







配置Hadoop环境
1、下载openssh包
URL:
http://www.openssl.org/source/openssl-1.0.2a.tar.gz
安装ssl
2、下载openssh
http://www.openssh.com/openbsd.html

虚拟机和宿主机可以ping通
配置静态IP
在VM > settings > network中可以看出我使用的是VMWare默认的NAT方式(这儿解释为:使用NAT可以使虚拟机和宿主机可以相互ping,其他主机无法ping虚拟机),使用这种确实无须HOST和VM使用同一网段IP却仍能做到相互ping通。
6、视频安装Hadoop
步骤:
关闭防火墙
修改ip
修改hostname
设置ssh自动登录
安装jdk
安装Hadoop
开始安装
关闭防火墙
2.启用
sudo ufw enable
sudo ufw default deny
运行以上两条命令后,开启了防火墙,并在系统启动时自动开启。关闭所有外部对本机的访问,但本机访问外部正常。
sudo ufw enable|disable
2、配置SSH无密码登录:
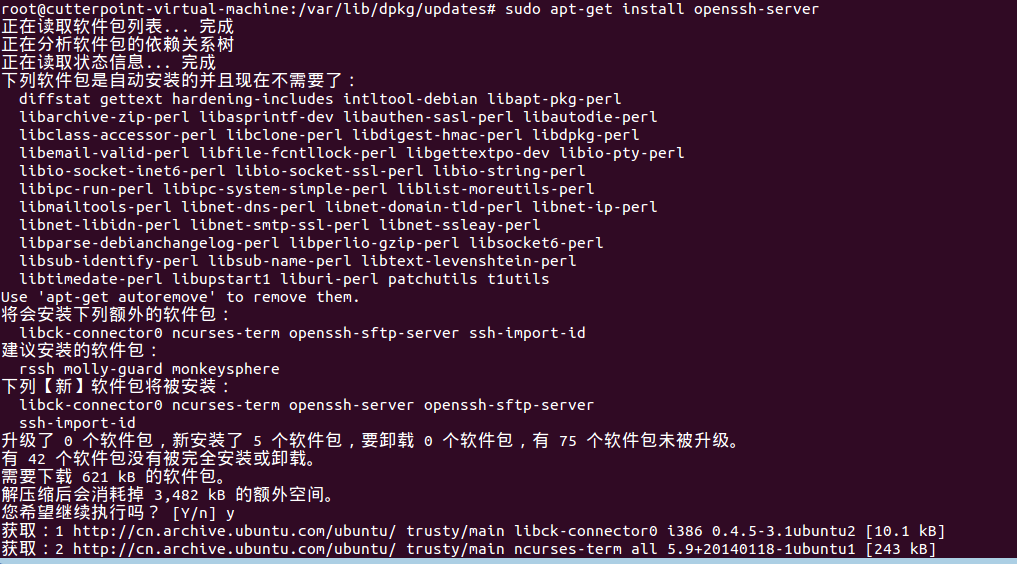
首先,更新一下系统(其实不必要,主要是因为有可能安装openssh-server不成功,所以,还是先更新一下吧)

