






Apache Spark
一、背景介绍
Spark是一个快如闪电的统一分析引擎(计算框架)用于大规模数据集的处理。Spark在做数据的批处理计算,计算性能大约是Hadoop MapReduce的10~100倍,因为Spark使用比较先进的基于DAG 任务调度,可以将一个任务拆分成若干个阶段,然后将这些阶段分批次交给集群计算节点处理。
MapReduce VS Spark
MapReduce作为第一代大数据处理框架,在设计初期只是为了满足基于海量数据级的海量数据计算的迫切需求。自2006年剥离自Nutch(Java搜索引擎)工程,主要解决的是早期人们对大数据的初级认知所面临的问题。

整个MapReduce的计算实现的是基于磁盘的IO计算,随着大数据技术的不断普及,人们开始重新定义大数据的处理方式,不仅仅满足于能在合理的时间范围内完成对大数据的计算,还对计算的实效性提出了更苛刻的要求,因为人们开始探索使用Map Reduce计算框架完成一些复杂的高阶算法,往往这些算法通常不能通过1次性的Map Reduce迭代计算完成。由于Map Reduce计算模型总是把结果存储到磁盘中,每次迭代都需要将数据磁盘加载到内存,这就为后续的迭代带来了更多延长。
2009年Spark在加州伯克利AMP实验室诞生,2010首次开源后该项目就受到很多开发人员的喜爱,2013年6月份开始在Apache孵化,2014年2月份正式成为Apache的顶级项目。Spark发展如此之快是因为Spark在计算层方面明显优于Hadoop的Map Reduce这磁盘迭代计算,因为Spark可以使用内存对数据做计算,而且计算的中间结果也可以缓存在内存中,这就为后续的迭代计算节省了时间,大幅度的提升了针对于海量数据的计算效率。

Spark也给出了在使用MapReduce和Spark做线性回归计算(算法实现需要n次迭代)上,Spark的速率几乎是MapReduce计算10~100倍这种计算速度。

不仅如此Spark在设计理念中也提出了One stack ruled them all战略,并且提供了基于Spark批处理至上的计算服务分支例如:实现基于Spark的交互查询、近实时流处理、机器学习、Grahx 图形关系存储等。

从图中不难看出Apache Spark处于计算层,Spark项目在战略上启到了承上启下的作用,并没有废弃原有以hadoop为主体的大数据解决方案。因为Spark向下可以计算来自于HDFS、HBase、Cassandra和亚马逊S3文件服务器的数据,也就意味着使用Spark作为计算层,用户原有的存储层架构无需改动。
二、计算流程
因为Spark计算是在MapReduce计算之后诞生,吸取了MapReduce设计经验,极大地规避了MapReduce计算过程中的诟病,先来回顾一下MapReduce计算的流程。

总结一下几点缺点:
1)MapReduce虽然基于矢量编程思想,但是计算状态过于简单,只是简单的将任务分为Map state和Reduce State,没有考虑到迭代计算场景。
2)在Map任务计算的中间结果存储到本地磁盘,IO调用过多,数据读写效率差。
3)MapReduce是先提交任务,然后在计算过程中申请资源。并且计算方式过于笨重。每个并行度都是由一个JVM进程来实现计算。
通过简单的罗列不难发现MapReduce计算的诟病和问题,因此Spark在计算层面上借鉴了MapReduce计算设计的经验,提出了DGASchedule和TaskSchedual概念,打破了在MapReduce任务中一个job只用Map State和Reduce State的两个阶段,并不适合一些迭代计算次数比较多的场景。因此Spark 提出了一个比较先进的设计理念,任务状态拆分,Spark在任务计算初期首先通过DGASchedule计算任务的State,将每个阶段的Sate封装成一个TaskSet,然后由TaskSchedual将TaskSet提交集群进行计算。可以尝试将Spark计算的流程使用一下的流程图描述如下:
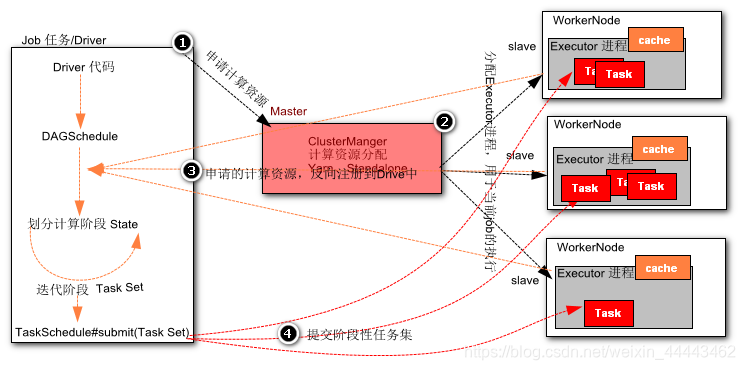
相比较于MapReduce计算,Spark计算有以下优点:
1)智能DAG任务拆分,将一个复杂计算拆分成若干个State,满足迭代计算场景
2)Spark提供了计算的缓存和容错策略,将计算结果存储在内存或者磁盘,加速每个state的运行,提升运行效率
3)Spark在计算初期,就已经申请好计算资源。任务并行度是通过在Executor进程中启动线程实现,相比较于MapReduce计算更加轻快。
目前Spark提供了Cluster Manager的实现由Yarn、Standalone、Messso、kubernates等实现。其中企业常用的有Yarn和Standalone方式的管理。
三、环境搭建-单机版
1.Standalone
Hadoop环境
- 设置CentOS进程数和文件数(重启)
[root@CentOS ~]# vi /etc/security/limits.conf
* soft nofile 204800
* hard nofile 204800
* soft nproc 204800
* hard nproc 204800
[root@CentOS ~]# reboot
- 配置主机名(重启)
[root@CentOS ~]# vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=CentOS
[root@CentOS ~]# reboot
- 设置IP映射
[root@CentOS ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.111.132 CentOS
- 防火墙服务
[root@CentOS ~]# service iptables stop
iptables: Setting chains to policy ACCEPT: filter [ OK ]
iptables: Flushing firewall rules: [ OK ]
iptables: Unloading modules: [ OK ]
[root@CentOS ~]# chkconfig iptables off
- 安装JDK1.8+
[root@CentOS ~]# rpm -ivh jdk-8u191-linux-x64.rpm
warning: jdk-8u191-linux-x64.rpm: Header V3 RSA/SHA256 Signature, key ID ec551f03: NOKEY
Preparing... ########################################### [100%]
1:jdk1.8 ########################################### [100%]
Unpacking JAR files...
tools.jar...
plugin.jar...
javaws.jar...
deploy.jar...
rt.jar...
jsse.jar...
charsets.jar...
localedata.jar...
[root@CentOS ~]# vi .bashrc
JAVA_HOME=/usr/java/latest
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
[root@CentOS ~]# source ~/.bashrc
- SSH配置免密
[root@CentOS ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
a5:2d:f5:c3:22:83:cf:13:25:59:fb:c1:f4:63:06:d4 root@CentOS
The key's randomart image is:
+--[ RSA 2048]----+
| ..+. |
| o + oE |
| o = o = |
| . B + + . |
| . S o = |
| o = . . |
| + |
| . |
| |
+-----------------+
[root@CentOS ~]# ssh-copy-id CentOS
The authenticity of host 'centos (192.168.111.132)' can't be established.
RSA key fingerprint is fa:1b:c0:23:86:ff:08:5e:83:ba:65:4c:e6:f2:1f:3b.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'centos,192.168.111.132' (RSA) to the list of known hosts.
root@centos's password:`需要输入密码`
Now try logging into the machine, with "ssh 'CentOS'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
- 配置HDFS
将hadoop-2.9.2.tar.gz解压到系统的/usr目录下然后配置[core|hdfs]-site.xml配置文件。
[root@CentOS ~]# vi /usr/hadoop-2.9.2/etc/hadoop/core-site.xml
<!--nn访问入口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://CentOS:9000</value>
</property>
<!--hdfs工作基础目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop-2.9.2/hadoop-${user.name}</value>
</property>
[root@CentOS ~]# vi /usr/hadoop-2.9.2/etc/hadoop/hdfs-site.xml
<!--block副本因子-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--配置Sencondary namenode所在物理主机-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>CentOS:50090</value>
</property>
<!--设置datanode最大文件操作数-->
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
<!--设置datanode并行处理能力-->
<property>
<name>dfs.datanode.handler.count</name>
<value>6</value>
</property>
[root@CentOS ~]# vi /usr/hadoop-2.9.2/etc/hadoop/slaves
CentOS
- 配置hadoop环境变量
[root@CentOS ~]# vi .bashrc
HADOOP_HOME=/usr/hadoop-2.9.2
JAVA_HOME=/usr/java/latest
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
export HADOOP_HOME
[root@CentOS ~]# source .bashrc
- 启动Hadoop服务
[root@CentOS ~]# hdfs namenode -format # 创建初始化所需的fsimage文件
[root@CentOS ~]# start-dfs.sh
- Spark环境
下载spark-2.4.3-bin-without-hadoop.tgz解压到/usr目录,并且将Spark目录修改名字为spark-2.4.3然后修改spark-env.sh和spark-default.conf文件.
下载地址:http://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.3/spark-2.4.3-bin-without-hadoop.tgz
- 解压Spark安装包,并且修改解压文件名
[root@CentOS ~]# tar -zxf spark-2.4.3-bin-without-hadoop.tgz -C /usr/
[root@CentOS ~]# mv /usr/spark-2.4.3-bin-without-hadoop/ /usr/spark-2.4.3
[root@CentOS ~]# vi .bashrc
SPARK_HOME=/usr/spark-2.4.3
HADOOP_HOME=/usr/hadoop-2.9.2
JAVA_HOME=/usr/java/latest
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$SPARK_HOME/sbin
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
export HADOOP_HOME
export SPARK_HOME
[root@CentOS ~]# source .bashrc
- 配置Spark服务
[root@CentOS spark-2.4.3]# cd /usr/spark-2.4.3/conf/
[root@CentOS conf]# mv spark-env.sh.template spark-env.sh
[root@CentOS conf]# mv slaves.template slaves
[root@CentOS conf]# vi slaves
CentOS
[root@CentOS conf]# vi spark-env.sh
SPARK_MASTER_HOST=CentOS
SPARK_MASTER_PORT=7077
SPARK_WORKER_CORES=4
SPARK_WORKER_MEMORY=2g
LD_LIBRARY_PATH=/usr/hadoop-2.9.2/lib/native
SPARK_DIST_CLASSPATH=$(hadoop classpath)
export SPARK_MASTER_HOST
export SPARK_MASTER_PORT
export SPARK_WORKER_CORES
export SPARK_WORKER_MEMORY
export LD_LIBRARY_PATH
export SPARK_DIST_CLASSPATH
- 启动Spark进程
[root@CentOS ~]# cd /usr/spark-2.4.3/
[root@CentOS spark-2.4.3]# ./sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/spark-2.4.3/logs/spark-root-org.apache.spark.deploy.master.Master-1-CentOS.out
CentOS: starting org.apache.spark.deploy.worker.Worker, logging to /usr/spark-2.4.3/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-CentOS.out
- 测试Spark
[root@CentOS spark-2.4.3]# ./bin/spark-shell
--master spark://CentOS:7077
--deploy-mode client
--executor-cores 2
executor-cores:在standalone模式表示程序每个Worker节点分配资源数。不能超过单台自大core个数,如果不清每台能够分配的最大core的个数,可以使用--total-executor-cores,该种分配会尽最大可能分配。
scala> sc.textFile("hdfs:///words/t_words",5)
.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.sortBy(_._1,true,3)
.saveAsTextFile("hdfs:///results")
2.Spark On Yarn
Hadoop环境
- 设置CentOS进程数和文件数(重启)
[root@CentOS ~]# vi /etc/security/limits.conf
* soft nofile 204800
* hard nofile 204800
* soft nproc 204800
* hard nproc 204800
[root@CentOS ~]# reboot
- 配置主机名(重启)
[root@CentOS ~]# vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=CentOS
[root@CentOS ~]# reboot
- 设置IP映射
[root@CentOS ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.111.132 CentOS
- 防火墙服务
[root@CentOS ~]# service iptables stop
iptables: Setting chains to policy ACCEPT: filter [ OK ]
iptables: Flushing firewall rules: [ OK ]
iptables: Unloading modules: [ OK ]
[root@CentOS ~]# chkconfig iptables off
- 安装JDK1.8+
[root@CentOS ~]# rpm -ivh jdk-8u191-linux-x64.rpm
warning: jdk-8u191-linux-x64.rpm: Header V3 RSA/SHA256 Signature, key ID ec551f03: NOKEY
Preparing... ########################################### [100%]
1:jdk1.8 ########################################### [100%]
Unpacking JAR files...
tools.jar...
plugin.jar...
javaws.jar...
deploy.jar...
rt.jar...
jsse.jar...
charsets.jar...
localedata.jar...
[root@CentOS ~]# vi .bashrc
JAVA_HOME=/usr/java/latest
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
[root@CentOS ~]# source ~/.bashrc
- SSH配置免密
[root@CentOS ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
a5:2d:f5:c3:22:83:cf:13:25:59:fb:c1:f4:63:06:d4 root@CentOS
The key's randomart image is:
+--[ RSA 2048]----+
| ..+. |
| o + oE |
| o = o = |
| . B + + . |
| . S o = |
| o = . . |
| + |
| . |
| |
+-----------------+
[root@CentOS ~]# ssh-copy-id CentOS
The authenticity of host 'centos (192.168.111.132)' can't be established.
RSA key fingerprint is fa:1b:c0:23:86:ff:08:5e:83:ba:65:4c:e6:f2:1f:3b.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'centos,192.168.111.132' (RSA) to the list of known hosts.
root@centos's password:`需要输入密码`
Now try logging into the machine, with "ssh 'CentOS'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
- 配置HDFS
将hadoop-2.9.2.tar.gz解压到系统的/usr目录下然后配置[core|hdfs]-site.xml配置文件。
[root@CentOS ~]# vi /usr/hadoop-2.9.2/etc/hadoop/core-site.xml
<!--nn访问入口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://CentOS:9000</value>
</property>
<!--hdfs工作基础目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop-2.9.2/hadoop-${user.name}</value>
</property>
[root@CentOS ~]# vi /usr/hadoop-2.9.2/etc/hadoop/hdfs-site.xml
<!--block副本因子-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--配置Sencondary namenode所在物理主机-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>CentOS:50090</value>
</property>
<!--设置datanode最大文件操作数-->
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
<!--设置datanode并行处理能力-->
<property>
<name>dfs.datanode.handler.count</name>
<value>6</value>
</property>
[root@CentOS ~]# vi /usr/hadoop-2.9.2/etc/hadoop/slaves
CentOS
[root@CentOS ~]# vi /usr/hadoop-2.9.2/etc/hadoop/yarn-site.xml
<!--配置MapReduce计算框架的核心实现Shuffle-洗牌-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--配置资源管理器所在的目标主机-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>CentOS</value>
</property>
<!--关闭物理内存检查-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--关闭虚拟内存检查-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
[root@CentOS ~]# vi /usr/hadoop-2.9.2/etc/hadoop/mapred-site.xml
<!--MapRedcue框架资源管理器的实现-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- 配置hadoop环境变量
[root@CentOS ~]# vi .bashrc
HADOOP_HOME=/usr/hadoop-2.9.2
JAVA_HOME=/usr/java/latest
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
export HADOOP_HOME
[root@CentOS ~]# source .bashrc
- 启动Hadoop服务
[root@CentOS ~]# hdfs namenode -format # 创建初始化所需的fsimage文件
[root@CentOS ~]# start-dfs.sh
[root@CentOS ~]# start-yarn.sh
- Spark环境
下载spark-2.4.3-bin-without-hadoop.tgz解压到/usr目录,并且将Spark目录修改名字为spark-2.4.3然后修改spark-env.sh和spark-default.conf文件.
