





 本文介绍了如何使iOS应用程序更具辅助功能,特别是通过使用AVAudioEngine进行语音识别。教程涵盖了从请求用户许可到设计用户界面,初始化变量,设置语音识别任务的各个步骤。通过这个过程,开发者可以创建一个类似Siri的语音转文本功能,提升应用的无障碍体验。
本文介绍了如何使iOS应用程序更具辅助功能,特别是通过使用AVAudioEngine进行语音识别。教程涵盖了从请求用户许可到设计用户界面,初始化变量,设置语音识别任务的各个步骤。通过这个过程,开发者可以创建一个类似Siri的语音转文本功能,提升应用的无障碍体验。
开发人员一直在努力使他们的应用程序更高级,但是实际上每个人都可以使用它们吗? 对于大多数应用程序,答案是否定的。 为了吸引最大的受众群体,让我们了解使应用程序更易于访问的方法。
在联合国国际残疾人日的后续活动中 ,让我们看一下如何使我们的iOS应用程序更易于访问。
在本教程中,我们将使用AVAudioEngine转录语音并将其以文本形式显示给用户(就像Siri在iPhone上一样)。
本教程假定您精通Swift,并且熟悉使用Xcode进行iOS开发。
项目设置
为此,您可以在Xcode中创建一个新项目,或者下载此应用程序的示例项目。
如果您正在使用新项目,则将以下行添加到ViewController.swift文件的顶部,以便导入Speech API。
import Speech 开始之前,必须执行的另一步骤是使ViewController()类符合SFSpeechRecognizerDelegate 。
完成后,您就可以开始学习本教程了。
1.寻求许可
由于Apple认真对待隐私,因此在使用设备麦克风之前,他们要求开发人员要求用户许可是有道理的,尤其是因为数据已发送到Apple的服务器进行分析。
在语音识别的情况下,需要权限,因为数据传输和临时存储在苹果的服务器,以提高recognition.-的准确性苹果文档
在您的Xcode项目中,您需要打开Info.plist文件并添加两个键值对。 您可以在其中粘贴以下键:
-
NSMicrophoneUsageDescription -
NSSpeechRecognitionUsageDescription
对于这些值,您可以输入任何能准确描述所需权限以及为什么需要它们的字符串。 添加后,其外观应如下所示:

现在,我们需要先向用户征求许可,然后才能继续。 为此,我们可以简单地调用一个方法,方便地称为requestAuthorization() 。
但是在执行此操作之前,请在您的viewDidLoad()方法内,添加以下代码行:
microphoneButton.isEnabled = false默认情况下,这将使按钮处于禁用状态,因此在应用程序有机会与用户核对之前,用户没有机会按下按钮。
接下来,您需要添加以下方法调用:
SFSpeechRecognizer.requestAuthorization { (status) in
OperationQueue.main.addOperation {
// Your code goes here
}
} 在此方法的完成处理程序中,我们将接收授权状态,然后将其设置为一个名为status的常量。 之后,我们进行了异步调用,该调用将块内的代码添加到主线程中(因为必须在主线程中更改按钮的状态)。
在addOperation块内部,您需要添加以下switch语句以检查授权状态实际上是什么:
switch status {
case .authorized: dictationButton.isEnabled = true
promptLabel.text = "Tap the button to begin dictation..."
default: dictationButton.isEnabled = false
promptLabel.text = "Dictation not authorized..."
} 我们正在打开authorizationStatus()函数的返回值。 如果操作已授权( status为.authorized ),则启用听写按钮,然后点击该按钮以开始听写...。 否则,将禁用听写按钮,并显示未授权听写...。
2.设计用户界面
接下来,我们需要设计一个用户界面以能够执行两件事:启动或停止听写并显示解释后的文本。 为此,请转到Main.storyboard文件。
这是继续本教程所需的三个界面构建器元素:
-
UILabel
-
UITextView -
UIButton
由于放置在此应用程序中并不重要,因此我将不会确切介绍所有位置和放置方式,因此在放置用户界面元素时,请遵循以下基本线框:
作为参考,这是我此时的故事板:
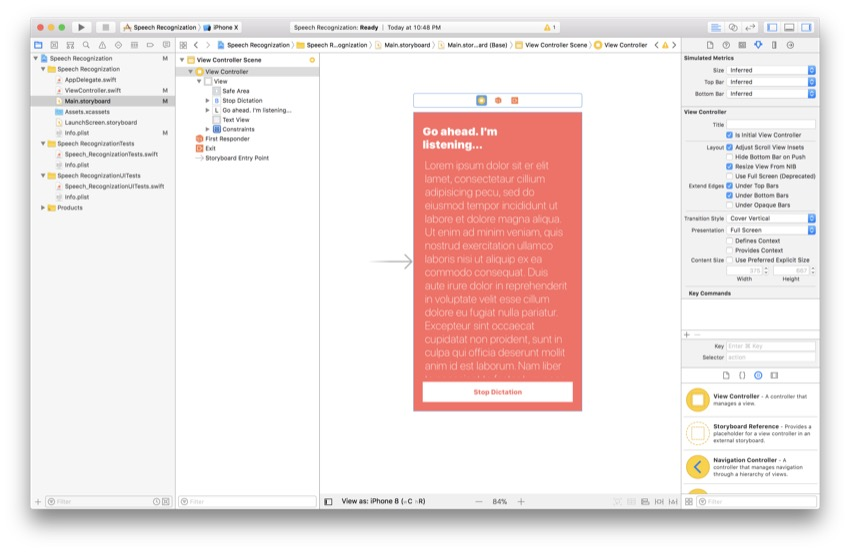
同样,如果布局看起来不同也可以,但是只需确保线框中的三个基本元素相同即可。 现在,将以下代码行粘贴到ViewController()类的顶部:
@IBOutlet var promptLabel: UILabel!