安装open-ssh
sudo apt-get install openssh-server

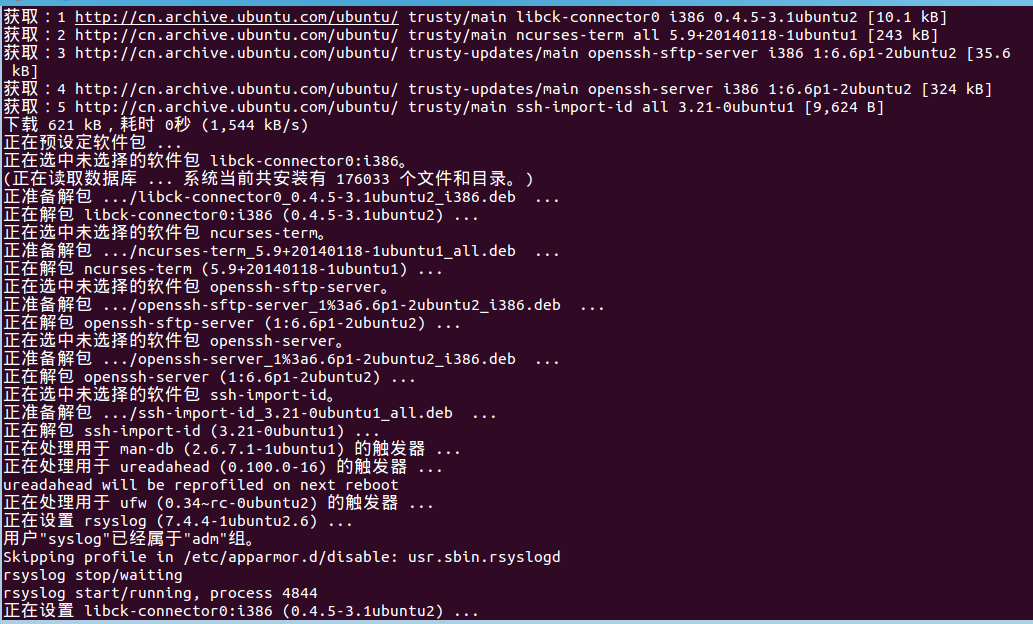
。。。
配置无密码登陆
接下来,配置无密码登录:
?
| 1 |
|

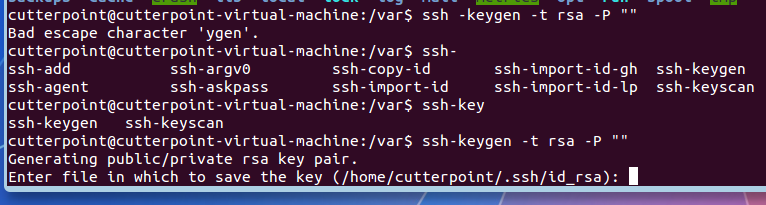
默认公钥和私钥存放
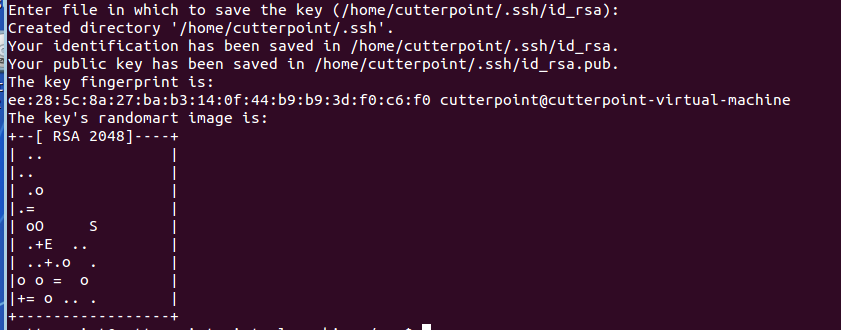
进入文件.ssh
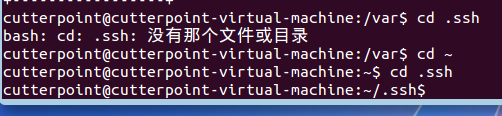
这将生成一个隐藏文件 .ssh,进入这个文件夹,然后将公钥追加到authorized_keys文件中,此文件最初并不存在,但执行追加命令后将自动生成:
?
| 1 2 |
|

最后,验证是否安装成功。用能否登录本机来验证,命令如下:
ssh localhost

输入yes

退出

现在,无密码登录配置成功~~~~
3、开始安装Hadoop
下载好Hadoop,然后修改权限:
sudo chmod 777 hadoop-0.20.203.0rc1.tar.gz

