





python并发程序
If you’ve heard lots of talk about asyncio being added to Python but are curious how it compares to other concurrency methods or are wondering what concurrency is and how it might speed up your program, you’ve come to the right place.
如果您听到过很多关于将asyncio 添加到Python的讨论,但是好奇如何将它与其他并发方法进行比较,或者想知道什么是并发以及它如何加快程序速度,那么您来对地方了。
In this article, you’ll learn the following:
在本文中,您将学到以下内容:
- What concurrency is
- What parallelism is
- How some of Python’s concurrency methods compare, including
threading,asyncio, andmultiprocessing - When to use concurrency in your program and which module to use
- 什么是并发
- 什么是并行性
- 如何比较Python的一些并发方法 ,包括
threading,asyncio和multiprocessing - 何时在程序中使用并发以及使用哪个模块
This article assumes that you have a basic understanding of Python and that you’re using at least version 3.6 to run the examples. You can download the examples from the Real Python GitHub repo.
本文假定您对Python有基本的了解,并且至少使用3.6版来运行示例。 您可以从Real Python GitHub repo下载示例。
Free Bonus: 5 Thoughts On Python Mastery, a free course for Python developers that shows you the roadmap and the mindset you’ll need to take your Python skills to the next level.
免费奖金: 关于Python精通的5个想法 ,这是针对Python开发人员的免费课程,向您展示了将Python技能提升到新水平所需的路线图和心态。
什么是并发? (What Is Concurrency?)
The dictionary definition of concurrency is simultaneous occurrence. In Python, the things that are occurring simultaneously are called by different names (thread, task, process) but at a high level, they all refer to a sequence of instructions that run in order.
并发的字典定义是同时发生。 在Python中,同时发生的事物通过不同的名称(线程,任务,进程)进行调用,但在较高层次上,它们都引用了按顺序运行的指令序列。
I like to think of them as different trains of thought. Each one can be stopped at certain points, and the CPU or brain that is processing them can switch to a different one. The state of each one is saved so it can be restarted right where it was interrupted.
我喜欢将它们视为不同的思路。 每个人都可以在某些时候停下来,处理它们的CPU或大脑可以切换到另一个人。 每个状态都已保存,因此可以在中断的地方重新启动。
You might wonder why Python uses different words for the same concept. It turns out that threads, tasks, and processes are only the same if you view them from a high level. Once you start digging into the details, they all represent slightly different things. You’ll see more of how they are different as you progress through the examples.
您可能想知道为什么Python在同一概念中使用不同的词。 事实证明,只有从较高的角度来看,线程,任务和进程才是相同的。 一旦您开始研究细节,它们都代表了略有不同的事物。 在阅读示例时,您将更多地了解它们的不同之处。
Now let’s talk about the simultaneous part of that definition. You have to be a little careful because, when you get down to the details, only multiprocessing actually runs these trains of thought at literally the same time. Threading and asyncio both run on a single processor and therefore only run one at a time. They just cleverly find ways to take turns to speed up the overall process. Even though they don’t run different trains of thought simultaneously, we still call this concurrency.
现在让我们讨论该定义的同时部分。 您必须谨慎一些,因为当您深入细节时,实际上只有multiprocessing实际上在同一时间运行这些思路。 Threading和asyncio都在单个处理器上运行,因此一次只能运行一个。 他们只是巧妙地找到了轮流加快总体流程的方法。 即使他们不能同时运行不同的思路,我们仍然称其为并发。
The way the threads or tasks take turns is the big difference between threading and asyncio. In threading, the operating system actually knows about each thread and can interrupt it at any time to start running a different thread. This is called pre-emptive multitasking since the operating system can pre-empt your thread to make the switch.
线程或任务轮流的方式是threading和asyncio之间的最大区别。 在threading ,操作系统实际上了解每个线程,并且可以随时中断它以开始运行其他线程。 这被称为抢先式多任务处理,因为操作系统可以抢占您的线程来进行切换。
Pre-emptive multitasking is handy in that the code in the thread doesn’t need to do anything to make the switch. It can also be difficult because of that “at any time” phrase. This switch can happen in the middle of a single Python statement, even a trivial one like x = x + 1.
抢先式多任务处理非常方便,因为线程中的代码不需要执行任何操作即可进行切换。 由于存在“随时”一词,这也可能很困难。 此切换可能发生在单个Python语句的中间,甚至是琐碎的x = x + 1语句。
Asyncio, on the other hand, uses cooperative multitasking. The tasks must cooperate by announcing when they are ready to be switched out. That means that the code in the task has to change slightly to make this happen.
另一方面, Asyncio使用协作多任务处理 。 这些任务必须通过宣布何时准备好退出来进行协作。 这意味着任务中的代码必须稍作更改才能实现。
The benefit of doing this extra work up front is that you always know where your task will be swapped out. It will not be swapped out in the middle of a Python statement unless that statement is marked. You’ll see later how this can simplify parts of your design.
预先进行此额外工作的好处是,您始终知道任务将在哪里调出。 除非标记了该语句,否则它不会在Python语句中间交换出来。 稍后,您将看到这如何简化设计的各个部分。
什么是并行性? (What Is Parallelism?)
So far, you’ve looked at concurrency that happens on a single processor. What about all of those CPU cores your cool, new laptop has? How can you make use of them? multiprocessing is the answer.
到目前为止,您已经研究了在单个处理器上发生的并发性。 酷炫的新笔记本电脑拥有的所有这些CPU核心如何? 您如何利用它们? multiprocessing就是答案。
With multiprocessing, Python creates new processes. A process here can be thought of as almost a completely different program, though technically they’re usually defined as a collection of resources where the resources include memory, file handles and things like that. One way to think about it is that each process runs in its own Python interpreter.
通过multiprocessing ,Python创建了新的进程。 可以将这里的过程视为几乎完全不同的程序,尽管从技术上讲,它们通常被定义为资源的集合,其中资源包括内存,文件句柄以及类似的东西。 考虑它的一种方法是,每个进程都在自己的Python解释器中运行。
Because they are different processes, each of your trains of thought in a multiprocessing program can run on a different core. Running on a different core means that they actually can run at the same time, which is fabulous. There are some complications that arise from doing this, but Python does a pretty good job of smoothing them over most of the time.
因为它们是不同的过程,所以多处理程序中的每条思路都可以在不同的核心上运行。 在不同的内核上运行意味着它们实际上可以同时运行,这真是太好了。 这样做会带来一些复杂性,但是Python在大多数情况下都可以很好地平滑它们。
Now that you have an idea of what concurrency and parallelism are, let’s review their differences, and then we can look at why they can be useful:
现在您已经了解了并行和并行是什么,让我们回顾一下它们之间的差异,然后我们来看一下它们为何有用的原因:
| Concurrency Type | 并发类型 | Switching Decision | 切换决策 | Number of Processors | 处理器数量 |
|---|---|---|---|---|---|
threading)threading ) | The operating system decides when to switch tasks external to Python. | 操作系统决定何时切换Python外部的任务。 | 1 | 1个 | |
asyncio)asyncio ) | The tasks decide when to give up control. | 这些任务决定何时放弃控制权。 | 1 | 1个 | |
multiprocessing)multiprocessing ) | The processes all run at the same time on different processors. | 所有进程都在不同的处理器上同时运行。 | Many | 许多 |
Each of these types of concurrency can be useful. Let’s take a look at what types of programs they can help you speed up.
这些并发类型中的每一个都是有用的。 让我们看一下它们可以帮助您加快速度的程序类型。
并发何时有用? (When Is Concurrency Useful?)
Concurrency can make a big difference for two types of problems. These are generally called CPU-bound and I/O-bound.
并发可以对两种类型的问题产生很大的影响。 这些通常称为CPU绑定和I / O绑定。
I/O-bound problems cause your program to slow down because it frequently must wait for input/output (I/O) from some external resource. They arise frequently when your program is working with things that are much slower than your CPU.
受I / O约束的问题会导致程序变慢,因为它经常必须等待某些外部资源的输入/输出(I / O)。 当您的程序使用比CPU慢得多的东西时,它们经常出现。
Examples of things that are slower than your CPU are legion, but your program thankfully does not interact with most of them. The slow things your program will interact with most frequently are the file system and network connections.
