





java金融
Java 8不仅仅是Oracle提供的最新软件小工具,它还可以极大地简化您的代码,甚至可以使其运行更快
我是最新小工具的忠实拥护者,但是Java 8为Java带来的不仅仅是新的小工具。 随着lambda形式的函数式编程在Java 8中首次亮相,这是自泛型以来对语言的最大改变。 我从事金融服务已经超过25年,从Java 7到Java 8的转变几乎与95年代从C ++到Java本身一样令人兴奋。
在本文中,我将大致执行以下操作……
- 从Excel电子表格中的一些简单CSV数据开始,将其导入Java模型并在包含数据的Java模型上运行一些lambda
- 通过随机生成其他数据; 这样,我们可以生成几百万个而不是上面的10行-更适合分类演示
- 最后,我将放弃简单的数据,并使用来自FpML的更复杂的XML数据,将其随机化并运行类似的lambda。
设置-读取一些测试数据…
让我们从一个可以使用的数据集开始,我们可以在本文的其余部分中参考这些数据集。 很简单,我们可以使示例保持简单,但是稍后我将向您展示如何使用简单版本进行所有操作,也可以使用更复杂的数据源(例如FpML,ISO-20022,SWIFT或FIX)进行处理。
首先是数据
|
ID | 贸易日期 | 买卖 | 货币1 | 数量1 | 汇率 | 货币2 | 数量2 | 结算日期 |
1个 | 2014年7月21日 | 购买 | 欧元 | 50,000,000 | 1.344 | 美元 | 67,200,000 | 2014/07/28 |
2 | 2014年7月21日 | 卖 | 美元 | 35,000,000 | 0.7441 | 欧元 | 26,043,500 | 2014年8月20日 |
3 | 2014/07/22 | 购买 | 英镑 | 7,000,000 | 172.99 | 日元 | 1,210,930,000 | 2014/05/08 |
4 | 2014年7月23日 | 卖 | 澳币 | 13,500,000 | 0.9408 | 美元 | 12,700,800 | 2014年8月22日 |
5 | 2014/07/24 | 购买 | 欧元 | 11,000,000 | 1.2148 | 瑞士法郎 | 13,362,800 | 2014年7月31日 |
6 | 2014/07/24 | 购买 | 瑞士法郎 | 6,000,000 | 0.6513 | 英镑 | 3,907,800 | 2014年7月31日 |
7 | 2014年25月25日 | 卖 | 日元 | 150,000,000 | 0.6513 | 欧元 | 97,695,000 | 2014年8月8日 |
8 | 2014年25月25日 | 卖 | 电脑辅助设计 | 17,500,000 | 0.9025 | 美元 | 15,793,750 | 2014年1月8日 |
9 | 2014/07/28 | 购买 | 英镑 | 7,000,000 | 1.8366 | 电脑辅助设计 | 12,856,200 | 2014年8月27日 |
10 | 2014/07/28 | 购买 | 欧元 | 13,500,000 | 0.7911 | 英镑 | 10,679,850 | 2014年11月8日 |
这是纯虚拟的数据,仅用Excel在几分钟内就完成了,但是我们将在示例中使用它。 要将其导入Java,我们有几种选择。 我们可以手动编写Trade类并在数据中进行硬编码,可以进行演示,但不能满足其他任何要求。 我们可以编写一个快速的解析器来读取CSV,但是现在我们在开始播放之前谈论了很多代码。 我的首选方式和建议(即使我不是CTO)也要使用C24的集成对象( 免费下载 ),只需Java绑定CSV或XLS以在几秒钟内生成Java,所有这些演示都使用C24 CSV绑定。
创建和使用Java 8流
顾名思义,流是一种处理数据的新方法,即流。 再次像lambdas一样,使用Streams不能做的事就是没有它们不能做的事。 但是,它确实使您的代码更加简单,并且只要您理解它,就易于阅读和维护。 最后,使用这些新结构为编译器和JVM提供了更多信息,因此可以在运行时进行进一步的改进,以提供更好的性能。 有一些陷阱,例如异常处理,调试和无限流,但我们将逐步介绍这些陷阱。
拿一个货币列表,我们可能想过滤或打印出来,我敢肯定,您可以想到使用数组,列表,集合,迭代器,for循环等的十二种方法。这是Stream版本或应该我说“ a”流版本…
Stream<String> currencies = Stream.of("GBP", "EUR", "USD", "CAD", "AUD", "JPY", "HKD" );
currencies.forEach( ccy -> System.out.println( ccy ) ); 如果您立即发现forEach并说有一种更简单的方法,那是对的,我想展示一些更容易理解的东西。 因此,我们创建了一个变量“ ccy”,可以调用任何东西(通常只使用一个字母),然后定义适用于该变量的内容。
这些都同样有效……
currencies.forEach( currency -> System.out.println( currency ) );
currencies.forEach( c -> System.out.println( c ) );
currencies.forEach( x -> System.out.println( x ) ); 我非常喜欢自我记录代码,因此出于这些原因,我真的应该更喜欢带有“ currency”的第一个版本,但是老实说,我开始习惯于单字母版本。 我的建议是只选择一个有意义的字母,“ c”(对于货币)对我而言比“ x”更有意义。 有趣的是,值得指出的是,在Stream中,变量被神奇地键入到Stream中的项目,在这种情况下,Stream元素(在<>中)是字符串。
实际上,我们可以使用此lambda进一步发展,并使用方法引用,“ ::”语法是指要应用于每个元素的方法(可以是构造函数,静态方法和实例方法)。
currencies.forEach( System.out::println ); 现在让我们尝试一个过滤器...