然后解压:
tar zxvf hadoop-2.6.0.tar.gz

修改解压出来的文件夹的权限(可以看到,解压出来的文件夹上有个灰颜色的锁,至少我这儿是这样)
sudo chmod 777 -R hadoop-0.20.203

也可以将文件夹的名字改得短一点,后文中笔者就用改后的名字:
mv hadoop-0.20.203 hadoop

解压工作完成,现在开始配置:
进入Hadoop的etc/hadoop文件中
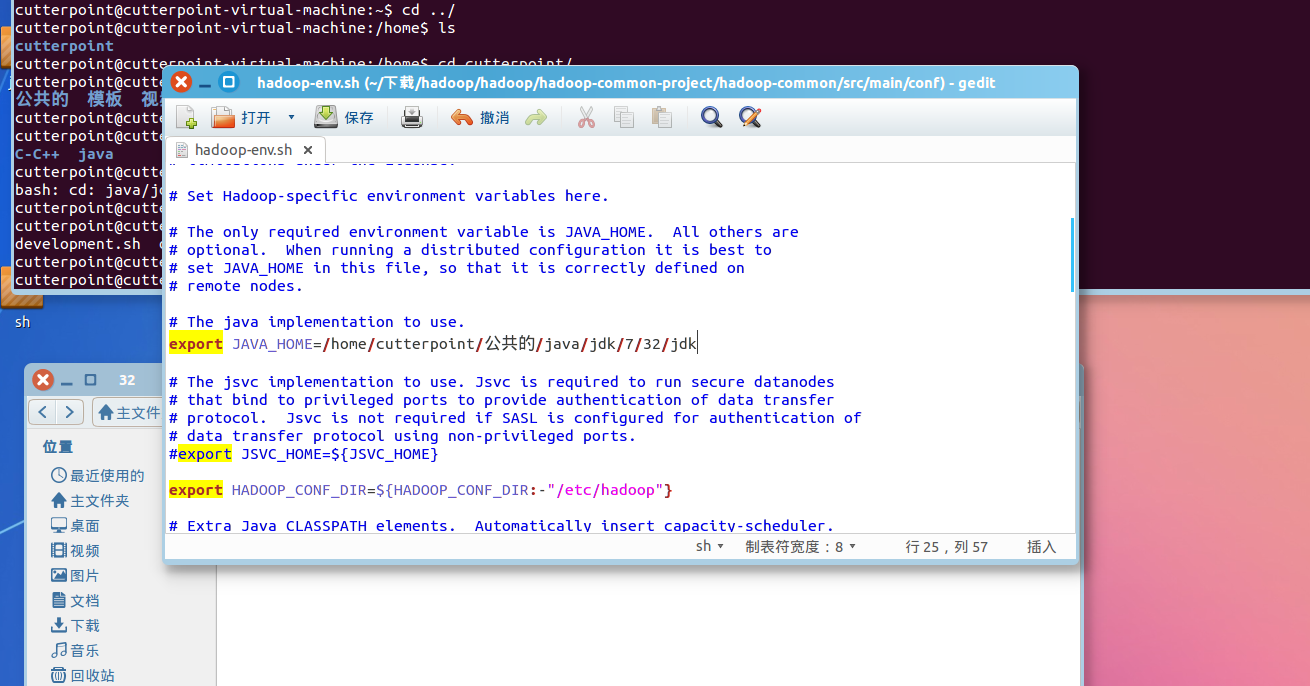
打开hadoop-env.sh文件,找到exportJAVA_HOME这句话,去掉注释标记,等号后面改成你的JDK路径,保存退出
打开Hadoop-env.sh文件

