





sql server 分区
When talking about performance and scalability inside SQL Server, I don’t see anyone missing out on the fact to mention how locks get involved. I often see DBA’s complain to developers that their code is not scalable and they are experiencing heavy locks in the system because of the way the code has been written. The more I work with SQL Server, the more I start to understand some of these nuances.
在谈论SQL Server内部的性能和可伸缩性时,我看不到有人在提及锁如何涉及这一事实。 我经常看到DBA向开发人员抱怨他们的代码不可扩展,并且由于代码的编写方式,他们在系统中遇到了沉重的锁。 我与SQL Server的合作越深入,对这些细微差别的理解就越多。
In a recent conversation with one of the DBA’s in a conference where I was presenting, I was told the way SQL Server handles locks even in large databases (VLDBs) is to be improved. This was sort of generic statement and then I asked the gentleman to explain me why they thought so.
在我与会的一次会议中,与一位DBA的最近对话中,有人告诉我SQL Server处理锁的方法,即使在大型数据库(VLDB)中也要改进。 这是一种一般性的陈述,然后我请这位绅士向我解释为什么他们这么认为。
Even after doing some great work around partitioning their tables, they are still seeing large amount of locking and lock escalations to table are happening on database. This got me curious to why this can even happen on first place. SQL Server has done tons of optimizations from time to time to enhance this capability.
即使在围绕表分区进行了一些出色的工作之后,他们仍然看到数据库上发生了大量的锁定,并且锁升级到了表。 这让我很好奇为什么这种情况甚至可以发生在第一位。 SQL Server会不时进行大量优化以增强此功能。
I thought to bring this topic into a digestible form in this blog so that we get the basics right. There are options enabled at the database level that can help enhance this capability. I have seen many a times people go ahead and use generic recommendations and enable the wrong settings and get into a pitfall of misconfigurations.
我想在本博客中将此主题转换为易于理解的形式,以便使基础知识正确。 在数据库级别启用了一些选项,可以帮助增强此功能。 我见过很多次人们继续使用通用建议并启用错误的设置并陷入配置错误的陷阱。
Hence for this blog, I am going to do the following:
因此,对于此博客,我将执行以下操作:
- Setup the initial database configurations and Setup the tables 设置初始数据库配置并设置表
- Check how Lock escalations happen based on database properties 检查如何根据数据库属性进行锁定升级
- Look at the Locking information and waits 查看锁定信息并等待
- Change the settings at DB level 在数据库级别更改设置
- See the effect of the same on lock escalations 查看相同对锁升级的影响
- Wrap up and clean the script 总结并清理脚本
Let us first create our database for the experiment.
让我们首先为实验创建数据库。
USE MASTER;
GO
IF DATABASEPROPERTYEX ('LocksDB', 'Version') > 0
DROP DATABASE LocksDB;
CREATE DATABASE LocksDB;
GO
-- Create partition functions
ALTER DATABASE [LocksDB] ADD FILEGROUP FG10000;
ALTER DATABASE [LocksDB] ADD FILE (NAME = LocksDB_Data_10000, FILENAME = 'C:\DATA\LocksDB_Data_10000.NDF', SIZE = 100MB, FILEGROWTH = 150MB) TO FILEGROUP FG10000;
ALTER DATABASE [LocksDB] ADD FILEGROUP FG20000;
ALTER DATABASE [LocksDB] ADD FILE (NAME = LocksDB_Data_20000, FILENAME = 'C:\DATA\LocksDB_Data_20000.NDF', SIZE = 100MB, FILEGROWTH = 150MB) TO FILEGROUP FG20000;
ALTER DATABASE [LocksDB] ADD FILEGROUP FG30000;
ALTER DATABASE [LocksDB] ADD FILE (NAME = LocksDB_Data_30000, FILENAME = 'C:\DATA\LocksDB_Data_30000.NDF', SIZE = 100MB, FILEGROWTH = 150MB) TO FILEGROUP FG30000;
Once the database is created, let us next create the Partitioning Function and Partitioning Scheme for our experiment. The Partitioning Function defines the boundaries for our respective partitions and the Partitioning Scheme defines the way each of the partitions will be mapped to a logical filegroup (hence data files).