比CPU慢的例子很多,但值得庆幸的是您的程序并未与其中的大多数交互。 您的程序最常与之交互的缓慢事物是文件系统和网络连接。
Let’s see what that looks like:
让我们看看它是什么样的:
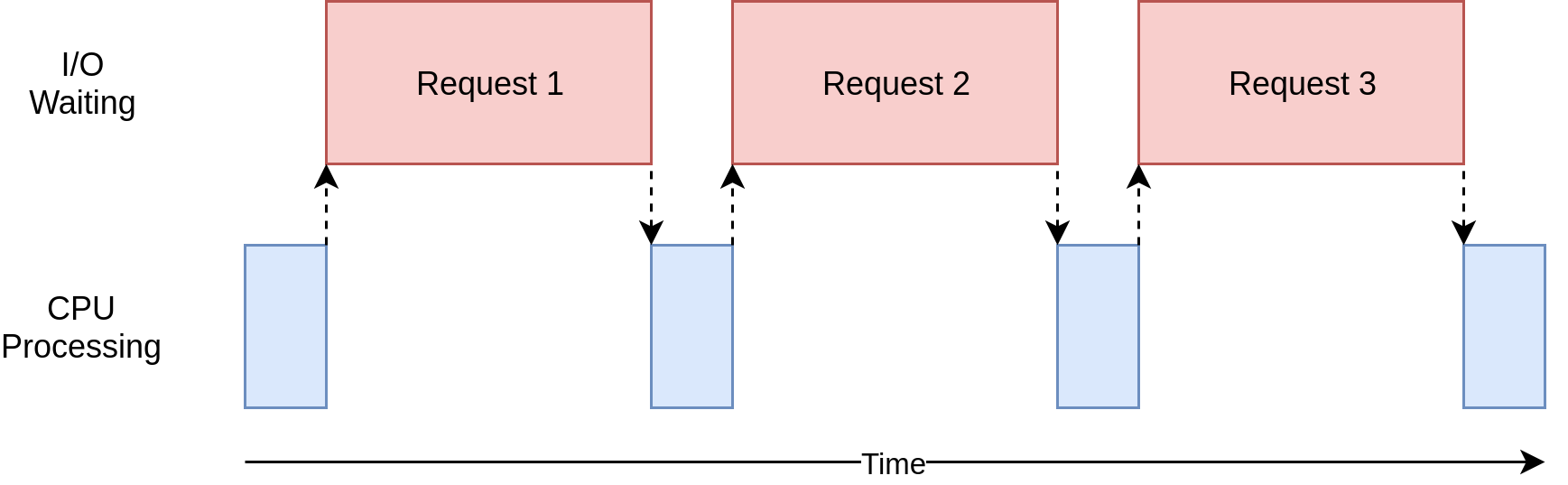
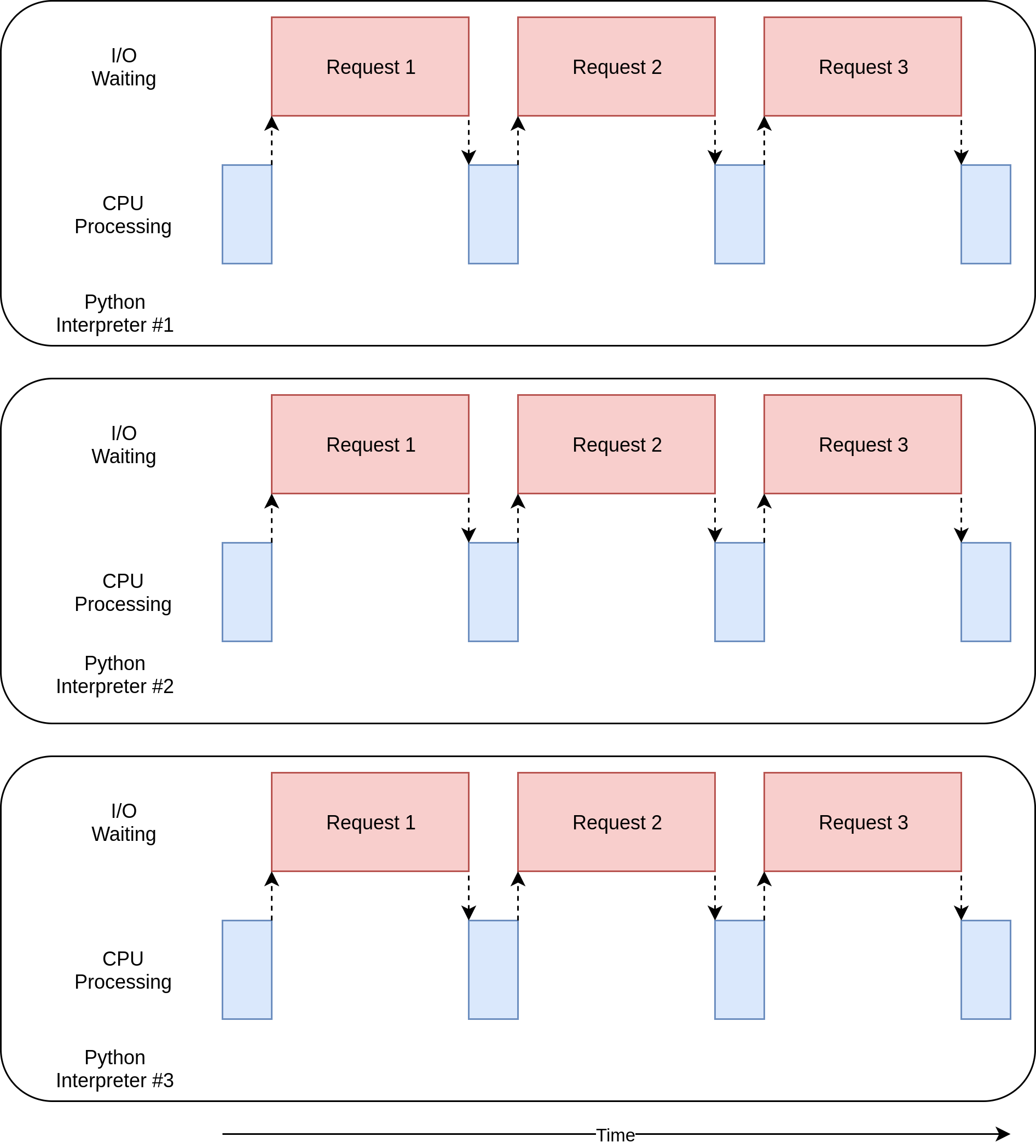
In the diagram above, the blue boxes show time when your program is doing work, and the red boxes are time spent waiting for an I/O operation to complete. This diagram is not to scale because requests on the internet can take several orders of magnitude longer than CPU instructions, so your program can end up spending most of its time waiting. This is what your browser is doing most of the time.
在上图中,蓝色框显示了程序执行工作的时间,红色框是等待I / O操作完成所花费的时间。 该图未按比例绘制,因为Internet上的请求可能比CPU指令花费几个数量级,因此您的程序最终可能会花费大部分时间等待。 这是您的浏览器大部分时间都在执行的操作。
On the flip side, there are classes of programs that do significant computation without talking to the network or accessing a file. These are the CPU-bound programs, because the resource limiting the speed of your program is the CPU, not the network or the file system.
另一方面,有些程序类无需进行网络计算或访问文件即可进行大量计算。 这些是与CPU绑定的程序,因为限制程序速度的资源是CPU,而不是网络或文件系统。
Here’s a corresponding diagram for a CPU-bound program:
这是CPU绑定程序的对应图:
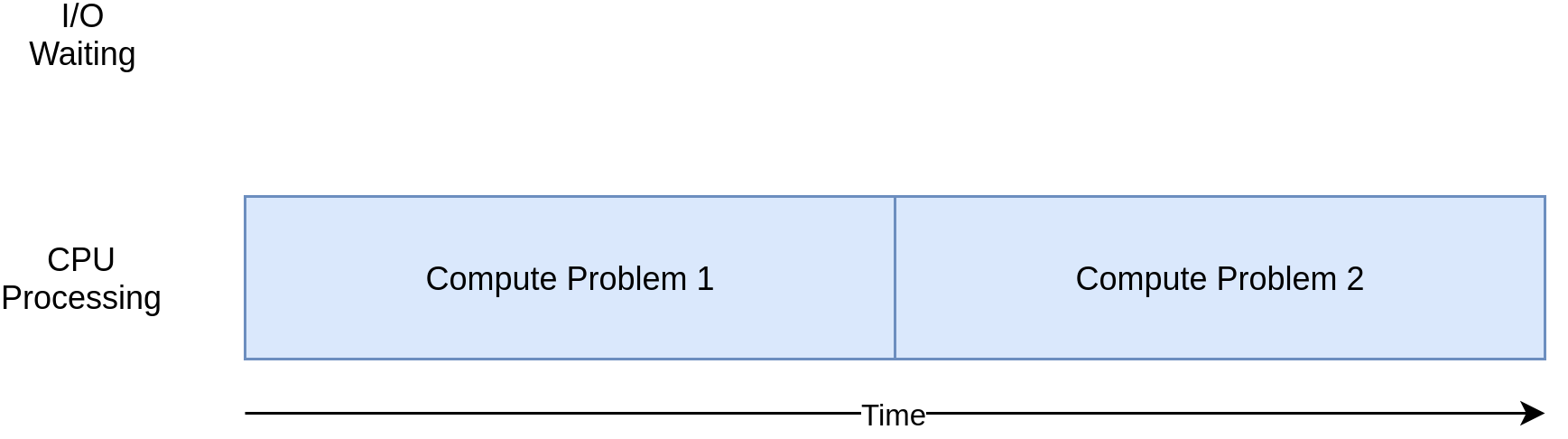
As you work through the examples in the following section, you’ll see that different forms of concurrency work better or worse with CPU-bound and I/O-bound programs. Adding concurrency to your program adds extra code and complications, so you’ll need to decide if the potential speed up is worth the extra effort. By the end of this article, you should have enough info to start making that decision.
在处理下一节中的示例时,您会发现,不同形式的并发在受CPU约束和受I / O约束的程序中表现更好或更差。 在程序中增加并发性会增加代码和复杂性,因此您需要确定潜在的加速是否值得付出额外的努力。 在本文末尾,您应该有足够的信息来开始做出该决定。
Here’s a quick summary to clarify this concept:
以下是简要说明,以阐明此概念:
| I/O-Bound Process | I / O绑定过程 | CPU-Bound Process | CPU绑定进程 |
|---|---|---|---|
| Your program spends most of its time talking to a slow device, like a network connection, a hard drive, or a printer. | 您的程序大部分时间都花在与速度较慢的设备(例如网络连接,硬盘驱动器或打印机)上进行交谈。 | You program spends most of its time doing CPU operations. | 您的程序大部分时间都花在CPU操作上。 |
| Speeding it up involves overlapping the times spent waiting for these devices. | 加快速度涉及使等待这些设备所花费的时间重叠。 | Speeding it up involves finding ways to do more computations in the same amount of time. | 加快速度需要找到在相同的时间内进行更多计算的方法。 |
You’ll look at I/O-bound programs first. Then, you’ll get to see some code dealing with CPU-bound programs.
您将首先查看I / O绑定程序。 然后,您将看到一些处理CPU绑定程序的代码。
如何加快I / O限制程序 (How to Speed Up an I/O-Bound Program)
Let’s start by focusing on I/O-bound programs and a common problem: downloading content over the network. For our example, you will be downloading web pages from a few sites, but it really could be any network traffic. It’s just easier to visualize and set up with web pages.