我的jdk路径是
/home/cutterpoint/公共的/java/jdk/7/32/jdk
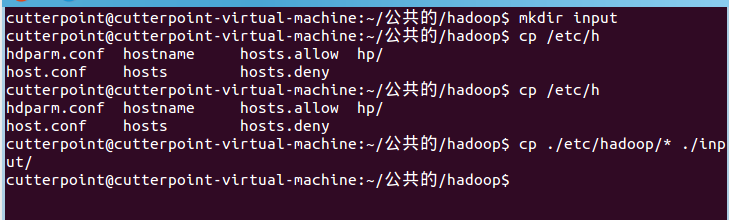
先进行简单测试:
$cd /home/hadoop/hadoop/
$mkdir input
$cp /etc/hadoop/* input/
$bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grepinput output 'dfs[a-z.]+'
$cd output
$cat *
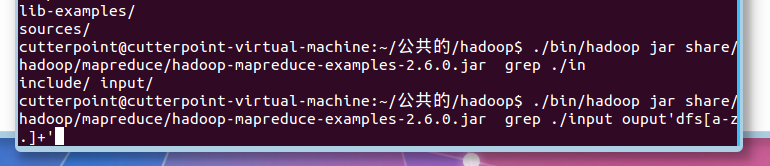
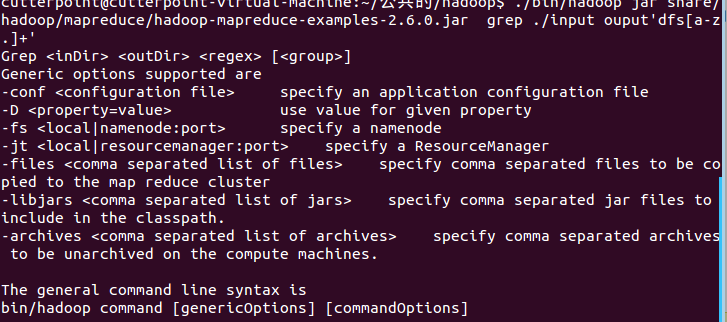
红框位置,图为去掉#号后的截图
接下来将配置三个文件core-site.xml,hdfs-site.xml,mapred-site.xml,其中,加入的内容都在<configuration>与</configuration>之间添加,后面不在一一赘述

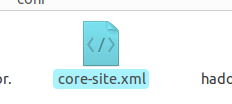
配置core-site.xml文件:
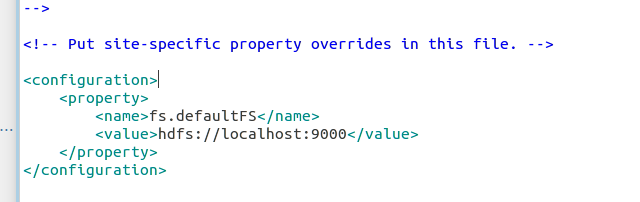
配置hdfs-site.xml文件:
加入如下内容:
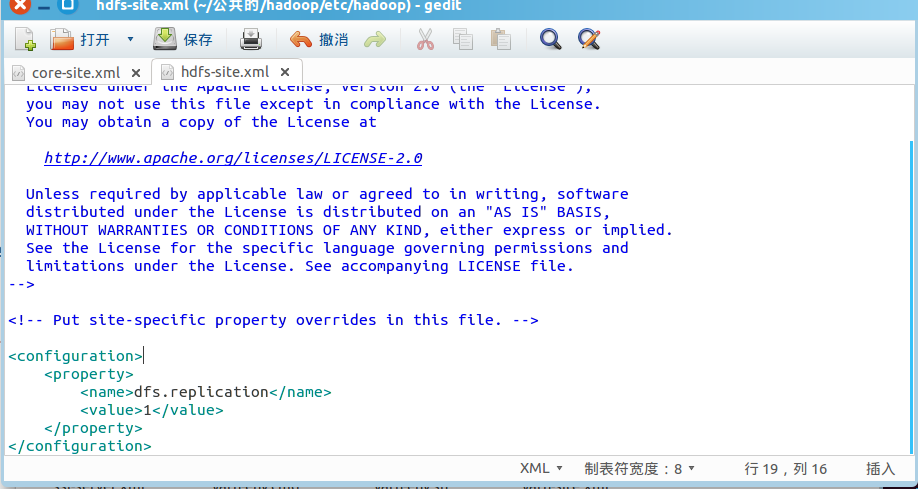
保存退出。
测试
$mkdir /home/hadoop/bin
$ln -s /home/hadoop/hadoop/jdk/bin/jps/home/hadoop/bin/
$cd /home/hadoop/hadoop/
$sbin/hdfs namenode -format 先进行初始化
$sbin/start-dfs.sh

