





openjdk和jdk

本文将调查该JEP为使用新的堆外功能增强熟悉的Java HashMap所必须产生的影响。 简单地说,这JEP可能只是魔力,可以“教”的HashMap(是那个可爱的老狗 )一些新花样。 JEP要求将来的OpenJDK版本与传统Java平台优先级有一些根本性的偏离:
- 将sun.misc.Unsafe的有用部分安全地重构到新的API包中
- 提倡使用新包装的API直接影响堆外本地内存操作数上的高性能本地内存操作
- 提供(通过新的API)从Java到外部函数接口(FFI)的桥 ,用于定向操作系统资源和系统调用。
- 增强Java运行时,以帮助硬件事务存储提供者的焦点将低并行字节代码重写为高并行推测分支机器代码
- 删除与使用堆外编程策略实现Java性能提升相关的FUD(坦率地说,是技术偏执)。 最终,很明显,这个JEP正在要求OpenJDK平台现在公开地将这种曾经黑暗的技术,秘密从业者的秘密社会作为主流。
本文将努力(以一般和温和的方式)容纳所有感兴趣的Java开发人员。 作者要求即使是陌生的“路上颠簸”,即使是新手也要在整篇文章中继续阅读。 因此,请不要气--并且-请保持就座,直到文章完全停下来为止。 本文将努力提供一个历史背景,以提供对以下问题的深入了解:
- 堆中的HashMap问题从何而来?
- 与解决方案工作相关的历史成功/失败是什么?
- 堆上的HashMap用例仍面临哪些未解决的问题?
- 通过新的JEP提供的功能如何帮助提供补救措施(即通过使HashMap脱离堆)?
- 对于解决仍未被堆式JEP解决的问题,我们可以从未来的JEP中获得什么期望?
因此,让我们开始这个旅程。 值得记住的是,在Java之前,哈希表是在本机内存堆中实现的,例如在C和C ++中。 从某种意义上说,重新引入堆外内存进行存储是对大多数现代开发人员都不知道的旧技巧的重新引入。 从许多方面来说,这都是一次“回到未来”的旅程,因此请尽享旅程。
OpenJDK堆外JEP
堆外JEP已有一些提交。 以下示例概述了支持堆外内存的最低要求。 其他提交者试图替代sun.misc.Unsafe(目前正在堆中使用)。 这些还包括许多其他有用和有趣的功能。
JEP摘要:为sun.misc.Unsafe的各个部分创建替换项,因此没有理由直接使用该库。
目标:无需直接访问内部类。
非目标: 不支持不推荐使用的方法,也不支持不安全的方法。
成功指标:有一种受支持的方法可以以相同的性能实现与Unsafe和FileDispatcherImpl相同的关键功能。
动机: 当前,不安全是构建大型,线程安全的堆外数据结构的唯一方法。 这对于最大程度地减少GC开销,在进程之间共享内存以及实现嵌入式数据库而无需使用C和JNI很有用,因为C和JNI可能会更慢且移植性更差。 当前需要FileDispatcherImpl来实现任何大小的内存映射。 (标准API限制为小于2 GB。)
描述: 提供用于堆外内存的包装器类(类似于ByteBuffer ),但具有以下增强功能。
- 64位大小和偏移量
- 线程安全构造,例如易失性和有序访问,比较和交换(CAS)操作。
- JVM优化了边界检查,或开发人员对边界检查的控制。 (前提是安全设置允许这样做)
- 对缓冲区内的不同记录重用缓冲区片段的能力。
- 以优化边界检查的方式将堆外数据结构映射到此类缓冲区的能力。
保留的关键功能:
- 支持内存映射文件
- 支持NIO
- 支持提交到磁盘的写入。
替代方法:直接使用sun.misc.Unsafe。
测试:这将具有与sun.misc.Unsafe相同的测试要求,并且内存映射文件现在需要进行测试。 需要进行其他测试才能证明线程安全操作与AtomicXxxx类的工作方式相同。 可以重写AtomicXxxx类以单独使用此公共API。
风险:虽然许多开发人员使用Unsafe,但他们可能在什么是合适的替代品上未达成共识。 这可能意味着此JEP的范围已扩大,或创建了新的JEP来涵盖Unsafe中的其他功能。
其他JDK: NIO
兼容性:向后兼容性库是可取的。 如果有足够的兴趣,可以为Java 7和Java 6实现。 (由于在撰写本文时,Java 7是当前版本)
安全性 :理想情况下,安全风险应不超过当前的ByteBuffer。
性能和可伸缩性 :优化边界检查可能很困难。 可能需要将更多功能添加到新缓冲区中以进行常见操作,以减少开销,例如writeUTF,readUTF。
HashMap的简要历史
“哈希码”一词最早出现在1953年1月的计算机文学中,当时HP Luhn (1896-1964)使用该术语编写了一份内部IBM备忘录。 卢恩(Luhn)试图解决问题“鉴于课本格式的单词流,呈现100%完整(单词,页面集)索引的最佳算法和数据结构是什么?”

