





 本文详细介绍如何在PowerBI中实现星型模式,通过分解数据集为事实表和维度表,提升数据分析效率。以图书销售数据为例,演示了创建维度查询和事实查询的过程。
本文详细介绍如何在PowerBI中实现星型模式,通过分解数据集为事实表和维度表,提升数据分析效率。以图书销售数据为例,演示了创建维度查询和事实查询的过程。
In this article, you will see how to implement a star schema in Power BI. Microsoft Power BI is a business analytics tool used to manipulate and analyze data from a variety of sources.
在本文中,您将看到如何在Power BI中实现星形模式。 Microsoft Power BI是一种业务分析工具,用于处理和分析来自各种来源的数据。
什么是星型模式? (What is a Star Schema?)
Star schema refers to the logical description of datasets where data is divided into facts tables and dimension tables.
星型模式是指数据集的逻辑描述,其中数据分为事实表和维度表。
The facts table contains the actual information and the dimensions table contains the related information. Star schema is very similar to a one-to-many relationship, where a table can have multiple/duplicate foreign keys from a foreign key column.
事实表包含实际信息,维度表包含相关信息。 星型模式非常类似于一对多关系,其中一个表可以具有来自外键列的多个/重复外键。
Take a look at the following figure. In the figure below, we have two tables that are dimensional: Categories and Authors and one fact table Books.
看下图。 在下图中,我们有两个维度表:“类别”和“作者”,以及一个事实表“书籍”。
As a rule of thumb, the tables that contain values that can be repeated in the other tables are dimension tables and the table which contains foreign keys from other tables is implemented as a fact table.
根据经验,包含可以在其他表中重复的值的表是维度表,而包含来自其他表的外键的表则被实现为事实表。
For instance, if you look at the Authors table it contains values as author_id and author_name. Since one author can write multiple books, there can be multiple records in the Books table where the value for the author_id will be the same and so repeated. Therefore, the Authors table will be implemented as a dimension table in a star schema in Power BI. In the same way, the Categories table has been implemented as a dimension table.
例如,如果您查看“作者”表,它包含的值包括author_id和author_name。 由于一位作者可以写多本书,因此Books表中可以有多个记录,在这些记录中author_id的值将相同并且如此重复。 因此,作者表将在Power BI中的星型模式中实现为维度表。 以相同的方式,类别表已实现为维度表。
If you look at the Books table, it contains columns that can be used to retrieve data from other tables i.e. using category_id and author_name columns from the Books table, the category names, and author names can be retrieved. Since the Books table contains keys that can be used to retrieve data from other tables, the Books table is implemented as a fact table.
如果您查看Books表,则该表包含可用于从其他表检索数据的列,即使用Books表中的category_id和author_name列,可以检索类别名称和作者名称。 由于Books表包含可用于从其他表检索数据的键,因此Books表被实现为事实表。
Now that you understand what star schema is and what dimensions and facts tables are, let’s briefly look at why you might want to use a star schema in Power BI.
现在您已经了解了什么是星型模式以及什么维度和事实表,现在让我们简要地看一下为什么要在Power BI中使用星型模式。
The main advantages of star schemas are:
星型模式的主要优点是:
简单 (Simplicity)
Star schemas are very easy to understand, read and use. Dimensions are used to slice and dice the data, and facts to aggregate numbers.
星型模式非常易于理解,阅读和使用。 维度用于对数据进行切片和切块,事实用于汇总数字。
性能 (Performance)
Star schemas contain clear join paths and relatively small numbers of tables. This means that queries run more quickly than they will on an operational system.
星型模式包含清晰的联接路径和相对较少的表。 这意味着查询比在操作系统上运行更快。
可扩展性 (Scalability)
Star schemas can accommodate changes, such as adding new dimensions, attributes or measures very easily. Making changes to your star schema in Power BI will be simple once you are set up.
星型模式可以轻松地进行更改,例如添加新的尺寸,属性或度量。 设置完成后,在Power BI中对星型架构进行更改将很简单。
支持 (Support)
Star schemas are the most commonly used schemas in BI. This means that they are widely understood and supported by a large number of BI tools.
