





python中的内存管理
Ever wonder how Python handles your data behind the scenes? How are your variables stored in memory? When do they get deleted?
有没有想过Python如何在后台处理您的数据? 您的变量如何存储在内存中? 他们什么时候被删除?
In this article, we’re going to do a deep dive into the internals of Python to understand how it handles memory management.
在本文中,我们将深入研究Python的内部结构,以了解其如何处理内存管理。
By the end of this article, you’ll:
到本文结尾,您将:
- Learn more about low-level computing, specifically as relates to memory
- Understand how Python abstracts lower-level operations
- Learn about Python’s internal memory management algorithms
- 了解有关低级计算的更多信息,特别是与内存有关的信息
- 了解Python如何抽象底层操作
- 了解Python的内部内存管理算法
Understanding Python’s internals will also give you better insight into some of Python’s behaviors. Hopefully, you’ll gain a new appreciation for Python as well. So much logic is happening behind the scenes to ensure your program works the way you expect.
了解Python的内部结构还可以使您更好地了解Python的某些行为。 希望您也会对Python也有新的了解。 幕后发生了太多的逻辑,以确保您的程序按预期方式工作。
Free Bonus: 5 Thoughts On Python Mastery, a free course for Python developers that shows you the roadmap and the mindset you’ll need to take your Python skills to the next level.
免费奖金: 关于Python精通的5个想法 ,这是针对Python开发人员的免费课程,向您展示了将Python技能提升到新水平所需的路线图和心态。
记忆是一本空书 (Memory Is an Empty Book)
You can begin by thinking of a computer’s memory as an empty book intended for short stories. There’s nothing written on the pages yet. Eventually, different authors will come along. Each author wants some space to write their story in.
您可以首先将计算机的内存视为一本空谈的短篇小说。 页面上还没有任何内容。 最终,会有不同的作者出现。 每个作者都需要一些空间来写他们的故事。
Since they aren’t allowed to write over each other, they must be careful about which pages they write in. Before they begin writing, they consult the manager of the book. The manager then decides where in the book they’re allowed to write.
由于不允许彼此书写,因此必须注意书写的页面。开始书写之前,请先咨询书籍的管理员。 然后,经理决定允许他们在书中写什么。
Since this book is around for a long time, many of the stories in it are no longer relevant. When no one reads or references the stories, they are removed to make room for new stories.
由于本书已经存在很长时间了,因此本书中的许多故事都不再适用。 当没有人阅读或参考故事时,它们将被删除以为新故事腾出空间。
In essence, computer memory is like that empty book. In fact, it’s common to call fixed-length contiguous blocks of memory pages, so this analogy holds pretty well.
本质上,计算机内存就像一本空书。 实际上,调用固定长度的连续内存页块是很常见的,因此这种类推非常适用。
The authors are like different applications or processes that need to store data in memory. The manager, who decides where the authors can write in the book, plays the role of a memory manager of sorts. The person who removed the old stories to make room for new ones is a garbage collector.
作者就像需要将数据存储在内存中的不同应用程序或流程。 决定作者可以在书中写哪些位置的管理者扮演着各种存储管理者的角色。 删除旧故事为新故事腾出空间的人是垃圾收集者。
内存管理:从硬件到软件 (Memory Management: From Hardware to Software)
Memory management is the process by which applications read and write data. A memory manager determines where to put an application’s data. Since there’s a finite chunk of memory, like the pages in our book analogy, the manager has to find some free space and provide it to the application. This process of providing memory is generally called memory allocation.
内存管理是应用程序读写数据的过程。 内存管理器确定将应用程序数据放置在何处。 由于内存有限,就像本书中的类比页面一样,管理器必须找到一些可用空间并将其提供给应用程序。 提供内存的过程通常称为内存分配 。
On the flip side, when data is no longer needed, it can be deleted, or freed. But freed to where? Where did this “memory” come from?
另一方面,当不再需要数据时,可以将其删除或释放 。 但是释放到哪里? 这个“记忆”是从哪里来的?
Somewhere in your computer, there’s a physical device storing data when you’re running your Python programs. There are many layers of abstraction that the Python code goes through before the objects actually get to the hardware though.