下载地址:http://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.3/spark-2.4.3-bin-without-hadoop.tgz
- 解压Spark安装包,并且修改解压文件名
[root@CentOS ~]# tar -zxf spark-2.4.3-bin-without-hadoop.tgz -C /usr/
[root@CentOS ~]# mv /usr/spark-2.4.3-bin-without-hadoop/ /usr/spark-2.4.3
[root@CentOS ~]# vi .bashrc
SPARK_HOME=/usr/spark-2.4.3
HADOOP_HOME=/usr/hadoop-2.9.2
JAVA_HOME=/usr/java/latest
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$SPARK_HOME/sbin
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
export HADOOP_HOME
export SPARK_HOME
[root@CentOS ~]# source .bashrc
- 配置Spark服务
[root@CentOS spark-2.4.3]# cd /usr/spark-2.4.3/conf/
[root@CentOS conf]# mv spark-env.sh.template spark-env.sh
[root@CentOS conf]# vi spark-env.sh
HADOOP_CONF_DIR=/usr/hadoop-2.9.2/etc/hadoop
YARN_CONF_DIR=/usr/hadoop-2.9.2/etc/hadoop
SPARK_EXECUTOR_CORES=4
SPARK_EXECUTOR_MEMORY=2G
SPARK_DRIVER_MEMORY=1G
LD_LIBRARY_PATH=/usr/hadoop-2.9.2/lib/native
SPARK_DIST_CLASSPATH=$(hadoop classpath):$SPARK_DIST_CLASSPATH
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs:///spark-logs"
export HADOOP_CONF_DIR
export YARN_CONF_DIR
export SPARK_EXECUTOR_CORES
export SPARK_DRIVER_MEMORY
export SPARK_EXECUTOR_MEMORY
export LD_LIBRARY_PATH
export SPARK_DIST_CLASSPATH
export SPARK_HISTORY_OPTS
[root@CentOS conf]# mv spark-defaults.conf.template spark-defaults.conf
[root@CentOS conf]# vi spark-defaults.conf
spark.eventLog.enabled=true
spark.eventLog.dir=hdfs:///spark-logs
在HDFS上创建spark-logs目录,用于作为Sparkhistory服务器存储数据的地方。
[root@CentOS ~]# hdfs dfs -mkdir /spark-logs
- 启动Spark历史服务器(可选)
[root@CentOS spark-2.4.3]# ./sbin/start-history-server.sh
starting org.apache.spark.deploy.history.HistoryServer, logging to /usr/spark-2.4.3/logs/spark-root-org.apache.spark.deploy.history.HistoryServer-1-CentOS.out
[root@CentOS spark-2.4.3]# jps
5728 NodeManager
5090 NameNode
5235 DataNode
10531 Jps
5623 ResourceManager
5416 SecondaryNameNode
10459 HistoryServer
改进程启动一个内嵌的web ui端口是18080,用户可以访问改页面查看任务执行计划、历史。
- 测试Spark
./bin/spark-shell
--master yarn
--deploy-mode client
--num-executors 2
--executor-cores 3
--num-executors:在Yarn模式下,表示向NodeManager申请的资源数进程,--executor-cores表示每个进程所能运行线程数。真个任务计算资源= num-executors * executor-core
scala> sc.textFile("hdfs:///words/t_words",5)
.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.sortBy(_._1,true,3)
.saveAsTextFile("hdfs:///results")
3.本地仿真
在该种模式下,无需安装yarn、无需启动Stanalone,一切都是模拟。
[root@CentOS spark-2.4.3]# ./bin/spark-shell --master local[5]
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://CentOS:4040
Spark context available as 'sc' (master = local[5], app id = local-1561742649329).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.3
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_191)
Type in expressions to have them evaluated.
Type :help for more information.
scala> sc.textFile("hdfs:///words/t_words").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._1,false,3).saveAsTextFile("hdfs:///results1/")
scala>
四、Spark的Java开发环境构建
- 引入开发所需依赖
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.3</version>
</dependency>
</dependencies>
<build>
<plugins>
<!--scala编译插件-->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.0.1</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
- SparkRDDWordCount(本地)
//1.创建SparkContext
val conf = new SparkConf().setMaster("local[10]").setAppName("wordcount")
val sc = new SparkContext(conf)
val lineRDD: RDD[String] = sc.textFile("file:///E:/demo/words/t_word.txt")
lineRDD.flatMap(line=>line.split(" "))
.map(word=>(word,1))
.groupByKey()
.map(tuple=>(tuple._1,tuple._2.sum))
.sortBy(tuple=>tuple._2,false,1)
.collect()
.foreach(tuple=>println(tuple._1+"->"+tuple._2))
//3.关闭sc
sc.stop()
- 集群(yarn)
//1.创建SparkContext
val conf = new SparkConf().setMaster("yarn").setAppName("wordcount")
val sc = new SparkContext(conf)
val lineRDD: RDD[String] = sc.textFile("hdfs:///words/t_words")
lineRDD.flatMap(line=>line.split(" "))
.map(word=>(word,1))
.groupByKey()
.map(tuple=>(tuple._1,tuple._2.sum))
.sortBy(tuple=>tuple._2,false,1)
.collect()
.foreach(tuple=>println(tuple._1+"->"+tuple._2))
//3.关闭sc
sc.stop()
发布:
[root@CentOS spark-2.4.3]# ./bin/spark-submit --master yarn --deploy-mode client --class com.baizhi.demo02.SparkRDDWordCount --num-executors 3 --executor-cores 4 /root/sparkrdd-1.0-SNAPSHOT.jar
- 集群(standalone)
//1.创建SparkContext
val conf = new SparkConf().setMaster("spark://CentOS:7077").setAppName("wordcount")
val sc = new SparkContext(conf)
val lineRDD: RDD[String] = sc.textFile("hdfs:///words/t_words")
lineRDD.flatMap(line=>line.split(" "))
.map(word=>(word,1))
.groupByKey()
.map(tuple=>(tuple._1,tuple._2.sum))
.sortBy(tuple=>tuple._2,false,1)
.collect()
.foreach(tuple=>println(tuple._1+"->"+tuple._2))
//3.关闭sc
sc.stop()
发布:
[root@CentOS spark-2.4.3]# ./bin/spark-submit --master spark://CentOS:7077 --deploy-mode client --class com.baizhi.demo02.SparkRDDWordCount --num-executors 3 --total-executor-cores 4 /root/sparkrdd-1.0-SNAPSHOT.jar
五、RDD机制
(一)RDD概念
Spark计算中一个重要的概念就是可以跨越多个节点的可伸缩分布式数据集 RDD(resilient distributed dataset),Spark的内存计算的核心就是RDD的并行计算。RDD可以理解是一个弹性的,分布式、不可变的、带有分区的数据集合,所谓的Spark的批处理,实际上就是针对RDD的集合操作,RDD有以下特点:
- 任意一个RDD都包含分区数(决定程序某个阶段计算并行度)
- RDD所谓的分布式计算是在分区内部计算的
- 因为RDD是只读的,RDD之间的变换存着依赖关系(宽依赖、窄依赖)
- 针对于k-v类型的RDD,一般可以指定分区策略(一般系统提供)
- 针对于存储在HDFS上的文件,系统可以计算最优位置,计算每个切片。(了解)
如下案例:
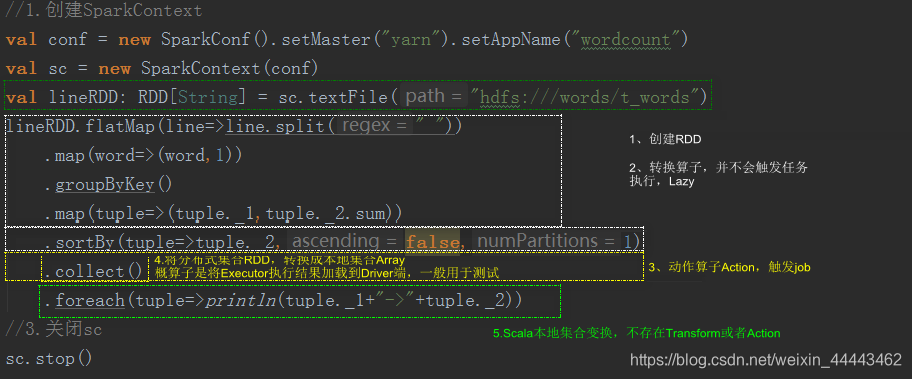
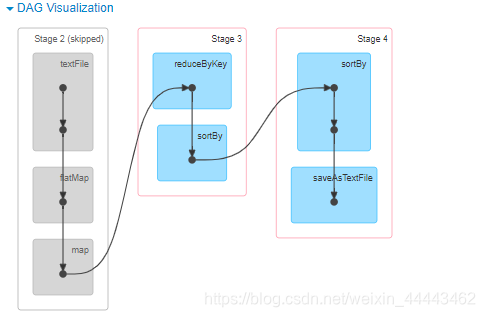
通过上述的代码中不难发现,Spark的整个任务的计算围绕RDD的三种类型操作RDD创建、RDD转换、RDD Action。通常习惯性的将flatMap/map/reduceByKey称为RDD的转换算子,collect触发任务执行,因此被人们称为动作算子。在Spark中所有的Transform算子都是lazy执行的,只有在Action算子的时候,Spark才会真正的运行任务,也就是说只有遇到Action算子的时候,SparkContext才会对任务做DAG状态拆分,系统才会计算每个状态下任务的TaskSet,继而TaskSchedule才会将任务提交给Executors执行。现将以上字符统计计算流程描述如下:

textFile(“路径”,分区数) -> flatMap -> map -> reduceByKey -> sortBy在这些转换中其中flatMap/map
、reduceByKey、sortBy都是转换算子,所有的转换算子都是Lazy执行的。程序在遇到collect(Action 算子)系统会触发job执行。
(二)RDD的容错机制
Spark底层会按照RDD的依赖关系将整个计算拆分成若干个阶段,我们通常将RDD的依赖关系称为RDD的血统-lineage。
Spark的计算本质就是对RDD做各种转换,因为RDD是一个不可变只读的集合,因此每次的转换都需要上一次的RDD作为本次转换的输入,因此RDD的lineage描述的是RDD间的相互依赖关系。为了保证RDD中数据的健壮性,RDD数据集通过所谓的血统关系(Lineage)记住了它是如何从其它RDD中演变过来的。Spark将RDD之间的关系归类为宽依赖和窄依赖。Spark会根据Lineage存储的RDD的依赖关系对RDD计算做故障容错,目前Saprk的容错策略根据RDD依赖关系重新计算、对RDD做Cache、对RDD做Checkpoint手段完成RDD计算的故障容错。
宽依赖|窄依赖
RDD在Lineage依赖方面分为两种Narrow Dependencies与Wide Dependencies用来解决数据容错的高效性。Narrow Dependencies是指父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区或多个父RDD的分区对应于子RDD的一个分区,也就是说一个父RDD的一个分区不可能对应一个子RDD的多个分区。Wide Dependencies父RDD的一个分区对应一个子RDD的多个分区。

对于Wide Dependencies这种计算的输入和输出在不同的节点上,一般需要跨节点做Shuffle,因此如果是RDD在做宽依赖恢复的时候需要多个节点重新计算成本较高。相对于Narrow Dependencies RDD间的计算是在同一个Task当中实现的是线程内部的的计算,因此在RDD分区数据丢失的的时候,也非常容易恢复。
(三)Stage阶段划分(重点)
Spark任务阶段的划分是按照RDD的lineage关系逆向生成的一个过程,Spark任务提交的大致流程及源码解析如下图所示:
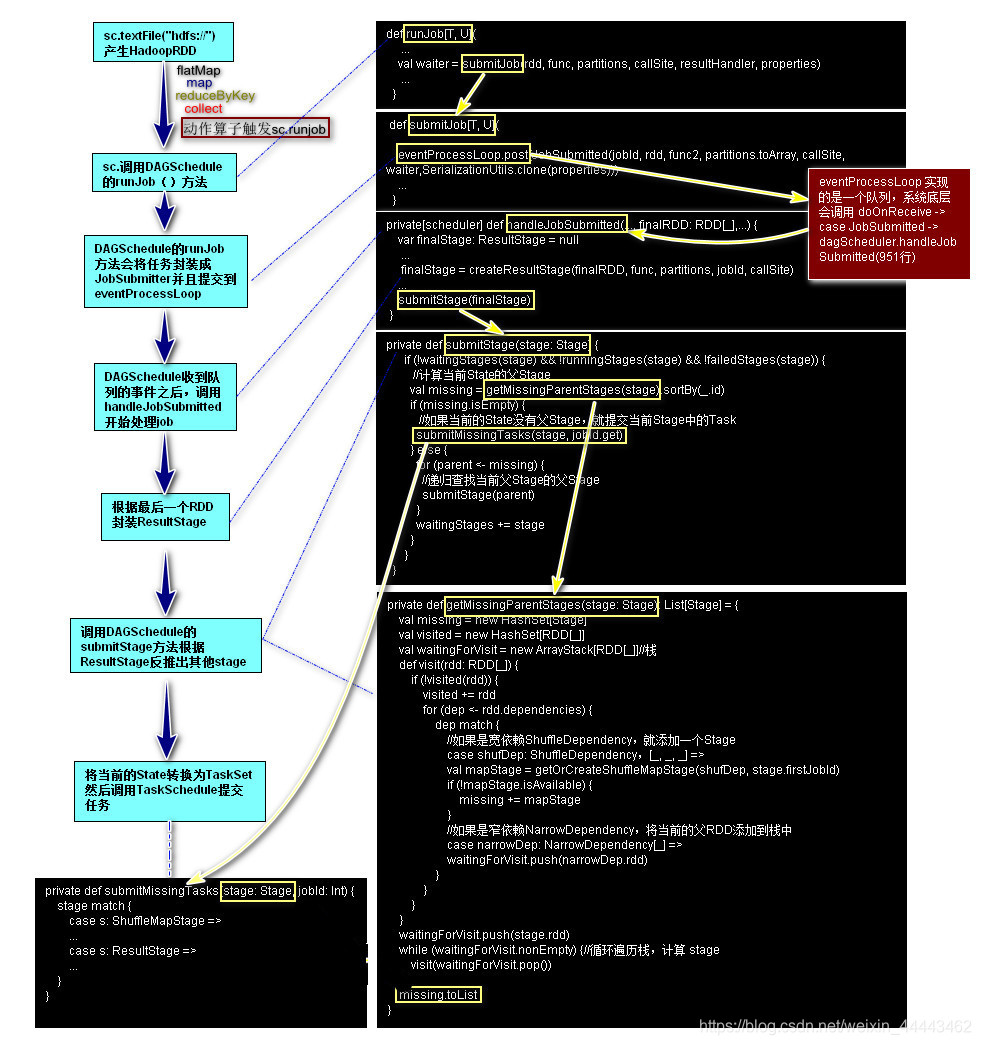
通过以上源码分析,可以得出Spark所谓宽窄依赖事实上指的是ShuffleDependency或者是NarrowDependency。如果是ShuffleDependency系统会生成一个ShuffeMapStage,如果是NarrowDependency则忽略,归为当前Stage。当系统回推到起始RDD的时候因为发现当前RDD或者ShuffleMapStage没有父Stage的时候,当前系统会将当前State下的Task封装成ShuffleMapTask(如果是ResultStage就是ResultTask),当前Task的数目等于当前state分区的分区数。然后将Task封装成TaskSet通过调用taskScheduler.submitTasks将任务提交给集群。
(四)RDD缓存
缓存是一种RDD计算容错的一种手段,程序在RDD数据丢失的时候,可以通过缓存快速计算当前RDD的值,而不需要反推出所有的RDD重新计算,因此Spark在需要对某个RDD多次使用的时候,为了提高程序的执行效率用户可以考虑使用RDD的cache。如下测试:
val conf = new SparkConf()
.setAppName("word-count")
.setMaster("local[2]")
val sc = new SparkContext(conf)
val value: RDD[String] = sc.textFile("file:///D:/demo/words/")
.cache()//添加缓存
value.count()
//失效缓存value.unpersist()
sc.stop()
除了调用cache之外,Spark提供了更细粒度的RDD缓存方案,用户可以根据集群的内存状态选择合适的缓存策略。用户可以使用persist方法指定缓存级别。缓存级别有如下可选项:
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
xxRDD.persist(StorageLevel.MEMORY_AND_DISK_SER_2)
其中:
-
MEMORY_ONLY:表示数据完全不经过序列化存储在内存中,效率高,但是有可能导致内存溢出. -
MEMORY_ONLY_SER和MEMORY_ONLY一样,只不过需要对RDD的数据做序列化,牺牲CPU节省内存,同样会导致内存溢出可能。 -
其中
_2表示缓存结果有备份,如果大家不确定该使用哪种级别,一般推荐MEMORY_AND_DISK_SER_2
(五)Check Point 机制
除了使用缓存机制可以有效的保证RDD的故障恢复,但是如果缓存失效还是会在导致系统重新计算RDD的结果,所以对于一些RDD的lineage较长的场景,计算比较耗时,用户可以尝试使用checkpoint机制存储RDD的计算结果,该种机制和缓存最大的不同在于,使用checkpoint之后被checkpoint的RDD数据直接持久化在文件系统中,一般推荐将结果写在hdfs中,这种checpoint并不会自动清空。注意checkpoint在计算的过程中先是对RDD做mark,在任务执行结束后,再对mark的RDD实行checkpoint,也就是要重新计算被Mark之后的rdd的依赖和结果,因此为了避免Mark RDD重复计算,推荐使用策略
val conf = new SparkConf().setMaster("yarn").setAppName("wordcount")
val sc = new SparkContext(conf)
sc.setCheckpointDir("hdfs:///checkpoints")
val lineRDD: RDD[String] = sc.textFile("hdfs:///words/t_word.txt")
val cacheRdd = lineRDD.flatMap(line => line.split(" "))
.map(word => (word, 1))
.groupByKey()
.map(tuple => (tuple._1, tuple._2.sum))
.sortBy(tuple => tuple._2, false, 1)
.cache()
cacheRdd.checkpoint()
cacheRdd.collect().foreach(tuple=>println(tuple._1+"->"+tuple._2))
cacheRdd.unpersist()
//3.关闭sc
sc.stop()
(六)RDD算子
1.转换算子(Transformation)
| 算子 | 作用 |
|---|---|
| map | 对元素进行RDD转换(类型) |
| filter | 过滤得到满足条件的新RDD |
