





这是Ashley Davis的《 数据与JavaScript争吵》一书第11章的摘录,该书现在可在Manning Early Access Program上找到 。 我绝对喜欢这个想法,因为网络上有太多数据可视化内容,它们依赖于功能齐全的客户端JavaScript和更多的API调用。 它不像它可能的那样健壮,可访问或可合成。 如果将数据可视化带回服务器,则可以为聚会带来逐步的增强。 所有示例代码和数据都可以在GitHub上找到。
在Node.js中进行探索性编码或数据分析时,能够根据我们的数据呈现可视化效果非常有用。 如果我们使用基于浏览器JavaScript,则可以从众多图表,图形和可视化库中选择任何一种。 不幸的是,在Node.js下,我们没有任何可行的选择,那么如何才能做到这一点呢?
我们可以尝试在Node.js下伪造DOM之类的方法,但是我找到了一种更好的方法。 我们可以使用无头浏览器使基于浏览器的可视化库在Node.js下为我们工作。 这是没有用户界面的浏览器。 您可以将其视为不可见的浏览器。
我使用Node.js下的Nightmare捕获可视化为PNG和PDF文件,并且效果非常好!
无头浏览器
当我们想到网络浏览器时,通常会想到在浏览网络时每天与之交互的图形软件。 通常,我们直接与这样的浏览器进行交互,用肉眼对其进行查看,并使用鼠标和键盘对其进行控制,如图1所示。
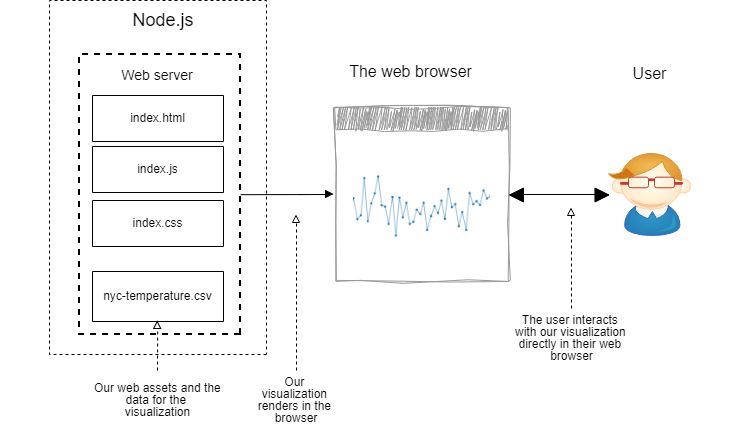
另一方面,无头浏览器是一种Web浏览器,它没有图形用户界面,也没有直接的方式可供我们控制。 您可能会问,我们无法直接查看或与之交互的浏览器有什么用途。
好吧,作为开发人员,我们通常会使用无头浏览器来自动化和测试网站。 假设您已经创建了一个网页,并且想要对其进行一套自动化测试以证明其可以正常工作。 测试套件是自动化的,这意味着它是由代码控制的,这意味着我们需要从代码驱动浏览器。
我们使用无头浏览器进行自动化测试,因为我们不需要直接查看被测试的网页或与之交互。 无需查看正在进行的这种自动化测试,我们只需要知道测试是否通过或失败即可;如果失败了,我们想知道为什么 。 确实,对于被测浏览器具有GUI实际上会阻碍连续集成或连续部署服务器,在该服务器中许多此类测试可以并行运行。
因此,无头浏览器通常用于自动测试我们的网页,但它们对于捕获基于浏览器的可视化并将其输出为PNG图像或PDF文件也非常有用。 为了完成这项工作,我们需要一个Web服务器和一个可视化文件,然后必须编写代码以实例化无头浏览器并将其指向我们的Web服务器。 然后,我们的代码指示无头浏览器获取网页的屏幕截图,并将其作为PNG或PDF文件保存到我们的文件系统中。
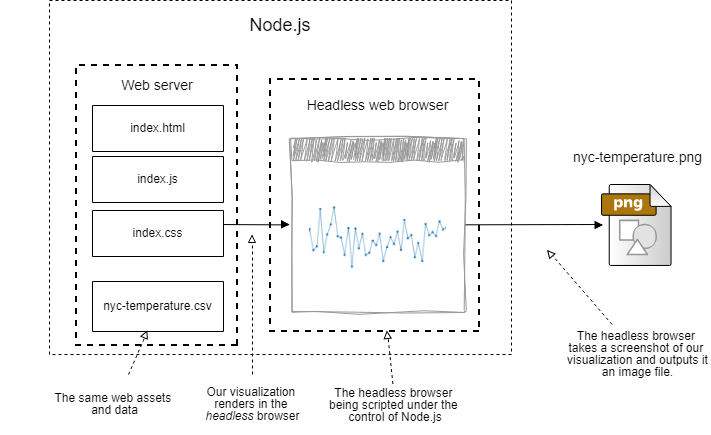
噩梦是我选择的无头浏览器。 它是在Electron上构建的Node.js库(通过npm安装)。 Electron是通常用于构建基于Web技术的跨平台桌面应用程序的框架。
为什么做噩梦?