让我们从关注I / O绑定程序和一个常见问题开始:通过网络下载内容。 对于我们的示例,您将从几个站点下载网页,但实际上可能是任何网络流量。 可视化和设置网页更加容易。
同步版本 (Synchronous Version)
We’ll start with a non-concurrent version of this task. Note that this program requires the requests module. You should run pip install requests before running it, probably using a virtualenv. This version does not use concurrency at all:
我们将从该任务的非并行版本开始。 请注意,该程序需要requests模块。 您应该在运行pip install requests之前运行它,可能使用virtualenv 。 此版本完全不使用并发:
import import requests
requests
import import time
time
def def download_sitedownload_site (( urlurl , , sessionsession ):
):
with with sessionsession .. getget (( urlurl ) ) as as responseresponse :
:
printprint (( ff "Read {len(response.content)} from "Read {len(response.content)} from {url}{url} "" )
)
def def download_all_sitesdownload_all_sites (( sitessites ):
):
with with requestsrequests .. SessionSession () () as as sessionsession :
:
for for url url in in sitessites :
:
download_sitedownload_site (( urlurl , , sessionsession )
)
if if __name__ __name__ == == "__main__""__main__" :
:
sites sites = = [
[
"http://www.jython.org""http://www.jython.org" ,
,
"http://olympus.realpython.org/dice""http://olympus.realpython.org/dice" ,
,
] ] * * 80
80
start_time start_time = = timetime .. timetime ()
()
download_all_sitesdownload_all_sites (( sitessites )
)
duration duration = = timetime .. timetime () () - - start_time
start_time
printprint (( ff "Downloaded {len(sites)} in "Downloaded {len(sites)} in {duration}{duration} seconds" seconds" )
)
As you can see, this is a fairly short program. download_site() just downloads the contents from a URL and prints the size. One small thing to point out is that we’re using a Session object from requests.
如您所见,这是一个相当短的程序。 download_site()只是从URL下载内容并打印大小。 需要指出的一点是,我们正在使用来自requests的Session对象。
It is possible to simply use get() from requests directly, but creating a Session object allows requests to do some fancy networking tricks and really speed things up.
可以直接从requests简单地使用get() ,但是创建Session对象可以使requests做一些花哨的网络技巧并真正加快速度。
download_all_sites() creates the Session and then walks through the list of sites, downloading each one in turn. Finally, it prints out how long this process took so you can have the satisfaction of seeing how much concurrency has helped us in the following examples.
download_all_sites()创建Session ,然后浏览站点列表,依次下载每个站点。 最后,它打印出此过程花费了多长时间,因此您可以满意地看到在以下示例中并发对我们的帮助。
The processing diagram for this program will look much like the I/O-bound diagram in the last section.
该程序的处理图看起来很像上一部分中的I / O绑定图。
Note: Network traffic is dependent on many factors that can vary from second to second. I’ve seen the times of these tests double from one run to another due to network issues.
注意:网络流量取决于许多因素,这些因素可能会每秒变化。 我已经看到由于网络问题,这些测试的时间从一次运行增加到另一次。
Why the Synchronous Version Rocks
为什么同步版本会摇摆
The great thing about this version of code is that, well, it’s easy. It was comparatively easy to write and debug. It’s also more straight-forward to think about. There’s only one train of thought running through it, so you can predict what the next step is and how it will behave.
这个版本的代码的优点在于,很容易。 编写和调试相对容易。 考虑起来也更加简单明了。 贯穿其中只有一条思路,因此您可以预测下一步是什么以及其行为方式。
The Problems With the Synchronous Version
同步版本存在的问题
The big problem here is that it’s relatively slow compared to the other solutions we’ll provide. Here’s an example of what the final output gave on my machine:
这里最大的问题是,与我们将提供的其他解决方案相比,它相对较慢。 这是最终输出在我的计算机上给出的示例:
Note: Your results may vary significantly. When running this script, I saw the times vary from 14.2 to 21.9 seconds. For this article, I took the fastest of three runs as the time. The differences between the methods will still be clear.
注意:您的结果可能会有很大差异。 运行此脚本时,我看到时间从14.2秒到21.9秒不等。 在本文中,我以最快的速度运行了三个时间。 两种方法之间的差异仍然很明显。
Being slower isn’t always a big issue, however. If the program you’re running takes only 2 seconds with a synchronous version and is only run rarely, it’s probably not worth adding concurrency. You can stop here.
但是,变慢并不总是一个大问题。 如果您正在运行的程序使用同步版本仅花费2秒,并且很少运行,则可能不值得添加并发性。 你可以在这里停下来。
What if your program is run frequently? What if it takes hours to run? Let’s move on to concurrency by rewriting this program using threading.
如果您的程序经常运行该怎么办? 如果要花几个小时运行怎么办? 让我们通过使用threading重写该程序来进行并发。
threading版本 (threading Version)
As you probably guessed, writing a threaded program takes more effort. You might be surprised at how little extra effort it takes for simple cases, however. Here’s what the same program looks like with threading:
您可能已经猜到了,编写线程程序会花费更多的精力。 但是,对于简单的案例,您花费很少的额外精力可能会感到惊讶。 这是带有threading的相同程序的外观:
import import concurrent.futures
concurrent.futures
import import requests
requests
import import threading
threading
import import time
time
thread_local thread_local = = threadingthreading .. locallocal ()
()
def def get_sessionget_session ():
():
if if not not getattrgetattr (( thread_localthread_local , , "session""session" , , NoneNone ):
):
thread_localthread_local .. session session = = requestsrequests .. SessionSession ()
()
return return thread_localthread_local .. session
session
def def download_sitedownload_site (( urlurl ):
):
session session = = get_sessionget_session ()
()
with with sessionsession .. getget (( urlurl ) ) as as responseresponse :
:
printprint (( ff "Read {len(response.content)} from "Read {len(response.content)} from {url}{url} "" )
)
def def download_all_sitesdownload_all_sites (( sitessites ):
):
with with concurrentconcurrent .. futuresfutures .. ThreadPoolExecutorThreadPoolExecutor (( max_workersmax_workers == 55 ) ) as as executorexecutor :
:
executorexecutor .. mapmap (( download_sitedownload_site , , sitessites )
)
if if __name__ __name__ == == "__main__""__main__" :
:
sites sites = = [
[
"http://www.jython.org""http://www.jython.org" ,
,
"http://olympus.realpython.org/dice""http://olympus.realpython.org/dice" ,
,
] ] * * 80
80
start_time start_time = = timetime .. timetime ()
()
download_all_sitesdownload_all_sites (( sitessites )
)
duration duration = = timetime .. timetime () () - - start_time
start_time
printprint (( ff "Downloaded {len(sites)} in "Downloaded {len(sites)} in {duration}{duration} seconds" seconds" )
)
When you add threading, the overall structure is the same and you only needed to make a few changes. download_all_sites() changed from calling the function once per site to a more complex structure.
添加threading ,总体结构相同,只需要进行一些更改。 download_all_sites()从每个站点调用一次功能更改为更复杂的结构。
In this version, you’re creating a ThreadPoolExecutor, which seems like a complicated thing. Let’s break that down: ThreadPoolExecutor = Thread + Pool + Executor.
在此版本中,您正在创建ThreadPoolExecutor ,这似乎很复杂。 让我们分解一下: ThreadPoolExecutor = Thread + Pool + Executor 。
You already know about the Thread part. That’s just a train of thought we mentioned earlier. The Pool portion is where it starts to get interesting. This object is going to create a pool of threads, each of which can run concurrently. Finally, the Executor is the part that’s going to control how and when each of the threads in the pool will run. It will execute the request in the pool.
您已经了解Thread部分。 这只是我们前面提到的思路。 Pool部分开始变得有趣。 该对象将创建一个线程池,每个线程可以同时运行。 最后, Executor是控制池中每个线程如何以及何时运行的部分。 它将在池中执行请求。
Helpfully, the standard library implements ThreadPoolExecutor as a context manager so you can use the with syntax to manage creating and freeing the pool of Threads.
有用的是,标准库将ThreadPoolExecutor实现为上下文管理器,因此您可以使用with语法来管理创建和释放Threads池。
Once you have a ThreadPoolExecutor, you can use its handy .map() method. This method runs the passed-in function on each of the sites in the list. The great part is that it automatically runs them concurrently using the pool of threads it is managing.
一旦有了ThreadPoolExecutor ,就可以使用它的方便的.map()方法。 此方法在列表中的每个站点上运行传递的功能。 最重要的是,它会使用其管理的线程池自动并发运行它们。
Those of you coming from other languages, or even Python 2, are probably wondering where the usual objects and functions are that manage the details you’re used to when dealing with threading, things like Thread.start(), Thread.join(), and Queue.
那些来自其他语言甚至Python 2的人可能想知道普通对象和函数在哪里,这些对象和函数可以管理处理threading时所习惯的细节,例如Thread.start() , Thread.join()和Queue 。
These are all still there, and you can use them to achieve fine-grained control of how your threads are run. But, starting with Python 3.2, the standard library added a higher-level abstraction called Executors that manage many of the details for you if you don’t need that fine-grained control.
这些都仍然存在,您可以使用它们来实现对线程运行方式的细粒度控制。 但是,从Python 3.2开始,标准库添加了一个称为Executors的更高级别的抽象,如果不需要细粒度的控件,它可以为您管理许多细节。
The other interesting change in our example is that each thread needs to create its own requests.Session() object. When you’re looking at the documentation for requests, it’s not necessarily easy to tell, but reading this issue, it seems fairly clear that you need a separate Session for each thread.
我们的示例中另一个有趣的变化是,每个线程都需要创建自己的requests.Session()对象。 当您查看有关requests的文档时,不一定很容易分辨出来,但是阅读此问题 ,显然,每个线程都需要一个单独的Session。
This is one of the interesting and difficult issues with threading. Because the operating system is in control of when your task gets interrupted and another task starts, any data that is shared between the threads needs to be protected, or thread-safe. Unfortunately requests.Session() is not thread-safe.
这是threading有趣且棘手的问题之一。 因为操作系统控制着您的任务何时中断以及另一个任务开始,所以线程之间共享的任何数据都必须受到保护,或者是线程安全的。 不幸的是, requests.Session()不是线程安全的。
There are several strategies for making data accesses thread-safe depending on what the data is and how you’re using it. One of them is to use thread-safe data structures like Queue from Python’s queue module.
