





python sql
介绍 (Introduction)
One of my favorite things about Python is that users get the benefit of observing the R community and then emulating the best parts of it. I’m a big believer that a language is only as helpful as its libraries and tools.
关于Python我最喜欢的事情之一是,用户可以从观察R社区然后模拟其最佳部分中受益。 我坚信,语言仅与其库和工具一样有用。
This post is about pandasql, a Python package we (Yhat) wrote that emulates the R package sqldf. It’s a small but mighty library comprised of just 358 lines of code. The idea of pandasql is to make Python speak SQL. For those of you who come from a SQL-first background or still “think in SQL”, pandasql is a nice way to take advantage of the strengths of both languages.
这篇文章是关于pandasql , pandasql是我们(Yhat)编写的一个Python包,它模仿R包sqldf 。 这是一个很小但强大的库,仅包含358行代码 。 pandasql的想法是使Python讲SQL。 对于那些来自SQL优先背景或仍然“ SQL思维”的人, pandasql是一种利用两种语言的优势的好方法。
In this introduction, we’ll show you to get up and running with pandasql inside of Rodeo, the integrated development environment (IDE) we built for data exploration and analysis. Rodeo is an open source and completely free tool. If you’re an R user, its a comparable tool with a similar feel to RStudio. As of today, Rodeo can only run Python code, but last week we added syntax highlighting of a bunch of other languages to the editor view (mardown, JSON, julia, SQL, markdown). As you may have read or guessed, we’ve got big plans for Rodeo, including adding SQL support so that you can run your SQL queries right inside of Rodeo, even without our handy little pandasql. More on that in the next week or two!
在本简介中,我们将向您展示pandasql在Rodeo (我们为数据探索和分析而构建的集成开发环境(IDE))中使用pandasql并运行它。 Rodeo是一个开源且完全免费的工具。 如果您是R用户,那么它是一款与RStudio类似的类似工具。 到目前为止,Rodeo只能运行Python代码,但是上周我们在编辑器视图(mardown,JSON,julia,SQL,markdown)中添加了其他语言的语法高亮显示。 您可能已经读过或猜到了,我们为Rodeo制定了宏伟的计划,包括添加SQL支持,以便即使没有方便的pandasql ,也可以在Rodeo内部直接运行SQL查询。 在接下来的一两周内还会有更多关于此的信息!
下载Rodeo (Downloading Rodeo)
Start by downloading Rodeo for Mac, Windows or Linux from the Rodeo page on the Yhat website.
首先从Yhat网站上的Rodeo页面下载适用于Mac,Windows或Linux的Rodeo 。
ps If you download Rodeo and encounter a problem or simply have a question, we monitor our discourse forum 24/7 (okay, almost).
ps如果您下载Rodeo并遇到问题或仅是一个问题,我们将全天候监控我们的讨论论坛 24/7。
有点背景,如果你好奇的话 (A bit of background, if you’re curious)
Behind the scenes, pandasql uses the pandas.io.sql module to transfer data between DataFrame and SQLite databases. Operations are performed in SQL, the results returned, and the database is then torn down. The library makes heavy use of pandas write_frame and frame_query, two functions which let you read and write to/from pandas and (most) any SQL database.
在后台, pandasql使用pandas.io.sql模块在DataFrame和SQLite数据库之间传输数据。 使用SQL执行操作,返回结果,然后拆除数据库。 该库大量使用了pandas write_frame和frame_query ,这两个函数使您可以对pandas和(大多数)任何SQL数据库进行读写。
安装pandasql (Install pandasql)
Install pandasql using the package manager pane in Rodeo. Simply search for pandasql and click Install Package.
使用Rodeo中的“程序包管理器”窗格安装pandasql 。 只需搜索pandasql ,然后单击“安装软件包”。
You can also run ! pip install pandasql from the text editor if you prefer to install that way.