当您运行Python程序时,在您计算机的某处有一个物理设备存储数据。 但是,在对象实际到达硬件之前,Python代码要经过很多抽象层。
One of the main layers above the hardware (such as RAM or a hard drive) is the operating system (OS). It carries out (or denies) requests to read and write memory.
硬件(例如RAM或硬盘驱动器)上方的主要层之一是操作系统(OS)。 它执行(或拒绝)读取和写入内存的请求。
Above the OS, there are applications, one of which is the default Python implementation (included in your OS or downloaded from python.org). Memory management for your Python code is handled by the Python application. The algorithms and structures that the Python application uses for memory management is the focus of this article.
在操作系统上方,有一些应用程序,其中之一是默认的Python实现(包含在您的操作系统中或从python.org下载)。 Python代码的内存管理由Python应用程序处理。 Python应用程序用于内存管理的算法和结构是本文的重点。
默认的Python实现 (The Default Python Implementation)
The default Python implementation, CPython, is actually written in the C programming language.
默认的Python实现CPython实际上是用C编程语言编写的。
When I first heard this, it blew my mind. A language that’s written in another language?! Well, not really, but sort of.
当我第一次听到这个消息时,我大吃一惊。 用另一种语言写的语言?! 好吧,不是真的,但是有点。
The Python language is defined in a reference manual written in English. However, that manual isn’t all that useful by itself. You still need something to interpret written code based on the rules in the manual.
Python语言在用英语编写的参考手册中定义。 但是,该手册本身并没有那么有用。 您仍然需要一些内容来根据手册中的规则解释书面代码。
You also need something to actually execute interpreted code on a computer. The default Python implementation fulfills both of those requirements. It converts your Python code into instructions that it then runs on a virtual machine.
您还需要一些东西才能在计算机上实际执行解释后的代码。 默认的Python实现同时满足这两个要求。 它将您的Python代码转换为指令,然后在虚拟机上运行。
Note: Virtual machines are like physical computers, but they are implemented in software. They typically process basic instructions similar to Assembly instructions.
Python is an interpreted programming language. Your Python code actually gets compiled down to more computer-readable instructions called bytecode. These instructions get interpreted by a virtual machine when you run your code.
Python是一种解释型编程语言。 实际上,您的Python代码已被编译为更多计算机可读指令,称为bytecode 。 运行代码时,虚拟机将解释这些指令。
Have you ever seen a .pyc file or a __pycache__ folder? That’s the bytecode that gets interpreted by the virtual machine.
您见过.pyc文件或__pycache__文件夹吗? 那是虚拟机解释的字节码。
It’s important to note that there are implementations other than CPython. IronPython compiles down to run on Microsoft’s Common Language Runtime. Jython compiles down to Java bytecode to run on the Java Virtual Machine. Then there’s PyPy, but that deserves its own entire article, so I’ll just mention it in passing.
重要的是要注意,除了CPython,还有其他实现。 IronPython可以向下编译以在Microsoft的公共语言运行时上运行。 Jython编译为Java字节码,以在Java虚拟机上运行。 然后是PyPy ,但这值得其撰写整篇文章,因此我只在顺带提及。
For the purposes of this article, I’ll focus on the memory management done by the default implementation of Python, CPython.
出于本文的目的,我将重点介绍由Python的默认实现CPython完成的内存管理。
Disclaimer: While a lot of this information will carry through to new versions of Python, things may change in the future. Note that the referenced version for this article is the current latest version of Python, 3.7.
免责声明 :尽管许多此类信息将保留到新版本的Python中,但未来情况可能会发生变化。 请注意,本文引用的版本是Python的当前最新版本3.7 。
Okay, so CPython is written in C, and it interprets Python bytecode. What does this have to do with memory management? Well, the memory management algorithms and structures exist in the CPython code, in C. To understand the memory management of Python, you have to get a basic understanding of CPython itself.
好的,所以CPython是用C编写的,它可以解释Python字节码。 这与内存管理有什么关系? 嗯,C中的CPython代码中存在内存管理算法和结构。要了解Python的内存管理,您必须对CPython本身有一个基本的了解。
CPython is written in C, which does not natively support object-oriented programming. Because of that, there are quite a bit of interesting designs in the CPython code.