惠普·鲁恩(1896-1964) | Luhn写道“哈希码”是我必不可少的运算符。 Luhn写道“关联数组”是我的基本操作数。 术语“ HashMap”(又名HashTable)在不断发展。 注意:HashMap源自1896年出生的CompScientist。HashMap是老狗! |
将HashMap的故事从起源转移到早期的实际使用中,让我们从1950年代中期过渡到1970年代中期
|
Niklaus Wirth在1976年的经典著作“算法+数据结构=程序”中讨论了“算法”被视为基本的“运算符”,而“数据结构”被视为基本的运算符 所有计算机程序的“操作数”。 从那时起,数据结构(HashMap,Heap等)的进展缓慢。 我们确实看到了塔里安的 F-Heap在1987年取得了非常 重大 的突破,但除此之外-对操作数而言,还有很多其他事情。 记住,HashMap最早出现于1953年,距今已有60多年了! 另一方面 ,算法社区( Karmakar 1984, NegaMax 1989, AKS Primality 2002, Map-Reduce 2006, Grover的Quantum搜索 -2011)发展Swift,为计算的基础奠定了强大的新运算符。 但是,现在是2014年,数据结构又可能再次取得重大进展。 从OpenJDK平台的角度来看, 堆外 HashMap是移动中的数据结构。 HashMap的历史就这么多了。 现在让我们开始探索当今的HashMap。 具体来说,让我们开始看看这只老狗的三个最新Java品种。 |

沃斯(1934-) |
java.util.HashMap(不是线程安全的)
对于任何真正的多线程(MT)并发用例,每次都会Swift失败。 所有地方的所有代码都必须使用Java内存模型(JMM)内存屏障策略(例如同步或易失性)来保证顺序。

| 一个简单的假设示例失败: -同步作家 -非同步阅读器。 -真正的并发(2 x CPU / L1) 让我们看看为什么失败了... |
假设线程1名写入到HashMap中,它的作用只存储在CPU 1的1级高速缓存。 然后,线程2有资格在几秒钟后运行,并在CPU 2上恢复; 它读取来自CPU 2的1级缓存的HashMap-它看不到线程1进行的写入,因为在写入和读取线程中,写入和读取之间都没有内存屏障操作, 这是由共享状态的Java内存模型。 即使线程1同步了写操作,即使写操作的效果将刷新到主内存中,线程2仍将看不到它们,因为读操作来自CPU 2的1级缓存。 因此,只有在同步只写写防止碰撞。 要影响所有线程视图上必要的内存屏障操作,还必须同步阅读器。
thrSafeHM =集合。 synchronizedMap (hm); (课程锁定)
使用“同步”时要获得高性能,就需要低竞争率。 这是很常见的,因此在许多情况下,它并不像听起来那样糟糕。 但是,一旦引入任何争用(试图同时在同一个集合上运行多个线程),性能就会受到影响。 在最坏的情况下,具有高锁争用的情况,您可能最终会导致多个线程的性能比单线程的性能差(没有任何类型的锁或争用)。

这是通过对所有键上的所有mutate()和access()运算符进行阻塞的粗粒度锁来实现的,有效地将整个Map操作数阻塞给除一个Thread运算符之外的所有运算符。 这导致MT并发为零,这意味着一次只能访问一个线程。 这种粗粒度锁定方法的另一个结果是极端不希望的情况,称为高锁定争用(请参见左图,其中N个线程争用1x锁定,但由于1 x运行已拥有该锁定而被迫阻塞等待)线。
幸运的是,对于即将出现的HashMap的完全同步,从未真正并发的,隔离=可序列化(和令人失望的)陷阱,我们即将推出的OpenJDK堆外JEP提出了以下建议 :硬件事务存储(HTM)。 使用HTM,用Java编写粗粒度的同步块将再次变得很棒! 只需让HTM通过采用零并发的代码来协助,并在硬件中将其转变为真正并发且100%MT安全的代码即可。 那一定很酷,对吧?
java.util.concurrent.ConcurrentHashMap(线程安全,锁定灵巧但不是“完美”)
随着JDK 1.5的到来,我们Java程序员终于在核心API中找到了梦long以求的java.util.concurrent.ConcurrentHashMap。 尽管CHM不能用作HashMap的通用替代(CHM使用更多资源,并且在低争用情况下可能不合适),但确实解决了其他HashMap无法解决的问题:提供真正的MT安全性和真实性MT并发。 让我们画出CHM到底有何帮助。
- 锁条。