创建数据库后,让我们接下来为实验创建分区功能和分区方案。 分区功能定义了我们各自分区的边界,分区方案定义了每个分区映射到逻辑文件组(因此数据文件)的方式。
USE [LocksDB]
GO
IF EXISTS (SELECT * FROM sys.partition_functions WHERE name = 'pf_thousand')
DROP PARTITION FUNCTION [pf_thousand];
CREATE PARTITION FUNCTION [pf_thousand] (int) AS RANGE left FOR VALUES (10000,20000,30000);
GO
IF EXISTS (SELECT * FROM sys.partition_schemes WHERE name = 'ps_thousand_range')
DROP PARTITION SCHEME ps_thousand_range;
CREATE PARTITION SCHEME ps_thousand_range AS PARTITION pf_thousand TO ([PRIMARY],[FG10000],[FG20000],[FG30000]);
GO
Our LocksDB filegroups look like below:
我们的LocksDB文件组如下所示:
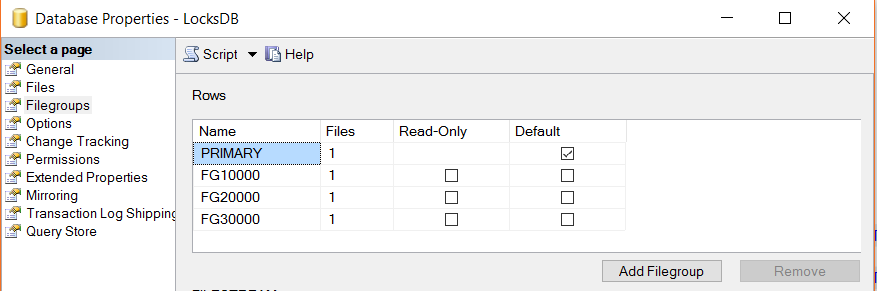
Our next logical step is to create a table, map the Partitioning Schema and add some data into the table to respective partitions.
我们的下一个逻辑步骤是创建表,映射分区模式,并将一些数据添加到表中的各个分区。
SET NOCOUNT ON
-- Create partitioned table
CREATE TABLE MyPartitionedTable(
c1 int NOT NULL,
c2 int NOT NULL,
c3 VARCHAR(100))
ON ps_thousand_range (c1);
GO
ALTER TABLE MyPartitionedTable
ADD CONSTRAINT [PK_MyPartitionedTable] PRIMARY KEY NONCLUSTERED (c1 ASC)
WITH (ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
ON ps_thousand_range (c1)
-- Populate partitioned table
DECLARE @count int
SET @count = 1
WHILE @count <> 28000
BEGIN
INSERT INTO MyPartitionedTable
SELECT @count, RAND(2), REPLICATE('a', 9)
SET @count = @count + 1
CONTINUE
END
Let us take a step back to validate if the rows were inserted into the table. Let us query the partitions DMVs to find the same:
让我们退后一步来验证是否将行插入到表中。 让我们查询分区DMV以查找相同的内容:
SELECT
OBJECT_NAME(object_id) AS [Table Name],
partition_number,
SUM(rows) AS [SQL RowCount]
FROM sys.partitions
WHERE
index_id IN (0, 1) -- 0:Heap, 1:Clustered
AND object_id = OBJECT_ID('MyPartitionedTable')
GROUP BY
object_id, partition_number
Now that the basics are done, let us try to mimic the scenario our DBA friend had first got. The code that was in setup of database script had the following:
现在已经完成了基础工作,让我们尝试模仿DBA朋友最初遇到的情况。 数据库脚本的安装程序中的代码具有以下内容:
USE LocksDB;
GO
SET STATISTICS IO ON;
GO
-- First select on partition 3 range to check if data exists
SELECT MyPartitionedTable.c1 FROM MyPartitionedTable WHERE c1>16000
-- Enable LOCK ESCALATION on the table
ALTER TABLE MyPartitionedTable SET (LOCK_ESCALATION = TABLE); --default
Note the last statement in the code above. It mentions that the Lock Escalation needs to bubble to the Table level. Though there was no need to do it, this was done in one of their code. So let us see what the effect of this is.