CPython是用C编写的,它本身不支持面向对象的编程。 因此,CPython代码中有很多有趣的设计。
You may have heard that everything in Python is an object, even types such as int and str. Well, it’s true on an implementation level in CPython. There is a struct called a PyObject, which every other object in CPython uses.
您可能已经听说Python中的所有东西都是对象,甚至是int和str类的类型。 好吧,在CPython的实现级别上确实如此。 有一个称为PyObject的struct ,CPython中的所有其他对象都使用该结构。
Note: A struct, or structure, in C is a custom data type that groups together different data types. To compare to object-oriented languages, it’s like a class with attributes and no methods.
注意: C中的struct或structure是将不同数据类型组合在一起的自定义数据类型。 与面向对象的语言相比,它就像是具有属性且没有方法的类。
The PyObject, the grand-daddy of all objects in Python, contains only two things:
PyObject是Python中所有对象的祖父,仅包含两件事:
ob_refcnt: reference countob_type: pointer to another type
-
ob_refcnt:参考计数 -
ob_type:指向另一种类型的指针
The reference count is used for garbage collection. Then you have a pointer to the actual object type. That object type is just another struct that describes a Python object (such as a dict or int).
参考计数用于垃圾收集。 然后,您有一个指向实际对象类型的指针。 该对象类型只是描述Python对象的另一种struct (例如dict或int )。
Each object has its own object-specific memory allocator that knows how to get the memory to store that object. Each object also has an object-specific memory deallocator that “frees” the memory once it’s no longer needed.
每个对象都有自己的特定于对象的内存分配器,该分配器知道如何获取用于存储该对象的内存。 每个对象还具有一个特定于对象的内存释放器,一旦不再需要该内存,它就可以“释放”该内存。
However, there’s an important factor in all this talk about allocating and freeing memory. Memory is a shared resource on the computer, and bad things can happen if two different processes try to write to the same location at the same time.
但是,在所有有关分配和释放内存的讨论中,都有一个重要因素。 内存是计算机上的共享资源,如果两个不同的进程试图同时写入同一位置,则可能会发生不良情况。
全球口译员锁(GIL) (The Global Interpreter Lock (GIL))
The GIL is a solution to the common problem of dealing with shared resources, like memory in a computer. When two threads try to modify the same resource at the same time, they can step on each other’s toes. The end result can be a garbled mess where neither of the threads ends up with what they wanted.
GIL是解决共享资源(例如计算机内存)的常见问题的解决方案。 当两个线程尝试同时修改同一资源时,它们可以互相踩脚趾。 最终结果可能是乱码,其中两个线程都没有达到他们想要的结果。
Consider the book analogy again. Suppose that two authors stubbornly decide that it’s their turn to write. Not only that, but they both need to write on the same page of the book at the same time.
再次考虑这本书的类比。 假设有两位作者顽固地决定轮到他们写作了。 不仅如此,而且他们都需要同时在书的同一页上书写。
They each ignore the other’s attempt to craft a story and begin writing on the page. The end result is two stories on top of each other, which makes the whole page completely unreadable.
他们每个人都忽略了对方制作故事并开始在页面上写作的尝试。 最终结果是两个故事相互叠加,这使得整个页面完全不可读。
One solution to this problem is a single, global lock on the interpreter when a thread is interacting with the shared resource (the page in the book). In other words, only one author can write at a time.
解决此问题的一种方法是,当线程与共享资源(书中的页面)进行交互时,在解释器上进行单个全局锁定。 换句话说,一次只有一位作者可以写作。
Python’s GIL accomplishes this by locking the entire interpreter, meaning that it’s not possible for another thread to step on the current one. When CPython handles memory, it uses the GIL to ensure that it does so safely.
Python的GIL通过锁定整个解释器来实现这一点,这意味着另一个线程不可能踩到当前线程。 当CPython处理内存时,它使用GIL来确保安全地这样做。
There are pros and cons to this approach, and the GIL is heavily debated in the Python community. To read more about the GIL, I suggest checking out What is the Python Global Interpreter Lock (GIL)?.
这种方法各有利弊,GIL在Python社区中引起了激烈的争论。 要阅读有关GIL的更多信息,建议您检查一下什么是Python全局解释器锁(GIL)? 。
垃圾收集 (Garbage Collection)
Let’s revisit the book analogy and assume that some of the stories in the book are getting very old. No one is reading or referencing those stories anymore. If no one is reading something or referencing it in their own work, you could get rid of it to make room for new writing.