根据数据是什么以及如何使用数据,有几种使数据访问线程安全的策略。 其中之一是使用线程安全的数据结构,例如Python queue模块中的Queue 。
These objects use low-level primitives like threading.Lock to ensure that only one thread can access a block of code or a bit of memory at the same time. You are using this strategy indirectly by way of the ThreadPoolExecutor object.
这些对象使用诸如threading.Lock类的低级原语,以确保只有一个线程可以同时访问一块代码或一部分内存。 您是通过ThreadPoolExecutor对象间接使用此策略的。
Another strategy to use here is something called thread local storage. Threading.local() creates an object that look like a global but is specific to each individual thread. In your example, this is done with threadLocal and get_session():
这里使用的另一种策略是称为线程本地存储。 Threading.local()创建一个看起来像全局对象的对象,但该对象特定于每个单独的线程。 在您的示例中,这是通过threadLocal和get_session() :
ThreadLocal is in the threading module to specifically solve this problem. It looks a little odd, but you only want to create one of these objects, not one for each thread. The object itself takes care of separating accesses from different threads to different data.
ThreadLocal在threading模块中专门用于解决此问题。 看起来有些奇怪,但是您只想创建这些对象之一,而不是为每个线程创建一个。 对象本身负责将来自不同线程的访问分离到不同的数据。
When get_session() is called, the session it looks up is specific to the particular thread on which it’s running. So each thread will create a single session the first time it calls get_session() and then will simply use that session on each subsequent call throughout its lifetime.
调用get_session() ,它查找的session是特定于其正在运行的特定线程的。 因此,每个线程将在首次调用get_session()时创建一个会话,然后在整个生命周期中仅在随后的每次调用中使用该会话。
Finally, a quick note about picking the number of threads. You can see that the example code uses 5 threads. Feel free to play around with this number and see how the overall time changes. You might expect that having one thread per download would be the fastest but, at least on my system it was not. I found the fastest results somewhere between 5 and 10 threads. If you go any higher than that, then the extra overhead of creating and destroying the threads erases any time savings.
最后,简要介绍一下选择线程数的方法。 您可以看到示例代码使用5个线程。 随意使用此数字,看看整体时间如何变化。 您可能希望每次下载只有一个线程是最快的,但是至少在我的系统上不是。 我发现最快的结果在5到10个线程之间。 如果您的要求更高,那么创建和销毁线程的额外开销将消除任何时间节省。
The difficult answer here is that the correct number of threads is not a constant from one task to another. Some experimentation is required.
此处的难题是,从一个任务到另一个任务,正确的线程数并不是一个常数。 需要一些实验。
Why the threading Version Rocks
为什么threading版本会摇摆
It’s fast! Here’s the fastest run of my tests. Remember that the non-concurrent version took more than 14 seconds:
它很快! 这是我测试的最快速度。 请记住,非并行版本花费了超过14秒的时间:
$ ./io_threading.py
$ ./io_threading.py
[most output skipped]
[most output skipped]
Downloaded 160 in 3.7238826751708984 seconds
Downloaded 160 in 3.7238826751708984 seconds
Here’s what its execution timing diagram looks like:
其执行时序图如下所示:
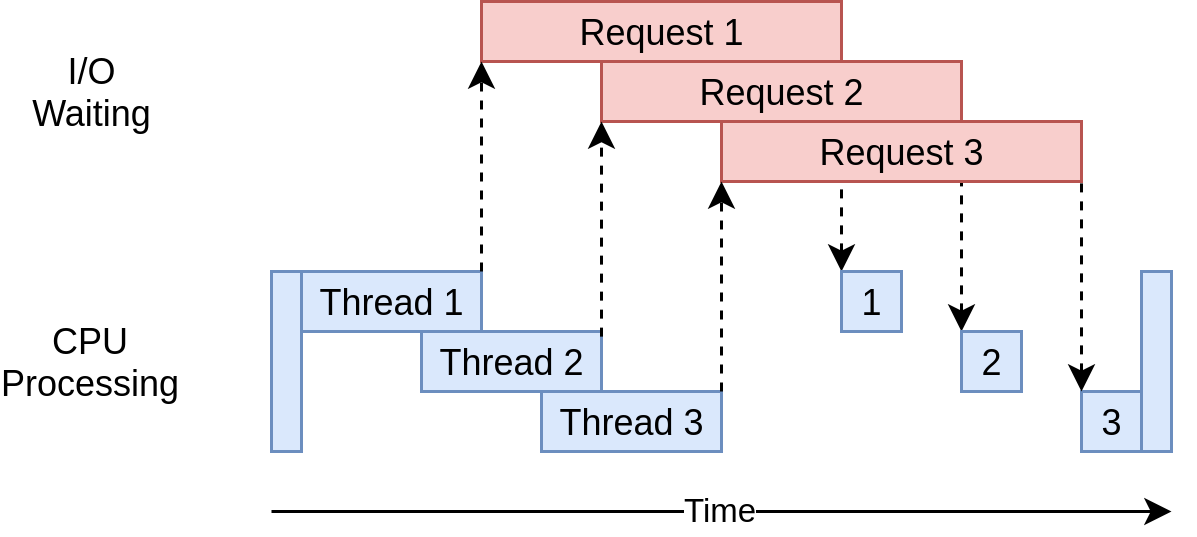
It uses multiple threads to have multiple open requests out to web sites at the same time, allowing your program to overlap the waiting times and get the final result faster! Yippee! That was the goal.
它使用多个线程来同时向网站发出多个打开的请求,从而使您的程序可以重叠等待时间,从而更快地获得最终结果! pp! 那是目标。
The Problems with the threading Version
threading版本的问题
Well, as you can see from the example, it takes a little more code to make this happen, and you really have to give some thought to what data is shared between threads.
好的,正如您从示例中看到的那样,需要花费一些代码才能实现此目的,并且您确实必须考虑线程之间共享的数据。
Threads can interact in ways that are subtle and hard to detect. These interactions can cause race conditions that frequently result in random, intermittent bugs that can be quite difficult to find. Those of you who are unfamiliar with the concept of race conditions might want to expand and read the section below.
线程可以以微妙且难以检测的方式进行交互。 这些相互作用会导致竞态条件,从而经常导致随机,间歇性的错误,这些错误很难发现。 那些不熟悉比赛条件概念的人可能想扩大阅读下面的部分。
Race conditions are an entire class of subtle bugs that can and frequently do happen in multi-threaded code. Race conditions happen because the programmer has not sufficiently protected data accesses to prevent threads from interfering with each other. You need to take extra steps when writing threaded code to ensure things are thread-safe.
竞争条件是一类细微的错误,它们经常在多线程代码中发生。 发生竞争情况是因为程序员没有充分保护数据访问以防止线程相互干扰。 在编写线程代码时,需要采取额外的步骤以确保事物是线程安全的。
What’s going on here is that the operating system is controlling when your thread runs and when it gets swapped out to let another thread run. This thread swapping can occur at any point, even while doing sub-steps of a Python statement. As a quick example, look at this function:
这里发生的是,操作系统正在控制何时运行线程以及何时将其换出以允许另一个线程运行。 即使执行Python语句的子步骤,此线程交换也可以随时发生。 举个简单的例子,看一下这个函数:
This code is quite similar to the structure you used in the threading example above. The difference is that each of the threads is accessing the same global variable counter and incrementing it. Counter is not protected in any way, so it is not thread-safe.
该代码与您在上面的threading示例中使用的结构非常相似。 不同之处在于每个线程都在访问相同的全局变量counter并对其进行递增。 Counter没有任何保护,因此它不是线程安全的。
In order to increment counter, each of the threads needs to read the current value, add one to it, and the save that value back to the variable. That happens in this line: counter += 1.
为了增加counter ,每个线程都需要读取当前值,将其添加一个,然后将该值保存回变量。 发生在这一行: counter += 1 。
Because the operating system knows nothing about your code and can swap threads at any point in the execution, it’s possible for this swap to happen after a thread has read the value but before it has had the chance to write it back. If the new code that is running modifies counter as well, then the first thread has a stale copy of the data and trouble will ensue.
因为操作系统对您的代码一无所知,并且可以在执行的任何时刻交换线程,所以这种交换有可能在线程读取值之后但有机会将其写回之前发生。 如果正在运行的新代码也修改了counter ,则第一个线程将拥有该数据的陈旧副本,从而将导致麻烦。
As you can imagine, hitting this exact situation is fairly rare. You can run this program thousands of times and never see the problem. That’s what makes this type of problem quite difficult to debug as it can be quite hard to reproduce and can cause random-looking errors to show up.
可以想象,碰到这种确切情况的情况很少见。 您可以运行该程序数千次,而不会发现问题。 这就是使得这类问题很难调试的原因,因为它很难重现,并且可能导致出现看起来很随意的错误。
As a further example, I want to remind you that requests.Session() is not thread-safe. This means that there are places where the type of interaction described above could happen if multiple threads use the same Session. I bring this up not to cast aspersions on requests but rather to point out that these are difficult problems to resolve.
再举一个例子,我想提醒您, requests.Session()不是线程安全的。 这意味着,如果多个线程使用同一个Session ,则在某些情况下可能发生上述类型的交互。 我提出这一点不是要对requests进行分散处理,而是要指出这些是很难解决的问题。
asyncio版本 (asyncio Version)
Before you jump into examining the asyncio example code, let’s talk more about how asyncio works.
在深入研究asyncio示例代码之前,让我们先讨论一下asyncio工作原理。
asyncio Basics
asyncio基础
This will be a simplified version of asycio. There are many details that are glossed over here, but it still conveys the idea of how it works.
这将是asycio的简化版本。 这里掩盖了许多细节,但仍然传达了其工作原理的想法。
The general concept of asyncio is that a single Python object, called the event loop, controls how and when each task gets run. The event loop is aware of each task and knows what state it’s in. In reality, there are many states that tasks could be in, but for now let’s imagine a simplified event loop that just has two states.
asyncio的一般概念是单个Python对象(称为事件循环)控制每个任务的运行方式和时间。 事件循环知道每个任务并知道其处于什么状态。实际上,任务可以处于许多状态,但是现在让我们想象一个简化的事件循环,其中只有两个状态。
The ready state will indicate that a task has work to do and is ready to be run, and the waiting state means that the task is waiting for some external thing to finish, such as a network operation.