| flatMap | 将一个元素转换成元素数组,然后对数组进行展开 |
| mapPartitions | 与map类似,但在RDD的每个分区(块)上单独运行 |
| mapPartitionsWithIndex | 与mapPartitions类似,但也为func提供了表示分区索引的整数值 |
| sample | 对数据进行一定比例的采样,得到新的RDD |
| union | 返回一个新RDD,其中包含源数据集和参数中元素的并集。 |
| intersection | 返回包含源数据集和参数中元素交集的新RDD |
| distinct | 返回包含源数据集的不同元素的新RDD(去重)。 |
| groupByKey | 在(K,V)对的数据集上调用时,返回(K,Iterable )对的数据集 |
| reduceByKey | 当调用(K,V)对的数据集时,返回(K,V)对的数据集 |
| aggregateByKey | 当调用(K,V)对的数据集时,返回(K,U)对的数据集 |
| sortByKey | 返回按Key进行排序的RDD |
| sortBy | 返回可以指定按K或V进行排序的RDD |
| join | 当调用类型(K,V)和(K,W)的RDD时,返回(K,(V,W))对的RDD |
| cogroup | 当调用类型(K,V)和(K,W)的RDD时,返回(K,(Iterable ,Iterable ))元组的RDD |
| cartesian | 当调用类型为T和U的数据集时,返回(T,U)对的数据集(所有元素对)。 |
| coalesce(numPartitions) | 将RDD中的分区数减少为numPartitions |
| repartition | 随机重新调整RDD中的数据以创建更多或更少的分区。 |
map(function)
传入的集合元素进行RDD[T]转换 def map(f: T => U): org.apache.spark.rdd.RDD[U]
scala> sc.parallelize(List(1,2,3,4,5),3).map(item => item*2+" " )
res1: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at map at <console>:25
scala> sc.parallelize(List(1,2,3,4,5),3).map(item => item*2+" " ).collect
res2: Array[String] = Array("2 ", "4 ", "6 ", "8 ", "10 ")
filter(func)
将满足条件结果记录 def filter(f: T=> Boolean): org.apache.spark.rdd.RDD[T]
scala> sc.parallelize(List(1,2,3,4,5),3).filter(item=> item%2==0).collect
res3: Array[Int] = Array(2, 4)
flatMap(func)
将一个元素转换成元素的数组,然后对数组展开。def flatMap[U](f: T=> TraversableOnce[U]): org.apache.spark.rdd.RDD[U]
scala> sc.parallelize(List("ni hao","hello spark"),3).flatMap(line=>line.split("\\s+")).collect
res4: Array[String] = Array(ni, hao, hello, spark)
mapPartitions(func)
与map类似,但在RDD的每个分区(块)上单独运行,因此当在类型T的RDD上运行时,func必须是Iterator <T> => Iterator <U>类型
def mapPartitions[U](f: Iterator[Int] => Iterator[U],preservesPartitioning: Boolean): org.apache.spark.rdd.RDD[U]
scala> sc.parallelize(List(1,2,3,4,5),3).mapPartitions(items=> for(i<-items;if(i%2==0)) yield i*2 ).collect()
res7: Array[Int] = Array(4, 8)
mapPartitionsWithIndex(func)
与mapPartitions类似,但也为func提供了表示分区索引的整数值,因此当在类型T的RDD上运行时,func必须是类型(Int,Iterator <T>)=> Iterator <U>。
def mapPartitionsWithIndex[U](f: (Int, Iterator[T]) => Iterator[U],preservesPartitioning: Boolean): org.apache.spark.rdd.RDD[U]
scala> sc.parallelize(List(1,2,3,4,5),3).mapPartitionsWithIndex((p,items)=> for(i<-items) yield (p,i)).collect
res11: Array[(Int, Int)] = Array((0,1), (1,2), (1,3), (2,4), (2,5))
sample(withReplacement, fraction, seed)
对数据进行一定比例的采样,使用withReplacement参数控制是否允许重复采样。
def sample(withReplacement: Boolean,fraction: Double,seed: Long): org.apache.spark.rdd.RDD[T]
scala> sc.parallelize(List(1,2,3,4,5,6,7),3).sample(false,0.7,1L).collect
res13: Array[Int] = Array(1, 4, 6, 7)
union(otherDataset)
返回一个新数据集,其中包含源数据集和参数中元素的并集。
def union(other: org.apache.spark.rdd.RDD[T]): org.apache.spark.rdd.RDD[T]
scala> var rdd1=sc.parallelize(Array(("张三",1000),("李四",100),("赵六",300)))
scala> var rdd2=sc.parallelize(Array(("张三",1000),("王五",100),("温七",300)))
scala> rdd1.union(rdd2).collect
res16: Array[(String, Int)] = Array((张三,1000), (李四,100), (赵六,300), (张三,1000), (王五,100), (温七,300))
intersection(otherDataset)
返回包含源数据集和参数中元素交集的新RDD。
def intersection(other: org.apache.spark.rdd.RDD[T],numPartitions: Int): org.apache.spark.rdd.RDD[T]
scala> var rdd1=sc.parallelize(Array(("张三",1000),("李四",100),("赵六",300)))
scala> var rdd2=sc.parallelize(Array(("张三",1000),("王五",100),("温七",300)))
scala> rdd1.intersection(rdd2).collect
res17: Array[(String, Int)] = Array((张三,1000))
distinct([numPartitions]))
返回包含源数据集的不同元素的新数据集。
scala> sc.parallelize(List(1,2,3,3,5,7,2),3).distinct.collect
res19: Array[Int] = Array(3, 1, 7, 5, 2)
groupByKey([numPartitions])
在(K,V)对的数据集上调用时,返回(K,Iterable <V>)对的数据集。 注意:如果要对每个键执行聚合(例如总和或平均值)进行分组,则使用reduceByKey或aggregateByKey将产生更好的性能。 注意:默认情况下,输出中的并行级别取决于父RDD的分区数。您可以传递可选的numPartitions参数来设置不同数量的任务。
scala> sc.parallelize(List("ni hao","hello spark"),3).flatMap(line=>line.split("\\s+")).map(word=>(word,1)).groupByKey(3).map(tuple=>(tuple._1,tuple._2.sum)).collect
reduceByKey(func, [numPartitions])
当调用(K,V)对的数据集时,返回(K,V)对的数据集,其中使用给定的reduce函数func聚合每个键的值,该函数必须是类型(V,V)=> V.
scala> sc.parallelize(List("ni hao","hello spark"),3).flatMap(line=>line.split("\\s+")).map(word=>(word,1)).reduceByKey((v1,v2)=>v1+v2).collect()
res33: Array[(String, Int)] = Array((hao,1), (hello,1), (spark,1), (ni,1))
scala> sc.parallelize(List("ni hao","hello spark"),3).flatMap(line=>line.split("\\s+")).map(word=>(word,1)).reduceByKey(_+_).collect()
res34: Array[(String, Int)] = Array((hao,1), (hello,1), (spark,1), (ni,1))
aggregateByKey(zeroValue)(seqOp, combOp, [numPartitions])
当调用(K,V)对的数据集时,返回(K,U)对的数据集,其中使用给定的组合函数和中性“零”值聚合每个键的值。允许与输入值类型不同的聚合值类型,同时避免不必要的分配。
scala> sc.parallelize(List("ni hao","hello spark"),3).flatMap(line=>line.split("\\s+")).map(word=>(word,1)).aggregateByKey(0L)((z,v)=>z+v,(u1,u2)=>u1+u2).collect
res35: Array[(String, Long)] = Array((hao,1), (hello,1), (spark,1), (ni,1))
sortByKey([ascending], [numPartitions])
当调用K实现Ordered的(K,V)对数据集时,返回按键升序或降序排序的(K,V)对数据集,如布尔升序参数中所指定。
scala> sc.parallelize(List("ni hao","hello spark"),3).flatMap(line=>line.split("\\s+")).map(word=>(word,1)).aggregateByKey(0L)((z,v)=>z+v,(u1,u2)=>u1+u2).sortByKey(false).collect()
res37: Array[(String, Long)] = Array((spark,1), (ni,1), (hello,1), (hao,1))
sortBy(func,[ascending], [numPartitions])**
对(K,V)数据集调用sortBy时,用户可以通过指定func指定排序规则,T => U 要求U必须实现Ordered接口
scala> sc.parallelize(List("ni hao","hello spark"),3).flatMap(line=>line.split("\\s+")).map(word=>(word,1)).aggregateByKey(0L)((z,v)=>z+v,(u1,u2)=>u1+u2).sortBy(_._2,true,2).collect
res42: Array[(String, Long)] = Array((hao,1), (hello,1), (spark,1), (ni,1))
join
当调用类型(K,V)和(K,W)的数据集时,返回(K,(V,W))对的数据集以及每个键的所有元素对。通过leftOuterJoin,rightOuterJoin和fullOuterJoin支持外连接。
scala> var rdd1=sc.parallelize(Array(("001","张三"),("002","李四"),("003","王五")))
scala> var rdd2=sc.parallelize(Array(("001",("apple",18.0)),("001",("orange",18.0))))
scala> rdd1.join(rdd2).collect
res43: Array[(String, (String, (String, Double)))] = Array((001,(张三,(apple,18.0))), (001,(张三,(orange,18.0))))
cogroup
当调用类型(K,V)和(K,W)的数据集时,返回(K,(Iterable ,Iterable ))元组的数据集。此操作也称为groupWith。
scala> var rdd1=sc.parallelize(Array(("001","张三"),("002","李四"),("003","王五")))
scala> var rdd2=sc.parallelize(Array(("001","apple"),("001","orange"),("002","book")))
scala> rdd1.cogroup(rdd2).collect()
res46: Array[(String, (Iterable[String], Iterable[String]))] = Array((001,(CompactBuffer(张三),CompactBuffer(apple, orange))), (002,(CompactBuffer(李四),CompactBuffer(book))), (003,(CompactBuffer(王五),CompactBuffer())))
cartesian
当调用类型为T和U的数据集时,返回(T,U)对的数据集(所有元素对)。
scala> var rdd1=sc.parallelize(List("a","b","c"))
scala> var rdd2=sc.parallelize(List(1,2,3,4))
scala> rdd1.cartesian(rdd2).collect()
res47: Array[(String, Int)] = Array((a,1), (a,2), (a,3), (a,4), (b,1), (b,2), (b,3), (b,4), (c,1), (c,2), (c,3), (c,4))
coalesce(numPartitions)
将RDD中的分区数减少为numPartitions。过滤大型数据集后,可以使用概算子减少分区数。
scala> sc.parallelize(List("ni hao","hello spark"),3).coalesce(1).partitions.length
res50: Int = 1
scala> sc.parallelize(List("ni hao","hello spark"),3).coalesce(1).getNumPartitions
res51: Int = 1
repartition
随机重新调整RDD中的数据以创建更多或更少的分区。
scala> sc.parallelize(List("a","b","c"),3).mapPartitionsWithIndex((index,values)=>for(i<-values) yield (index,i) ).collect
res52: Array[(Int, String)] = Array((0,a), (1,b), (2,c))
scala> sc.parallelize(List("a","b","c"),3).repartition(2).mapPartitionsWithIndex((index,values)=>for(i<-values) yield (index,i) ).collect
res53: Array[(Int, String)] = Array((0,a), (0,c), (1,b))
2.动作算子
collect
用在测试环境下,通常使用collect算子将远程计算的结果拿到Drvier端,注意一般数据量比较小,用于测试。
scala> var rdd1=sc.parallelize(List(1,2,3,4,5),3).collect().foreach(println)
saveAsTextFile
将计算结果存储在文件系统中,一般存储在HDFS上
scala> sc.parallelize(List("ni hao","hello spark"),3).flatMap(_.split("\\s+")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false,3).saveAsTextFile("hdfs:///wordcounts")
foreach
迭代遍历所有的RDD中的元素,通常是将foreach传递的数据写到外围系统中,比如说可以将数据写入到Hbase中。
scala> sc.parallelize(List(“ni hao”,“hello spark”),3).flatMap(.split("\s+")).map((,1)).reduceByKey(+).sortBy(_._2,false,3).foreach(println)
(hao,1)
(hello,1)
(spark,1)
(ni,1)
注意如果使用以上代码写数据到外围系统,会因为不断创建和关闭连接影响写入效率,一般推荐使用foreachPartition
val lineRDD: RDD[String] = sc.textFile("file:///E:/demo/words/t_word.txt")
lineRDD.flatMap(line=>line.split(" "))
.map(word=>(word,1))
.groupByKey()
.map(tuple=>(tuple._1,tuple._2.sum))
.sortBy(tuple=>tuple._2,false,3)
.foreachPartition(items=>{
//创建连接
items.foreach(t=>println("存储到数据库"+t))
//关闭连接
})
(七)共享变量
1.变量广播
通常情况下,当一个RDD的很多操作都需要使用driver中定义的变量时,每次操作,driver都要把变量发送给worker节点一次,如果这个变量中的数据很大的话,会产生很高的传输负载,导致执行效率降低。使用广播变量可以使程序高效地将一个很大的只读数据发送给多个worker节点,而且对每个worker节点只需要传输一次,每次操作时executor可以直接获取本地保存的数据副本,不需要多次传输。
val conf = new SparkConf().setAppName("demo").setMaster("local[2]")
val sc = new SparkContext(conf)
val userList = List(
"001,张三,28,0",