- 为java.util.HashMap的独立子集设置一个锁:N个哈希桶N /段锁。 (右侧的像素,细分为3)
- 当设计雄心勃勃地将高争用锁重构为多个锁而又不损害数据完整性时,锁条将非常有用
- 更好的并发性,非同步解决方案,以解决“先检查后行动”的竞争条件问题
- 问题:如何同时保护整个收藏集? 获取所有锁(递归)?

因此,现在您可能会问:随着ConcurrentHashMap和java.uti.concurrent包的到来,Java最终是一个编程平台, 高性能计算社区可以在该平台上构建解决其问题的解决方案吗?
不幸的是,最现实的答案仍然是“还没有”。 真的,那还有什么问题呢?
CHM有一个与规模和持有中等生命物体有关的问题。 如果使用CHM的关键集合数量很少,则其中一些可能非常大。 在某些情况下,大部分中等寿命的对象都生活在这些集合中。 中寿命对象的问题在于它们对GC暂停时间的贡献最大,并且可能比短期对象贵20倍。 长寿命的对象倾向于留在保管空间中,而短寿命的对象则早逝,但中型的对象会通过所有复制的幸存者空间,并在保管空间中死亡,这使得它们昂贵的复制成本和最终清理成本。 理想情况下,您需要一个可以存储零GC影响的数据的集合。
ConcurrentHashMap元素在运行时在Java VM Heap上运行。 由于CHM处于堆中状态,因此即使不是最重要的情况,也可能是世界停止 (STW)暂停的重要原因。 当发生STW GC事件时,所有应用程序处理都会遭受声名狼藉的“尴尬暂停”延迟。 CHM(及其所有元素)被堆放导致的这种延迟是一种惨痛的经历。 高性能计算社区不会容忍这种经历和问题。

解决方案在精神上非常简单:将CHM取消使用。
而且,此OpenJDK堆外JEP旨在支持的正是这种解决方案。
在深入研究HashMap的堆外生活之前,让我们充分展示堆上不友好的细节。
堆简史
Java堆内存由操作系统分配给JVM。 所有Java对象都是通过其堆上JVM位置/身份来引用的。 运行时对象的堆上引用必须位于两个不同的堆上区域之一中。 这些区域更正式地称为世代 。 具体来说:(1) 年轻 生成(由EDEN和两个SURVIVOR子空间组成)和(2) 持久的 代。 (注意:Oracle宣布Perm Generation将开始在JDK 7中逐步淘汰,并将在JDK 8中被淘汰)。 除非使用“ Azul's Zing ”之类的“少暂停”收集器,否则所有世代都将遭受可怕的“世界停止”完整垃圾收集事件。
在垃圾回收世界中, 操作由“收集器”执行,这些收集器的操作数是堆的“生成”(和子空间)目标。 收集器在Heap Gen / Space目标上运行。 完整垃圾收集工作原理的内部细节是其自己的(非常大的)主题,在其专门的文章中进行了介绍 。
现在就知道这一点:如果在任何一代的堆空间上运行的任何收集器(任何类型)引起了完整的“世界停止”事件-这是一个严重的问题。
这是一个必须解决的问题。
堆外JEP将解决这个问题。
让我们仔细看看。
Java堆布局: 通过世代视图

