZE = 5MB,
MAXSIZE = 5MB,
FILEGROWTH = 5MB);
This creates a database called DBTest on my C drive, with some relatively small data and log file sizes. If you plan on creating a more legitimate database to be used by any actual processes, then adjust the file sizes and autogrow settings as needed. With a database on this drive, we can run the DMV query from earlier and get free space on this drive:
这将在我的C驱动器上创建一个名为DBTest的数据库,其中包含一些相对较小的数据和日志文件。 如果计划创建供任何实际进程使用的更合法的数据库,请根据需要调整文件大小和自动增长设置。 使用该驱动器上的数据库,我们可以更早地运行DMV查询,并获得该驱动器上的可用空间:
USE DBTest;
SELECT
CAST(CAST(available_bytes AS DECIMAL) / (1024 * 1024 * 1024) AS BIGINT) AS gb_free
FROM sys.master_files AS f
CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id)
WHERE f.database_id = DB_ID()
AND f.type_desc = 'ROWS';
The result is exactly what we were looking for earlier, with no need for any OS-level commands via xp_cmdshell or Powershell:
结果正是我们之前所寻找的,不需要通过xp_cmdshell或Powershell进行任何操作系统级命令:
I currently have 154GB free, and the only cost of this data was the creation of a tiny database on the backup drive. With this tool in hand, we can look at a simple backup stored procedure and add logic in to manage space while it is running:
我目前有154GB的可用空间,这些数据的唯一开销是在备份驱动器上创建了一个微型数据库。 有了这个工具,我们可以看一个简单的备份存储过程,并在运行时添加逻辑来管理空间:
USE AdventureWorks2014;
GO
IF EXISTS (SELECT * FROM sys.procedures WHERE procedures.name = 'full_backup_plan')
BEGIN
DROP PROCEDURE dbo.full_backup_plan;
END
GO
CREATE PROCEDURE dbo.full_backup_plan
@backup_location NVARCHAR(MAX) = 'C:\SQLBackups\' -- Default backup folder
AS
BEGIN
SET NOCOUNT ON;
DECLARE @current_time TIME = CAST(CURRENT_TIMESTAMP AS TIME);
DECLARE @current_day TINYINT = DATEPART(DW, CURRENT_TIMESTAMP);
DECLARE @datetime_string NVARCHAR(MAX) = FORMAT(CURRENT_TIMESTAMP , 'MMddyyyyHHmmss');
DECLARE @sql_command NVARCHAR(MAX) = '';
DECLARE @database_list TABLE
(database_name NVARCHAR(MAX) NOT NULL, recovery_model_desc NVARCHAR(MAX));
INSERT INTO @database_list
(database_name, recovery_model_desc)
SELECT
name,
recovery_model_desc
FROM sys.databases
WHERE databases.name NOT IN ('msdb', 'master', 'TempDB', 'model');
SELECT @sql_command = @sql_command +
'
BACKUP DATABASE [' + database_name + ']
TO DISK = ''' + @backup_location + database_name + '_' + @datetime_string + '.bak'';
'
FROM @database_list;
PRINT @sql_command;
EXEC sp_executesql @sql_command;
END
This simple stored procedure will perform a full backup of all databases on the server, with the exception of msdb, tempdb, model, and master. What we want to do is verify free space before running backups, similar to earlier. If space is unacceptably low, then end the job and notify the correct people immediately. By maintaining enough space on the drive, we prevent running out completely and causing regular transaction log backups to fail. The test for space on the backup drive incorporates our dm_os_volume_stats query from earlier and assumes that we must maintain 25GB free at all times:
这个简单的存储过程将对服务器上的所有数据库执行完整备份,但msdb , tempdb , model和master除外。 我们想要做的是在运行备份之前验证可用空间,与之前类似。 如果空间太小,请结束工作并立即通知正确的人员。 通过在驱动器上保留足够的空间,我们可以防止完全用完并导致常规事务日志备份失败。 备份驱动器上的空间测试结合了之前的dm_os_volume_stats查询,并假设我们必须始终保持25GB的可用空间:
IF EXISTS (SELECT * FROM sys.procedures WHERE procedures.name = 'full_backup_plan')
BEGIN
DROP PROCEDURE dbo.full_backup_plan;
END
GO
CREATE PROCEDURE dbo.full_backup_plan
@backup_location NVARCHAR(MAX) = 'C:\SQLBackups\', -- Default backup folder
@backup_free_space_required_gb INT = 25 -- Default GB allowed on the backup drive
AS
BEGIN
SET NOCOUNT ON;
DECLARE @current_time TIME = CAST(CURRENT_TIMESTAMP AS TIME);
DECLARE @current_day TINYINT = DATEPART(DW, CURRENT_TIMESTAMP);
DECLARE @datetime_string NVARCHAR(MAX) = FORMAT(CURRENT_TIMESTAMP , 'MMddyyyyHHmmss');
DECLARE @sql_command NVARCHAR(MAX) = '';
DECLARE @database_list TABLE
(database_name NVARCHAR(MAX) NOT NULL, recovery_model_desc NVARCHAR(MAX));
INSERT INTO @database_list
(database_name, recovery_model_desc)
SELECT
name,
recovery_model_desc
FROM sys.databases
WHERE databases.name NOT IN ('msdb', 'master', 'TempDB', 'model');
SELECT @sql_command = @sql_command + '
DECLARE @backup_drive_space_free BIGINT;
DECLARE @current_db_size BIGINT;
DECLARE @error_message NVARCHAR(MAX);'
SELECT @sql_command = @sql_command + '
USE [DBTest];
SELECT
@backup_drive_space_free = CAST(CAST(available_bytes AS DECIMAL) / (1024 * 1024 * 1024) AS BIGINT)
FROM sys.master_files AS f
CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id)
WHERE f.database_id = DB_ID()
AND f.type_desc = ''ROWS'';
USE [' + database_name + '];
SELECT
@current_db_size = SUM(size) * 8 / 1024 / 1024
FROM sysfiles;
IF @backup_drive_space_free - @current_db_size < ' + CAST(@backup_free_space_required_gb AS NVARCHAR(MAX)) + '
BEGIN
SELECT @error_message = ''Not enough space available to process backup on ' + database_name + ' while executing the full backup maintenance job. '' + CAST(@backup_drive_space_free AS VARCHAR(MAX)) + ''GB are currently free.'';
RAISERROR(@error_message, 16, 1);
RETURN;
END
BACKUP DATABASE [' + database_name + ']
TO DISK = ''' + @backup_location + database_name + '_' + @datetime_string + '.bak'';
'
FROM @database_list;
PRINT @sql_command;
EXEC sp_executesql @sql_command;
END
Within the dynamic SQL, and prior to each backup, we check the current free space on the backup drive, the size of the database we are about to back up, and compare those values (in GB) to the allowable free space set in the stored procedure parameters. In the event that the backup we are about to take is too large, an error will be thrown. We can, in addition, take any number of actions to alert the responsible parties, such as emails, pager services, and/or additional logging.