Stream<String> currencies = Stream.of("GBP", "EUR", "USD", "CAD", "AUD", "JPY", "HKD" );
currencies
.filter( c -> c.matches( "GBP|EUR"))
.forEach( System.out::println );
此输出基本上是GBP和EUR,我们也可以尝试…
currencies
.filter( c -> c.contains("A"))
.forEach( System.out::println );
而且我们得到CAD和AUD。
让我们快速转到我们的贸易数据,并开始真正使用流和lambda ...
作为流阅读行业
用代码读取CSV测试数据仅需一行,它被读入并由上述C24流程生成的绑定代码填充。 现在,我们有了一个Trades对象,该对象实际上具有一个可选的标头和一组Trade对象。
Trades tradeData = C24.parse(Trades.class).from(new File("tradedata.csv"));
ArrayList<Trade> tradesList = new ArrayList<>(Arrays.asList(tradeData.getTrade()));
Stream<Trade> tradeStream = tradesList.stream();
tradeStream.forEach(System.out::print); 我在这里所做的是使用静态Arrays.asList()方法从array []创建一个列表,结果我们得到了交易对象列表,这些是交易数据行(减去标题当然) 。 最后,像上面一样,获取Stream并应用forEach将它们全部打印出来。
1,21/07/2014,Buy,EUR,50000000,1.344,USD,67200000,28/07/2014
2,21/07/2014,Sell,USD,35000000,0.744,EUR,26043500,20/08/2014
3,22/07/2014,Buy,GBP,7000000,172.99,JPY,1210930000,05/08/2014
让我们应用一个过滤器...
(注意:我在自己的lambda中使用“ t->”,但我同样可以使用“ trade->”甚至“ banana->”。没有标准,也没有常规做法,只需选择最有意义的方法,那就是您的代码。)
tradeStream
.filter( t -> t.getID() == 9 )
.forEach(System.out::print);
我们只得到以数字9开头的行。
9,28/07/2014,Buy,GBP,7000000,1.837,CAD,12856200,27/08/2014 让我们尝试货币...
tradeStream
.filter( t -> t.getCurrency1().matches("GBP|EUR") )
.forEach(System.out::print);
1,21/07/2014,Buy,EUR,50000000,1.344,USD,67200000,28/07/2014
3,22/07/2014,Buy,GBP,7000000,172.99,JPY,1210930000,05/08/2014
5,24/07/2014,Buy,EUR,11000000,1.215,CHF,13362800,31/07/2014
9,28/07/2014,Buy,GBP,7000000,1.837,CAD,12856200,27/08/2014
10,28/07/2014,Buy,EUR,13500000,0.791,GBP,10679850,11/08/2014 好的,现在我们只想计算“购买”交易的数量…
long count = tradeStream
.filter(t -> t.getBuySell().matches("Buy"))
.count();
System.out.printf("count = %d%n", count); 我们得到“ count = 6”,现在我们得到所有英镑交易的总和……
BigDecimal total = tradeStream
.filter(t -> t.getCurrency1().matches("GBP"))
.map(t -> t.getAmount1())
.reduce(BigDecimal.ZERO, BigDecimal::add);
System.out.printf("total = %,d", total.intValue()); 首先是一个仅适用于GBP值的过滤器(是的,为简单起见,我们忽略了交易的另一面),然后“地图”基本上将流从Trade对象流转换为BigDecimal对象流,输出getAmount1()的值。 最后,reduce()使用第一个值BigDecimal.ZERO初始化自身,然后对流的每个成员执行BigDecimal :: add方法。 结果如预期般…
total = 14,000,000 我们可以用许多不同的方法来做到这一点。 下面的代码从amount1()获取双精度值,然后使用稍微不同的流,该流添加了sum()方法。 我要给出的警告是,我们正在加倍努力,这对财务业务不利。 幸运的是,对于这个小小的演示,结果是相同的,但是在更大的体积下,我们可以看到由于double的舍入和精度而累积的错误。
double total = tradeStream
.filter(t -> t.getCurrency1().matches("GBP"))
.mapToDouble(t -> t.getAmount1().doubleValue())
.sum();
System.out.printf("total = %,d", total);
我们对交易进行了分类,但让我们进行一些整理,以便我们演示分类…
Trades tradeData = C24.parse(Trades.class).from(new File(fileName));
ArrayList<Trade> tradesList = new ArrayList<>(Arrays.asList(tradeData.getTrade()));
Collections.shuffle(tradesList);
Stream<Trade> tradeStream = tradesList.stream();
tradeStream. sorted( Comparator.comparing(Trade::getID) )
.forEach(System.out::print);
我突出了这两行,首先是标准的(旧的)Java shuffle,然后是新的传递给我想要排序的属性或列的排序。
在进入更大数量和更复杂的消息之前,让我们看一下其他一些功能。 我们有谓词,我们可以在其中查看是否有任何或所有交易与谓词匹配,让我们检查所有金额计算是否正确……