垃圾收集使编写程序变得更加容易,但是在SLA目标领域(无论是编写还是隐含的)(我的Java Applet都不能停止30秒),Stop-The-World暂停时间令人头疼。 它是如此之大,以至于对于许多Java开发人员来说,这是他们面前唯一的性能问题。 顺便说一下,一旦STW不再是一个问题,还需要解决许多其他性能问题。
使用堆外存储的好处是,中等生命期对象的数量可以大大减少。 它甚至还可以减少短命对象的数量。 对于高频交易系统,一天内创建的垃圾可能少于您的伊甸园大小,这意味着您可以整天运行,而无需收集单个垃圾。 一旦您的内存压力非常低,并且几乎没有对象到达占用空间,则对GC进行调整就变得非常简单。 通常,您甚至不需要设置任何GC参数(除非可能会增加伊甸园大小)
通过将对象移出堆外,Java应用程序通常能够收回控制自己的命运的托管权,从而满足性能SLA的期望和义务。
等待。 最后一句话刚刚说了什么?
注意:所有乘客,请折叠好您的托盘并将座椅直立放置。 这是非常值得重复的,并且是此OpenJDK堆外JEP的主要租户之一。
通过将集合(如HashMap)移出堆外,Java应用程序通常能够收回其托管权(不再受STW GC“令人尴尬的暂停”事件的支配)来控制自己的命运,从而满足性能SLA的期望和义务。
这是一种实用的选择,已经在Java的高频交易系统中使用过。
为了使Java对高性能计算社区保持越来越大的吸引力,此选项也是完全必要的。
堆上的优势
- 熟悉,编写自然的Java代码。 所有有经验的Java开发人员都可以编写此代码。
- 避免出现内存访问问题。
- 自动GC服务–无需自我管理malloc()/ free()操作
- 与Java Lock API和JMM完全就地集成
- 无需序列化/复制数据即可将其添加到结构中。
堆外优势
- 将“ Stop The World” GC事件控制在您满意的水平。
- 可以在规模上胜过堆上结构(当使用堆上的影响足够高时)
- 可以用作本机IPC传输(java.net.Socket不进行IP环回)
- 分配器注意事项:
- NIO DirectByteBuffer到/ dev / shm(tmpfs)映射?
- 还是直接使用sun.misc.Unsafe.malloc()?
HashMap的现状…这个“老狗”现在可以解决哪些新问题(通过淘汰)?
OpenHFT HugeCollections(SHM)简介
“堆”到底在哪里?
下图说明了两个JavaVM进程(PID1和PID2),它们有志于使用SharedHashMap(SHM)作为进程间通信(IPC)工具。 该图的底部水平轴代表整个SHM OS本地域。 在对其进行操作时,OpenHFT对象必须位于OS物理内存的用户地址空间或内核地址空间视图中的某个位置。 深入研究,我们知道它们必须从“处理中”位置开始。 从Linux OS视图来看,JVM是a.out (通过gcc invoke渲染)。 当该a.out运行时,从Linux进程内部视图来看,该运行a.out具有PID。 PID的a.out(在运行时) 具有已知的解剖结构,包含三个部分:
- 文本(低位地址...执行代码的地方)
- 数据(通过sbrk(2)从低地址托管到高地址托管)
- 堆栈(从高地址托管到低地址托管)
那是PID的OS视图。 PID是一个正在执行的JVM,并且JVM对操作数的潜在位置有自己的看法。
从JVM角度看,操作数以On-PID-on-heap(普通Java)或On-PID-off-heap(通过Unsafe或NIO到Linux mmap(2)的桥)形式存在。 无论是堆上On-PID堆上还是堆上On-PID断堆,所有操作数仍在USER地址空间中执行。 在C / C ++中,有可用的API(OS系统调用),这些API允许C ++操作数具有局部性Off-PID-off-heap。 这些操作数位于KERNEL地址空间中。

