





mpp架构hadoop架构
"Hadoop is an open source software framework which provides huge data storage".
“ Hadoop是提供大量数据存储的开源软件框架” 。
Now, from the definition, we can see that Hadoop is open source now the people who are from tech field can easily understand that what open field, is means we don’t need to pay for using it, its free anybody can access it.
现在,从定义中,我们可以看到Hadoop是开放源代码,现在,来自技术领域的人们可以轻松地了解什么是开放域,这意味着我们不需要为使用它付费,任何人都可以免费使用它。
Now, comes software framework, means Hadoop is not a software it is a software framework, like for example we can say java, java is not a software it’s a software platform, like the cloud, google cloud they all are platforms they are not software, from anywhere you can access them.
现在,出现了软件框架,这意味着Hadoop不是软件而是软件框架,例如我们可以说java,java不是软件,而是软件平台,例如云,谷歌云,它们都是平台,而不是软件。 ,您可以从任何地方访问它们。
Hadoop基本图 (Basic diagram of Hadoop)
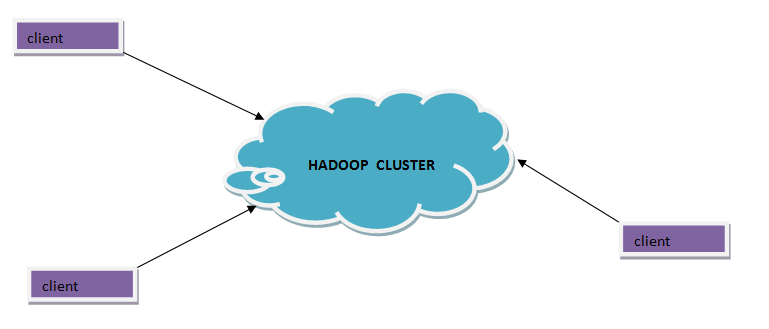
Now, the above shown is the basic diagram of Hadoop, you can see I represented it by a cloud shape, and it’s working is also shown as that there are no. of clients accessing it and in between there is a cluster, cluster means it cannot be on one machine it is located on multiple machines.
现在,上面显示的是Hadoop的基本示意图,您可以看到我用云的形状表示了它,并且它的工作状态也得到了显示,因为它没有。 的客户端之间,并且在群集之间,群集意味着群集不能位于一台计算机上,而位于多台计算机上。
Hadoop的基本组件 (Basic components of Hadoop)
Name Node (NN)
名称节点(NN)
Job Tracker (JT)
作业跟踪器(JT)
Secondary Name Node (SNN)
辅助名称节点(SNN)
Task Tracker (TT)
任务跟踪器(TT)
Hadoop的物理架构 (Physical Architecture of Hadoop)
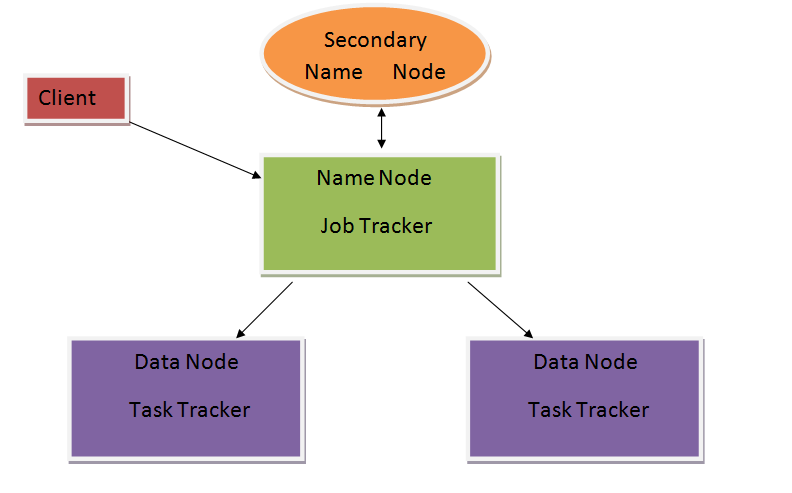
Note: There is no fixed number of data nodes, it can be as much as required or made.
注意:没有固定数量的数据节点,可以根据需要或制造任意数量。
加工 (Working)
When the client will submit his job, it Will go to the name node, now name node will decide whether to accept the job or not. After accepting the job, the name node will transfer the job to the job tracker, job tracker will divide the job into components and transfer them to data nodes now data nodes will further transfer the jobs to the task tracker, now the actual processing will be done here, means the execution of the job submitted is done here. Now, after completing the part of the jobs assigned to them, the task tracker will submit the completed task to the job tracker via the data node. Now, coming on secondary name node, the task of secondary name node is to just monitor the whole process ongoing.
客户提交作业后,它将转到名称节点,现在名称节点将决定是否接受该作业。 接受作业后,名称节点会将作业转移到作业跟踪器,作业跟踪器会将作业分为组件,然后将其转移到数据节点,现在数据节点将作业进一步转移到任务跟踪器,现在实际的处理是在这里完成,意味着提交的作业的执行在这里完成。 现在,在完成分配给他们的部分作业之后,任务跟踪器将通过数据节点将完成的任务提交给作业跟踪器。 现在,在辅助名称节点上,辅助名称节点的任务是仅监视正在进行的整个过程。
Note: The job tracker continuously communicates with the task trackers in the case in any moment job trackers do not get a reply from any of the task trackers it considers that it failed and transfers its work to another one.
注意:在任何情况下,作业跟踪器都不会从其认为已失败的任何任务跟踪器得到答复,并将其工作转移给另一任务跟踪器时,作业跟踪器会与任务跟踪器连续进行通信。
Now, physical architecture of Hadoop is a Master-slave process, here name node is a master, job tracker is a part of master and data nodes are the slaves.
现在,Hadoop的物理体系结构是一个主从过程,这里的名称节点是一个主节点,作业跟踪程序是主节点的一部分,数据节点是从节点。
Hadoop组件说明 (Description of Hadoop components)
Name Node
名称节点
- It is the master of HDFS (Hadoop file system).
- Contains Job Tracker, which keeps tracks of a file distributed to different data nodes.
- Failure of Name Node will lead to the failure of the full Hadoop system.
Data node
数据节点
- Data node is the slave of HDFS.
- A data node can communicate with each other through the name node to avoid replication in the provided task.
- Data nodes update the change to the data node.
Job Tracker
工作追踪器
- Determines which file to process.
- There can be only one job tracker for per Hadoop cluster.
Task Tracker
任务追踪器
- Only single task tracker is present per slave node.
- Performs tasks given by job tracker and also continuously communicates with the job tracker.
SSN (Secondary Name Node)
SSN(辅助名称节点)
- Its main purpose is to monitor.
- One SSN is present per cluster.
Conclusion
结论
In this article I tried to explain Hadoop and its physical architecture in a very simplified way, I hope I am able to make you understand Hadoop and its Physical architecture clearly. For any further queries, you can shoot your questions in the comment section, I will surely try to answer them as soon as possible. Will be coming with new articles very soon. Till then stay connected, keep learning and stay updated!
在本文中,我试图以一种非常简化的方式来解释Hadoop及其物理体系结构 ,希望我能使您清楚地理解Hadoop及其物理体系结构。 如有其他疑问,您可以在评论部分中提出您的问题,我一定会尽力尽快回答。 即将推出新文章。 然后保持联系,保持学习并保持最新!
翻译自: https://www.includehelp.com/big-data/introduction-to-hadoop-and-its-physical-architecture.aspx
mpp架构hadoop架构















 3410
3410











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