星型模式是BI中最常用的模式。 这意味着它们被大量的BI工具广泛理解和支持。
Now that we understand what star schema is and why you might want to implement star schema in Power BI, let’s create a database in SQL Server that will be used as a source to Power BI desktop. The database will be used to implement the start Schema in Power BI.
现在,我们了解了星型架构以及为什么要在Power BI中实现星型架构,让我们在SQL Server中创建一个数据库,该数据库将用作Power BI桌面的源。 该数据库将用于在Power BI中实现启动模式。
创建一个虚拟数据库 (Creating a dummy database)
We will create a simple SQL Server database for a fictional book store. The name of the database will be the BookStore.
我们将为一个虚构的书店创建一个简单SQL Server数据库。 数据库的名称将为BookStore。
The following script creates our database:
以下脚本创建我们的数据库:
CREATE DATABASE BookStore
The database will contain only one table i.e.:
该数据库将仅包含一个表,即:
USE BookStore
CREATE TABLE Books
(
Id INT PRIMARY KEY IDENTITY(1,1),
book_name VARCHAR (50) NOT NULL,
price INT,
category_id INT,
category_name VARCHAR (50) NOT NULL,
author_id INT,
author_name VARCHAR (50) NOT NULL,
)
The Books table contains 7 columns: Id, book_name, price, cateogory_id, category_name, author_id, and author_name.
Books表包含7列:Id,book_name,价格,cateogory_id,category_name,author_id和author_name。
Let’s add some dummy records in the Books table:
让我们在Books表中添加一些虚拟记录:
USE BookStore
INSERT INTO Books
VALUES ( 'Book-A', 100, 1, 'CAT-A', 1, 'Author-A'),
( 'Book-B', 200, 2, 'CAT-B', 2, 'Author-B'),
( 'Book-C', 150, 3, 'CAT-C', 2, 'Author-B'),
( 'Book-D', 100, 3, 'CAT-C', 1, 'Author-A'),
( 'Book-E', 200, 3, 'CAT-C', 2, 'Author-B'),
( 'Book-F', 150, 4, 'CAT-D', 3, 'Author-C'),
( 'Book-G', 100, 5, 'CAT-E', 2, 'Author-B'),
( 'Book-H', 200, 5, 'CAT-E', 4, 'Author-D'),
('Book-I', 150, 6, 'CAT-F', 4, 'Author-D')
将Power BI与SQL Server连接 (Connecting Power BI with SQL Server)
We have created a dummy dataset. The next step is to connect Power BI with SQL Server and then import the BookStore dataset into Power BI. To see the detailed explanation for how to connect Power BI with SQL Server, have a look at this article on connecting Power BI to SQL. Only a brief explanation is given in this section.
我们创建了一个虚拟数据集。 下一步是将Power BI与SQL Server连接,然后将BookStore数据集导入Power BI。 要查看有关如何将Power BI与SQL Server连接的详细说明,请参阅这篇有关将Power BI连接到SQL的文章 。 本节仅作简要说明。
To connect Power BI with SQL Server, open the Power BI main dashboard, and then select the “Get Data” option from the top menu. A dialogue box will appear where you have to enter the SQL Server and the database names. Enter the server name as per your SQL Server instance name. In the Database field, enter “BookStore”.
要将Power BI与SQL Server连接,请打开Power BI主仪表板,然后从顶部菜单中选择“获取数据”选项。 将出现一个对话框,您必须在其中输入SQL Server和数据库名称。 根据您SQL Server实例名称输入服务器名称。 在数据库字段中,输入“ BookStore”。
Once the connection is established, you will see the following window.