boolean match = tradeStream
.allMatch(t -> t.getAmount1().multiply(BigDecimal.valueOf(t.getExchangeRate()))
.compareTo(t.getAmount2()) == 0);
System.out.println("allMatch = " + match);
Stream.allMatch()只需对流中的所有项目再次运行谓词,然后返回布尔值(如果它们都匹配,则为true)。 我们在这里所做的是检查第一个金额乘以汇率是否等于第二个金额。 我们在这里使用BigDecimal是因为这就是您在金融服务领域所做的事情,我们必须对每一分钱或一分钱都有精确的控制,而IEEE double会在一段时间后给我们一些错误。
我们还可以将谓词放入一种方法中以再次使用它……
private static Predicate<Trade> rateCheck() {
return t -> t.getAmount1().multiply(BigDecimal.valueOf(t.getExchangeRate()))
.compareTo(t.getAmount2()) == 0;
}
然后就叫它...
boolean match = tradeStream.allMatch(rateCheck());
System.out.println("allMatch = " + match); 请注意,我在这里使用static纯粹是因为在本文中我正在main()中编写代码,没有其他原因。
谓词也可以是Trade对象的一部分,但是我们也可以在Trade对象上重用验证方法,而该谓词将只是isValidate()方法的结果有效或为true。 C24提供了内置在模型中的功能非常强大的验证,特别适用于FpML,FIX,ISO-20022,SWIFT和其他需要除语法验证之外还需要复杂语义验证的标准。
我们没有noneMatch()…
boolean match = tradeStream
.noneMatch( t -> t.getTradeDate().getTime() > t.getSettlementDate().getTime());
System.out.println("allMatch = " + match);
这只是检查所有交易的交易日期都不会大于其结算日期,而不使用新的Java Date类,而是使用良好的java.util.Date。 最后是anyMatch(),但希望现在可以得到图片。
大量交易
让我们删除仅10个交易的示例文件,并使用另一个名为generate()的有用方法来创建更大的流。 我们这样做的原因是为了证明使用并行操作可以提高性能。
首先,我们需要创建新的Trade对象的东西,我基本上已经使用新方法createTrade()将交易的内容随机化了。 为了使它适合一页,我已经删除了注释,但是我想您会发现仅使用纯代码就可以理解它。 它遍历交易中的每个领域并创建一个新的随机领域。 对于货币,我们需要确保第二个与第一个不相同,因此我们循环播放直到不同为止,并使用tradeDate进行相同操作以确保它不是周末。 最后,我使用固定值作为汇率,但使用具有0.5%标准偏差的高斯分布对它们进行了一些随机化处理,然后将其限制为5个有效数字。
运行它,我们得到的是这样的东西,显然每次运行它都是不同的,当然是随机的……
1,25/08/2014,Buy,CAD,3000000,0.82775,CHF,2483250,15/09/2014
2,27/08/2014,Sell,GBP,14000000,1.84579,CAD,25841060,03/09/2014
3,01/08/2014,Buy,CHF,17000000,0.65699,GBP,11168830,22/08/2014
4,14/08/2014,Buy,CHF,24000000,1.18559,AUD,28454160,04/09/2014
5,19/08/2014,Sell,AUD,7000000,0.68886,EUR,4822020,02/09/2014 由此创建流非常简单,我们可以使用Stream.generate()
// Our random Trade creator has the signature “Trade createTrade()”
Stream<Trade> tradeStream = Stream.generate(() -> {
return createTrade();
});
使用这种随机产生的交易流,我们可以在小样本上完成上面做的所有事情。 但是请注意,我在此处打印的结果不一定与您的结果相同。 但是,如果您要运行此程序,则有一个问题……
tradeStream.forEach(System.out::print); 您将有很多输出,而且它不会结束。 同样,如果我们要计算总和或计算项目数,则永远不会返回结果,因此我们需要限制流的输出。 limit(n)很好地完成了工作。
tradeStream
.limit(100)
.forEach(System.out::print); 现在我们可以生成更大的数字,让我们列出1,000个仅将GBP转换为USD的交易。 这次我使用收集器,使用toList()将所有结果收集到List中。 除了在此处进行演示之外,原因之一是在打印结果时,我们可以多次使用该结果。 不利的一面是,每个交易现在都存储在内存中,而我们失去了流的优势之一。
List<Trade> gbp2usdTradeList = tradeStream
.filter(t -> t.getCurrency1().matches("GBP") && t.getCurrency2().matches("USD"))
.limit(1_000)
.collect(Collectors.toList()); 并打印出前三个和后三个…
gbp2usdTradeList.stream().limit(3).forEach(System.out::print);
System.out.println("...");
gbp2usdTradeList.stream().skip(997).forEach(System.out::print); 我们得到了,或者至少我得到了(因为您的人会有不同的数字)…
20,28/08/2014,Sell,GBP,34000000,1.68473,USD,57280820,11/09/2014
29,11/08/2014,Sell,GBP,18000000,1.69772,USD,30558960,18/08/2014
39,07/08/2014,Buy,GBP,13000000,1.68216,USD,21868080,21/08/2014
...
