





spark apache
Apache Spark (Apache Spark)
Apache Spark is an open source data processing framework which can perform analytic operations on Big Data in a distributed environment. It was an academic project in UC Berkley and was initially started by Matei Zaharia at UC Berkeley’s AMPLab in 2009. Apache Spark was created on top of a cluster management tool known as Mesos. This was later modified and upgraded so that it can work in a cluster based environment with distributed processing.
Apache Spark是一个开放源数据处理框架,可以在分布式环境中对大数据执行分析操作。 它是UC Berkley的一个学术项目,最初由Matei Zaharia在UC Berkeley的AMPLab于2009年启动。Apache Spark是在称为Mesos的群集管理工具之上创建的。 后来对其进行了修改和升级,使其可以在具有分布式处理的基于集群的环境中工作。
Apache Spark示例项目设置 (Apache Spark Example Project Setup)
We will be using Maven to create a sample project for the demonstration. To create the project, execute the following command in a directory that you will use as workspace:
我们将使用Maven创建一个示例项目进行演示。 要创建项目,请在将用作工作空间的目录中执行以下命令:
mvn archetype:generate -DgroupId=com.journaldev.sparkdemo -DartifactId=JD-Spark-WordCount -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=falseIf you are running maven for the first time, it will take a few seconds to accomplish the generate command because maven has to download all the required plugins and artifacts in order to make the generation task.
如果您是第一次运行maven,则完成生成命令将需要几秒钟,因为maven必须下载所有必需的插件和工件才能完成生成任务。
Once you have created the project, feel free to open it in your favourite IDE. Next step is to add appropriate Maven Dependencies to the project. Here is the pom.xml file with the appropriate dependencies:
创建项目后,请随时在您喜欢的IDE中打开它。 下一步是向项目添加适当的Maven依赖关系。 这是带有适当依赖项的pom.xml文件:
<dependencies>
<!-- Import Spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>1.4.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.0.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<mainClass>com.geekcap.javaworld.sparkexample.WordCount</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<executions>
<execution>
<id>copy</id>
<phase>install</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/lib</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>As this is a maven-based project, there is actually no need to install and setup Apache Spark on your machine. When we run this project, a runtime instance of Apache Spark will be started and once the program has done executing, it will be shutdown.
由于这是一个基于Maven的项目,因此实际上无需在计算机上安装和设置Apache Spark 。 当我们运行该项目时,将启动Apache Spark的运行时实例,一旦程序执行完毕,它将关闭。
Finally, to understand all the JARs which are added to the project when we added this dependency, we can run a simple Maven command which allows us to see a complete Dependency Tree for a project when we add some dependencies to it. Here is a command which we can use:
最后,要了解添加此依赖项时添加到项目中的所有JAR,我们可以运行一个简单的Maven命令,当我们向项目添加一些依赖项时,该命令使我们能够看到项目的完整依赖关系树。 这是我们可以使用的命令:
mvn dependency:treeWhen we run this command, it will show us the following Dependency Tree:
当我们运行此命令时,它将向我们显示以下依赖关系树:
shubham:JD-Spark-WordCount shubham$ mvn dependency:tree
[INFO] Scanning for projects...
[WARNING]
[WARNING] Some problems were encountered while building the effective model for com.journaldev:java-word-count:jar:1.0-SNAPSHOT
[WARNING] 'build.plugins.plugin.version' for org.apache.maven.plugins:maven-jar-plugin is missing. @ line 41, column 21
[WARNING]
[WARNING] It is highly recommended to fix these problems because they threaten the stability of your build.
[WARNING]
[WARNING] For this reason, future Maven versions might no longer support building such malformed projects.