@IBOutlet var transcribedTextView: UITextView!
@IBOutlet var dictationButton: UIButton! 在ViewController()类的底部,只需点击以下命令即可添加以下要触发的功能:
@IBAction func dictationButtonTapped() {
// Your code goes here
}剩下要做的最后一件事是打开助手编辑器 ,并将界面构建器连接连接到Main.storyboard文件。 出现在它们旁边的点现在应该显示为实心,并且您现在可以分别将所有这些元素作为变量和方法来访问。
3.添加变量
现在,我们终于可以开始语音识别了。 第一步是创建适当的变量和常量,我们将在整个过程中使用它们。 在界面构建器出口下方,添加以下代码行:
let audioEngine = AVAudioEngine()
let speechRecognizer = SFSpeechRecognizer(locale: Locale(identifier: "en-US"))!
var request: SFSpeechAudioBufferRecognitionRequest?
var task: SFSpeechRecognitionTask?这是变量和常量的作用的描述:
-
audioEngine是AVAudioEngine()类的实例。 简单来说,此类是一系列音频节点。 音频节点用于处理音频的各种操作,例如生成和处理音频。 -
speechRecognizer是SFSpeechRecognizer()类的实例。 此类无法识别除指定语言以外的任何语言,在这种情况下为美国英语。 -
request是SFSpeechAudioBufferRecognitionRequest类型的可选变量,当前正在初始化为nil。 在本教程的后面,我们将实际创建其中之一并在需要使用它时设置其值。 这将用于识别来自设备麦克风的输入数据。 -
task是另一个可选变量,这次是SFSpeechRecognition类型。 稍后,我们将使用此变量来监视语音识别的进度。
添加变量后,您便拥有了深入语音识别过程所需的一切。
4.宣布听写方法
现在,我们将成为语音识别算法的主要方法。 在viewDidLoad()方法下面,声明以下函数:
func startDictation() {
// Your code goes here
} 由于我们不知道task的当前状态,因此需要取消当前任务,然后将其设置回nil (以防尚未完成)。 这可以通过将以下两行代码添加到您的方法中来完成:
task?.cancel()
task = nil 大! 现在我们知道还没有任务正在运行。 当您使用在方法范围之外声明的变量时,这是重要的一步。 需要注意的一件事是,我们正在使用可选的链接在task上调用cancel() 。 这是一种简洁的编写方式,如果task不是nil,我们只想调用cancel() 。
5.初始化变量
现在,我们必须初始化在本教程前面创建的变量。 要继续,请将以下代码行添加到上一步的startDictation()方法中:
request = SFSpeechAudioBufferRecognitionRequest()
let audioSession = AVAudioSession.sharedInstance()
let inputNode = audioEngine.inputNode
guard let request = request else { return }
request.shouldReportPartialResults = true
try? audioSession.setCategory(AVAudioSessionCategoryRecord)
try? audioSession.setMode(AVAudioSessionModeMeasurement)
try? audioSession.setActive(true, with: .notifyOthersOnDeactivation) 让我们分解一下。 还记得我们之前创建的request变量吗? 代码的第一行使用SFSpeechAudioBufferRecognitionRequest类的实例初始化该变量。
接下来,我们将共享音频会话实例分配给一个名为audioSession的常量。 音频会话的行为就像是应用程序和设备本身(以及音频组件)之间的中间人。
之后,我们将输入节点设置为一个名为inputNode的单例。 要开始录制,我们稍后将在此节点上创建一个tap 。
接下来,我们使用防护来解开我们先前初始化的request变量。 这仅仅是为了避免在应用程序的后面拆开包装。 然后,我们将启用不完整结果的显示。 这类似于在iPhone上执行听写操作-如果您曾经使用过听写功能,您将知道系统会根据自己的想法进行键入,然后使用上下文线索在必要时进行调整。
最后,最后三行代码尝试设置音频会话的各种属性。 这些操作可能会引发错误,因此必须将其标记为try? 关键词。 为了节省时间,我们将忽略任何发生的错误。
现在,我们已经初始化了以前处于nil状态的大多数变量。 最后一个要初始化的变量是task变量。 我们将在下一步中进行操作。
6.初始化任务变量
此变量的初始化将需要完成处理程序。 将以下代码粘贴到startDictation()方法的底部:
task = speechRecognizer.recognitionTask(with: request, resultHandler: { (result, error) in
guard let result = result else { return }
self.transcribedTextView.text = result.bestTranscription.formattedString
if error != nil || result.isFinal {
self.audioEngine.stop()
self.request = nil
self.task = nil
inputNode.removeTap(onBus: 0)
}
}) 首先,我们创建一个以request为参数的recognitionTask 。 第二个参数是一个定义结果处理程序的闭包。 result参数是SFSpeechRecognitionResult的实例。 在此完成处理程序中,我们需要再次解开结果变量。
接下来,我们将文本视图的文本设置为该算法可以提供的最佳转录。 这不一定是完美的,但这是算法认为最适合所听到的内容的。
最后,在此if语句内,我们首先检查是否有错误,或者结果是否已完成。 如果其中任何一个正确,音频引擎和其他相关过程将停止,我们将删除tap 。 别担心,您将在下一步中了解水龙头!
7.启动音频引擎
终于,您一直在等待的时刻! 我们终于可以启动花了这么长时间创建的引擎。 我们将通过安装“ tap”来实现。 在task初始化下添加以下代码:
let recordingFormat = inputNode.outputFormat(forBus: 0)
inputNode.installTap(onBus: 0, bufferSize: 1024, format: recordingFormat) { (buffer, when) in
self.request?.append(buffer)
} 在这段代码中,我们将输入节点的输出格式设置为一个称为recordingFormat的常量。 在下一步中将其用于在输入节点上安装音频tap以记录和监视音频。 在完成处理程序内部,我们将PCM格式的buffer添加到识别请求的末尾。 要启动引擎,只需添加以下两行代码:
audioEngine.prepare()
try? audioEngine.start()这只是准备,然后尝试启动音频引擎。 现在,我们需要从按钮中调用此方法,因此让我们在下一步中进行操作。
8.禁用和启用按钮
除非可以使用,否则我们不希望用户能够激活语音识别,否则,该应用程序可能会崩溃。 我们可以通过委托方法来做到这一点,因此在startDictation()方法声明下面添加以下几行代码:
func speechRecognizer(_ speechRecognizer: SFSpeechRecognizer, availabilityDidChange available: Bool) {
if available {
dictationButton.isEnabled = true
} else {
dictationButton.isEnabled = false
}
}语音识别器不可用后可用或语音可用后不可用时,将调用此方法。 在其中,我们将仅使用if语句根据可用性状态启用或禁用按钮。
禁用该按钮后,用户将看不到任何内容,但该按钮将不响应轻击。 这是一种安全网,可防止用户过快按下按钮。
9.响应按钮点击
剩下要做的最后一件事是当用户点击按钮时做出响应。 在这里,我们还可以更改按钮的内容,并告诉用户他们需要做什么。 为了刷新您的记忆,这是我们之前做的@IBAction :
@IBAction func dictationButtonTapped() {
// Your code goes here
}在此函数内部,添加以下if语句:
if audioEngine.isRunning {
dictationButton.setTitle("Start Recording", for: .normal)
promptLabel.text = "Tap the button to dictate..."
request?.endAudio()
audioEngine.stop()
} else {
dictationButton.setTitle("Stop Recording", for: .normal)
promptLabel.text = "Go ahead. I'm listening..."
startDictation()
}如果音频引擎已经在运行,我们希望停止语音识别并向用户显示适当的提示。 如果未运行,则需要启动识别并显示选项,以使用户停止听写。
结论
而已! 您已经创建了一个可以识别您的声音并将其转录的应用。 它可以用于各种应用程序,以帮助无法以其他方式与您的应用程序进行交互的用户。 如果您喜欢本教程,请务必查看本系列的其他教程!
翻译自: https://code.tutsplus.com/tutorials/accessibility-for-ios-apps-speech-recognition--cms-30045


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