在动态SQL中,并且在每次备份之前,我们都会检查备份驱动器上的当前可用空间,我们将要备份的数据库的大小,并将这些值(以GB为单位)与磁盘中设置的允许的可用空间进行比较。存储过程参数。 如果我们要进行的备份太大,则会引发错误。 此外,我们可以采取多种措施来提醒责任方,例如电子邮件,寻呼机服务和/或其他日志记录。
In the event that I try to back up a particularly large database, the expected error will be thrown:
如果我尝试备份一个特别大的数据库,则会抛出预期的错误:
Msg 50000, Level 16, State 1, Line 656 Not enough space available to process backup on AdventureWorks2014 while executing the full backup maintenance job. 141GB are currently free.
消息50000,级别16,状态1,行656执行完整的备份维护作业时,没有足够的空间来处理AdventureWorks2014上的备份。 141GB目前是免费的。
Since backup failures are far more serious than an index rebuild not running, we would want to err on the side of caution and make sure the right people were notified as quickly as possible. The parallel job solution from earlier could also be used to monitor backup jobs and, in the event that free space was too low send out alerts as needed and/or end the job.
由于备份失败要比不运行索引重建严重得多,因此我们要谨慎行事,并确保尽快通知正确的人员。 较早版本的并行作业解决方案也可以用于监视备份作业,如果可用空间太低,则根据需要发出警报和/或结束作业。
结论 (Conclusion)
Our ability to proactively monitor and manage potentially messy situations has few limits. With some creativity, we could monitor for locking, blocking, IO volume, data space used, and more. Whenever a job fails or we are woken up at 2am by an unfortunate on-call situation, our first thoughts should be to determine how to prevent that late night from happening again. A combination of smart alerting and proactive management of jobs will ensure that our database server never gets into an unrecoverable situation.
我们主动监视和管理潜在混乱情况的能力几乎没有限制。 有了一些创造力,我们就可以监视锁定,阻塞,IO量,使用的数据空间等。 每当工作失败或因不幸的电话待命而在凌晨2点醒来时,我们的首要想法就是确定如何防止深夜再次发生。 智能警报和主动管理作业的结合将确保我们的数据库服务器永远不会陷入无法恢复的境地。
You likely have other monitoring tools that watch over a variety of OS, disk, and SQL Server metrics. This is a good thing, and having redundant monitoring ensures that a failure in one does not render all alerting data irrelevant. The solutions presented above are the tip of the iceberg in terms of customized monitoring and automated response and should complement those other systems, not replace them.
您可能还有其他监视工具可以监视各种OS,磁盘和SQL Server指标。 这是一件好事,并且具有冗余监视功能可确保其中的一个故障不会使所有警报数据都不相关。 上面介绍的解决方案在定制监视和自动响应方面是冰山一角,应该补充那些其他系统,而不是替代它们。
Always consider how different jobs interact and time them such that there is no overlap in sensitive or resource intensive tasks. Backups, index rebuilds, ETL processes, updating statistics, archiving, software releases, and data collection processes should be timed in such a way that they do not impact each other, nor do they affect normal business processing. When there is a risk of poor timing, build in short-circuit mechanisms that prevent intolerable situations from arising.
始终考虑不同作业的交互方式并为它们计时,以使敏感或资源密集型任务之间不会重叠。 备份,索引重建,ETL过程,更新统计信息,归档,软件发布和数据收集过程的时间安排应相互不影响,也不会影响正常业务处理。 如果存在时序不正确的风险,请建立短路机制以防止出现无法忍受的情况。
In an ideal universe, we would always catch disk space issues long before they become a threat to our day-to-day processing, but we know that the real world doesn’t work like this. Exceptions will happen, so be prepared! Make common processes robust enough to withstand those inevitable circumstances and your job will become significantly easier. As a bonus, you’ll impress your coworkers and managers with time & cost-saving measures!
在理想的宇宙中,我们总是会在磁盘空间问题成为对我们日常处理的威胁之前就捕获它们,但是我们知道现实世界并非如此。 会有异常发生,所以请做好准备! 使通用流程足够健壮以承受那些不可避免的情况,您的工作将变得非常容易。 作为奖励,您将以节省时间和成本的方式给同事和经理留下深刻的印象!
翻译自: https://www.sqlshack.com/removing-the-risk-from-important-maintenance-tasks-in-sql-server/















 1697
1697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