它被称为梦,,但绝对不是要使用的梦m。 实际上,它是我使用过的最简单,最方便的无头浏览器。 它自动包含Electron,因此要开始使用,只需将Nightmare安装到Node.js项目中,如下所示:
npm install --save nightmare这就是我们安装Nightmare所需要的,我们可以立即从JavaScript中开始使用它!
噩梦几乎包含了我们所需的一切:带有嵌入式无头浏览器的脚本库。 它还包括用于从Node.js控制无头浏览器的通信机制。 在大多数情况下,它是无缝的并且与Node.js很好地集成在一起。
Electron建立在Node.js和Chromium之上,并由GitHub维护,是许多流行的桌面应用程序的基础。
我选择在任何其他无头浏览器上使用Nightmare的原因如下:
- 电子非常稳定。
- 电子具有良好的性能。
- 该API简单易学。
- 没有复杂的配置(只需开始使用它即可)。
- 它与Node.js很好地集成在一起。
噩梦和电子
当您通过npm安装Nightmare时,它会自动带有Electron的嵌入式版本。 因此,可以说,噩梦不仅仅是控制无头浏览器的库,它实际上是无头浏览器。 这是我喜欢梦Night的另一个原因。 在其他一些无头浏览器中,控件库是独立的,或者比这更糟,它们根本没有Node.js控件库。 在最坏的情况下,您必须使用自己的通信机制来控制无头浏览器。
噩梦使用Node.js child_process模块创建Electron流程的实例。 然后,它使用进程间通信和自定义协议来控制Electron实例。 关系如图3所示。
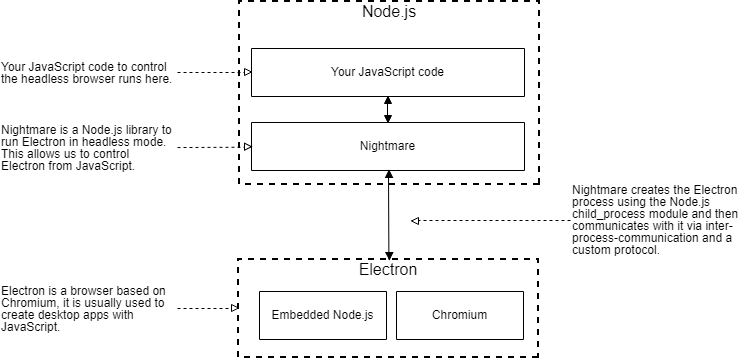
我们的过程:使用噩梦捕获可视化
那么将可视化图像捕获到图像文件的过程是什么? 这是我们的目标:
- 采集数据。
- 启动本地Web服务器以承载我们的可视化
- 将我们的数据注入Web服务器
- 实例化无头浏览器并将其指向我们的本地Web服务器
- 等待可视化显示
- 将可视化的屏幕截图捕获到图像文件
- 关闭无头浏览器
- 关闭本地Web服务器
准备可视化以进行渲染
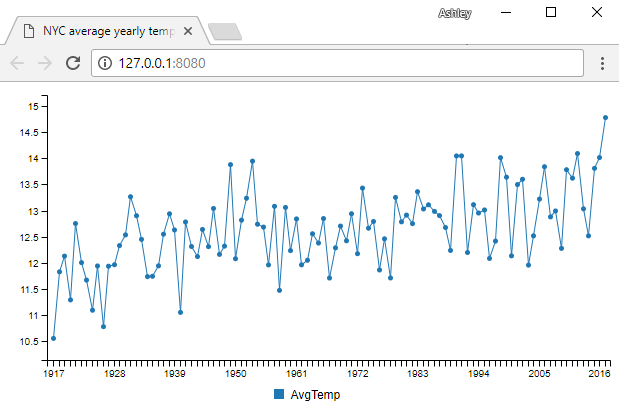
我们需要的第一件事是进行可视化。 图4显示了我们将使用的图表。 此图为过去200年纽约市的年平均气温。
要运行此代码,您需要安装Node.js。 对于第一个示例,我们还将使用实时服务器(任何Web服务器都可以使用)来测试可视化效果(因为我们尚未创建Node.js Web服务器),请按如下所示安装实时服务器:
npm install -g live-server然后,您可以克隆此博客文章的示例代码存储库:
git clone https://github.com/Data-Wrangling-with-JavaScript/nodejs-visualization-example现在进入存储库,安装依赖项并使用live-server运行示例
cd nodejs-visualization-example/basic-visualization
bower install
live-server当运行实时服务器时,浏览器应该会自动打开,您应该看到图4中的图表。
在尝试在无头浏览器中捕获可视化效果之前,最好先检查一下它是否可以在浏览器中直接运行。 可能很容易出问题,在真正的浏览器中比在无头浏览器中解决问题要容易得多。 实时服务器具有内置的实时重新加载功能,因此,在尝试在Node.js下捕获图表之前,您可以在此处进行交互式编辑和改进图表时,在这里有了一个不错的设置。
这个简单的折线图是使用C3构建的。 请看一下示例代码,或者看一下C3库中的一些示例,以了解有关C3的更多信息。
启动网络服务器
要托管我们的可视化,我们需要一个Web服务器。 拥有Web服务器还远远不够,我们还需要能够动态启动和停止它。 清单1显示了我们的Web服务器的代码。
清单1 –一个可以启动和停止的简单Web服务器的代码
const express = require('express');
const path = require('path');
module.exports = {
start: () => { // Export a start function so we can start the web server on demand.