[WARNING]
[INFO]
[INFO] -------------------< com.journaldev:java-word-count >-------------------
[INFO] Building java-word-count 1.0-SNAPSHOT
[INFO] --------------------------------[ jar ]---------------------------------
[INFO]
[INFO] --- maven-dependency-plugin:2.8:tree (default-cli) @ java-word-count ---
[INFO] com.journaldev:java-word-count:jar:1.0-SNAPSHOT
[INFO] +- org.apache.spark:spark-core_2.11:jar:1.4.0:compile
[INFO] | +- com.twitter:chill_2.11:jar:0.5.0:compile
[INFO] | | \- com.esotericsoftware.kryo:kryo:jar:2.21:compile
[INFO] | | +- com.esotericsoftware.reflectasm:reflectasm:jar:shaded:1.07:compile
[INFO] | | +- com.esotericsoftware.minlog:minlog:jar:1.2:compile
[INFO] | | \- org.objenesis:objenesis:jar:1.2:compile
[INFO] | +- com.twitter:chill-java:jar:0.5.0:compile
[INFO] | +- org.apache.hadoop:hadoop-client:jar:2.2.0:compile
[INFO] | | +- org.apache.hadoop:hadoop-common:jar:2.2.0:compile
[INFO] | | | +- commons-cli:commons-cli:jar:1.2:compile
[INFO] | | | +- org.apache.commons:commons-math:jar:2.1:compile
[INFO] | | | +- xmlenc:xmlenc:jar:0.52:compile
[INFO] | | | +- commons-io:commons-io:jar:2.1:compile
[INFO] | | | +- commons-logging:commons-logging:jar:1.1.1:compile
[INFO] | | | +- commons-lang:commons-lang:jar:2.5:compile
[INFO] | | | +- commons-configuration:commons-configuration:jar:1.6:compile
[INFO] | | | | +- commons-collections:commons-collections:jar:3.2.1:compile
[INFO] | | | | +- commons-digester:commons-digester:jar:1.8:compile
[INFO] | | | | | \- commons-beanutils:commons-beanutils:jar:1.7.0:compile
[INFO] | | | | \- commons-beanutils:commons-beanutils-core:jar:1.8.0:compile
[INFO] | | | +- org.codehaus.jackson:jackson-core-asl:jar:1.8.8:compile
[INFO] | | | +- org.apache.avro:avro:jar:1.7.4:compile
[INFO] | | | +- com.google.protobuf:protobuf-java:jar:2.5.0:compile
[INFO] | | | +- org.apache.hadoop:hadoop-auth:jar:2.2.0:compile
[INFO] | | | \- org.apache.commons:commons-compress:jar:1.4.1:compile
[INFO] | | | \- org.tukaani:xz:jar:1.0:compile
[INFO] | | +- org.apache.hadoop:hadoop-hdfs:jar:2.2.0:compile
[INFO] | | | \- org.mortbay.jetty:jetty-util:jar:6.1.26:compile
[INFO] | | +- org.apache.hadoop:hadoop-mapreduce-client-app:jar:2.2.0:compile
[INFO] | | | +- org.apache.hadoop:hadoop-mapreduce-client-common:jar:2.2.0:compile
[INFO] | | | | +- org.apache.hadoop:hadoop-yarn-client:jar:2.2.0:compile
[INFO] | | | | | +- com.google.inject:guice:jar:3.0:compile
[INFO] | | | | | | +- javax.inject:javax.inject:jar:1:compile
[INFO] | | | | | | \- aopalliance:aopalliance:jar:1.0:compile
[INFO] | | | | | +- com.sun.jersey.jersey-test-framework:jersey-test-framework-grizzly2:jar:1.9:compile
[INFO] | | | | | | +- com.sun.jersey.jersey-test-framework:jersey-test-framework-core:jar:1.9:compile
[INFO] | | | | | | | +- javax.servlet:javax.servlet-api:jar:3.0.1:compile
[INFO] | | | | | | | \- com.sun.jersey:jersey-client:jar:1.9:compile
[INFO] | | | | | | \- com.sun.jersey:jersey-grizzly2:jar:1.9:compile
[INFO] | | | | | | +- org.glassfish.grizzly:grizzly-https:jar:2.1.2:compile