40594,26/08/2014,Buy,GBP,33000000,1.67706,USD,55342980,02/09/2014
40631,29/08/2014,Buy,GBP,40000000,1.69239,USD,67695600,12/09/2014
40672,07/08/2014,Buy,GBP,40000000,1.68191,USD,67276400,14/08/2014 现在让我们测试并行排序,数据已经按tradeId排序,而且金额不是唯一的,所以让我们先按汇率排序(不是并行)……
long start = System.nanoTime();
tradeStream
.filter(t -> t.getCurrency1().matches("GBP") && t.getCurrency2().matches("USD"))
.limit(1_000_000)
.sorted(Comparator.comparing(Trade::getExchangeRate))
.limit(3)
.forEach(System.out::print);
System.out.printf("time = %.3f%n", (System.nanoTime() - start) / 1e9);
我得到...
37387422,29/08/2014,Sell,GBP,18000000,1.64245,USD,29564100,05/09/2014
16612950,21/08/2014,Buy,GBP,11000000,1.6431,USD,18074100,28/08/2014
24092486,11/08/2014,Sell,GBP,18000000,1.64346,USD,29582280,18/08/2014
time = 91.153 现在添加parallel()…
long start = System.nanoTime();
tradeStream
.filter(t -> t.getCurrency1().matches("GBP") && t.getCurrency2().matches("USD"))
.limit(1_000_000)
.parallel()
.sorted(Comparator.comparing(Trade::getExchangeRate))
.limit(3)
.forEach(System.out::print);
System.out.printf("time = %.3f%n", (System.nanoTime() - start) / 1e9); 我知道了
23330640,25/08/2014,Buy,GBP,16000000,1.64217,USD,26274720,15/09/2014
31114616,29/08/2014,Buy,GBP,35000000,1.64179,USD,57462650,05/09/2014
7073144,22/08/2014,Sell,GBP,33000000,1.64487,USD,54280710,12/09/2014
time = 29.270 再次记住,每次运行此交易时,都会产生不同的结果,在我们正在处理的交易量中,4200万笔(大约)的100万笔交易(按时间顺序)肯定会产生一切被平均。
我的机器是4核(超线程)MacBookPro,因此这3倍的性能提升与我期望的差不多,并且仅添加一个方法调用就令人印象深刻。 幕后发生的事情是正在使用新的fork / join。 值得指出的是,如果我不首先过滤数据,就不会看到这种收益,仅仅是因为瓶颈将是流生成。
让我们看一下一些更复杂的流和lambda操作…
让我们使用groupBy操作来计算每个货币对的数量,这与您在SQL中的操作类似……
select CCY1,CCY2,count(*) from Trades group by CCY1,CCY2 现在在Java中使用Streams和lambdas…
Map<String, Long> map = tradeStream
.limit(1_000_000)
.collect(Collectors.groupingBy(t -> t.getCurrency1() + "/" + t.getCurrency2(),
Collectors.counting()));
System.out.println("map = " + map);
我们得到(或至少我得到了)…
map = {AUD/JPY=23816, USD/JPY=23706, AUD/GBP=23949, USD/GBP=23745, CHF/GBP=23666,
JPY/CHF=23864, EUR/CAD=23934, CHF/JPY=23844, CHF/AUD=24077, EUR/USD=23934, USD/AUD=23982,
GBP/EUR=23564, EUR/AUD=23568, USD/EUR=23606, GBP/CAD=23735, GBP/USD=23676, JPY/GBP=23551,
EUR/JPY=24097, USD/CAD=23791, CHF/USD=23738, AUD/CHF=23869, CHF/CAD=23903, CAD/CHF=23875,
JPY/AUD=23759, CHF/EUR=23780, EUR/GBP=23975, GBP/AUD=23831, GBP/JPY=23606, CAD/AUD=23752,
JPY/USD=23773, JPY/CAD=24081, EUR/CHF=23860, CAD/JPY=24001, JPY/EUR=23783, CAD/GBP=23835,
USD/CHF=23770, AUD/USD=23900, AUD/CAD=23799, AUD/EUR=23969, CAD/EUR=23566, CAD/USD=23543,
GBP/CHF=23927} groupingBy()创建一个映射,在这种情况下为Map <String,Long>,该字符串来自groupingBy(),而Long来自Collectors.counting()。
现在再进一步,我们将对货币进行分组(仅是Currency1),然后对分组进行买入/卖出,最后将金额总计(金额1)。
Map<String, Map<Object, BigDecimal>> map = tradeStream
.limit(1_000_000)
.collect(
Collectors.groupingBy(t -> t.getCurrency1(),
Collectors.groupingBy(t -> t.getBuySell(),
Collectors.reducing(
BigDecimal.ZERO, Trade::getAmount1, BigDecimal::add))));
System.out.println("map = " + map); 和输出...