就绪状态将指示任务有工作要做并且已准备好运行,而等待状态意味着任务正在等待某些外部事物完成,例如网络操作。
Your simplified event loop maintains two lists of tasks, one for each of these states. It selects one of the ready tasks and starts it back to running. That task is in complete control until it cooperatively hands the control back to the event loop.
简化的事件循环维护两个任务列表,每个状态列表一个。 它选择一个就绪任务,然后将其重新启动运行。 该任务处于完全控制状态,直到它协作将控制权移交给事件循环。
When the running task gives control back to the event loop, the event loop places that task into either the ready or waiting list and then goes through each of the tasks in the waiting list to see if it has become ready by an I/O operation completing. It knows that the tasks in the ready list are still ready because it knows they haven’t run yet.
当正在运行的任务将控制权交还给事件循环时,事件循环将该任务放入就绪列表或等待列表中,然后遍历等待列表中的每个任务以查看其是否已通过I / O操作准备就绪完成。 它知道就绪列表中的任务仍处于就绪状态,因为它知道它们尚未运行。
Once all of the tasks have been sorted into the right list again, the event loop picks the next task to run, and the process repeats. Your simplified event loop picks the task that has been waiting the longest and runs that. This process repeats until the event loop is finished.
一旦将所有任务重新分类到正确的列表中,事件循环就会选择要运行的下一个任务,然后重复该过程。 简化的事件循环将选择等待时间最长的任务并运行该任务。 重复此过程,直到事件循环完成。
An important point of asyncio is that the tasks never give up control without intentionally doing so. They never get interrupted in the middle of an operation. This allows us to share resources a bit more easily in asyncio than in threading. You don’t have to worry about making your code thread-safe.
asyncio的重要一点是,任务不会在没有故意的情况下放弃控制。 他们从不会在手术过程中被打断。 这使我们在asyncio比在threading更容易共享资源。 您不必担心使代码成为线程安全的。
That’s a high-level view of what’s happening with asyncio. If you want more detail, this StackOverflow answer provides some good details if you want to dig deeper.
这是asyncio发生情况的高级视图。 如果您想了解更多细节,如果您想更深入地了解, 此StackOverflow答案提供了一些很好的细节。
async and await
async await
Now let’s talk about two new keywords that were added to Python: async and await. In light of the discussion above, you can view await as the magic that allows the task to hand control back to the event loop. When your code awaits a function call, it’s a signal that the call is likely to be something that takes a while and that the task should give up control.
现在,让我们讨论添加到Python中的两个新关键字: async和await 。 根据上面的讨论,您可以将await视为一种魔术,它使任务可以将控制权交还给事件循环。 当您的代码等待函数调用时,这表明该调用可能要花一些时间,并且该任务应该放弃控制。
It’s easiest to think of async as a flag to Python telling it that the function about to be defined uses await. There are some cases where this is not strictly true, like asynchronous generators, but it holds for many cases and gives you a simple model while you’re getting started.
最简单的方法是将async视为Python的标志,告诉它要定义的函数使用await 。 在某些情况下,这并不是严格意义上的,例如异步生成器 ,但是它在很多情况下都适用,并在您入门时为您提供了一个简单的模型。
One exception to this that you’ll see in the next code is the async with statement, which creates a context manager from an object you would normally await. While the semantics are a little different, the idea is the same: to flag this context manager as something that can get swapped out.
在下一个代码中将看到的一个例外是async with语句,该语句从通常等待的对象创建上下文管理器。 尽管语义有所不同,但思路是相同的:将上下文管理器标记为可以交换的内容。
As I’m sure you can imagine, there’s some complexity in managing the interaction between the event loop and the tasks. For developers starting out with asyncio, these details aren’t important, but you do need to remember that any function that calls await needs to be marked with async. You’ll get a syntax error otherwise.
您一定可以想象,管理事件循环和任务之间的交互会有些复杂。 对于开始使用asyncio开发人员asyncio ,这些细节并不重要,但是您确实需要记住,任何调用await函数都需要标记async 。 否则,您将收到语法错误。
Back to Code
返回代码
Now that you’ve got a basic understanding of what asyncio is, let’s walk through the asyncio version of the example code and figure out how it works. Note that this version adds aiohttp. You should run pip install aiohttp before running it:
现在,您已经对什么是asyncio有了基本的了解,让我们来看一下示例代码的asyncio版本,并弄清楚它是如何工作的。 请注意,此版本添加了aiohttp 。 您应先运行pip install aiohttp然后再运行它:
import import asyncio
asyncio
import import time
time
import import aiohttp
aiohttp
async async def def download_sitedownload_site (( sessionsession , , urlurl ):
):
async async with with sessionsession .. getget (( urlurl ) ) as as responseresponse :
:
printprint (( "Read "Read {0}{0} from from {1}{1} "" .. formatformat (( responseresponse .. content_lengthcontent_length , , urlurl ))
))
async async def def download_all_sitesdownload_all_sites (( sitessites ):
):
async async with with aiohttpaiohttp .. ClientSessionClientSession () () as as sessionsession :
:
tasks tasks = = []
[]
for for url url in in sitessites :
:
task task = = asyncioasyncio .. ensure_futureensure_future (( download_sitedownload_site (( sessionsession , , urlurl ))
))
taskstasks .. appendappend (( tasktask )
)
await await asyncioasyncio .. gathergather (( ** taskstasks , , return_exceptionsreturn_exceptions == TrueTrue )
)
if if __name__ __name__ == == "__main__""__main__" :
:
sites sites = = [
[
"http://www.jython.org""http://www.jython.org" ,
,
"http://olympus.realpython.org/dice""http://olympus.realpython.org/dice" ,
,
] ] * * 80
80
start_time start_time = = timetime .. timetime ()
()
asyncioasyncio .. get_event_loopget_event_loop ()() .. run_until_completerun_until_complete (( download_all_sitesdownload_all_sites (( sitessites ))
))
duration duration = = timetime .. timetime () () - - start_time
start_time
printprint (( ff "Downloaded {len(sites)} sites in "Downloaded {len(sites)} sites in {duration}{duration} seconds" seconds" )
)
This version is a bit more complex than the previous two. It has a similar structure, but there’s a bit more work setting up the tasks than there was creating the ThreadPoolExecutor. Let’s start at the top of the example.
这个版本比前两个版本复杂一些。 它具有类似的结构,但是设置任务要比创建ThreadPoolExecutor多得多。 让我们从示例的顶部开始。
download_site()
download_site()
download_site() at the top is almost identical to the threading version with the exception of the async keyword on the function definition line and the await keyword when you actually call session.get(). You’ll see later why Session can be passed in here rather than using thread-local storage.
顶部的download_site()与threading版本几乎相同,但函数定义行上的async关键字和实际调用session.get()时的await关键字session.get() 。 您稍后将看到为什么可以在此处传递Session而不是使用线程本地存储。
download_site_from_list()
download_site_from_list()
The next function, download_site_from_list(), is fairly straight-forward. While there are still items in the list of sites, it pops one from the list and processes it by calling download_site().
下一个函数download_site_from_list()非常简单。 尽管网站列表中仍然有项目,但它会从列表中弹出一项,并通过调用download_site() 。
Since this function is run concurrently in many tasks, you might be wondering if calling pop() on a List is thread-safe. It is not. But all of our asyncio tasks are actually running in the same thread so you don’t need to worry about thread safety.
由于此函数在许多任务中同时运行,因此您可能想知道在List上调用pop()是否是线程安全的。 它不是。 但是我们所有的asyncio任务实际上都在同一线程中运行,因此您不必担心线程安全。
Tasks can’t be swapped out in the middle of a statement, which means that you don’t need to worry about a task getting interrupted and leaving the list in a bad state. Because there is no await keyword, you know that this statement will not hand control back to the event loop.
不能在语句的中间交换任务,这意味着您不必担心任务会被中断并使列表处于错误状态。 因为没有await关键字,所以您知道此语句不会将控制权交还给事件循环。
The next statement, await download_site(...), will hand control back to the event loop, but by that point you know the sites list will be in a good state.
下一条语句, await download_site(...) ,将把控制权移交给事件循环,但是到那时,您知道sites列表将处于良好状态。
Note that, similar to our threading example, if you actually need things like queues in your design, the asyncio module provides classes and methods that do those operations but work with an event loop.
请注意,类似于我们的threading示例,如果您在设计中确实需要诸如队列之类的东西,那么asyncio模块提供了可以执行这些操作但可以使用事件循环的类和方法。
A slightly more subtle difference is that the session object does not need to be created in each task like it was in each thread. Each task uses the same session that was created earlier and passed in. You can get away with this because, again, all tasks are running in the same thread, so you don’t have to worry about thread safety.
稍微细微的区别是,不需要像在每个线程中那样在每个任务中都创建会话对象。 每个任务都使用先前创建并传入的同一会话。您可以避免这样做,因为所有任务都在同一线程中运行,因此您不必担心线程安全。
download_all_sites()
download_all_sites()
download_all_sites() is where you will see the biggest change from the threading example.
download_all_sites()是您从threading示例中看到的最大变化。
You can share the session across all tasks, so the session is created here as a context manager.
您可以在所有任务之间共享会话,因此该会话在此处创建为上下文管理器。
Inside that context manager, it creates a list of tasks using asyncio.ensure_future(), which also takes care of starting them. Once all the tasks are created, this function uses asyncio.wait() to keep the session context alive until all of the tasks have completed.
在该上下文管理器内部,它使用asyncio.ensure_future()创建任务列表,该任务列表还负责启动任务。 创建所有任务后,此函数将使用asyncio.wait()使会话上下文保持活动状态,直到完成所有任务。
The threading code does something similar to this, but the details are conveniently handled in the ThreadPoolExecutor. There currently is not an AsyncioPoolExecutor class.
threading代码执行的操作与此类似,但是细节可以在ThreadPoolExecutor中方便地处理。 当前没有AsyncioPoolExecutor类。
There is one small but important change buried in the details here, however. Remember how we talked about the number of threads to create? It wasn’t obvious in the threading example what the optimal number of threads was.