建立连接后,您将看到以下窗口。
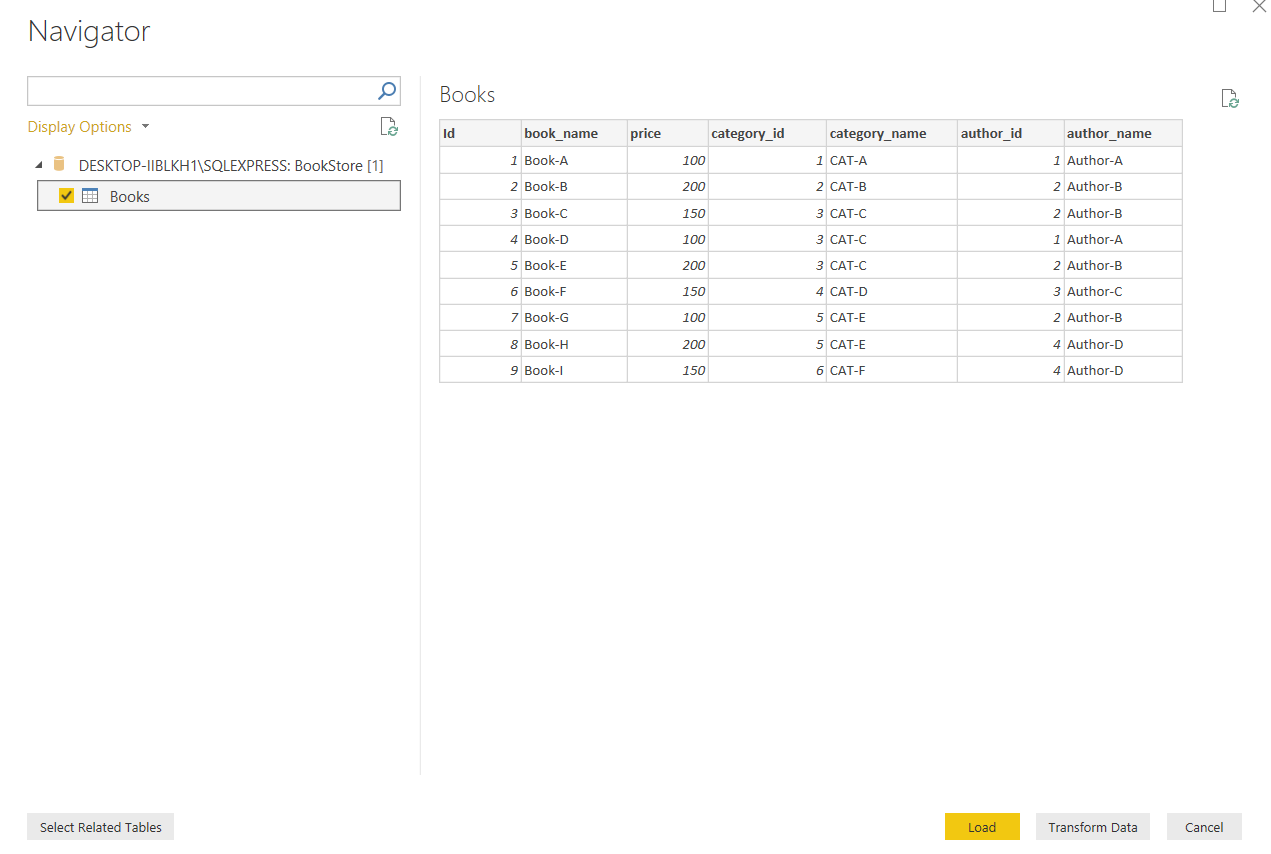
Click on the table name “Books” and then click “Transform Data” button. The data will be loaded into the Query Editor.