map = {AUD={Sell=1826959000000, Buy=1822442000000}, CHF={Sell=1818975000000,
Buy=1823776000000}, JPY={Sell=1826692000000, Buy=1812326000000}, EUR={Sell=1828203000000,
Buy=1824140000000}, GBP={Sell=1807283000000, Buy=1818057000000}, CAD={Sell=1818615000000,
Buy=1826496000000}, USD={Sell=1817626000000, Buy=1820617000000}} 如果您想知道如何调试它,这里有个提示。 使用peek(),但请记住,您不能放入条件语句,因此可以使用if(t.something()<5)print(t)。 最好的计划是要有一种像这样做的方法……
Map<String, Map<Object, BigDecimal>> map = tradeStream
.limit(1_000_000)
.peek( t -> occasionallyDebug(t) )
.collect( Collectors.groupingBy(t -> t.getCurrency1(), 以及方法/功能... / p>
private static void occasionallyDebug( Trade trade ) {
if( trade.getID() % 100_000 == 0 ) {
System.out.print(“DEBUG: " + trade);
}
}
在现实生活中,我们可以使用此计算来保持位置。 我们可以按交易对手,按货币,当然也可以按日期进行交易。
大量和复杂的XML消息
到目前为止,我们使用了简单的交易模型。 通常,这是最容易理解的方法,但是我们现在要加倍努力,并进行FpML中定义的实际交易。 好吧,当我说“真实”时,我指的是真实的交易,自然地,我们将不得不再次随机化它们。
这是我要使用的示例 ,它有几页,所以我不会在这里打印它浪费空间…
在TradeHeader中,我将两个TradeId值从TW9235和SW2000更改为“ Party1-1234”和“ Party2-1234”,其中“ 1234”是所生成消息的索引,并且我将添加一个随机值。日期(从工作日开始)(从2013年开始)到TradeDate。
然后,我将把InitialValue的值随机化为0到1000万(小数点后2位)。 这发生在两个区域(两个SwapStreams)中,因此都将被更改,尽管如此,我将对此进行随机化处理,因为其他任何值都将使我们将要看的内容变得毫无意义。
FpML非常复杂; 邮件可以具有13个层次结构,这就是为什么我没有开始的原因。 在这种情况下,使用Java比使用关系数据库要容易得多。 我们可以使用分层XML绑定来处理XML。 我们也可以使用XQuery和XPath做到这一点,但是它们都是以XML为中心的语言,而不是我们为什么在这里。 在FpML内部有几个替换组,这些替换组有点像对在运行时定义实现的接口的引用,因此我们还必须导航这些接口,有时还要将接口强制转换为具体类,以便使用正确的getter。 我们的网站上对此有很多介绍,因此在此我们将跳过任何更多的细节。
读取FpML模板(链接中的模板)非常简单,我们使用与CSV文件相同的API…
File XML_INPUT_FILE = new File("valid-ird-ex01-vanilla-swap.xml");
Fpmlmain54DocumentRoot message = C24.parse(Fpmlmain54DocumentRoot.class).from(XML_INPUT_FILE); 设定交易日期…
Trade trade = cdo.getDataDocument().getDataDocumentSG1().getTrade()[0];
trade.getTradeHeader().getTradeDate().setValue(new ISO8601Date(tradeDate.toString()));
设置两个初始值...