注意上面代码中的最后一条语句。 它提到锁升级需要冒泡到表级别。 尽管没有必要这样做,但这是在他们的代码之一中完成的。 因此,让我们看看这样做的效果。
-- Force lock escalation by updating all 10000 rows on 1st partition
-- in a single transaction.
BEGIN TRAN
UPDATE MyPartitionedTable SET c1 = c1 WHERE c1 < 10000
GO
Since we are updating close to 10000 rows in the 1st partition, the lock escalation would have happened and let us see if we can query any data from other partitions in a separate / new session.
由于我们正在更新接近第1个分区10000行,锁升级就会发生,让我们看看我们是否能够在一个单独的/新会话查询来自其他分区的任何数据。
-- Query partition 3 in a different window
USE LocksDB;
GO
SELECT COUNT (*) FROM MyPartitionedTable
WHERE c1 >= 21000;
GO
In this case you will see that the current query window is blocked and waiting indefinitely. This is very much the case to happen because our database has been misconfigured here. If we query the DMVs, we can find out:
在这种情况下,您将看到当前查询窗口被阻止并无限期等待。 这是很可能发生的情况,因为我们的数据库在这里配置不正确。 如果查询DMV,则可以发现:
-- Verify locks
USE LocksDB;
GO
SELECT * FROM sys.dm_tran_locks
WHERE [resource_type] <> 'DATABASE';
GO

As you can see, the Table object has been granted [X] Lock (Exclusive) on one of the sessions and we are waiting on another session to take an IS (Shared) lock.
如您所见,Table对象已在其中一个会话上被授予[X]锁(独占),我们正在等待另一个会话上的IS(共享)锁。
So what is the point of partitioning if we are bubbling our locks to the table level and not allowing other queries to execute. There must be something wrong right?
因此,如果我们将锁冒泡到表级别并且不允许执行其他查询,那么分区的意义何在? 一定有什么不对吗?
As I said earlier, ideally we would have wanted SQL Server to take the locks at the partition level and allowed us to query other partitions that are not affected. This is exactly what we will be doing in our code next.
如前所述,理想情况下,我们希望SQL Server在分区级别上取得锁,并允许我们查询其他不受影响的分区。 这正是我们接下来将在代码中执行的操作。
-- ROLLBACK the transaction in the first session
ROLLBACK TRAN;
GO
On the first session, execute the below code.
在第一个会话中,执行以下代码。
-- Enable LOCK ESCALATION = AUTO to enable partition level lock
ALTER TABLE MyPartitionedTable SET (LOCK_ESCALATION = AUTO);
Here we are going to change the Lock Escalation settings to Automatic and let us see how partitioning behavior changes because of this setting.
在这里,我们将“锁定升级”设置更改为“自动”,让我们看看由于该设置分区行为如何变化。
Again on session 1, change large amount of rows and let us see where this leads us:
再次在会话1上,更改大量行,然后让我们看看这将导致什么:
-- Again, UPDATE
BEGIN TRAN
UPDATE MyPartitionedTable SET c1 = c1 WHERE c1 < 10000
GO
On another session window, let us try to query the table’s data:
在另一个会话窗口上,让我们尝试查询表的数据:
-- Query partition 3 in a different window
USE LocksDB;
GO
SELECT COUNT (*) FROM MyPartitionedTable
WHERE c1 >= 21000;
GO
As you can see, the data is returned without any problems this time. This is exactly the behavior we want to see.