[INFO] | | | | | | | \- org.glassfish.grizzly:grizzly-framework:jar:2.1.2:compile
[INFO] | | | | | | | \- org.glassfish.gmbal:gmbal-api-only:jar:3.0.0-b023:compile
[INFO] | | | | | | | \- org.glassfish.external:management-api:jar:3.0.0-b012:compile
[INFO] | | | | | | +- org.glassfish.grizzly:grizzly-http-server:jar:2.1.2:compile
[INFO] | | | | | | | \- org.glassfish.grizzly:grizzly-rcm:jar:2.1.2:compile
[INFO] | | | | | | +- org.glassfish.grizzly:grizzly-http-servlet:jar:2.1.2:compile
[INFO] | | | | | | \- org.glassfish:javax.servlet:jar:3.1:compile
[INFO] | | | | | +- com.sun.jersey:jersey-json:jar:1.9:compile
[INFO] | | | | | | +- org.codehaus.jettison:jettison:jar:1.1:compile
[INFO] | | | | | | | \- stax:stax-api:jar:1.0.1:compile
[INFO] | | | | | | +- com.sun.xml.bind:jaxb-impl:jar:2.2.3-1:compile
[INFO] | | | | | | | \- javax.xml.bind:jaxb-api:jar:2.2.2:compile
[INFO] | | | | | | | \- javax.activation:activation:jar:1.1:compile
[INFO] | | | | | | +- org.codehaus.jackson:jackson-jaxrs:jar:1.8.3:compile
[INFO] | | | | | | \- org.codehaus.jackson:jackson-xc:jar:1.8.3:compile
[INFO] | | | | | \- com.sun.jersey.contribs:jersey-guice:jar:1.9:compile
[INFO] | | | | \- org.apache.hadoop:hadoop-yarn-server-common:jar:2.2.0:compile
[INFO] | | | \- org.apache.hadoop:hadoop-mapreduce-client-shuffle:jar:2.2.0:compile
[INFO] | | +- org.apache.hadoop:hadoop-yarn-api:jar:2.2.0:compile
[INFO] | | +- org.apache.hadoop:hadoop-mapreduce-client-core:jar:2.2.0:compile
[INFO] | | | \- org.apache.hadoop:hadoop-yarn-common:jar:2.2.0:compile
[INFO] | | +- org.apache.hadoop:hadoop-mapreduce-client-jobclient:jar:2.2.0:compile
[INFO] | | \- org.apache.hadoop:hadoop-annotations:jar:2.2.0:compile
[INFO] | +- org.apache.spark:spark-launcher_2.11:jar:1.4.0:compile
[INFO] | +- org.apache.spark:spark-network-common_2.11:jar:1.4.0:compile
[INFO] | +- org.apache.spark:spark-network-shuffle_2.11:jar:1.4.0:compile
[INFO] | +- org.apache.spark:spark-unsafe_2.11:jar:1.4.0:compile
[INFO] | +- net.java.dev.jets3t:jets3t:jar:0.7.1:compile
[INFO] | | +- commons-codec:commons-codec:jar:1.3:compile
[INFO] | | \- commons-httpclient:commons-httpclient:jar:3.1:compile
[INFO] | +- org.apache.curator:curator-recipes:jar:2.4.0:compile
[INFO] | | +- org.apache.curator:curator-framework:jar:2.4.0:compile
[INFO] | | | \- org.apache.curator:curator-client:jar:2.4.0:compile
[INFO] | | +- org.apache.zookeeper:zookeeper:jar:3.4.5:compile
[INFO] | | | \- jline:jline:jar:0.9.94:compile
[INFO] | | \- com.google.guava:guava:jar:14.0.1:compile
[INFO] | +- org.eclipse.jetty.orbit:javax.servlet:jar:3.0.0.v201112011016:compile
[INFO] | +- org.apache.commons:commons-lang3:jar:3.3.2:compile
[INFO] | +- org.apache.commons:commons-math3:jar:3.4.1:compile
[INFO] | +- com.google.code.findbugs:jsr305:jar:1.3.9:compile
[INFO] | +- org.slf4j:slf4j-api:jar:1.7.10:compile
[INFO] | +- org.slf4j:jul-to-slf4j:jar:1.7.10:compile
[INFO] | +- org.slf4j:jcl-over-slf4j:jar:1.7.10:compile
[INFO] | +- log4j:log4j:jar:1.2.17:compile
[INFO] | +- org.slf4j:slf4j-log4j12:jar:1.7.10:compile
[INFO] | +- com.ning:compress-lzf:jar:1.0.3:compile