"002,李四,18,1",
"003,王五,38,0",
"004,zhaoliu,38,-1"
)
val genderMap = Map("0" -> "女", "1" -> "男")
val bcMap = sc.broadcast(genderMap)
sc.parallelize(userList,3)
.map(info=>{
val prefix = info.substring(0, info.lastIndexOf(","))
val gender = info.substring(info.lastIndexOf(",") + 1)
val genderMapValue = bcMap.value
val newGender = genderMapValue.getOrElse(gender, "未知")
prefix + "," + newGender
}).collect().foreach(println)
sc.stop()
2.累加器
Spark提供的Accumulator,主要用于多个节点对一个变量进行共享性的操作。Accumulator只提供了累加的功能。但是确给我们提供了多个task对一个变量并行操作的功能。但是task只能对Accumulator进行累加操作,不能读取它的值。只有Driver程序可以读取Accumulator的值。
scala> var count=sc.longAccumulator("count")
scala> sc.parallelize(List(1,2,3,4,5,6),3).foreach(item=> count.add(item))
scala> count.value
res1: Long = 21
六、Spark Stream
(一)框架介绍
Spark Streaming是核心Spark API的扩展,可实现实时数据流的可扩展,高吞吐量,容错流处理。数据可以从许多来源(如Kafka,Flume,Kinesis或TCP套接字)中获取,并且可以使用以高级函数(如map,reduce,join和window)表示的复杂算法进行处理。最后,处理后的数据可以推送到文件系统,数据库和实时dashboards(仪表盘)。

在内部,它的工作原理如下。 Spark Streaming接收实时输入数据流并将数据分成批处理,然后由Spark引擎处理以批量生成最终结果流。
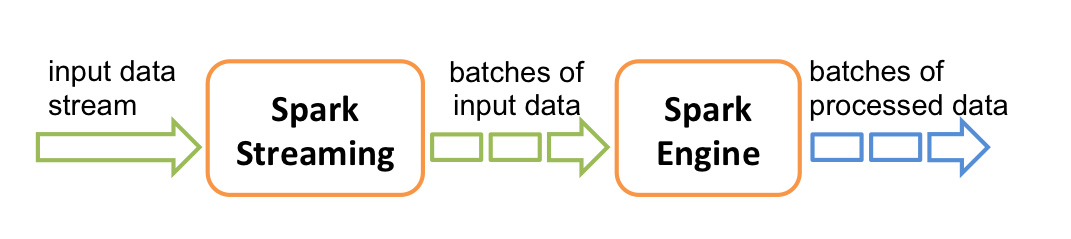
Spark Streaming提供称为离散流或DStream的高级抽象,表示连续的数据流。DStream可以从来自Kafka,Flume和Kinesis等源的输入数据流创建,也可以通过在其他DStream上应用高级操作来创建。在内部DStream表示为一系列RDD。
备注:Spark Streaming 因为底层使用批处理模拟流处理,因此在实时性上大打折扣,这就导致了Spark Streaming在流处理领域有者着先天的劣势。虽然Spark Streaming 在实时性上不如一些专业的流处理引擎(Storm/Flink)但是Spark Stream在使用吸取RDD设计经验,提供了比较友好的API算子,使得使用RDD做批处理的程序员可以平滑的过渡到流处理。
针对于Spark Streaming的微观的批处理问题,目前大数据处理领域又诞生了新秀
Flink,该大数据处理引擎,在API易用性上和实时性上都有一定的兼顾,但是与spark最大的差异是Flink底层的处理引擎是流处理引擎,因此Flink天生就是流处理,但是Spark因为底层是批处理,导致了Spark Streaming在实时性上就没法和其他的专业流处理框架对比了。
(二)入门案例
- pom.xml
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.4.3</version>
</dependency>
- SparkStreamWordCounts
//本地测试
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(5))//Seconds(5)底层微批的时间间隔5s
ssc.sparkContext.setLogLevel("FATAL")//关闭日志打印
ssc.socketTextStream("CentOS",9999)//从外部netCat获得流数据
.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.print()
ssc.start()
ssc.awaitTermination()//等待系统发送指令关闭流计算
注意1:
[root@CentOS ~]# yum install -y nc启动nc服务
[root@CentOS ~]# nc -lk 9999,
注意2:
在调用该程序的时候,需要设置local[n],n>1。
(三)概念介绍
通过上述案例的运行,现在我们来一起探讨一些流处理的概念。在处理流计算的时候,除去spark-core依赖以外我们还需要引入spark-streaming模块。要从Spark Streaming核心API中不存在的Kafka,Flume和Kinesis等源中提取数据,您必须将相应的工件spark-streaming-xyz_2.11添加到依赖项中。例如Kafka
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.4.3</version>
</dependency>
1.初始化 StreamingContext
要初始化Spark Streaming程序,必须创建一个StreamingContext对象,它是所有Spark Streaming功能的主要入口点。
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1))
AppName参数是应用程序在集群UI上显示的名称。
Master在Standalone环境下为“spark://CentOS:7077”,在Spark On Yarn环境下为“yarn”,在本地环境下为“local[n]” 。
请注意ssc会在内部创建一个SparkContext(所有Spark功能的起点),如果需要获取SparkContext对象用户可以调用ssc.sparkContext访问。例如用户使用SparkContext关闭日志。
val conf = new SparkConf()
.setMaster("local[5]")
.setAppName("wordCount")
val ssc = new StreamingContext(conf,Seconds(1))
//关闭其他日志
ssc.sparkContext.setLogLevel("FATAL")
必须根据应用程序的延迟要求和可用的群集资源设置批处理间隔。要使群集上运行的Spark Streaming应用程序保持稳定,系统应该能够以接收数据的速度处理数据。换句话说,批处理数据应该在生成时尽快处理。通过监视流式Web UI中的处理时间可以找到是否适用于应用程序,其中批处理时间应小于批处理间隔。
val conf = new SparkConf()
.setMaster("local[5]")
.setAppName("wordCount")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc,Seconds(1))
当用户创建完StreamingContext对象之后,用户需要完成以下步骤
- 定义数据源,用于创建输入的 DStreams.
- 定义流计算算子,通过定义这些算子实现对DStream数据转换和输出
- 调用streamingContext.start()启动数据.
- 等待计算结束 (人工结束或者是错误) 调用 streamingContext.awaitTermination().
- 如果是人工结束,程序应当调用 streamingContext.stop()结束流计算.
重要因素需要谨记
- 一旦流计算启动,无法再往计算流程中添加计算算子
- 一旦SparkContext对象被stop后,无法重启。
- 一个JVM系统中只能实例化一个StreamingContext对象。
- StreamingContext被stop()后,内部创建的SparkContext也会被stop.如果仅仅是想Stop StreamingContext, 可以设置stop() 中的可选参数 stopSparkContext=false即可.
ssc.stop(stopSparkContext = false)
- 一个SparkContext 可以重复使用并且创建多个StreamingContexts, 前提是上一个启动的StreamingContext 被停止了(但是并没有关闭 SparkContext对象) 。
2.Discretized Streams (DStreams)
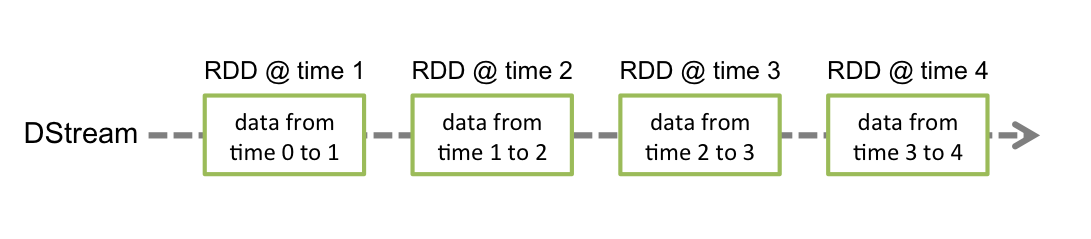
Discretized Stream(离散流)或DStream是Spark Streaming提供的基本抽象。它表示连续的数据流,可以是从源接收的输入数据流,也可以是通过转换输入流生成的已处理数据流。在内部,DStream由一系列连续的RDD表示,这是Spark对不可变分布式数据集的抽象。DStream中的每个RDD都包含来自特定时间间隔的数据,如下图所示。
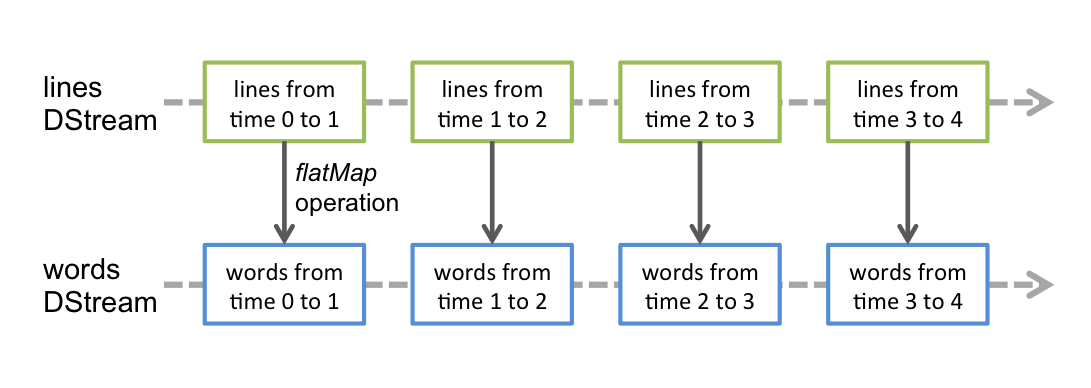
应用于DStream的任何操作都转换为底层RDD上的操作。例如,在先前Quick Start示例中,flatMap操作应用于行DStream中的每个RDD以生成单词DStream的RDD。如下图所示。
这些底层RDD转换由Spark引擎计算。 DStream操作隐藏了大部分细节,并为开发人员提供了更高级别的API以方便使用。
3.InputStream & Receivers
Input DStream 表示流计算的输入,Spark中默认提供了两类的InputStream:
- Baisc Source :例如 filesystem、scoket(网络)
- Advance Source:例如:Kafka、Flume等外围系统的数据。
除filesystem以外,其他的Input DStream默认都会占用一个Core(计算资源),在测试或者生产环境下,分配给计算应用的Core数目必须大于Receivers个数。(本质上除filesystem源以外,其他的输入都是Receiver抽象类的实现。)例如socketTextStream底层封装了SocketReceiver
(1)Basic Sources
因为在快速入门案例中已经使用了socketTextStream,接下来只测试一下filesystem对于从与HDFS API兼容的任何文件系统(即HDFS,S3,NFS等)上的文件读取数据,可以通过StreamingContext.fileStream [KeyClass,ValueClass,InputFormatClass]创建DStream。文件流不需要运行Receiver,因此不需要为接收文件数据分配任何core。对于简单的文本文件,最简单的方法是StreamingContext.textFileStream(dataDirectory)
val conf = new SparkConf().setMaster("local[2]").setAppName("FileSystemWordCount")
val ssc = new StreamingContext(conf, Seconds(5))
ssc.sparkContext.setLogLevel("FATAL")//关闭日志打印
val lines = ssc.textFileStream("hdfs://CentOS:9000/demo/words")
lines.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.print()
ssc.start()
ssc.awaitTermination()
在HDFS上创建目录,与("hdfs://CentOS:9000/demo/words")对应
[root@CentOS ~]# hdfs dfs -mkdir -p /demo/words
启动程序,再将需要处理的文本文件放入hdfs目录/demo/words中
[root@CentOS ~]# hdfs dfs -put install.log /demo/words
注意 在使用采集hdfs系统数据的时候,必须先将需要采集的文件上传到非监测目录,等文件上传结束后将数据移动到采样目录,否则spark采集不到数据,原因如下:
“完整”文件系统(如HDFS)会在创建输出流后立即在其文件上设置修改时间。打开文件时,即使在数据完全写入之前,它也可能包含在DStream中 ,之后将忽略同一窗口中文件的更新。即:可能会遗漏更改,并从流中省略数据。
(2)Queue of RDDs as a Stream(用于测试)
为了使用测试数据测试Spark Streaming应用程序,还可以使用streamingContext.queueStream(queueOfRDDs)基于RDD队列创建DStream。推入队列的每个RDD将被视为DStream中的一批数据,并像流一样处理。
val conf = new SparkConf().setMaster("local[2]").setAppName("FileSystemWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
ssc.sparkContext.setLogLevel("FATAL")//关闭日志打印
val queue=new mutable.Queue[RDD[String]]();//队列的泛型是RDD[String]
val lines = ssc.queueStream(queue)
lines.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.print()
ssc.start()
for(i <- 1 to 30){
queue += ssc.sparkContext.makeRDD(List("this is a demo","hello how are you"))
Thread.sleep(1000)
}
ssc.stop()
(3)Advance Source Kafka
- pom.xml
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.4.3</version>
</dependency>
- Kafka对接Spark Streaming
val conf = new SparkConf().setMaster("local[2]").setAppName("FileSystemWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
ssc.sparkContext.setLogLevel("FATAL")//关闭日志打印
设置kafka的连接参数
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "CentOS:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "group1",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
KafkaUtils.createDirectStream(
ssc,
LocationStrategies.PreferConsistent,//设置加载数据位置策略,
Subscribe[String,String](Array("topic01"),kafkaParams)
)
.map(record => record.value())
.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.print()
ssc.start()
ssc.awaitTermination()
//注:Subscribe导包注意import org.apache.spark.streaming.kafka010.ConsumerStrategies._
(四)Spark Stream算子
| Transformation | Meaning |
|---|---|
| map(func) | 通过将源DStream的每个元素传递给函数func来返回一个新的DStream。 |
| flatMap(func) | 与map类似,但每个输入项可以映射到0个或更多输出项。 |
| filter(func) | 通过仅选择func返回true的源DStream的记录来返回新的DStream。 |
| repartition(numPartitions) | 通过创建更多或更少的分区来更改此DStream中的并行度级别。 |
| union(otherStream) | 返回一个新的DStream,它包含源DStream和otherDStream中元素的并集。(要求RDD类型一致) |
| count() | 通过计算源DStream的每个RDD中的元素数量,返回单元素RDD的新DStream。 |
| reduce(func) | 通过使用函数func(它接受两个参数并返回一个)聚合源DStream的每个RDD中的元素,返回单元素RDD的新DStream。该函数应该是关联的和可交换的,以便可以并行计算。 |
| countByValue() | 当在类型为K的元素的DStream上调用时,返回(K,Long)对的新DStream,其中每个键的值是其在源DStream的每个RDD中的频率。 |
| reduceByKey(func, [numTasks]) | 当在(K,V)对的DStream上调用时,返回(K,V)对的新DStream,其中使用给定的reduce函数聚合每个键的值。注意:默认情况下,这使用Spark的默认并行任务数(本地模式为2,在群集模式下,数量由配置属性spark.default.parallelism确定)进行分组。您可以传递可选的numTasks参数来设置不同数量的任务。 |
| join(otherStream, [numTasks]) | 当在(K,V)和(K,W)对的两个DStream上调用时,返回(K,(V,W))对的新DStream与每个键的所有元素对。 |
| cogroup(otherStream, [numTasks]) | 当在(K,V)和(K,W)对的DStream上调用时,返回(K,Seq [V],Seq [W])元组的新DStream。 |
| transform(func) | 通过将RDD-to-RDD函数应用于源DStream的每个RDD来返回新的DStream。这可以用于在DStream上执行任意RDD操作。 |
| updateStateByKey(func) | 返回一个新的“状态”DStream,其中通过在键的先前状态和键的新值上应用给定函数来更新每个键的状态。这可用于维护每个密钥的任意状态数据。 |
| mapWithState | 因为UpdateStateByKey 算子每一次的输出都是全量输出,在做状态更新的时候代价较高,因此推荐大家使用mapWithState |
| window(windowLength, slideInterval) | 返回一个新的DStream,它是根据源DStream的窗口批次计算的。 |
| countByWindow(windowLength, slideInterval) | 返回流中元素的滑动窗口数。 |
| reduceByWindow(func, windowLength, slideInterval) | 返回一个新的单元素流,通过使用func在滑动间隔内聚合流中的元素而创建。该函数应该是关联的和可交换的,以便可以并行正确计算。 |
| reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | 当在(K,V)对的DStream上调用时,返回(K,V)对的新DStream,其中使用给定的reduce函数func在滑动窗口中的批次聚合每个键的值。注意:默认情况下,这使用Spark的默认并行任务数(本地模式为2,在群集模式下,数量由配置属性spark.default.parallelism确定)进行分组。您可以传递可选的numTasks参数来设置不同数量的任务。 |
| reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) | 上述reduceByKeyAndWindow()的更高效版本,其中每个窗口的reduce值使用前一个窗口的reduce值逐步计算。这是通过减少进入滑动窗口的新数据和“反向减少”离开窗口的旧数据来完成的。一个例子是当窗口滑动时“添加”和“减去”键的计数。但是,它仅适用于“可逆减少函数”,即那些具有相应“反向减少”函数的减函数(作为参数invFunc)。与reduceByKeyAndWindow类似,reduce任务的数量可通过可选参数进行配置。请注意,必须启用检查点才能使用此操作。 |
| countByValueAndWindow(windowLength,slideInterval, [numTasks]) | 当在(K,V)对的DStream上调用时,返回(K,Long)对的新DStream,其中每个键的值是其在滑动窗口内的频率。与reduceByKeyAndWindow类似,reduce任务的数量可通过可选参数进行配置。 |
1.转换算子
该算子可以将DStream的数据转变成RDD,用户操作流数据就像操作RDD感觉是一样的。
应用场景:将静态RDD与动态生成的RDD合并到一起输出。如下例:将数据库中存储的用户信息(静态)RDD与动态生成的订单信息RDD合并输出。
object SparkKafkaWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("SparkKafkaWordCount")
val ssc = new StreamingContext(conf,Seconds(1))
ssc.sparkContext.setLogLevel("FATAL")
//添加Kafka连接信息
val kafkaParams=Map[String,Object](
"bootstrap.servers"->"CentOSX:9092",
"key.deserializer"->classOf[StringDeserializer],
"value.deserializer"->classOf[StringDeserializer],
"group.id"->"group1",
"enable.auto.commit"->(false:java.lang.Boolean)
)
//模拟从数据库中读取的静态RDD
val cacheRDD= ssc.sparkContext.makeRDD(List("001 zhangsan", "002 lisi", "003 wangwu"))
//使用map将文本数据进行切分,得到RDD[(String,String)]形式
.map(item => (item.split("\\s+")(0), item.split("\\s+")(1)))
.distinct()//去除重复
.cache()//添加缓存,节省重复读取占用资源
KafkaUtils.createDirectStream(
ssc,
LocationStrategies.PreferConsistent,
Subscribe[String,String](Array("topic01"),kafkaParams))
.map(_.value())//根据topic01中的record,获得record.value
//对于来自kafka中的record.value进行切分
.map(value=>{
val tokens = value.split("\\s+")
(tokens(0),tokens(1))})
//将静态RDD与动态RDD进行join输出-右连接
.transform(rdd=>rdd.rightOuterJoin(cacheRDD))
//因为静态RDD始终存在,因此在使用右连接后程序始终打印输出,此时需要加上过滤滤掉如(001,(null,zhangsan))的结果
.filter(_._2._1!=None)
.print()
ssc.start()
ssc.awaitTermination()
}
}
在Kafka的topic01中生产数据,如“001 apple”,在控制台中输出(001,(Some(apple),zhangsan))
2.状态算子
object SparkKafkaWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("SparkKafkaWordCount")
val ssc = new StreamingContext(conf,Seconds(1))
ssc.sparkContext.setLogLevel("FATAL")
//将状态信息存储在hdfs的/checkpoints目录下(自动创建)
ssc.checkpoint("hdfs://CentOSX:9000/checkpoints")
//定义函数updateFun,作为updateStateBykey状态算子的参数
def updateFun(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
//newValues.sum获得增量值的和,runningCount.getOrElse(0)获得历史数据,不存在则为0
var total= newValues.sum+runningCount.getOrElse(0)
Some(total)
}
ssc.socketTextStream("CentOSX",9999)
.flatMap(_.split("\\s+"))
.map((_,1))
.updateStateByKey(updateFun)
.print()
ssc.start()
ssc.awaitTermination()
}
}
注://本例中是本地测试,直接启动会报错,原因是本地测试没有hdfs的写权限,因此需要在启动前在JVM启动参数中添加-DHADOOP_USER_NAME=root,如下图
因为UpdateStateByKey 算子每一次的输出都是
全量输出,在做状态更新的时候代价较高,因此推荐大家使用mapWithState
object SparkKafkaWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("SparkKafkaWordCount")
val ssc = new StreamingContext(conf,Seconds(5))
ssc.sparkContext.setLogLevel("FATAL")
//将状态信息存储在hdfs的/checkpoints目录下(自动创建)
ssc.checkpoint("hdfs://CentOSX:9000/checkpoints")
ssc.socketTextStream("CentOSX",9999)
.flatMap(_.split("\\s+"))
.map((_,1))
.mapWithState(StateSpec.function((k:String,v:Option[Int],state:State[Int])=>{
var total=0
//判断存储状态的state是否存在
if(state.exists()){
//如果存在,获得state存储的值赋值给total
total=state.getOption().getOrElse(0)
}
//得到历史值之后的total加上增量值
total+=v.getOrElse(1)//v.getOrElse不存在则增量为1
//根据total修改state
state.update(total)
//输出(k,出现次数)
(k,total)
}))
//设置状态持久化的频率,改频率不能高于 微批 拆分频率 ts>=5s
.checkpoint(Seconds(5))
.print()
ssc.start()
ssc.awaitTermination()
}
}
- 从故障中|重启中恢复状态
object SparkKafkaWordCount {
def main(args: Array[String]): Unit = {
//将状态信息存储在hdfs的/checkpoints目录下(自动创建)
var checkpointPath="hdfs://CentOSX:9000/checkpoint"
//第一次启时候初始化,一旦书写完成后,无法进行修改!
var sscg=StreamingContext.getOrCreate(checkpointPath,()=>{
val conf = new SparkConf().setMaster("local[2]").setAppName("SparkKafkaWordCount")
val ssc=new StreamingContext(conf,Seconds(5))
ssc.checkpoint(checkpointPath)
def updateFun(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
var total= newValues.sum+runningCount.getOrElse(0)
Some(total)
}
ssc.socketTextStream("CentOSX",9999)
.flatMap(_.split("\\s+"))
.map((_,1))
.mapWithState(StateSpec.function((k:String,v:Option[Int],state:State[Int])=>{
var total=0
//判断存储状态的state是否存在
if(state.exists()){
//如果存在,获得state存储的值赋值给total
total=state.getOption().getOrElse(0)
}
//得到历史值之后的total加上增量值
total+=v.getOrElse(1)//v.getOrElse不存在则增量为1
//根据total修改state
state.update(total)
//输出(k,出现次数)
(k,total)
}))
//设置状态持久化的频率,改频率不能高于 微批 拆分频率 ts>=5s
.checkpoint(Seconds(5))
.print()
ssc
})
sscg.sparkContext.setLogLevel("FATAL")//关闭日志打印
sscg.start()
sscg.awaitTermination()
}
}
3.窗口算子
- window
Spark Streaming还提供窗口计算,允许您在滑动数据窗口上应用转换。下图说明了此滑动窗口。
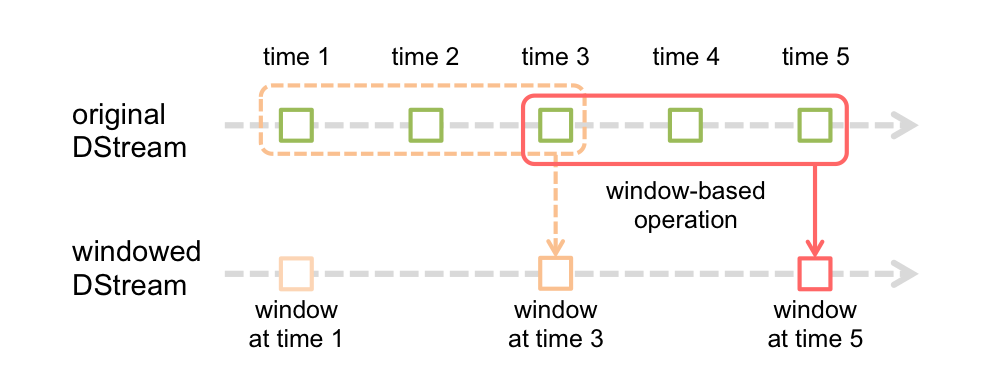
以上描述了窗口长度是3个时间单位的微批,窗口的滑动间隔是2个时间单位的微批,注意:Spark的流处理中要求窗口的长度以及滑动间隔必须是微批的整数倍。
val conf = new SparkConf().setMaster("local[2]").setAppName("KafkaStreamWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
ssc.socketTextStream("CentOS",9999)
.flatMap(_.split("\\s+"))
.map((_,1))
.reduceByKeyAndWindow((v1:Int,v2:Int)=> v1+v2,Seconds(5),Seconds(5))
.print()
ssc.sparkContext.setLogLevel("FATAL")//关闭日志打印
ssc.start()
ssc.awaitTermination()
4.输出算子(Output Operations)
- foreachRDD(func)
val conf = new SparkConf().setMaster("local[2]").setAppName("KafkaStreamWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
ssc.socketTextStream("CentOS",9999)
.flatMap(_.split("\\s+"))
.map((_,1))
.window(Seconds(5),Seconds(5))
.reduceByKey((v1:Int,v2:Int)=> v1+v2)
//foreachRDD是spark stream算子
.foreachRDD(rdd=>{
//foreachPartition是spark RDD算子
rdd.foreachPartition(items=>{
var jedisPool=new JedisPool("CentOS",6379)
val jedis = jedisPool.getResource
val pipeline = jedis.pipelined()//jedis批处理
//将RDD-item使用map算子转换成(Int,String)形式,封装成scala的Map集合,再转换成java的Map集合
val map = items.map(t=>(t._1,t._2+"")).toMap.asJava
pipeline.hmset("wordcount",map)
pipeline.sync()//对Jedis批处理加锁
jedis.close()//将Jedis连接放回连接池
})
})
ssc.sparkContext.setLogLevel("FATAL")//关闭日志打印
ssc.start()
ssc.awaitTermination()
六、Spark SQL(Structure Query Language)
(一)Spark SQL介绍
Spark SQL是用于结构化数据处理的一个模块。同Spark RDD 不同地方在于Spark SQL的API可以给Spark计算引擎提供更多地信息,例如:数据结构、计算算子等。在内部Spark可以通过这些信息有针对对任务做优化和调整。这里有几种方式和Spark SQL进行交互,例如Dataset API和SQL等,这两种API可以混合使用。Spark SQL的一个用途是执行SQL查询。 Spark SQL还可用于从现有Hive安装中读取数据。从其他编程语言中运行SQL时,结果将作为Dataset/DataFrame返回,使用命令行或JDBC / ODBC与SQL接口进行交互。
Dataset是一个分布式数据集合在Spark 1.6提供一个新的接口,Dataset提供RDD的优势(强类型,使用强大的lambda函数)以及具备了Spark SQL执行引擎的优点。Dataset可以通过JVM对象构建,然后可以使用转换函数等(例如:map、flatMap、filter等),目前Dataset API支持Scala和Java 目前Python对Dataset支持还不算完备。
Data Frame是命名列的数据集,他在概念是等价于关系型数据库。DataFrames可以从很多地方构建,比如说结构化数据文件、hive中的表或者外部数据库,使用Dataset[row]的数据集,可以理解DataFrame就是一个Dataset[Row].
- 依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.3</version>
</dependency>
- SparkSession
Spark中所有功能的入口点是SparkSession类。要创建基本的SparkSession,只需使用SparkSession.builder():
val spark = SparkSession.builder()//此处定义变量需声明为常量val
.appName("hellosql")
.master("local[10]")
.getOrCreate()
//一般都需要引入隐试转换,主要是将RDD转换为DataFrame/Dataset
import spark.implicits._//此处引入隐式转换需用上步定义的常量spark调用
//此处书写相关功能代码
//关闭Spark日志
spark.sparkContext.setLogLevel("FATAL")
spark.stop()
(二)API形式-Dataset
Dataset与RDD类似,但是,它们不使用Java序列化或Kryo,而是使用专用的Encoder来序列化对象以便通过网络进行处理或传输。虽然Encoder和标准序列化都负责将对象转换为字节,但Encoder是动态生成的代码,并使用一种格式,允许Spark执行许多操作,如过滤,排序和散列,而无需将字节反序列化为对象。
1.Dataset处理case class类的集合
case class Person(id:Int,name:String,age:Int,sex:Boolean)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("hellosql")
.master("local[10]")
.getOrCreate()
import spark.implicits._
val dataset: Dataset[Person] = List(Person(1,"zhangsan",18,true),Person(2,"wangwu",28,true)).toDS()
dataset.select($"id",$"name").show()//列名引用
//关闭Spark日志
spark.sparkContext.setLogLevel("FATAL")
spark.stop()
}
2.Dataset处理元组形成的集合
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("hellosql")
.master("local[10]")
.getOrCreate()
import spark.implicits._
val dataset: Dataset[(Int,String,Int,Boolean)] = List((1,"zhangsan",18,true),(2,"wangwu",28,true)).toDS()
dataset.select($"_1",$"_2").show()//元组没有具体类做支撑,因此引入列指定以tuple._下标的形式
//关闭Spark日志
spark.sparkContext.setLogLevel("FATAL")
spark.stop()
}
3.Dataset处理json文件数据
准备json文件,路径D:/Person.json
{"name":"张三","age":18}
{"name":"lisi","age":28}
{"name":"wangwu","age":38}
书写代码
case class Person(name: String, age: Long)//此处age类型必须用Long
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[5]")
.appName("spark session")
.getOrCreate()
spark.sparkContext.setLogLevel("FATAL")
import spark.implicits._
val dataset = spark.read.json("D:///Person.json").as[Person]
dataset.show()
spark.stop()
}
(三)API形式-Data Frame
Data Frame是命名列的数据集,他在概念是等价于关系型数据库。DataFrames可以从很多地方构建,比如说结构化数据文件、hive中的表或者外部数据库,使用Dataset[row]的数据集,可以理解DataFrame就是一个Dataset[Row].