(点击图片放大)
接下来的6个项目符号参考上图。
#1。 为了更好地利用此图的流程,我们假设 PID 1定义了与 JavaBean兼容的BondVOInterface 。 我们要演示(遵循上面的编号流程)如何突出显示堆外优势的方式对Map <String,BondVOInterface>进行操作。
public interface BondVOInterface {
/* add support for entry based locking */
void busyLockEntry () throws InterruptedException;
void unlockEntry ();
long getIssueDate ();
void setIssueDate ( long issueDate); /* time in millis */
long getMaturityDate ();
void setMaturityDate ( long maturityDate); /* time in millis */
double getCoupon ();
void setCoupon ( double coupon);
// OpenHFT Off-Heap array[ ] processing notice ‘At’ suffix
void setMarketPxIntraDayHistoryAt (@MaxSize( 7 ) int tradingDayHour, MarketPx mPx);
/* 7 Hours in the Trading Day:
* index_0 = 9.30am,
* index_1 = 10.30am,
…,
* index_6 = 4.30pm
*/
MarketPx getMarketPxIntraDayHistoryAt ( int tradingDayHour);
/* nested interface - empowering an Off-Heap hierarchical “TIER of prices”
as array[ ] value */
interface MarketPx {
double getCallPx ();
void setCallPx ( double px);
double getParPx ();
void setParPx ( double px);
double getMaturityPx ();
void setMaturityPx ( double px);
double getBidPx ();
void setBidPx ( double px);
double getAskPx ();
void setAskPx ( double px);
String getSymbol ();
void setSymbol ( String symbol );
}
} PID 1(在上图的步骤1中,使用接口)调用OpenHFT SharedHashMap工厂,可能类似于
SharedHashMap<String, BondVOInterface> shm = new SharedHashMapBuilder()
. generatedValueType (true)
. entrySize ( 512 )
. create (
new File ( "/dev/shm/myBondPortfolioSHM" ),
String. class ,
BondVOInterface. class
);
BondVOInterface bondVO = DataValueClasses. newDirectReference (BondVOInterface. class );
shm. acquireUsing ( "369604103" , bondVO);
bondVO. setIssueDate (parseYYYYMMDD( "20130915" ));
bondVO. setMaturityDate (parseYYYYMMDD( "20140915" ));
bondVO. setCoupon ( 5.0 / 100 ); // 5.0%
BondVOInterface. MarketPx mpx930 = bondVO. getMarketPxIntraDayHistoryAt ( 0 );
mpx930. setAskPx ( 109.2 );
mpx930. setBidPx ( 106.9 );
BondVOInterface. MarketPx mpx1030 = bondVO. getMarketPxIntraDayHistoryAt ( 1 );
mpx1030. setAskPx ( 109.7 );
mpx1030. setBidPx ( 107.6 ); 现在,发生了一些OpenHFT堆→堆外魔术。 仔细观察…对于本文的所有旅行,现在即将分享的“魔术”是这次旅行的最佳“视线”机会:
#2。 上述OpenHFT工厂在每个进程的运行时调用,呈现并编译BondVOInterfacenative 内部实现,需要完全托管来执行必要的字节寻址算法,以证明可传递的声音/完整的堆外abstractAccess()/ abstractMutate()运算符集(通过接口的getXX()/ setXX()Java Bean兼容方法签名)。 所有这些的影响是OpenHFT运行时占用了您的接口并将其编译为一个实现类,该类将充当您通往显式堆外功能的桥梁。 使用索引的getter和setter模拟数组。 阵列的接口也以与外部接口相同的方式生成。 数组的setter和getter签名为setXxxxAt(int index,Type t); 和getXxxxAt(int index); (注意两个数组gettr / settr签名的' At '后缀)。
所有这些都在运行时通过进程内OpenHFT JIT编译器为您呈现。 您要做的就是提供界面。 很酷吧?
#3 。 然后,PID 1调用OpenHFT API的shm.put(K,V); 通过Key(V = BondVOInterface )数据将数据写入堆外SHM。 我们已经跨越了[2]中为我们建立的OpenHFT桥梁。
我们现在堆满了! 风景不错吧? :-)