单击表名“ Books”,然后单击“转换数据”按钮。 数据将被加载到查询编辑器中。
使用查询编辑器在Power BI中实现星型架构 (Implementing Star Schema in Power BI with Query Editor)
If you look at the Books table in the query editor, it contains 7 columns as shown below:
如果您在查询编辑器中查看“图书”表,则该表包含7列,如下所示:
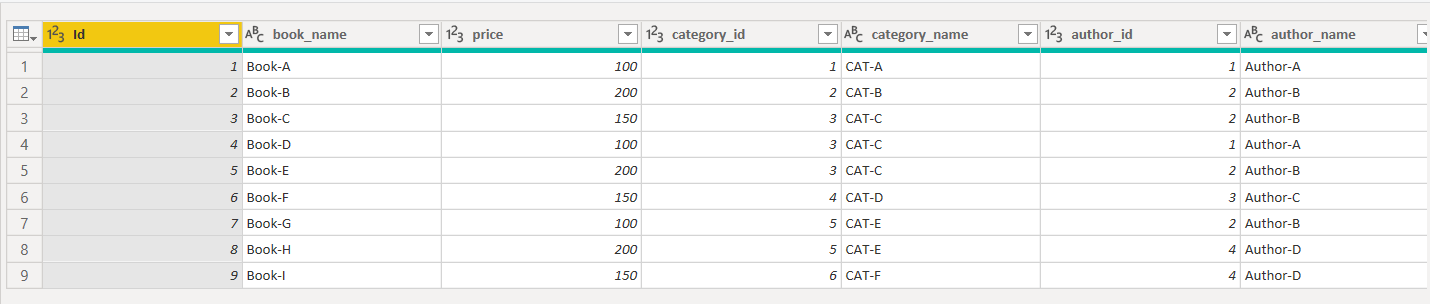
To implement Star Schema in Power BI using the Books table, as I explained earlier, we need to split the Books table into three tables i.e. Books, Categories and Authors. A single dataset or table in the Power BI Query Editor is called a query. From now on, I will use the term query for each table.
如前所述,要使用Books表在Power BI中实现Star Schema,我们需要将Books表分为三个表,即Books,类别和Authors。 Power BI查询编辑器中的单个数据集或表称为查询。 从现在开始,我将对每个表使用术语查询。
创建类别的维查询 (Creating a Dimensional Query for Categories)
As a first step, we will create a dimension table for Category. To do so, right-click on the Books query (table), and select “Reference” from the drop-down menu as shown below. This will create a new query that references the actual Books query. The new query will not have any connection with the actual data source. This new query will be used to create a dimension query for Category. Click on the query name and rename it to DIM-Category.
第一步,我们将为Category创建一个维表。 为此,请在“图书”查询(表)上单击鼠标右键,然后从下拉菜单中选择“参考”,如下所示。 这将创建一个引用实际Books查询的新查询。 新查询将与实际数据源没有任何关系。 此新查询将用于为“类别”创建维度查询。 单击查询名称,并将其重命名为DIM-Category。
The DIM-Category query will contain all the same seven columns as Books query. In the DIM-Category query, we only need the category_id and category_name columns. Therefore, select all the columns except those two, and click the “Remove Columns” option from the top menu as shown in the following screenshot.
DIM类别查询将包含与“书籍”查询相同的所有七个列。 在DIM类别查询中,我们只需要category_id和category_name列。 因此,选择除这两列以外的所有列,然后从顶部菜单中单击“删除列”选项,如以下屏幕截图所示。
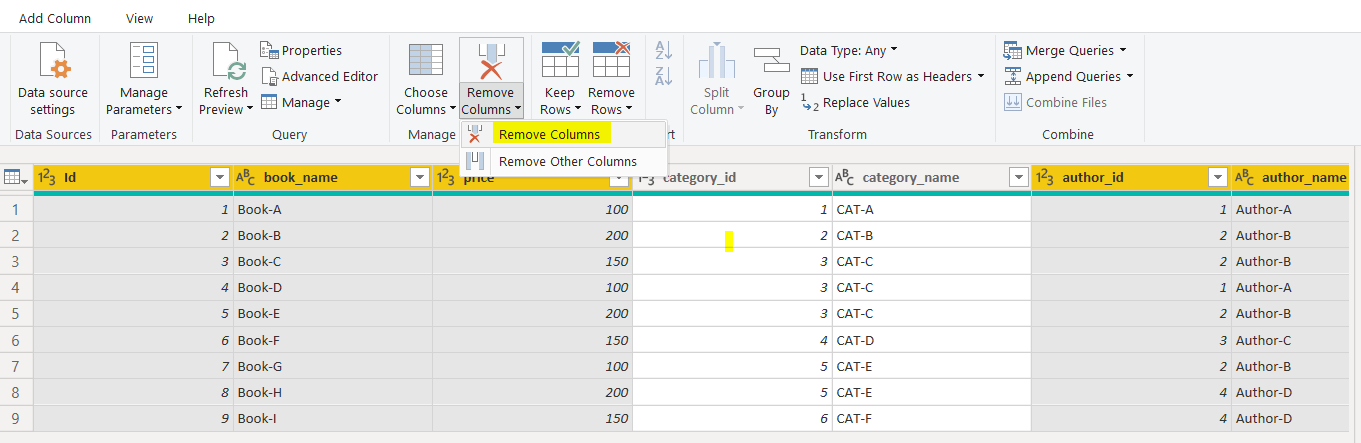
The next step is to remove the duplicate rows from the DIM-Category query. To do so, select any column and then click “Remove Rows -> Remove Duplicates” option from the top menu.