[INFO] | +- org.xerial.snappy:snappy-java:jar:1.1.1.7:compile
[INFO] | +- net.jpountz.lz4:lz4:jar:1.2.0:compile
[INFO] | +- org.roaringbitmap:RoaringBitmap:jar:0.4.5:compile
[INFO] | +- commons-net:commons-net:jar:2.2:compile
[INFO] | +- org.spark-project.akka:akka-remote_2.11:jar:2.3.4-spark:compile
[INFO] | | +- org.spark-project.akka:akka-actor_2.11:jar:2.3.4-spark:compile
[INFO] | | | \- com.typesafe:config:jar:1.2.1:compile
[INFO] | | +- io.netty:netty:jar:3.8.0.Final:compile
[INFO] | | +- org.spark-project.protobuf:protobuf-java:jar:2.5.0-spark:compile
[INFO] | | \- org.uncommons.maths:uncommons-maths:jar:1.2.2a:compile
[INFO] | +- org.spark-project.akka:akka-slf4j_2.11:jar:2.3.4-spark:compile
[INFO] | +- org.scala-lang:scala-library:jar:2.11.6:compile
[INFO] | +- org.json4s:json4s-jackson_2.11:jar:3.2.10:compile
[INFO] | | \- org.json4s:json4s-core_2.11:jar:3.2.10:compile
[INFO] | | +- org.json4s:json4s-ast_2.11:jar:3.2.10:compile
[INFO] | | \- org.scala-lang:scalap:jar:2.11.0:compile
[INFO] | | \- org.scala-lang:scala-compiler:jar:2.11.0:compile
[INFO] | | +- org.scala-lang.modules:scala-xml_2.11:jar:1.0.1:compile
[INFO] | | \- org.scala-lang.modules:scala-parser-combinators_2.11:jar:1.0.1:compile
[INFO] | +- com.sun.jersey:jersey-server:jar:1.9:compile
[INFO] | | \- asm:asm:jar:3.1:compile
[INFO] | +- com.sun.jersey:jersey-core:jar:1.9:compile
[INFO] | +- org.apache.mesos:mesos:jar:shaded-protobuf:0.21.1:compile
[INFO] | +- io.netty:netty-all:jar:4.0.23.Final:compile
[INFO] | +- com.clearspring.analytics:stream:jar:2.7.0:compile
[INFO] | +- io.dropwizard.metrics:metrics-core:jar:3.1.0:compile
[INFO] | +- io.dropwizard.metrics:metrics-jvm:jar:3.1.0:compile
[INFO] | +- io.dropwizard.metrics:metrics-json:jar:3.1.0:compile
[INFO] | +- io.dropwizard.metrics:metrics-graphite:jar:3.1.0:compile
[INFO] | +- com.fasterxml.jackson.core:jackson-databind:jar:2.4.4:compile
[INFO] | | +- com.fasterxml.jackson.core:jackson-annotations:jar:2.4.0:compile
[INFO] | | \- com.fasterxml.jackson.core:jackson-core:jar:2.4.4:compile
[INFO] | +- com.fasterxml.jackson.module:jackson-module-scala_2.11:jar:2.4.4:compile
[INFO] | | +- org.scala-lang:scala-reflect:jar:2.11.2:compile
[INFO] | | \- com.thoughtworks.paranamer:paranamer:jar:2.6:compile
[INFO] | +- org.apache.ivy:ivy:jar:2.4.0:compile
[INFO] | +- oro:oro:jar:2.0.8:compile
[INFO] | +- org.tachyonproject:tachyon-client:jar:0.6.4:compile
[INFO] | | \- org.tachyonproject:tachyon:jar:0.6.4:compile
[INFO] | +- net.razorvine:pyrolite:jar:4.4:compile
[INFO] | +- net.sf.py4j:py4j:jar:0.8.2.1:compile
[INFO] | \- org.spark-project.spark:unused:jar:1.0.0:compile
[INFO] \- junit:junit:jar:4.11:test
[INFO] \- org.hamcrest:hamcrest-core:jar:1.3:test
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 2.987 s
[INFO] Finished at: 2018-04-07T15:50:34+05:30
[INFO] ------------------------------------------------------------------------With just two added dependencies, Spark collected all the required dependencies in the project which includes Scala dependencies as well as Apache Spark is written in Scala itself.
