









决策树
决策树
1. 决策树概述
2. 数据集的熵计算
3. 分割数据集 Splitting the dataSet
程序说明:4. 选择分割后的数据集中的最佳特征代码说明
5. 构建决策树
1. 决策树概述
-
优点:计算上使用便宜,人类易于理解学习结果,缺少值可以,可以处理不相关的特征
-
缺点:容易过度拟合使用:数值,名义值
要构建决策树,需要对数据集做出第一个决定,以指定用于拆分数据的功能。要确定这一点,您可以尝试每个功能并测量哪个分割可以获得最佳效果。之后,您将数据集拆分为子集。 然后子集将遍历第一个决策节点的分支。如果分支上的数据是同一个类,那么您已正确分类它,不需要继续拆分它。如果数据不相同,则需要在此子集上重复拆分过程。关于如何拆分此子集的决定与原始数据集的完成方式相同,并重复此过程,直到您对所有数据进行分类。
函数:createBranch():伪代码
Check if every item in the dataset is in the same class: If so return the class label Else find the best feature to split the data split the dataset create a branch node for each split call createBranch and add the result to the branch node return branch node
决策树的一般方法:
1.收集:任何方法。 2.准备:此树构建算法仅适用于标称值,因此需要量化任何连续值。 3.分析:任何方法。构建后,您应该直观地检查树。 4.培训:构建树数据结构。 5.测试:使用学习树计算错误率。 6.使用:这可以用于任何监督学习任务。通常,树木用于更好地理解数据。
熵与信息熵说明:
用熵来表示信息的复杂度,熵越大,则信息越复杂。公式如下:
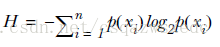
信息增益(information gain),表示两个信息熵的差值。 首先计算未分类前的熵,总共有8位同学,男生3位,女生5位。 熵(总)=-3/8log2(3/8)-5/8log2(5/8)=0.9544 接着分别计算同学A和同学B分类后信息熵。 同学A首先按头发分类,分类后的结果为:长头发中有1男3女。短头发中有2男2女。 熵(同学A长发)=-1/4log2(1/4)-3/4log2(3/4)=0.8113 熵(同学A短发)=-2/4log2(2/4)-2/4log2(2/4)=1 熵(同学A)=4/80.8113+4/81=0.9057 信息增益(同学A)=熵(总)-熵(同学A)=0.9544-0.9057=0.0487 同理,按同学B的方法,首先按声音特征来分,分类后的结果为:声音粗中有3男3女。声音细中有0男2女。 熵(同学B声音粗)=-3/6log2(3/6)-3/6log2(3/6)=1 熵(同学B声音粗)=-2/2log2(2/2)=0 熵(同学B)=6/81+2/8*0=0.75 信息增益(同学B)=熵(总)-熵(同学A)=0.9544-0.75=0.2087
按同学B的方法,先按声音特征分类,信息增益更大,区分样本的能力更强,更具有代表性。
2. 数据集的熵计算
from math import log
def calShannonEnt(dataSet):
numEntries=len(dataSet)
labelCount={}
for featVec in dataSet:
currentLabel=featVec[-1]
if currentLabel not in labelCount.keys():
labelCount[currentLabel]=0
labelCount[currentLabel]+=1
shannonEnt=0.0
for key in labelCount:
prob=float(labelCount[key])/numEntries
shannonEnt=-prob*log(prob,2)
return shannonEnt
代码很简单。
-
首先,计算数据集中实例数的计数。这可能是内联计算的,但它在代码中多次使用,因此为它创建了一个显式变量。
-
接下来,您将创建一个字典,其键是最后一列中的值。如果先前未遇到密钥,则创建一个密钥。对于每个键,您可以跟踪此标签出现的次数。
-
最后,使用所有不同标签的频率来计算该标签的概率。该概率用于计算香农熵,
-
你总结了所有的标签。让我们试试这个熵的东西吧。
#创建数据集和标签如下:
dataSet = [[1, 1, 'maybe'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
labels = ['no surfacing','flippers']
#计算给定数据集香农熵的calcShannonEnt()函数要复杂些,一行一行地来
from math import log #从数学计算模块math模块中导入对数计算方法log
numEntries = len(dataSet) #获取数据集dataSet的长度,为5
labelCounts = {} #新建一个空字典labelCounts,用以统计每个标签出现的次数,进而计算概率
for featVec in dataSet: #the the number of unique elements and their occurance
currentLabel = featVec[-1]
#print currentLabel #打印出可知featVec[-1]获取了daatSet中最后一列的数值,作为字典中的key(标签)
if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1 #以currentLabel作为key加入到字典labelCounts里,存在则对应value+1
print (labelCounts)
shannonEnt = 0.0 #建立变量shannonEnt用以计算香农熵
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
#print "prob=",prob #计算分类概率prob=标签发生频率labelCounts[key]除以数据集长度numEntries
shannonEnt -= prob * log(prob,2) #log base 2,以2为对数
#print shannonEnt
print ("shannonEnt(香农熵)= ",shannonEnt) #每次shannonEnt自相加,最后得到了香农熵,搞定
3. 分割数据集 Splitting the dataSet
划分数据集的splitDataSet()函数,关键要理解这个函数的是作用是当我们按某个特征划分数据集时,把划分后剩下的元素抽取出来,形成一个新的子集,用于计算条件熵。
