






作者 | 前进四先生 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/669376925
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【全栈算法】技术交流群
本文只做学术分享,如有侵权,联系删文
最近在思考自动驾驶( Autonomous Driving,以下简称AD)的发展趋势,发出来我的观点和大家讨论。
AD 1.0
定义
每个相机的图像输入给不同的模型来检测障碍物、车道线、交通灯等信息,融合模块使用规则来融合这些信息给规控模块,规控输出控车信号。具体架构如下图:
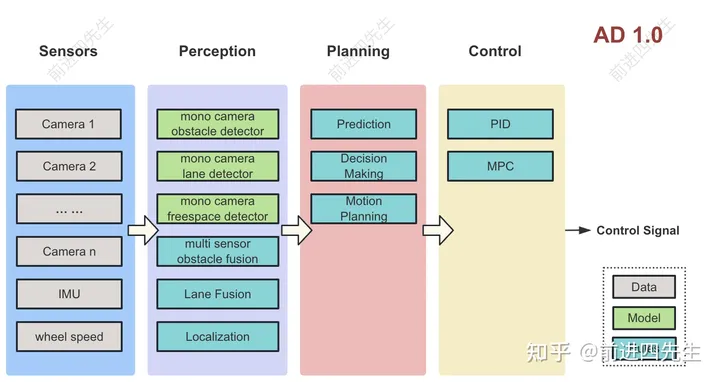
特点
每个相机图像单独过模型
有很多小模型:障碍物模型,车道线模型,交通灯模型等
融合、定位、规控模块都是人工编码
问题
障碍物是白名单制度,无法识别标注对象之外的目标,比如倒地的大卡车,路上的石块等等
障碍物表示为3D框,表示精度有限,比如运货大卡车凸出来的钢管等
规划模块不具备完备性,不考虑车辆运动之间的互相影响
融合、规控模块均为复杂的手工编码,迭代到最后非常容易出现顾此失彼的现象,难以维护
整个Debug流程本质上是用人力做反向传播,消耗的人力资源很多,无法规模化
应用案例
TDA4等低算力平台
2020年之前的特斯拉
2022年之前的国内新势力
总结
AD1.0仅支持实现高速场景辅助驾驶,国内新势力也都已经经过了这个阶段。
AD 2.0
定义
各个相机的输入统一给模型,直接由模型完成不同相机及时序间的信息融合,感知模型同时输出障碍物、占据栅格、车道结构等等。规控模型接收感知输出的feature,输出自车预测轨迹或者控车信号。架构如下图
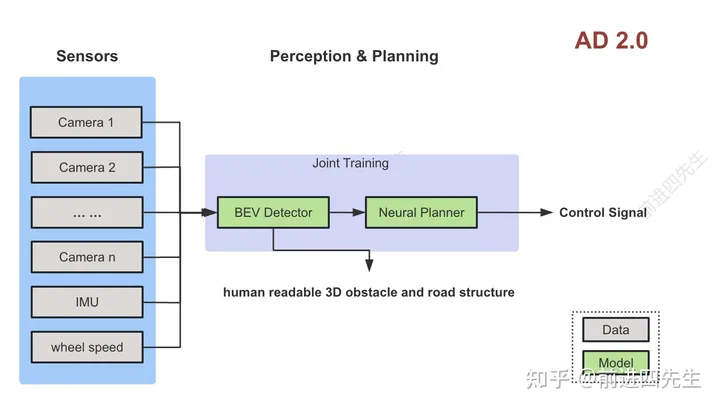
特点
感知只有一个BEV模型,完成多相机时序上的融合工作,输出3D障碍物、Occ、车道结构等信息。
规划也用模型,输出自车的预测轨迹或者控制信号
感知和规划模型必须要联合训练
问题
解决了通用障碍物的问题。但依然无法处理部分没有障碍物,但是需要特别注意的场景,比如说路面上有积水、未凝结的水泥路面、有水渍的环氧地坪地面等。
缺乏对现实世界的常识:比如塑料袋可以压过(物体材质),前方渣土车上的土块看起来要掉(地球有重力),前方路段是小学放学时间(社会规律),前面两个车撞到一起(突发事件)
和人类的交互太弱,目前的人机共驾只是人和汽车方向盘、油门的协同。人类无法告诉车辆『前面第二个路口右转,注意要提前上辅路』这类信息。
应用案例
Tesla FSD V12 (2023年11月开始员工内部推送)
英国的自动驾驶公司 Wayve
总结
AD 2.0支持实现城区辅助驾驶,但由于上述问题的存在,依然无法实现无人化。国内新势力在感知端已经完成了AD 2.0的切换,但是规控端还是规则,也可以称之为AD 1.5
AD 3.0
定义
AD 1.0和AD 2.0的架构已经在业界达成共识,但还是支撑不了真正的无人化驾驶。怎么能通向真正的无人化,目前并无确定的方向。
这里介绍一种可能的方案,把多模态大模型(Multi-modal LLM)作为Agent来控车,架构如下图。
相比AD 2.0的输入只有传感器数据,这里多了人类指令交互,机器可以听从人类指令,调整驾驶行为。
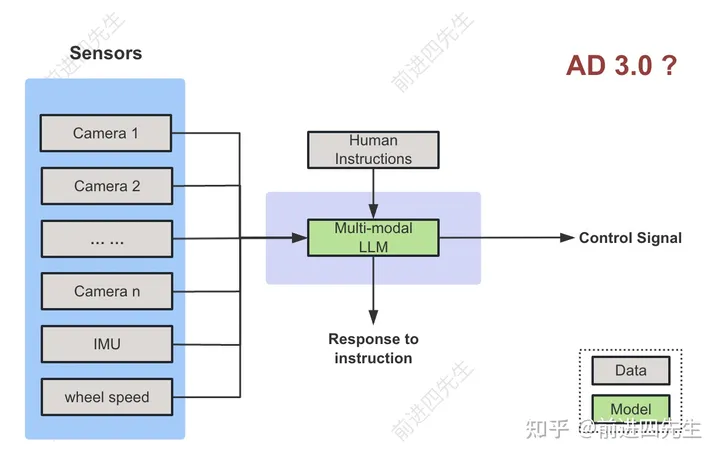
特点
由多模态大模型作为核心来控车
可以和人类(车内的乘客和车外的管理人员)进行语言交互
问题
怎么消除MLLM的幻觉问题?
怎么在车上实时的运行MLLM?
应用案例
暂无,硬要说的话可以看看OpenAI投资的自动驾驶公司Ghost Autonomy(Ghost也无法解决上车问题)
总结
这种方案上限很高,有望达到人类级别的驾驶水平。但是目前还在学术探索阶段,还需要几年时间才能落地。
在当前这个时间点,也许可以通过把MLLM部署在云端,来监管车辆自动驾驶的行为,并在必要的时候做出修正,类似于L4的远程司机,这种架构称之为AD 2.5?
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