Swap swap = (Swap) trade.getProduct();
BigDecimal value = BigDecimal.valueOf(Math.random() * 10_000_000).setScale(2,
BigDecimal.ROUND_UP);
swap.getSwapStream()[0].getCalculationPeriodAmount().getCalculation().getCalculationSG1()
.getNotionalSchedule().getNotionalStepSchedule().setInitialValue(value);
swap.getSwapStream()[1].getCalculationPeriodAmount().getCalculation().getCalculationSG1()
.getNotionalSchedule().getNotionalStepSchedule().setInitialValue(value);
自然地,我们可以编写一些隐藏这种复杂性的方法,这正是我为将在几段中使用的lambda所做的工作。
private void setInitialValue( Fpmlmain54DocumentRoot message, int index, BigDecimal value ) {
Swap swap = (Swap)
message.getDataDocument().getDataDocumentSG1().getTrade()[0].getProduct();
swap.getSwapStream()[index].getCalculationPeriodAmount().getCalculation().getCalculationSG1()
.getNotionalSchedule().getNotionalStepSchedule().setInitialValue(value);
}
我还应该指出,实际上可以在C24的工作室中将FpML模型添加到此辅助方法,这意味着我们可以使用getter和setter将“虚拟” InitialValue添加到消息的根中,如下所示。 这极大地简化了传统Java和新lambda的代码。 现在,我们可以执行以下操作…
message.setInitialValue( 0, value );
BigDecimal value = message.getInitialValue( 0 ); 因此,我们已经获得了包含随机数据的消息,我们现在只需要几千个即可。 为此,我们将它们复制并添加到列表中。
private static final int ARRAY_SIZE = 10_000;
private static List<Fpmlmain54DocumentRoot> messageList = new ArrayList<>(ARRAY_SIZE);
messageList.add((Fpmlmain54DocumentRoot) message.cloneDeep());
让我们开始使用messageList。
我们将遍历这些消息并计算价值超过990万的交易数量,并记住它们现在要复杂得多。
long start = System.nanoTime();
long count = messageList.stream()
.map(t -> t.getInitialValue(0))
.filter(v -> v.compareTo(BigDecimal.valueOf(9_900_000)) > 0)
.count();
System.out.println("count = " + count);
double seconds = (System.nanoTime() - start) / 1e9;