但是,这里的细节中隐藏着一个小而重要的变化。 还记得我们是如何谈论要创建的线程数的吗? 在threading示例中,最佳线程数并不明显。
One of the cool advantages of asyncio is that it scales far better than threading. Each task takes far fewer resources and less time to create than a thread, so creating and running more of them works well. This example just creates a separate task for each site to download, which works out quite well.
asyncio一个很酷的优点之一是它的asyncio比threading好得多。 与线程相比,每个任务花费的资源更少,创建时间也更少,因此创建和运行更多任务的效果很好。 这个例子只是为每个站点创建一个单独的任务供下载,效果很好。
__main__
__main__
Finally, the nature of asyncio means that you have to start up the event loop and tell it which tasks to run. The __main__ section at the bottom of the file contains the code to get_event_loop() and then run_until_complete(). If nothing else, they’ve done an excellent job in naming those functions.
最后, asyncio的性质意味着您必须启动事件循环并告诉它要运行哪些任务。 文件底部的__main__部分包含get_event_loop()和run_until_complete() 。 如果没有别的,他们在命名这些功能方面做得很好。
If you’ve updated to Python 3.7, the Python core developers simplified this syntax for you. Instead of the asyncio.get_event_loop().run_until_complete() tongue-twister, you can just use asyncio.run().
如果您已更新至Python 3.7 ,则Python核心开发人员会为您简化此语法。 可以使用asyncio.run()代替asyncio.get_event_loop().run_until_complete()绕口令。
Why the asyncio Version Rocks
为什么asyncio版本会asyncio
It’s really fast! In the tests on my machine, this was the fastest version of the code by a good margin:
真的很快! 在我的机器上的测试中,这是最快的代码版本:
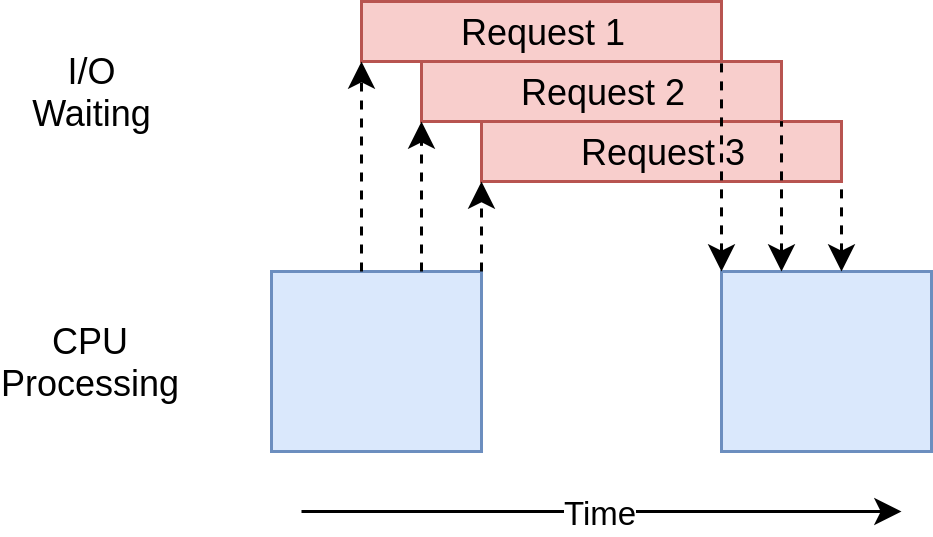
The execution timing diagram looks quite similar to what’s happening in the threading example. It’s just that the I/O requests are all done by the same thread:
执行时序图看起来与threading示例中发生的事情非常相似。 只是I / O请求都由同一线程完成:
The lack of a nice wrapper like the ThreadPoolExecutor makes this code a bit more complex than the threading example. This is a case where you have to do a little extra work to get much better performance.
缺少像ThreadPoolExecutor这样的好的包装器,使得此代码比threading示例要复杂一些。 在这种情况下,您必须做一些额外的工作才能获得更好的性能。
Also there’s a common argument that having to add async and await in the proper locations is an extra complication. To a small extent, that is true. The flip side of this argument is that it forces you to think about when a given task will get swapped out, which can help you create a better, faster, design.
还有一个普遍的论点,即必须在适当的位置添加async和await是一个额外的麻烦。 在一定程度上,这是对的。 该论点的另一面是,它迫使您考虑何时换出给定的任务,这可以帮助您创建更好,更快的设计。
The scaling issue also looms large here. Running the threading example above with a thread for each site is noticeably slower than running it with a handful of threads. Running the asyncio example with hundreds of tasks didn’t slow it down at all.
缩放问题在这里也隐约可见。 使用每个站点的线程运行上面的threading示例明显比使用少数线程运行它慢。 运行具有数百个任务的asyncio示例并不会降低它的运行速度。
The Problems With the asyncio Version
asyncio版本的问题
There are a couple of issues with asyncio at this point. You need special async versions of libraries to gain the full advantage of asycio. Had you just used requests for downloading the sites, it would have been much slower because requests is not designed to notify the event loop that it’s blocked. This issue is getting smaller and smaller as time goes on and more libraries embrace asyncio.
此时, asyncio存在两个问题。 您需要特殊的异步版本的库才能充分利用asycio优势。 如果您只是使用requests来下载站点,那么它会慢很多,因为requests并非旨在通知事件循环它已被阻止。 随着时间的流逝,这个问题越来越小,越来越多的图书馆采用asyncio 。
Another, more subtle, issue is that all of the advantages of cooperative multitasking get thrown away if one of the tasks doesn’t cooperate. A minor mistake in code can cause a task to run off and hold the processor for a long time, starving other tasks that need running. There is no way for the event loop to break in if a task does not hand control back to it.
另一个更微妙的问题是,如果其中一项任务不合作,则协作多任务处理的所有优势都会被丢弃。 代码中的小错误会导致任务运行并长时间保持处理器,从而使其他需要运行的任务饿死。 如果任务没有将控制权交还给它,则无法中断事件循环。
With that in mind, let’s step up to a radically different approach to concurrency, multiprocessing.
考虑到这一点,让我们着手采用根本不同的并发方法,即multiprocessing 。
multiprocessing版本 (multiprocessing Version)
Unlike the previous approaches, the multiprocessing version of the code takes full advantage of the multiple CPUs that your cool, new computer has. Or, in my case, that my clunky, old laptop has. Let’s start with the code:
与以前的方法不同,代码的multiprocessing版本可以充分利用您的全新酷炫计算机具有的多个CPU。 或者,就我而言,那是我笨拙的旧笔记本电脑。 让我们从代码开始:
import import requests
requests
import import multiprocessing
multiprocessing
import import time
time
session session = = None
None
def def set_global_sessionset_global_session ():
():
global global session
session
if if not not sessionsession :
:
session session = = requestsrequests .. SessionSession ()
()
def def download_sitedownload_site (( urlurl ):
):
with with sessionsession .. getget (( urlurl ) ) as as responseresponse :
:
name name = = multiprocessingmultiprocessing .. current_processcurrent_process ()() .. name
name
printprint (( ff "" {name}{name} :Read {len(response.content)} from :Read {len(response.content)} from {url}{url} "" )
)
def def download_all_sitesdownload_all_sites (( sitessites ):
):
with with multiprocessingmultiprocessing .. PoolPool (( initializerinitializer == set_global_sessionset_global_session ) ) as as poolpool :
:
poolpool .. mapmap (( download_sitedownload_site , , sitessites )
)
if if __name__ __name__ == == "__main__""__main__" :
:
sites sites = = [
[
"http://www.jython.org""http://www.jython.org" ,
,
"http://olympus.realpython.org/dice""http://olympus.realpython.org/dice" ,
,
] ] * * 80
80
start_time start_time = = timetime .. timetime ()
()
download_all_sitesdownload_all_sites (( sitessites )
)
duration duration = = timetime .. timetime () () - - start_time
start_time
printprint (( ff "Downloaded {len(sites)} in "Downloaded {len(sites)} in {duration}{duration} seconds" seconds" )
)
This is much shorter than the asyncio example and actually looks quite similar to the threading example, but before we dive into the code, let’s take a quick tour of what multiprocessing does for you.
这比asyncio示例短得多,并且实际上看起来与threading示例非常相似,但是在深入研究代码之前,让我们快速浏览一下multiprocessing为您提供的功能。
multiprocessing in a Nutshell
multiprocessing技术手册
Up until this point, all of the examples of concurrency in this article run only on a single CPU or core in your computer. The reasons for this have to do with the current design of CPython and something called the Global Interpreter Lock, or GIL.
到目前为止,本文中的所有并发示例仅在计算机上的单个CPU或内核上运行。 这样做的原因与CPython的当前设计以及称为全局解释器锁(GIL)的东西有关。
This article won’t dive into the hows and whys of the GIL. It’s enough for now to know that the synchronous, threading, and asyncio versions of this example all run on a single CPU.
本文不会深入探讨GIL的方式和原因。 现在足以知道该示例的asyncio , threading和asyncio版本都在单个CPU上运行。
multiprocessing in the standard library was designed to break down that barrier and run your code across multiple CPUs. At a high level, it does this by creating a new instance of the Python interpreter to run on each CPU and then farming out part of your program to run on it.
标准库中的multiprocessing旨在消除这一障碍,并在多个CPU上运行代码。 从高层次上讲,它是通过创建一个新的Python解释器实例以在每个CPU上运行,然后将部分程序植入其上来执行此操作的。
As you can imagine, bringing up a separate Python interpreter is not as fast as starting a new thread in the current Python interpreter. It’s a heavyweight operation and comes with some restrictions and difficulties, but for the correct problem, it can make a huge difference.
可以想象,建立一个单独的Python解释器并不像在当前的Python解释器中启动新线程那样快。 这是一项重量级的操作,并且有一些限制和困难,但是对于正确的问题,它可以带来很大的改变。
multiprocessing Code
multiprocessing代码
The code has a few small changes from our synchronous version. The first one is in download_all_sites(). Instead of simply calling download_site() repeatedly, it creates a multiprocessing.Pool object and has it map download_site to the iterable sites. This should look familiar from the threading example.
