





SQL Server FILESTREAM allows storing the Varbinary (Max) objects in the file system instead of placing them inside the database. In the previous article – FILESTREAM in SQL Server, we took an overview of the FILESTREAM feature in SQL Server and process to enable this feature in SQL Server Instance.
SQL Server FILESTREAM允许将Varbinary(Max)对象存储在文件系统中,而不是将其放置在数据库中。 在上一篇文章– SQL Server中的FILESTREAM中 ,我们对SQL Server中的FILESTREAM功能进行了概述,并介绍了在SQL Server实例中启用此功能的过程。
Before we move further in this article, ensure you follow the first article and do the following:
在继续本文之前,请确保您遵循第一篇文章并执行以下操作:
- Enable FILESTREAM from the SQL Server Configuration Manager 从SQL Server配置管理器启用FILESTREAM
- Specify the SQL Server FILESTREAM access level using the sp_configure command or from SSMS instance properties 使用sp_configure命令或从SSMS实例属性指定SQL Server FILESTREAM访问级别
In this article, first, we will be creating a FILESTREAM enabled SQL Server database. To do this, connect to the database instance and right click on ‘Databases’ and then ‘New Database’ to create a new FILESTREAM database.
在本文中,首先,我们将创建一个启用FILESTREAMSQL Server数据库。 为此,请连接到数据库实例,然后右键单击“数据库”,然后单击“新建数据库”以创建新的FILESTREAM数据库。
In the general page, specify the Database name and the location of the MDF and LDF files. In the demo, our database file and log file location is ‘C: \sqlshack\SQLDB.’
在常规页面中,指定数据库名称以及MDF和LDF文件的位置。 在演示中,我们的数据库文件和日志文件位置为“ C:\ sqlshack \ SQLDB”。
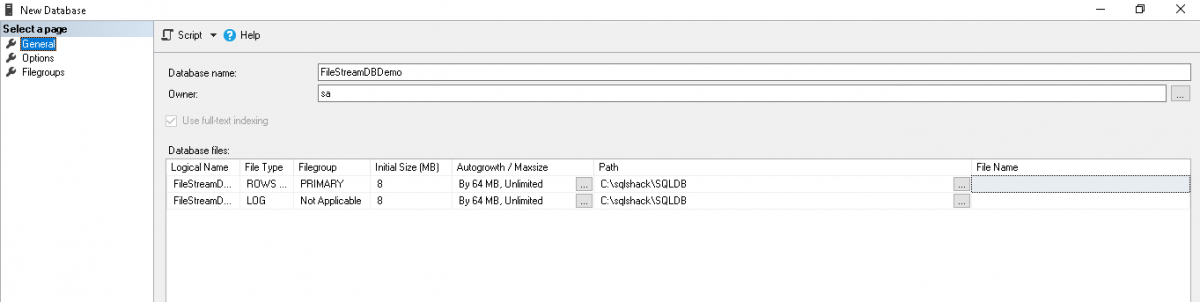
Click on the ‘Filegroups’ page from the left menu, and you can see a separate group for the FILESTREAM.
单击左侧菜单中的“文件组”页面,您可以看到FILESTREAM的单独组。
We need to add the SQL SERVER FILESTREAM filegroup here, but in the screenshot, you can see that the ‘Add Filegroup’ option is disabled. If we do not restart the SQL Service after enabling the FILESTREAM feature at the instance level from SQL Server Configuration Manager, you will not be able to add the FILESTREAM filegroup.