让我们重新看一下这本书的类比,并假设书中的某些故事已经很老了。 没有人正在阅读或引用这些故事。 如果没有人在自己的作品中阅读或引用某些东西,则可以摆脱它,为新的写作腾出空间。
That old, unreferenced writing could be compared to an object in Python whose reference count has dropped to 0. Remember that every object in Python has a reference count and a pointer to a type.
可以将未引用的旧文字与Python中引用计数已降至0的对象进行比较。 请记住,Python中的每个对象都有一个引用计数和一个指向类型的指针。
The reference count gets increased for a few different reasons. For example, the reference count will increase if you assign it to another variable:
引用计数由于一些不同的原因而增加。 例如,如果您将引用计数分配给另一个变量,它将增加:
numbers numbers = = [[ 11 , , 22 , , 33 ]
]
# Reference count = 1
# Reference count = 1
more_numbers more_numbers = = numbers
numbers
# Reference count = 2
# Reference count = 2
It will also increase if you pass the object as an argument:
如果将对象作为参数传递,它也会增加:
As a final example, the reference count will increase if you include the object in a list:
作为最后一个示例,如果将对象包括在列表中,则引用计数将增加:
matrix matrix = = [[ numbersnumbers , , numbersnumbers , , numbersnumbers ]
]
Python allows you to inspect the current reference count of an object with the sys module. You can use sys.getrefcount(numbers), but keep in mind that passing in the object to getrefcount() increases the reference count by 1.
Python允许您使用sys模块检查对象的当前引用计数。 您可以使用sys.getrefcount(numbers) ,但是请记住,将对象传递给getrefcount()会使引用计数增加1 。
In any case, if the object is still required to hang around in your code, its reference count is greater than 0. Once it drops to 0, the object has a specific deallocation function that is called which “frees” the memory so that other objects can use it.
无论如何,如果仍然需要将该对象在代码中徘徊,则其引用计数大于0 。 一旦降为0 ,该对象就会具有一个特定的释放函数,该函数将释放内存,以便其他对象可以使用它。
But what does it mean to “free” the memory, and how do other objects use it? Let’s jump right into CPython’s memory management.
但是“释放”内存是什么意思,其他对象如何使用它呢? 让我们直接进入CPython的内存管理。
CPython的内存管理 (CPython’s Memory Management)
We’re going to dive deep into CPython’s memory architecture and algorithms, so buckle up.
我们将深入研究CPython的内存体系结构和算法,因此请锁定。
As mentioned before, there are layers of abstraction from the physical hardware to CPython. The operating system (OS) abstracts the physical memory and creates a virtual memory layer that applications (including Python) can access.
如前所述,从物理硬件到CPython都有抽象层。 操作系统(OS)提取物理内存并创建应用程序(包括Python)可以访问的虚拟内存层。
An OS-specific virtual memory manager carves out a chunk of memory for the Python process. The darker gray boxes in the image below are now owned by the Python process.
特定于操作系统的虚拟内存管理器为Python进程占用了大量内存。 下图的深灰色框现在归Python进程所有。
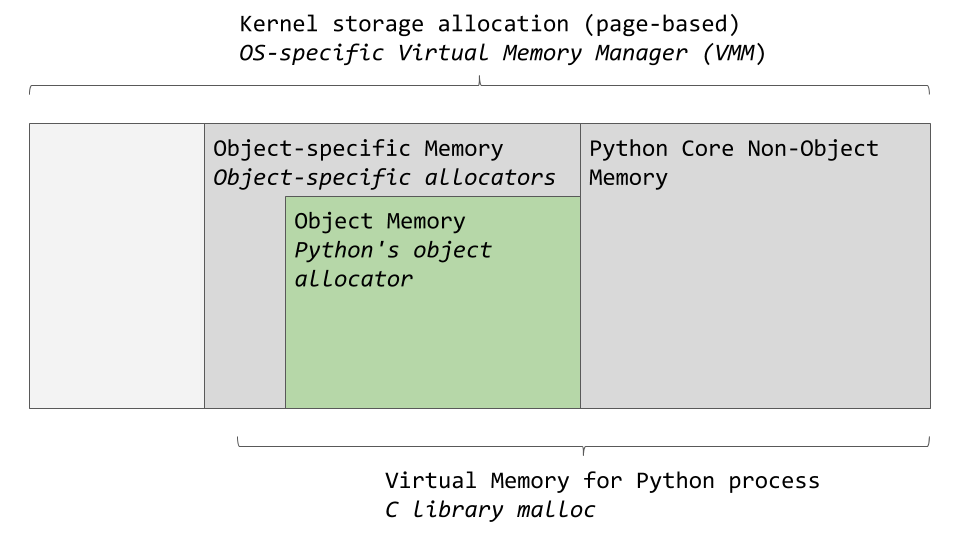
Python uses a portion of the memory for internal use and non-object memory. The other portion is dedicated to object storage (your int, dict, and the like). Note that this was somewhat simplified. If you want the full picture, you can check out the CPython source code, where all this memory management happens.
