





谷歌去水印java实现
介绍
搜索引擎用户经常因各种原因而拼写错误的搜索词,包括键盘问题(键不起作用),陌生的国际名称(例如Sigmund Freud),意外更改一个字母(Sinpsons)或添加一个字母(Frusciaante)等。 。 Google的搜索引擎包括许多网络用户现在所熟悉的功能-“您是不是要说”-当您可能拼写错误的搜索词时,它会提供其他建议。
文本搜索在包括许多电子商务网站在内的各种应用程序中很常见,通常用于允许客户在产品目录中搜索可用商品。 用户在这里拼错一个术语可能会直接导致销售损失。 例如,假设您经营一家销售DVD的在线商店。 演员阿诺·施瓦辛格(Arnold Schwarzenegger)的粉丝进入您的网站,以购买由演员担任主角的所有DVD。 他的第一个动作是在搜索字段中输入Schwarzenegger的名称,但不幸的是,他拼错了名称,键入“ Arnold Swuazeneger”。 搜索没有返回结果,因此他将浏览器指向另一个商店,然后在该商店再次尝试。
一种解决方案是使用内置的某些领域知识来实现“您的意思是”功能的实现,以便它可以返回“您的意思是Arnold Schwarzenegger”。 在本文中,我们将探索Java中此功能的简单实现。
编辑距离算法
在信息论和计算机科学中,两个字符串之间的编辑距离是将一个字符串转换为另一个字符串所需的操作数。 有几种不同的方法来定义编辑距离,并且有多种算法可用于使用这些各种定义来计算其值。 主要的有Levenshtein,Jaro-Winkler和n-gram。 Jaro-Winkler是Jaro距离度量的一种变体,主要用于记录链接(重复检测)领域。 在Levenshtein算法中,两个字符串之间的距离定义为将一个字符串转换为另一个字符串所需的最小编辑次数,允许的编辑操作为单个字符的插入,删除或替换。 它以弗拉基米尔·莱文斯泰因( Vladimir Levenshtein)的名字命名,他于1965年考虑了这种距离方法。n元语法模型是一种用于预测序列中下一个项目的概率模型,并用于统计自然语言处理和遗传序列分析的各个领域。
出于本文的目的,我们可以使用Apache Lucene沙箱中SpellChecker项目提供的预先存在的实现,而不是从头开始实现算法。
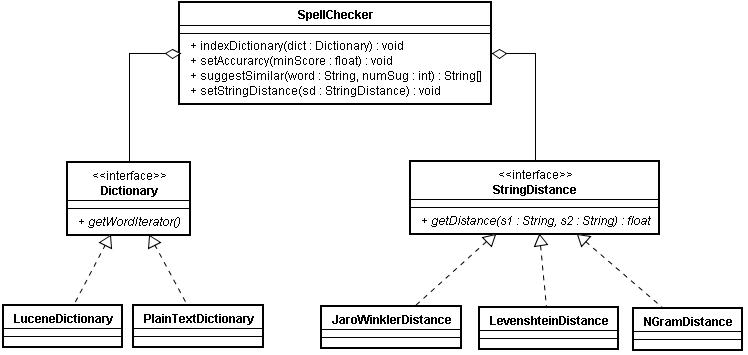
简单来说,Lucene SpellChecker实现包括一个名为SpellChecker的主类,该主类使用目录,字典和三种StringDistance算法之一。 SpellChecker类使用策略模式(GoF)来允许您选择使用哪种StringDistance算法,以及JaroWinklerDistance,LevenshteinDistance和NGramDistance的内置实现,默认为LevenshteinDistance。 您还可以使用0到1之间的默认值0.5调整结果的准确性。 精度设置对结果有重大影响,您可能会发现要设置一个高于默认值的值,但是将其设置得太高可能导致不返回任何结果。 例如,使用我的字典,准确度数为0.749产生了最佳结果。 Dictionary接口有两个直接实现,也允许您实现自己的实现。
对于我们的“您是不是想要的”实现,我们在字典中搜索单词的子集,根据所选的字符串距离算法查找“近”的单词,并且该距离与您定义的精度设置相匹配。 图1显示了Lucene SpellChecker的概述类图。
例
下面是一个简单的代码示例。 要运行它,您将需要Java5或更高版本,lucene-core-3.0.0.jar,lucene-spellchecker-3.0.0.jar和一个名为dictionary.txt的平面文件(简单文本文件,单词之间用行分隔-例如这是在下面)。
//directory creation
//spell checker instantiation
final SpellChecker sp = new SpellChecker(directory);
//index the dictionary
sp.indexDictionary(new PlainTextDictionary(new File("dictionary.txt")));
//your 'wrong' search
String search = "Arnold Swuazeneger";
//number of suggestions
final int suggestionNumber = 5;
//get the suggested words
String[] suggestions = sp.suggestSimilar(search, suggestionNumber);
//show the results.
System.out.println("Your Term:" + search);
for (String word : suggestions) {