我们需要在此处添加SQL SERVER FILESTREAM文件组,但是在屏幕截图中,您可以看到“添加文件组”选项已禁用。 如果从SQL Server配置管理器在实例级别启用FILESTREAM功能后,我们没有重新启动SQL Service,则将无法添加FILESTREAM文件组。
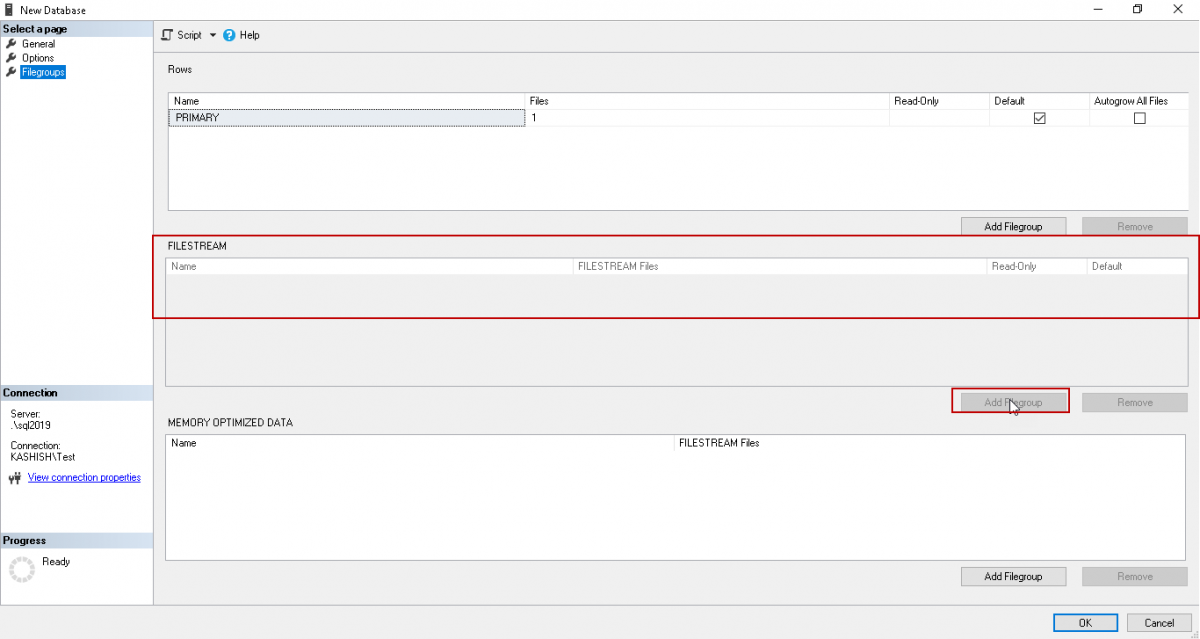
Restart the SQL Server service now and then again follows the steps above. You can see in below screenshot that the ‘Add filegroup’ option is now enabled.
立即重新启动SQL Server服务,然后再次执行上述步骤。 您可以在下面的屏幕截图中看到“添加文件组”选项已启用。
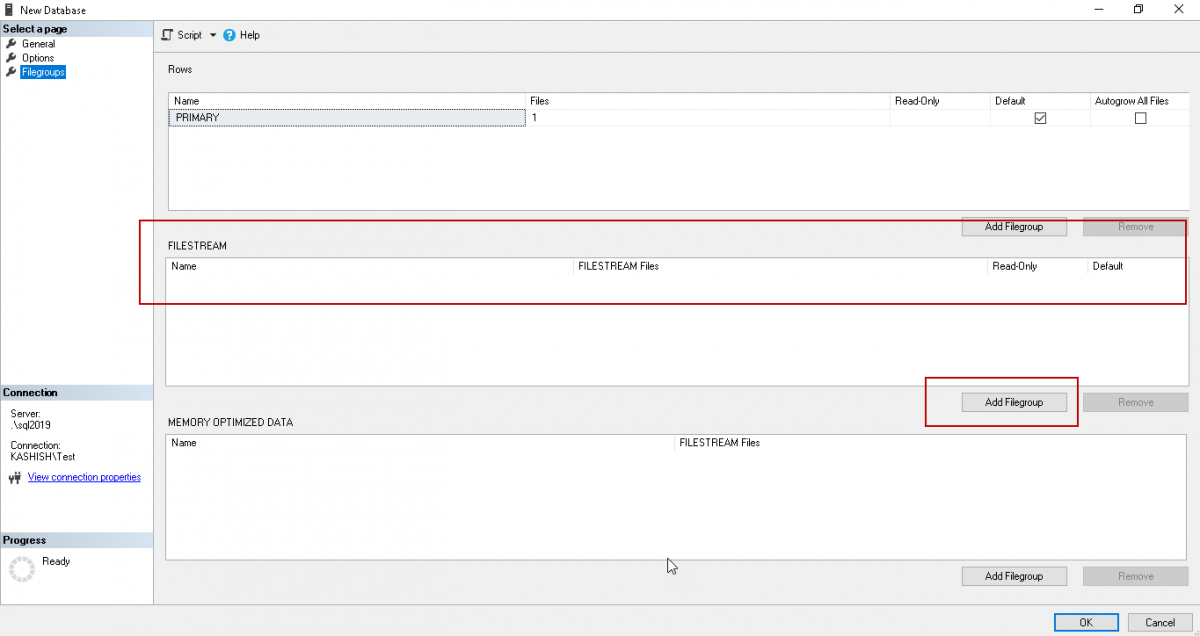
Click on ‘Add FileGroup’ in the FILESTREAM section and specify the name of the SQL Server FILESTREAM filegroup.