让我们看一下如何从PID 2的角度来看这里。
#4 。 PID 1完成将其数据放入非堆SHM中后,PID 2现在可以调用完全相同的OpenHFT工厂,例如
SharedHashMap<String, BondVOInterface> shmB = new SharedHashMapBuilder()
. generatedValueType (true)
. entrySize ( 512 )
. create (
new File ( "/dev/shm/myBondPortfolioSHM" ),
String. class ,
BondVOInterface. class
); 开始跨过OpenHFT构建的桥梁的旅程,以获得对完全相同的非OpenHFT SHM的引用。 当然,假定位于同一本地主机OS上的PID 1和PID 2共享/ dev / shm的公共视图(并且具有对相同的/ dev / shm / myBondPortfolioSHM文件视图的优先访问权身份)。
#5。 PID 2然后可以调用V = shm.get(K) ; (每次都会创建一个新的堆外引用)或PID 2可以调用V2 = shm.getUsing(K,V); 它会重用您选择的堆外引用(如果K不是Entry ,则返回NULL)。 由于目前尚未第三GET OpenHFT API中可用于PID 2的签名: V2 = AcquisitionUsing(K,V); 区别在于, K 不是Entry , 则 不会返回NULL-但是,您将返回对新提供的非NULL V2占位符的引用 。 此参考允许PID 2 在就地 SHM的堆外V2 条目 上运行 。
注意:每当PID 2调用V = shm.get(K)时 ; 它返回一个新的堆外引用。 这会产生一些垃圾,但是您必须对此数据进行引用,直到您将其丢弃。 但是,当PID2调用V2 = shm.getUsing(K,V)时; 或V2 = shm.acquireUsing(K,V); ,将堆外引用移至新密钥的位置,并且此操作无需使用GC,因为您可以自己回收所有内容。
注意:此时不会发生任何复制,仅设置或更改了堆外空间中数据的位置。
BondVOInterface bondVOB = shmB. get ( "369604103" );
assertEquals( 5.0 / 100 , bondVOB. getCoupon (), 0.0 );
BondVOInterface. MarketPx mpx930B = bondVOB. getMarketPxIntraDayHistoryAt ( 0 );
assertEquals( 109.2 , mpx930B. getAskPx (), 0.0 );
assertEquals( 106.9 , mpx930B. getBidPx (), 0.0 );
BondVOInterface. MarketPx mpx1030B = bondVOB. getMarketPxIntraDayHistoryAt ( 1 );
assertEquals( 109.7 , mpx1030B. getAskPx (), 0.0 );
assertEquals( 107.6 , mpx1030B. getBidPx (), 0.0 ); #6 。 堆外记录是一个包装字节的引用,用于堆外操作和偏移量。 通过更改这两个位置,可以访问任何内存区域,就好像它是您选择的接口一样。 当PID 2在'shm'引用上运行时,它将设置正确的字节数和偏移量,这是通过读取存储在/ dev / shm文件视图中的哈希图计算得出的。 如果返回getUsing(),则偏移量的计算很简单并且是内联的。 即,一旦对代码进行JIT处理,就可以将get()和set()方法转换为简单的机器代码指令以访问这些字段。 仅读取或写入您访问的字段,才是真正的零复制! 美丽。
//ZERO-COPY
// our reusable, mutable off heap reference, generated from the interface.
BondVOInterface bondZC = DataValueClasses. newDirectReference (BondVOInterface. class );
// lookup the key and give me my reference to the data if it exists.
if (shm. getUsing ( "369604103" , bondZC) != null) {
// found a key and bondZC has been set
// get directly without touching the rest of the record.
long _matDate = bondZC. getMaturityDate ();
// write just this field, again we need to assume we are the only writer.
bondZC. setMaturityDate (parseYYYYMMDD( "20440315" ));
//demo of how to do OpenHFT off-heap array[ ] processing
int tradingHour = 2 ; //current trading hour intra-day
BondVOInterface. MarketPx mktPx = bondZC. getMarketPxIntraDayHistoryAt (tradingHour);
if (mktPx. getCallPx () < 103.50 ) {
mktPx. setParPx ( 100.50 );
mktPx. setAskPx ( 102.00 );
mktPx. setBidPx ( 99.00 );
// setMarketPxIntraDayHistoryAt is not needed as we are using zero copy,
// the original has been changed.
}
}
// bondZC will be full of default values and zero length string the first time.
// from this point, all operations are completely record/entry local,
// no other resource is involved.
// now perform thread safe operations on my reference
bondZC. addAtomicMaturityDate ( 16 * 24 * 3600 * 1000L ); //20440331
bondZC. addAtomicCoupon (- 1 * bondZC. getCoupon ()); //MT-safe! now a Zero Coupon Bond.
// say I need to do something more complicated
// set the Threads getId() to match the process id of the thread.
AffinitySupport. setThreadId ();
bondZC. busyLockEntry ();
try {
String str = bondZC. getSymbol ();
if (str. equals ( "IBM_HY_2044" ))
bondZC. setSymbol ( "OPENHFT_IG_2044" );
} finally {
bondZC. unlockEntry ();
} 重要的是要实现上图中发生的OpenHFT堆←→堆魔术的全部范围。
事实是OpenHFT SHM实现是在步骤#6中在运行时拦截V2的arg-2重载调用= shm.getUsing(K,V); 。 本质上,SHM实现是查询
(
( arg2 instanceof Byteable ) ?
ZERO_COPY :
COPY
)并有资格执行为零复制(通过参考更新)而不是完整的复制(通过可外部化)。
堆外引用功能的关键接口是可字节的。 这允许对引用进行(重新)分配。
public interface Byteable {
void bytes (Bytes bytes, long offset);
} 如果实现自己的支持此方法的类,则可以实现或生成自己的Byteable类。
就目前而言,正如我们所提到的,您可能会被诱惑继续认为“所有这一切都神奇地发生了”。 这里有很多事情会影响这种魔力,而且这一切都是在执行应用程序过程中发生的! 使用运行时编译器(将我的BondVOInterface接口作为输入),OpenHFT内部构件确定接口的源并将其源(再次在过程中)编译为精通OpenHFT的实现类。 如果您不想在运行时生成类,则可以在生成时预先生成并编译它。 然后,OpenHFT内部将该新呈现的实现类加载到可运行的上下文中。 正是在这一点上,然后运行时才物理执行渲染的BondVOInterfacenative内部类的生成方法,以影响到零字节Bytes []记录上的ZERO-COPY运算符功能。 此功能非常零,以至于您在一个线程中执行线程安全操作后,即使该线程在另一个进程中,该线程对另一线程也可见。
您将拥有OpenHFT SHM魔术的精髓:Java现在具有真正的 ZERO-COPY IPC。
阿布拉·卡达布拉!
绩效结果:CHM vs.SHM
在Linux 13.10上,i7-3970X CPU @ 3.50GHz,十六进制核心,32 GB内存。
SharedHashMap -verbose:gc -Xmx 64m