Python将部分内存用于内部使用和非对象内存。 另一部分专用于对象存储(您的int , dict等)。 请注意,这已被简化。 如果您需要完整的图片,可以签出CPython源代码 ,所有这些内存管理都在其中进行。
CPython has an object allocator that is responsible for allocating memory within the object memory area. This object allocator is where most of the magic happens. It gets called every time a new object needs space allocated or deleted.
CPython有一个对象分配器,负责在对象内存区域内分配内存。 这个对象分配器是大多数魔术发生的地方。 每当新对象需要分配或删除空间时,都会调用该方法。
Typically, the adding and removing of data for Python objects like list and int doesn’t involve too much data at a time. So the design of the allocator is tuned to work well with small amounts of data at a time. It also tries not to allocate memory until it’s absolutely required.
通常,为list和int等Python对象添加和删除数据一次不会涉及太多数据。 因此,分配器的设计已调整为可以同时处理少量数据。 它还尝试在绝对需要之前不分配内存。
The comments in the source code describe the allocator as “a fast, special-purpose memory allocator for small blocks, to be used on top of a general-purpose malloc.” In this case, malloc is C’s library function for memory allocation.
源代码中的注释将分配器描述为“一种用于小块的快速,专用内存分配器,将在通用malloc的顶部使用。” 在这种情况下, malloc是C的用于分配内存的库函数。
Now we’ll look at CPython’s memory allocation strategy. First, we’ll talk about the 3 main pieces and how they relate to each other.
现在,我们来看一下CPython的内存分配策略。 首先,我们将讨论这三个主要部分以及它们之间的关系。
Arenas are the largest chunks of memory and are aligned on a page boundary in memory. A page boundary is the edge of a fixed-length contiguous chunk of memory that the OS uses. Python assumes the system’s page size is 256 kilobytes.
Arenas是最大的内存块,并在内存中的页面边界上对齐。 页面边界是操作系统使用的固定长度连续内存块的边缘。 Python假定系统的页面大小为256 KB。

Within the arenas are pools, which are one virtual memory page (4 kilobytes). These are like the pages in our book analogy. These pools are fragmented into smaller blocks of memory.
竞技场内有池,池是一个虚拟内存页面(4 KB)。 这些就像我们书中类比的页面。 这些池被分成较小的内存块。
All the blocks in a given pool are of the same “size class.” A size class defines a specific block size, given some amount of requested data. The chart below is taken directly from the source code comments:
给定池中的所有块都具有相同的“大小等级”。 给定一定数量的请求数据,大小类定义特定的块大小。 下图直接取自源代码注释:
| Request in bytes | 请求(以字节为单位) | Size of allocated block | 分配块的大小 | Size class idx | 尺寸等级IDX |
|---|---|---|---|---|---|
| 1-8 | 1-8 | 8 | 8 | 0 | 0 |
| 9-16 | 9-16 | 16 | 16 | 1 | 1个 |
| 17-24 | 17-24 | 24 | 24 | 2 | 2 |
| 25-32 | 25-32 | 32 | 32 | 3 | 3 |
| 33-40 | 33-40 | 40 | 40 | 4 | 4 |
| 41-48 | 41-48 | 48 | 48 | 5 | 5 |
| 49-56 | 49-56 | 56 | 56 | 6 | 6 |
| 57-64 | 57-64 | 64 | 64 | 7 | 7 |
| 65-72 | 65-72 | 72 | 72 | 8 | 8 |
| … | … | … | … | … | … |
| 497-504 | 497-504 | 504 | 504 | 62 | 62 |
| 505-512 | 505-512 | 512 | 512 | 63 | 63 |
For example, if 42 bytes are requested, the data would be placed into a size 48-byte block.