单击“ FILESTREAM”部分中的“添加文件组”,然后指定SQL Server FILESTREAM文件组的名称。
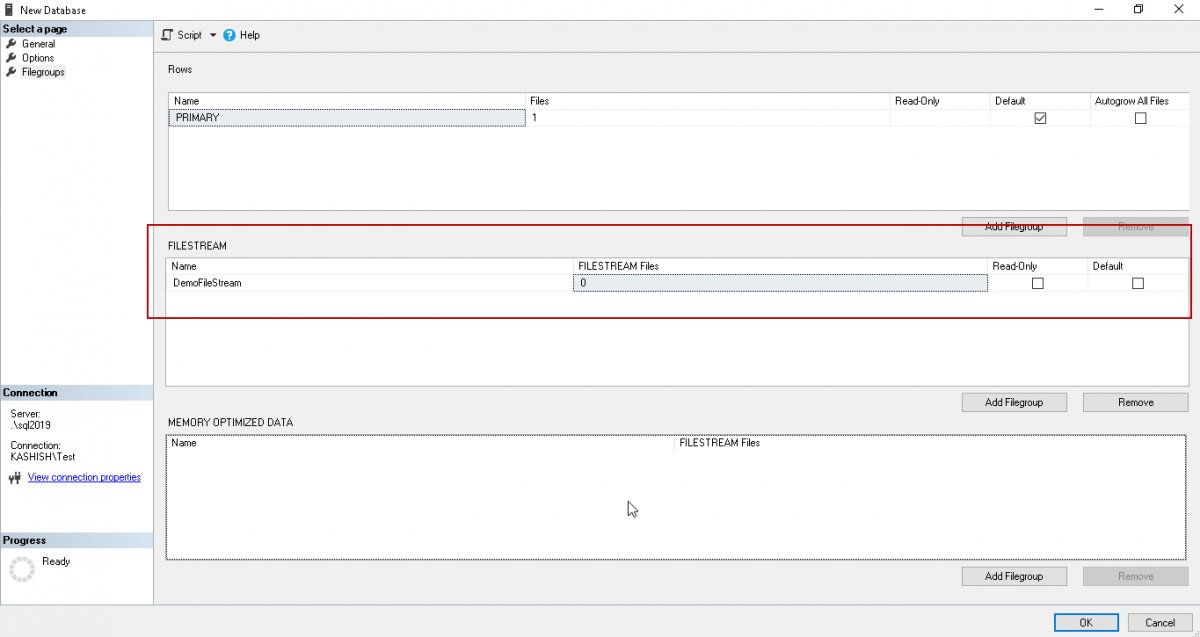
Click ‘OK’ to create the database with this new filegroup. Once the database is created, open the database properties to add the file in the newly created ‘DemoFileStream’ filegroup.
单击“确定”以使用此新文件组创建数据库。 创建数据库后,打开数据库属性以将文件添加到新创建的“ DemoFileStream”文件组中。
Specify the Database file name and select the file type as ‘FILESTREAM Data’ from the drop-down option. In the filegroup, it automatically shows the SQL Server FILESTREAM filegroup name. We also need to specify the path where we will store all the large files such as documents, audio, video files etc. You should have sufficient free space in the drive as per the space consumption of these big files.
