






logback配置文件详解


基准测试可帮助您发现Logback在压力下的性能
日志记录对于服务器端应用程序是必不可少的,但这是有代价的。 令人惊讶的是,微小的更改和配置调整对应用程序的日志记录吞吐量有多大影响。 在这篇文章中,我们将根据每分钟的日志条目对Logback的性能进行基准测试。 我们将找出哪些追加程序性能最佳,什么是谨慎模式以及Async方法,筛选和控制台日志记录的一些令人敬畏的副作用是什么。 让我们开始吧。
基准测试的基础
Logback的核心是基于Log4j,并根据CekiGülcü的愿景进行了调整和改进。 或者如他们所说,更好的Log4j 。 它具有本地slf4j API,更快的实现,XML配置,审慎的模式以及一组有用的Appender,我将在稍后详细介绍。
话虽这么说,但是有很多方法可以使用Logback上可用的不同Appender,模式和模式进行记录。 我们采用了一组常用组合,并在10个并发线程上进行了测试,以找出运行速度更快的组合。 每分钟写入的日志条目越多,该方法越有效,并且有更多资源可用于为用户服务。 这不是一门精确的科学,但更精确地说,我们已经对每个测试运行了5次,删除了顶部和底部的异常值,并取了结果的平均值。 为了公平起见,所有写入的日志行也具有相等的200个字符的长度。
**所有代码都可以在GitHub的权利在这里。 该测试在Debian Linux机器上运行,该机器在具有8GB RAM的Intel i7-860(4核@ 2.80 GHz)上运行。
第一个基准:同步日志文件的成本是多少?
首先,我们看一下同步和异步日志记录之间的区别。 既写入单个日志文件,FileAppender均将条目直接写入文件,而AsyncAppender将条目馈入队列,然后写入队列。 默认队列大小为256,当队列大小达到80%时,它将停止输入较低级别的新条目(WARN和ERROR除外)。
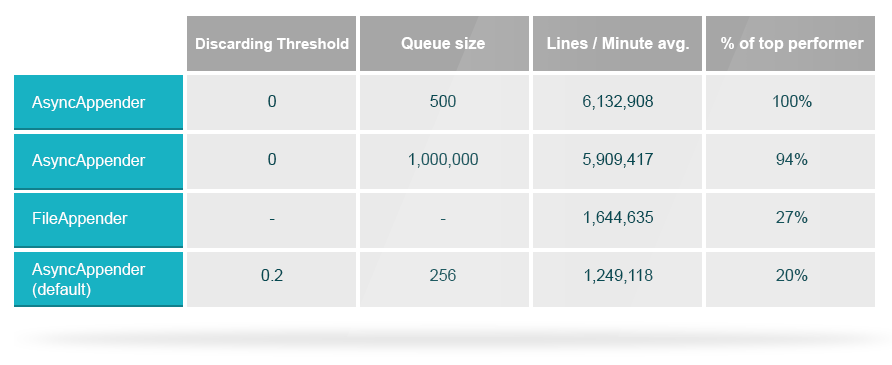

