







java文件流插入数据库
在本文中,您将学习如何编写纯Java应用程序,这些应用程序能够处理现有数据库中的数据,而无需编写一行SQL(或类似的语言,例如HQL),而无需花费数小时将所有内容放在一起。 准备好应用程序之后,您将通过仅添加两行代码来学习如何使用JVM内加速功能将延迟性能提高1000倍以上。
在本文中,我们将使用Speedment,它是一个Java流ORM,可以直接从数据库模式生成代码,并且可以自动将Java Streams直接呈现为SQL,从而允许您使用纯Java编写代码。
您还将发现,通过直接在RAM中运行流的JVM内存技术可以显着提高数据访问性能。
示例数据库
我们将使用来自MySQL的名为Sakila的示例数据库。 它具有名为Film,Actor,Category等的表格,可以在此处免费下载。
步骤1:连接到数据库
我们将开始使用可以在此处找到的Speedment Initializer配置pom.xml文件。 按“下载”,您将获得带有自动生成的Main.java文件的项目文件夹。

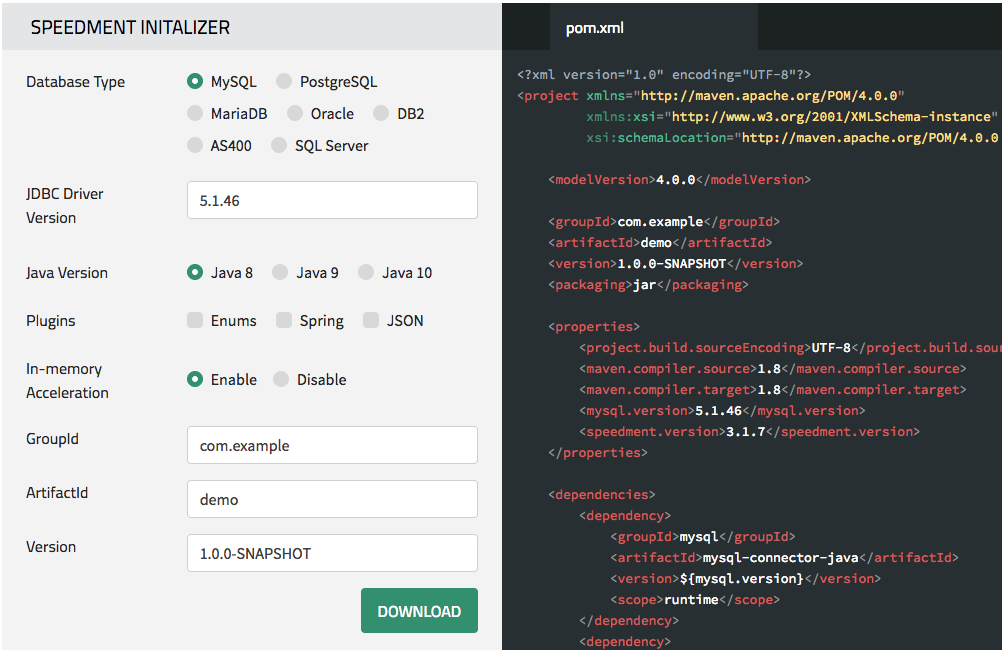
接下来,解压缩项目文件夹zip文件,打开命令行,转到解压缩的文件夹(pom.xml文件所在的文件夹)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3451
3451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}