配置mapred-site.xml
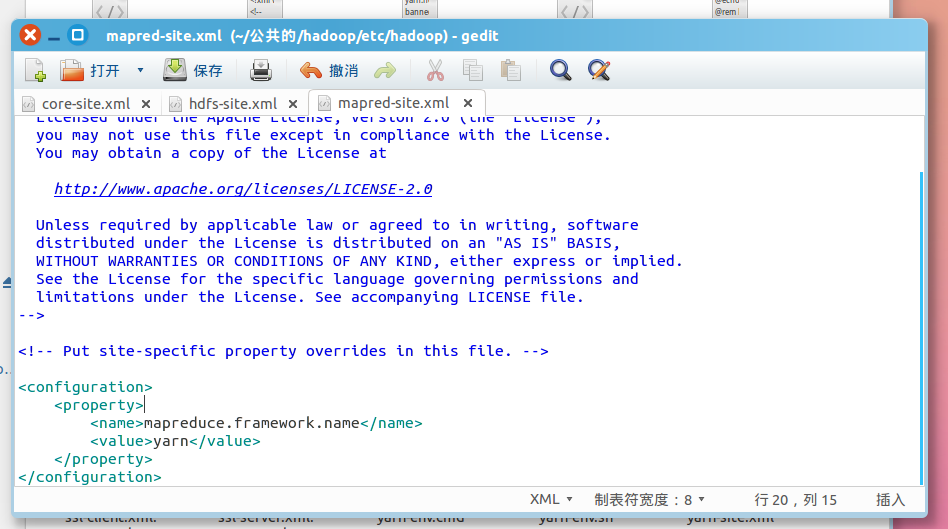
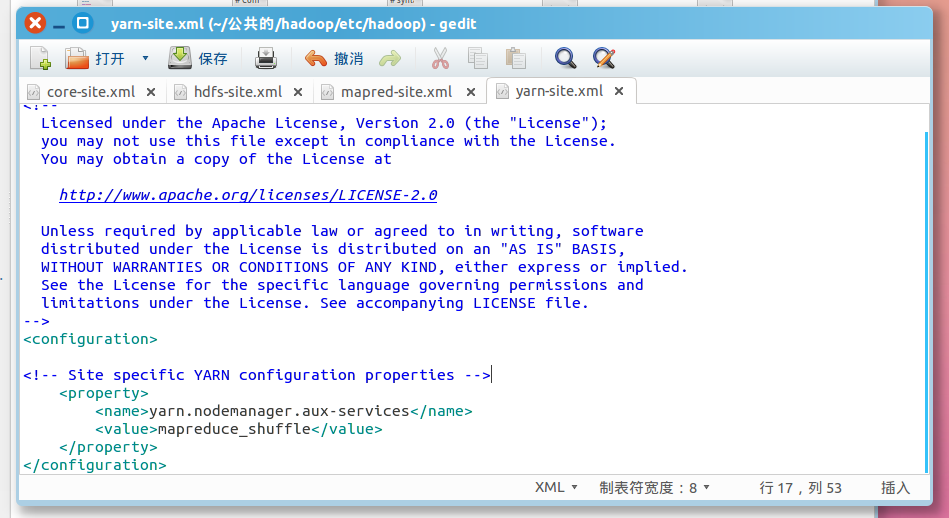
关于配置的一点说明:上面只要配置 fs.defaultFS 和 dfs.replication 就可以运行,不过有个说法是如没有配置 hadoop.tmp.dir 参数,此时 Hadoop 默认的使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在每次重启后都会被干掉,必须重新执行format 才行(未验证),所以伪分布式配置中最好还是设置一下。
配置完成后,首先在 Hadoop 目录下创建所需的临时目录:
cd /usr/local/hadoop
mkdir tmp dfs dfs/name dfs/data
那么我们还得配一下tmp
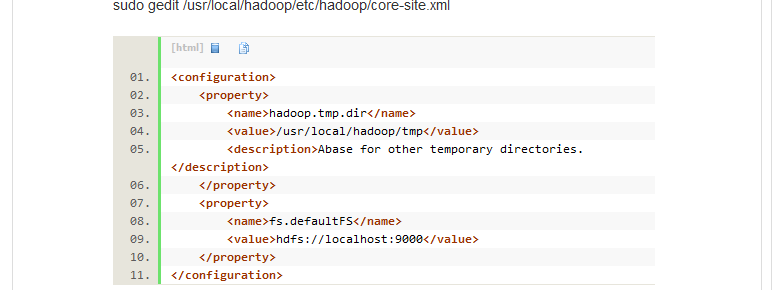
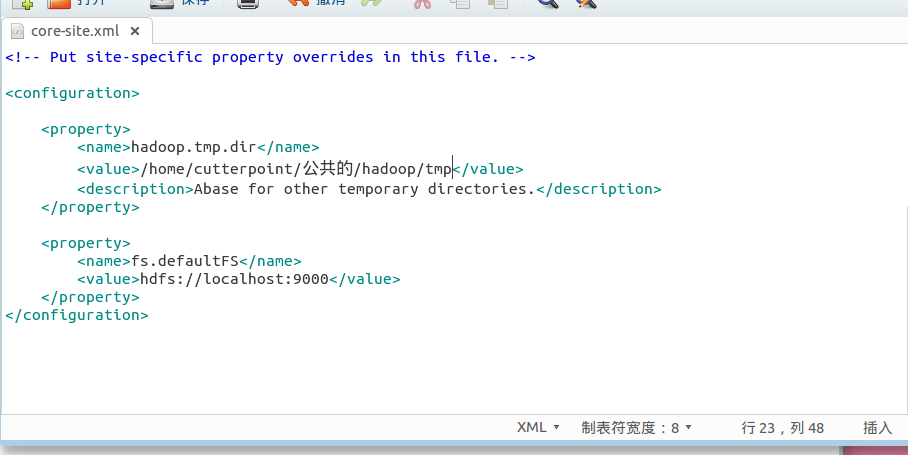
进行初始化文件系统hdfs