该代码与我们的同步版本相比有一些小的变化。 第一个在download_all_sites() 。 与其简单地反复调用download_site() ,不如创建一个multiprocessing.Pool对象并将其映射download_site到可迭代的sites 。 从threading示例中应该看起来很熟悉。
What happens here is that the Pool creates a number of separate Python interpreter processes and has each one run the specified function on some of the items in the iterable, which in our case is the list of sites. The communication between the main process and the other processes is handled by the multiprocessing module for you.
这里发生的是, Pool创建了许多单独的Python解释器进程,并且每个进程都在iterable中的某些项目(在我们的情况下是站点列表)上运行指定的功能。 主流程与其他流程之间的通信由您的multiprocessing模块处理。
The line that creates Pool is worth your attention. First off, it does not specify how many processes to create in the Pool, although that is an optional parameter. By default, multiprocessing.Pool() will determine the number of CPUs in your computer and match that. This is frequently the best answer, and it is in our case.
创建Pool的行值得您注意。 首先,它没有指定要在Pool创建多少个进程,尽管这是可选参数。 默认情况下, multiprocessing.Pool()将确定计算机中的CPU数量并进行匹配。 这通常是最好的答案,就我们而言。
For this problem, increasing the number of processes did not make things faster. It actually slowed things down because the cost for setting up and tearing down all those processes was larger than the benefit of doing the I/O requests in parallel.
对于这个问题,增加进程数量并不能使事情变得更快。 实际上,它减慢了速度,因为建立和拆除所有这些进程的成本大于并行执行I / O请求的收益。
Next we have the initializer=set_global_session part of that call. Remember that each process in our Pool has its own memory space. That means that they cannot share things like a Session object. You don’t want to create a new Session each time the function is called, you want to create one for each process.
接下来,我们进行该调用的initializer=set_global_session部分。 请记住,我们Pool每个进程都有其自己的内存空间。 这意味着他们无法共享诸如Session对象之类的东西。 您不想每次调用该函数都创建一个新的Session ,而是想为每个进程创建一个。
The initializer function parameter is built for just this case. There is not a way to pass a return value back from the initializer to the function called by the process download_site(), but you can initialize a global session variable to hold the single session for each process. Because each process has its own memory space, the global for each one will be different.
initializer函数参数就是针对这种情况而构建的。 无法将返回值从initializer值设定项传递回由进程download_site()调用的函数,但是您可以初始化一个全局session变量来为每个进程保留单个会话。 由于每个进程都有其自己的内存空间,因此每个进程的全局空间将有所不同。
That’s really all there is to it. The rest of the code is quite similar to what you’ve seen before.
真的就是全部。 其余代码与您之前所见非常相似。
Why the multiprocessing Version Rocks
为什么multiprocessing版本会摇摇欲坠
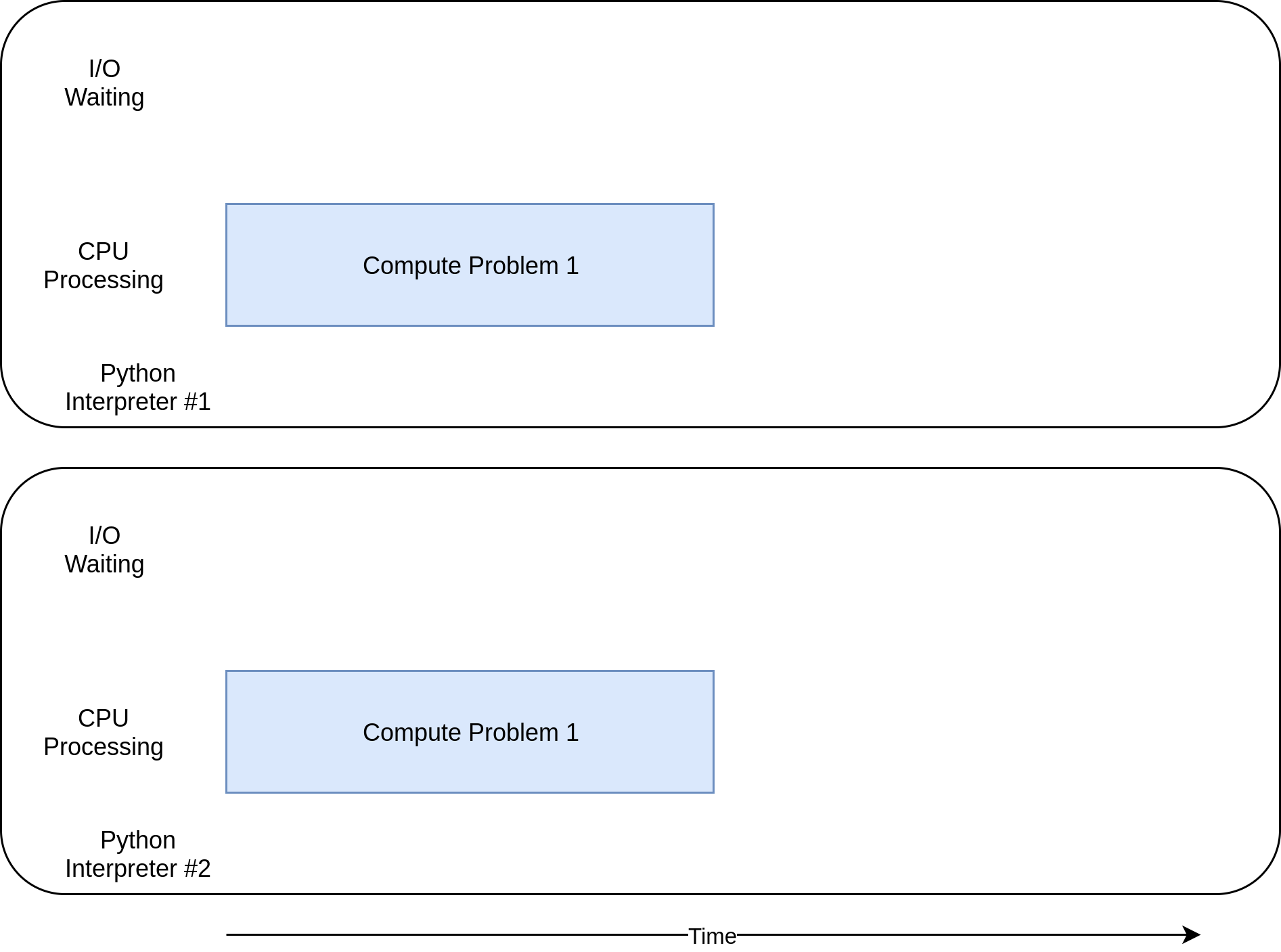
The multiprocessing version of this example is great because it’s relatively easy to set up and requires little extra code. It also takes full advantage of the CPU power in your computer. The execution timing diagram for this code looks like this:
此示例的multiprocessing版本很棒,因为它相对容易设置并且几乎不需要额外的代码。 它还充分利用了计算机中的CPU功能。 该代码的执行时序图如下所示:
The Problems With the multiprocessing Version
multiprocessing版本的问题
This version of the example does require some extra setup, and the global session object is strange. You have to spend some time thinking about which variables will be accessed in each process.
此版本的示例确实需要进行一些额外的设置,并且全局session对象很奇怪。 您必须花一些时间考虑在每个过程中将访问哪些变量。
Finally, it is clearly slower than the asyncio and threading versions in this example:
最后,在此示例中,它显然比asyncio和threading版本慢:
That’s not surprising, as I/O-bound problems are not really why multiprocessing exists. You’ll see more as you step into the next section and look at CPU-bound examples.
这不足为奇,因为与I / O绑定的问题并不是真正存在multiprocessing原因。 进入下一部分并查看受CPU约束的示例时,您将看到更多。
如何加快CPU绑定程序 (How to Speed Up a CPU-Bound Program)
Let’s shift gears here a little bit. The examples so far have all dealt with an I/O-bound problem. Now, you’ll look into a CPU-bound problem. As you saw, an I/O-bound problem spends most of its time waiting for external operations, like a network call, to complete. A CPU-bound problem, on the other hand, does few I/O operations, and its overall execution time is a factor of how fast it can process the required data.
让我们在这里换档。 到目前为止,所有示例都处理了与I / O绑定的问题。 现在,您将研究受CPU限制的问题。 如您所见,一个受I / O约束的问题花费了大部分时间来等待外部操作(例如网络调用)完成。 另一方面,受CPU限制的问题很少执行I / O操作,其总体执行时间是可以处理所需数据的速度的一个因素。
For the purposes of our example, we’ll use a somewhat silly function to create something that takes a long time to run on the CPU. This function computes the square of each number from 1 to the passed-in value:
就我们的示例而言,我们将使用一个有点愚蠢的函数来创建一些需要很长时间才能在CPU上运行的函数。 此函数计算从1到传入值的每个数字的平方:
def def cpu_boundcpu_bound (( numbernumber ):
):
return return sumsum (( i i * * i i for for i i in in rangerange (( numbernumber ))
))
You’ll be passing in large numbers, so this will take a while. Remember, this is just a placeholder for your code that actually does something useful and requires significant processing time, like computing the roots of equations or sorting a large data structure.
您将大量传递,因此需要一段时间。 请记住,这只是代码的占位符,它实际上在做有用的事情,并且需要大量的处理时间,例如计算方程式的根或对大型数据结构进行排序。
CPU限制同步版本 (CPU-Bound Synchronous Version)
Now let’s look at the non-concurrent version of the example:
现在让我们看一下示例的非并行版本:
This code calls cpu_bound() 20 times with a different large number each time. It does all of this on a single thread in a single process on a single CPU. The execution timing diagram looks like this:
此代码调用cpu_bound() 20次,每次均使用不同的大数。 它在单个CPU上的单个进程中的单个线程上完成所有这些操作。 执行时序图如下所示:
Unlike the I/O-bound examples, the CPU-bound examples are usually fairly consistent in their run times. This one takes about 7.8 seconds on my machine:
与I / O绑定示例不同,CPU绑定示例在运行时间上通常相当一致。 这在我的机器上大约需要7.8秒:
$ ./cpu_non_concurrent.py
$ ./cpu_non_concurrent.py
Duration 7.834432125091553 seconds
Duration 7.834432125091553 seconds
Clearly we can do better than this. This is all running on a single CPU with no concurrency. Let’s see what we can do to make it better.