指定数据库文件名,然后从下拉选项中选择文件类型为“ FILESTREAM数据”。 在文件组中,它会自动显示SQL Server FILESTREAM文件组名称。 我们还需要指定存储所有大型文件(如文档,音频,视频文件等)的路径。根据这些大型文件的空间消耗,驱动器中应有足够的可用空间。
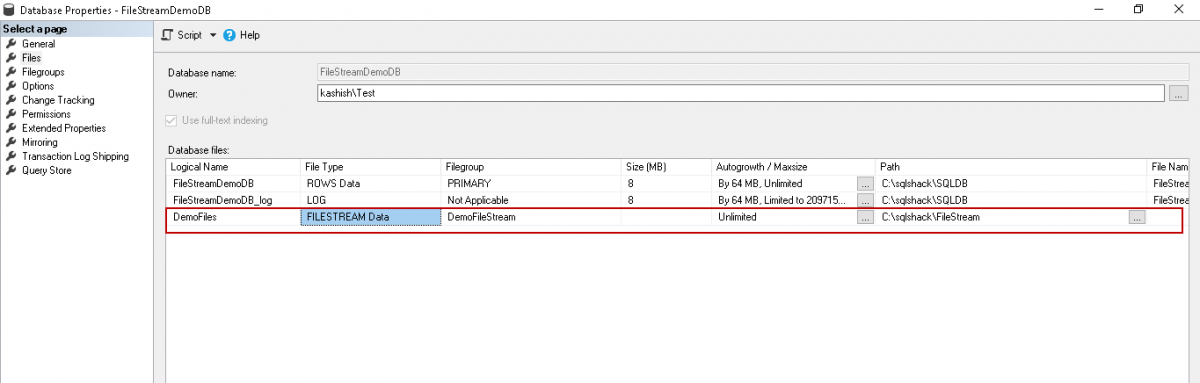
We can generate the script using the ‘Script’ option as highlighted below.
我们可以使用“脚本”选项生成脚本,如下所示。
We can see the below scripts for the adding a SQL Server FILESTREAM filegroup and add a file into it.
我们可以看到以下脚本,用于添加SQL Server FILESTREAM文件组并将文件添加到其中。
USE [master]
Go
ALTER DATABASE [FileStreamDemoDB] ADD FILEGROUP [DemoFileStream] CONTAINS FILESTREAM
GO
ALTER DATABASE [FileStreamDemoDB] ADD FILE ( NAME = N'DemoFiles', FILENAME = N'C:\sqlshack\FileStream\DemoFiles' ) TO FILEGROUP [DemoFileStream]
GO
You can verify the container in the FILESTREAM file path ‘ C:\sqlshack\FileStream\DemoFiles as per our demo.
您可以按照我们的演示在FILESTREAM文件路径'C:\ sqlshack \ FileStream \ DemoFiles中验证容器。
Here filestream.hdr file contains metadata for the FILESTREAM and $FSLOG directory is similar to the t-log in the database.
这里的filestream.hdr文件包含FILESTREAM的元数据,$ FSLOG目录类似于数据库中的t-log。
在SQL Server FILESTREAM数据库中创建表 (Creating a table in a SQL Server FILESTREAM database)
Now let us create a table with the FILESTREAM data. In the below script, you can see we have used VarBinary(Max) FILESTREAM to create a FILEASTREAM table. As specified earlier, to use the FILESTREAM we should have a table with UNIQUEIDENTIFIER column with ROWGUIDCOL. In our script, [FileID] column contains unique non-null values.
现在,让我们用FILESTREAM数据创建一个表。 在下面的脚本中,您可以看到我们已经使用VarBinary(Max)FILESTREAM创建了FILEASTREAM表。 如前所述,要使用FILESTREAM,我们应该有一个带有UNIQUEIDENTIFIER列和ROWGUIDCOL的表。 在我们的脚本中,[FileID]列包含唯一的非空值。
Use FileStreamDemoDB
Go
CREATE TABLE [DemoFileStreamTable] (
[FileId] UNIQUEIDENTIFIER ROWGUIDCOL NOT NULL UNIQUE,
[FileName] VARCHAR (25),
[File] VARBINARY(MAX) FILESTREAM);
GO
Now if we look at the FILESTREAM path, we can see a new folder with GUID values.