下一步是从DIM-Category查询中删除重复的行。 为此,请选择任意列,然后从顶部菜单中单击“删除行->删除重复项”选项。
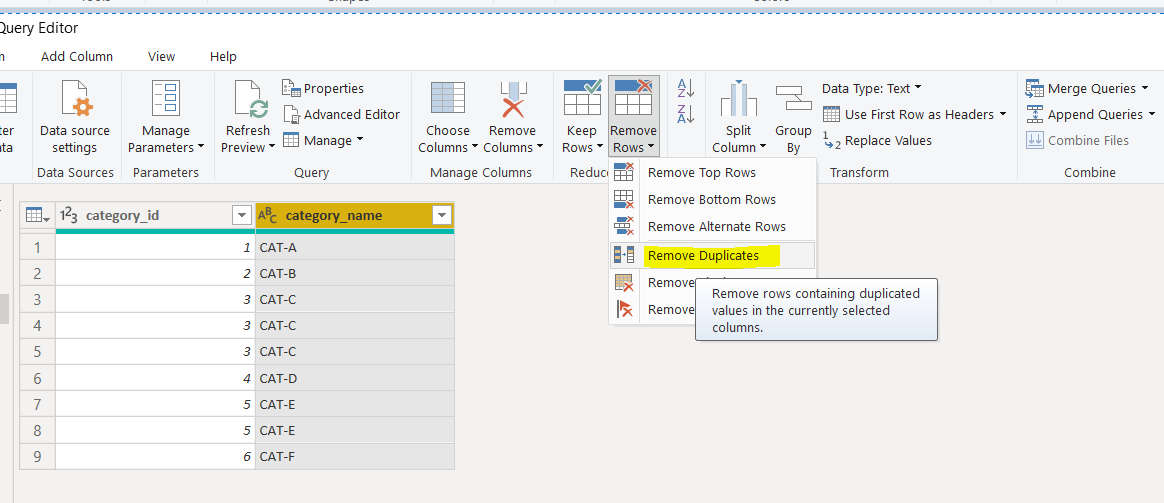
Once you remove the duplicates you should see the following query. You can see that the DIM-Category query now only contains unique ids and names of the authors.
