









对于使用hadoop进行日志分析等工作的开发者来说,相信一直都面临着一个非常头 疼的问题。那就是:对hadoop的mapreduce作业,在分布式集群上进行单个task的单步debug跟踪调试无法办到。只能在本地进行调试,然 后提交到集群中运行,但是集群中如果某个task总是失败,要对这一个task进行单步跟踪就非常困难。其实原因很简单,因为当把作业提交到hadoop 集群进行运行的时候,你事先根本就不知道那个map或者reduce的task会被分配到哪个tasktracker上执行。所以过去的两年里,写 mapreduce应用的工程师们一直面临着这个悬而未决的问题。只能通过在程序中加日志,并在作业完成或者失败后追踪日志来进行问题定位。无法达到对程 序象调试单机程序一样的进行调试。
其 实在hadoop中,有一个好东西,利用这个好东西,就可以实现在集群中对某个task进行单步调试的需求。这个东西就是 IsolationRunner。IsolationRunner是一个小工具,能够在tasktracker机器上,重新单独运行失败的task,这样 对于某些大作业(比如job的输入有100TB),如果因为某一个task重复失败而导致整个job失败,就不用连续不断的提交job,进行复现,然后定 位某个task失败的原因,这样做的代价就会非常的大。如果能够对失败的task进行单独执行,那么要定位问题的原因代价就变得很小,对工程师来说也非常 的方便。
要 想对失败的task进行单独重跑,肯定是有前提的,大家知道,对于map而言,其输入数据是来自分布式文件系统(通常是HDFS)中输入数据的某个 split,所以如果想要重跑map task,其输入数据就需要被保留下来。同样对于reduce而言,其输入是从所有map的中间结果shuffle到该reduce的数据,如果想要重跑 reduce task,这些数据也就需要保留下来。所以为了提供对失败的task进行单独重跑的功能,作业执行过程中的中间结果,或者每个map的输入数据对应的 split数据,就需要被保留下来。为此hadoop提供了一个作业的配置选项:keep.failed.task.files,该选项默认为 false,表示对于失败的task,其运行的临时数据和目录是不会被保存的,这也是hadoop在支持这项功能前默认的做法,因为如果失败的task的 临时文件和目录被保留的过多,会占据tasktracker上过多的磁盘空间和文件数,造成磁盘浪费。而当将 keep.failed.task.files选项设置为true(注意:该配置选项是一个per job的配置),那么hadoop在执行该job时,当发生map fail或者reduce fail时,就会将task能够单独重跑的所有环境都保留下来,比如task运行时对应的job.xml,map input对应的split.dta文件,或者reduce的输入file.out文件。这样,要重跑一个map或者reduce task的环境就已经具备。
如何重跑:
当fail的task环境具备以后,就可以对单独的task进行重跑了。重跑的方式为:
- 上到task出错的tasktracker机器 上
- 在该tasktracker上找到fail的task运行时的目录环境
- 在 tasktracker中,对于每一个task都会有一个单独的执行环境,其中包括其work目录,其对应的中间文件,以及其运行时需要用到的配置文件等
- 这些 目录是由tasktracker的配置决定,配置选项为: mapred.local.dir. 该选项可能是一个逗号分隔的路径list,每个 list都是tasktracker对在其上执行的task建立工作目录的根目录。比如如果mapred.local.dir=/disk1 /mapred/local,/disk2/mapred/local,那么task的执行环境就是mapred.local.dir /taskTracker/jobcache/job-ID/task-attempt-ID
- 找到该task的执行工作目录后,就可以进入到 该目录下,然后其中就会有该task的运行环境,通常包括一个work目录,一个job.xml文件,以及一个task要进行操作的数据文件(对map来 说是split.dta,对reduce来说是file.out)。
- 找到环境以后,就可以重跑task了。
- cd work
- hadoop org.apache.hadoop.mapred.IsolationRunner ../job.xml
-
- 这样,IsolationRunner就会读取job.xml的配置(这里的job.xml相当 于提交客户端的hadoop-site.xml配置文件与命令行-D配置的接合),然后对该map或者reduce进行重新运行。
- 到这里为止,已经实现了task单独重跑,但是还是没有解决对其进行单步断点debug。这里利用到的其实是jvm的远程 debug的功能。方式如下:
- 在重跑task之前,export一个环境变 量:export HADOOP_OPTS="-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=8888"
- 这 样,hadoop的指令就会通过8888端口将debug信息发送出去
- 然后在自己本地的开发环境IDE中(比如 eclipse),launch一个远程调试,并在代码中打一个断点,就可以对在tasktracker上运行的独立map或者reduce task进行远程单步调试了。
以下是图解示意,这里采用最简单的wordcount来进行示例。在wordcount的输入文 件中,加入一行数据,如“guaishushu”,然后修改wordcount的Mapper实现,如下:
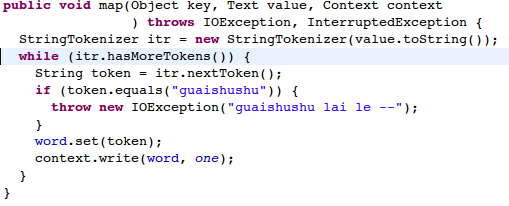
这样修改以后,由于数据中有 “guaishushu”的字符串,并且该行一定会被落到某个map的输入中去,然后代码中当读到”guaishushu”的时候会抛出 IOException异常,所以该job在运行过程中就肯定会有一个task失败。然后,在提交作业时,将 keep.failed.task.files设置为true,并按如下程序提交,job就开始运行:
- 在jobtracker监控web页面上找到 task失败的机器,并确保keep.failed.task.files为true


- 上到该tasktracker,并找到该 task运行环境

- 进到该task运行环境的work目录(如果没有,可以自己创建
- export jvm远程调试环境变量

- 运行IsolationRunner

- 在自己的开发机IDE环境中launch一个远 程调试进程

- 单步跟踪示意















 1972
1972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