System.out.printf("Time to process: %,d messages: %,.3f seconds (%,.0f per second)%n%n”,
ARRAY_SIZE, seconds, ARRAY_SIZE / seconds);
我得到10,000 FpML消息以下。 我应该指出,我没有进行任何JIT预热,这只是指示性的。
count = 123
Time to run: 10,000 messages: 0.028 seconds (362,371 per second)
一秒钟后,我们将回到表演。 现在,让我们尝试汇总7月份以来的所有交易…
BigDecimal result = messageList.stream()
.filter(t -> getTradeDate(t).getMonth() == 7)
.map(t -> t.getInitialValue(0))
.reduce(BigDecimal.ZERO, BigDecimal::add);
再次表现相似。 我现在想做的是演示并行性能。 我们需要做的就是使用parallelStream()…
for( int loop = 0; loop < 10; loop++ ) {
start = System.nanoTime();
result = cdoList.parallelStream()
.filter(t -> getTradeDate(t).getMonth() == 7)
.map(t -> t.getInitialValue(0))
.reduce(BigDecimal.ZERO, BigDecimal::add);
seconds = (System.nanoTime() - start) / 1e9;
}
System.out.println("result = " + result);
System.out.printf("Time to process (parallel): %,d messages: %,.3f seconds (%,.0f per
second)%n%n”,
ARRAY_SIZE, seconds, ARRAY_SIZE / seconds); 为了获得更好的计时结果,我在这里所做的就是将测试循环10次,然后获取最后的结果。 请记住,如果在JVM设置中使用-server,则默认值为10,000次迭代,然后JIT会编译代码。
我连续和并行运行了100,000条消息…
result = 44656591648.06
Time to process (serial): 100,000 messages: 0.028 seconds (3,561,634 per second) result = 44656591648.06
Time to process (parallel): 100,000 messages: 0.007 seconds (13,713,659 per second) 减少内存使用
如您所见,并行流的性能令人印象深刻。 如果您尝试运行此程序,可能会注意到您需要大量的RAM和一些较大的Xms / Xmx设置。 原因是messageList要求所有消息都在内存中。 将FpML绑定到Java会导致消息对象的大小为15-25k,创建其中的100,000,我们需要2GB的RAM。
我们相信我们已经使用新的Java绑定技术解决了这个问题,该技术将复杂模型直接绑定到二进制文件。 使用上面的代码,但使用此新绑定(无需更改代码,仅更改库),我们可以将40倍以上的消息存入RAM。 我能够在笔记本电脑上进行多达2000万次FpML内存交易来运行上述测试。
分析内存和GC性能