现在,如果我们查看FILESTREAM路径,我们将看到一个具有GUID值的新文件夹。
Let us create another FILESTREAM table in the same SQL Server database:
让我们在同一SQL Server数据库中创建另一个FILESTREAM表:
Use FileStreamDemoDB
Go
CREATE TABLE [DemoFileStreamTable_1] (
[FileId] UNIQUEIDENTIFIER ROWGUIDCOL NOT NULL UNIQUE,
[FileName] VARCHAR (25),
[File] VARBINARY (MAX) FILESTREAM);
GO
We will get a new container for each FILESTREAM table in the path where we have created the FILESTREAM file.
我们将在创建FILESTREAM文件的路径中为每个FILESTREAM表获得一个新容器。
Open the container, and you can see another folder inside that. This folder shows the FILESTREAM column for the newly created table.
打开容器,您可以看到其中的另一个文件夹。 此文件夹显示新创建的表的FILESTREAM列。
We will insert the data in the newly created FILESTREAM table. In this example, we will insert a picture which is located at the ‘C:\sqlshack’ folder.
我们将数据插入到新创建的FILESTREAM表中。 在此示例中,我们将插入位于“ C:\ sqlshack”文件夹中的图片。
DECLARE @File varbinary(MAX);
SELECT
@File = CAST(
bulkcolumn as varbinary(max)
)
FROM
OPENROWSET(BULK 'C:\sqlshack\akshita.png', SINGLE_BLOB) as MyData;
INSERT INTO DemoFileStreamTable_1
VALUES
(
NEWID(),
'Sample Picture',
@File
)
We can select the records from the demo table. In the ‘File’ column you can see that the image is converted into the varbinary object.
我们可以从演示表中选择记录。 在“文件”列中,您可以看到图像已转换为varbinary对象。
SELECT TOP (1000) [FileId]
,[FileName]
,[File]
FROM [FileStreamDemoDB].[dbo].[DemoFileStreamTable_1]
Once we have inserted the data into the table, we can see a file into the folder. We can directly open this file using the compatible application program.
将数据插入表格后,我们可以在文件夹中看到一个文件。 我们可以使用兼容的应用程序直接打开此文件。
Right click this file and click ‘Open With’. Choose the program from the list of applications. In our example, we inserted image file; therefore, I choose ‘Photo Gallery’ to open it.
右键单击该文件,然后单击“打开方式”。 从应用程序列表中选择程序。 在我们的示例中,我们插入了图像文件; 因此,我选择“照相馆”将其打开。
The image is opened in photo gallery as shown below.
图像在相册中打开,如下所示。
When we insert the document using the FILESTREAM feature, SQL Server copies the file into the FILESTREAM path. It does not change the file properties. In the below image, you can see the file stored in the container(C:\sqlshack\FileStream\DemoFiles\97f720ed-afbf-413d-8f5c-5b56d4736984\8f62d1b7-7f8b-4f98-abe9-a06b4faa1d2e) and the actual file (Path – C:\sqlshack) properties. You can see here that file size is the same for these files.
当我们使用FILESTREAM功能插入文档时,SQL Server将文件复制到FILESTREAM路径中。 它不会更改文件属性。 在下图中,您可以看到存储在容器中的文件(C:\ sqlshack \ FileStream \ DemoFiles \ 97f720ed-afbf-413d-8f5c-5b56d4736984 \ 8f62d1b7-7f8b-4f98-abe9-a06b4faa1d2e) – C:\ sqlshack)属性。 您可以在此处看到这些文件的文件大小相同。
FILESTREAM Container | Actual File |
Size: 1.19 KB | Size: 1.19 KB |
Size on Disk: 4 KB | Size on Disk: 4 KB |
| FILESTREAM容器 | 实际档案 |
大小:1.19 KB | 大小:1.19 KB |
磁盘大小:4 KB | 磁盘大小:4 KB |
Updating Data stored in a FILESTREAM Table
更新存储在FILESTREAM表中的数据
Suppose we want to update the FILESTREAM document in our example. In this example, we want to replace the existing image with a word document. We can do it directly using the update command similar to the t-SQL command.