如您所见,这次返回的数据没有任何问题。 这正是我们想要看到的行为。
USE LocksDB;
GO
SELECT * FROM sys.partitions WHERE object_id =
OBJECT_ID ('MyPartitionedTable');
GO
SELECT * FROM sys.dm_tran_locks
WHERE [resource_type] <> 'DATABASE';
GO
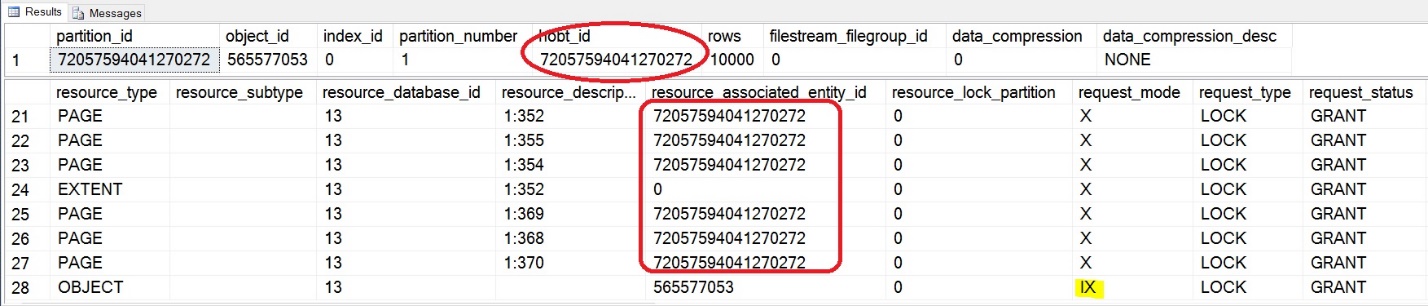
As you can see above, the hobt_id for the first partition has the Exclusive lock and the object has only the Intent locks. This is the very reason why we were able to query from other partition without any problems.
如上所示,第一个分区的hobt_id具有排他锁,而对象仅具有Intent锁。 这就是为什么我们能够从其他分区进行查询而没有任何问题的原因。
As you can see, we have used a number of combinations of DMV’s and database settings to identify potential problems that might occur in a database.
如您所见,我们使用了DMV和数据库设置的多种组合来识别数据库中可能发生的潜在问题。
As an DBA, be aware of all the settings that get introduced in every release of SQL Server and try play around with them to understand their functioning. The more we question our understanding of how SQL Server works, we will be able to write code that will make things work. Understanding the root-cause for any problem will help us in eliminating the problem totally.
作为一名DBA,请注意每个SQL Server版本中引入的所有设置,并尝试使用它们来了解其功能。 我们对我们对SQL Server如何工作的理解提出的疑问越多,我们将能够编写使事情正常进行的代码。 了解任何问题的根本原因将有助于我们彻底消除问题。
After this experiment, I wrote back to my DBA friend to let him know how some of the settings in SQL Server had helped me gain confidence in eliminating potential performance problems. I had also requested them to check the status on their SQL Server’s for this setting on every database. If there was deviation, told them to automate in changing the same.
完成该实验后,我写信给我的DBA朋友,让他知道SQL Server中的某些设置如何帮助我获得了消除潜在性能问题的信心。 我还要求他们检查每个数据库上此设置SQL Server状态。 如果存在偏差,请告诉他们自动进行更改。
As I wrap up, let us take a moment to clean up our experiment database that was just created. Cleanup script would be:
在总结时,让我们花点时间清理刚刚创建的实验数据库。 清理脚本为:
Rollback
-- Cleanup
USE master
GO
DROP DATABASE [LocksDB]
GO
In this blog post we have learned that how we can lock settings to use to enhance partitioning capability. Lots of people think partitioning is be a silver bullet to solve all of the problems but it is not true, there are some problems which require a bit more thinking like playing with lock settings.
在此博客文章中,我们了解了如何锁定设置以增强分区功能。 许多人认为分区是解决所有问题的灵丹妙药,但事实并非如此,有些问题需要更多的思考,例如使用锁定设置。
翻译自: https://www.sqlshack.com/sql-server-lock-settings-to-use-to-enhance-partitioning-capability/
sql server 分区















 82
82

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