1.处理数据的类型
(1)Data Frame处理case class类的集合
case class Person(name:String,age:Long)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("hellosql")
.master("local[10]")
.getOrCreate()
import spark.implicits._
//与Dataset的不同之处为toDF(Dataset为toDS)
List(Person("zhangsan",18),Person("王五",20)).toDF("uname","uage").show()
//关闭Spark日志
spark.sparkContext.setLogLevel("FATAL")
spark.stop()
}
(2)Data Frame处理元组形成的集合
case class Person(name:String,age:Long)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("hellosql")
.master("local[10]")
.getOrCreate()
import spark.implicits._
//与Dataset的不同之处为toDF(Dataset为toDS),Data Frame可以指定列名
List(("zhangsan",18),("王五",20)).toDF("name","age").show()
//关闭Spark日志
spark.sparkContext.setLogLevel("FATAL")
spark.stop()
}
(3)Dataset处理json文件数据
val spark = SparkSession.builder()
.appName("hellosql")
.master("local[10]")
.getOrCreate()
import spark.implicits._
//与Dataset不同的是不用加.as[Person]
val frame = spark.read.json("file:///f:/person.json")
frame.show()
//关闭Spark日志
spark.sparkContext.setLogLevel("FATAL")
spark.stop()
2.RDD向Data Frame转换(灵活)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("hellosql")
.master("local[10]")
.getOrCreate()
val lines = spark.sparkContext.parallelize(List("zhangsan,20", "lisi,30"))
//先将字符串进行切分,得到Rdd[Row(zhangsan,20)]
.map(line => Row(line.split(",")(0), line.split(",")(1).toInt))
//定义要转换成的frame的结构类型(结构属性(名称,类型,是否可以为空))
val structType = new StructType(Array(StructField("name",StringType,true),StructField("age",IntegerType,true)))
//创建DataFrame(RDD[Row]数据,结构类型)
val frame = spark.createDataFrame(lines,structType)
frame.show()
//关闭Spark日志
spark.sparkContext.setLogLevel("FATAL")
spark.stop()
}
算子操作
准备如下格式数据
Michael,29,2000,true
Andy,30,5000,true
Justin,19,1000,true
Kaine,20,5000,true
Lisa,19,1000,false
(1)select
任务代码
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("hellosql")
.master("local[10]")
.getOrCreate()
import spark.implicits._//必须引入隐式转换,否则相关附加功能优化不能实现
var rdd=spark.sparkContext.textFile("file:///D:/WorkSpace02/people.txt")
//先将字符串进行切分,得到Rdd[Row(Michael,29,2000,true)]
.map(_.split(","))
.map(arr=>Row(arr(0),arr(1).trim().toInt,arr(2).trim().toDouble,arr(3).trim().toBoolean))
//定义要转换成frame的结构类型的结构属性(名称,类型,是否可以为空))
var fields=new StructField("name",StringType,true)::
new StructField("age",IntegerType,true)::
new StructField("salary",DoubleType,true)::
//::表示追加,给内容为Nil(Null)的集合向前追加,相当于Array(StructField("name",StringType,true),StructField("age",IntegerType,true)...)
new StructField("sex",BooleanType,true)::Nil
//创建DataFrame(RDD[Row]数据,结构类型)
val frame = spark.createDataFrame(rdd, StructType(fields)).as("t_user")
//执行select算子($"名称"引入结构属性名称)
frame.select($"name",$"age",$"salary",$"sex",$"salary"*12 as "年薪")
.show()
//关闭Spark日志
spark.sparkContext.setLogLevel("FATAL")
spark.stop()
}
输出结果
+-------+---+------+-----+-------+
| name|age|salary| sex| 年薪|
+-------+---+------+-----+-------+
|Michael| 29|2000.0| true|24000.0|
| Andy| 30|5000.0| true|60000.0|
| Justin| 19|1000.0| true|12000.0|
| Kaine| 20|5000.0| true|60000.0|
| Lisa| 19|1000.0|false|12000.0|
+-------+---+------+-----+-------+
(2) filter
任务代码(部分)
var rdd= spark.sparkContext.textFile("file:///D:/people.txt")
.map(_.split(","))
.map(arr=>Row(arr(0),arr(1).trim().toInt,arr(2).trim().toDouble,arr(3).trim().toBoolean))
var fields=new StructField("name",StringType,true)::new StructField("age",IntegerType,true)::new StructField("salary",DoubleType,true):: new StructField("sex",BooleanType,true)::Nil
spark.createDataFrame(rdd,StructType(fields))
.select($"name",$"age",$"sex",$"salary",$"salary" * 12 as "年薪")
//执行filter算子,相当于sql中的where
.filter($"name" === "Michael" or $"年薪" < 60000)
.show()
输出结果
+-------+---+------+-----+-------+
| name|age|salary| sex| 年薪|
+-------+---+------+-----+-------+
|Michael| 29|2000.0| true|24000.0|
| Justin| 19|1000.0| true|12000.0|
| Lisa| 19|1000.0|false|12000.0|
+-------+---+------+-----+-------+
(3)where
任务代码(部分)
//Michael,29,2000,true
var rdd= spark.sparkContext.textFile("file:///D:/people.txt")
.map(_.split(","))
.map(arr=>Row(arr(0),arr(1).trim().toInt,arr(2).trim().toDouble,arr(3).trim().toBoolean))
var fields=new StructField("name",StringType,true)::new StructField("age",IntegerType,true)::new StructField("salary",DoubleType,true):: new StructField("sex",BooleanType,true)::Nil
//创建DataFrame(RDD[Row]数据,结构类型)
val frame = spark.createDataFrame(rdd, StructType(fields)).as("t_user")
//执行select算子($"名称"引入结构属性名称)
//方式一:
//frame.select($"name",$"age",$"salary",$"sex",$"salary"*12 as "year_salary")//不能使用中文
// .where("(name = 'Michael') or ( year_salary <= 24000) ")
//方式二:
frame.select($"name",$"age",$"sex",$"salary",$"salary" * 12 as "年薪")
.where($"name" === "Michael" or $"年薪" <= 24000)
.show()
输出结果
+-------+---+-----+------+-------+
| name|age| sex|salary| 年薪|
+-------+---+-----+------+-------+
|Michael| 29| true|2000.0|24000.0|
| Justin| 19| true|1000.0|12000.0|
| Lisa| 19|false|1000.0|12000.0|
+-------+---+-----+------+-------+
(4)withColumn
任务代码(部分)
var rdd= spark.sparkContext.textFile("file:///D:/people.txt")
.map(_.split(","))
.map(arr=>Row(arr(0),arr(1).trim().toInt,arr(2).trim().toDouble,arr(3).trim().toBoolean))
var fields=new StructField("name",StringType,true)::new StructField("age",IntegerType,true)::new StructField("salary",DoubleType,true):: new StructField("sex",BooleanType,true)::Nil
spark.createDataFrame(rdd,StructType(fields))
.select($"name",$"age",$"sex",$"salary",$"salary" * 12 as "年薪")
.where($"name" === "Michael" or $"年薪" <= 24000)
//执行withColumn算子,(新增列列名,列数据来源&计算)
.withColumn("年终奖",$"年薪" * 0.8)
.show()
输出结果
+-------+---+-----+------+-------+-------+
| name|age| sex|salary| 年薪| 年终奖|
+-------+---+-----+------+-------+-------+
|Michael| 29| true|2000.0|24000.0|19200.0|
| Justin| 19| true|1000.0|12000.0| 9600.0|
| Lisa| 19|false|1000.0|12000.0| 9600.0|
+-------+---+-----+------+-------+-------+
(5)groupBy
任务代码(部分)
var rdd= spark.sparkContext.textFile("file:///D:/people.txt")
.map(_.split(","))
.map(arr=>Row(arr(0),arr(1).trim().toInt,arr(2).trim().toDouble,arr(3).trim().toBoolean))
var fields=new StructField("name",StringType,true)::new StructField("age",IntegerType,true)::new StructField("salary",DoubleType,true):: new StructField("sex",BooleanType,true)::Nil
spark.createDataFrame(rdd,StructType(fields))
.select($"age",$"sex")
.groupBy($"sex")
.avg("age")
.show()
输出结果
+-----+--------+
| sex|avg(age)|
+-----+--------+
| true| 24.5|
|false| 19.0|
+-----+--------+
(6)agg
任务代码(部分)
var rdd= spark.sparkContext.textFile("file:///D:/people.txt")
.map(_.split(","))
.map(arr=>Row(arr(0),arr(1).trim().toInt,arr(2).trim().toDouble,arr(3).trim().toBoolean))
var fields=new StructField("name",StringType,true)::new StructField("age",IntegerType,true)::new StructField("salary",DoubleType,true):: new StructField("sex",BooleanType,true)::Nil
import org.apache.spark.sql.functions._
spark.createDataFrame(rdd,StructType(fields))
.select($"age",$"sex",$"salary")
.groupBy($"sex")
//执行agg算子,算子内可以使用sum.avg.max.min.count组函数
.agg(sum($"salary") as "toatalSalary",avg("age") as "avgAge",max($"salary"))
.show()
+-----+------------+------+-----------+
| sex|toatalSalary|avgAge|max(salary)|
+-----+------------+------+-----------+
| true| 13000.0| 24.5| 5000.0|
|false| 1000.0| 19.0| 1000.0|
+-----+------------+------+-----------+
(7)join
准备下数据
dept.txt
1,销售部门
2,研发部门
3,媒体运营
4,后勤部门
people.txt
Michael,29,2000,true,1
Andy,30,5000,true,1
Justin,19,1000,true,2
Kaine,20,5000,true,2
Lisa,19,1000,false,3
任务代码(部分)
//userFrame相关
var userRdd= spark.sparkContext.textFile("file:///D:/people.txt")
.map(_.split(","))
.map(arr=>Row(arr(0),arr(1).trim().toInt,arr(2).trim().toDouble,arr(3).trim().toBoolean,arr(4).trim().toInt))
var userFields=new StructField("name",StringType,true)::new StructField("age",IntegerType,true)::new StructField("salary",DoubleType,true):: new StructField("sex",BooleanType,true)::new StructField("deptno",IntegerType,true)::Nil
val userFrame = spark.createDataFrame(userRdd,StructType(userFields)).as("user")
//deptFrame相关
var deptFrame = spark.sparkContext.textFile("file:///D:/dept.txt")
.map(line =>(line.split(",")(0).toInt,line.split(",")(1)))
.toDF("deptno","deptname").as("dept")
//执行join算子进行表连接
userFrame.select($"name",$"user.deptno")
.join(dept,$"dept.deptno" === $"user.deptno")
.show()
输出结果
+-------+------+------+--------+
| name|deptno|deptno|deptname|
+-------+------+------+--------+
|Michael| 1| 1|销售部门|
| Andy| 1| 1|销售部门|
| Lisa| 3| 3|媒体运营|
| Justin| 2| 2|研发部门|
| Kaine| 2| 2|研发部门|
+-------+------+------+--------+
(8)drop
任务代码(部分)
userDF.select($"deptno",$"salary" )
.groupBy($"deptno")
.agg(sum($"salary") as "总薪资",avg($"salary") as "平均值",max($"salary") as "最大值")
.join(deptDF,$"dept.deptno" === $"user.deptno")
//执行drop算子,使."user.deptno"列不显示
.drop($"dept.deptno")
.show()
输出结果
+------+-------+------------------+-------+--------+
|deptno| 总薪资| 平均值| 最大值|deptname|
+------+-------+------------------+-------+--------+
| 1|43000.0|14333.333333333334|20000.0|销售部门|
| 2|38000.0| 19000.0|20000.0|研发部门|
+------+-------+------------------+-------+--------+
(9)orderBy
任务代码(部分)
userDF.select($"deptno",$"salary" )
.groupBy($"deptno")
.agg(sum($"salary") as "总薪资",avg($"salary") as "平均值",max($"salary") as "最大值")
.join(deptDF,$"dept.deptno" === $"user.deptno")
.drop($"dept.deptno")
.orderBy($"总薪资" asc)
.show()
输出结果
+------+-------+------------------+-------+--------+
|deptno| 总薪资| 平均值| 最大值|deptname|
+------+-------+------------------+-------+--------+
| 2|38000.0| 19000.0|20000.0|研发部门|
| 1|43000.0|14333.333333333334|20000.0|销售部门|
+------+-------+------------------+-------+--------+
(10)map
userDF.map(row => (row.getString(0),row.getInt(1))).show()
+--------+---+
| name|age|
+--------+---+
|zhangsan| 28|
+--------+---+
默认情况下SparkSQL会在执行SQL的时候将序列化里面的参数数值,一般情况下系统提供了常见类型的Encoder,如果出现了没有的Encoder,用户需要声明 隐式转换Encoder
implicit val mapEncoder = org.apache.spark.sql.Encoders.kryo[Map[String, Any]]
userDF.map(row => row.getValuesMap[Any](List("name","age","salary")))
.foreach(map=>{
var name=map.getOrElse("name","")
var age=map.getOrElse("age",0)
var salary=map.getOrElse("salary",0.0)
println(name+" "+age+" "+salary)
})
(11)flatMap
implicit val mapEncoder = org.apache.spark.sql.Encoders.kryo[Map[String, Any]]
userDF.flatMap(row => row.getValuesMap(List("name","age")))
.map(item => item._1 +" -> "+item._2)
.show()
+---------------+
| value|
+---------------+
|name -> Michael|
| age -> 29|
| name -> Andy|
| age -> 30|
| name -> Justin|
| age -> 19|
| name -> Kaine|
| age -> 20|
| name -> Lisa|
| age -> 19|
+---------------+
(12)limit (take(n))
var rdd= spark.sparkContext.textFile("file:///D:/people.txt")
.map(_.split(","))
.map(arr=>Row(arr(0),arr(1).trim().toInt,arr(2).trim().toDouble,arr(3).trim().toBoolean,arr(4).trim().toInt))
var fields=new StructField("name",StringType,true)::new StructField("age",IntegerType,true)::new StructField("salary",DoubleType,true):: new StructField("sex",BooleanType,true)::new StructField("deptno",IntegerType,true)::Nil
val user = spark.createDataFrame(rdd,StructType(fields)).as("user")
var dept = spark.sparkContext.textFile("file:///D:/dept.txt")
.map(line =>(line.split(",")(0).toInt,line.split(",")(1)))
.toDF("deptno","deptname").as("dept")
user.select($"name",$"deptno" as "u_dept")
.join(dept,$"dept.deptno" === $"u_dept")
.drop("u_dept")
.orderBy($"deptno" desc)
//执行limit算子(注意格式-只有一个参数)
.limit(3)
.show()
| name|deptno|deptname|
+------+------+--------+
| Lisa| 3|媒体运营|
|Justin| 2|研发部门|
| Kaine| 2|研发部门|
+------+------+--------+
(四)SQL形式-Data Frame
准备数据,存储在D:/people.txt目录
Michael,29,20000,true,MANAGER,1
Andy,30,15000,true,SALESMAN,1
Justin,19,8000,true,CLERK,1
Kaine,20,20000,true,MANAGER,2
Lisa,19,18000,false,SALESMAN,2
D:/dept.txt
1,销售部门
2,研发部门
3,媒体运营
4,后勤部门
1.sql查询
val rdd = spark.sparkContext.textFile("file:///D:/people.txt")
.map(line => {
val tokens = line.split(",")
Row(tokens(0), tokens(1).toInt, tokens(2).toDouble, tokens(3).toBoolean, tokens(4), tokens(5).toInt)
})
var fields=new StructField("name",StringType,true)::
new StructField("age",IntegerType,true)::
new StructField("salary",DoubleType,true)::
new StructField("sex",BooleanType,true)::
new StructField("job",StringType,true)::
new StructField("deptno",IntegerType,true)::Nil
val userDF = spark.createDataFrame(rdd,StructType(fields))
//创建一个视图
userDF.createTempView("t_user")
spark.sql("select * from t_user where name like '%M%' or salary between 10000 and 20000").show()
//关闭Spark日志
spark.sparkContext.setLogLevel("FATAL")
spark.stop()
输出结果
+-------+---+-------+-----+--------+------+
| name|age| salary| sex| job|deptno|
+-------+---+-------+-----+--------+------+
|Michael| 29|20000.0| true| MANAGER| 1|
| Andy| 30|15000.0| true|SALESMAN| 1|
| Kaine| 20|20000.0| true| MANAGER| 2|
| Lisa| 19|18000.0|false|SALESMAN| 2|
+-------+---+-------+-----+--------+------+
2.group by
val rdd = spark.sparkContext.textFile("file:///D:/people.txt")
.map(line => {
val tokens = line.split(",")
Row(tokens(0), tokens(1).toInt, tokens(2).toDouble, tokens(3).toBoolean, tokens(4), tokens(5).toInt)
})
var fields=new StructField("name",StringType,true)::