删除重复项后,您将看到以下查询。 您可以看到DIM-Category查询现在仅包含唯一的ID和作者姓名。
为作者创建维度查询 (Creating a Dimensional Query for Authors)
To create a dimension query for the Authors, again create a new reference query and rename it “DIM-Author”. Next remove all the columns from the DIM-Author query, except author_id, and author_name as shown below:
要为作者创建维度查询,请再次创建一个新的参考查询并将其重命名为“ DIM-Author”。 接下来,从DIM-Author查询中删除所有列,但author_id和author_name除外,如下所示:
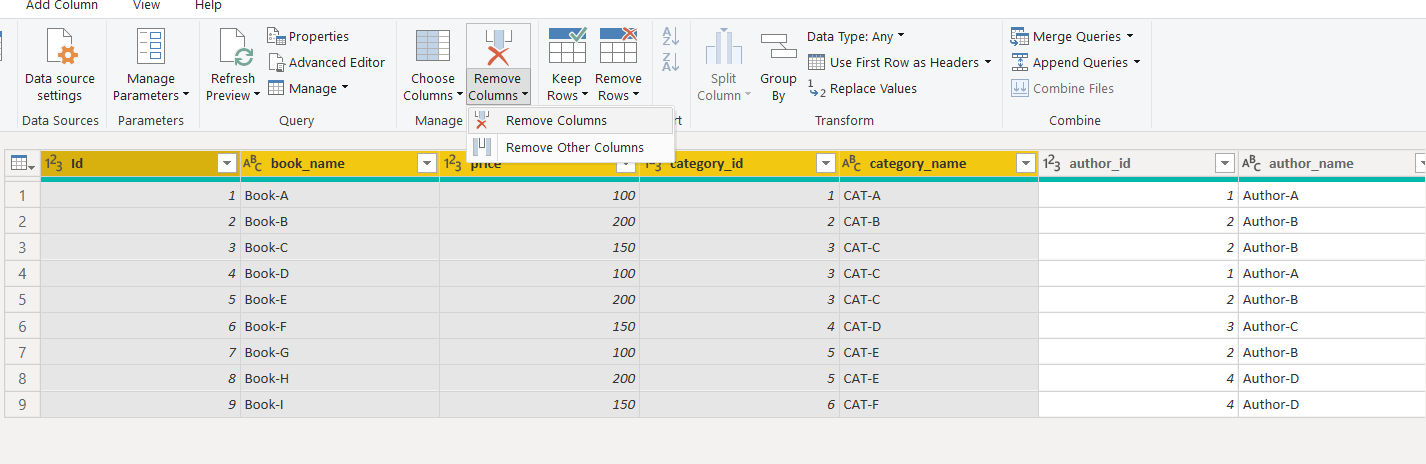
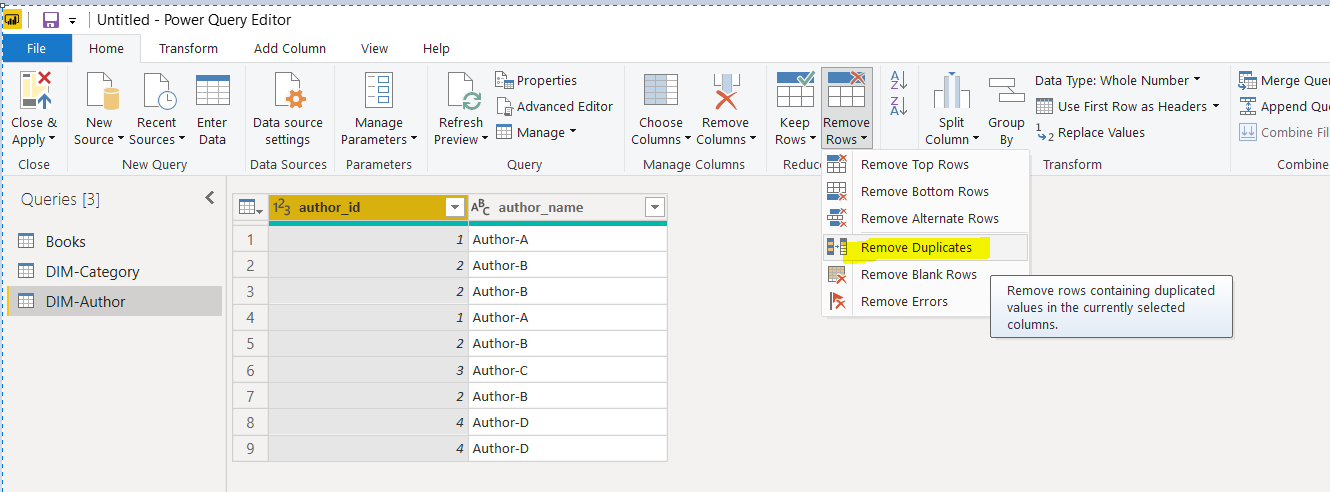
Next, remove the duplicate columns from the DIM-Author query by clicking the “Remove Rows -> Remove Duplicates” option from the top menu.
接下来,通过单击顶部菜单中的“删除行->删除重复项”选项,从DIM-Author查询中删除重复的列。
The DIM-Author query will look like this once you remove the duplicates.