例如,如果请求42字节,则数据将被放入48字节大小的块中。
泳池 (Pools)
Pools are composed of blocks from a single size class. Each pool maintains a double-linked list to other pools of the same size class. In that way, the algorithm can easily find available space for a given block size, even across different pools.
池由单个大小类的块组成。 每个池维护一个到相同大小类的其他池的双向链接列表。 这样,即使在不同的池中,该算法也可以轻松找到给定块大小的可用空间。
A usedpools list tracks all the pools that have some space available for data for each size class. When a given block size is requested, the algorithm checks this usedpools list for the list of pools for that block size.
usedpools列表会跟踪所有具有一定空间可用于每个大小类的数据的池。 当请求给定的块大小时,算法会在此usedpools列表中检查该块大小的池列表。
Pools themselves must be in one of 3 states: used, full, or empty. A used pool has available blocks for data to be stored. A full pool’s blocks are all allocated and contain data. An empty pool has no data stored and can be assigned any size class for blocks when needed.
池本身必须处于以下三种状态之一: used , full或empty 。 used池具有可用的块,用于存储数据。 full池的块均已分配并包含数据。 empty池没有存储任何数据,可以在需要时为块分配任何大小的类。
A freepools list keeps track of all the pools in the empty state. But when do empty pools get used?
freepools列表跟踪处于empty状态的所有池。 但是什么时候使用空池呢?
Assume your code needs an 8-byte chunk of memory. If there are no pools in usedpools of the 8-byte size class, a fresh empty pool is initialized to store 8-byte blocks. This new pool then gets added to the usedpools list so it can be used for future requests.
假设您的代码需要8字节的内存块。 如果8字节大小类的usedpools中没有池,则初始化一个empty池以存储8字节块。 然后,此新池将添加到usedpools列表中,以便可用于将来的请求。
Say a full pool frees some of its blocks because the memory is no longer needed. That pool would get added back to the usedpools list for its size class.
说一个full池释放了它的一些块,因为不再需要内存。 该池将被添加回其大小级别的usedpools列表中。
You can see now how pools can move between these states (and even memory size classes) freely with this algorithm.
现在,您将看到使用此算法,池如何在这些状态(甚至是内存大小类)之间自由移动。
积木 (Blocks)
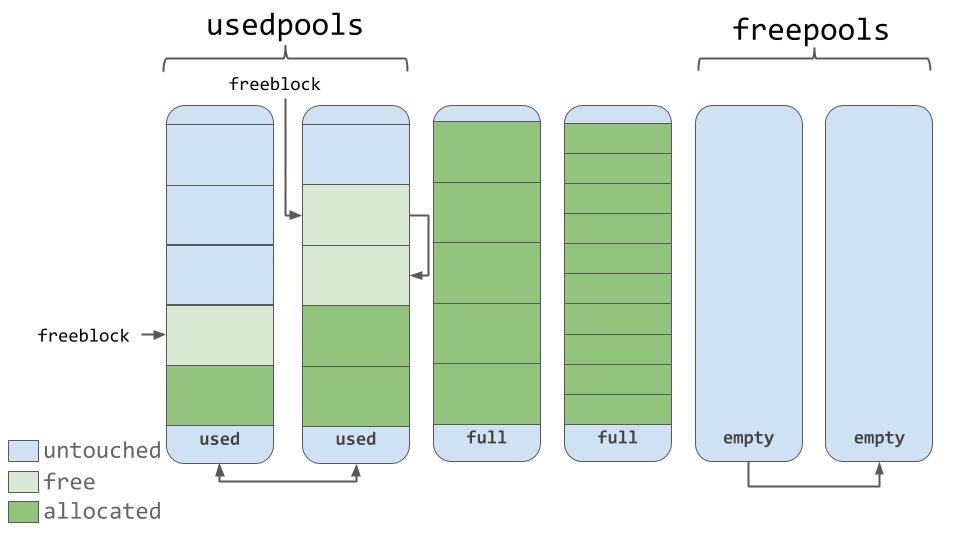
As seen in the diagram above, pools contain a pointer to their “free” blocks of memory. There’s a slight nuance to the way this works. This allocator “strives at all levels (arena, pool, and block) never to touch a piece of memory until it’s actually needed,” according to the comments in the source code.