显然,我们可以做得更好。 所有这些都在没有并发的单个CPU上运行。 让我们看看如何做才能更好。
threading和asyncio版本 (threading and asyncio Versions)
How much do you think rewriting this code using threading or asyncio will speed this up?
您认为使用threading或asyncio重写此代码将加快多少速度?
If you answered “Not at all,” give yourself a cookie. If you answered, “It will slow it down,” give yourself two cookies.
如果您回答“完全不”,请给自己一个cookie。 如果您回答“它将减慢速度”,请给自己两个cookie。
Here’s why: In your I/O-bound example above, much of the overall time was spent waiting for slow operations to finish. threading and asyncio sped this up by allowing you to overlap the times you were waiting instead of doing them sequentially.
原因如下:在上面的I / O绑定示例中,大部分时间都花在了等待缓慢的操作完成上。 threading和asyncio加速了此过程,它允许您重叠等待的时间,而不是依次执行。
On a CPU-bound problem, however, there is no waiting. The CPU is cranking away as fast as it can to finish the problem. In Python, both threads and tasks run on the same CPU in the same process. That means that the one CPU is doing all of the work of the non-concurrent code plus the extra work of setting up threads or tasks. It takes more than 10 seconds:
但是,在受CPU限制的问题上,无需等待。 CPU正在尽可能快地启动以解决问题。 在Python中,线程和任务都在同一进程中在同一CPU上运行。 这意味着一个CPU负责完成非并行代码的所有工作以及设置线程或任务的额外工作。 耗时超过10秒:
I’ve written up a threading version of this code and placed it with the other example code in the GitHub repo so you can go test this yourself. Let’s not look at that just yet, however.
我已经编写了此代码的threading版本,并将其与其他示例代码一起放置在GitHub存储库中,以便您可以自己进行测试。 但是,让我们现在不看看它。
CPU限制的multiprocessing版本 (CPU-Bound multiprocessing Version)
Now you’ve finally reached where multiprocessing really shines. Unlike the other concurrency libraries, multiprocessing is explicitly designed to share heavy CPU workloads across multiple CPUs. Here’s what its execution timing diagram looks like:
现在您终于到达了multiprocessing真正发挥作用的地方。 与其他并发库不同, multiprocessing被明确设计为在多个CPU之间共享繁重的CPU工作负载。 其执行时序图如下所示:
Here’s what the code looks like:
代码如下所示:
import import multiprocessing
multiprocessing
import import time
time
def def cpu_boundcpu_bound (( numbernumber ):
):
return return sumsum (( i i * * i i for for i i in in rangerange (( numbernumber ))
))
def def find_sumsfind_sums (( numbersnumbers ):
):
with with multiprocessingmultiprocessing .. PoolPool () () as as poolpool :
:
poolpool .. mapmap (( cpu_boundcpu_bound , , numbersnumbers )
)
if if __name__ __name__ == == "__main__""__main__" :
:
numbers numbers = = [[ 55 _000_000 _000_000 + + x x for for x x in in rangerange (( 2020 )]
)]
start_time start_time = = timetime .. timetime ()
()
find_sumsfind_sums (( numbersnumbers )
)
duration duration = = timetime .. timetime () () - - start_time
start_time
printprint (( ff "Duration "Duration {duration}{duration} seconds" seconds" )
)
Little of this code had to change from the non-concurrent version. You had to import multiprocessing and then just change from looping through the numbers to creating a multiprocessing.Pool object and using its .map() method to send individual numbers to worker-processes as they become free.
与非并行版本相比,这段代码几乎不需要更改。 您必须import multiprocessing ,然后才将其从遍历数字转变为创建multiprocessing.Pool对象,并使用其.map()方法将单个数字免费发送给工作进程。
This was just what you did for the I/O-bound multiprocessing code, but here you don’t need to worry about the Session object.
这就是您对I / O绑定的multiprocessing代码所做的事情,但是在这里,您不必担心Session对象。
As mentioned above, the processes optional parameter to the multiprocessing.Pool() constructor deserves some attention. You can specify how many Process objects you want created and managed in the Pool. By default, it will determine how many CPUs are in your machine and create a process for each one. While this works great for our simple example, you might want to have a little more control in a production environment.
如上所述, multiprocessing.Pool()构造函数的processes可选参数值得关注。 您可以指定要在Pool创建和管理的Process对象的数量。 默认情况下,它将确定计算机中有多少个CPU,并为每个CPU创建一个进程。 尽管这对于我们的简单示例非常有用,但您可能希望在生产环境中拥有更多控制权。
Also, as we mentioned in the first section about threading, the multiprocessing.Pool code is built upon building blocks like Queue and Semaphore that will be familiar to those of you who have done multithreaded and multiprocessing code in other languages.
而且,正如我们在关于threading的第一部分中提到的那样, multiprocessing.Pool代码是建立在诸如Queue和Semaphore类的构建基块上的,这对那些使用其他语言完成多线程和多处理代码的人来说是很熟悉的。
Why the multiprocessing Version Rocks
为什么multiprocessing版本会摇摇欲坠
The multiprocessing version of this example is great because it’s relatively easy to set up and requires little extra code. It also takes full advantage of the CPU power in your computer.
此示例的multiprocessing版本很棒,因为它相对容易设置并且几乎不需要额外的代码。 它还充分利用了计算机中的CPU功能。
Hey, that’s exactly what I said the last time we looked at multiprocessing. The big difference is that this time it is clearly the best option. It takes 2.5 seconds on my machine:
嘿,这就是我上次看multiprocessing时所说的。 最大的区别是这次显然是最好的选择。 在我的机器上需要2.5秒:
That’s much better than we saw with the other options.
这比我们在其他选项中看到的要好得多。
The Problems With the multiprocessing Version
multiprocessing版本的问题
There are some drawbacks to using multiprocessing. They don’t really show up in this simple example, but splitting your problem up so each processor can work independently can sometimes be difficult.
使用multiprocessing有一些缺点。 在这个简单的示例中并没有真正显示它们,但是有时很难分解问题以使每个处理器都可以独立工作。
Also, many solutions require more communication between the processes. This can add some complexity to your solution that a non-concurrent program would not need to deal with.
同样,许多解决方案要求流程之间进行更多的交流。 这会给您的解决方案增加一些复杂性,从而使非并行程序无需处理。
何时使用并发 (When to Use Concurrency)
You’ve covered a lot of ground here, so let’s review some of the key ideas and then discuss some decision points that will help you determine which, if any, concurrency module you want to use in your project.
您已经在这里进行了很多介绍,因此让我们回顾一些关键思想,然后讨论一些决策点,这些决策点将帮助您确定要在项目中使用哪个并发模块(如果有)。
The first step of this process is deciding if you should use a concurrency module. While the examples here make each of the libraries look pretty simple, concurrency always comes with extra complexity and can often result in bugs that are difficult to find.
此过程的第一步是确定是否应使用并发模块。 尽管这里的示例使每个库看起来都非常简单,但是并发总是带来额外的复杂性,并且常常会导致难以发现的错误。
Hold out on adding concurrency until you have a known performance issue and then determine which type of concurrency you need. As Donald Knuth has said, “Premature optimization is the root of all evil (or at least most of it) in programming.”
坚持添加并发,直到遇到已知的性能问题,然后确定所需的并发类型。 正如Donald Knuth所说:“过早的优化是编程中所有(或至少大部分)邪恶的根源。”
Once you’ve decided that you should optimize your program, figuring out if your program is CPU-bound or I/O-bound is a great next step. Remember that I/O-bound programs are those that spend most of their time waiting for something to happen while CPU-bound programs spend their time processing data or crunching numbers as fast as they can.
决定优化程序后,下一步是确定程序是CPU约束还是I / O约束。 请记住,与I / O绑定的程序是那些花费大量时间等待事情发生的程序,而与CPU绑定的程序则花费时间尽可能快地处理数据或处理数字。
As you saw, CPU-bound problems only really gain from using multiprocessing. threading and asyncio did not help this type of problem at all.
如您所见,使用multiprocessing只会真正带来CPU受限的问题。 threading和asyncio根本没有帮助这类问题。
For I/O-bound problems, there’s a general rule of thumb in the Python community: “Use asyncio when you can, threading when you must.” asyncio can provide the best speed up for this type of program, but sometimes you will require critical libraries that have not been ported to take advantage of asyncio. Remember that any task that doesn’t give up control to the event loop will block all of the other tasks.
对于受I / O约束的问题,Python社区有一条通用的经验法则:“ asyncio使用asyncio时使用threading 。” asyncio可以为asyncio程序提供最快的速度,但是有时您会需要尚未移植的关键库以利用asyncio 。 请记住,任何不放弃对事件循环的控制的任务都将阻止所有其他任务。
结论 (Conclusion)
You’ve now seen the basic types of concurrency available in Python:
现在,您已经了解了Python中可用的基本并发类型:
threadingasynciomultiprocessing
-
threading -
asyncio -
multiprocessing
You’ve got the understanding to decide which concurrency method you should use for a given problem, or if you should use any at all! In addition, you’ve achieved a better understanding of some of the problems that can arise when you’re using concurrency.
您已经了解了可以针对特定问题使用哪种并发方法,或者是否应该使用任何并发方法! 此外,您已经对使用并发时可能出现的一些问题有了更好的了解。
I hope you’ve learned a lot from this article and that you find a great use for concurrency in your own projects!
希望您从本文中学到了很多知识,并希望在自己的项目中发现并发的重要用处!
翻译自: https://www.pybloggers.com/2019/01/speed-up-your-python-program-with-concurrency/
python并发程序















 319
319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