new StructField("age",IntegerType,true)::
new StructField("salary",DoubleType,true)::
new StructField("sex",BooleanType,true)::
new StructField("job",StringType,true)::
new StructField("deptno",IntegerType,true)::Nil
val userDF = spark.createDataFrame(rdd,StructType(fields))
//创建一个视图
userDF.createTempView("t_user")
spark.sql("select deptno,max(salary),avg(salary),sum(salary),count(1) from t_user group by deptno").show()
//关闭Spark日志
spark.sparkContext.setLogLevel("FATAL")
spark.stop()
输出结果
+------+-----------+------------------+-----------+--------+
|deptno|max(salary)| avg(salary)|sum(salary)|count(1)|
+------+-----------+------------------+-----------+--------+
| 1| 20000.0|14333.333333333334| 43000.0| 3|
| 2| 20000.0| 19000.0| 38000.0| 2|
+------+-----------+------------------+-----------+--------+
3.having 过滤
val rdd = spark.sparkContext.textFile("file:///D:/people.txt")
.map(line => {
val tokens = line.split(",")
Row(tokens(0), tokens(1).toInt, tokens(2).toDouble, tokens(3).toBoolean, tokens(4), tokens(5).toInt)
})
var fields=new StructField("name",StringType,true)::
new StructField("age",IntegerType,true)::
new StructField("salary",DoubleType,true)::
new StructField("sex",BooleanType,true)::
new StructField("job",StringType,true)::
new StructField("deptno",IntegerType,true)::Nil
val userDF = spark.createDataFrame(rdd,StructType(fields))
//创建一个视图
userDF.createTempView("t_user")
spark.sql("select deptno,max(salary),avg(salary),sum(salary),count(1) total from t_user group by deptno having total > 2 ")
.show()
//关闭Spark日志
spark.sparkContext.setLogLevel("FATAL")
spark.stop()
输出结果
+------+-----------+------------------+-----------+-----+
|deptno|max(salary)| avg(salary)|sum(salary)|total|
+------+-----------+------------------+-----------+-----+
| 1| 20000.0|14333.333333333334| 43000.0| 3|
+------+-----------+------------------+-----------+-----+
4.表连接 join
val userRdd = spark.sparkContext.textFile("file:///D:/people.txt")
.map(line => {
val tokens = line.split(",")
Row(tokens(0), tokens(1).toInt, tokens(2).toDouble, tokens(3).toBoolean, tokens(4), tokens(5).toInt)
})
val deptRdd = spark.sparkContext.textFile("file:///D:/dept.txt")
.map(line => {
val tokens = line.split(",")
Row(tokens(0).toInt, tokens(1))
})
var userFields=new StructField("name",StringType,true)::
new StructField("age",IntegerType,true)::
new StructField("salary",DoubleType,true)::
new StructField("sex",BooleanType,true)::
new StructField("job",StringType,true)::
new StructField("deptno",IntegerType,true)::Nil
var deptFields=new StructField("deptno",IntegerType,true)::
new StructField("name",StringType,true)::Nil
spark.createDataFrame(userRdd,StructType(userFields)).createTempView("t_user")
spark.createDataFrame(deptRdd,StructType(deptFields)).createTempView("t_dept")
spark.sql("select u.*,d.name from t_user u left join t_dept d on u.deptno=d.deptno")
.show()
//关闭Spark日志
spark.sparkContext.setLogLevel("FATAL")
spark.stop()
输出结果
+-------+---+-------+-----+--------+------+--------+
| name|age| salary| sex| job|deptno|deptname|
+-------+---+-------+-----+--------+------+--------+
|Michael| 29|20000.0| true| MANAGER| 1|销售部门|
| Andy| 30|15000.0| true|SALESMAN| 1|销售部门|
| Justin| 19| 8000.0| true| CLERK| 1|销售部门|
| Kaine| 20|20000.0| true| MANAGER| 2|研发部门|
| Lisa| 19|18000.0|false|SALESMAN| 2|研发部门|
+-------+---+-------+-----+--------+------+--------+
5.limit
val userRdd = spark.sparkContext.textFile("file:///D:/people.txt")
.map(line => {
val tokens = line.split(",")
Row(tokens(0), tokens(1).toInt, tokens(2).toDouble, tokens(3).toBoolean, tokens(4), tokens(5).toInt)
})
val deptRdd = spark.sparkContext.textFile("file:///D:/dept.txt")
.map(line => {
val tokens = line.split(",")
Row(tokens(0).toInt, tokens(1))
})
var userFields=new StructField("name",StringType,true)::
new StructField("age",IntegerType,true)::
new StructField("salary",DoubleType,true)::
new StructField("sex",BooleanType,true)::
new StructField("job",StringType,true)::
new StructField("deptno",IntegerType,true)::Nil
var deptFields=new StructField("deptno",IntegerType,true)::
new StructField("name",StringType,true)::Nil
spark.createDataFrame(userRdd,StructType(userFields)).createTempView("t_user")
spark.createDataFrame(deptRdd,StructType(deptFields)).createTempView("t_dept")
spark.sql("select u.*,d.name from t_user u left join t_dept d on u.deptno=d.deptno order by u.age asc limit 8")
.show()
//关闭Spark日志
spark.sparkContext.setLogLevel("FATAL")
spark.stop()
6.子查询
val userRdd = spark.sparkContext.textFile("file:///D:/people.txt")
.map(line => {
val tokens = line.split(",")
Row(tokens(0), tokens(1).toInt, tokens(2).toDouble, tokens(3).toBoolean, tokens(4), tokens(5).toInt)
})
var userFields=new StructField("name",StringType,true)::
new StructField("age",IntegerType,true)::
new StructField("salary",DoubleType,true)::
new StructField("sex",BooleanType,true)::
new StructField("job",StringType,true)::
new StructField("deptno",IntegerType,true)::Nil
spark.createDataFrame(userRdd,StructType(userFields)).createTempView("t_user")
spark.sql("select * from (select name,age,salary from t_user)")
.show()
//关闭Spark日志
spark.sparkContext.setLogLevel("FATAL")
spark.stop()
输出结果
+-------+---+-------+
| name|age| salary|
+-------+---+-------+
|Michael| 29|20000.0|
| Andy| 30|15000.0|
| Justin| 19| 8000.0|
| Kaine| 20|20000.0|
| Lisa| 19|18000.0|
+-------+---+-------+
7.开窗函数
在正常的统计分析中 ,通常使用聚合函数作为分析,聚合分析函数的特点是将n行记录合并成一行,在数据库的统计当中还有一种统计称为开窗统计,开窗函数可以实现将一行变成多行。可以将数据库查询的每一条记录比作是一幢高楼的一层, 开窗函数就是在每一层开一扇窗, 让每一层能看到整座楼的全貌或一部分。
应用场景:查询每个部门员工信息,并返回本部门的平均薪资
val userRdd = spark.sparkContext.textFile("file:///D:/people.txt")
.map(line => {
val tokens = line.split(",")
Row(tokens(0), tokens(1).toInt, tokens(2).toDouble, tokens(3).toBoolean, tokens(4), tokens(5).toInt)
})
var userFields=new StructField("name",StringType,true)::
new StructField("age",IntegerType,true)::
new StructField("salary",DoubleType,true)::
new StructField("sex",BooleanType,true)::
new StructField("job",StringType,true)::
new StructField("deptno",IntegerType,true)::Nil
spark.createDataFrame(userRdd,StructType(userFields)).createTempView("t_user")
spark.sql("select *, avg(salary) over(partition by deptno) as avgSalary from t_user")
.show()
//关闭Spark日志
spark.sparkContext.setLogLevel("FATAL")
spark.stop()
输出结果
+-------+---+-------+-----+--------+------+------------------+
| name|age| salary| sex| job|deptno| avgSalary|
+-------+---+-------+-----+--------+------+------------------+
|Michael| 29|20000.0| true| MANAGER| 1|14333.333333333334|
| Andy| 30|15000.0| true|SALESMAN| 1|14333.333333333334|
| Justin| 19| 8000.0| true| CLERK| 1|14333.333333333334|
| Kaine| 20|20000.0| true| MANAGER| 2| 19000.0|
| Lisa| 19|18000.0|false|SALESMAN| 2| 19000.0|
+-------+---+-------+-----+--------+------+------------------+
8.ROW_NUMBER()
统计员工在部门内部薪资排名
spark.sql("select * , ROW_NUMBER() over(partition by deptno order by salary DESC) as rank from t_user")
.show()
+-------+---+-------+-----+--------+------+----+
| name|age| salary| sex| job|deptno|rank|
+-------+---+-------+-----+--------+------+----+
|Michael| 29|20000.0| true| MANAGER| 1| 1|
| Andy| 30|15000.0| true|SALESMAN| 1| 2|
| Justin| 19| 8000.0| true| CLERK| 1| 3|
| Kaine| 20|20000.0| true| MANAGER| 2| 1|
| Lisa| 19|18000.0|false|SALESMAN| 2| 2|
+-------+---+-------+-----+--------+------+----+
统计员工在公司所有员工的薪资排名
spark.sql("select * , ROW_NUMBER() over(order by salary DESC) as rank from t_user")
.show()
+-------+---+-------+-----+--------+------+----+
| name|age| salary| sex| job|deptno|rank|
+-------+---+-------+-----+--------+------+----+
|Michael| 29|20000.0| true| MANAGER| 1| 1|
| Kaine| 20|20000.0| true| MANAGER| 2| 2|
| Lisa| 19|18000.0|false|SALESMAN| 2| 3|
| Andy| 30|15000.0| true|SALESMAN| 1| 4|
| Justin| 19| 8000.0| true| CLERK| 1| 5|
+-------+---+-------+-----+--------+------+----+
可以看出ROW_NUMBER()函数只能计算结果在当前开窗函数中的顺序。并不能计算排名。
9.DENSE_RANK()
计算员工在公司薪资排名
val sql="select * , DENSE_RANK() over(order by salary DESC) rank from t_emp"
spark.sql(sql).show()
+-------+---+-------+-----+--------+------+----+
| name|age| salary| sex| job|deptno|rank|
+-------+---+-------+-----+--------+------+----+
|Michael| 29|20000.0| true| MANAGER| 1| 1|
| Jimi| 25|20000.0| true|SALESMAN| 1| 1|
| Kaine| 20|20000.0| true| MANAGER| 2| 1|
| Lisa| 19|18000.0|false|SALESMAN| 2| 2|
| Andy| 30|15000.0| true|SALESMAN| 1| 3|
| Justin| 19| 8000.0| true| CLERK| 1| 4|
+-------+---+-------+-----+--------+------+----+
计算员工在公司部门薪资排名
val sql="select * , DENSE_RANK() over(partition by deptno order by salary DESC) rank from t_emp"
spark.sql(sql).show()
+-------+---+-------+-----+--------+------+----+
| name|age| salary| sex| job|deptno|rank|
+-------+---+-------+-----+--------+------+----+
|Michael| 29|20000.0| true| MANAGER| 1| 1|
| Kaine| 20|20000.0| true| MANAGER| 2| 1|
| Lisa| 19|18000.0|false|SALESMAN| 2| 2|
| Andy| 30|15000.0| true|SALESMAN| 1| 3|
| Justin| 19| 8000.0| true| CLERK| 1| 4|
+-------+---+-------+-----+--------+------+----+
10.RANK()
该函数和DENSE_RANK()类似,不同的是RANK计算的排名顺序不连续。
计算员工在公司部门薪资排名
val sql="select * , RANK() over(partition by deptno order by salary DESC) rank from t_user"
spark.sql(sql).show()
+-------+---+-------+-----+--------+------+----+
| name|age| salary| sex| job|deptno|rank|
+-------+---+-------+-----+--------+------+----+
|Michael| 29|20000.0| true| MANAGER| 1| 1|
| Kaine| 20|20000.0| true| MANAGER| 2| 1|
| Lisa| 19|18000.0|false|SALESMAN| 2| 3|
| Andy| 30|15000.0| true|SALESMAN| 1| 4|
| Justin| 19| 8000.0| true| CLERK| 1| 5|
+-------+---+-------+-----+--------+------+----+
11.自定义函数
(1)单行函数
//注册单行函数-根据岗位匹配年薪计算方式
spark.udf.register("yearSalary",(job:String,salary:Double)=> {
job match {
case "MANAGER" => salary * 14
case "SALESMAN" => salary * 16
case "CLERK" => salary * 13
case _ => salary*12
}
})
//将单行函数在sql语句中引入
spark.sql("select name,salary, yearSalary(job,salary) as yearSalary from t_user")
.show()
(2)聚合函数
无类型聚合( 使用范围:Spark SQL)
- order.txt
1,苹果,4.5,2,001
2,橘子,2.5,5,001
3,机械键盘,800,1,002
- MySumAggregateFunction
import org.apache.spark.sql.Row
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, DoubleType, IntegerType, StructType}
class MySumAggregateFunction extends UserDefinedAggregateFunction{
//指明函数参数类型,name参数无所谓
override def inputSchema: StructType = {
new StructType().add("price",DoubleType).add("count",IntegerType)
}
//指明函数结果的结构(Schema)
override def bufferSchema: StructType = {
new StructType().add("totalCost",DoubleType)
}
//指明函数结果值的类型
override def dataType: DataType = DoubleType
//一般为true
override def deterministic: Boolean = true
//设置统计结果的初始值(0-第一个参数,0.0-Double类型的初始值)
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer.update(0,0.0)
}
//局部计算
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
val price=input.getAs[Double](0)
val count=input.getAs[Integer](1)
val historyCost=buffer.getDouble(0)
buffer.update(0,historyCost+price*count)
}
//汇总计算最终结果,将最终结果更新到buffer1
//每次局部计算形成一个buffer,本方法将buffer1作为基点,将后续buffer与buffer1逐个相加求和
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
var totalCost=buffer1.getDouble(0)+buffer2.getDouble(0)
buffer1.update(0,totalCost)
}
//执行最终的返回结果
override def evaluate(buffer: Row): Any = {
buffer.getDouble(0)
}
}
- 按照userid统计用户消费
//定义样本类,将所需要的参数进行封装
case class OrderLog(price:Double,count:Int,userid:String)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("hellosql")
.master("local[10]")
.getOrCreate()
import spark.implicits._//必须引入隐式转换,否则相关附加功能优化不能实现
var orderDF= spark.sparkContext.textFile("file:///D:/WorkSpace02/order.txt")
.map(_.split(","))
//将RDD装换成由OrderLog封装的Row
.map(arr=> OrderLog(arr(2).toDouble,arr(3).toInt,arr(4)))
.toDF().createTempView("t_order")
//注册聚合函数类
spark.udf.register("customsum",new MySumAggregateFunction())
//书写Sql语句,调用聚合函数
spark.sql("select userid , customsum(price,count) as totalCost from t_order group by userid").show()
//关闭Spark日志
spark.sparkContext.setLogLevel("FATAL")
spark.stop()
}
输出结果
+------+---------+
|userid|totalCost|
+------+---------+
| 001| 21.5|
| 002| 800.0|
+------+---------+
有类型聚合|强类型聚合 (使用范围:DataFrame API )
- AverageState
case class AverageState(var sum: Double, var total: Int)
- MyAggregator
import org.apache.spark.sql.{Encoder, Encoders}
import org.apache.spark.sql.catalyst.expressions.GenericRowWithSchema
import org.apache.spark.sql.expressions.Aggregator
class MyAggregator extends Aggregator[GenericRowWithSchema,AverageState,Double]{
//定义平均值的初始值
override def zero: AverageState = AverageState(0.0,0)
//局部合并,在b(AverageState)的基础上,累加
override def reduce(b: AverageState, a: GenericRowWithSchema): AverageState = {
var sum=b.sum+a.getAs[Int]("count")*a.getAs[Double]("price")
var count=b.total+1
//将最新值更新到b
b.copy(sum,count)
}
//最终合并
//每次局部计算形成一个buffer,本方法将b1作为基点,将后续buffer与b1逐个相加求和
override def merge(b1: AverageState, b2: AverageState): AverageState = {
//将最新值(最终值)更新到b1
b1.copy(b1.sum+b2.sum,b1.total+b2.total)
}
//最终输出结果
override def finish(reduction: AverageState): Double = {
reduction.sum/reduction.total
}
//将中间计算结果序列化
override def bufferEncoder: Encoder[AverageState] = {
Encoders.product[AverageState]
}
//将最终计算结果序列化