如上图所示,池包含一个指向其“空闲”内存块的指针。 运作方式略有细微差别。 根据源代码中的注释,此分配器“努力在各个级别(区域,池和块)努力直到真正需要时才接触内存”。
That means that a pool can have blocks in 3 states. These states can be defined as follows:
这意味着一个池可以有3种状态的块。 这些状态可以定义如下:
untouched: a portion of memory that has not been allocatedfree: a portion of memory that was allocated but later made “free” by CPython and that no longer contains relevant dataallocated: a portion of memory that actually contains relevant data
-
untouched:尚未分配的一部分内存 -
free:分配的一部分内存,但后来由CPython使其“空闲”,并且不再包含相关数据 -
allocated:实际包含相关数据的内存部分
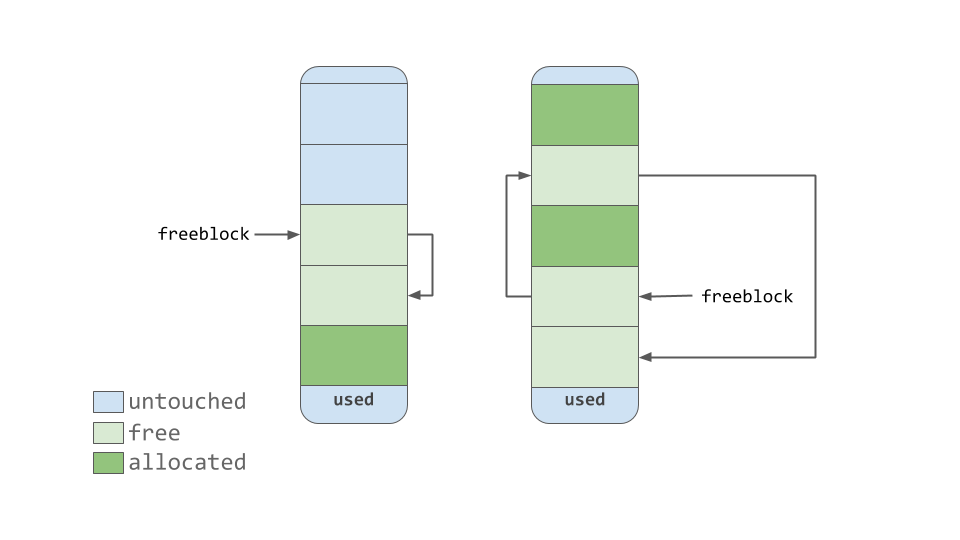
The freeblock pointer points to a singly linked list of free blocks of memory. In other words, a list of available places to put data. If more than the available free blocks are needed, the allocator will get some untouched blocks in the pool.
freeblock指针指向内存的空闲块的单链接列表。 换句话说,是放置数据的可用位置的列表。 如果需要的可用块更多,分配器将在池中获得一些untouched块。
As the memory manager makes blocks “free,” those now free blocks get added to the front of the freeblock list. The actual list may not be contiguous blocks of memory, like the first nice diagram. It may look something like the diagram below:
由于内存管理器使块“自由”,那些现在free块被添加到前面freeblock列表。 实际的列表可能不是连续的内存块,例如第一个漂亮的图表。 它可能看起来像下面的图:
竞技场 (Arenas)
Arenas contain pools. Those pools can be used, full, or empty. Arenas themselves don’t have as explicit states as pools do though.
竞技场内有游泳池。 这些池可以被used , full或为empty 。 但是,Arenas本身并不像池那样具有明确的状态。
Arenas are instead organized into a doubly linked list called usable_arenas. The list is sorted by the number of free pools available. The fewer free pools, the closer the arena is to the front of the list.