我说过我会简要谈谈GC,内存和性能测量。 我已经使用了许多工具,但是现在倾向于使用的是jVisualVM和Oracle的新Java任务控制(简称“ jmc”,用于命令行分析)和jClarity的Censum(用于GC分析), 在此处了解更多信息。 。
(点击图片放大)

这些是我发现的唯一提供准确结果的工具,尤其是对于Java 8和G1 GC。
JMC基本上类似于类固醇上的jVisualVM。 Oracle显然希望从中获利,并且它很可能会成为有用的工具。 许可虽然有点奇怪,但我什至不确定我是否应该在这里放屏幕快照。 如果他们抱怨,我就不会宣传它。
您可以在没有许可证的情况下使用它(有限制),但是在启动时确实需要添加一些-XX和-D参数。 如您所见,它确实很性感。 我必须指出使用这些工具的陷阱,这基本上是因为它们会严重影响您的运行时性能。 因此,我更喜欢将它们用于代码性能分析,而不是性能基准。 当然,一个导致另一个,因此您最终到达了那里。 但是,您可以很好地了解代码中正在发生的事情。 详细信息级别非常适合查看分配大量内存的地方或代码中花费过多轮询或等待IO的部分。
(点击图片放大)

(点击图片放大)
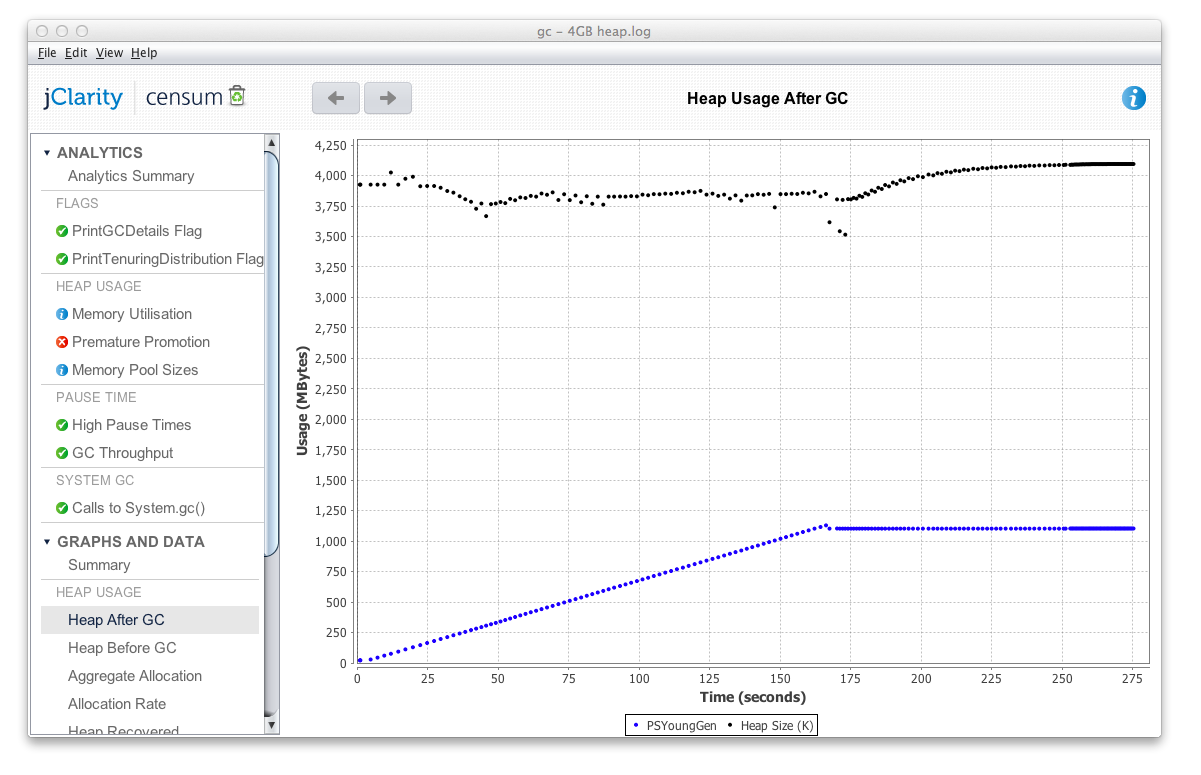
jClarity的Censum:这是一个GC日志文件分析器-JVM中的一些参数再次启动,您可以对日志文件进行非常简洁的事后分析。 与运行时分析相比,这没有那么麻烦,并且到目前为止,这是我发现用于查看内存和GC行为的最佳,最准确的机制。 在右侧,随着我们创建200万条消息,您可以看到后期GC堆使用率逐渐上升。 最终达到令人满意的平坦平台,约为1.08GB。 这是使用4GB的堆,显然总使用量不会随堆大小而改变,但性能会改变,尤其是并行性能。
(点击图片放大)
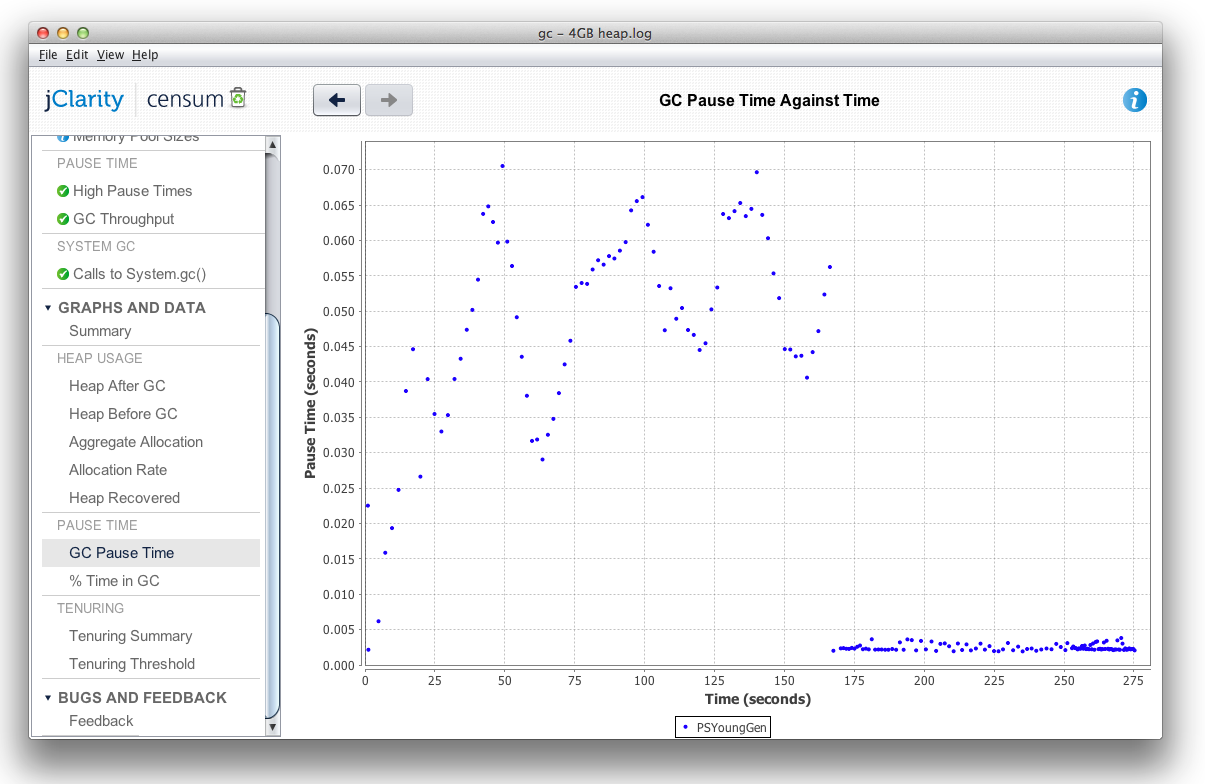
在左侧,您可以看到200万次测试期间GC的暂停时间。 第一部分“跳动”到大约170秒标记是测试之前的数据生成。 在数据生成过程中,暂停时间最长为70毫秒,但对于查询/搜索,暂停时间保持在几毫秒内,这很好。 Censum与jClarity专家的专业知识相结合,是测试代码性能的理想方法。
最后,创建交易的分配率更加复杂,因此分配率相对较低。 运行测试将其增加到大约800MB / sec,然后在并行测试期间最终显着提高。 通常,我不想看到这么高的分配率,但是在这种情况下,我们使用的是一个返回BigDecimal的API,用Java来讲这是一个怪兽。 如果API返回的是double或float,则除了流或lambda创建的任何内容外,我们几乎会看到零分配。 我们刚刚谈到了流API和Lambda。 我的目标是为您提供快速介绍,并向您展示如何将其应用于金融服务。 我个人已经在Internet上找到了数百个资源和示例,尽管刚开始习惯语法可能会有些困难。 我发现最好的方法是从这样简单的事情开始,然后首先尝试您想要的。
(点击图片放大)

我们从几条虚拟交易开始,然后上升到一百万左右,并触及了平行流。 最后,我们极大地增加了FpML交易(利率衍生品)的复杂性,并提到了一些巧妙的内存压缩(使用二进制编解码器),以扩展单个JVM的能力,从而仅在笔记本电脑的内存中就可以并行搜索超过1000万个FpML交易。 。
Java 8是用于编程的新工具,但是产生所需内容的技能仍在程序员手中。 Java 8与诸如AKKA和Spring之类的框架以及诸如二进制绑定之类的性能增强相结合,熟练的程序员现在可以创建一个杰作。
要了解有关C24技术,C24集成对象和C24的SDO(包括数据表,代码参考实现以及更多技术信息)的更多信息,请访问此网站 。
java金融















 1163
1163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