ConcurrentHashMap -verbose:gc -Xmx 30g

当然,导致CHM比SHM慢438%的主要原因是CHM经历了21.8秒的STW GC事件。 但是从SLA的角度来看,对原因进行说明(不对原因进行补救)是不相关的。 从SLA的角度来看,事实是CHM仅慢了438%。 从SLA的角度来看,此测试中的CHM性能令人难以忍受 。
JSR-107自适应:SHM作为(100%可互操作)堆外JCACHE操作数
2014年第二季度,Java社区流程将宣布JSR-107 EG的JCACHE版本-Java缓存标准API / SPI。 JCACHE将为Java Caching社区提供完全与JDBC对Java RDBMS社区相同的服务。 JCACHE的核心和唯一之处是其原始缓存操作数接口javax.cache.Cache <K,V> 。 如果仔细看一下这个Cache API,应该清楚地知道Cache是Map的近乎完美的超集(有一些学上的区别)。 JCACHE的主要目标之一是帮助为一般Java数据局部性,延迟和缓存问题提供可伸缩的(向上扩展和向外扩展)解决方案。 因此,如果JCACHE的中央操作数是Map,并且JCACHE的主要任务之一是解决数据的局部性/延迟问题,那么将OpenHFT的非堆SHM用作JCACHE的主要操作数接口的实现有多完美? 对于某些Java缓存用例,OpenHFT的非SHM野心非常完美。
稍后(请保持坐着),本文将精确分享如何将OpenHFT SHM用作完全JSR-107可互操作的堆外JCACHE操作数。 在此之前,我们首先要弄清javax.cache.Cache接口是java.util.Map接口的功能超集的事实。 我们需要确切地知道“超级集有多大?” …。 因为这将完全影响我们必须完成多少工作才能100%正确地完成,并且100%完全采用SHM作为实现。
-缓存必须提供哪些基本HashMap无法提供的内容?
- 驱逐,到期
- WeakRef,StrongRef(BTW,与堆外缓存实现无关)
- 位置角色(例如Hibernate L2)
- EntryProcessors
- ACID交易
- 事件监听器
- “通读”运算符(同步/异步)
- “写在后面”运算符(同步/异步)
- JGRID参与( JSR-347 )
- JPA参与
-OpenHFT + Infinispan“婚礼日” 计划 (JCACHE仪式)
下图描述了社区驱动的OpenHFT程序员将OpenHFT堆外SHM适配/贡献为完全JSR-107可互操作的JCACHE操作数(社区驱动的开源JCACHE提供程序= RedHat Infinispan )需要进行的少量开发工作。 。
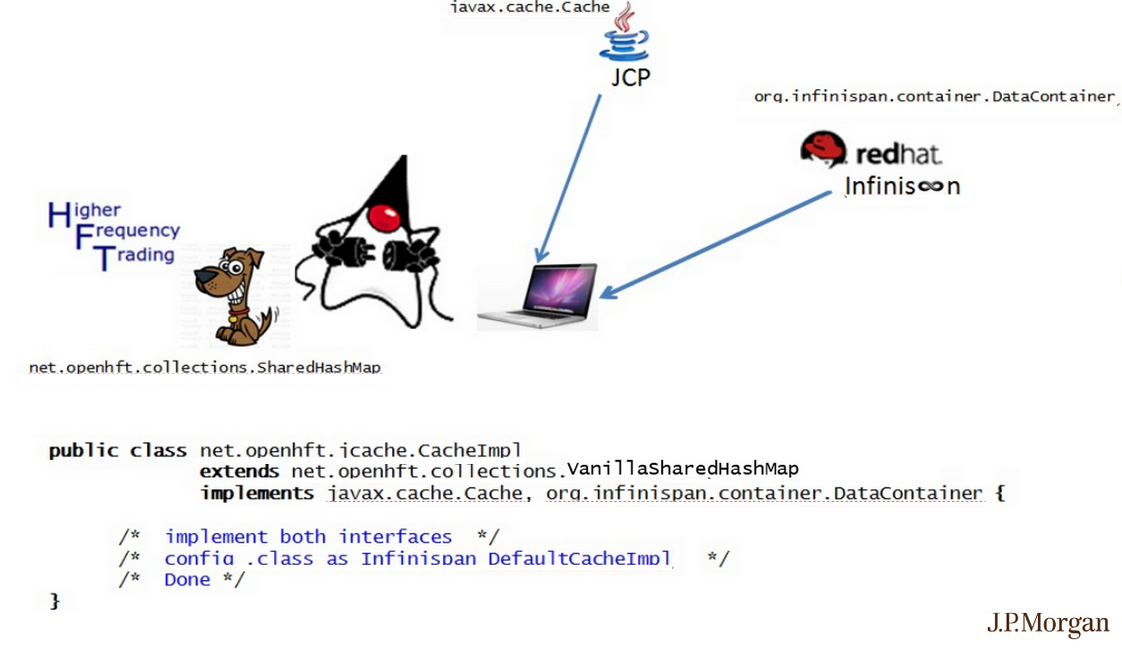
(点击图片放大)
结论:堆外Hashmap…今天,明天,“直到奶牛回家”