dataSet = [[1, 1, 'maybe'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']] labels = ['no surfacing','flippers'] #标签好像暂时没什么用 #书中给出splitDataSet()函数的代码如下: def splitDataSet(dataSet, axis, value): # 输入的参数分别为:待划分的数据集,划分数据集的特征,需要返回的特征的值 retDataSet = [] # python语言方法中传递的是列表的引用,为了不改变源数据,所以用一个新的变量来存储返回结果 for featVec in dataSet: #遍历数据集dataSet if featVec[axis] == value: #当第axis个特征的值等于value时 #print 'featVec=',featVec #打印出变量分析 #print 'featVec[axis]=',featVec[axis] #打印出变量分析 reducedFeatVec = featVec[:axis] #将符合特征的数据抽取出来,[:axis]表示前axis行,即若axis为2,就是取featVec的前axis行 #print 'featVec[:axis]=',reducedFeatVec #打印出变量分析 reducedFeatVec.extend(featVec[axis+1:]) #[axis+1:]表示从跳过axis+1行,取接下来的数据 #print 'featVec[axis+1:]=',featVec[axis+1:] #打印出变量分析 retDataSet.append(reducedFeatVec) #把reducedFeatVec抽取出来的元素加到列表retDataSet里 return retDataSet #返回列表retDataSet
#调用splitDataSet()函数测试下,当特征为0的时候,我们希望返回特征值为1的对象 splitDataSet(dataSet, 0, 1) #splitDataSet(dataSet, 0, 1)
程序说明:
您每次都创建一个新列表,因为您将在同一数据集上多次调用此函数,并且您不希望修改原始数据集。我们的数据集是列表清单;
迭代列表中的每个项目,如果它包含您要查找的值,您将把它添加到新创建的列表中。在if语句中,您删除了拆分的功能。
4. 选择分割后的数据集中的最佳特征
chooseBestFeatureToSplit()函数能选出划分数据集最好的特征,也就是说用该特征划分数据集dataSet,能使信息增益最大(信息增益表示得知特征X的信息而使类Y的信息的熵减少的程度),ID3算法:从根节点开始,计算所有可能的特征的信息增益,选择信息增益最大的特征作为当前节点的特征,由特征的不同取值建立空白子节点,对空白子节点递归调用此方法,直到所有特征的信息增益小于阀值或者没有特征可选为止。
#chooseBestFeatureToSplit()函数能选出划分数据集最佳的特征,也就是说用该特征划分数据集dataSet,使信息增益最大 def chooseBestFeatureToSplit(dataSet): numFeatures = len(dataSet[0]) - 1 #the last column is used for the labels,获取分类长度 #print 'numFeatures',numFeatures #print 'dataSet',dataSet baseEntropy = calcShannonEnt(dataSet) #获取数据集dataSet的香农熵 #print "baseEntropy",baseEntropy bestInfoGain = 0.0; bestFeature = -1 #初始化 for i in range(numFeatures): #遍历数据集中特征 featList = [example[i] for example in dataSet] #用列表表达式创建列表featList,抽取第i个特征所有可能值放入这个列表中 #print "featList",featList uniqueVals = set(featList) #从特征列获取该特征的特征值的set集合 #print "uniqueVals",uniqueVals newEntropy = 0.0 #初始化newEntropy for value in uniqueVals: #从每行中去掉上边抽取的相应第i个特征,计算信息熵 subDataSet = splitDataSet(dataSet, i, value) #print 'subDataSet',subDataSet prob = len(subDataSet)/float(len(dataSet)) #print 'prob',prob newEntropy += prob * calcShannonEnt(subDataSet) #这计算条件信息熵 #print 'newEntropy',newEntropy infoGain = baseEntropy - newEntropy #计算得到最大的信息熵,并将选择的最佳的特征划分返回 if (infoGain > bestInfoGain): #compare this to the best gain so far bestInfoGain = infoGain #if better than current best, set to best bestFeature = i return bestFeature #returns an integer
#重新创建数据测试下 myDat,labels=createDataSet() #选出最好的划分特征 chooseBestFeatureToSplit(myDat)
代码说明
我们对数据做了一些假设。
-
第一个假设是它以列表的形式出现,所有这些列表的大小相同。
-
下一个假设是数据中的最后一列或每个实例中的最后一项是该实例的类标签。
-
您可以在函数的第一行中使用这些假设来查找给定数据集中可用的特征数量。我们没有对列表中的数据类型做出任何假设。它可以是数字或字符串;
5. 构建决策树
您现在拥有了创建算法所需的所有组件,该算法可以从数据集中创建决策树。
工作原理:您从我们的数据集开始,并根据要分割的最佳属性将其拆分。这些不是二叉树,因此您可以处理多个双向分割。一旦拆分,数据将遍历树的分支到另一个节点。然后,该节点将再次拆分数据。您将使用递归原理来处理此问题。 停止条件:用尽要拆分的属性或分支中的所有实例都是同一个类。如果所有实例都具有相同的类,那么您将创建叶节点或终止块。到达该叶节点的任何数据都被认为属于该叶节点的类。 第一个停止条件使这个算法易于处理,你甚至可以设置你可以拥有的最大分割数量的界限。稍后您将遇到其他决策树算法,例如C4.5和CART。这些不会“消耗”每次拆分时的功能。















 415
415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