删除重复项后,DIM-Author查询将如下所示。
为书籍创建事实查询 (Creating a Fact Query for Books)
The final step is to create a fact query for Books. Again, create a new reference query.
最后一步是为Books创建一个事实查询。 再次,创建一个新的参考查询。
We can simply remove the author_name and category_name columns to create a fact query for books.
我们只需删除author_name和category_name列即可创建图书的事实查询。
However, to make sure that the category_id and author_id columns actually refer to the category_id and author_id columns of the DIM-Category and DIM-Author queries, we will take a different approach. So click on “Merge Queries” option from the top menu as shown below:
但是,为了确保category_id和author_id列实际上引用了DIM-Category和DIM-Author查询的category_id和author_id列,我们将采用另一种方法。 因此,从顶部菜单中单击“合并查询”选项,如下所示:
Next select the category_name column from the Fact-Book query and from the DIM-Category query, also select category_name as shown below. Click the “OK” button.
接下来,从事实书查询和DIM-Category查询中选择category_name列,还选择category_name,如下所示。 点击“确定”按钮。
You will see the DIM-Category column in the FACT-Book query.
您将在FACT-Book查询中看到DIM-Category列。
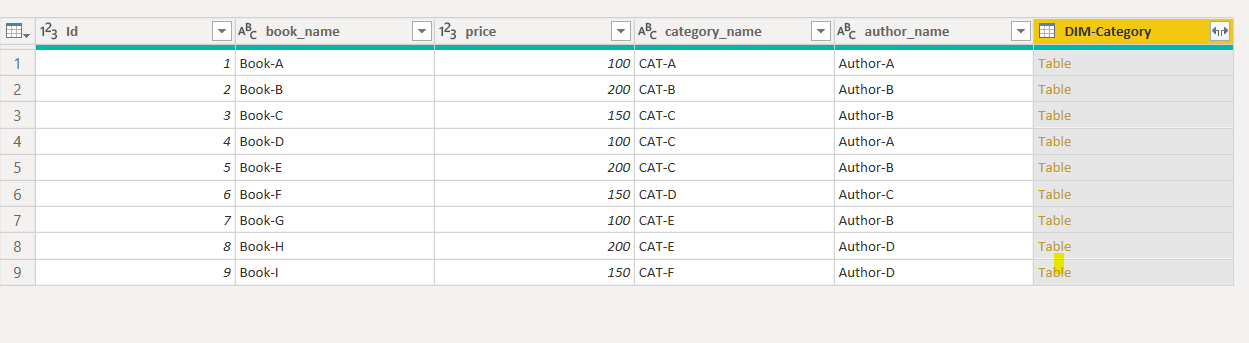
Click on the button on the extreme right in the DIM-Category column header. You will see the following window.
单击DIM-Category列标题中最右端的按钮。 您将看到以下窗口。
Select the “category_id” column and you will see a column “DIM-Category.category_id” in the FACT-Book query as shown below. This column actually refers to the category_id column of the DIM-Category query and connects it with the FACT-Book.
选择“ category_id”列,您将在FACT-Book查询中看到“ DIM-Category.category_id”列,如下所示。 该列实际上是指DIM类别查询的category_id列,并将其与FACT-Book关联。
In the same way, you can merge the author_name column of the DIM-Author and FACT-Book query as shown below:
以相同的方式,您可以合并DIM-Author和FACT-Book查询的author_name列,如下所示:
Finally, remove the author_name, and category_name columns to get the final version of the FACT-Book query.
最后,删除author_name和category_name列以获取FACT-Book查询的最终版本。
结论 (Conclusion)
Star schema is one of the most commonly used schemas for logical implementation of related data. This article shows how to implement the star schema in Power BI Query Editor, with the help of an example.
星型模式是用于相关数据的逻辑实现的最常用模式之一。 本文通过一个示例说明如何在Power BI查询编辑器中实现星形模式。
翻译自: https://www.sqlshack.com/implementing-star-schemas-in-power-bi-desktop/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