假设我们要在示例中更新FILESTREAM文档。 在此示例中,我们要用Word文档替换现有图像。 我们可以使用类似于t-SQL命令的update命令直接执行此操作。
Below is the existing record in the table:
以下是表中的现有记录:
SELECT TOP (1000) [FileId]
,[FileName]
,[File]
FROM [FileStreamDemoDB].[dbo].[DemoFileStreamTable_1]
Run the below update command.
运行以下更新命令。
UPDATE DemoFileStreamTable_1
SET [File] = (SELECT *
FROM OPENROWSET(
BULK 'C:\sqlshack\SQL Server Profiler in Azure Data Studio.docx',
SINGLE_BLOB) AS Document)
WHERE fileid = '60236384-AC5B-45D1-97F8-4C05D90784F8'
GO
Update DemoFileStreamTable_1
set filename='Sample Doc'
WHERE fileid = '60236384-AC5B-45D1-97F8-4C05D90784F8'
GO
Now let us verify the updated record in the table.
现在,让我们验证表中的更新记录。
SELECT TOP (1000) [FileId]
,[FileName]
,[File]
FROM [FileStreamDemoDB].[dbo].[DemoFileStreamTable_1]
In the FILESTREAM path, you can see that we have a new word document file. We can open this file into the word document.
在FILESTREAM路径中,您可以看到我们有一个新的Word文档文件。 我们可以将此文件打开到word文档中。
However, the FILESTREAM path contains the old image file as well. SQL Server did not remove this file.
但是,FILESTREAM路径也包含旧的图像文件。 SQL Server并未删除此文件。
In this case, we can see both the old and new FILESTREAM document. SQL Server removes the old files using the garbage collection process. This process will remove the old file if it is no longer required by the SQL Server. Initially, we saw a folder $log into the FILESTREAM path. It works similar to a transaction log in the SQL Server database.
在这种情况下,我们可以同时看到旧的和新的FILESTREAM文档。 SQL Server使用垃圾回收过程删除旧文件。 如果SQL Server不再需要该旧文件,则此过程将删除它。 最初,我们看到文件夹$ log进入FILESTREAM路径。 它的工作方式类似于SQL Server数据库中的事务日志。
SQL Server has a particular internal filestream_tombstone table, which contains an entry for this old file.
SQL Server有一个特定的内部filestream_tombstone表,其中包含此旧文件的条目。
SELECT * FROM sys.internal_tables where name like ‘filestream_tomb%’
The garbage collection process removes the old file only if there is no entry for the file in the filestream_tombstone table. We cannot see the content of this filestream_tombstone table. However, if you wish to do so, use the DAC connection.
仅当filestream_tombstone表中没有该文件的条目时,垃圾收集过程才会删除该旧文件。 我们看不到此filestream_tombstone表的内容。 但是,如果您愿意,可以使用DAC连接。
The database recovery model plays an essential role in the entry in the filestream_tombstone table.
数据库恢复模型在filestream_tombstone表中的条目中起着至关重要的作用。
- Simple recovery mode: In a database in simple recovery model, the file is removed on next checkpoint
- 简单恢复模式:在简单恢复模式的数据库中,该文件在下一个检查点被删除
- Full recovery model: If the database is in full recovery mode, we need to perform a transaction log backup to remove this file automatically 完全恢复模式:如果数据库处于完全恢复模式,则需要执行事务日志备份以自动删除此文件
Take the transaction log backup with below command (you should have a full backup before to run a transaction log backup.
使用以下命令进行事务日志备份(运行事务日志备份之前,您应该具有完整备份。
BACKUP LOG [FileStreamDemoDB] TO DISK = N'C:\Program Files\Microsoft SQL Server\MSSQL15.SQL2019\MSSQL\Backup\FileStreamDemoDB.bak'
WITH NOFORMAT, NOINIT, NAME = N'FileStreamDemoDB-Full Database Backup', SKIP, NOREWIND, NOUNLOAD, STATS = 10
GO
You can see now that old file is removed from the FILESTREAM path automatically.
现在您可以看到旧文件已自动从FILESTREAM路径中删除。
We might need to run multiple transaction log backups if there are still VLF in the database. You can consider this similar to a standard transaction log truncate process.