成功的话,最后的提示如下,Exitting with status 0 表示成功,Exitting with status 1: 则是出错。
开始运行
sbin/start-dfs.sh 这句我的会报错!!!!
sbin/start-yarn.sh


运行下面下局
http://localhost:8088
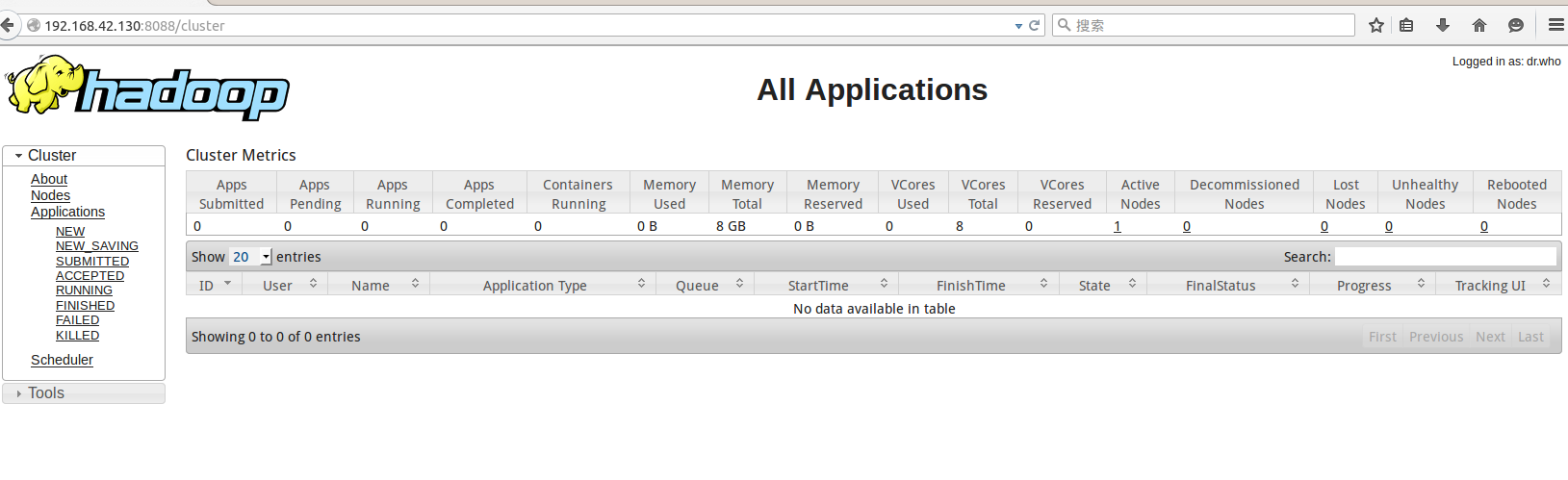
运行成功
问题
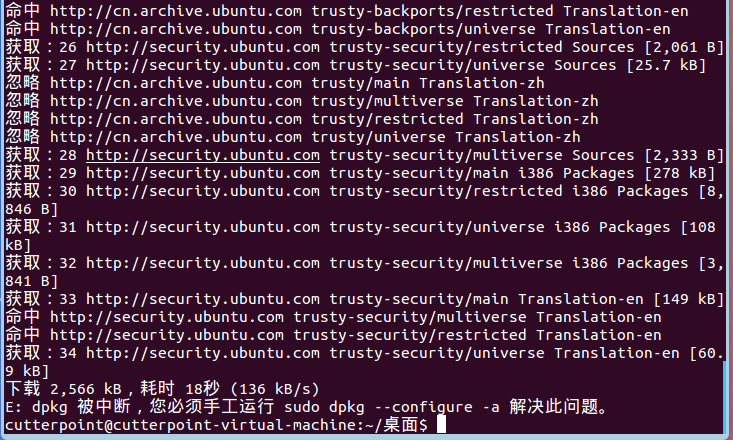
1、dpkg 被中断,您必须手工运行 sudo dpkg –configure -a解决此问题
前天给本地电脑虚拟机的Ubuntu系统安装FTP软件,结果没有安装成功,后面再安装其它软件就提示dpkg 被中断,您必须手工运行sudo dpkg --configure -a解决此问题,但是即使运行sudo dpkg --configure -a也不能解决问题,也在百度上找了一些解决方法,可还是没有搞定,最后在Ubuntu的论坛里面找到了解决方法。