您还可以运行! pip install pandasql ! pip install pandasql如果愿意,可以从文本编辑器中! pip install pandasql 。
检出数据集 (Check out the datasets)
pandasql has two built-in datasets which we’ll use for the examples below.
pandasql具有两个内置数据集,我们将在下面的示例中使用它们。
meat: Dataset from the U.S. Dept. of Agriculture containing metrics on livestock, dairy, and poultry outlook and productionbirths: Dataset from the United Nations Statistics Division containing demographic statistics on live births by month
-
meat:来自美国农业部的数据集,其中包含有关牲畜,奶制品和家禽的前景和产量的指标 -
births:联合国统计司的数据集,其中包含按月分列的活产人口统计数据
Run the following code to check out the data sets.
运行以下代码以检出数据集。
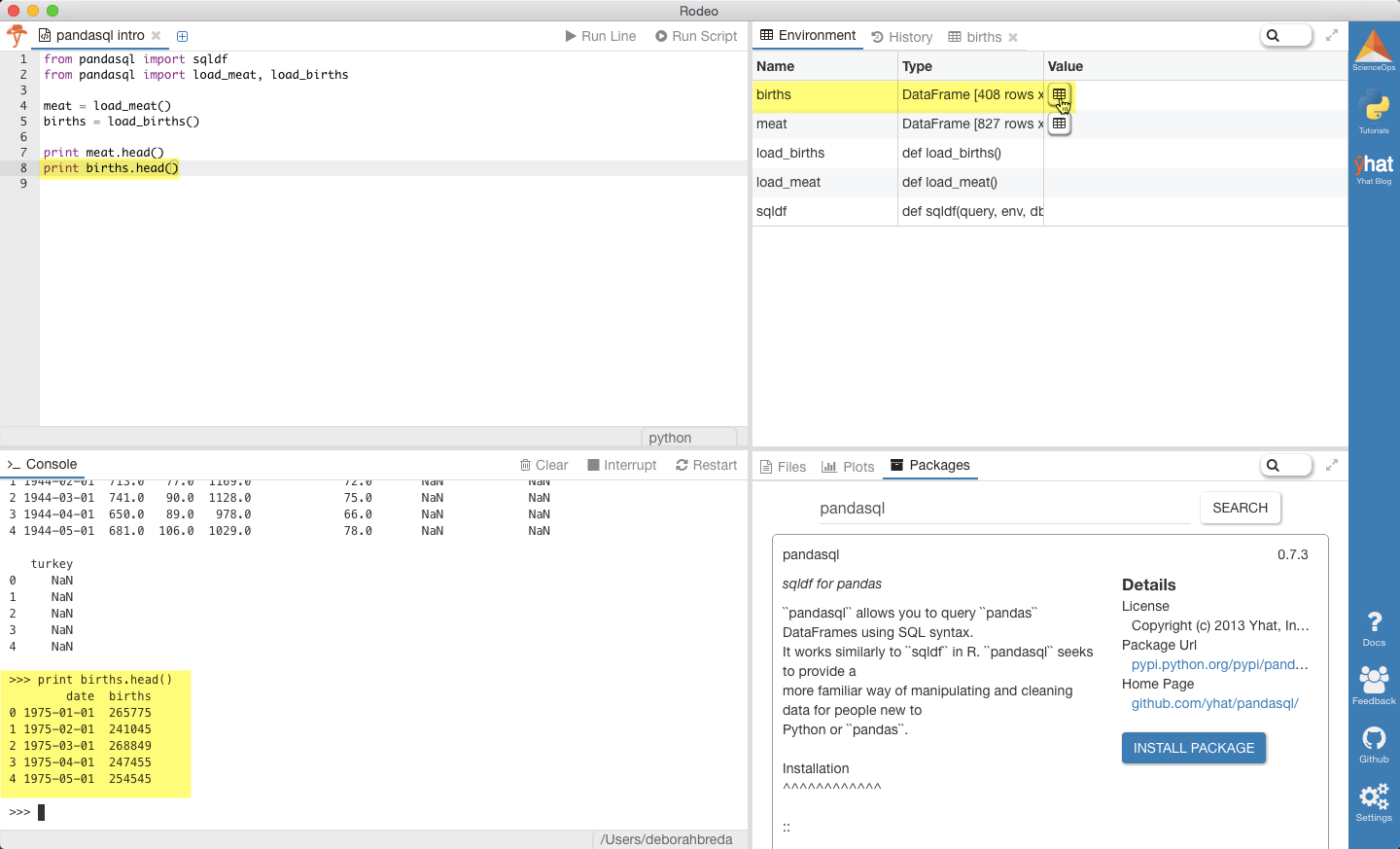
#Checking out meat and birth data from pandasql import sqldf from pandasql import load_meat, load_births meat = load_meat() births = load_births() #You can inspect the dataframes directly if you're using Rodeo #These print statements are here just in case you want to check out your data in the editor, too print meat.head() print births.head()#Checking out meat and birth data from pandasql import sqldf from pandasql import load_meat, load_births meat = load_meat() births = load_births() #You can inspect the dataframes directly if you're using Rodeo #These print statements are here just in case you want to check out your data in the editor, too print meat.head() print births.head()