仅添加了两个依赖关系,Spark收集了项目中所有必需的依赖关系,其中包括Scala依赖关系以及Apache Spark是用Scala本身编写的。
创建输入文件 (Creating an Input File)
As we’re going to create a Word Counter program, we will create a sample input file for our project in the root directory of our project with name input.txt. Put any content inside it, we use the following text:
在创建Word Counter程序时,我们将在项目的根目录中为项目创建一个示例输入文件,名称为input.txt。 将任何内容放入其中,我们使用以下文本:
Hello, my name is Shubham and I am author at JournalDev . JournalDev is a great website to ready
great lessons about Java, Big Data, Python and many more Programming languages.
Big Data lessons are difficult to find but at JournalDev , you can find some excellent
pieces of lessons written on Big Data.Feel free to use any text in this file.
随时使用此文件中的任何文本。
项目结构 (Project Structure)
Before we move on and start working on the code for the project, let’s present here the project structure we will have once we’re finished adding all the code to the project:
在继续进行并开始处理项目代码之前,让我们在这里介绍完成所有代码添加到项目后将拥有的项目结构:

Project Structure
项目结构
创建WordCounter (Creating the WordCounter)
Now, we’re ready to start writing our program. When you start working with Big Data programs, imports can create a lot of confusion. To avoid this, here are all the imports we will use in our project:
现在,我们准备开始编写程序。 当您开始使用大数据程序时,导入会造成很多混乱。 为避免这种情况,以下是我们将在项目中使用的所有导入:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;Next, here is the structure of our class which we will be using:
接下来,这是我们将使用的类的结构:
package com.journaldev.sparkdemo;
...imports...
public class WordCounter {
private static void wordCount(String fileName) {
...
}
public static void main(String[] args) {
...
}
}All the logic will lie inside the wordCount method. We will start by defining an object for the SparkConf class. The object this class is used to set various Spark parameters as key-value pairs for the program. We provide just simple parameters:
所有逻辑将位于wordCount方法内。 我们将从为SparkConf类定义一个对象开始。 此类的对象用于将各种Spark参数设置为程序的键值对。 我们只提供简单的参数:
SparkConf sparkConf = new SparkConf().setMaster("local").setAppName("JD Word Counter");The master specifies local which means that this program should connect to Spark thread running on the localhost. App name is just a way to provide Spark with the application metadata. Now, we can construct a Spark Context object with this configuration object:
master指定本地,这意味着该程序应连接到在localhost上运行的Spark线程。 应用程序名称只是向Spark提供应用程序元数据的一种方式。 现在,我们可以使用以下配置对象构造一个Spark Context对象:
JavaSparkContext sparkContext = new JavaSparkContext(sparkConf);Spark considers every resource it gets to process as an RDD (Resilient Distributed Datasets) which helps it to organise the data in a find data structure which is much more efficient to be analysed. We will now convert the input file to a JavaRDD object itself:
Spark将其要处理的每个资源都视为RDD(弹性分布式数据集),这有助于其将数据组织到查找数据结构中,从而更有效地进行分析。 现在,我们将输入文件转换为JavaRDD对象本身:
JavaRDD<String> inputFile = sparkContext.textFile(fileName);We will now use Java 8 APIs to process the JavaRDD file and split the words the file contains into separate words:
现在,我们将使用Java 8 API处理JavaRDD文件,并将文件中包含的单词拆分为单独的单词:
JavaRDD<String> wordsFromFile = inputFile.flatMap(content -> Arrays.asList(content.split(" ")));Again, we make use of Java 8 mapToPair(...) method to count the words and provide a word, number pair which can be presented as an output:
同样,我们利用Java 8 mapToPair(...)方法对单词进行计数,并提供一个word, number对,可以将其显示为输出:
JavaPairRDD countData = wordsFromFile.mapToPair(t -> new Tuple2(t, 1)).reduceByKey((x, y) -> (int) x + (int) y);Now, we can save the output file as a text file:
现在,我们可以将输出文件另存为文本文件:
countData.saveAsTextFile("CountData");Finally, we can provide the entry point to our program with the main() method:
最后,我们可以使用main()方法为程序提供入口点:
public static void main(String[] args) {
if (args.length == 0) {
System.out.println("No files provided.");
System.exit(0);
}
wordCount(args[0]);
}The complete file looks like:
完整的文件如下所示:
package com.journaldev.sparkdemo;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
public class WordCounter {
private static void wordCount(String fileName) {
SparkConf sparkConf = new SparkConf().setMaster("local").setAppName("JD Word Counter");
JavaSparkContext sparkContext = new JavaSparkContext(sparkConf);
JavaRDD<String> inputFile = sparkContext.textFile(fileName);
JavaRDD<String> wordsFromFile = inputFile.flatMap(content -> Arrays.asList(content.split(" ")));
JavaPairRDD countData = wordsFromFile.mapToPair(t -> new Tuple2(t, 1)).reduceByKey((x, y) -> (int) x + (int) y);
countData.saveAsTextFile("CountData");
}
public static void main(String[] args) {
if (args.length == 0) {
System.out.println("No files provided.");
System.exit(0);
}
wordCount(args[0]);
}
}We will now move forward to run this program using Maven itself.