如果数据库中仍然有VLF,我们可能需要运行多个事务日志备份。 您可以认为这类似于标准事务日志截断过程。
We can run the garbage collector process file manually to remove the files from the container before the automatic garbage collector process cleans the file. We can do it using ‘sp_filestream_force_garbage_collection’.
我们可以手动运行垃圾收集器进程文件,以在自动垃圾收集器进程清除文件之前从容器中删除文件。 我们可以使用“ sp_filestream_force_garbage_collection”来实现。
Below is the syntax for ‘sp_filestream_force_garbage_collection’
以下是“ sp_filestream_force_garbage_collection”的语法
sp_filestream_force_garbage_collection @dbname, @filename
UPDATE DemoFileStreamTable_1
SET [File] = (SELECT *
FROM OPENROWSET (
BULK ‘C:\sqlshack\Flow Map Chart Power BI Desktop.docx’,
SINGLE BLOB) AS Document)
WHERE fileid = ‘835FF1A7-DFFD-485F-ABAE-B718D277B258’
GO
We have both the old and new file after the update.
更新后,我们将同时拥有旧文件和新文件。
Let us run the sp_filestream_force_garbage_collection for the SQL Server FILESTREAM database.
让我们为SQL Server FILESTREAM数据库运行sp_filestream_force_garbage_collection。
USE FileStreamDemoDB;
GO
EXEC sp_filestream_force_garbage_collection @dbname = N’FileStreamDemoDB’
Here you can see that value for the num_unprocessd_items is 1. It indicates that the garbage collector process does not remove the file. As highlighted earlier, it may be due to a pending transaction log backup, checkpoint or the long-running active transaction.
在这里,您可以看到num_unprocessd_items的值为1。这表明垃圾收集器进程没有删除该文件。 如前所述,这可能是由于挂起的事务日志备份,检查点或长时间运行的活动事务引起的。
last_collected_lsn shows the LSN number to which garbage collector has removed the files.
last_collected_lsn显示垃圾回收器已将文件删除到的LSN号。
Rerun the transaction log backup and rerun the procedure. We can see that the there are no unprocessed items (num_unprocessed_items=0) and last_collected_lsn is also modified as per the last log backup.
重新运行事务日志备份,然后重新运行该过程。 我们可以看到没有未处理的项目(num_unprocessed_items = 0),并且last_collected_lsn也根据上次日志备份进行了修改。
USE FileStreamDemoDB;
GO
EXEC sp_filestream_force_garbage_collection @dbname = N’FileStreamDemoDB’
Note: We need to have db_owner permission in the database to run this procedure.
注意:我们需要数据库中具有db_owner权限才能运行此过程。
Deleting FILESTREAM data
删除FILESTREAM数据
We can remove the rows from the FILESTREAM table using the delete statement similar to a standard database table.
我们可以使用类似于标准数据库表的delete语句从FILESTREAM表中删除行。
SELECT TOP (1000) [FileId]
,[FileName]
,[File]
FROM [FileStreamDemoDB].[dbo].[DemoFileStreamTable_1]
SELECT TOP (1000) [FileId]
,[FileName]
,[File]
FROM [FileStreamDemoDB].[dbo].[DemoFileStreamTable_1]
We have deleted the row from the FILESTREAM table, however; the file will be deleted from the path once the garbage collector process runs.
但是,我们已经从FILESTREAM表中删除了该行; 一旦垃圾收集器进程运行,该文件将从路径中删除。
结论: (Conclusion:)
In this article, we explored how to create a database with a SQL Server FILESTREAM filegroup along with demonstrating DML activity on it. You can explore this exciting feature in the SQL Server Database yourself and continue to follow along as we will cover more on the SQL Server FILESTREAM feature in the next article.
在本文中,我们探讨了如何使用SQL Server FILESTREAM文件组创建数据库以及如何在数据库上演示DML活动。 您可以自己在SQL Server数据库中探索这一令人兴奋的功能,并继续进行下去,因为我们将在下一篇文章中详细介绍SQL Server FILESTREAM功能。
目录 (Table of contents)
翻译自: https://www.sqlshack.com/managing-data-with-sql-server-filestream-tables/















 257
257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