Inside Rodeo, you really don’t even need the print.variable.head() statements, since you can actually just examine the dataframes directly.
在Rodeo内部,您甚至根本不需要print.variable.head()语句,因为实际上您可以直接检查数据帧。
奇数图 (An odd graph)
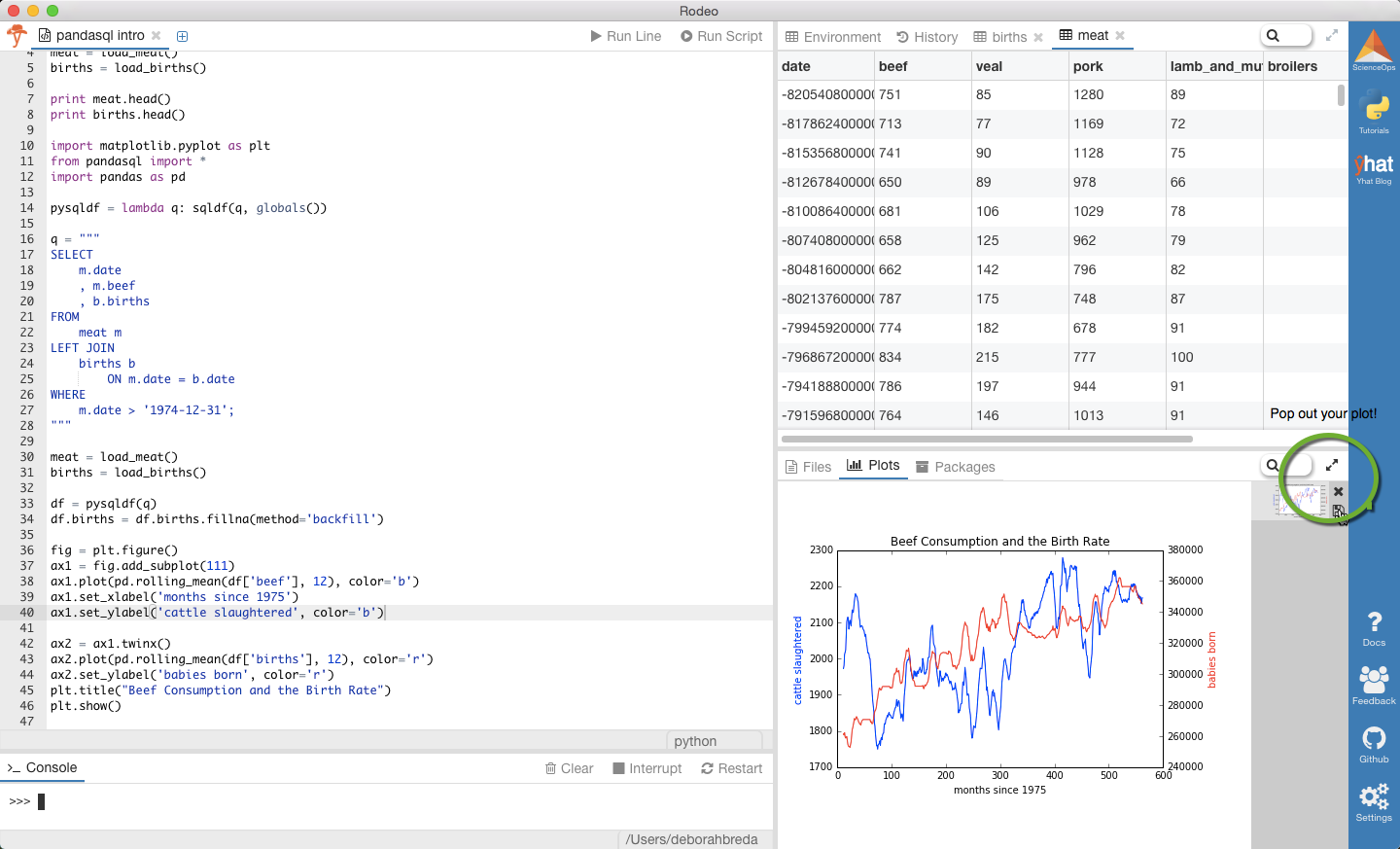
Notice that the plot appears both in the console and the plot tab (bottom right tab).
请注意,该图同时出现在控制台和“图”选项卡(右下方选项卡)中。
Tip: You can “pop out” your plot by clicking the arrows at the top of the pane. This is handy if you’re working on muliple monitors and want to dedicate one just to your data visualzations.
提示:您可以通过单击窗格顶部的箭头来“弹出”绘图。 如果您正在使用多显示器,并且只想将其用于数据可视化,这将很方便。
用法 (Usage)
To keep this post concise and easy to read, we’ve just given the code snippets and a few lines of results for most of the queries below.
为了使这篇文章简洁明了且易于阅读,我们为下面的大多数查询提供了代码片段和几行结果。
If you’re following along in Rodeo, a few tips as you’re getting started:
如果您遵循Rodeo,那么在开始时有一些提示:
Run Scriptwill indeed run everything you have written in the text editor- You can highlight a code chunk and run it by clicking