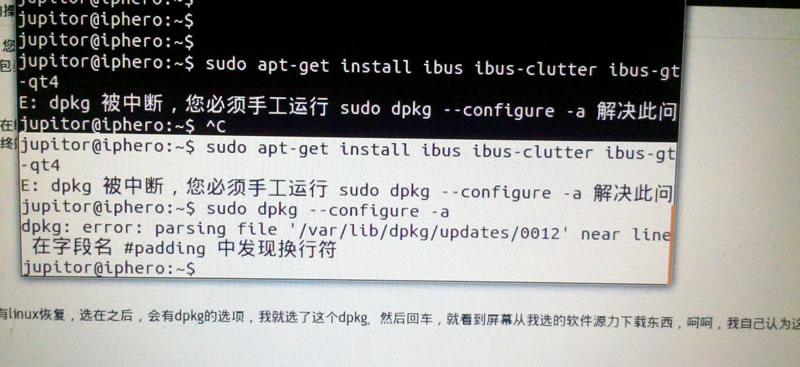
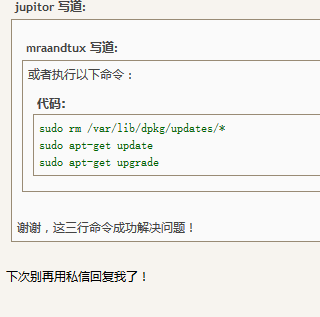
运行下面的命令即可解决
sudo rm /var/lib/dpkg/updates/*
sudo apt-get update
sudo apt-get upgrade
主要原因应该是/var/lib/dpkg/updates 文件夹里面的资料有错误,使得更新软件的程序出现错误,所以得把它们完全删除,通过sudo apt-get update这个指令会重新建立这些资料,使用sudoapt-get upgrade更新你的电脑里面已安装的软件的明细,根据软件的明细更新软件到最新版。
英文好的可以看看这篇文章:http://ubuntuforums.org/archive/index.php/t-941125.html
我:

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