System.out.println("Did you mean:" + word);
}
//creating another misspelled search
search = "bava";
suggestions = sp.suggestSimilar(search, suggestionNumber);
System.out.println("Your Term:" + search);
for (String word : suggestions) {
System.out.println("Did you mean:" + word);
} 给定以下dictionary.txt文件:
塞思·麦克法兰
阿诺德·施瓦辛格
斯嘉丽约翰逊
罗德里戈·桑托罗
Java
岩浆
子弹
该程序将输出:
您的字词:arnold swuazeneger
您的意思是:阿诺德·施瓦辛格
您的条款:bava
您的意思是:java
您的意思是:熔岩
你是说:子弹
标杆管理
为了了解性能,我们在具有以下配置的计算机上将示例运行了15次,并取平均值:
操作系统:Windows XP Professional SP3
处理器:Intel Core 2 Duo E6550 @ 2.33GHz
内存:1.96GB
测验
| 测试 | 字数 | 字典大小 | 准确性 | 算法 | 分度时间 | 建议时间 | |
| T1 | 17 | 5 | 0,5 | 莱文施泰因 | 73,0136214 | 25,036049 | |
| T2 | 17 | 81000 | 0,5 | 莱文施泰因 | 3402,293693 | 27,7293112 | |
| T3 | 17 | 5 | 0,5 | 杰罗·温克勒 | 69,53269 | 24,232477 | |
| T4 | 17 | 81000 | 0,5 | 杰罗·温克勒 | 3356,016059 | 26,287849 | |
| T5 | 17 | 81000 | 0,5 | NGram | 3353,633583 | 26,580123 | |
| T6 | 17 | 81000 | 0,9 | 莱文施泰因 | 3325,310027 | 26,96378 | |
| T7 | 17 | 81000 | 0,3 | 莱文施泰因 | 3408,072786 | 24,723142 | |
| T8 | 4 | 81000 | 0,67 | 莱文施泰因 | 3328,584784 | 25,363586 | |
| T9 | 28 | 81000 | 0,67 | 莱文施泰因 | 3354,5943 | 31,284672 |
图形
哪里:
单词大小是单词中字母的数量。
字典是文件中的行数。
精度是通过setAccuracy方法设置的精度。
在这些测试的基础上,我们可以得出结论,精度值对时间的影响很小。 但是,字长很重要-具有四个字符的字会在2ms左右的时间内得到结果。 在测试的三种算法中,NGramDistance比其他算法稍快。 在我的测试中,我还发现JaroWinklerDistance算法产生的结果最不准确。
结论
如您所见,使用预先存在的算法使“您的意思是您的意思”的实现细节非常简单。 然而,在实际情况下,大部分工作将是使用具有特定领域特定术语的字典来构建字典,以支持您的应用程序。
参考资料
- http://lucene.apache.org/java/docs/
- http://today.java.net/pub/a/today/2005/08/09/didyoumean.html
- http://archsofty.blogspot.com/2009/12/adicione-o-recurso-voce-quis-dizer-nas.html
- http://lucene.apache.org/java/3_0_0/api/contrib-spellchecker/index.html
- http://en.wikipedia.org/wiki/Edit_distance
- http://en.wikipedia.org/wiki/Levenshtein_distance
- http://en.wikipedia.org/wiki/Jaro-Winkler_distance
关于作者
Leandro R. Moreira自2002年以来一直是一名软件开发人员,目前担任巴西政府机构的Java开发人员。 他还为包括Jpcsp在内的许多开源项目做出了贡献。 他在Mundo Java上发表了一篇文章-第30期“世界OO:实现内部DS”,并以其母语葡萄牙语维护一个博客 。
谷歌去水印java实现















 1552
1552











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