该表在FileAppender和AsyncAppender的不同队列大小之间进行比较。 异步以500个队列大小排在首位。
- 调整#1: AsyncAppender的速度可以比同步FileAppender快3.7倍。 实际上,这是跨所有附加程序记录的最快方法。
它的性能比默认配置要好,该默认配置甚至落后于应该最后完成的同步FileAppender。 那么可能发生了什么?
由于我们是从10个并发线程中写入INFO消息,因此默认队列大小可能太小,消息可能已丢失到默认阈值。 查看500和1,000,000队列大小的结果,您会发现它们的吞吐量相似,因此队列大小和阈值对他们来说不是问题。
- 调整#2:默认的AsyncAppender可能导致性能降低5倍,甚至丢失消息。 确保根据需要自定义队列大小和丢弃阈值。
<appender name="ASYNC500" class="ch.qos.logback.classic.AsyncAppender">
<queueSize>500</queueSize>
<discardingThreshold>0</discardingThreshold>
<appender-ref ref="FILE" />
</appender>**设置AsyncAppender的queueSize并丢弃Threshold
第二个基准:消息模式真的有作用吗?
现在,我们想看看日志输入模式对写入速度的影响。 为了公平起见,即使使用不同的模式,我们也使日志行的长度相等(200个字符)。 默认的Logback条目包括日期,线程,级别,记录器名称和消息,通过尝试使用它,我们试图查看对性能的影响。
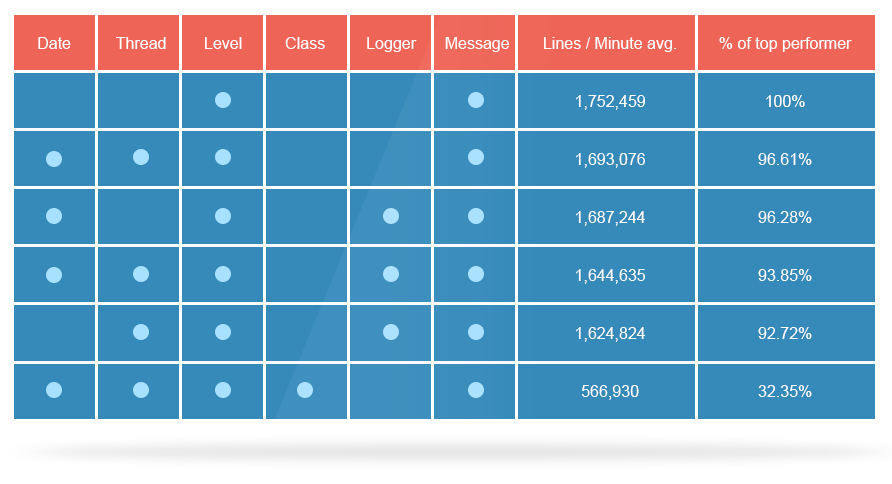
该基准测试演示并帮助您了解记录器命名约定的好处。 只要记住要相应地更改其名称即可使用它。
- 调整#3:按类名命名记录器可将性能提高3倍。
取消记录器或线程名称后,每分钟会增加大约40k-50k条目。 无需编写您将不使用的信息。 最小化也被证明更有效。
- 调整#4:与默认模式相比,仅使用“级别”和“消息”字段每分钟提供了127k多个条目。
第三基准:亲爱的审慎,你不会出来玩吗?
在审慎模式下,可以从多个JVM访问单个日志文件。 由于需要处理另一个锁,因此这当然会影响性能。 我们使用之前运行的相同基准测试了在2个JVM上写入单个文件的谨慎模式。


谨慎模式会如预期般受到打击,尽管我的第一个猜测是影响会更大。
- 调整5:仅在绝对需要时才使用谨慎模式,以避免吞吐量下降。
<appender name="FILE_PRUDENT" class="ch.qos.logback.core.FileAppender">
<file>logs/test.log</file>
<prudent>true</prudent>
</appender>**在FileAppender上配置审慎模式
第四个基准:如何加快同步日志记录?
让我们看看FileAppender以外的同步附加程序如何执行。 ConsoleAppender写入system.out或system.err(默认为system.out),当然也可以通过管道传输到文件。 这就是我们能够计算结果的方式。 SocketAppender通过TCP套接字写入指定的网络资源。 如果目标脱机,则该消息将被丢弃。 否则,它将像在本地生成一样被接收。 对于基准测试,套接字将数据发送到同一台计算机,因此我们避免了网络问题。


令我们惊讶的是,通过FIleAppender进行显式文件访问比编写控制台并将其通过管道传输到文件要昂贵得多。 相同的结果,不同的方法,每分钟增加约200k日志条目。 尽管在两者之间添加了序列化,但SocketAppender的性能与FileAppender相似,但网络资源(如果存在)将承担大部分开销。
- 调整#6:将ConsoleAppender管道传输到文件提供的吞吐量比使用FileAppender高13%。
第五基准:现在我们可以把它提高一个档次吗?
我们工具栏中的另一个有用方法是SiftingAppender。 筛选允许将日志分为多个文件。 我们这里的逻辑是创建4个单独的日志,每个日志保存我们在测试中运行的10个线程中的2或3个日志。 这是通过指示鉴别符(在我们的情况下为logid)来完成的,该鉴别符确定日志的文件名:
<appender name="SIFT" class="ch.qos.logback.classic.sift.SiftingAppender">
<discriminator>
<key>logid</key>
<defaultValue>unknown</defaultValue>
</discriminator>
<sift>
<appender name="FILE-${logid}" class="ch.qos.logback.core.FileAppender">
<file>logs/sift-${logid}.log</file>
<append>false</append>
</appender>
</sift>
</appender>**配置SiftingAppender


我们的FileAppender再次失败了。 输出目标越多,锁的压力就越小,上下文切换也就越少。 与Async示例相同,日志记录的主要瓶颈被证明是正在同步文件。
- 调整#7:使用SiftingAppender可以使吞吐量提高3.1倍。
我们发现实现最高吞吐量的方法是使用自定义的AsyncAppender。 如果必须使用同步日志记录,则最好对结果进行筛选,并按某种逻辑使用多个文件。 我希望您发现Logback基准测试的见解有用,并希望在下面的评论中听到您的想法。
logback配置文件详解















 7115
7115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