相反,Arenas被组织成一个名为usable_arenas的双向链接列表。 该列表按可用空闲池的数量排序。 可用池越少,竞技场就越靠近列表的前面。
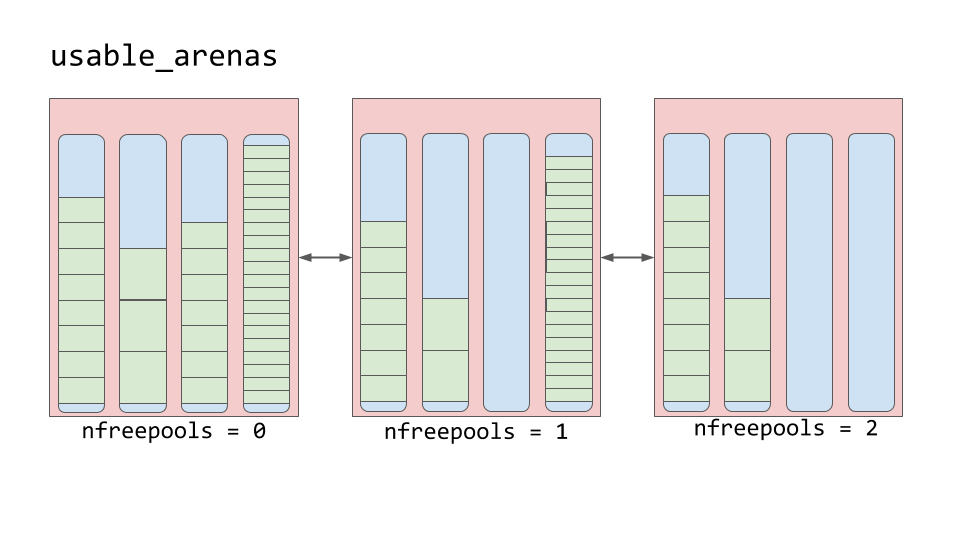
This means that the arena that is the most full of data will be selected to place new data into. But why not the opposite? Why not place data where there’s the most available space?
这意味着将选择数据最充分的区域来放置新数据。 但是为什么不相反呢? 为什么不将数据放在有最大可用空间的地方?
This brings us to the idea of truly freeing memory. You’ll notice that I’ve been saying “free” in quotes quite a bit. The reason is that when a block is deemed “free”, that memory is not actually freed back to the operating system. The Python process keeps it allocated and will use it later for new data. Truly freeing memory returns it to the operating system to use.
这使我们想到了真正释放内存的想法。 您会注意到,我在报价中一直说“免费”。 原因是当一个块被视为“空闲”时,该内存实际上并未释放回操作系统。 Python进程会对其进行分配,并将在以后将其用于新数据。 真正释放内存会将其返回给操作系统使用。
Arenas are the only things that can truly be freed. So, it stands to reason that those arenas that are closer to being empty should be allowed to become empty. That way, that chunk of memory can be truly freed, reducing the overall memory footprint of your Python program.
竞技场是唯一可以真正释放的东西。 因此,理所应当的是,应该允许那些更接近空旷的舞台变成空旷的。 这样,就可以真正释放该内存块,从而减少Python程序的总体内存占用。
结论 (Conclusion)
Memory management is an integral part of working with computers. Python handles nearly all of it behind the scenes, for better or for worse.
内存管理是使用计算机不可或缺的一部分。 无论好坏,Python几乎都会在后台处理所有问题。
In this article, you learned:
在本文中,您了解了:
- What memory management is and why it’s important
- How the default Python implementation, CPython, is written in the C programming language
- How the data structures and algorithms work together in CPython’s memory management to handle your data
- 什么是内存管理及其重要性
- 默认的Python实现CPython如何用C编程语言编写
- 数据结构和算法如何在CPython的内存管理中协同工作以处理数据
Python abstracts away a lot of the gritty details of working with computers. This gives you the power to work on a higher level to develop your code without the headache of worrying about how and where all those bytes are getting stored.
Python提取了许多使用计算机的严格细节。 这使您能够在更高级别上进行工作以开发代码,而不必担心所有字节的存储方式和位置。
翻译自: https://www.pybloggers.com/2018/11/memory-management-in-python/
python中的内存管理















 1523
1523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









