






点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
『自动驾驶之心知识星球』是聚焦于自动驾驶、具身智能、多模态大模型等最前沿的技术交流社区,星球每日分享行业动态、前沿技术、企业招聘等一手信息,欢迎加入!
DeepSeek发布最新的 Attention 算子论文:Native Sparse Attention(NSA),梁文锋挂名,与北大合作发布论文,解码提速11.6倍!
论文链接: https://arxiv.org/abs/2502.11089
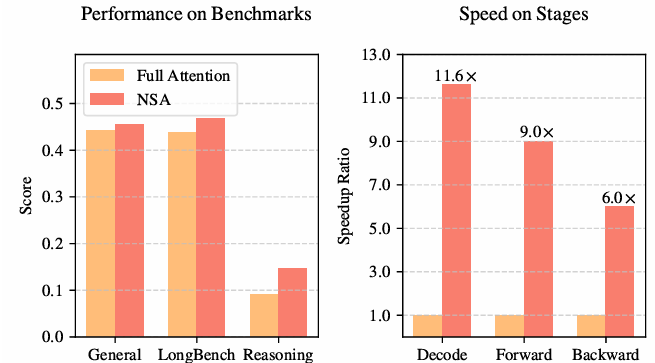
效果非常不错,主要有以下几个方面:
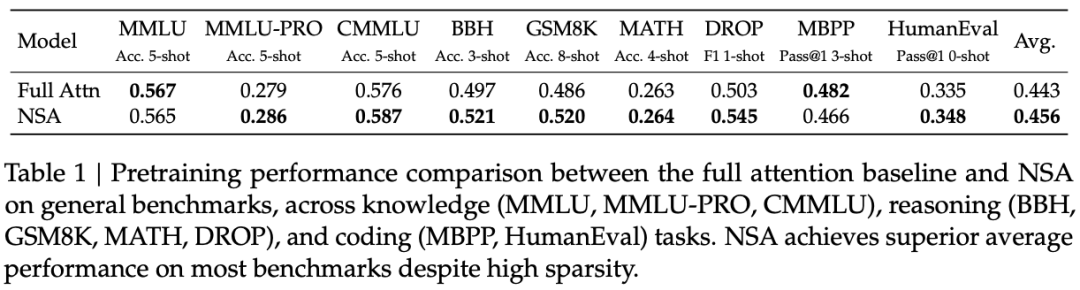
模型性能:优于常规 Full Attention
训练速度:64k序列下,前向传播加速9倍,反向传播加速6倍。
解码速度:内存访问量减少至全注意力的1/11.6,64k序列解码速度提升11.6倍。
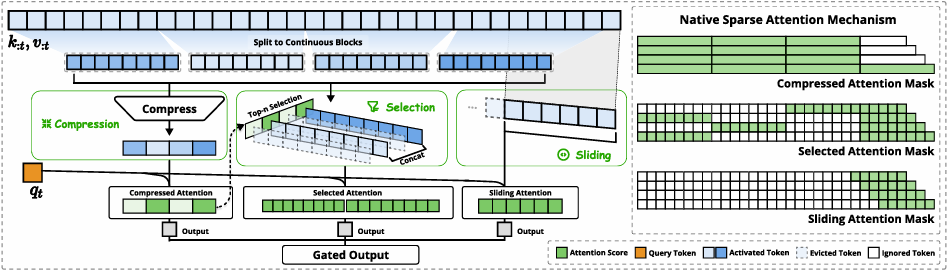
关键优化主要有三个:
动态层次稀疏策略,NSA通过三种并行注意力路径处理输入序列:
压缩路径(Compression):将连续令牌块聚合为粗粒度表示,捕获全局语义;
选择路径(Selection):基于重要性评分(利用压缩路径的中间注意力得分)动态保留关键令牌块,确保细粒度精度;
滑动窗口(Sliding Window):维护局部上下文,避免局部模式主导全局学习。
硬件对齐优化
块状内存访问:连续块处理适配GPU的Tensor Core和内存带宽,提升计算吞吐;
共享KV缓存:在GQA架构下,组内共享稀疏KV块索引,减少冗余内存访问;
专用内核设计:基于Triton实现高效前向/后向传播,支持FlashAttention级别的加速。
端到端可训练性
所有操作(包括重要性评分和门控)均为可微分的,支持梯度反向传播,以往的稀疏注意力都会有一些不可微分的结构,比如哈希计算等。
避免了离散操作(如聚类、哈希),确保稀疏模式通过训练动态优化。
本文内容均出自『自动驾驶之心知识星球』,欢迎加入交流,这里已经汇聚了近4000名自动驾驶从业人员,每日分享前沿技术、行业动态、岗位招聘、大佬直播等一手资料!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