Run Lineor pressing Command + Enter - You can resize the panes (when I’m not making plots I shrink down the bottom right pane)
-
Run Script确实可以运行您在文本编辑器中编写的所有内容 - 您可以突出显示代码块并通过单击
Run Line或按Command + Enter来运行它 - 您可以调整窗格的大小(当我不进行绘图时,我会缩小右下方的窗格)
基本 (Basics)
Write some SQL and execute it against your pandas DataFrame by substituting DataFrames for tables.
编写一些SQL并通过用DataFrames代替表对您的pandas DataFrame执行它。
q = """ SELECT * FROM meat LIMIT 10;""" print sqldf(q, locals()) # date beef veal pork lamb_and_mutton broilers other_chicken turkey # 0 1944-01-01 00:00:00 751 85 1280 89 None None None # 1 1944-02-01 00:00:00 713 77 1169 72 None None None # 2 1944-03-01 00:00:00 741 90 1128 75 None None None # 3 1944-04-01 00:00:00 650 89 978 66 None None Noneq = """ SELECT * FROM meat LIMIT 10;""" print sqldf(q, locals()) # date beef veal pork lamb_and_mutton broilers other_chicken turkey # 0 1944-01-01 00:00:00 751 85 1280 89 None None None # 1 1944-02-01 00:00:00 713 77 1169 72 None None None # 2 1944-03-01 00:00:00 741 90 1128 75 None None None # 3 1944-04-01 00:00:00 650 89 978 66 None None None
pandasql creates a DB, schema and all, loads your data, and runs your SQL.