现在,我们将继续使用Maven本身运行该程序。
运行应用程序 (Running the Application)
To run the application, go inside the root directory of the program and execute the following command:
要运行该应用程序,请进入程序的根目录并执行以下命令:
mvn exec:java -Dexec.mainClass=com.journaldev.sparkdemo.WordCounter -Dexec.args="input.txt"In this command, we provide Maven with the fully-qualified name of the Main class and the name for input file as well. Once this command is done executing, we can see a new directory is created in our project:
在此命令中,我们为Maven提供Main类的全限定名称以及输入文件的名称。 执行完此命令后,我们可以看到在项目中创建了一个新目录:
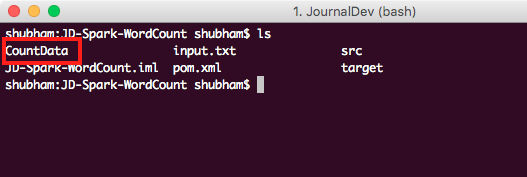
Project Output Directory
项目输出目录
When we open the directory and the file named “part-00000.txt” inside it, its contents are as follows:
打开目录和其中的名为“ part-00000.txt”的文件时,其内容如下:
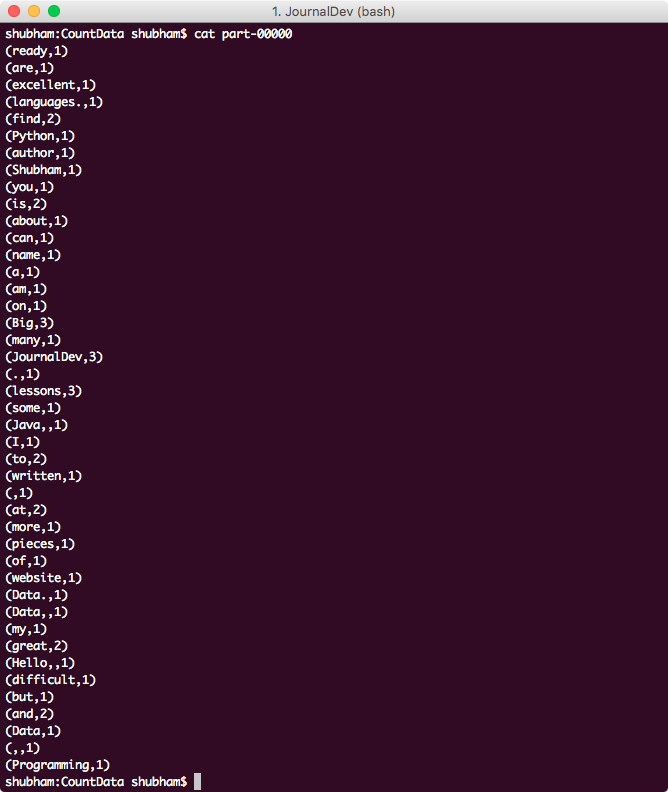
Word Counter Output
字计数器输出
结论 (Conclusion)
In this lesson, we saw how we can use Apache Spark in a Maven-based project to make a simple but effective Word counter program. Read more Big Data Posts to gain deeper knowledge of available Big Data tools and processing frameworks.
在本课程中,我们了解了如何在基于Maven的项目中使用Apache Spark来制作简单但有效的Word计数器程序。 阅读更多有关大数据的文章,以更深入地了解可用的大数据工具和处理框架。
下载源代码 (Download the Source Code)
翻译自: https://www.journaldev.com/20342/apache-spark-example-word-count-program-java
spark apache















 2441
2441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









