







Phi-3
论文
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
模型结构
基于transformer结构
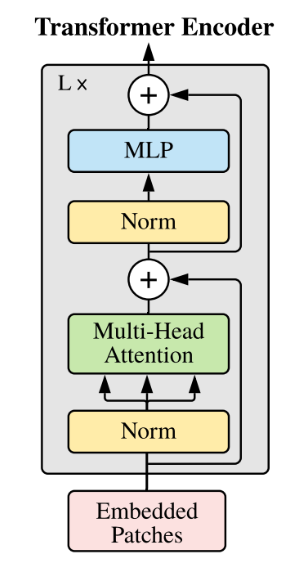
算法原理
Phi-3 模型是目前功能最强大、性价比最高的小型语言模型 (SLM),在各种语言、推理、编码和数学基准测试中,其表现优于同等规模和下一个规模的模型。此版本扩大了客户的高质量模型选择范围,为他们编写和构建生成式 AI 应用程序提供了更多实用选择。
环境配置
-v 路径、docker_name和imageID根据实际情况修改
Docker(方法一)
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
docker run -it --network=host --privileged=true --name=docker_name --device=/dev/kfd --device=/dev/dri --ipc=host --shm-size=32G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro imageID /bin/bash
cd /your_code_path/phi-3_pytorch
pip install -r requirements.txt
Dockerfile(方法二)
cd ./docker
docker build --no-cache -t phi-3:latest .
docker run -it --network=host --privileged=true --name=docker_name --device=/dev/kfd --device=/dev/dri --ipc=host --shm-size=32G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro imageID /bin/bash
cd /your_code_path/phi-3_pytorch
pip install -r requirements.txt
Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装。
DTK驱动:dtk24.04.1
python:3.10
torch:2.1
vllm: 0.3.3
Tips:以上dtk驱动、python等DCU相关工具版本需要严格一一对应
其它非深度学习库参照requirements.txt安装:
pip install -r requirements.txt
数据集
暂无
训练
暂无
推理
# 指定显卡
export HIP_VISIBLE_DEVICES=0
python inference.py --model_path /path/of/model
result

精度
暂无
应用场景
算法类别
多轮对话
热点应用行业
家居,教育,科研
预训练权重
- Phi-3-mini-4k-instruct
- Phi-3-mini-128k-instruct
- Phi-3-small-8k-instruct
- Phi-3-small-128k-instruct
- Phi-3-medium-4k-instruct
- Phi-3-medium-128k-instruct

















 140
140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