return new Promise((resolve, reject) => {
const app = express();
const staticFilesPath = path.join(__dirname, "public"); // Make our 'public' sub-directory accessible via HTTP.
const staticFilesMiddleWare = express.static(staticFilesPath);
app.use('/', staticFilesMiddleWare);
const server = app.listen(3000, err => { // Start the web server!
if (err) {
reject(err); // Error occurred while starting web server.
}
else {
resolve(server); // Web server started ok.
}
});
});
}
}清单1中的代码模块导出了一个启动函数,我们可以调用该启动函数来启动Web服务器。 能够启动和停止我们的Web服务器的这项技术对于在网站上进行自动化集成测试也非常有用。 假设您要启动Web服务器,对其进行一些测试,然后最后将其停止。
因此,现在我们有了基于浏览器的可视化效果,并且有了可以按需启动和停止的Web服务器。 这些是我们捕获服务器端可视化所需的原始要素。 让我们将它与噩梦混在一起!
将网页渲染为图像
现在,让我们充实代码以使用Nightmare捕获可视化的屏幕截图。 清单2显示了实例Nightmare的代码,将其指向我们的Web服务器,然后获取屏幕截图。
清单2 –使用噩梦将图表捕获到图像文件中
const webServer = require('./web-server.js');
const Nightmare = require('nightmare');
webServer.start() // Start the web server.
.then(server => {
const outputImagePath = "./output/nyc-temperatures.png";
const nightmare = new Nightmare(); // Create the Nightmare instance.
return nightmare.goto("http://localhost:3000") // Point the browser at the web server we just started.
.wait("svg") // Wait until the chart appears on screen.
.screenshot(outputImagePath) // Capture a screenshot to an image file.
.end() // End the Nightmare session. Any queued operations are completed and the headless browser is terminated.
.then(() => server.close()); // Stop the web server when we are done.
})
.then(() => {
console.log("All done :)");
})
.catch(err => {
console.error("Something went wrong :(");
console.error(err);
}); 请注意goto函数的使用,这实际上是指示浏览器加载可视化文件的功能。
网页通常需要一些时间才能加载。 可能不会花很长时间,尤其是当我们正在运行本地Web服务器时,但是仍然面临着在无头浏览器进行初始绘制之前或期间拍摄其截图的危险。 这就是为什么我们必须调用wait函数来等待,直到图表的<svg>元素出现在浏览器的DOM中,然后才调用屏幕截图函数。
最终,将调用end函数。 到目前为止,我们已经有效地构建了要发送到无头浏览器的命令列表。 最终功能实际上将命令发送到浏览器,浏览器获取屏幕截图并输出文件nyc-temperatures.png 。 捕获图像文件后,我们通过关闭Web服务器来完成操作。
您可以在回购中的capture-visualization子目录下找到完整的代码。 进入子目录并安装依赖项:
cd nodejs-visualization-example/capture-visualization
cd public
bower install
cd ..
npm install
live-server现在,您可以自己尝试代码:
node index.js这摘自Manning Early Access计划上现在提供的使用JavaScript进行数据整理的第11章。 请使用此折扣代码fccdavis3享受37%的折扣。 请检查数据争吵者,以获取有关该书的新更新。
翻译自: https://css-tricks.com/server-side-visualization-with-nightmare/















 1090
1090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