pandasql创建一个数据库,一个架构以及所有数据库,加载数据并运行SQL。
聚合 (Aggregation)
pandasql supports aggregation. You can use aliased column names or column numbers in your group by clause.
pandasql支持聚合。 您可以在group by子句中使用别名列名或列号。
locals()与globals() (locals() vs. globals())
pandasql needs to have access to other variables in your session/environment. You can pass locals() to pandasql when executing a SQL statement, but if you’re running a lot of queries that might be a pain. To avoid passing locals all the time, you can add this helper function to your script to set globals() like so:
pandasql需要访问您的会话/环境中的其他变量。 您可以在执行SQL语句时将locals()传递给pandasql ,但是如果要运行很多查询,可能会很pandasql 。 为了避免始终传递本地globals() ,可以将此辅助函数添加到脚本中以设置globals()如下所示:
def pysqldf(q): return sqldf(q, globals()) q = """ SELECT * FROM births LIMIT 10;""" print pysqldf(q) # 0 1975-01-01 00:00:00 265775 # 1 1975-02-01 00:00:00 241045 # 2 1975-03-01 00:00:00 268849def pysqldf(q): return sqldf(q, globals()) q = """ SELECT * FROM births LIMIT 10;""" print pysqldf(q) # 0 1975-01-01 00:00:00 265775 # 1 1975-02-01 00:00:00 241045 # 2 1975-03-01 00:00:00 268849
加入 (joins)
You can join dataframes using normal SQL syntax.
您可以使用常规SQL语法联接数据框。
WHERE条件 (WHERE conditions)
Here's a `WHERE` clause. q = """ SELECT date , beef , veal , pork , lamb_and_mutton FROM meat WHERE lamb_and_mutton >= veal ORDER BY date DESC LIMIT 10; """ print pysqldf(q) # date beef veal pork lamb_and_mutton # 0 2012-11-01 00:00:00 2206.6 10.1 2078.7 12.4 # 1 2012-10-01 00:00:00 2343.7 10.3 2210.4 