override def outputEncoder: Encoder[Double] = {
Encoders.scalaDouble
}
}
- 按照userid统计用户每次消费的平均值
//定义样本类,将所需要的参数进行封装
case class OrderLog(price:Double,count:Int,userid:String)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("hellosql")
.master("local[10]")
.getOrCreate()
import spark.implicits._//必须引入隐式转换,否则相关附加功能优化不能实现
var orderDF= spark.sparkContext.textFile("file:///D:/WorkSpace02/order.txt")
.map(_.split(","))
//将RDD装换成由OrderLog封装的Row
.map(arr=> OrderLog(arr(2).toDouble,arr(3).toInt,arr(4)))
.toDF()
//调用自定义聚合函数类型MyAggregator(),并添加新列“avgCost”
val avg=new MyAggregator().toColumn.name("avgCost")
//执行Data Frame的groupBy和agg算子
orderDF.groupBy($"userid").agg(avg).show()
//关闭Spark日志
spark.sparkContext.setLogLevel("FATAL")
spark.stop()
}
输出结果
+------+-------+
|userid|avgCost|
+------+-------+
| 001| 10.75|
| 002| 800.0|
+------+-------+
12.Load & save 函数
- MySQL集成(引入MysQL驱动jar)
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
spark.read
.format("jdbc")
.option("url", "jdbc:mysql://CentOS:3306/test")
.option("dbtable", "t_user")
.option("user", "root")
.option("password", "root")
.load().createTempView("t_user")
spark.sql("select * from t_user").show()
- 读取CSV格式的数据
spark.read.format("csv")
.option("sep", ",")
.option("inferSchema", "true")
.option("header", "true")
.load("file:///D:/t_user.csv").createTempView("t_user")
- 读取json数据
spark.read.format("json")
.load("file:///D:/Person.json")
.createTempView("t_user")
- 数据导入MysQL
val personRDD = spark.sparkContext.parallelize(Array("14 tom 19", "15 jerry 18", "16 kitty 20"))
.map(_.split(" "))
.map(tokens=>Row(tokens(0).toInt,tokens(1),tokens(2).toInt))
//通过StrutType直接指定每个字段的schema
val schema = StructType(
List(
StructField("id",IntegerType,true),
StructField("name",StringType,true),
StructField("age",IntegerType,true)
)
)
val props = new Properties()
props.put("user", "root")
props.put("password", "root")
spark.createDataFrame(personRDD,schema)
.write.mode("append")
.jdbc("jdbc:mysql://CentOS:3306/test",
"t_user",props)
- 存储为Json
val personRDD = spark.sparkContext.parallelize(Array("14 tom 19", "15 jerry 18", "16 kitty 20"))
.map(_.split(" "))
.map(tokens=>Row(tokens(0).toInt,tokens(1),tokens(2).toInt))
//通过StrutType直接指定每个字段的schema
val schema = StructType(
List(
StructField("id",IntegerType,true),
StructField("name",StringType,true),
StructField("age",IntegerType,true)
)
)
spark.createDataFrame(personRDD,schema)
.write.mode("append")
.format("json")
.save("file:///D:/aa.json")
- 存储为CSV格式
val personRDD = spark.sparkContext.parallelize(Array("14 tom 19", "15 jerry 18", "16 kitty 20"))
.map(_.split(" "))
.map(tokens=>Row(tokens(0).toInt,tokens(1),tokens(2).toInt))
//通过StrutType直接指定每个字段的schema
val schema = StructType(
List(
StructField("id",IntegerType,true),
StructField("name",StringType,true),
StructField("age",IntegerType,true)
)
)
spark.createDataFrame(personRDD,schema)
.write.mode("append")
.format("csv")
.option("header", "true")//存储表头
.save("file:///D:/csv")
- 生产分区文件
val spark = SparkSession.builder()
.appName("hellosql")
.master("local[10]")
.getOrCreate()
spark.read.format("csv")
.option("sep", ",")
.option("inferSchema", "true")
.option("header", "true")
.load("file:///D:/t_user.csv").createTempView("t_user")
spark.sql("select * from t_user")
.write.format("json")
.mode(SaveMode.Overwrite)
.partitionBy("id")
.save("file:///D:/partitions")
spark.stop()
Jar包解决
- 使用shade插件, 生成fatjar
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.0.1</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
- 使用 --packages解决jar包依赖(需要联网)
[root@CentOS spark-2.4.3]# ./bin/spark-submit --master spark://CentOS:7077 --deploy-mode client --class com.baizhi.demo10parkStreamWordCounts --total-executor-cores 4 --packages 'org.apache.spark:spark-streaming-kafka-0-10_2.11:2.4.3,redis.clients:jedis:2.9.0' /root/original-sparkstream-1.0-SNAPSHOT.jar
注意以上两种方式均不可以解决MySQL的依赖问题。
- 使用spark.executor.extraClassPath和spark.driver.extraClassPath能够解决MySQL依赖问题
[root@CentOS spark-2.4.3]# ./bin/spark-submit --master spark://CentOS:7077 --deploy-mode client --class com.baizhi.demo10parkStreamWordCounts --total-executor-cores 4 --packages 'org.apache.spark:spark-streaming-kafka-0-10_2.11:2.4.3,redis.clients:jedis:2.9.0' --conf spark.executor.extraClassPath=/root/mysql-xxx.jar --conf spark.driver.extraClassPath=/root/mysql-xxx.jar /root/original-sparkstream-1.0-SNAPSHOT.jar
如果大家觉得麻烦,还可以在spark-defaut.conf配置改参数
spark.executor.extraClassPath=/root/.ivy2/jars/*
spark.driver.extraClassPath=/root/.ivy2/jars/*
六、Standalone集群构建(HA)
物理资源:CentOSA/B/C-6.5 64bit 内存2GB
| 主机名 | IP | 角色 |
|---|---|---|
| CentOSA | 192.168.111.134 | Zookepper、NameNode、DataNode、journalnode、zkfc、master(spark)、Worker(Spark)、Kafka |
| CentOSB | 192.168.111.135 | Zookepper、NameNode、DataNode、journalnode、zkfc、master(spark)、Worker(Spark)、Kafka |
| CentOSC | 192.168.111.136 | Zookepper、DataNode、journalnode、master(spark)、Worker(Spark)、Kafka |
(一)环境准备
- 主机名和IP映射关系
[root@CentOSX ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.111.134 CentOSA
192.168.111.135 CentOSB
192.168.111.136 CentOSC
- 设置CentOS进程数和文件数(重启)
[root@CentOS ~]# vi /etc/security/limits.conf
* soft nofile 204800
* hard nofile 204800
* soft nproc 204800
* hard nproc 204800
[root@CentOS ~]# reboot
- 关闭防火墙
[root@CentOSX ~]# service iptables stop
iptables: Setting chains to policy ACCEPT: filter [ OK ]
iptables: Flushing firewall rules: [ OK ]
iptables: Unloading modules: [ OK ]
[root@CentOSX ~]# chkconfig iptables off
- 同步时钟
[root@CentOSX ~]# yum install -y ntp
[root@CentOSX ~]# ntpdate ntp.ubuntu.com
[root@CentOSX ~]# clock -w
- SSH免密码认证
[root@CentOSX ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
2c:4b:ba:46:66:27:18:74:11:a7:96:f5:e5:96:97:d5 root@CentOSA
The key's randomart image is:
+--[ RSA 2048]----+
| ooo . .. |
| . .= . o . o E|
| . .+ . + o |
| .. . . . |
| o o S |
| . =o.o |
| +.o. |
| .. |
| .. |
+-----------------+
[root@CentOSX ~]# ssh-copy-id CentOSA
[root@CentOSX ~]# ssh-copy-id CentOSB
[root@CentOSX ~]# ssh-copy-id CentOSC
(二)构建zookeeper集群
- 安装JDK
jdk-8u191-linux-x64.rpm
[root@CentOSX ~]# rpm -ivh jdk-8u191-linux-x64.rpm
[root@CentOSX ~]# vi .bashrc
JAVA_HOME=/usr/java/latest
PATH=$PATH:$/bin
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
[root@CentOSX ~]# source .bashrc
[root@CentOSX ~]# java -version
java version "1.8.0_191"
Java(TM) SE Runtime Environment (build 1.8.0_191-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.191-b12, mixed mode)
- 安装配置Zookeeper集群
[root@CentOSX ~]# tar -zxf zookeeper-3.4.6.tar.gz -C /usr/
[root@CentOSX ~]# mkdir /root/zkdata
[root@CentOSA ~]# echo 1 >> /root/zkdata/myid
[root@CentOSB ~]# echo 2 >> /root/zkdata/myid
[root@CentOSC ~]# echo 3 >> /root/zkdata/myid
[root@CentOSX ~]# vi /usr/zookeeper-3.4.6/conf/zoo.cfg
tickTime=2000
dataDir=/root/zkdata
clientPort=2181
initLimit=5
syncLimit=2
server.1=CentOSA:2887:3887
server.2=CentOSB:2887:3887
server.3=CentOSC:2887:3887
[root@CentOSX ~]# /usr/zookeeper-3.4.6/bin/zkServer.sh start zoo.cfg
[root@CentOSX ~]# /usr/zookeeper-3.4.6/bin/zkServer.sh status zoo.cfg
JMX enabled by default
Using config: /usr/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: `follower|leader`
(三)构建Kafka集群
1.配置与安装
[root@hadoopX ~]# tar -zxf kafka_2.11-2.2.0.tgz -C /usr
[root@hadoop2 ~]# vi /usr/kafka_2.11-2.2.0/config/server.properties
############################# Server Basics #############################
broker.id=[0|1|2]
############################# Socket Server Settings #############################
listeners=PLAINTEXT://CentOS[A|B|C]:9092
############################# Log Basics #############################
# A comma separated list of directories under which to store log files
log.dirs=/usr/kafka-logs
############################# Zookeeper #############################
zookeeper.connect=CentOSA:2181,CentOSB:2181,CentOSC:2181
2.启动服务
[root@CentOSX ~]# cd /usr/kafka_2.11-2.2.0/
[root@CentOSX kafka_2.11-2.2.0]# ./bin/kafka-server-start.sh -daemon config/server.properties
3.测试环境
- 创建topic01
[root@CentOSA kafka_2.11-2.2.0]# ./bin/kafka-topics.sh
--zookeeper CentOSA:2181,CentOSB:2181,CentOSC:2181
--create
--topic topic01
--partitions 3
--replication-factor 3
Created topic topic01.
这里
partitions指定日志分区数目,replication-factor指定分区日志的副本因子。
- 消费者订阅topic01
[root@CentOSA kafka_2.11-2.2.0]# ./bin/kafka-console-consumer.sh
--bootstrap-server CentOSA:9092,CentOSB:9092,CentOSC:9092
--topic topic01
- 生产消息
[root@CentOSB kafka_2.11-2.2.0]# ./bin/kafka-console-producer.sh --broker-list CentOSA:9092,CentOSB:9092,CentOSC:9092 --topic topic01
> Hello Kafka
4.关闭Kafka服务
修改kafka-server-stop.sh
#!/bin/sh
SIGNAL=${SIGNAL:-TERM}
#PIDS=$(ps ax | grep -i 'kafka\.Kafka' | grep java | grep -v grep | awk '{print $1}')
PIDS=$(jps | grep 'Kafka' | awk '{print $1}')
if [ -z "$PIDS" ]; then
echo "No kafka server to stop"
exit 1
else
kill -s $SIGNAL $PIDS
fi
(四)Hadoop NameNode HA
- 解压并配置HADOOP_HOME
[root@CentOSX ~]# tar -zxf hadoop-2.9.2.tar.gz -C /usr/
[root@CentOSX ~]# vi .bashrc
HADOOP_HOME=/usr/hadoop-2.9.2
JAVA_HOME=/usr/java/latest
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
export HADOOP_HOME
[root@CentOSX ~]# source .bashrc
- 配置core-site.xml
<!--配置Namenode服务ID-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop-2.9.2/hadoop-${user.name}</value>
</property>
<!--配置垃圾回收间隔-->
<property>
<name>fs.trash.interval</name>
<value>30</value>
</property>
<!--配置机架脚本-->
<property>
<name>net.topology.script.file.name</name>
<value>/usr/hadoop-2.9.2/etc/hadoop/rack.sh</value>
</property>
<!--配置ZK服务信息-->
<property>
<name>ha.zookeeper.quorum</name>
<value>CentOSA:2181,CentOSB:2181,CentOSC:2181</value>
</property>
<!--配置SSH秘钥位置-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
- 配置机架脚本
[root@CentOSX ~]# touch /usr/hadoop-2.9.2/etc/hadoop/rack.sh
[root@CentOSX ~]# chmod u+x /usr/hadoop-2.9.2/etc/hadoop/rack.sh
[root@CentOSX ~]# vi /usr/hadoop-2.9.2/etc/hadoop/rack.sh
while [ $# -gt 0 ] ; do
nodeArg=$1
exec</usr/hadoop-2.9.2/etc/hadoop/topology.data
result=""
while read line ; do
ar=( $line )
if [ "${ar[0]}" = "$nodeArg" ] ; then
result="${ar[1]}"
fi
done
shift
if [ -z "$result" ] ; then
echo -n "/default-rack"
else
echo -n "$result "
fi
done
[root@CentOSX ~]# vi /usr/hadoop-2.9.2/etc/hadoop/topology.data
192.168.111.134 /rack01
192.168.111.135 /rack02
192.168.111.136 /rack03
- 配置hdfs-site.xml
<!--配置副本集-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--开启自动故障转移-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--解释core-site.xml内容-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!--配置Active和StandBy NameNode-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>CentOSA:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>CentOSB:9000</value>
</property>
<!--配置日志服务器的信息-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://CentOSA:8485;CentOSB:8485;CentOSC:8485/mycluster</value>
</property>
<!--实现故障转切换的实现类-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
- 配置slaves
CentOSA
CentOSB
CentOSC
- 启动HDFS(集群初始化启动)
[root@CentOSX ~]# hadoop-daemon.sh start journalnode (等待10s钟)
[root@CentOSA ~]# hdfs namenode -format
[root@CentOSA ~]# hadoop-daemon.sh start namenode
[root@CentOSB ~]# hdfs namenode -bootstrapStandby
[root@CentOSB ~]# hadoop-daemon.sh start namenode
#注册Namenode信息到zookeeper中,只需要在CentOSA或者B上任意一台执行一下指令
[root@CentOSA|B ~]# hdfs zkfc -formatZK
[root@CentOSA ~]# hadoop-daemon.sh start zkfc
[root@CentOSB ~]# hadoop-daemon.sh start zkfc
[root@CentOSX ~]# hadoop-daemon.sh start datanode
(五)构建Spark Standalone
- 安装配置Spark
[root@CentOSX ~]# tar -zxf spark-2.4.3-bin-without-hadoop.tgz -C /usr/
[root@CentOSX ~]# mv /usr/spark-2.4.3-bin-without-hadoop/ /usr/spark-2.4.3
[root@CentOSX ~]# cd /usr/spark-2.4.3/conf/
[root@CentOS conf]# mv spark-env.sh.template spark-env.sh
[root@CentOS conf]# mv slaves.template slaves
[root@CentOS conf]# vi slaves
CentOSA
CentOSB
CentOSC
[root@CentOS conf]# vi spark-env.sh
SPARK_WORKER_CORES=4
SPARK_WORKER_MEMORY=2g
LD_LIBRARY_PATH=/usr/hadoop-2.9.2/lib/native
SPARK_DIST_CLASSPATH=$(hadoop classpath)
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=CentOSA:2181,CentOSB:2181,CentOSC:2181 -Dspark.deploy.zookeeper.dir=/spark"
export SPARK_WORKER_CORES
export SPARK_WORKER_MEMORY
export LD_LIBRARY_PATH
export SPARK_DIST_CLASSPATH
export SPARK_DAEMON_JAVA_OPTS
- 启动Spark服务
[root@CentOSX ~]# cd /usr/spark-2.4.3/
[root@CentOSA spark-2.4.3]# ./sbin/start-all.sh
[root@CentOSB spark-2.4.3]# ./sbin/start-master.sh
[root@CentOSC spark-2.4.3]# ./sbin/start-master.sh
- 测试Spark环境
[root@CentOSA spark-2.4.3]# ./bin/spark-shell --master spark://CentOSA:7077,CentOSB:7077,CentOSC:7077 --total-executor-cores 6
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://CentOSA:4040
Spark context available as 'sc' (master = spark://CentOSA:7077,CentOSB:7077,CentOSC:7077, app id = app-20190708162400-0000).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.3
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_191)
Type in expressions to have them evaluated.
Type :help for more information.
scala>

















 1247
1247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