当这趟旅程接近其“最后一站”时,我们谨提供离别寓言供您考虑。
社区驱动的开源堆外HashMap提供程序与JCACHE提供程序供应商(专有的和开源的)之间的业务关系可以和谐统一。 每一个在使最终用户的堆外体验变得更愉快方面都起着至关重要的作用。 堆外HashMap提供程序可以交付核心堆外HashMap(作为JCACHE)。 JCACHE供应商(专有的和开放源代码的)可以将该操作数调整到其产品中,然后提供核心的JCACHE运算符(和基础结构)。
这是一种像奶牛的关系(奶农,如果你愿意,核心操作数 =牛奶的生产者)与乳业公司(牛奶operato R SET的生产者= {巴氏灭菌,脱脂,1%,2%,一半-半等)。 (Cows,Dairy Cos。)对一起生产的产品,如果(Cows,Dairy Cos。)对不一起工作,最终用户会享受到更多的产品。 最终用户都需要它们。
但是一个词是“买方当心!” 最终用户注意:
如果有人遇到专有厂商提供封闭源代码外HashMap / Cache解决方案的野心,声称他们的封闭源代码外操作数在某种程度上比开源,社区驱动的方法“更好”,那么,请记住以下几点:
乳制品公司不做牛奶 。 牛做牛奶。
奶牛全天候24/7全天候地制作牛奶,而且焦点完全没有阻碍。 乳制品公司可以使牛奶更令人愉悦(一半,一半,2%,1%脱脂)……因此,他们确实有机会发挥重要作用……但他们没有制造牛奶。 现在,OpenSource的“牛群”正在使堆外的HashMap成为“牛奶”。 如果专有的解决方案供应商认为他们可以使这种牛奶更令人愉悦,那就去做,所有人都欢迎这种努力。 但是,鼓励这些供应商不要试图声称自己的专有牛奶在任何方面都是更好的“牛奶”。 牛是最好的牛奶。
最后,考虑到Java在适应高性能计算社区方面的发展,真是令人兴奋。 事情确实发生了很大变化,一切都变得更好。
从并发包 ,从日益优秀的现代GC解决方案 ,从无阻塞I / O功能,从套接字直接协议的本机RDMA, JVM内部函数 ,等等。 ,一直到本机缓存 ,作为本机IPC传输的 OpenHFT的SHM以及在此OpenJDK堆外JEP中都需要的机器级HTM辅助功能 ,很明显:OpenJDK平台社区确实具有优先考虑提高性能。
只要看看什么是那个可爱的老狗的HashMap 现在能做的! 借助OpenJDK,OpenHFT和Linux,堆外HashMap现在在“低处”(即本机OS)拥有朋友。

HashMap现在受到保护,不受STW GC引起的任何干扰,现在又作为基本的HPC数据结构操作数而诞生。 永远年轻 ,HashMap…永远年轻!
感谢您与我们一起旅行,希望您喜欢这个旅程。 下次再见。
openjdk和jdk















 3079
3079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}