14.2 # 2 2012-09-01 00:00:00 2016.0 8.8 1911.0 12.5 # 3 2012-08-01 00:00:00 2367.5 10.1 1997.9 14.2Here's a `WHERE` clause. q = """ SELECT date , beef , veal , pork , lamb_and_mutton FROM meat WHERE lamb_and_mutton >= veal ORDER BY date DESC LIMIT 10; """ print pysqldf(q) # date beef veal pork lamb_and_mutton # 0 2012-11-01 00:00:00 2206.6 10.1 2078.7 12.4 # 1 2012-10-01 00:00:00 2343.7 10.3 2210.4 14.2 # 2 2012-09-01 00:00:00 2016.0 8.8 1911.0 12.5 # 3 2012-08-01 00:00:00 2367.5 10.1 1997.9 14.2
这只是SQL (It’s just SQL)
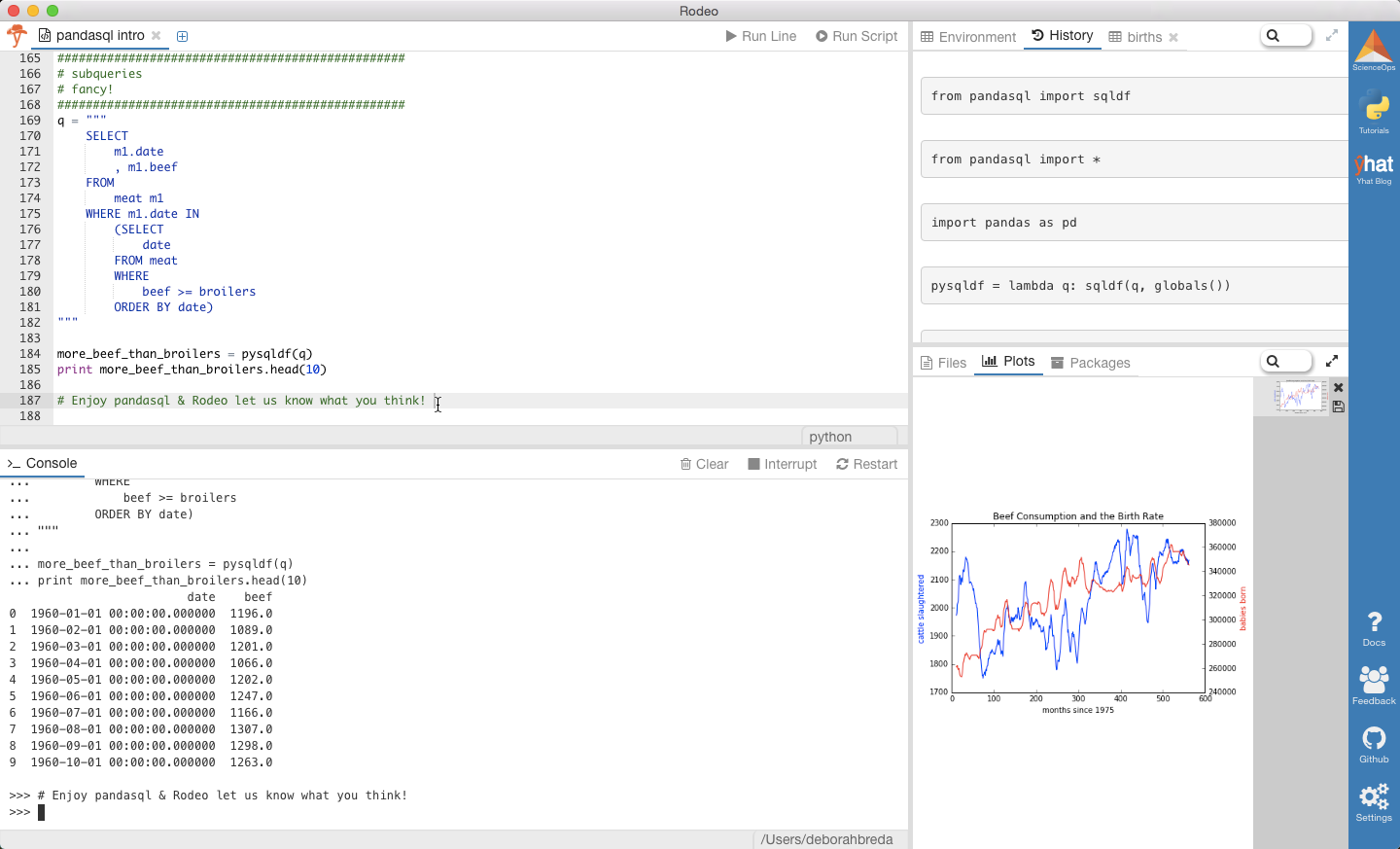
Since pandasql is powered by SQLite3, you can do most anything you can do in SQL. Here are some examples using common SQL features such as subqueries, order by, functions, and unions.
由于pandasql由SQLite3提供支持,因此您可以执行SQL中可以执行的大多数操作。 以下是一些使用常见SQL功能的示例,例如子查询,排序依据,函数和联合。
最后的想法 (Final thoughts)
pandas is an incredible tool for data analysis in large part, we think, because it is extremely digestible, succinct, and expressive. Ultimately, there are tons of reasons to learn the nuances of merge, join, concatenate, melt and other native pandas features for slicing and dicing data. Check out the docs for some examples.
我们认为, pandas在很大程度上是一种令人难以置信的数据分析工具,因为它具有极强的易消化性,简洁性和表现力。 最终,有大量的理由来学习merge , join , concatenate , melt和其他本地pandas特征的细微差别,以便对数据进行切片和切块。 查看文档中的一些示例。
翻译自: https://www.pybloggers.com/2016/10/pandasql-make-python-speak-sql/
python sql















 1896
1896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









